

مقدمه
ترنسفورمر (Transformer) یکی از مهمترین معماریهای یادگیری عمیق در سالهای اخیر است که با معرفی مکانیزم توجه (Attention) توانست بسیاری از محدودیتهای مدلهای ترتیبیِ قدیمی مثل RNN و LSTM را کاهش دهد. مشکل اصلی مدلهای ترتیبی این بود که توالی را مرحلهبهمرحله پردازش میکردند؛ در نتیجه هم آموزش کندتر بود و هم وابستگیهای دور (Long-Range Dependencies) را بهخوبی یاد نمیگرفتند. ترنسفورمر با اتکا به Self-Attention امکان میدهد تا هر کلمه (یا هر توکن) بهصورت مستقیم با سایر بخشهای توالی ارتباط بگیرد و اهمیت هر بخش را نسبت به هدف مدل وزندهی کند؛ همین ویژگی باعث افزایش دقت، سرعت آموزش (بهواسطه موازیسازی) و انعطافپذیری در مسائل مختلف شده است.
در این مقاله ابتدا ایدهی کلی ترنسفورمر و دلیل محبوبیت آن را مرور میکنیم، سپس اجزای اصلی معماری (Encoder/Decoder)، مفهوم Self-Attention و Multi-Head Attention و نقش Positional Encoding را توضیح میدهیم. در ادامه به مزایا و چالشهای این معماری (از جمله هزینه محاسباتیِ Attention در توالیهای طولانی) اشاره کرده و در نهایت کاربردهای مهم ترنسفورمر در پردازش زبان طبیعی، بینایی ماشین و سایر حوزهها را جمعبندی میکنیم. پیشنیاز پیشنهادی برای درک بهتر مطالب، آشنایی مقدماتی با مفاهیم شبکه عصبی، embedding، ماتریسها و ایدهی کلی آموزش مدلها در یادگیری عمیق است.
تعریف
ترنسفورمر یک معماری شبکه عصبی است که بر پایه مکانیزم توجه-شخصی (Self-Attention) ساخته شده است. این مدل برخلاف مدلهای قدیمیتر (مانند RNNها) که دادهها را به صورت متوالی و کُند پردازش میکردند، میتواند توالیهای داده را به صورت موازی تحلیل کند. این ویژگی به ترنسفورمر اجازه میدهد تا وابستگیهای دوربرد (Long-range Dependencies) و روابط بافتی پیچیده را در دادهها با دقت و سرعت بسیار بالایی تشخیص و تولید کند.
چرا مدلهای ترنسفورمر تا این حد اهمیت دارند؟
بزرگترین دستاورد معماری ترنسفورمر، مکانیزم خود-توجهی (Self-attention) است. این همان موتوری است که به ترنسفورمرها قدرت عجیبی برای درک روابط و وابستگیهای میان بخشهای مختلف یک ورودی میدهد. برخلاف معماریهای قدیمیتر مثل RNN و CNN، ترنسفورمرها مسیر متفاوتی را انتخاب کردهاند و تنها از لایههای توجه و لایههای استاندارد فیدفوروارد استفاده میکنند.
در واقع، همین توانایی توجه به خود و به ویژه تکنیک توجه چندسره (Multi-head attention) است که باعث شده ترنسفورمرها از سد عملکردی مدلهای پیشین عبور کنند و به استانداردهای طلایی امروز تبدیل شوند.
عبور از محدودیتهای گذشته: از RNN به ترنسفورمر
پیش از ظهور ترنسفورمرها، اکثر وظایف پردازش زبان طبیعی (NLP) بر عهده شبکههای عصبی بازگشتی (RNN) بود. اما RNNها یک مشکل ذاتی داشتند: آنها دادهها را به صورت سریالی یا پشتسرهم پردازش میکردند. یعنی کلمات را یکییکی و با ترتیبی خاص میبلعیدند.
این موضوع دو چالش بزرگ ایجاد میکرد:
- ناتوانی در درک جملات طولانی: RNNها در به خاطر سپردن روابط کلماتی که فاصله زیادی از هم داشتند، ضعیف بودند.
- کندی در پردازش: چون همه چیز باید پشت سر هم انجام میشد، امکان استفاده از قدرت کامل پردازندههای گرافیکی (GPU) وجود نداشت.
ترنسفورمرها با معرفی موازیسازی (Parallelization) این بازی را عوض کردند. آنها کل جمله را همزمان میبینند و میتوانند هزاران مرحله محاسباتی را در یک لحظه انجام دهند. این ویژگی راه را برای آموزش مدلها روی دیتاسِتهای عظیم و بیسابقه باز کرد.
