

مقدمه: از فرمانبرداری به یادگیری مستقل
دنیای امروز بر پایه پیشبینی و تحلیل میچرخد و در مرکز این تحول، یادگیری ماشین (Machine Learning – ML) قرار دارد. اگر هوش مصنوعی (AI) هدف است، یادگیری ماشین ابزار دستیابی به آن است. همانطور که در مقاله( یادگیری ماشین چیست؟) اشاره کردیم، ML فرآیندی است که به ماشینها اجازه میدهد بدون برنامهنویسی صریح، از دادهها یاد بگیرند.
اما سؤال اصلی که متخصصان و مدیران را درگیر میکند، “چگونه” است. چگونه یک الگوریتم میتواند الگوهای پیچیده را در میلیونها داده شناسایی کند؟ و مکانیسمهای پشت پرده این “مغز ماشینی” برای تصمیمگیری چیست؟
این مقاله، فراتر از تعاریف اولیه، به جزئیات مکانیسمهای اصلی و انواع تکنیکهای یادگیری ماشین میپردازد. ما با استناد به مدلهای ریاضی و گزارشهای کاربردی هاروارد، استنفورد، مککنزی، و دلویت (Deloitte)، نقشه راه عملکرد یادگیری ماشین را برای شما رمزگشایی میکنیم.
۱. چارچوب اساسی یادگیری ماشین
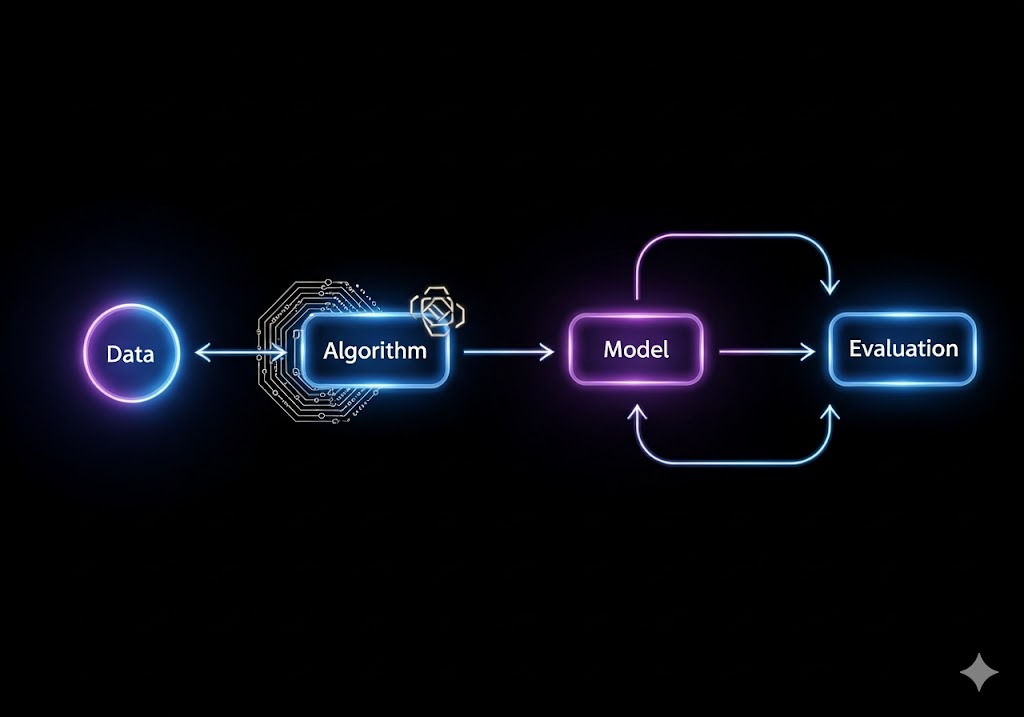
قبل از پرداختن به جزئیات الگوریتمها، درک یک چارچوب استاندارد ضروری است. یادگیری ماشین یک فرآیند خطی نیست، بلکه یک چرخه مداوم است که از داده شروع شده و به بهبود مدل ختم میشود.
