

مقدمه: الهام از مغز، خلق هوش نوین
در قلب تحول بزرگ هوش مصنوعی (AI) و به ویژه یادگیری عمیق (Deep Learning)، ساختاری شگفتانگیز به نام شبکه عصبی مصنوعی (Artificial Neural Network – ANN) قرار دارد. اگر هوش مصنوعی را به یک انقلاب صنعتی تشبیه کنیم، شبکههای عصبی موتور بخار این انقلاب هستند؛ نیرویی که امکان پردازش دادهها، تشخیص چهرهها، درک زبان و حتی خلق هنر را به ماشینها داده است.
شاید در مقاله [شبکه عصبی چیست؟] به طور گذرا به شبکههای عصبی اشاره کرده باشیم، اما عمق این سازوکار فراتر از یک تعریف ساده است. این مقاله برای شما که تا حدودی با مفاهیم AI آشنا هستید، دروازهای به سوی درک کامل نحوه عملکرد، معماری و دلایل قدرت بیانتهای این ساختار پیچیده است. ما با استناد به تحقیقات پیشگامانه دانشگاه استنفورد و گزارشهای استراتژیک BCG و Deloitte، به رمزگشایی از عملکرد این مغز ماشینی میپردازیم.
معماری پایه: آناتومی یک نورون مصنوعی
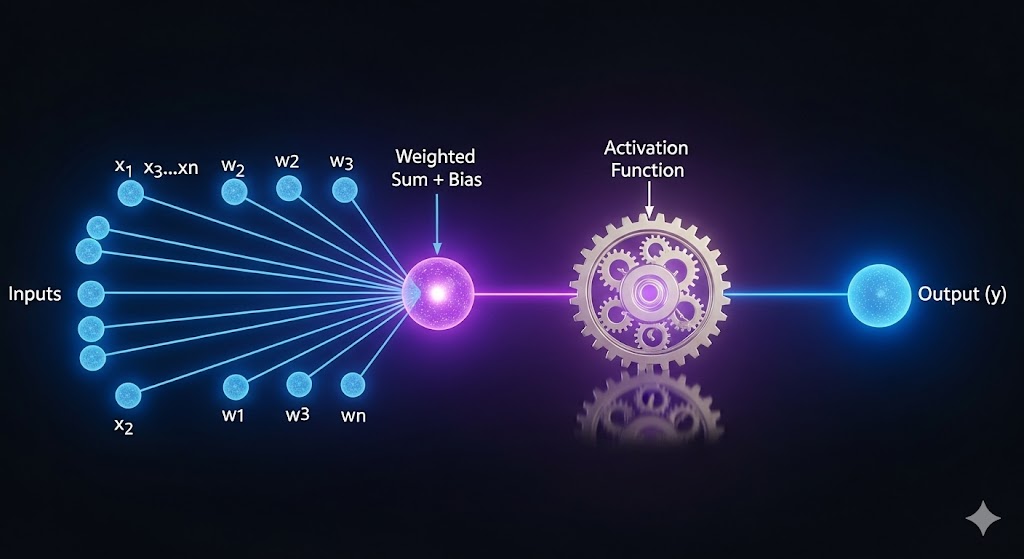
شبکه عصبی، همانطور که از نامش پیداست، از سلولهای بیولوژیکی مغز انسان الهام گرفته است. درک کارکرد شبکه، با درک کوچکترین واحد سازنده آن، یعنی نورون مصنوعی یا پِرسِپترون (Perceptron) آغاز میشود.
ساختار پرسپترون: واحد پردازش بنیادی
یک نورون مصنوعی بسیار سادهتر از یک نورون بیولوژیکی است، اما عملکرد آن را شبیهسازی میکند: دریافت ورودیها، انجام یک محاسبه و تولید خروجی. این فرآیند سه مرحله کلیدی دارد:
الف. ورودیها و وزنها (Inputs and Weights)
هر نورون چندین ورودی (x1,x2,…,xn) دریافت میکند. این ورودیها میتوانند پیکسلهای یک تصویر، کلمات یک جمله یا ویژگیهای یک رکورد داده باشند. مهمتر از خود داده، وزنها (w1,w2,…,wn) هستند.
