

1.شبکه عصبی چیست و چگونه کار می کند؟
در اینجا چیزی وجود دارد که ممکن است شما را شگفتزده کند: شبکههای عصبی آنقدرها هم پیچیده نیستند! اصطلاح «شبکه عصبی» اغلب به عنوان یک واژه پُر زرق و برق استفاده میشود، اما در واقعیت، آنها اغلب بسیار سادهتر از آن چیزی هستند که مردم تصور میکنند.
این نوشته برای مبتدیان کامل در نظر گرفته شده است و فرض ما بر صفر بودن دانش قبلی شما در مورد یادگیری ماشین است. ما نحوه عملکرد شبکههای عصبی را در حین پیادهسازی یکی از آنها، از صفر در پایتون، درک خواهیم کرد.
2.نورونها (Neurons)و ساختار آن ها در شبکه
ابتدا، باید در مورد نورونها صحبت کنیم که واحد اساسی یک شبکه عصبی هستند. یک نورون ورودیها را میگیرد، محاسباتی را روی آنها انجام میدهد و یک خروجی تولید میکند.
این شکلی است که یک نورون ۲-ورودی به نظر میرسد:
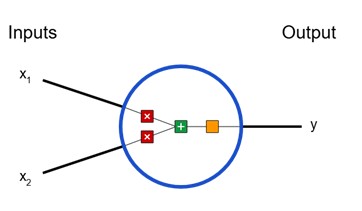
در اینجا ۳ اتفاق در حال رخ دادن است. اول، هر ورودی در یک وزن ضرب میشود:
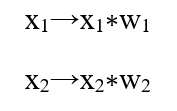
در مرحله بعد، تمام ورودیهای وزندهیشده به همراه یک بایاس b با هم جمع میشوند:
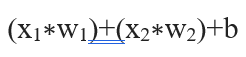
در نهایت، مجموع (Sum) از طریق یک تابع فعالسازی (Activation Function) عبور داده میشود:
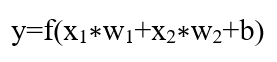
تابع فعالسازی (Activation Function) برای تبدیل یک ورودی نامحدود به خروجیای استفاده میشود که دارای شکلی مطلوب و قابل پیشبینی است. یک تابع فعالسازی رایج، تابع سیگموئید است:
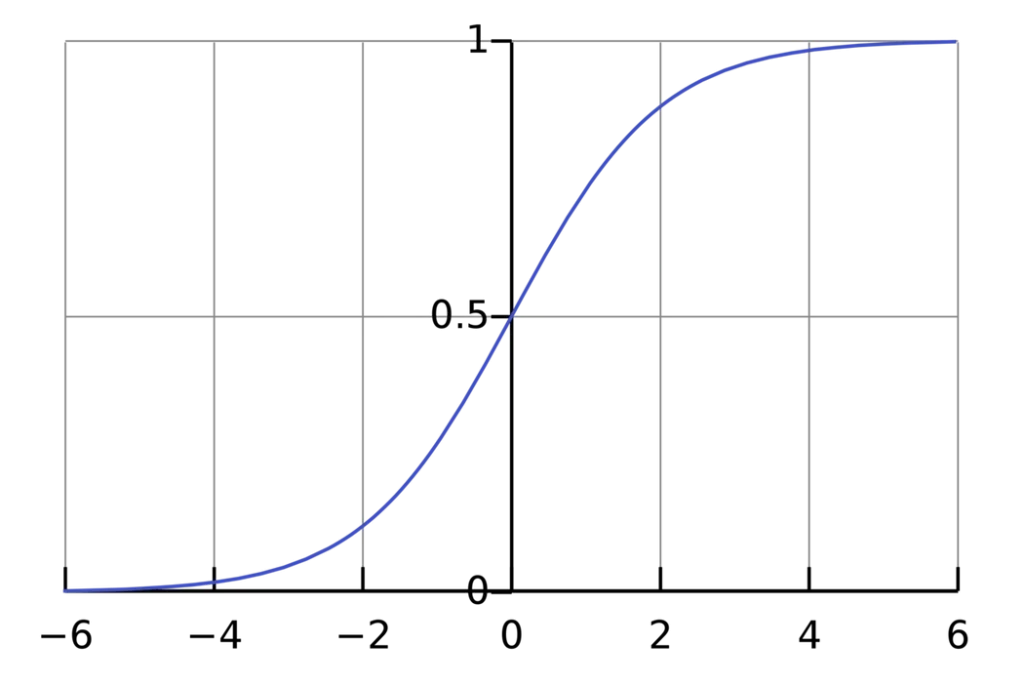
تابع سیگموئید (Sigmoid Function) تنها مقادیر را در بازه (0, 1) خروجی میدهد.