چرا ترنسفورمرها حتی از CNNها هم بهترند؟
حتی در دادههای تصویری، ترنسفورمرها مزایایی نسبت به شبکههای کانولوشنی (CNN) دارند. CNNها به صورت ذاتی محلی عمل میکنند؛ یعنی هر بار فقط تکه کوچکی از تصویر را میبینند. به همین دلیل، در درک روابط بین پیکسلها یا کلماتی که در دو طرف مقابل هم قرار دارند، دچار مشکل میشوند. اما مکانیزم توجه هیچ مرز و محدودیتی نمیشناسد.
مکانیزم خود-توجهی واقعاً چیست؟
برای درک موفقیت ترنسفورمرها، باید بفهمیم توجه یعنی چه. به زبان ساده، توجه الگوریتمی است که به مدل میگوید در هر لحظه، باید به کدام بخش از دادهها بیشتر دقت کند.
بیایید با یک مثال جلو برویم. جمله زیر را در نظر بگیرید:
در روز جمعه، قاضی حکم را صادر کرد. (در انگلیسی کلمه Sentence هم به معنای جمله است و هم حکم قضایی).
مدل چگونه میفهمد منظور از Sentence در اینجا حکم است؟
- کلمه قاضی نشان میدهد که با یک فضای حقوقی طرف هستیم.
- کلمه صادر کرد تایید میکند که Sentence قطعاً به معنای جریمه یا حکم قانونی است، نه یک جمله دستوری. بنابراین، وقتی مدل میخواهد کلمه Sentence را تفسیر کند، به جای کلمات بیاهمیت مثل در یا روز، تمام توجه خود را روی کلمات قاضی و صادر کرد متمرکز میکند.
.
خود-توجهی چگونه در ۴ گام عمل میکند؟
- تبدیل به زبان اعداد (Embeddings): ابتدا مدل دادههای خام را میخواند و آنها را به بردارهای عددی تبدیل میکند که معنای مفاهیم را در خود دارند.
- سنجش شباهت (Alignment): مدل با استفاده از یک عملیات ریاضی به نام ضرب داخلی (Dot product)، میزان ارتباط هر کلمه با کلمات دیگر را میسنجد. اگر دو کلمه به هم مرتبط باشند، عدد بزرگی حاصل میشود. ۳.
- تولید وزنهای توجه (Attention Weights): این اعداد به تابعی به نام Softmax داده میشوند تا به درصدهایی بین ۰ و ۱ تبدیل شوند. مثلاً وزن ۰ یعنی این کلمه را کاملاً نادیده بگیر و وزن ۱ یعنی ۱۰۰٪ روی این کلمه تمرکز کن. ۴.
- تمرکز نهایی: در نهایت، مدل از این وزنها استفاده میکند تا اطلاعات مهم را پررنگ و اطلاعات بیهوده را کمرنگ کند.
یادگیری از طریق تجربه: در ابتدا، مدل نمیداند باید به چه چیزی توجه کند. اما در طول فرآیند آموزش و با بررسی میلیونها مثال، از طریق رفت و برگشتهای ریاضی (پسانتشار و گرادیان کاهشی)، اشتباهات خود را اصلاح کرده و یاد میگیرد که چطور دقیقترین وزنهای توجه را برای درک معنا تولید کند.
معماری ترنسفورمر: از تحلیل داده تا استخراج معنا
معماری ترنسفورمر بر پایه همکاری استراتژیک بین دو قطب اصلی بنا شده است: رمزگذار (Encoder) و رمزگشا. (Decoder) برخلاف مدلهای بازگشتی (RNN) که دادهها را به صورت متوالی پردازش میکردند، ترنسفورمر با بهرهگیری از پردازش موازی، کل توالی را به طور همزمان تحلیل کرده و روابط پیچیده میان توکنها را استخراج میکند.
۱. رمزگذار (Encoder):
رمزگذار از پشتهای از لایههای یکسان (معمولاً ۶ لایه) تشکیل شده است. وظیفه اصلی آن تبدیل توالی ورودی به یک بازنمایی با ابعاد بالا (High-dimensional) است که غنای معنایی کافی برای استفاده در رمزگشا را داشته باشد.
زیرلایههای رمزگذار:
- مکانیزم توجه-شخصی چندسره (Multi-Head Self-Attention): این لایه به مدل اجازه میدهد تا روابط میان کلمات را بدون توجه به فاصله فیزیکی آنها درک کند. برای مثال، در جمله بانک از پرداخت وام خودداری کرد چون سرمایه کافی نداشت، مدل میفهمد که نداشت به بانک برمیگردد.
- شبکه عصبی فیدفوروارد (Feed-Forward Neural Network): خروجی لایه توجه را پردازش کرده و آن را برای لایه بعدی آماده میکند.
- نگهبانان آموزش (Residual & LayerNorm): در اطراف هر زیرلایه، از اتصالات باقیمانده و نرمالسازی لایهای استفاده میشود تا پایداری و سرعت همگرایی تضمین شود.
.