- وزن (Weight) : وزن، نشاندهنده اهمیت یا قدرت تأثیرگذاری هر ورودی بر خروجی نهایی نورون است. اگر یک ورودی خاص (مثلاً وجود یک لبه تیز در تشخیص تصویر) برای نتیجه نهایی حیاتی باشد، وزن بالاتری دریافت میکند.
- دیدگاه یادگیری: همانطور که هاروارد در مقالات خود توضیح میدهد، یادگیری در شبکههای عصبی چیزی نیست جز تنظیم همین وزنها. هدف الگوریتم، پیدا کردن مجموعهای از وزنهاست که به دقیقترین خروجی منجر شود.
ب. مجموع وزندار و بایاس (Weighted Sum and Bias)
نورون در مرحله میانی، یک مجموع وزندار را محاسبه میکند:
Weighted Sum=(x1×w1)+(x2×w2)+⋯+(xn×wn)+Bias
بایاس (Bias) : بایاس را میتوان به عنوان یک ضریب ثابت در نظر گرفت که به نورون اجازه میدهد، مستقل از ورودیها، آستانه فعالسازی خود را تنظیم کند. اگر تمام ورودیها صفر باشند، بایاس میتواند همچنان نورون را فعال کند. این ویژگی انعطافپذیری مدل را به شدت افزایش میدهد.
ج. تابع فعالسازی (Activation Function)
نتیجه مجموع وزندار به تابع فعالسازی داده میشود. این تابع، خروجی نهایی نورون را تعیین میکند.
- نقش کلیدی: مهمترین نقش تابع فعالسازی، وارد کردن غیرخطی بودن (Non-linearity) به شبکه است. بدون این توابع مانند ReLU، Sigmoid، Tanh، شبکه صرفاً یک مدل خطی بسیار بزرگ میشد که توانایی حل مسائل پیچیده مانند تشخیص الگوها در تصاویر یا متن را نداشت.
- استناد : محققان در مؤسسه آلن تورینگ و سایر مراکز، اهمیت توابع فعالسازی غیرخطی را در ساخت مدلهای یادگیری عمیق (Deep Learning) برای حل مسائل جهان واقعی تأکید میکنند.
ساختار عمیق: لایههای پنهان هوش
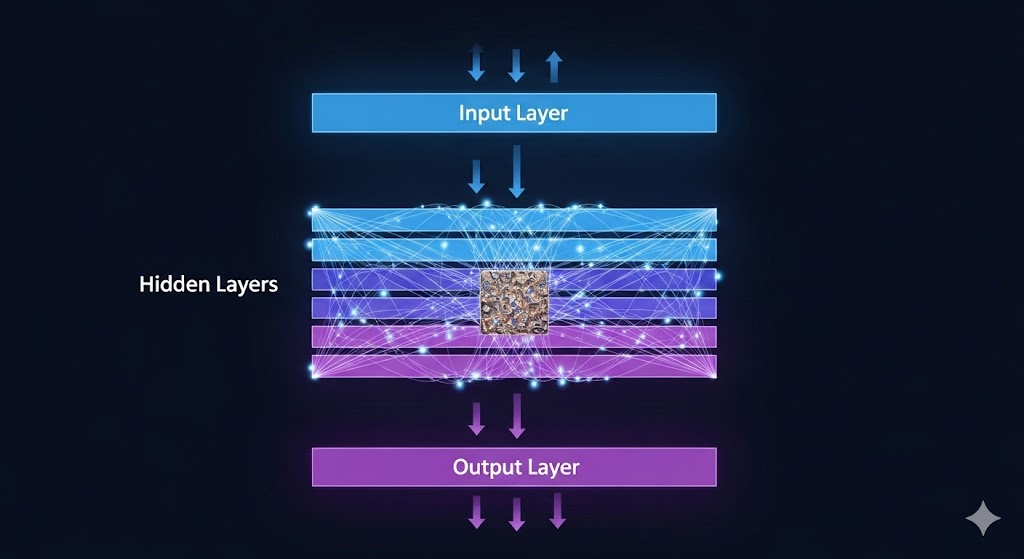
یک نورون به تنهایی قدرتی ندارد؛ قدرت واقعی در اتصال و عمق لایهها نهفته است. شبکههای عصبی ساختاری لایهای دارند.