۱.۱. سه گام حیاتی در مسیر یادگیری
هر مدل یادگیری ماشین، فارغ از نوع الگوریتم، برای رسیدن به هدف خود، سه گام ریاضیاتی و آماری را طی میکند که در هسته کارکرد آن قرار دارند:
الف. تابع هدف یا معیار عملکرد (Objective/Cost Function)
هر الگوریتم ML ابتدا باید بداند که هدفش چیست و چگونه موفقیت را اندازه بگیرد. این معیار، همان تابع زیان (Loss Function) یا تابع هزینه (Cost Function) است.
- نقش: این تابع، میزان اختلاف (خطا) بین پیشبینی مدل و مقدار واقعی (حقیقت زمینی یا Ground Truth) را محاسبه میکند.
- دیدگاه آماری: این تابع، اساساً به الگوریتم میگوید که “چقدر بد عمل کردهای”. هدف مدل، تنظیم پارامترهای داخلی خود به گونهای است که مقدار خروجی این تابع (زیان) به کمترین حد ممکن برسد.
ب. الگوریتم آموزش یا بهینهساز (Optimization Algorithm)
این مکانیسم قلب فرآیند یادگیری است. وظیفه بهینهساز، تغییر پارامترهای داخلی مدل (وزنها و بایاسها) در جهت کاهش تابع زیان است.
- گرادیان کاهشی (Gradient Descent) : الگوریتمهای مدرن ML تقریباً همگی از مشتقات این تکنیک استفاده میکنند. گرادیان کاهشی، همانند یک کوهنورد عمل میکند که در یک مه شدید، در جستجوی پایینترین نقطه دره (کمترین زیان) است و تنها با بررسی شیب لحظهای (گرادیان) مسیر خود را تنظیم میکند.
- سرعت یادگیری (Learning Rate) : این پارامتر، اندازه گامهایی را که الگوریتم برای رسیدن به حداقل زیان برمیدارد، تعیین میکند. تنظیم نادرست این نرخ، میتواند منجر به کندی بیش از حد یا پرش از روی نقطه بهینه شود.
ج. مدل و نمایش داده (Model and Representation)
مدل ML، صرف نظر از نوع آن، یک نمایش ریاضیاتی از دادهها و روابط بین آنها ایجاد میکند. توانایی ML در موفقیت، به طور مستقیم به توانایی آن در استخراج ویژگیها (Feature Engineering) بستگی دارد.
- نقش استخراج ویژگی : در گذشته، مهندسان باید ویژگیهای حیاتی را به صورت دستی استخراج میکردند؛ اما ML، به ویژه یادگیری عمیق، توانایی خودکارسازی این فرآیند را دارد و روابط پنهان را کشف میکند.
یادگیری ماشین: یک فرآیند چرخهای، نه یک جادو

اولین چیزی که باید بدانید این است که یادگیری ماشین یک فرآیند خطی نیست. بلکه یک چرخه تکرارشونده است که شامل مراحل زیر میشود:
- تعریف مسئله
- جمعآوری و آمادهسازی داده
- انتخاب و آموزش مدل
- ارزیابی و اعتبارسنجی
- استقرار و نظارت
هر یک از این مراحل نقش حیاتی در موفقیت نهایی دارد. در ادامه، هر مرحله را با مثالهای واقعی و ارجاع به منابع معتبر جهانی بررسی میکنیم.
مرحله ۱: تعریف مسئله
بسیاری از پروژههای یادگیری ماشین از همان ابتدا شکست میخورند، چون مسئله بهدرستی تعریف نشده است.
- آیا هدف ما طبقهبندی است (مثلاً «این ایمیل اسپم است یا خیر»)؟
- یا رگرسیون (مثلاً «فروش ماه آینده چقدر خواهد بود»)؟
- یا خوشهبندی (مثلاً «چه گروههایی از مشتریان رفتار مشابه دارند»)؟
همانطور که هاروارد بیزینس ریویو (2023) هشدار میدهد:
“اگر مسئله را اشتباه فرموله کنید، حتی بهترین مدل هم جواب اشتباهی میدهد.”