شما میتوانید آن را به عنوان فشردهسازی بازه (-∞, +∞) به (0, 1) در نظر بگیرید — اعداد منفی بزرگ تقریباً 0 و اعداد مثبت بزرگ تقریباً 1 میشوند.
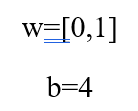
w = [0, 1] فقط روشی برای نوشتن w1 = 0, w2 = 1 به صورت برداری است. اکنون، بیایید ورودی x = [2, 3] را به نورون بدهیم. از «ضرب داخلی» (Dot Product) برای نگارش فشردهتر استفاده خواهیم کرد:
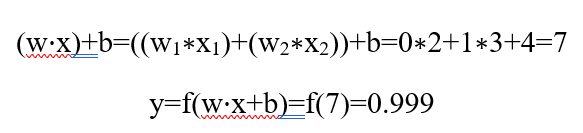
خروجی نورون برای ورودیهای x = [2, 3] برابر با 0.999 است. همین! این فرآیند ارسال ورودیها به جلو برای دریافت خروجی به عنوان «انتشار رو به جلو» (feedforward) شناخته میشود.
import numpy as np
def sigmoid(x):
# Our activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# Weight inputs, add bias, then use the activation function
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994
آن اعداد را تشخیص میدهید؟ این همان مثالی است که ما به تازگی انجام دادیم! ما همان پاسخ 0.999 را دریافت میکنیم.
3.ترکیب نورونها برای تشکیل یک شبکه کامل
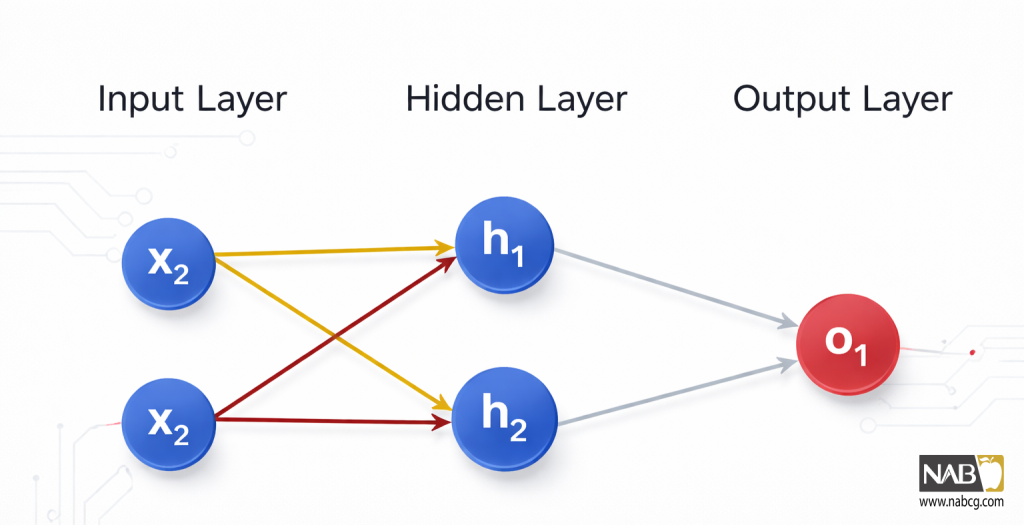
یک شبکه عصبی چیزی جز مجموعهای از نورونهای متصل به هم نیست. این چیزی است که یک شبکه عصبی ساده ممکن است به نظر برسد:
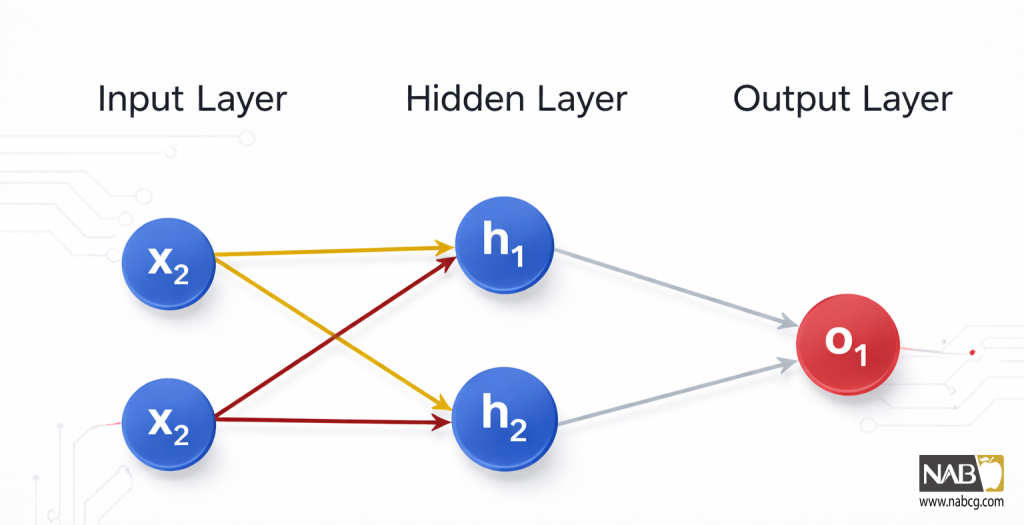
این شبکه دارای ۲ ورودی، یک لایه پنهان با ۲ نورون h1 و h2 و یک لایه خروجی با ۱ نورون o1 است. توجه داشته باشید که ورودیهای o1، خروجیهای h1 و h2 هستند — این چیزی است که این ساختار را به یک شبکه تبدیل میکند.
یک لایه پنهان (Hidden Layer) هر لایهای است که بین لایه ورودی (اولین لایه) و لایه خروجی (آخرین لایه) قرار دارد. میتواند چندین لایه پنهان وجود داشته باشد!
مثال: محاسبه گام رو به جلو (Feedforward )
برای درک نحوه عملکرد شبکههای عصبی چندلایه، این مثال عالی است. فرآیند انتشار رو به جلو (Feedforward ) شامل عبور ورودیها از طریق لایهها، محاسبه مجموع وزندار و اعمال تابع فعالسازی سیگموئید (Sigmoid) است.
چه اتفاقی میافتد اگر ورودی x: [2, 3]را وارد کنیم؟
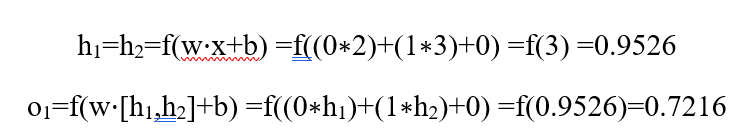
خروجی شبکه عصبی برای ورودی x = [2, 3] برابر با 0.7216 است. بسیار ساده است، اینطور نیست؟
یک شبکه عصبی میتواند «هر تعداد لایه» با «هر تعداد نورون» در آن لایهها داشته باشد. ایده اصلی ثابت میماند: ورودی(ها) را به صورت رو به جلو از طریق نورونهای شبکه هدایت کنید تا خروجی(ها) را در انتها به دست آورید. برای سادگی، ما برای ادامه این متن از شبکهای که در بالا تصویر شده است، استفاده خواهیم کرد.
