

مقدمه
شناسایی دادههای پرت فقط نیمی از مسیر است؛ تصمیمگیری درباره اینکه با این نقاط چه رفتاری داشته باشیم، بخش حساستر و تعیینکنندهتر ماجراست. یک انتخاب اشتباه—مثل حذف همه دادههای پرت—میتواند تحلیلها را منحرف کند، دقت مدلها را کاهش دهد یا حتی بخش مهمی از واقعیت داده را از بین ببرد.
در این بخش به مهمترین راهبردهای مدیریت دادههای پرت میپردازیم و توضیح میدهیم که هر کدام در چه شرایطی بهترین انتخاب هستند. تشخیص دادههای پرت پایان کار نیست؛ تازه نقطهی شروع مرحلهای حساستر است: تصمیمگیری درباره اینکه با این نقاط چه کار کنیم. این تصمیم، پاسخ آماده و واحد ندارد و کاملاً به زمینه، نوع داده، هدف تحلیل و دانش دامنه بستگی دارد. اگر بدون فکر، همیشه یک استراتژی ثابت را (مثلاً حذف همه نقاط پرت) اجرا کنیم، هم از نظر علمی و هم از نظر عملی کار خطرناکی انجام دادهایم
برای آشنایی با تعریف Outlier و انواع آن، بخش «کالبدشکافی دادههای پرت» را ببینید.
Outlier، Anomaly و Novelty چه تفاوتی دارند؟
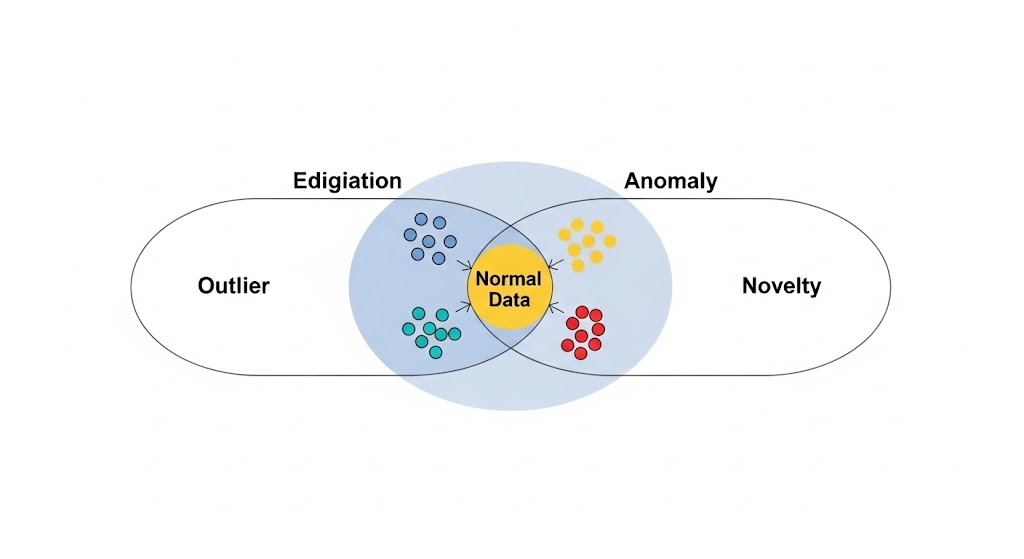
در بسیاری از متون، این سه اصطلاح به جای هم بهکار میروند، اما از نظر علمی سه مفهوم متفاوت هستند و تشخیص این تفاوت برای تصمیمگیری در مورد مدیریت دادههای پرت بسیار مهم است.
1. Outlier (داده پرت)
یک مشاهده «غیرعادی» که از الگوی کلی داده فاصله دارداما لزومی ندارد خطرناک، نادر، یا مهم باشد.
مثالها:
• خطای اندازهگیری سنسور
• اشتباه تایپی
• مقدار بسیار بزرگ اما طبیعی
• رفتار متفاوت یک کاربر در یک روز خاص
Outlier ممکن است:
- خطا باشد ← باید اصلاح/حذف شود
- واقعی باشد ← باید بررسی و تحلیل شود
2. Anomaly (ناهنجاری)
هر Outlier لزوماً anomaly نیست.
Anomaly دادهای است که معنی عملی مهم داردو اغلب نشاندهنده یک اتفاق خطرناک، بحرانی، یا حساس است؛ مثل:
• تراکنش تقلبی
• حمله سایبری
• خرابی تجهیزات
• نشانه بیماری خطرناک
• رفتار غیرعادی بازار
اینجا Outlier = سیگنال است، نه خطا.