مثال واقعی: یک بانک میخواست «ریسک اعتباری» را پیشبینی کند. اما بهجای تعریف دقیق «عدم پرداخت وام در 6 ماه آینده»، از معیارهای مبهمی مانند «وضعیت مالی ضعیف» استفاده کرد. نتیجه؟ مدل ساختهشده بیفایده بود.
مرحله ۲: جمعآوری و آمادهسازی داده
اگر یادگیری ماشین یک ماشین است، داده سوخت آن است. اما نه هر دادهای — بلکه دادهای باکیفیت، مرتبط و کافی.
چرا آمادهسازی داده مهم است؟
طبق گزارش دیلویت (2024)، تا 80 درصد زمان یک پروژه یادگیری ماشین صرف جمعآوری، پاکسازی و تبدیل داده میشود. این مرحله شامل:
- حذف دادههای گمشده
- یکنواختسازی فرمتها (مثلاً تاریخها)
- تبدیل متغیرهای دستهای به عددی (مثل «مرد» = 1، «زن» = 0)
- حذف سوگیریهای پنهان (مثلاً دادههایی که فقط از یک منطقه جغرافیایی جمعآوری شدهاند)
💡 نکته طلایی: «دادههای زباله، خروجیهای زباله» (Garbage In, Garbage Out). این اصل قدیمی هنوز برقرار است.
اگر علاقهمندید بدانید چگونه دادهها تحلیل میشوند، مقاله «دادهکاوی چیست و چرا برای کسبوکارها مهم است؟» میتواند دیدگاه گستردهتری ارائه دهد.
مرحله ۳: انتخاب و آموزش مدل
در این مرحله، دادههای آمادهشده به یک الگوریتم یادگیری ماشین داده میشوند تا الگوهای پنهان را یاد بگیرد.
چگونه یک مدل «یاد میگیرد»؟
تصور کنید میخواهید به یک کودک یاد بدهید که سیب را از پرتقال تشخیص دهد. شما چندین تصویر نشان میدهید و میگویید: «این سیب است»، «این پرتقال است». کودک بهتدریج ویژگیهایی مانند رنگ، شکل و بافت را یاد میگیرد.
مدلهای یادگیری ماشین هم همین کار را میکنند — اما بهجای تصویر، از اعداد و بردارها استفاده میکنند. در هر دور آموزش (Epoch)، مدل پیشبینی میکند، خطای خود را محاسبه میکند، و پارامترهای داخلی خود را تنظیم میکند تا در آینده بهتر عمل کند.
این فرآیند بهنام بهینهسازی شناخته میشود و معمولاً از روشی به نام گرادیان کاهشی (Gradient Descent) استفاده میکند.
انتخاب مدل مناسب
انتخاب الگوریتم مناسب به نوع مسئله و داده بستگی دارد:
- درخت تصمیم (Decision Tree) : برای مسائل ساده و قابل تفسیر
- جنگل تصادفی (Random Forest) : برای دقت بالاتر بدون بیشبرازش
- ماشین بردار پشتیبان (SVM) : برای دادههای با ابعاد بالا
- شبکه عصبی: برای دادههای پیچیده مانند تصویر یا متن
اگرچه شبکههای عصبی محبوب هستند، اما طبق گزارش مک کنزی (2023)، بیش از 60 درصد پروژههای صنعتی هنوز از الگوریتمهای سادهتر استفاده میکنند — چون قابل تفسیرتر و کمهزینهتر هستند.
مرحله ۴: ارزیابی و اعتبارسنجی
یکی از بزرگترین سوءتفاهمها این است که اگر مدل روی دادههای آموزشی خوب عمل کند، پس «خوب است». اما این کاملاً اشتباه است.
مشکل بیشبرازش (Overfitting)
مدلی که بیشازحد به دادههای آموزشی وابسته شود، ممکن است آنها را «حفظ» کند، نه «یاد بگیرد». چنین مدلی روی دادههای جدید عملکرد ضعیفی خواهد داشت.