کدنویسی شبکه عصبی: انتشار رو به جلو (Feedforward)
بیایید انتشار رو به جلو را برای شبکه عصبی پیادهسازی کنیم. تصویر شبکه دوباره برای ارجاع در اینجا آمده است:
import numpy as np
# ... code from previous section here
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
Each neuron has the same weights and bias:
- w = [0, 1]
- b = 0
'''
def __init__(self):
weights = np.array([0, 1])
bias = 0
# The Neuron class here is from the previous section
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# The inputs for o1 are the outputs from h1 and h2
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421
دوباره 0.7216 را به دست آوردیم! به نظر میرسد که کار میکند.
4.آموزش شبکه عصبی و کاهش خطا:
فرض کنید اندازهگیریهای زیر را داریم:
| نام (Name) | وزن (lb) | قد (in) | جنسیت (Gender) |
|---|---|---|---|
| Alice | 133 | 65 | F |
| Bob | 160 | 72 | M |
| Charlie | 152 | 70 | M |
| Diana | 120 | 60 | F |
ما جنسیت «مرد» (Male) را با 0 و جنسیت «زن» (Female) را با 1 نمایش میدهیم و همچنین دادهها را جابهجا (Shift) خواهیم کرد تا استفاده از آنها آسانتر شود:
| نام (Name) | وزن (lb) (منهای 135) | قد (in) (منهای 66) | جنسیت (Gender) |
|---|---|---|---|
| Alice | 2- | 1- | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | 15- | 6- | 1 |
مقادیر جابهجایی (shift amounts) (135 و 66) را به صورت دلخواه انتخاب کردیم تا اعداد ظاهری بهتری داشته باشند. به طور معمول، شما باید بر اساس میانگین [واقعی دادهها] جابهجا شوید.
زیان (Loss)
قبل از اینکه شبکه خود را آموزش دهیم، ابتدا به روشی نیاز داریم تا اندازهگیری کنیم که شبکه چقدر «خوب» عمل میکند، تا بتواند تلاش کند «بهتر» عمل کند. این همان چیزی است که «زیان» نامیده میشود.
ما از خطای میانگین مجذورات (Mean Squared Error – MSE) استفاده خواهیم کرد:
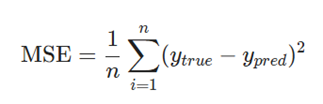
بیایید این را جزء به جزء تحلیل کنیم:
- n (تعداد نمونهها): برابر با 4 است (آلیس، باب، چارلی، دیانا).
- y (متغیر پیشبینیشونده): نشاندهنده جنسیت (Gender) است.
- ytrue (مقدار حقیقی): مقدار درست متغیر است («پاسخ صحیح»). به عنوان مثال، ytrue برای آلیس 1 (Female) خواهد بود.
- ypred (مقدار پیشبینیشده): خروجی شبکه عصبی ما است.
- ^2(ytrue – ypred) (خطای مجذور): به عنوان خطای مجذور (Squared Error) شناخته میشود.
تابع زیان (Loss Function) ما به سادگی میانگین تمام خطاهای مجذور را میگیرد (از این رو نام «خطای میانگین مجذورات» (Mean Squared Error – MSE) بر آن گذاشته شده است).
مثالی از محاسبه زیان
فرض کنید شبکه ما همیشه خروجی 0 را میدهد – به عبارت دیگر، با اطمینان کامل فرض میکند که همه انسانها مرد هستند (Male). زیان ما چقدر خواهد بود؟
| نام (Name) | ytrue (حقیقت مبنا) | ypred (پیشبینی) | (ytrue−ypred)2 (خطای مجذور) |
| Alice | 1 | 0 | 1 |
| Bob | 0 | 0 | 0 |
| Charlie | 0 | 0 | 0 |
| Diana | 1 | 0 | 1 |
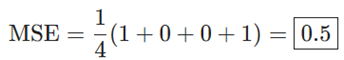
کد: زیان MSE
در اینجا کدی برای محاسبه زیان برای ما آمده است:
import numpy as np
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5
اگر نمیدانید چرا این کد کار میکند، بخش «شروع سریع» (quickstart) NumPy را در مورد عملیات آرایهها بخوانید.
