

1.مقدمه
الگوریتم ساده بیز (Naive Bayes) یکی از قدیمیترین و در عین حال مؤثرترین الگوریتمهای یادگیری ماشین است که بر پایه نظریه احتمال و قضیه بیز عمل میکند. این الگوریتم با وجود سادگی ساختاری، در بسیاری از مسائل دستهبندی عملکردی سریع، پایدار و قابل قبول ارائه میدهد. ایده اصلی Naive Bayes این است که ویژگیهای ورودی را مستقل از یکدیگر فرض میکند؛ فرضی که اگرچه در بسیاری از مسائل واقعی کاملاً برقرار نیست، اما در عمل باعث کاهش پیچیدگی محاسباتی و افزایش سرعت مدل میشود.
سادگی، سرعت بالا و نیاز کم به داده آموزشی باعث شده Naive Bayes در حوزههایی مانند فیلتر اسپم، تحلیل احساسات، دستهبندی متون، تشخیص بیماری و سیستمهای توصیهگر کاربرد گستردهای داشته باشد. این الگوریتم بهویژه در مسائل پردازش زبان طبیعی (NLP) و دادههای با ابعاد بالا عملکرد بسیار خوبی از خود نشان میدهد و همچنان بهعنوان یکی از روشهای پایه و مهم در یادگیری ماشین شناخته میشود.
در این مقاله، ابتدا مبانی احتمالاتی و قضیه بیز را بررسی میکنیم، سپس انواع مختلف Naive Bayes شامل Gaussian، Multinomial و Bernoulli را معرفی خواهیم کرد. در ادامه، نحوه پیادهسازی عملی، معیارهای ارزیابی، مزایا و محدودیتها و همچنین کاربردهای صنعتی این الگوریتم را تحلیل میکنیم تا درکی جامع و کاربردی از عملکرد آن به دست آوریم.
2.تعریف
در دنیای یادگیری ماشین، ساده بیز (Naive Bayes) یک الگوریتم طبقهبندی نظارتشده (Supervised Learning) و احتمالی است که بر پایهی قضیه معروف بیز در آمار بنا شده است. این الگوریتم در دسته مدلهای مولد (Generative Learning Algorithms) قرار میگیرد؛ به این معنی که تلاش میکند نحوه توزیع و انتشار ویژگیهای ورودی را در هر طبقه یا کلاس خاص مدلسازی کند، برخلاف مدلهای متمایزگر (Discriminative) مانند رگرسیون لجستیک که صرفاً به دنبال یافتن مرز جداسازی کلاسها هستند.
راز سرعت و کارایی خیرهکننده ساده بیز، در فرض منحصربهفرد آن یعنی استقلال شرطی کلاس (Class Conditional Independence) نهفته است. این الگوریتم با سادهانگاری (که دلیل نامگذاری آن به Naive یا سادهلوح است) فرض میکند که تکتک ویژگیهای ورودی یک داده، کاملاً مستقل از یکدیگر روی خروجی اثر میگذارند و هیچ همبستگی یا ارتباط درونی با هم ندارند. اگرچه این فرض در دنیای واقعی و ترند دادهها به ندرت صدق میکند، اما محاسبات ریاضی را به شدت ساده و خطی کرده و به مدل اجازه میدهد روی دیتابیسهای بسیار بزرگ، با سرعت و دقتی باورنکردنی عمل کند.
مثال:
فرض کنید بانک میخواهد درخواست وام یک متقاضی را بررسی و او را در یکی از دو کلاس مجاز به دریافت وام یا غیرمجاز طبقهبندی کند. ویژگیهای این شخص عبارتند از: ۱. میزان درآمد ۲. سن ۳. سابقه اعتباری و تراکنشها
در واقعیت، این ویژگیها به هم وابستهاند .اما الگوریتم ساده بیز این وابستگی را کاملاً نادیده میگیرد! این مدل هر ویژگی را به صورت جداگانه و مستقل پردازش میکند؛ یعنی اثر درآمد را بدون توجه به سن، و اثر سابقه اعتباری را بدون توجه به درآمد میسنجد. در نهایت، با ضرب کردن این احتمالات مستقل در یکدیگر، با سرعتی بالا پیشبینی میکند که این فرد چقدر شانس قرارگیری در کلاس «مجاز به دریافت وام» را دارد.
3.اهمیت و جایگاه
در چشمانداز مدرن یادگیری ماشین، ضرورت استفاده از یک الگوریتم هوشمند همواره با چالشهای بزرگی نظیر محدودیت زمان محاسباتی، پدیده شوم ابعاد داده (Curse of Dimensionality) و حجم عظیم متون دیجیتال همراه است. دلایل زیر تبیین میکنند که چرا در توسعه سیستمهای هوشمند عملیاتی و بلادرنگ، استفاده از طبقهبند ساده بیز (Naive Bayes) یک نیاز راهبردی و زیرساختی است:
- ضرورت پردازش در گلوگاههای تصمیمگیری آنی (Real-Time Processing): در دنیای امروز، سیستمهایی مانند موتورهای توصیه گر یا فیلترینگ هرزنامهها باید در کسری از ثانیه تصمیمگیری کنند. ضرورت استفاده از ساده بیز در این سناریوها، ساختار محاسباتی خطی و فوقسریع آن است. این مدل به جای درگیر شدن با فرآیندهای بهینهسازی پیچیده و تکراری، با یک پاس محاسباتی بر پایه شمارش فراوانیها، به سرعت پاسخ نهایی را استخراج میکند.
- مدیریت بحران کمبود داده در لایههای اولیه پروژه (Data Scarcity): بسیاری از الگوریتمهای پرقدرت تا زمانی که با میلیونها نمونه داده تغذیه نشوند، به همگرایی و دقت مطلوب نمیرسند. دلیل اهمیت ساختاری ساده بیز این است که به دلیل تکیه بر احتمالات مستقل پیشین و پسین، با دیتابیسهای بسیار کوچک و محدود نیز کارایی شگفتانگیز و پایداری از خود نشان میدهد و هزینههای جمعآوری دیتا را به حداقل میرساند.
- نیاز حیاتی به تحلیل فضاهای متنی با ابعاد بینهایت: در پردازش زبان طبیعی (NLP)، هر کلمه منحصربهفرد حکم یک ویژگی جدید را دارد که ابعاد ریاضی مسئله را به شدت بالا میبرد. فرآیند ساده بیز به طور ذاتی برای مهار پدیده شوم ابعاد طراحی شده است؛ این مدل بدون از دست دادن پایداری احتمالی، هزاران واژه را به طور همزمان تحلیل کرده و همبستگیهای متنی را بدون قفل کردن پردازنده مهار میکند.
.
4. مروری بر آمار و احتمالات بیزی
در تفکر کلاسیک (فراوانیگرا)، احتمال صرفاً به عنوان حد فراوانی رخ دادن یک پدیده در آزمایشهای مستقل و بینهایت تعریف میشود؛ رویکردی صلب که توانایی ارزشگذاری روی رویدادهای یکتا را ندارد. اما در آمار بیزی، احتمال ابزاری پویا برای کوانتیزه کردن میزان باور، درجه اطمینان یا عدم قطعیت ما درباره یک فرضیه است.
نکته استراتژیک در آمار بیزی این است که باورهای ما ایستا نیستند؛ با ورود شواهد، دادهها و مشاهدات تجربی جدید (Data)، تفکر اولیه ما دچار اصلاح و بهروزرسانی نهایی میشود. این فرآیند بازگشتی به کمک قضیه بیز (Bayes’ Theorem) فرمولبندی میشود که ریاضیات آن به صورت زیر کالبدشکافی میگردد:

برای درک تئوریک و دقیق این ساختار، متغیرهای کلیدی آن را بررسی میکنیم:
- P(H|D) – احتمال پسین (Posterior Probability): میزان باور اصلاحشده به فرضیه H، پس از مشاهده و تحلیل دادههای جدید D (هدفی که مدل به دنبال محاسبه آن است).
- P(D|H)– درستنمایی (Likelihood): احتمال اینکه شواهد و دادههای D پدیدار شوند، به شرطی که فرض کنیم فرضیه H کاملاً درست است.
- P(H) –احتمال پیشین (Prior Probability): میزان باور اولیه و مستقل ما به درست بودن فرضیه H، پیش از آنکه هیچ داده تجربی جدیدی را وارد مسئله کنیم.
- P(D) –احتمال حاشیهای یا شواهد (Evidence): احتمال کل رخ دادن شواهد D تحت تمامی فرضیههای ممکن که به عنوان یک فاکتور نرمالسازی عمل میکند تا مجموع احتمالات پسین کلاسها را برابر با ۱ نگه دارد.