برای جلوگیری از این مشکل، دادهها را به سه بخش تقسیم میکنیم:
- داده آموزشی (70%) : برای آموزش مدل
- داده اعتبارسنجی (15%) : برای تنظیم هایپرپارامترها
- داده آزمون (15%) : برای ارزیابی نهایی
معیارهای ارزیابی
انتخاب معیار مناسب بستگی به نوع مسئله دارد:
- صحت (Accuracy) : برای مسائل متعادل
- دقت : (Precision) برای مسائل نامتعادل (مثل تشخیص تقلب)
- بازیابی : (Recall) برای مسائل نامتعادل (مثل تشخیص تقلب)
- F1-Score : برای مسائل نامتعادل (مثل تشخیص تقلب)
- میانگین مربعات خطا (MSE) : برای رگرسیون
همانطور که آیبیام در راهنمای خود تأکید میکند:
هرگز فقط به صحت نگاه نکنید. زمینه مسئله تعیینکننده معیار مناسب است.
مرحله ۵: استقرار و نظارت
آموزش مدل فقط آغاز کار است. چالش واقعی اجرای آن در محیط تولید است.
چالشهای استقرار
- تغییر تدریجی در دادهها (Data Drift) : مثلاً رفتار مشتریان پس از یک بحران اقتصادی تغییر میکند.
- کاهش عملکرد مدل (Model Decay) : مدلی که سال گذشته خوب کار میکرد، امروز ممکن است بیفایده باشد.
- نیاز به تفسیرپذیری: در صنایعی مانند بانکداری، باید بتوانید توضیح دهید چرا یک وام رد شده است.
شرکت اکسنچر در گزارشی با عنوان MLOps : The Next Frontier (2024) تأکید میکند که سازمانهای موفق، یادگیری ماشین را بهعنوان یک فرآیند مداوم، نه یک پروژه یکباره، مدیریت میکنند.
مثال واقعی: تشخیص تقلب بانکی با یادگیری ماشین

- تعریف مسئله: پیشبینی اینکه آیا یک تراکنش تقلبی است یا خیر (طبقهبندی دودویی).
- جمعآوری داده: تراکنشهای گذشته با برچسب «تقلبی/غیرتقلبی»، شامل مبلغ، زمان، مکان، دستگاه و غیره.
- آمادهسازی داده: حذف تراکنشهای ناقص، تبدیل مکان به مختصات جغرافیایی، نرمالسازی مبالغ.
- آموزش مدل: استفاده از جنگل تصادفی برای دقت بالا و تفسیرپذیری.
- ارزیابی: استفاده از F1-Score بهدلیل نامتعادل بودن داده (تقلبها کم هستند).
- استقرار: ادغام مدل در سیستم پرداخت لحظهای.
- نظارت: رصد عملکرد ماهانه و بازآموزش در صورت کاهش دقت.
طبق گزارش PwC (2024)، بانکهایی که این چرخه را بهدرستی پیادهسازی کردهاند، تا 35% کمتر با کلاهبرداری مواجه میشوند.
چرا برخی مدلهای یادگیری ماشین شکست میخورند؟
دادههای سوگیر: یک سیستم استخدامی که فقط از رزومههای مردان آموزش دیده، زنان را رد میکند.
- تعریف اشتباه موفقیت: پیشبینی «کلیک» بهجای «خرید واقعی» در تبلیغات.
- عدم نظارت پس از استقرار: مدلی که پس از 6 ماه بدون بازآموزش، دقت خود را از دست میدهد.
دانشگاه استنفورد در AI Index 2024 هشدار میدهد که بیش از 50% مدلهای یادگیری ماشین پس از استقرار، هرگز بازآموزش داده نمیشوند — و این یک اتلاف منابع عظیم است.