. سه لایه اصلی شبکه عصبی
- لایه ورودی (Input Layer) : مسئول دریافت دادههای خام (مثلاً 784 پیکسل یک تصویر 28×28 ).
- لایههای پنهان (Hidden Layers) : قلب پردازش شبکه. در این لایهها، نورونها به طور متوالی ویژگیهای پیچیدهتر و انتزاعیتر را از دادهها استخراج میکنند. هر چه تعداد این لایهها بیشتر باشد، شبکه عمیقتر است (Deep Learning).
- لایه خروجی (Output Layer) : مسئول ارائه نتیجه نهایی (مثلاً احتمال اینکه تصویر ورودی عدد “۵” باشد).
مفهوم عمق در یادگیری عمیق
چرا به آن یادگیری عمیق میگویند؟ بر اساس تعاریف BCG و مککنزی، عمق (تعداد لایهها) به شبکه اجازه میدهد که سلسله مراتبی از ویژگیها را بیاموزد:
- لایه اول: یاد میگیرد لبهها و خطوط ساده را شناسایی کند.
- لایههای میانی: یاد میگیرند اشکال پیچیدهتر مانند چشمها، بینی یا چرخها را از ترکیب لبهها تشکیل دهند.
- لایههای عمیق تر: یاد میگیرند ساختارهای کلی (مانند چهره انسان یا کل خودرو) را از ترکیب اشکال پیچیده تشخیص دهند.
این توانایی استخراج خودکار و سلسله مراتبی ویژگیها، تمایز اصلی یادگیری عمیق از روشهای سنتی یادگیری ماشین است که در آنها ویژگیها باید توسط انسان تعریف میشدند.
فرآیند آموزش شبکه عصبی
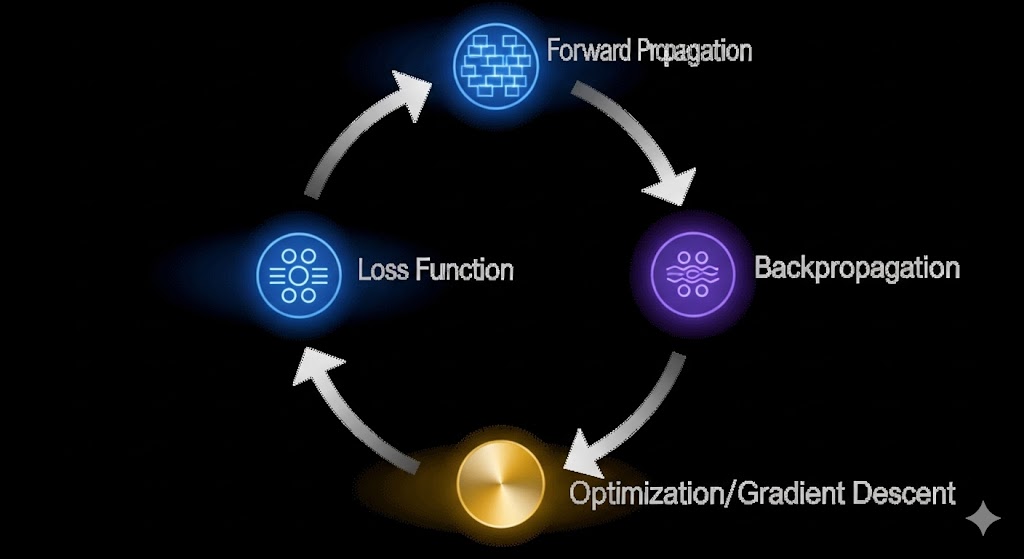
نکته شگفتانگیز در مورد شبکههای عصبی، توانایی آنها در آموزش مستقل است. فرآیند یادگیری، که عمدتاً از طریق یادگیری تحت نظارت (Supervised Learning) انجام میشود، یک چرخه بازخوردی است که شامل چهار مرحله کلیدی است.