5.یک شبکه عصبی
ما اکنون یک هدف واضح داریم: کمینهسازی زیان شبکه عصبی. ما میدانیم که میتوانیم وزنها و بایاسهای شبکه را برای تأثیرگذاری بر پیشبینیهای آن تغییر دهیم، اما چگونه این کار را به شیوهای انجام دهیم که زیان کاهش یابد؟
این بخش از مقدار کمی حساب چندمتغیره استفاده میکند. اگر با حساب دیفرانسیل راحت نیستید، آزادید که از بخشهای ریاضی صرف نظر کنید.
برای سادگی، فرض کنید ما تنها آلیس را در مجموعه داده خود داریم:
| نام | وزن (منهای 135) | قد (منهای 66) | جنسیت |
|---|---|---|---|
| Alice | 2- | 1- | 1 |
در این صورت، زیان خطای میانگین مجذورات همان خطای مجذور آلیس خواهد بود:
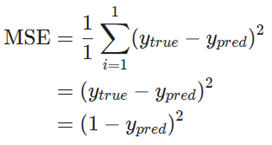
راه دیگری برای فکر کردن به زیان ، به عنوان تابعی از وزنها و بایاسها است. بیایید هر وزن و بایاس را در شبکه خود برچسبگذاری کنیم:
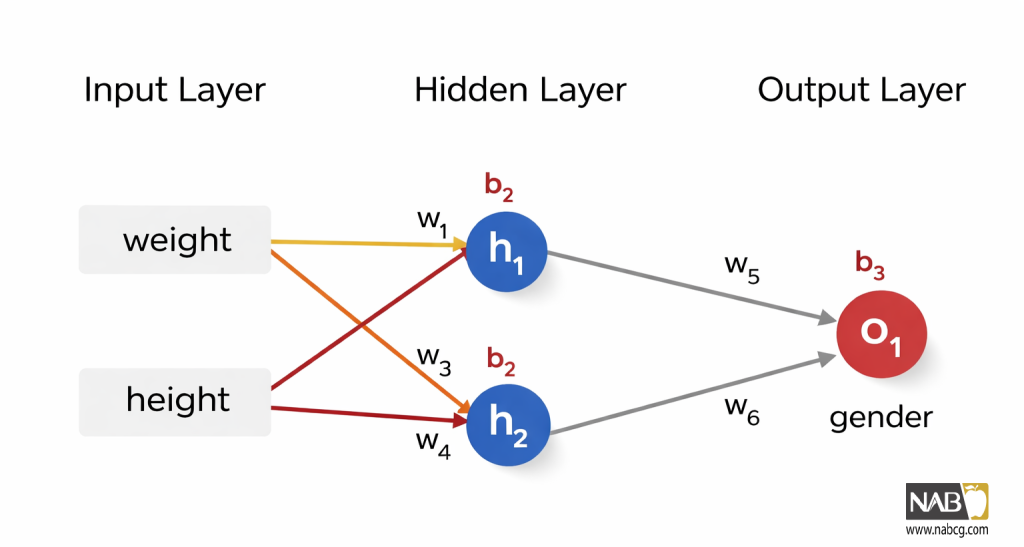
میتوان زیان را به عنوان یک تابع چندمتغیره نوشت:
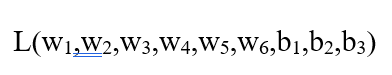
تصور کنید میخواهیم w1 را تغییر دهیم. زیان L چگونه با تغییر w1 تغییر خواهد کرد؟ چگونه آن را محاسبه کنیم؟
بیایید مشتق جزئی را بر حسب ∂ypred /∂w1 بازنویسی کنیم:
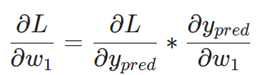
ما میتوانیم مشتق L /ypred را محاسبه کنیم، زیرا L = (1 – ypred) 2را در بالا محاسبه کردهایم:
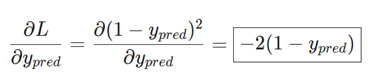
حالا، بیایید بفهمیم با
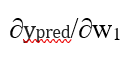
چه کنیم.