انواع اصلی یادگیری ماشین
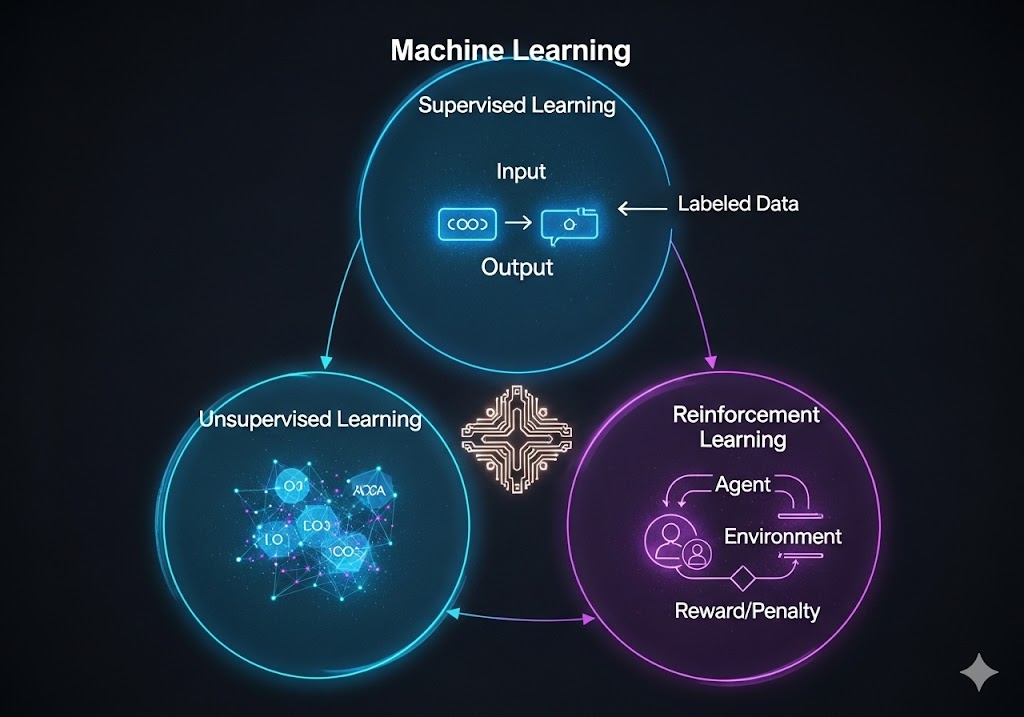
یادگیری ماشین بر اساس نحوه تعامل با دادهها و نوع دادههای ورودی، به سه رویکرد اصلی تقسیم میشود.
۱. یادگیری تحت نظارت (Supervised Learning)
این رویکرد، رایجترین شکل ML است و بر اساس دادههایی که از پیش برچسبگذاری شدهاند (Labelled Data)، آموزش میبیند.
- تمثیل: مانند یادگیری یک دانشآموز با حضور یک معلم که در هر مرحله پاسخ صحیح را به او میگوید.
- انواع وظایف (Tasks) :
- دستهبندی (Classification) : پیشبینی یک دسته یا گروه گسسته (مانند تشخیص اینکه یک ایمیل هرزنامه است یا عادی). هاروارد در تحقیقات خود بر کاربرد این روش در پزشکی برای دستهبندی تومورها (خوشخیم/بدخیم) تأکید میکند.
- رگرسیون (Regression) : پیشبینی یک مقدار پیوسته (مانند پیشبینی قیمت مسکن بر اساس متراژ و موقعیت(.
- الگوریتمهای کلیدی:
- ماشینهای بردار پشتیبان (Support Vector Machines – SVM) : برای جداسازی دادهها با یک مرز تصمیمگیری بهینه.
- جنگل تصادفی (Random Forest) : ترکیبی از چندین درخت تصمیمگیری برای بهبود دقت و کاهش بیشبرازش (Overfitting). (این تکنیک، در گزارشهای BCG برای تحلیل ریسک مشتریان بسیار مورد اشاره قرار گرفته است.)
۲. یادگیری بدون نظارت (Unsupervised Learning)
این رویکرد با دادههایی کار میکند که فاقد برچسب هستند و هدف آن، کشف ساختارها و الگوهای پنهان در دادهها بدون هیچ راهنمایی خارجی است.
- تمثیل: مانند قرار دادن یک دانشآموز در مقابل مجموعهای از اشیاء ناشناخته و درخواست برای گروهبندی آنها بر اساس شباهتهایشان.