انتشار رو به جلو (Forward Propagation)
در این مرحله، دادههای ورودی از طریق شبکه حرکت میکنند:
- دادهها وارد لایه ورودی میشوند.
- از طریق مجموع وزندار و تابع فعالسازی، از هر نورون در لایههای پنهان عبور میکنند.
- یک خروجی یا پیشبینی (Prediction) در لایه خروجی تولید میشود.
تابع زیان (Loss Function)
پس از تولید پیشبینی توسط شبکه، نیاز است بدانیم این پیشبینی چقدر از حقیقت (برچسب واقعی داده) فاصله دارد. این وظیفه بر عهده تابع زیان (Loss Function) است مانند Mean Squared Error یا Cross-Entropy.
- نقش: تابع زیان، یک مقدار عددی تولید میکند که نشاندهنده میزان خطای شبکه است. هدف فرآیند یادگیری، کاهش این مقدار زیان به کمترین حد ممکن است.
انتشار روبهعقب (Backpropagation)
این مرحله، مهمترین و تعیینکنندهترین گام در آموزش شبکه عصبی است.
- مفهوم اصلی: فرآیند انتشار روبهعقب، خطا را از لایه خروجی گرفته و آن را به صورت معکوس در تمام لایهها، تا لایه ورودی، توزیع میکند. این کار با استفاده از قانون مشتقگیری زنجیرهای (Chain Rule) در حساب دیفرانسیل انجام میشود تا مشخص شود که سهم هر وزن در ایجاد خطای نهایی چقدر بوده است.
- اهمیت تاریخی: کشف و عمومیسازی الگوریتم Backpropagation در دهه ۱۹۸۰، یکی از عواملی بود که به رنسانس هوش مصنوعی در سالهای بعد کمک کرد.
بهینهسازی و گرادیان کاهشی (Optimization and Gradient Descent)
پس از تعیین سهم هر وزن در خطا، شبکه باید وزنها را طوری تنظیم کند که در تکرار بعدی، خطا کاهش یابد. این کار توسط یک الگوریتم بهینهساز انجام میشود که معروفترین آنها گرادیان کاهشی (Gradient Descent) است.
- تمثیل بصری : گرادیان کاهشی را مانند یک کوهنورد در نظر بگیرید که در یک مه شدید (تابع زیان) قرار دارد و به دنبال پایینترین نقطه دره است. کوهنورد نمیتواند کل نقشه را ببیند، اما میتواند شیب زمین (گرادیان) را زیر پایش احساس کند و همیشه در جهتی قدم برمیدارد که بیشترین سرازیری را دارد.
- نرخ یادگیری (Learning Rate) : این نرخ، تعیین میکند که هر بار کوهنورد (الگوریتم) چقدر گام بردارد. گامهای خیلی کوچک فرآیند را کند، و گامهای خیلی بزرگ ممکن است باعث پرش از پایینترین نقطه و شکست شوند.