۲. رمزگشا (Decoder):
رمزگشا وظیفه تولید توالی خروجی را بر عهده دارد و در هر مرحله، بر اساس ورودیهای قبلی خود و اطلاعات دریافتی از رمزگذار، کلمه بعدی را پیشبینی میکند.
زیرلایههای اختصاصی رمزگشا:
- توجه-شخصی ماسکشده (Masked Self-Attention): این لایه دیدِ مدل به کلمات آینده را مسدود میکند. این کار تضمین میکند که پیشبینی کلمه در موقعیت t فقط به کلمات قبل از t بستگی داشته باشد (خاصیت اتورگرسیو).
- توجه رمزگذار-رمزگشا (Encoder-Decoder Attention): در این لایه، رمزگشا مانند یک نورافکن روی بخشهای مرتبط با متن ورودی (خروجی رمزگذار) تمرکز میکند تا دقیقترین معادل یا پاسخ را تولید کند.
.
تحلیل و فرمول ریاضی مؤلفهها
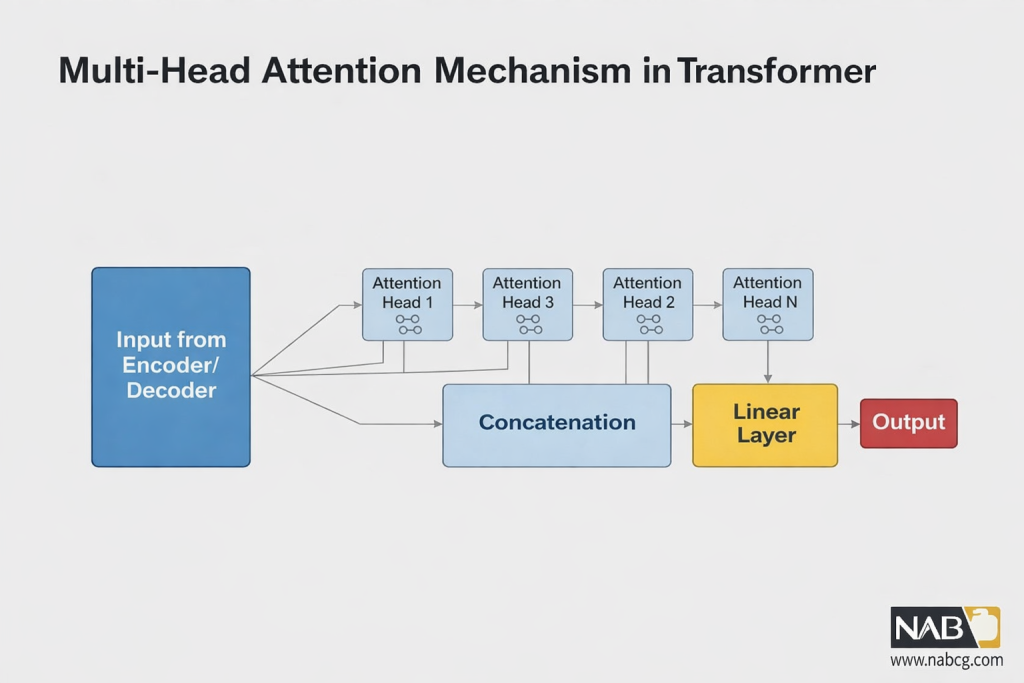
الف) مکانیزم توجه چندسره (Multi-Head Attention)
این مکانیزم به مدل اجازه میدهد تا جنبههای مختلف روابط دادهها (مثلاً روابط گرامری و معنایی) را به طور همزمان در سرهای مختلف بیاموزد.
۱. فرمول توجه مقیاسشده (Scaled Dot-Product Attention):
ابتدا سه ماتریس پرسوجو (Q)، کلید (K) و مقدار (V) ایجاد میشوند:
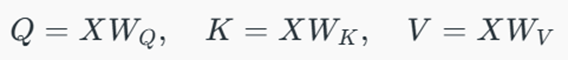
سپس خروجی توجه به صورت زیر محاسبه میگردد:
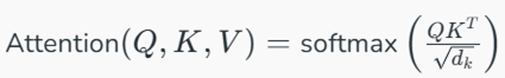
۲. فرمول چندسره (Multi-Head): خروجی تمام سرها (headi) با هم ترکیب (Concat) شده و در یک ماتریس وزن نهایی ضرب میشوند:

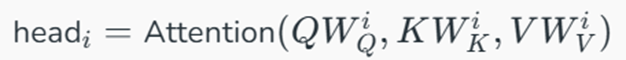
- dk: ابعاد کلیدها. تقسیم بر √dk یک فاکتور مقیاسبندی است که مانع از بزرگ شدن بیش از حد ضرب داخلی و به اشباع رفتن تابع softmax میشود.
.