- انواع وظایف:
- خوشهبندی (Clustering) : گروهبندی نقاط داده مشابه به یکدیگر (مانند تقسیمبندی مشتریان بر اساس عادات خرید برای بازاریابی هدفمند). مککنزی بر اهمیت این روش در ایجاد مدلهای شخصیسازی تأکید دارد.
- کاهش ابعاد (Dimensionality Reduction) : سادهسازی دادهها با حذف ویژگیهای غیرضروری برای کاهش پیچیدگی و بهبود سرعت مدل (مانند PCA).
- الگوریتمهای کلیدی:
- K-Means : الگوریتمی پرکاربرد برای خوشهبندی که دادهها را در ‘K’ خوشه بر اساس نزدیکی به مرکز خوشه تقسیم میکند.
۳. یادگیری تقویتی (Reinforcement Learning – RL)
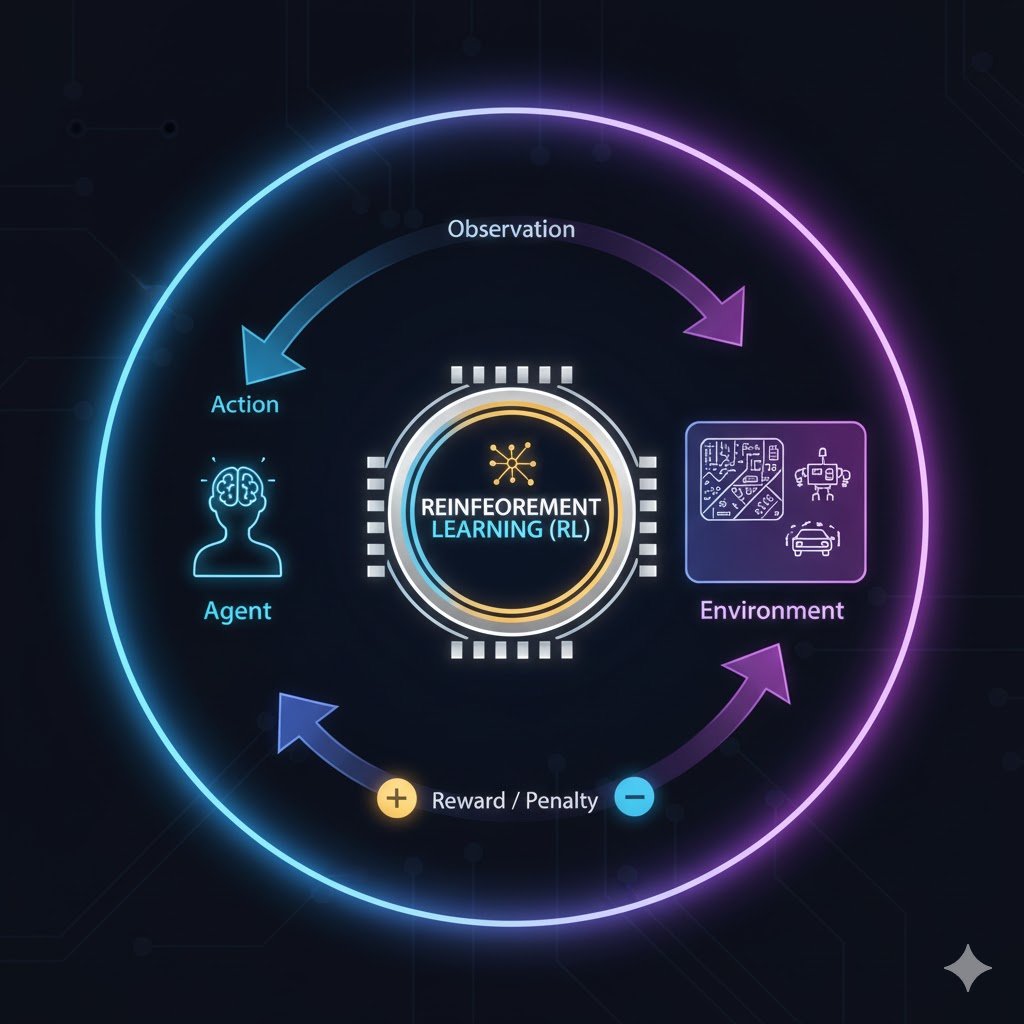
این رویکرد، یک روش منحصر به فرد است که در آن یک عامل (Agent) در یک محیط پویا یاد میگیرد که چه اقدامی را در چه وضعیتی انجام دهد تا پاداش (Reward) خود را به حداکثر برساند.