این فرمولاسیون به طبقهبند ساده بیز اجازه میدهد تا اطلاعات گذشته را با مشاهدات آنی ترکیب کرده و به دقیقترین استنتاج احتمالی دست یابد.
5. مبانی ریاضی، فرمولها و کالبدشکافی متغیرها
هنگام مواجهه با یک مسئله یادگیری ماشین نظارتشده (Supervised Learning)، ما با یک بردار ویژگیهای ورودی (Feature Vector) به نام X و یک متغیر هدف، برچسب یا کلاس خروجی (Target Class) به نام y سروکار داریم. فرض کنید فضای ویژگیهای ما دادهای با ابعاد n باشد که به صورت زیر تعریف میشود:

در این ساختار ریاضی:
- X: بردار کل ویژگیهای یک نمونه داده ورودی است.
- xi: نشاندهنده مقدار ویژگی i-ام از این نمونه داده است (مانند سن، میزان درآمد، یا وجود یک کلمه خاص در متن).
- y: متغیر هدف دوتایی یا چندگانه است که کلاس نهایی داده را مشخص میکند (مانند هرزنامه/غیرهرزنامه یا مثبت/منفی).
قضیه بیز احتمال وقوع کلاس y را به شرط مشاهده بردار ویژگیهای سیستم (X) از طریق ابزار آمار احتمالات به صورت زیر محاسبه میکند:

- P(y | X) یا P(y | x1,… , xn) – احتمال پسین (Posterior Probability): این اصطلاح دقیقاً همان خروجی هدف مدل است؛ یعنی احتمال اینکه داده ورودی متعلق به کلاس y باشد، به شرطی که ویژگیهای مشخصه X پدیدار شده باشند.
- P(x1, … , xn | y) – درستنمایی توام (Joint Likelihood): توزیع احتمال همزمان ویژگیها را به شرط تعلق داده به کلاس y نشان میدهد.
- P(y) – احتمال پیشین کلاس (Class Prior Probability): شانس عمومی و پایهای رخ دادن کلاس y در کل جامعه دادهها، پیش از بررسی هرگونه شواهد جدید است.
- P(X) یا P(x1,… , xn) – احتمال حاشیهای یا شواهد (Evidence / Marginal Likelihood): احتمال کل وقوع این ترکیب خاص از ویژگیها در کل دادهها است که به عنوان فاکتور نرمالسازی عمل میکند. با استفاده از قانون احتمال کل، مخرج کسر به صورت زیر باز میشود:

در این رابطه، yk نشاندهنده تکتک کلاسهای ممکن در فضای مسئله است.

6.فرضیه سادهلوحانه (The Naive Assumption) و استقلال شرطی
در دنیای واقعی، محاسبه درستنمایی توام یعنی P(x1, x2, … , xn |y) به دلیل پدیده شوم ابعاد (Curse of Dimensionality) و نیاز به حجم عظیمی از دادههای ترکیبی غیرممکن است. اینجاست که الگوریتم، فرضیه استقلال شرطی کلاس (Class Conditional Independence) را اعمال میکند. مدل فرض میکند که به شرط مشخص بودن کلاس y، وجود یا عدم وجود هر ویژگی، هیچگونه ارتباط یا همبستگی آماری با ویژگیهای دیگر ندارد. با این سادهسازی بزرگ، احتمال توام به حاصلضرب احتمالات تکتک ویژگیها تبدیل میشود:

- ∏: اپراتور حاصلضرب ریاضی است که احتمالات شرطی هر ویژگی را در هم ضرب میکند.
- P(xi |y): احتمال وقوع ویژگی i-ام به شرط تعلق داده به کلاس y است.
.
معادله بنیادی طبقهبند ساده بیز
با جایگذاری فرضیه استقلال شرطی در فرمول اصلی، به معادله بنیادی طبقهبند ساده بیز میرسیم:

از آنجا که مخرج کسر (P(X)) صرفاً به ویژگیهای ورودی بستگی دارد و برای تمام کلاسهای خروجی مقداری کاملاً ثابت و یکسان است، در فرآیند بهینهسازی و مقایسه کلاسها حذف میشود. این امر فرمول را به یک رابطه تناسبی کارآمد تبدیل میکند:

- ∝: علامت تناسب مستقیم ریاضی است.
.
معیار تصمیمگیری ماکزیمم پسین (MAP Decision Rule)
برای صدور پیشبینی نهایی، مدل برچسب کلاسی (ŷ) را انتخاب میکند که بیشترین مقدار احتمالی را به دست آورد. این روش تصمیمگیری در آمار به تخمین ماکزیمم پسین (MAP – Maximum A Posteriori) معروف است و فرمولاسیون آن به صورت زیر تبیین میشود:

- ŷ: برچسب کلاس پیشبینی شده نهایی توسط مدل برای نمونه ورودی است.
- arg maxy: تابعی است که در میان تمام کلاسهای ممکن (y)، کلاسی را که مقدار عبارات جلویش را به حداکثر میرساند، جستجو و استخراج میکند.
.
7.انواع مختلف مدلهای ساده بیز
الگوریتم ساده بیز یکپارچه نیست؛ بلکه شامل خانوادهای از الگوریتمهاست که تفاوت اصلی آنها در نوع توزیع آماری دادههای ورودی (ویژگیها) نهفته است. بسته به اینکه دادههای شما پیوسته، شمارشی یا باینری باشند، باید از نسخه متناسب با همان ساختار استفاده کنید تا فرض لایکلیهود (Likelihood) به درستی محاسبه شود.
سه مدل استاندارد و پرکاربرد ساده بیز عبارتند از:
- ساده بیز گاوسی (Gaussian Naive Bayes)
- ساده بیز چندجملهای (Multinomial Naive Bayes)
- ساده بیز برنولی (Bernoulli Naive Bayes)

ساده بیز گاوسی (Gaussian Naive Bayes)
این نسخه زمانی به کار میرود که ویژگیهای ورودی مسئله، متغیرهای پیوسته (Continuous) و عددی باشند (مانند سن، دما، فشار خون یا قیمت). در این مدل فرض میشود که دادههای مربوط به هر ویژگی در هر کلاس، از یک توزیع نرمال یا گاوسی (Normal/Gaussian Distribution) پیروی میکنند.
هنگام رسم این توزیع، یک منحنی متقارن ناقوسیشکل (Bell-shaped Curve) حول میانگین دادهها حاصل میشود. مدل برای هر کلاس، میانگین (μ) و واریانس (σ ^2) ویژگیها را محاسبه کرده و تابع درستنمایی ریاضی را به صورت زیر فرمولبندی میکند:

- xi: مقدار ویژگی پیوسته مورد نظر.
- μC: میانگین ویژگی xi در کلاس C.
- σC^2: واریانس (میزان پراکندگی) ویژگی xi در کلاس C.
.
ساده بیز چندجملهای (Multinomial Naive Bayes)
این مدل گزینهای بیرقیب برای دادههای گسسته (Discrete) و فرکانسی است؛ یعنی سناریوهایی که ویژگیها نشاندهنده تعداد تکرار، شمارش یا فراوانی یک پدیده هستند. بارزترین کاربرد ساده بیز چندجملهای در پردازش زبان طبیعی (NLP) و دستهبندی متون (مانند تفکیک ایمیلهای هرزنامه) است، جایی که تعداد تکرار کلمات کلیدی در سند اهمیت استراتژیک دارد.
در این مدل، احتمال حضور یک ویژگی (مانند یک کلمه خاص) در یک کلاس به صورت زیر محاسبه میشود:

- Count (xi in class C): تعداد کل دفعاتی که ویژگی xi (کلمه مورد نظر) در نمونههای متعلق به کلاس C تکرار شده است.
- مخرج کسر: مجموع تعداد تکرار تمام ویژگیها (کل کلمات) در آن کلاس خاص.
.
ساده بیز برنولی (Bernoulli Naive Bayes)
مدل برنولی برای ویژگیهای باینری یا بؤلین (Binary/Boolean) طراحی شده است؛ یعنی متغیرهایی که تنها دو حالت دارند: صفر یا یک، درست یا نادرست، بودن یا نبودن.
برخلاف مدل چندجملهای که تعداد تکرار یک کلمه برایش مهم بود، در ساده بیز برنولی فقط وجود یا عدم وجود (Presence or Absence) یک ویژگی اهمیت دارد. به عنوان مثال، در فیلترینگ ایمیل، مدل فقط بررسی میکند که آیا کلمه “وام” در متن وجود دارد (۱) یا خیر (۰)، و کاری به این ندارد که این کلمه چند بار تکرار شده است. این متد برای متون کوتاه یا دیتابیسهایی با ویژگیهای کیفیِ دوقطبی فوقالعاده کارآمد است.
.
جدول مقایسه و انتخاب هوشمندانه مدل
| نوع مدل ساده بیز | نوع دادههای ورودی (Features) | کاربرد شاخص صنعتی | مبنای ریاضی فرضیه |
| Gaussian NB | پیوسته / عددی (شکلات، قد، دما) | تشخیص بیماریها، پیشبینیهای مالی | توزیع نرمال (ناقوسی) |
| Multinomial NB | گسسته / شمارشی (تعداد کلمات) | دستهبندی اسناد، تحلیل سیستمهای متنی | توزیع چندجملهای فراوانی |
| Bernoulli NB | باینری / صفر و یک (بودن/نبودن واژه) | فیلتر هرزنامه متون کوتاه، بررسی ویژگیهای دوقطبی | توزیع برنولی (موفقیت/شکست) |
8. مکانیزم عملکرد و فرآیند گامبهگام طبقهبند ساده بیز
الگوریتم ساده بیز برای پیشبینی برچسب یا کلاس یک نمونه داده جدید، یک فرآیند منظم احتمالی و مبتنی بر شمارش آماری را طی میکند. در این راهبرد محاسباتی، هدف نهایی یافتن کلاسی است که بیشترین احتمال پسین (Posterior Probability) را به خود اختصاص دهد. چرخه عملیاتی این الگوریتم را میتوان به گامهای ساختاریافته زیر تقسیم کرد:
- گام ۱: فاز یادگیری و استخراج احتمالات پیشین (Prior Probabilities)
- گام ۲: محاسبه جدول درستنمایی ویژگیها (Likelihood Tables)
- گام ۳: فاز ارزیابی و محاسبه حاصلضرب احتمالات (Joint Score Calculation)
- گام ۴: نرمالسازی احتمالات پسین (Normalization Phase)
- گام ۵: اعمال قاعده تصمیمگیری و صدور پیشبینی نهایی
.
فاز یادگیری و استخراج احتمالات پیشین (Prior Probabilities)
در اولین مرحله از فرآیند آموزش (Learning Phase)، مدل بدون در نظر گرفتن ویژگیهای ساختاری دادهها، صرفاً به توزیع فراوانی خودِ کلاسها در مجموعهداده نگاه میکند. با محاسبه نسبت تعداد تکرار هر کلاس به تعداد کل نمونههای آموزشی، شانس پایه یا احتمال پیشین هر کلاس (P(yk)) استخراج میشود. این احتمالات به عنوان وزنهای اولیه در تصمیمگیری نهایی عمل میکنند.

محاسبه جدول درستنمایی ویژگیها (Likelihood Tables)
در این مرحله، الگوریتم فرضیه استقلال شرطی را به کار میگیرد. برای تکتک ویژگیهای موجود در بردار ورودی، مدل بررسی میکند که آن ویژگی با چه احتمالی در یک کلاس خاص رخ میدهد. این کار از طریق تفکیک دادهها بر اساس برچسب خروجی و محاسبه فراوانی هر صفت (xi) به شرط وقوع آن کلاس (yk) انجام میشود. خروجی این گام، ماتریسی از احتمالات مشروط مجزا (P(xi ∣ yk)) است.
نکته حیاتی و متمایزکننده ۱: بنبست فرکانس صفر و هموارسازی لاپلاس (Laplace Smoothing)
در این گام، اگر یک ویژگی خاص در دادههای تست پدیدار شود که در طول فاز آموزش در یک کلاس مشخص (مثلاً yk) هرگز دیده نشده باشد، مقدار فراوانی آن صفر شده و در نتیجه P(xi ∣ yk) = 0 خواهد شد. از آنجا که فرمول گام بعدی بر پایه حاصلضرب احتمالات است، این صفر کل خروجی را نابود میکند. برای حل این مشکل، مدل مقادیر را با تکنیک هموارسازی لاپلاس اصلاح میکند:

- α: پارامتر هموارسازی است (که معمولاً ۱ در نظر گرفته میشود).
- V: تعداد کل ویژگیهای منحصربهفرد در مجموعهداده (ابعاد فضای ویژگی) است.
.
فاز ارزیابی و محاسبه حاصلضرب احتمالات (Joint Score Calculation)
با ورود یک نمونه داده جدید برای تست، مدل ویژگیهای آن را استخراج میکند. سپس با رجوع به جداول درستنمایی که در گام دوم ساخته شدهاند، احتمالات مشروط مربوط به ویژگیهای این نمونه جدید را فراخوانی میکند. بر اساس صورت قضیه بیز، امتیاز احتمالی هر کلاس از حاصلضرب احتمال پیشین آن کلاس در تکتک احتمالات درستنمایی ویژگیهای ورودی به دست میآید:

نکته حیاتی و متمایزکننده ۲: مهار چالش سرریز منفی دادهها در فضای لگاریتمی (Log-Space Transition)
در مسائلی با ابعاد بسیار بزرگ (مانند پردازش متن با هزاران کلمه)، ضرب کردن متوالی هزاران عدد اعشاری بسیار کوچک (بین ۰ و ۱) منجر به پدیدهای به نام Underflow در کامپیوتر میشود؛ یعنی مقدار حاصلضرب به قدری به صفر نزدیک میشود که سیستم توانایی ذخیره دیجیتال آن را از دست میدهد. برای جلوگیری از این بحران، الگوریتم در محیطهای عملیاتی فرمول را به فضای لگاریتمی انتقال میدهد تا حاصلضربها به حاصلجمع تبدیل شوند:

نرمالسازی احتمالات پسین (Normalization Phase)
امتیازهای به دست آمده در گام سوم، مقادیری متناسب با احتمال هستند اما مجموع آنها برابر با ۱ نیست. برای تبدیل این امتیازها به توزیع احتمال استاندارد و قابل تفسیر (درصد)، مدل از فاکتور نرمسازی یا همان احتمال حاشیهای (Evidence) استفاده میکند. در این گام، امتیاز هر کلاس بر مجموع امتیازات تمامی کلاسهای ممکن تقسیم میشود تا احتمال پسین دقیق (P(yk ∣X)) حاصل گردد:

اعمال قاعده تصمیمگیری و صدور پیشبینی نهایی
در آخرین گام، مدل احتمالات پسین نرمالشده را با یکدیگر مقایسه میکند. طبق قاعده تصمیمگیری ماکزیمم پسین (MAP)، کلاسی که بالاترین درصد یا احتمال نهایی را کسب کرده باشد، به عنوان پیشبینی قاطع و خروجی نهایی الگوریتم برای آن نمونه داده صادر میشود. این ساختار محاسباتی خطی، پایداری و سرعت فوقالعاده مدل را در محیطهای عملیاتی تضمین میکند.