ب) شبکههای فیدفوروارد (Position-wise FFN)
این شبکه به صورت مستقل بر روی هر موقعیت اعمال میشود و شامل دو تبدیل خطی با یک فعالساز غیرخطی ReLU در میان آنها است:
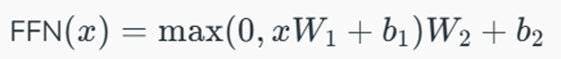
.
ج) کدگذاری موقعیتی (Positional Encoding)
از آنجا که ترنسفورمر ترتیب کلمات را به طور ذاتی نمیفهمد، از توابع سینوسی و کسینوسی برای اضافه کردن اطلاعات مکانی به بُردارهای تعبیه استفاده میکند:
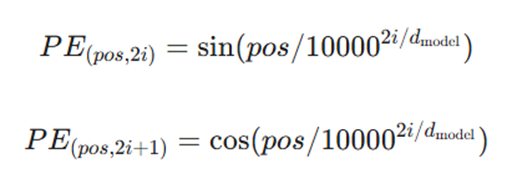
- pos: موقعیت توکن در جمله.
- i: بعدِ مربوط به بردار ویژگی.
د) اتصالات باقیمانده و نرمالسازی لایهای
این دو تکنیک برای جلوگیری از محو شدن گرادیانها و تضمین جریان اطلاعات در شبکههای عمیق استفاده میشوند:
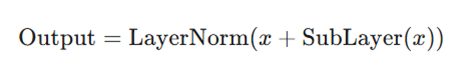
جدول مقایسهای عملکرد اجزاء
| مولفه | نقش اصلی | خروجی کلیدی |
| Self-Attention | درک روابط داخلی توالی | ماتریس امتیازات توجه |
| Cross-Attention | پیوند ورودی به خروجی | تمرکز بر بخشهای مرتبط ورودی |
| FFN | پردازش غیرخطی ویژگیها | بازنماییهای پالایششده |
| LayerNorm | پایداری عددی | آموزش سریعتر و منظم |
مدلهای ترنسفورمر چگونه کار میکنند؟
مدلهای ترنسفورمر با الهام از ساختار پایگاههای داده رابطهای عمل میکنند؛ به این صورت که برای هر بخش از یک توالی داده، بردارهای پرسوجو (Query)، کلید (Key) و مقدار (Value) تولید کرده و از آنها برای محاسبه وزنهای توجه (Attention Weights) از طریق ضرب ماتریسی استفاده میکنند.
در واقع، مقاله جریانساز Attention is All You Need این چارچوب مفهومی را برای پردازش روابط بین توکنها در یک توالی متن به کار گرفت.
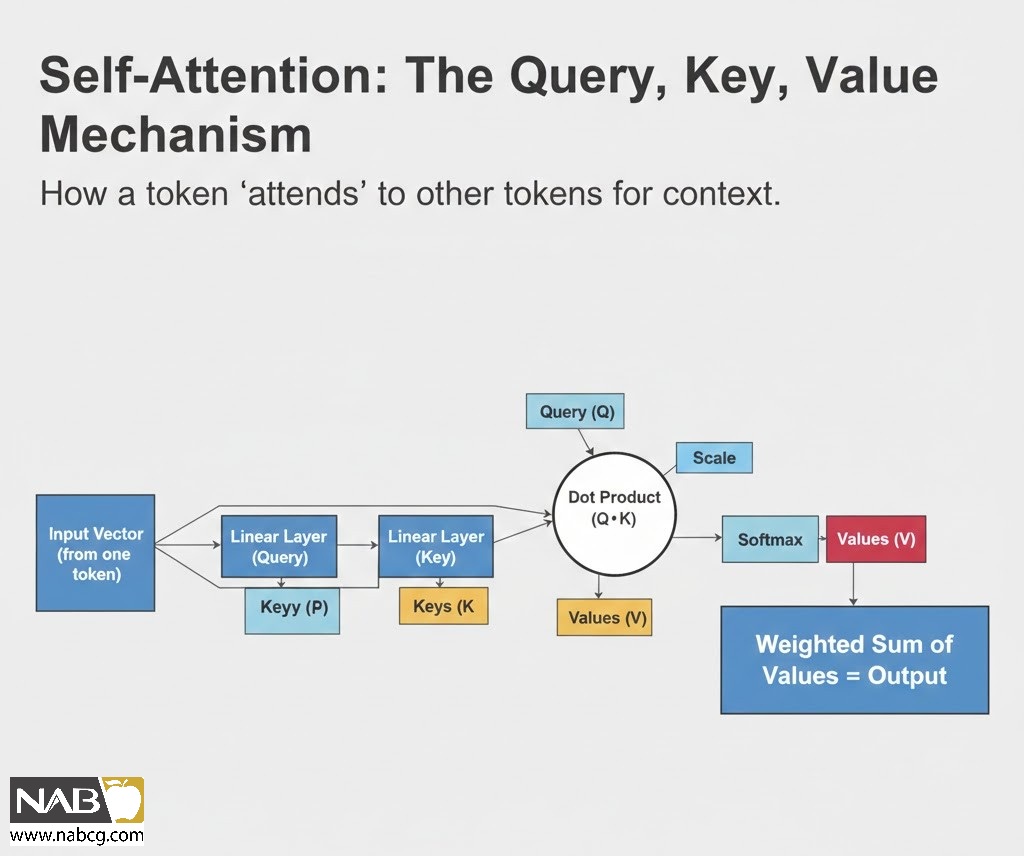
اجزای اصلی مکانیزم توجه
برای درک بهتر، میتوان این بردارهای سهگانه را به این صورت تعریف کرد:
- بردار پرسوجو (Query): اطلاعاتی است که یک توکن خاص به دنبال آن است تا بفهمد سایر کلمات چگونه بر معنا یا نقش آن در متن تأثیر میگذارند.