همانند قبل، فرض کنید h1، h2 و o1 خروجیهای نورونهایی باشند که نمایش میدهند. در این صورت:
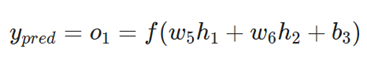
از آنجا که w1 تنها بر h1 تأثیر میگذارد (و نه بر h2)، میتوانیم بنویسیم:
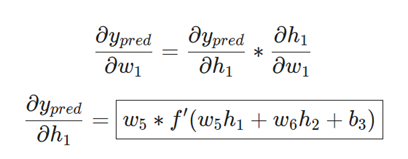
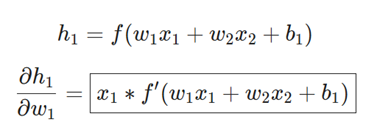
x1 در اینجا وزن و x2 قد است. این دومین باری است که f'(x) (مشتق تابع سیگموئید) را میبینیم! بیایید آن را استخراج کنیم:
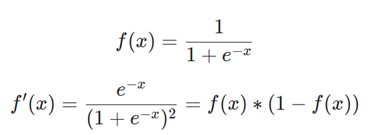
ما در ادامه از این شکل مناسب برای f'(x) استفاده خواهیم کرد.
کار تمام شد!
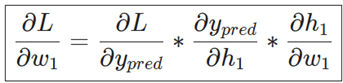
این سیستم محاسبه مشتقات جزئی با کار کردن در جهت معکوس، به عنوان «انتشار معکوس» شناخته میشود.
.
6.مثال: محاسبه مشتق جزئی (Partial Derivative)
ما همچنان فرض خواهیم کرد که تنها آلیس در مجموعه داده ما حضور دارد:
| نام (Name) | وزن (منهای 135) | قد (منهای 66) | جنسیت (Gender) |
|---|---|---|---|
| Alice | 2- | 1- | 1 |
بیایید تمام وزنها را با 1 و تمام بایاسها را با 0مقداردهی اولیه کنیم. اگر یک گام رو به جلو (feedforward pass) از طریق شبکه انجام دهیم، به دست میآوریم:
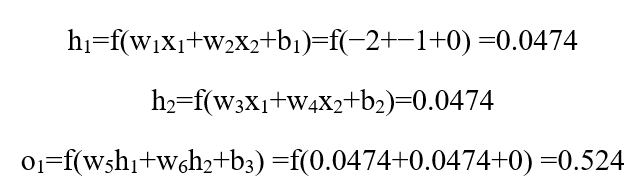
شبکه خروجیypred = 0.524 را میدهد، که به شدت نه به نفع مرد (0) است و نه زن (1). بیایید ∂L/∂w1را محاسبه کنیم:
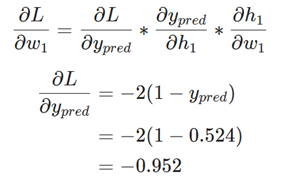
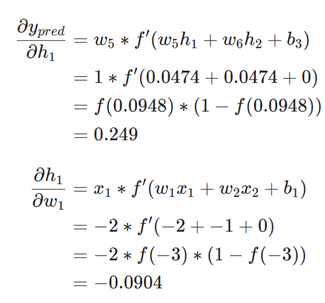

یادآوری: ما قبلاً f'(x) = f(x) * (1 – f(x)) را برای تابع فعالسازی سیگموئید خود استخراج کردیم.