3. Novelty (الگوی جدید)
Novelty دادهای است که مدل قبلی آن را ندیده و نمیشناسد،اما میتواند طبیعی باشد.
مثالها:
• مشتری جدید با الگوی خرید جدید
• محصول جدید
• شرایط جدید بازار
• رفتار تازه سیستم پس از بروزرسانی
پرسش های کلیدی قبل از انتخاب استراتژی
ماهیت دادهی پرت چیست؟
آیا تقریباً مطمئنیم که خطاست (اشتباه اندازهگیری، ورود دستی، خرابی سنسور، نمونهگیری غلط)، یا احتمال میدهیم یک مشاهدهی واقعی اما شدید / نادر باشد؟
هدف تحلیل چیست؟
فقط خلاصهی توصیفی میخواهیم؟ دنبال آزمون فرض آماری و برآورد پارامتر هستیم؟ دقت پیشبینی برای دادههای آینده مهمتر است یا خودِ ناهنجاریها برای ما موضوع اصلیاند (مثل تقلب، نفوذ، خرابی سامانه)؟
ویژگیهای داده چگونه است؟
حجم نمونه کوچک است یا بزرگ؟ تعداد متغیرها زیاد است؟ نوع متغیرها پیوستهاند یا اسمی و رتبهای؟
مدلها و روشهایی که قرار است استفاده کنیم چقدر به دادههای پرت حساساند؟
مثلاً رگرسیون OLS و K-Means آسیبپذیرند؛ درختهای تصمیم و روشهای مقاوم، معمولاً پایدارترند.
دانش دامنه چه میگوید؟
آیا محدودیتهای فیزیکی، زیستی، اقتصادی مشخصی برای مقادیر وجود دارد؟ متخصصان حوزه این مقدار را «غیرممکن» میدانند یا فقط «عجیب اما محتمل»؟
پیش از مدیریت Outlier، باید آنها را بهدرستی تشخیص دهیم. مقاله «جعبهابزار تشخیص دادههای پرت قسمت 1و قسمت 2» بخش مربوط به تشخیص را پوشش میدهد.
با این نگاه، مهمترین راهبردهای مدیریت دادههای پرت را میتوان به شکل زیر خلاصه کرد.
1-حذف (Deletion / Trimming)
سادهترین و در عین حال خطرناکترین واکنش، حذف کامل ردیفهای حاوی نقاط پرت است.
زمانی قابل توجیه است که:
- مقدار ثبتشده از نظر فیزیکی/منطقی غیرممکن باشد
(قد منفی، سن ۳۰۰ سال، دمای ۲۰۰۰ درجه در آزمایش معمولی و…)، - یا منشأ خطا تقریباً قطعی باشد
(خرابی تأییدشدهی حسگر، اشتباه تایپی واضح، نمونهگیری از جمعیتی اشتباه).
مزایا
- پیادهسازی و فهم آن بسیار ساده است؛
- تأثیر تحریفکنندهی مقدارِ واقعاً خطادار را صفر میکند؛
- در صورت خطای محض، بقیهی تحلیل را «پاکتر» میکند.
معایب
- اگر نقطهی پرت در واقع واقعی باشد، اطلاعات ارزشمند دربارهی دم توزیع، ریسکهای شدید یا پدیدههای خاص از بین میرود؛
- حجم نمونه کاهش مییابد و قدرت آزمونها کم میشود، مخصوصاً در نمونههای کوچک؛
- اگر پرتها در زیرگروههای خاصی متمرکز باشند، حذف آنها میتواند برآوردها را به طور سیستماتیک سوگیر کند.
مثال واقعی – خطای فیزیکی قطعی
- در دیتاست ارزیابی سلامت، مقدار «قد = 12− سانتیمتر» ثبت شده.
- این مقدار از نظر فیزیکی غیرممکن است و نمیتواند یک مشاهده واقعی باشد.
- در این حالت حذف داده تنها گزینه منطقی است.
مثال واقعی – اشتباه تایپی
- در ثبت دمای آزمایشگاهی، مقدار 2200درجه دیده میشود
- در حالیکه دستگاه فقط تا 200درجه کار میکند.
2. تبدیل داده (Data Transformation)
در این رویکرد، مقیاس متغیر را طوری تغییر میدهیم که اثر نقاط شدید کمتر شود، بدون آنکه خود مشاهدات را حذف کنیم.