- بردارهای کلید (Key): حاوی اطلاعاتی هستند که هر توکن در خود دارد. همترازی بین پرسوجو و کلید، وزن توجه یا میزان ارتباط آنها را تعیین میکند.
- بردار مقدار (Value): اطلاعات نهایی را بازمیگرداند که بر اساس وزن توجه، مقیاسبندی شده است. کلماتی که ارتباط بیشتری داشته باشند، وزن سنگینتری دریافت میکنند.
.
مرحله ۱: توکنسازی و تعبیهسازی ورودی (Tokenization & Embeddings)
ما انسانها از حروف استفاده میکنیم، اما مدلهای هوش مصنوعی با توکن کار میکنند. هر توکن یک عدد شناسایی (ID) دریافت میکند که این کار باعث کاهش چشمگیر توان محاسباتی مورد نیاز میشود. مدل برای شروع، به یک بردار اولیه و بدون بافتار (Contextless) برای هر توکن نیاز دارد که یا در طول آموزش یاد گرفته میشود و یا از مدلهای پیشآموزشدیده استخراج میگردد.
.
مرحله ۲: کدگذاری موقعیتی (Positional Encoding)
برخلاف مدلهای قدیمی (RNN) که کلمات را به ترتیب میخواندند، ترنسفورمرها همه کلمات را همزمان میبینند. بنابراین، باید اطلاعات مربوط به جایگاه هر کلمه به صورت دستی اضافه شود. مدل یک بردار مقادیر را به تعبیه هر توکن اضافه میکند؛ به طوری که توکنهای نزدیکتر، بردارهای موقعیتی مشابهتری دارند و مدل یاد میگیرد به کلمات مجاور توجه بیشتری نشان دهد.
.
مرحله ۳: تولید بردارهای Q، K و V
پس از اضافه شدن اطلاعات موقعیتی، تعبیهی هر توکن از سه لایه شبکه عصبی فیدفوروارد موازی عبور میکند تا سه بردار جدید تولید شود:
- ضرب در ماتریس وزن W^Q برای تولید بردار پرسوجو (Q)
- ضرب در ماتریس وزن W^K برای تولید بردار کلید (K)
- ضرب در ماتریس وزن W^V برای تولید بردار مقدار (V)
.
مرحله ۴: محاسبه خودتوجهی (Self-Attention)
وظیفه اصلی این بخش، اختصاص وزنهای دقیق به جفتهای پرسوجو و کلید است. در نهایت:
- بردار مقدارِ هر توکن در وزن توجه مربوطهاش ضرب میشود.
- این مقادیر با هم جمع میشوند تا اطلاعات بافتاری کل توالی برای توکن مورد نظر (مثلاً x) استخراج شود.
- این بردارِ نهایی به تعبیه اولیه توکن اضافه میشود تا معنای آن بر اساس کلمات پیرامونش بهروزرسانی شود.
.
مرحله ۵: توجه چندسره (Multi-head Attention)
برای درک جنبههای مختلف و پیچیده روابط بین کلمات، ترنسفورمرها از چندین سَرِ توجه استفاده میکنند. ورودی اولیه به بخشهای مساوی تقسیم شده و هر بخش وارد یک مدار موازی (یک Head) میشود. در پایان، خروجی تمام این مدارها دوباره به هم متصل (Concatenate) میشوند تا جنبههای مختلف معنایی در کنار هم قرار گیرند.
.
مرحله ۶: اتصالات باقیمانده و نرمالسازی لایهای
گاهی اوقات پردازشهای عمیق باعث میشود معنای اصلی کلمه گم شود. برای حل این مشکل، مدل از اتصالات باقیمانده استفاده میکند؛ یعنی بردار بهروزرسانی شده را با بردار اولیه جمع میکند تا پایداری آموزش حفظ شود. سپس دادهها نرمالسازی شده و به بلوک توجه بعدی فرستاده میشوند.
.