معماریهای پیشرفته شبکه های عصبی
شبکههای عصبی کانولوشنال (CNN)
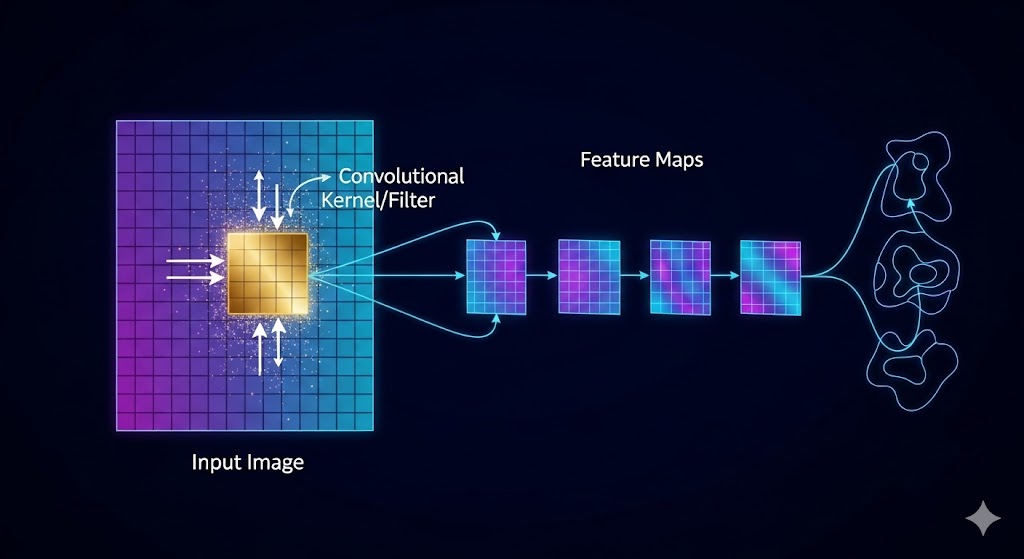
- هدف: تحلیل دادههای فضایی مانند تصویر و ویدئو.
- عملکرد : CNNها لایههایی به نام کانولوشن دارند که بهجای اتصال کامل (Full Connection)، تنها به بخشهای کوچکی از تصویر (فیلتر یا کرنل) نگاه میکنند. این امر باعث میشود که شبکه بتواند الگوهای محلی (مانند لبهها، بافتها و شکلها) را شناسایی کرده و آنها را به طور موثر در کل تصویر بهکار گیرد.
- استناد (Google AI) : این معماری، پایه و اساس بینایی کامپیوتر در خودروهای خودران، تشخیص پزشکی و نرمافزارهای تشخیص چهره است. (برای کسب اطلاعات بیشتر، مقاله [بینایی کامپیوتر چیست؟] را مطالعه کنید. )
شبکههای عصبی بازگشتی (RNN) و ترنسفورمرها (Transformers)
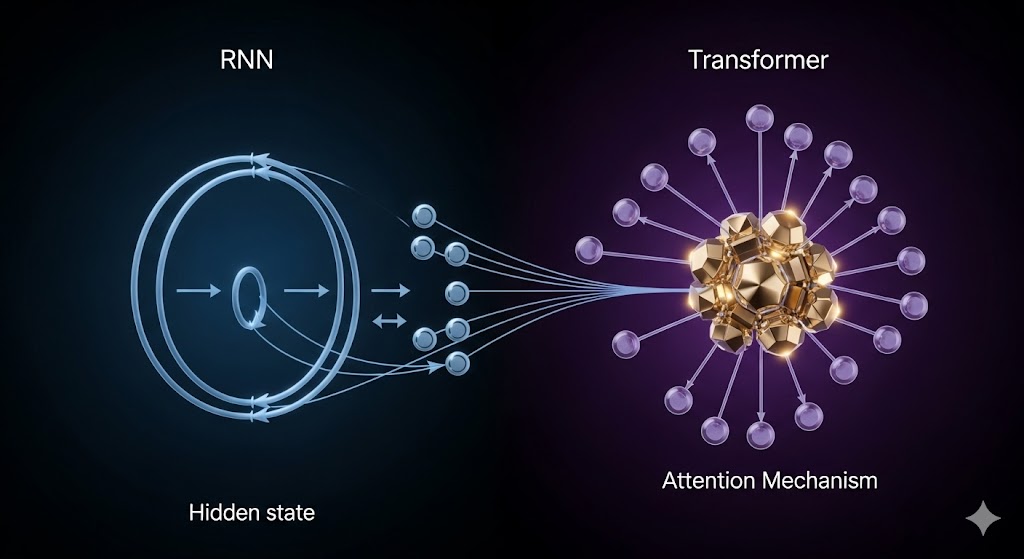
- هدف: تحلیل دادههای متوالی (Sequential) مانند متن، صوت و سریهای زمانی.