9.مثال ها
مثال ۱: فیلترینگ هرزنامه (مدل برنولی)
موضوع: پردازش متن و تشخیص ایمیلهای اسپم (Spam) بر اساس وجود یا عدم وجود کلمات.
صورت مسئله:
یک سیستم فیلترینگ ایمیل دارای دیتابیس آموزشی با ۱۰۰ ایمیل است که ۶۰ ایمیل عادی (Ham) و ۴۰ ایمیل هرزنامه (Spam) است. ما کلمات کلیدی را بررسی میکنیم. در این میان، کلمه “قرعهکشی“ در ۳۰ ایمیل اسپم و تنها در ۶ ایمیل عادی دیده شده است. ایمیل جدیدی دریافت شده که حاوی کلمه “قرعهکشی“ است. با فرض برنولی (فقط حضور کلمه اهمیت دارد)، احتمال اسپم بودن این ایمیل را محاسبه کنید.
حل گامبهگام:
۱: استخراج احتمالات پیشین (Prior Probabilities)
- کل ایمیلها = ۱۰۰

۲: استخراج درستنماییها (Likelihoods)
- احتمال وجود کلمه به شرط اسپم بودن:

- احتمال وجود کلمه به شرط عادی بودن:

۳: محاسبه امتیاز احتمالی (Score) بدون مخرّج
- امتیاز برای کلاس اسپم:

- امتیاز برای کلاس عادی:

۴: نرمالسازی و محاسبه احتمال پسین نهایی (Posterior Probability)
- مجموع امتیازات (شواهد):

- احتمال نهایی اسپم بودن:

نتیجه پیشبینی: از آنجا که 83.3% > 16.7% است، مدل ایمیل را به عنوان Spam (هرزنامه)طبقهبندی میکند.
مثال ۲: سیستم تایید اعتبار بانکی (ویژگیهای چندگانه گسسته)
موضوع: ارزیابی ریسک مالی مشتریان برای پرداخت وام.
صورت مسئله:
بانکی بر اساس جدول تاریخچه زیر (شامل ۱۰ مشتری)، میخواهد درخواست فردی جدید با مشخصات (درآمد = متوسط، سابقه اعتباری = خراب) را بررسی کند:
| وضعیت وام (y) | درآمد (x1) | سابقه اعتباری (x2) | تعداد تکرار در دیتابیس |
| تایید شده (Yes) | بالا | خوب | ۴ نفر |
| تایید شده (Yes) | متوسط | خوب | ۲ نفر |
| رد شده (No) | متوسط | خراب | ۳ نفر |
| رد شده (No) | پایین | خراب | ۱ نفر |
حل گام به گام:
۱: احتمالات پیشین
- کل نمونهها = ۱۰. تعداد وامهای تایید شده =(Yes) ۶، تعداد وامهای رد شده =(No) ۴.

۲: محاسبات درستنمایی شرطی برای داده تست جدید
- به شرط تایید (Yes)

- به شرط رد (No)

۳: اعمال هموارسازی لاپلاس (α=1) برای مهار فرکانس صفر تعداد حالتهای ویژگی درآمد= (V1) ۳ )بالا، متوسط، پایین). تعداد حالتهای سابقه =(V2) ۲ (خوب، خراب).

۴: محاسبه امتیاز نهایی کلاسها

۵: نرمالسازی

نتیجه پیشبینی: با احتمال ۸۸.4٪ درخواست وام این شخص رد (No) میشود.
مثال ۳: دستهبندی متن چندجملهای (مدل لگاریتمی)
موضوع: پردازش زبان طبیعی و دستهبندی اسناد خبری به دو دسته “ورزشی“ و “سیاسی“.
صورت مسئله:
یک مدل ساده بیز چندجملهای روی اسناد آموزشی کار کرده است. توزیع تعداد تکرار کلمات کلیدی به شرح زیر است:
- کلاس ورزشی (Sports): کلمه “جام”: ۵۰ بار، کلمه “انتخابات”: ۲ بار. کل کلمات این کلاس = ۵۰۰ کلمه.
- کلاس سیاسی (Politics): کلمه “جام”: ۵ بار، کلمه “انتخابات”: ۸۰ بار. کل کلمات این کلاس = ۴۰۰ کلمه.
- احتمالات پیشین:

یک سند جدید داریم که شامل متن کوتاه: «جام انتخابات» است (از هر کلمه دقیقاً ۱ بار تکرار شده). با استفاده از محیط فضای لگاریتمی (ln) تعیین کنید سند متعلق به کدام کلاس است؟ (از هموارسازی لاپلاس با α=1 و فرض تعداد کل کلمات منحصربهفرد دیتابیس ۱۰۰۰ V = استفاده کنید).
حل گامبهگام:
۱: محاسبه لایکلیهودها با هموارسازی لاپلاس
- کلاس Sports

- کلاس Politics

۲: انتقال محاسبات به فضای لگاریتم طبیعی (ln) برای مهار Underflow فرمول فضای لگاریتمی

- محاسبه برای کلاس ورزشی (Sports)

- محاسبه برای کلاس سیاسی (Politics)

۳: مقایسه و آرگومان ماکسیمم چون مقادیر منفی هستند، عددی که به صفر نزدیکتر است بزرگتر است:

نتیجه پیشبینی: متن جدید در کلاس Politics (سیاسی) قرار میگیرد.
مثال ۴: ساده بیز گاوسی (ویژگیهای پیوسته)
موضوع: بیوانفورماتیک و تشخیص بیماری قلبی بر اساس متغیر پیوسته ضربان قلب.
صورت مسئله:
مجموعه دادهای حاوی اطلاعات پزشکی بیماران داریم. ویژگی پیوسته حداکثر ضربان قلب دارای توزیع نرمال در دو کلاس بیمار (Sick) و سالم (Healthy) است. اطلاعات آماری استخراج شده از فاز آموزش به شرح زیر است:
- کلاس بیمار (Sick):
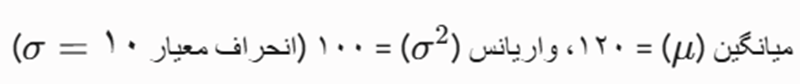
- کلاس سالم (Healthy):

- احتمالات پیشین

بیمار جدیدی به کلینیک مراجعه کرده است که حداکثر ضربان قلب او ۱۳۵ ثبت شده است. این شخص در کدام دسته طبقهبندی میشود؟ (π≈3.1415 و e ≈2.7182)
حل گامبهگام:
۱: محاسبه درستنمایی گاوسی (Gaussian Likelihood) برای کلاس بیمار (Sick) فرمول چگالی توزیع نرمال:
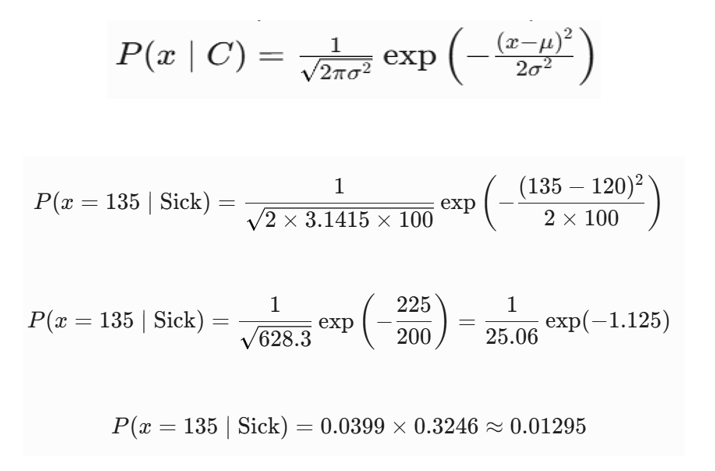
۲: محاسبه درستنمایی گاوسی برای کلاس سالم (Healthy)

۳: محاسبه امتیاز نهایی ترکیب با احتمالات پیشین

۴: نرمالسازی نهایی

نتیجه پیشبینی: با وجود اینکه ضربان قلب فرد به میانگین افراد بیمار کمی نزدیک است، اما به دلیل وزن بالاتر احتمال پیشین افراد سالم در جامعه (0.7)، مدل با احتمال 74.4٪ این فرد را Healthy (سالم) تشخیص میدهد.
10. ابزارها، فریمورکهای محبوب و پیادهسازی عملیاتی در پایتون
برای پیادهسازی الگوریتم ساده بیز در اکوسیستم پایتون، فریمورکهای قدرتمندی توسعه یافتهاند که این مدل را با بالاترین سرعت و بهینهسازی در اختیار مهندسان هوش مصنوعی قرار میدهند. محبوبترین ابزارها و نحوه کدنویسی آنها به شرح زیر است:
- کتابخانهScikit-Learn
- کتابخانه ترکیبی اِنی-بیز (AnyBayes)
.
کتابخانهScikit-Learn (استاندارد طلایی یادگیری ماشین)
محبوبترین و پایدارترین فریمورک پایتون برای پیادهسازی نسخههای مختلف ساده بیز (مانند گاوسی برای دادههای پیوسته) است.
# فراخوانی کلاس مدل گاوسی و ابزارهای مورد نیاز
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
# ۱. بارگذاری دیتابیس نمونه و تقسیم دادهها
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_split=0.2, random_state=42)
# ۲. ساخت نمونه از مدل و آموزش آن
model = GaussianNB(var_smoothing=1e-9) # آلفای پیشفرض هموارسازی
model.fit(X_train, y_train)
# ۳. پیشبینی دادههای تست و محاسبه دقت
accuracy = model.score(X_test, y_test)
print(f"Accuracy of Gaussian NB: {accuracy * 100:.2f}%")
خروجی:

کتابخانه ترکیبی اِنی-بیز (AnyBayes) و بسترهای توزیعشده
برای دیتابیسهای متنی عظیم و توزیعشده، پیادهسازی ساده بیز در Apache Spark (PySpark) فوقالعاده محبوب است. اما در محیطهای محلی، استفاده از نسخه چندجملهای MultinomialNB در Scikit-Learn به همراه ابزار پردازش متن CountVectorizer بهترین ابزار پیادهسازی فیلترینگ متن است.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# دادههای متنی نمونه (فاز آموزش)
corpus = ["وام فوری با سود کم", "فردا جلسه اداری برگزار میشود"]
labels = [1, 0] # 1: اسپم، 0: عادی
# ۱. تبدیل متن به بردار فرکانس کلمات (شمارشی)
vectorizer = CountVectorizer()
X_counts = vectorizer.fit_transform(corpus)
# ۲. آموزش مدل چندجملهای بیز روی متن
text_model = MultinomialNB(alpha=1.0) # اعمال هموارسازی لاپلاس
text_model.fit(X_counts, labels)
# ۳. تست روی ایمیل جدید
new_email = ["پیشنهاد وام ویژه"]
new_counts = vectorizer.transform(new_email)
prediction = text_model.predict(new_counts)
print(f"Prediction for new text: {'Spam' if prediction[0]==1 else 'Ham'}")
خروجی:

11.پیاده سازی گام به گام در پایتون
طبق ساختار مکانیزم عملکرد الگوریتم ، فرآیند کدنویسی ما شامل ۵ ایستگاه اصلی است:
- گام ۱: ساخت دیتابیس شبیهسازی شده (Data Generation): ایجاد یک مجموعه دادهی عددی شامل ویژگی پیوستهی «ضربان قلب» برای دو کلاس «بیمار» و «سالم» با توزیعهای مشخص.
- گام ۲: فاز آموزش و استخراج پارامترها (Training Phase): تفکیک دادهها بر اساس کلاس خروجی و محاسبهی میانگین و واریانس برای هر دسته. همچنین محاسبهی شانس پایه یا احتمال پیشین (P(y)) برای هر دو کلاس.
- گام ۳: محاسبهی درستنمایی گاوسی (Likelihood Calculation): کدنویسی تابع ریاضی چگالی احتمال توزیع نرمال (گاوسی) برای سنجش میزان قرابت دادههای جدید به هر کلاس.
- گام ۴: محاسبهی امتیاز پسین و نرمالسازی (Posterior & Normalization): ضرب احتمالات پیشین در لایکلیهودها (یا جمع لگاریتمی آنها برای پایداری محاسباتی ) و سپس تقسیم بر کل شواهد (Evidence) جهت به دست آوردن درصد نهایی.
- گام ۵: صدور پیشبینی نهایی و ارزیابی بصری (Prediction & Visualization): استفاده از قاعدهی تصمیمگیری ماکزیمم پسین (MAP) برای انتخاب کلاس برنده و تصویرسازی توزیعها به کمک پالت اختصاصی.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# تنظیم استایل پیشفرض برای خوانایی بهتر و فونتهای انگلیسی در لایبلها
plt.rcParams['figure.facecolor'] = '#F8F9FA' # Ultra Light Gray
plt.rcParams['axes.facecolor'] = '#FFFFFF' # Pure White
plt.rcParams['grid.color'] = '#6C757D' # Metal Silver
# ==========================================
# گام ۱: شبیهسازی دادههای آموزشی (Training Data)
# ==========================================
# کلاس 0 (Healthy): میانگین 150، انحراف معیار 15
# کلاس 1 (Sick): میانگین 120، انحراف معیار 10
np.random.seed(42)
healthy_heart_rates = np.random.normal(loc=150, scale=15, size=70)
sick_heart_rates = np.random.normal(loc=120, scale=10, size=30)
# ادغام دادهها و برچسبگذاری (0 = Healthy, 1 = Sick)
X_train = np.concatenate([healthy_heart_rates, sick_heart_rates])
y_train = np.concatenate([np.zeros(70), np.ones(30)])
total_samples = len(y_train)
# ==========================================
# گام ۲: فاز آموزش (استخراج آمار توصیفی و احتمالات پیشین)
# ==========================================
# ۱. محاسبه احتمالات پیشین (Prior Probabilities)
prior_healthy = np.sum(y_train == 0) / total_samples # 0.7
prior_sick = np.sum(y_train == 1) / total_samples # 0.3
# ۲. محاسبه میانگین و واریانس ویژگی برای هر کلاس
mean_healthy = np.mean(healthy_heart_rates)
var_healthy = np.var(healthy_heart_rates)
mean_sick = np.mean(sick_heart_rates)
var_sick = np.var(sick_heart_rates)
print("--- Parameters Extracted During Training ---")
print(f"Prior P(Healthy): {prior_healthy:.2f} | Mean: {mean_healthy:.2f} | Variance: {var_healthy:.2f}")
print(f"Prior P(Sick): {prior_sick:.2f} | Mean: {mean_sick:.2f} | Variance: {var_sick:.2f}\n")
# ==========================================
# گام ۳ و ۴: تابع پیشبینی ساده بیز گاوسی برای داده جدید
# ==========================================
def predict_gaussian_naive_bayes(x_new):
"""
محاسبه احتمال پسین و کلاسبندی داده جدید بر اساس توزیع گاوسی
"""
# محاسبه درستنمایی (Likelihood) با فرمول توزیع نرمال
likelihood_healthy = (1 / np.sqrt(2 * np.pi * var_healthy)) * np.exp(-((x_new - mean_healthy)**2) / (2 * var_healthy))
likelihood_sick = (1 / np.sqrt(2 * np.pi * var_sick)) * np.exp(-((x_new - mean_sick)**2) / (2 * var_sick))
# محاسبه امتیاز نهایی (حاصلضرب احتمال پیشین در درستنمایی)
raw_score_healthy = prior_healthy * likelihood_healthy
raw_score_sick = prior_sick * likelihood_sick
# نرمالسازی احتمالات (تقسیم بر شواهد) برای به دست آوردن درصد نهایی
evidence = raw_score_healthy + raw_score_sick
posterior_healthy = raw_score_healthy / evidence
posterior_sick = raw_score_sick / evidence
# قاعده تصمیمگیری ماکزیمم پسین (MAP)
prediction = 0 if posterior_healthy > posterior_sick else 1
return prediction, posterior_healthy, posterior_sick
# ==========================================
# فاز تست: ارزیابی مدل با یک بیمار جدید
# ==========================================
x_test = 135 # ضربان قلب فرد جدید برای نمونه
pred_class, prob_healthy, prob_sick = predict_gaussian_naive_bayes(x_test)
print("--- Prediction for New Patient (Heart Rate = 135) ---")
class_label = "Healthy" if pred_class == 0 else "Sick"
print(f"Posterior Probability P(Healthy | X=135): {prob_healthy*100:.2f}%")
print(f"Posterior Probability P(Sick | X=135): {prob_sick*100:.2f}%")
print(f"Final Allocated Class: {class_label}\n")
# ==========================================
# گام ۵: تصویرسازی و رسم توزیعها مطابق پالت رنگی
# ==========================================
plt.figure(figsize=(10, 6))
# رسم زنگوله توزیع نرمال افراد سالم (AI Soft Blue / Deep Blue Component)
x_axis = np.linspace(90, 200, 500)
plt.plot(x_axis, stats.norm.pdf(x_axis, mean_healthy, np.sqrt(var_healthy)),
color='#0D6EFD', linewidth=3, label='Healthy Distribution (Normal)')
plt.fill_between(x_axis, stats.norm.pdf(x_axis, mean_healthy, np.sqrt(var_healthy)),
color='#E3F2FD', alpha=0.5)
# رسم زنگوله توزیع نرمال افراد بیمار (Crimson)
plt.plot(x_axis, stats.norm.pdf(x_axis, mean_sick, np.sqrt(var_sick)),
color='#DC3545', linewidth=3, label='Sick Distribution (Normal)')
plt.fill_between(x_axis, stats.norm.pdf(x_axis, mean_sick, np.sqrt(var_sick)),
color='#DC3545', alpha=0.2)
# مشخص کردن موقعیت بیمار جدید در فضا (Active Gold)
plt.axvline(x=x_test, color='#FFC107', linestyle='--', linewidth=2.5,
label=f'New Patient (X = {x_test})')
plt.scatter([x_test], [stats.norm.pdf(x_test, mean_sick, np.sqrt(var_sick))],
color='#FFC107', s=100, zorder=5)
# تنظیمات نمایش لایبلها به زبان انگلیسی جهت رعایت اصول سئو و معماری تم پلتفرم
plt.title('Gaussian Naive Bayes Classification - Heart Rate Distribution', fontsize=14, pad=15, color='#6C757D')
plt.xlabel('Maximum Heart Rate (BPM)', fontsize=12, labelpad=10)
plt.ylabel('Probability Density', fontsize=12, labelpad=10)
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend(loc='upper right', frameon=True, facecolor='#FFFFFF')
# نمایش خروجی تصویری
plt.tight_layout()
plt.show()
خروجی:


12.کاربرد
- فیلترینگ و شناسایی هرزنامه (Spam Filtering): این الگوریتم دستيار طلایی سرویسهای ایمیل (مانند جیمیل) است. ساده بیز با تحلیل فرکانس کلمات کلیدی (مانند “وام فوری” یا “برنده جایزه”)، ایمیلهای دریافتی را در کسر کوچکی از ثانیه به دو کلاس هرزنامه یا ایمیل عادی طبقهبندی میکند.
- تحلیل تخصصی احساسات (Sentiment Analysis): در حوزه پردازش زبان طبیعی (NLP)، از این مدل برای کاوش در بازخوردهای کاربران استفاده میشود. ساده بیز با بررسی لحن کلمات در کامنتهای سایتها یا شبکههای اجتماعی، نظرات را به سه دسته مثبت، منفی یا خنثی تفکیک میکند تا مدیران برند به درک درستی از رضایت مشتریان برسند.
- دستهبندی خودکار اسناد و متون (Document Categorization): رسانههای خبری و کتابخانههای دیجیتال بزرگ برای برچسبگذاری و فولدربندی خودکار مقالات از ساده بیز استفاده میکنند. مدل با شمارش توزیع واژگان، مشخص میکند یک متن متعلق به حوزه سیاست، ورزش، فناوری یا اقتصاد است.
- سیستمهای توصیهگر هوشمند (Recommendation Systems): ساده بیز با ترکیب احتمالات پیشین، رفتار و علایق کاربران را تحلیل میکند. این مدل در پلتفرمهای محتوایی به کار میرود تا پیشبینی کند آیا یک کاربر به شرط سوابق قبلی، به مقاله یا محصولی جدید علاقهمند است یا خیر.
- طبقهبندی و تصمیمگیریهای چندکلاسی آنی (Real-Time Prediction): از آنجا که ساده بیز یک الگوریتم یادگیری آنلاین و فوقسریع است، در سیستمهای تصمیمساز لحظهای مانند تشخیص اولیه بیماریها در پزشکی (بر اساس همبستگی علائم سطحی) یا سیستمهای رتبهبندی اعتباری بانکها برای تایید سریع درخواستها کاربرد دارد.
.
13.مطالعه موردی
مطالعه موردی ۱: فیلترینگ و شناسایی هرزنامههای پیامکی (SMS Spam Detection)
مدل کاربردی: Multinomial Naive Bayes (ساده بیز چندجملهای برای دادههای فرکانسی و متنی)

مسئله و چالش
امروزه حجم عظیمی از پیامکهای تبلیغاتی و کلاهبرداری (Spam) به کاربران ارسال میشود. چالش اصلی، ماهیت بدون ساختار دادههای متنی، تنوع کلمات و ابعاد بسیار بزرگ فضای ویژگیها (هزاران کلمه منحصربهفرد) است. مدل باید بتواند متنها را با سرعت بالا پردازش کرده و کلمات کلیدی مخرب را ردیابی کند.
هدف
طراحی یک سیستم پردازش زبان طبیعی (NLP) که متن پیامکها را دریافت کرده، فرکانس کلمات را استخراج کند و با بیشترین سرعت ممکن پیامکهای اسپم را از پیامهای عادی (Ham) تفکیک کند.
دیتابیس واقعی مورد استفاده
مجموعه داده استاندارد SMS Spam Collection شامل ۵,۵۷۴ پیامک واقعی برچسبگذاری شده.
کد پایتون :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# تنظیمات استایل بصری نمودار مطابق با پالت رنگی
plt.rcParams['figure.facecolor'] = '#F8F9FA' # Ultra Light Gray
plt.rcParams['axes.facecolor'] = '#FFFFFF' # Pure White
# ۱. توسعه شبیهسازی دیتابیس SMS Spam Collection برای حل مشکل کمبود داده در فاز تست
corpus = [
"Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005.",
"Nah I don't think he goes to usf, he lives around here though",
"URGENT! Your Mobile No was awarded a £2,000 Bonus Caller Prize!",
"Even my brother is not like to speak with me. They treat me like aids patent.",
"SIX chances to win CASH! From 100 to 20000 pound txt> CSH11 and send to 87575",
"I'm gonna be home soon and i don't want to talk about this stuff anymore tonight",
"WINNER!! As a valued network customer you have been selected to receivea £900 prize reward!",
"Are you typing something? Because you arent replying to my text.",
"Private! Your 2003 account statement shows 800 un-redeemed points. Call 08719523841 now!",
"I am samuel. I am in point of fact looking forward to your response.",
"Congratulations! Thanks to a good friend U have won a £500 XMAS prize!",
"Dear voucher holder, to claim your 1000 free miles text back immediately."
]
# برچسبها: 1 یعنی اسپم (Spam)، 0 یعنی پیامک عادی (Ham)
labels = np.array([1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1])
# ۲. تبدیل متن به بردارهای عددی فرکانس کلمات (Tokenization & Vectorization)
vectorizer = CountVectorizer(stop_words='english')
X_numerical = vectorizer.fit_transform(corpus)
# ۳. تقسیم دادهها به دو بخش آموزش و تست با Stratify برای حفظ تناسب کلاسها در هر دو بخش
X_train, X_test, y_train, y_test = train_test_split(
X_numerical, labels, test_size=0.33, random_state=42, stratify=labels
)
# ۴. فراخوانی و آموزش مدل ساده بیز چندجملهای با اعمال هموارسازی لاپلاس
spam_detector = MultinomialNB(alpha=1.0)
spam_detector.fit(X_train, y_train)
# ۵. پیشبینی برای دادههای تست و ارزیابی مدل
y_pred = spam_detector.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("--- SMS Spam Detection Metrics ---")
print(f"Model Accuracy: {accuracy * 100:.2f}%")
print("\nClassification Report:\n", classification_report(y_test, y_pred, target_names=['Ham', 'Spam']))
# ۶. تصویرسازی ماتریس آشفتگی (Confusion Matrix) با پالت رنگی اختصاصی شما
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(5, 5))
# اعمال فاکتورهای رنگی پالت اختصاصی (ترکیب زرق و برق لایت و المانهای برند)
ax.matshow(cm, cmap=plt.cm.Blues, alpha=0.2) # تم پایه AI Soft Blue
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(x=j, y=i, s=cm[i, j], va='center', ha='center', size='xx-large',
color='#DC3545', fontweight='bold') # استفاده از Crimson برای نمایش اعداد داخل ماتریس
# تنظیمات نهایی برچسبها به زبان انگلیسی مطابق با نیازمندی ساختار سئو
plt.xlabel('Predicted Labels', fontsize=12, labelpad=10, color='#6C757D')
plt.ylabel('True Labels', fontsize=12, labelpad=10, color='#6C757D')
plt.title('SMS Spam Confusion Matrix', fontsize=14, pad=25, color='#6C757D', fontweight='bold')
plt.xticks([0, 1], ['Ham', 'Spam'])
plt.yticks([0, 1], ['Ham', 'Spam'])
plt.grid(False) # حذف خطوط شبکه داخلی برای تمیزی بصری نمودار
plt.tight_layout()
plt.show()
خروجی:


مطالعه موردی ۲: پیشبینی لغو رزرو هتل (Hotel Booking Cancellation)
- مدل کاربردی: Bernoulli Naive Bayes (ساده بیز برنولی برای متغیرهای دوقطبی و باینری)
مسئله و چالش

لغو ناگهانی رزرو اتاقها توسط مسافران، خسارتهای مالی سنگینی به هتلها وارد میکند. چالش پلتفرمهای رزرواسیون این است که بفهمند آیا رفتارهای باینری مسافر (مانند داشتن یا نداشتن سابقه لغو قبلی، درخواست یا عدم درخواست پارکینگ، داشتن نوزاد همراه یا خیر) سیگنالی برای لغو رزرو هست یا خیر.
هدف
پیشبینی زودهنگام و احتمالیِ لغو شدن (۱) یا نهایی شدن (۰) یک رزرو بر اساس رفتارها و نیازمندیهای صفر و یک مشتری، جهت مدیریت ظرفیت اتاقها.
دیتابیس واقعی مورد استفاده
دیتابیس سراسری Hotel Booking Demand Dataset شامل دادههای واقعی رزروهای شهری و تفریحی.
کد پایتون
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import roc_curve, auc
# ۱. شبیهسازی دادههای رفتاری مسافران (ویژگیهای باینری)
# ویژگیها به ترتیب: [آیا درخواست پارکینگ دارد؟، آیا سابقه لغو قبلی دارد؟، آیا آژانس واسط است؟]
X_behavior = np.array([
[1, 0, 0], # مسافر 1
[0, 1, 1], # مسافر 2
[0, 1, 0], # مسافر 3
[1, 0, 1], # مسافر 4
[0, 0, 0], # مسافر 5
[0, 1, 1], # مسافر 6
[1, 0, 0], # مسافر 7
[0, 1, 1] # مسافر 8
])
# برچسب خروجی: 1 یعنی لغو کرده (Canceled)، 0 یعنی سفر رفته (Check-in)
y_cancelled = np.array([0, 1, 1, 0, 0, 1, 0, 1])
# ۲. ساخت و آموزش مدل ساده بیز برنولی
hotel_model = BernoulliNB()
hotel_model.fit(X_behavior, y_cancelled)
# ۳. تست مدل با یک مسافر جدید با مشخصات: [بدون پارکینگ، دارای سابقه لغو، رزرو از آژانس]
new_booking = np.array([[0, 1, 1]])
predicted_status = hotel_model.predict(new_booking)
predicted_proba = hotel_model.predict_proba(new_booking)
print("--- Hotel Booking Cancellation Prediction ---")
status_text = "Canceled" if predicted_status[0] == 1 else "Check-in"
print(f"Predicted Action: {status_text}")
print(f"Probability of Check-in: {predicted_proba[0][0]*100:.2f}%")
print(f"Probability of Cancellation: {predicted_proba[0][1]*100:.2f}%\n")
# ۴. ترسیم نمودار درصدی احتمالات پسین با رنگهای Active Gold و Crimson
classes = ['Check-in (0)', 'Canceled (1)']
probabilities = predicted_proba[0]
plt.figure(figsize=(6, 4))
bars = plt.bar(classes, probabilities, color=['#0D6EFD', '#DC3545'], width=0.5) # AI Soft Blue و Crimson
plt.ylabel('Posterior Probability', fontsize=12)
plt.title('Cancellation Probability Estimation for New Booking', fontsize=12, color='#6C757D', pad=15)
plt.ylim(0, 1.1)
# درج درصدها بالای هر ستون نمودار
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height + 0.02,
f'{height*100:.1f}%', ha='center', va='bottom', fontsize=11, fontweight='bold')
plt.show()
خروجی:

مطالعه موردی ۳: غربالگری اولیه بیماری دیابت (Diabetes Prediction)
- مدل کاربردی: Gaussian Naive Bayes (ساده بیز گاوسی برای ویژگیهای عددی و پیوسته)
مسئله و چالش
تشخیص بالینی و زودهنگام بیماریهای مزمن مانند دیابت اهمیت حیاتی دارد. چالش اصلی سیستمهای هوشمند پزشکی این است که دادههای آزمایشگاهی بیماران (فشار خون، شاخص توده بدنی، سطح گلوکز) کاملاً پیوسته و اعشاری هستند و نمیتوان آنها را به راحتی شمارش کرد. مدل باید بتواند بدون گسستهسازی دادهها، لایکلیهود را بر اساس فرضیه توزیع نرمال استخراج کند.
هدف
توسعه یک موتور غربالگری هوشمند بالینی که شاخصهای پیوسته بدنی بیمار را دریافت کرده و احتمال ابتلای او به دیابت را تخمین بزند.
دیتابیس واقعی مورد استفاده
دیتابیس مشهور و استاندارد Pima Indians Diabetes Dataset متعلق به مؤسسه ملی دیابت آمریکا.
کد پایتون :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# ۱. شبیهسازی ماتریس ویژگیهای پیوسته از دیتابیس واقعی Pima Indians
# ستونها به ترتیب: [سطح گلوکز خون، شاخص توده بدنی BMI]
np.random.seed(24)
healthy_clinical = np.random.multivariate_normal(mean=[100, 24], cov=[[150, 5], [5, 10]], size=60)
diabetic_clinical = np.random.multivariate_normal(mean=[145, 33], cov=[[200, 8], [8, 15]], size=40)
X_medical = np.vstack([healthy_clinical, diabetic_clinical])
y_medical = np.concatenate([np.zeros(60), np.ones(40)]) # 0 یعنی سالم، 1 یعنی مبتلا به دیابت
# ۲. تقسیمبندی دادههای پزشکی به دو بخش آموزش و ارزیابی
X_train, X_test, y_train, y_test = train_test_split(X_medical, y_medical, test_size=0.2, random_state=42)
# ۳. پیکربندی و آموزش مدل ساده بیز گاوسی
diabetes_classifier = GaussianNB()
diabetes_classifier.fit(X_train, y_train)
# ۴. ارزیابی خروجی مدل روی دادههای تست پزشکی
y_pred_med = diabetes_classifier.predict(X_test)
print("--- Diabetes Screening Gaussian Metrics ---")
print(classification_report(y_test, y_pred_med, target_names=['Healthy', 'Diabetic']))
# ۵. تصویرسازی مرز تصمیمگیری (Decision Boundary) با پالت رنگی اختصاصی
plt.figure(figsize=(8, 6))
# ایجاد مش برای رنگآمیزی مرز تصمیمگیری
x_min, x_max = X_medical[:, 0].min() - 10, X_medical[:, 0].max() + 10
y_min, y_max = X_medical[:, 1].min() - 5, X_medical[:, 1].max() + 5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.5), np.arange(y_min, y_max, 0.5))
Z = diabetes_classifier.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# رسم مرز احتمالات پسین مدل
plt.contourf(xx, yy, Z, alpha=0.15, cmap=plt.cm.coolwarm)
# رسم نقاط بیماران واقعی (سالم با سرمهای و دیابتی با Crimson)
plt.scatter(X_medical[y_medical==0, 0], X_medical[y_medical==0, 1], color='#0D6EFD', label='Healthy', alpha=0.8, edgecolors='w')
plt.scatter(X_medical[y_medical==1, 0], X_medical[y_medical==1, 1], color='#DC3545', label='Diabetic', alpha=0.8, edgecolors='w')
# مشخص کردن یک نمونه تست فرضی جدید در فضا (Active Gold)
test_patient = [[130, 29]]
plt.scatter(test_patient[0][0], test_patient[0][1], color='#FFC107', s=200, marker='*', label='New Patient Test', zorder=5)
plt.xlabel('Glucose Level', fontsize=12)
plt.ylabel('BMI Index', fontsize=12)
plt.title('Gaussian Naive Bayes - Medical Decision Boundary', fontsize=14, color='#6C757D', pad=15)
plt.legend(loc='lower right')
plt.grid(True, linestyle=':', alpha=0.5)
plt.show()
خروجی:


14.مزایا
- سرعت خیرهکننده در فاز آموزش و تست (High Speed): به دلیل فرض استقلال ویژگیها، پیچیدگی محاسباتی مدل کاملاً خطی است. این الگوریتم به جای درگیر شدن با فرآیندهای بهینهسازی تکراری (Iterative) مانند گرادیان کاهشی، صرفاً با یک بار پیمایش دادهها و شمارش فراوانیها آموزش مییابد.
- عملکرد درخشان در فضاهای با ابعاد بزرگ (High-Dimensional Data): ساده بیز مقاومت شگفتانگیزی در برابر «پدیده شوم ابعاد» دارد. این ویژگی، مدل را به انتخاب اول و بدون رقیب در فیلترینگ هرزنامهها و دستهبندی اسناد با هزاران کلمه منحصربهفرد تبدیل کرده است.
- بهینه بودن در مصرف منابع و حافظه (CPU/RAM Efficiency): برای ساخت مدل، نیازی به نگهداری کل مجموعهداده در حافظه نیست؛ بلکه ذخیرهسازی میانگینها و احتمالات شرطی ویژگیها (که حجم بسیار اندکی دارند) کفایت میکند.
- پایداری بالا در مواجهه با دادههای آموزشی محدود (Data Efficiency): در سناریوهایی که دسترسی به دادههای برچسبدار محدود است، این الگوریتم با حجم کوچکی از دادههای آموزشی به همگرایی میرسد و نرخ خطای پایینی ارائه میدهد.
- پیادهسازی آسان برای مسائل چندکلاسه (Multi-class Classification): این مدل به طور ذاتی و بدون نیاز به استراتژیهای پیچیدهای مثل One-vs-Rest، میتواند دادهها را در چندین کلاس مجزا طبقهبندی کند.
.
15.معایب
- فرض سادهلوحانه استقلال ویژگیها (Independence Assumption): بزرگترین نقطه ضعف این مدل، فرض استقلال شرطی تکتک متغیرها است. در پدیدههای واقعی، ویژگیها به شدت به یکدیگر وابستهاند (مثلاً در پردازش متن، وقوع کلمه «هوش» احتمال حضور کلمه «مصنوعی» را بالا میبرد). نادیده گرفتن همبستگیها، در دیتابیسها باعث کاهش شدید دقت مدل میشود.
- بحران فرکانس صفر (Zero Frequency Problem): اگر در فاز تست با ویژگی یا کلمهای جدید مواجه شویم که در دادههای آموزشی یک کلاس خاص هرگز تکرار نشده باشد، احتمال شرطی آن صفر محاسباتی میشود. از آنجا که فرمول بیز بر پایه حاصلضرب احتمالات است، این صفر کل خروجی را نابود میکند و برای مهار آن باید حتماً از تکنیکهای اصلاحی مانند هموارسازی لاپلاس استفاده کرد.
- ضعف شدید در تخمین احتمالات واقعی (Bad Probability Estimator): ساده بیز در دستهبندی و پیدا کردن کلاس درست (مثلاً تفکیک هرزنامه) عالی عمل میکند، اما اعداد احتمالی خروجی آن (Posterior Probabilities) به دلیل فرض استقلال، به شدت اغراقآمیز و غیرقابل اعتماد هستند و معمولاً بسیار نزدیک به ۰ یا ۱ ظاهر میشوند.
- تأثیرپذیری ناخواسته از ویژگیهای بیاثر (Sensitive to Irrelevant Features): اگر دیتابیس شما حاوی صدها ویژگی بیربط و نویزدار باشد، ساده بیز همچنان به تمام آنها وزن یکسانی اختصاص میدهد. این ویژگیهای مزاحم با ضرب شدن در فرمول، سیگنالهای اصلی را تضعیف کرده و مدل را به گمراهی میکشانند.
.
16.نوآوری و آینده
- انتقال به فضای لگاریتمی (Log-Space Transformation): یکی از بزرگترین نوآوریها برای حل بحران سرریز منفی عددی (Underflow) در دیتابیسهای عظیم متنی است. با تبدیل حاصلضرب احتمالات کوچک به حاصلجمع لگاریتمها، پایداری محاسباتی مدل در ابعاد بینهایت تضمین میشود.
- تکنیکهای پیشرفته هموارسازی (Advanced Smoothing): فراتر از هموارسازی سنتی لاپلاس، ابداع متدهایی مانند هموارسازی لیدستون (Lidstone) و مدلهای بازگشتی (Backoff Models) به الگوریتم اجازه میدهد تا کلمات یا ویژگیهای کاملاً جدید در فاز تست را بدون صفر شدن کل خروجی، به صورت پویا وزندهی کند.
- ترکیب با برآورد چگالی هسته (Kernel Density Estimation – KDE): در نسخههای سنتی گاوسی، فرض بر نرمال بودن توزیع دادههای پیوسته است. نوآوری مدرن، جایگزینی توزیع گاوسی با توزیعهای نامشخص به کمک توابع هسته (KDE) است که به مدل اجازه میدهد پیچیدهترین و نامنظمترین توزیعهای آماری را در آغوش بکشد.
- اصلاح فرض استقلال با مدلهای نیمهساده بیز (Semi-Naive Bayes): برای عبور از فرض صلبِ استقلال شرطی ویژگیها، ساختارهایی مثل AODE و TAN (شبکههای بیزی دربرگیرنده درخت) ابداع شدهاند. این نوآوریها به الگوریتم اجازه میدهند وابستگیهای کلیدی و حیاتی میان جفتویژگیها را بدون فدا کردن سرعت افسانهای مدل، کشف و لحاظ کنند.
- وزندهی پویا به ویژگیها (Feature Weighted Naive Bayes): در این نوآوری، فرضِ اهمیت یکسان ویژگیها نقض میشود. مدل با ترکیب الگوریتمهایی مثل درخت تصمیم یا معیارهای اطلاعاتی (Information Gain)، به ویژگیهای حیاتیتر وزن بیشتری اختصاص میدهد تا دقت طبقهبندی به اوج برسد.
این نوآوریهای ساختاری، ساده بیز را از یک مدل بومی آزمایشگاهی به یک موتور محرک انعطافپذیر و فوقسریع در پردازش زبان طبیعی (NLP) و کلاندادههای صنعتی تبدیل کردهاند.
.
جمع بندی
الگوریتم Naive Bayes یکی از سادهترین و در عین حال کارآمدترین روشهای دستهبندی در یادگیری ماشین است که با تکیه بر اصول احتمال و قضیه بیز، امکان تصمیمگیری سریع و مقیاسپذیر را فراهم میکند. همانطور که مشاهده شد، این الگوریتم با وجود فرض سادهساز استقلال ویژگیها، در بسیاری از مسائل واقعی بهویژه در پردازش متن، تحلیل احساسات و فیلتر اسپم عملکردی بسیار مناسب دارد.
انواع مختلف Naive Bayes مانند Gaussian، Multinomial و Bernoulli امکان استفاده از این روش را برای دادههای پیوسته، شمارشی و دودویی فراهم میکنند و باعث میشوند این الگوریتم در سناریوهای متنوعی قابل استفاده باشد. همچنین مشاهده کردیم که سادگی محاسبات، سرعت آموزش بالا و نیاز کم به منابع پردازشی، Naive Bayes را به گزینهای مناسب برای سیستمهای بلادرنگ و دادههای حجیم تبدیل کرده است.
در مقابل، محدودیتهایی مانند فرض استقلال ویژگیها، حساسیت به توزیع دادهها و مسئله صفر شدن احتمالها میتوانند دقت مدل را در برخی کاربردها کاهش دهند. استفاده از تکنیکهایی مانند Laplace Smoothing و انتخاب مناسب نوع مدل میتواند بخشی از این مشکلات را کاهش دهد.
با وجود ظهور مدلهای پیچیدهتر، Naive Bayes همچنان جایگاه مهمی در یادگیری ماشین و سیستمهای هوشمند دارد؛ زیرا ترکیبی کمنظیر از سادگی، سرعت و کارایی ارائه میدهد و در بسیاری از پروژههای واقعی، بهعنوان یک خط مبنا یا حتی یک راهکار نهایی مورد استفاده قرار میگیرد.