مرحله ۷: تولید خروجی (Generating Outputs)
در نهایت، در مدلهای زبانی بزرگ (LLM)، لایه آخر از تابع Softmax استفاده میکند تا احتمال مطابقت کلمه بعدی با هر یک از توکنهای موجود در واژگان خود را محاسبه کند. مدل بر اساس این احتمالات، توکن بعدی خروجی را انتخاب میکند.
.
پیاده سازی در پایتون
این پیادهسازی مستقیماً بر اساس لایهها و فرمولهای ریاضی است که در مقاله بررسی کردیم. فرآیند کدنویسی را میتوان به گامهای زیر تقسیم کرد:
- تولید بردارها (Linear Projections): ورودی از سه لایه خطی عبور میکند تا ماتریسهای پرسوجو (Q)، کلید (K) و مقدار (V) تولید شوند.
- محاسبه نمرات شباهت (Dot Product): با ضرب ماتریسی Q در ترانهادهی K، میزان ارتباط هر توکن با سایر توکنها سنجیده میشود.
- مقیاسبندی (Scaling): برای جلوگیری از بزرگ شدن بیش از حد اعداد و پایداری نمرات، حاصل بر ریشه دوم ابعاد کلیدها (√dk) تقسیم میشود.
- نرمالسازی (Softmax): نمرات به احتمال (وزنهای بین ۰ و ۱) تبدیل میشوند تا مجموع توجه در هر سطر برابر با ۱ باشد.
- تولید خروجی نهایی: با ضرب این وزنها در ماتریس V، بردار بافتار (Context Vector) نهایی ساخته میشود.
کد پایتون:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerAttention(nn.Module):
def __init__(self, d_model):
super(TransformerAttention, self).__init__()
self.d_k = d_model
# تعریف لایههای خطی برای تولید Q, K, V
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
# گام 1: تولید ماتریسهای Q, K, V
q = self.w_q(x)
k = self.w_k(x)
v = self.w_v(x)
# گام 2 و 3: ضرب داخلی و مقیاسبندی
# خروجی امتیازها ابعادی به اندازه (batch, seq_len, seq_len) دارد
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
# گام 4: اعمال ماسک (اصلاح شده)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# گام 5: محاسبه وزنهای توجه با تابع Softmax
attn_weights = F.softmax(scores, dim=-1)
# گام 6: محاسبه بردار بافتار نهایی
context_vector = torch.matmul(attn_weights, v)
return context_vector, attn_weights
# --- تست عملی کد و مشاهده خروجی ---
d_model = 16 # ابعاد ویژگیها (بردار هر کلمه)
seq_len = 4 # تعداد کلمات جمله ورودی
x = torch.randn(1, seq_len, d_model) # ایجاد یک ورودی تصادفی
# مقداردهی اولیه لایه توجه
attention_layer = TransformerAttention(d_model)
# اجرای مدل
output, weights = attention_layer(x)
# نمایش نتایج
print(f"شکل بردار خروجی نهایی: {output.shape}")
print("\nماتریس وزنهای توجه (میزان ارتباط کلمات با یکدیگر):")
print(weights[0].detach().numpy())
خروجی:

.
کاربردهای ترنسفورمرها
۱. انقلاب در پردازش زبان طبیعی (NLP)
ترنسفورمرها با تسخیر بنچمارکهایی نظیر GLUE و SuperGLUE، تعریف جدیدی از هوش زبانی ارائه دادهاند. از ترجمه ماشینی همزمان گرفته تا تحلیل عمیق احساسات و پاسخ به پرسشهای پیچیده، همگی تحت تأثیر این معماری به دقتِ سطح انسانی نزدیک شدهاند.
۲. بینایی ماشین (Computer Vision)
ظهور مدلهایی مانند Vision Transformers (ViTs) ثابت کرد که مکانیزم توجه فقط مختص متن نیست. امروزه در طبقهبندی تصاویر و تشخیص اشیاء (Object Detection)، ترنسفورمرها با درک روابط فضایی بین پیکسلها، تطبیقپذیری فوقالعادهای از خود نشان دادهاند.
۳. پردازش صوت و گفتار
در سیستمهای بازشناسی خودکار گفتار (ASR)، ترنسفورمرها با استفاده از مکانیزم توجه، بافتار معنایی را از توالیهای صوتی طولانی استخراج میکنند. این امر منجر به کاهش چشمگیر خطا در تبدیل گفتار به متن (Voice-to-Text) شده است.
۴. سیستمهای توصیهگر هوشمند
غولهای تجارت الکترونیک و پلتفرمهای محتوایی برای درک الگوهای پیچیده در تعاملات کاربر-کالا از ترنسفورمرها استفاده میکنند. این مدلها با تحلیل تاریخچه رفتاری شما، دقیقترین پیشنهادها را با توجه به علایق لحظهای ارائه میدهند.