ما انجامش دادیم! این به ما میگوید که اگر w1 را افزایش دهیم، L (زیان) در نتیجه آن، کمی زیاد خواهد شد.
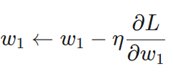
ηیک ثابت به نام «نرخ یادگیری» (learning rate) است که کنترل میکند ما با چه سرعتی آموزش دهیم. تمام کاری که ما انجام میدهیم، کم کردن η∂L/∂w1 از w1 است:
اگر
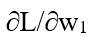
- اگر مثبت باشد، w1 کاهش مییابد، که باعث میشود L (زیان) کاهش یابد.
- اگر منفی باشد، w1 افزایش مییابد، که باعث میشود L (زیان) کاهش یابد.
اگر این کار را برای هر وزن و بایاس در شبکه انجام دهیم، زیان به آرامی کاهش مییابد و شبکه ما بهبود خواهد یافت.
7.کد: شبکه عصبی کامل
بالأخره زمان پیادهسازی یک شبکه عصبی کامل است:
| نام | وزن (منهای 135) (x1) | قد (منهای 66) (x2) | جنسیت (Female=1,Male=0) |
|---|---|---|---|
| Alice | 2- | 1- | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | 15- | 6- | 1 |
import numpy as np
def sigmoid(x):
# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
*** DISCLAIMER ***:
The code below is intended to be simple and educational, NOT optimal.
Real neural net code looks nothing like this. DO NOT use this code.
Instead, read/run it to understand how this specific network works.
'''
def __init__(self):
# Weights
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# Biases
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# x is a numpy array with 2 elements.
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
- data is a (n x 2) numpy array, n = # of samples in the dataset.
- all_y_trues is a numpy array with n elements.
Elements in all_y_trues correspond to those in data.
'''
learn_rate = 0.1
epochs = 1000 # number of times to loop through the entire dataset
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- Do a feedforward (we'll need these values later)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- Calculate partial derivatives.
# --- Naming: d_L_d_w1 represents "partial L / partial w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Neuron o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- Update weights and biases
# Neuron h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- Calculate total loss at the end of each epoch
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# Define dataset
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# Train our neural network!
network = OurNeuralNetwork()
network.train(data, all_y_trues)
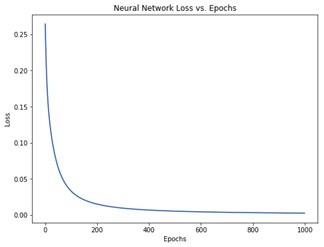
با یادگیری شبکه، زیان (Loss) ما به طور پیوسته (Steadily) کاهش مییابد:
اکنون میتوانیم از شبکه برای پیشبینی جنسیتها استفاده کنیم:
# Make some predictions
emily = np.array([-7, -3]) # 128 pounds, 63 inches
frank = np.array([20, 2]) # 155 pounds, 68 inches
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M
جمع بندی
در اینجا یک مرور سریع از آنچه انجام دادیم آمده است:
- نورونها، بلوکهای ساختمانی شبکههای عصبی، را معرفی کردیم.
- از تابع فعالسازی سیگموئید در نورونهای خود استفاده کردیم.
- دیدیم که شبکههای عصبی فقط نورونهای متصل به هم هستند.
- یک مجموعه داده با وزن و قد به عنوان ورودی و جنسیت به عنوان خروجی (یا برچسب) ایجاد کردیم.
- درباره توابع زیان و خطای میانگین مجذورات (MSE) آموختیم.
- درک کردیم که آموزش یک شبکه، صرفاً کمینهسازی زیان آن است.
- از انتشار معکوس (backpropagation) برای محاسبه مشتقات جزئی استفاده کردیم.
- از گرادیان کاهشی تصادفی (SGD) برای آموزش شبکه خود استفاده کردیم.