- RNN : این شبکهها دارای یک “حافظه“ یا حالت پنهان (Hidden State) هستند که اطلاعات قدمهای قبلی در یک توالی را حفظ میکنند. این ویژگی به آنها اجازه میدهد تا جملات طولانی و وابستگیهای زمانی را درک کنند.
- ترنسفورمرها: این معماری جدیدتر، که زیربنای مدلهای زبانی بزرگ (LLMs، مانند ChatGPT) است، مشکل اصلی RNNها (فراموش کردن اطلاعات در توالیهای بسیار طولانی) را با مکانیزمی به نام “توجه” (Attention) حل کرده است. توجه به شبکه اجازه میدهد تا هنگام پردازش یک کلمه، به طور همزمان به کلمات مرتبط در هر نقطه از جمله نگاه کند. در مقاله [پردازش زبان طبیعی] با جزئیات بیشتر به آن پرداختهایم.
شبکههای عصبی مولد رقابتی (GAN)
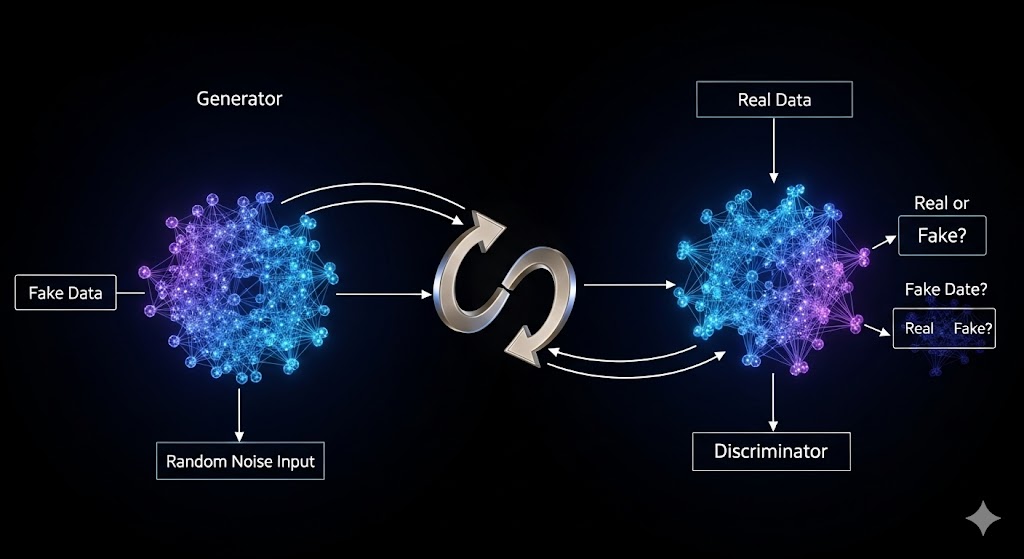
- هدف: تولید محتوای جدید (تصاویر، موسیقی، متن) که واقعی به نظر برسد.