۵. زیستفناوری و کشف دارو (Protein Folding)
یکی از شگفتانگیزترین کاربردهای ترنسفورمرها در مدل AlphaFold نمایان شد. از آنجا که توالی پروتئینها شباهت زیادی به ساختار زبان دارد، ترنسفورمرها توانستند ساختار سهبعدی پروتئینها را با دقت بینظیری پیشبینی کنند که انقلابی در داروسازی ایجاد کرده است.
۶. تحلیل سریهای زمانی و بازارهای مالی
در پیشبینی قیمت سهام، تحلیل نوسانات بازار و حتی پیشبینی هواشناسی، ترنسفورمرها به دلیل توانایی در ثبت وابستگیهای طولانیمدت (Long-term dependencies)، جایگزین مدلهای آماری سنتی شدهاند.
.
مطالعه موردی ۱: تحلیل احساسات (Sentiment Analysis) در بازارهای مالی
در این پروژه، از مدل BERT (که یک مدل فقط-رمزگذار است) استفاده میکنیم تا لحن اخبار اقتصادی را تشخیص دهیم. این کار در پیشبینی نوسانات بازار و بازارهای مالی بسیار کلیدی است.
توضیحات فنی
- مدل: distilbert-base-uncased-finetuned-sst-2-english (نسخهی بهینه و سریع BERT).
- فرآیند: متن خبر توکنسازی شده، از لایههای توجه عبور کرده و در نهایت برچسب مثبت یا منفی میگیرد.
from transformers import pipeline
import matplotlib.pyplot as plt
# 1. بارگذاری مدل تحلیل احساسات
classifier = pipeline("sentiment-analysis")
# 2. لیست اخبار فرضی بازار سرمایه
news_headlines = [
"Stock market reaches all-time high as inflation cools down",
"Investors are worried about the new interest rate hike",
"Tech companies report record-breaking profits this quarter",
"Oil prices crash due to low global demand"
]
# 3. تحلیل اخبار
results = classifier(news_headlines)
# 4. استخراج دادهها برای رسم نمودار
labels = [res['label'] for res in results]
scores = [res['score'] for res in results]
# خروجی بصری
colors = ['green' if l == 'POSITIVE' else 'red' for l in labels]
plt.barh(news_headlines, scores, color=colors)
plt.xlabel("Confidence Score")
plt.title("Financial News Sentiment Analysis")
plt.show()
خروجی:
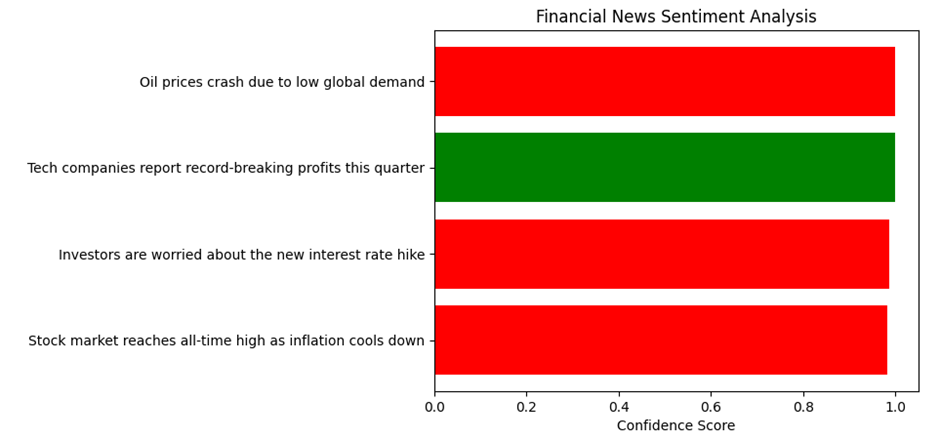
.
مطالعه موردی ۲: خلاصهسازی خودکار متن (Abstractive Summarization)
این مورد قدرت رمزگشا (Decoder) را در تولید جملات جدید بر اساس بافتار ورودی نشان میدهد. مدل باید اطلاعات را فشرده کرده و معنای اصلی را حفظ کند.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 1. نام مدل تخصصی بارت برای خلاصهسازی
model_name = "facebook/bart-large-cnn"
# 2. بارگذاری توکنساز و مدل
print("در حال بارگذاری مدل... (ممکن است کمی طول بکشد)")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 3. متن ورودی (برگرفته از مقاله شما)
article = """
The Transformer architecture has revolutionized deep learning by using self-attention mechanisms.
Unlike older RNN models that processed data sequentially, Transformers analyze entire sequences in parallel.
This allowed for massive scalability and led to the creation of large models like GPT-4.
However, they require significant GPU resources and face memory issues with very long texts.
"""
# 4. تبدیل متن به توکن
inputs = tokenizer([article], max_length=1024, return_tensors="pt", truncation=True)
# 5. تولید خلاصه توسط رمزگشا (Decoder)
summary_ids = model.generate(inputs["input_ids"], num_beams=4, max_length=50, early_stopping=True)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print("\n" + "="*20 + " خلاصه تولید شده " + "="*20)
print(summary)
print("="*57)
خروجی:
==================== خلاصه تولید شده ====================
The Transformer architecture has revolutionized deep learning by using self-attention mechanisms. Unlike older RNN models that processed data sequentially, Transformers analyze entire sequences in parallel. This allowed for massive scalability and led to the creation of.