- تمثیل: مانند آموزش یک سگ با استفاده از پاداش (تشویقی) و تنبیه.
- مکانیسم کار: عامل، محیط را مشاهده میکند، عملی انجام میدهد، پاداش یا جریمه دریافت میکند و بر اساس آن خطمشی (Policy) خود را تنظیم مینماید.
- کاربرد عملی (DeepMind) : این روش، پایه و اساس رباتیک پیشرفته، سیستمهای خودروی خودران، و مدلهایی است که بازیهای پیچیده مانند شطرنج یا Go را بازی میکنند.
بهینهسازی مدل و مدیریت عملکرد

عملکرد یک مدل ML تنها به انتخاب الگوریتم مناسب خلاصه نمیشود؛ بلکه بهینهسازی دقیق و مدیریت چالشهای آماری، رمز موفقیت آن است.
۱. مدیریت بیشبرازش و کمبرازش (Overfitting and Underfitting)
این دو مفهوم، بزرگترین چالشهای آماری در توسعه مدل ML هستند:
- بیشبرازش (Overfitting) : زمانی رخ میدهد که مدل، دادههای آموزشی را بیش از حد و با جزئیات دقیق حفظ میکند، از جمله نویز و خطاهای موجود در دادهها. در نتیجه، مدل روی دادههای جدید (که ندیده است) عملکرد ضعیفی دارد.
- راهحل (استنفورد): استفاده از تکنیکهایی مانند اعتبارسنجی متقابل (Cross-Validation) و رگولاریزاسیون (Regularization) برای جریمه کردن وزنهای بیش از حد بزرگ و سادهسازی مدل.
- کمبرازش (Underfitting) : زمانی رخ میدهد که مدل برای یادگیری روابط اساسی در دادهها بیش از حد ساده است و در نتیجه، هم روی دادههای آموزشی و هم دادههای جدید، عملکرد ضعیفی دارد.
۲. اعتبارسنجی و معیارهای ارزیابی (Evaluation Metrics)
برای اطمینان از اینکه مدل قابلیت تعمیم (Generalization) دارد، دادهها به سه بخش تقسیم میشوند:
- مجموعه آموزش (Training Set) : برای یادگیری پارامترهای مدل.
- مجموعه اعتبارسنجی (Validation Set) : برای تنظیم فراپارامترها (Hyperparameters) مانند نرخ یادگیری یا تعداد درختها.
- مجموعه آزمون (Test Set) : برای ارزیابی نهایی عملکرد مدل بر روی دادههای کاملاً جدید.
- معیارهای کلیدی: برای ارزیابی عملکرد، به جای صرفاً دقت (Accuracy)، از معیارهای تخصصی استفاده میشود: دقت (Precision)، فراخوانی (Recall)، F1-Score و AUC-ROC که به ما کمک میکنند تا عملکرد مدل را در موقعیتهای مختلف (مثلاً اهمیت تشخیص صحیح موارد مثبت در مقایسه با تشخیص صحیح موارد منفی) ارزیابی کنیم.
۵. نتیجهگیری : یادگیری ماشین، ابزار هوش در دستان شما
یادگیری ماشین، فرآیند پیچیدهای است که با سادهسازی یک مسئله پیچیده در قالب یک تابع زیان، و سپس استفاده از ابزارهای بهینهسازی مانند گرادیان کاهشی برای رسیدن به حداقل خطا، عمل میکند. درک مکانیسمهای داخلی ML، نه تنها برای متخصصان، بلکه برای مدیران استراتژیک نیز حیاتی است تا بتوانند از تواناییهای این ابزار قدرتمند در حوزه علم داده (که در مقاله [علم داده چیست؟] به آن پرداختهایم) و ساخت مدلهای آینده، به شیوهای مؤثر و مسئولانه بهره ببرند.