- ساختار رقابتی : GANها از دو شبکه عصبی که با یکدیگر رقابت میکنند، تشکیل شدهاند: مولد (Generator) که محتوای جعلی تولید میکند، و متمایزکننده (Discriminator) که سعی میکند تشخیص دهد کدام محتوا واقعی است و کدام جعلی. این رقابت، کیفیت محتوای تولیدی را به طور مداوم افزایش میدهد. (در مقاله [معرفی مدلهای مولد (Generative AI) این مفهوم به تفصیل بیان شده است. )
ابعاد تجاری و چالشهای شبکه عصبی
پیچیدگی شبکههای عصبی، پیامدهای عمیقی برای کسبوکارها و متخصصان به دنبال داشته است.
قدرت پیشبینی در صنعت (BCG & McKinsey)
شرکتهای مشاوره مانند BCG و مککنزی در گزارشهای خود تأکید میکنند که قدرت شبکههای عصبی در توانایی آنها برای پیشبینی دقیق و کاهش عدم قطعیتها نهفته است:
- پیشبینی تقاضا: شبکههای عصبی RNN و CNN میتوانند با تحلیل دادههای سری زمانی (اقتصادی، آب و هوایی، اجتماعی) تقاضای محصولات را با دقتی بیسابقه پیشبینی کنند.
- مدیریت ریسک: در امور مالی، شبکههای عمیق با تحلیل الگوهای پیچیده و نامحسوس در دادههای تراکنش، ریسکهای اعتباری یا عملیاتی را بسیار بهتر از مدلهای سنتی تشخیص میدهند.
چالش جعبه سیاه((Black Box و اخلاق (PwC & IBM)
با این حال، بزرگترین چالش شبکههای عصبی پیشرفته، بهویژه با لایههای متعدد، مسئله “جعبه سیاه” (Black Box) بودن است.
- مسئله شفافیت: همانطور که PwC در چارچوب Responsible AI خود تأکید میکند، در بسیاری از موارد (مانند تصمیمگیری در مورد پذیرش وام یا تشخیص پزشکی)، ما نمیتوانیم به طور واضح توضیح دهیم که شبکه عصبی چگونه به آن نتیجه رسیده است. این امر اعتمادپذیری و پاسخگویی (Accountability) را کاهش میدهد.
- راهحل: این چالش، ضرورت توسعه حوزه هوش مصنوعی توضیحپذیر (XAI) را دوچندان کرده است، جایی که محققان بهدنبال ابزارهایی برای شفافسازی فرآیندهای داخلی شبکههای عصبی هستند. )
منابع و مقیاسپذیری (Deloitte & Accenture)
آموزش شبکههای عصبی عمیق، به ویژه مدلهای ترنسفورمر با میلیاردها پارامتر، نیاز به قدرت محاسباتی و دادههای عظیم دارد. Deloitte و Accenture در گزارشهای خود اشاره میکنند که مقیاسپذیری و دسترسی به زیرساختهای ابری قدرتمند (مانند Google Cloud و Microsoft Azure) شرط لازم برای بهرهبرداری کامل از قدرت شبکههای عصبی است. این امر، شکاف بین شرکتهای بزرگ و کوچک در پذیرش AI را افزایش میدهد.
نتیجهگیری: شبکه عصبی، نقشه راه هوش آینده
شبکههای عصبی، معماری حیاتی و ستون فقرات عصر هوش مصنوعی مدرن هستند. از ورودیها و وزنها تا لایههای پنهان و انتشار روبهعقب، هر جزء نقش خود را در ساخت یک سیستم هوشمند و یادگیرنده ایفا میکند. این سیستمها نه تنها وظایف را خودکار میکنند، بلکه با توانایی استخراج خودکار ویژگیها، مرزهای اکتشافات علمی و ارزشآفرینی تجاری را جابهجا کردهاند. درک عمیق نحوه کارکرد این شبکهها، کلید بهرهبرداری مؤثر و مسئولانه از قدرت بینهایت یادگیری عمیق در آیندهای نزدیک است.