مزایا
- موازیسازی (Parallelization): برخلاف RNNها که کلمات را دانهبهدانه پردازش میکردند، ترنسفورمرها کل داده را همزمان میبینند. این ویژگی اجازه میدهد تا از قدرت کامل GPUها برای آموزش سریعتر استفاده کنیم.
- درک روابط دوربرد (Long-range Dependencies): به لطف مکانیزم توجه، ترنسفورمرها میتوانند ارتباط بین دو کلمه را که در ابتدا و انتهای یک متن طولانی قرار دارند، به راحتی درک کنند؛ مشکلی که در مدلهای قدیمی باعث فراموشی میشد.
- مقیاسپذیری (Scalability): این مدلها تشنهی داده و پارامتر هستند. هرچه ابعاد مدل و حجم دادهها را بیشتر کنید، هوشمندی آنها به شکل خیرهکنندهای افزایش مییابد (پدیدهای که منجر به ظهور GPT-4 شد).
.
معایب
- شدت محاسباتی (Computational Intensity): مکانیزم خود-توجهی به منابع سختافزاری بسیار زیادی نیاز دارد. هزینه آموزش و نگهداری این مدلها سرسامآور است و فقط در انحصار شرکتهای بزرگ با ابررایانههاست.
- تنگنای حافظه در توالیهای طولانی: با اینکه آنها در روابط دوربرد عالی هستند، اما حافظه مورد نیاز با افزایش طول متن به صورت نمایی (Quadratic) رشد میکند. این یعنی پردازش همزمانِ چندین کتاب قطور هنوز یک چالش جدی است.
- نیاز به دادههای حجیم (Data Hunger): ترنسفورمرها برخلاف انسانها، با چند مثال ساده یاد نمیگیرند. آنها برای رسیدن به عملکرد مطلوب، نیاز به میلیاردها کلمه و دادههای پیشآموزش (Pre-training) دارند تا دچار بیشبرازش نشوند.
- بایاس و سوگیریهای اخلاقی: از آنجا که این مدلها از دادههای اینترنت تغذیه میکنند، تمام کلیشهها، سوگیریهای نژادی و جنسیتی و رفتارهای نامناسب موجود در وب را جذب میکنند. پاکسازی این سوگیریها (Alignment) یکی از داغترین مباحث امروز هوش مصنوعی است.
- مصرف انرژی و محیط زیست: آموزش یک مدل ترنسفورمر بزرگ، معادل با چندین سال مصرف انرژی دهها خانه است. این موضوع باعث شده تا بحث هوش مصنوعی سبز و بهینهسازی مصرف انرژی در این مدلها اهمیت ویژهای پیدا کند.
.
جمع بندی
ترنسفورمر با جایگزینکردن پردازش کاملاً ترتیبی با مکانیزم Self-Attention، روشی قدرتمند برای مدلسازی توالیها ارائه میدهد؛ روشی که در آن مدل میتواند ارتباط میان اجزای دور و نزدیکِ داده را بهصورت مستقیم یاد بگیرد و همزمان از قابلیت موازیسازی برای آموزش سریعتر بهره ببرد. در این مقاله دیدیم که هستهی اصلی این معماری، محاسبهی توجه از طریق Query/Key/Value، استفاده از Multi-Head برای یادگیری روابط متنوعتر، و بهکارگیری Positional Encoding برای واردکردن اطلاعات ترتیب در داده است. همچنین ساختار Encoder/Decoder نشان میدهد ترنسفورمر چگونه هم برای وظایف درک (مثل طبقهبندی یا استخراج ویژگی) و هم برای وظایف تولید (مثل ترجمه و تولید متن) قابل استفاده است.
با وجود مزایای چشمگیر، ترنسفورمر استاندارد در توالیهای بسیار طولانی با چالش هزینهی محاسباتی و حافظه (معمولاً با رشد درجهدو نسبت به طول توالی) مواجه میشود؛ به همین دلیل در سالهای اخیر نسخههای بهینهتری مانند مدلهای Efficient/Linear Attention و روشهای فشردهسازی و پنجرهبندی توجه توسعه یافتهاند. در مجموع، ترنسفورمرها پایهی بسیاری از مدلهای مدرن (از BERT و GPT تا ViT) هستند و فهم سازوکار آنها برای یادگیری عمیقِ امروز ضروری است. پیشنهاد میشود برای ادامه مسیر، پیادهسازی Attention و سپس مطالعهی مدلهای معروف مبتنی بر ترنسفورمر و روشهای بهینهسازی آنها را دنبال کنید.