کاربرد اصلی:
- متغیرهای با توزیع بسیار چوله (درآمد، زمان پاسخ، شدت آلودگی و…)
- زمانی که مدل فرض نرمال بودن یا همسانی واریانس دارد و ما میخواهیم توزیع را «آرامتر» کنیم
تبدیلهای رایج
- لگاریتمی: log(x) یا log(x + c)
- ریشه دوم : sqrt(x)
- معکوس: 1/x برای نوع خاصی از نرخها
- خانوادههای توانی مثل Box–Cox (برای x>0) و Yeo–Johnson (برای دادههای شامل صفر و منفی)
این تبدیلها دم راست را فشرده میکنند، پراکندگی را کم میکنند و باعث میشوند مدلهای کلاسیک بهتر عمل کنند.
مزایا
- هیچ ردیفی حذف نمیشود؛
- توزیعها اغلب نرمالتر شده و واریانسها پایدارتر میشوند؛
- تأثیر عددی مقادیر بسیار بزرگ (یا بسیار کوچک) محدود میشود.
معایب
- تفسیر ضرایب در مقیاس تبدیلشده سختتر میشود (مثلاً یک واحد افزایش در log(x) یعنی چند برابر شدن x)؛
- برای گزارش نهایی باید نتایج را به مقیاس اصلی برگردانیم؛
- انتخاب تبدیل «مناسب» همیشه واضح نیست، و استفادهی صرفاً ابزاری برای گرفتن p-value کوچک، رویکرد درستی نیست.
مثال – درآمد ماهانه
- در یک دیتاست اقتصادی، توزیع درآمد بسیار چوله است:
۹۰٪ افراد بین ۱۰ تا ۳۰ میلیون درآمد دارند، ولی چند نفر بالای ۳۰۰ میلیون - با تبدیل : y=log (x)
- دامنه فشرده میشود و مدل رگرسیون دیگر توسط چند مقدار بزرگ کشیده نمیشود.
مثال – زمان پاسخ سرور
- زمان پاسخ وبسرویس معمولاً دم راست دارد.
- با تبدیل Box–Cox رفتار الگو پایدارتر میشود.
3. جایگزینی / انتساب (Imputation / Replacement)
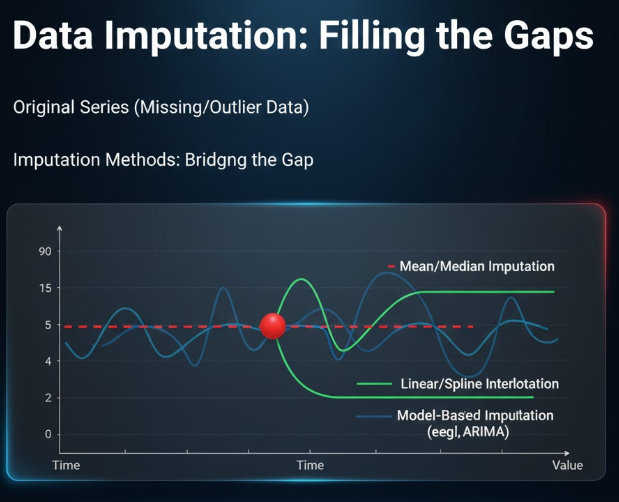
در این روش، مقدار پرت را با یک مقدار تخمینی جایگزین میکنیم و سعی میکنیم ردیف داده را حفظ کنیم.
مناسب زمانی که:
- مقدار پرت به احتمال زیاد خطاست،
- ولی بقیهی متغیرهای آن ردیف برای تحلیل مهماند (مثلاً در مطالعات طولی یا پرسشنامههای پیچیده).
روشهای متداول
- جایگزینی با میانگین/میانه/مد سایر مقادیر معتبر؛
- رگرسیون: پیشبینی مقدار بر اساس سایر متغیرها؛
- KNN: جایگزینی با میانگین/میانهی نزدیکترین همسایگان؛
- انتساب چندگانه (MI) :تولید چند نسخهی ممکن از مقدار جایگزین و ترکیب نتایج تحلیل.
مزایا
- حجم نمونه ثابت میماند؛
- ساختار داده (بهخصوص در مطالعات طولی) حفظ میشود.
معایب
- دادهی واقعی (هرچند شاید خطادار) را با مقداری مصنوعی عوض میکنیم؛
- روشهای ساده واریانس را کم و روابط را تحریف میکنند؛
- روشهای پیشرفتهتر نیازمند فرضیات، محاسبات و پیادهسازی دقیقاند.
مثال – خطای حسگر در سری زمانی
- حسگر دمای خط تولید بهطور لحظهای مقدار 150 درجه ثبت کرده
- در حالیکه بلافاصله قبل و بعد از آن مقادیر 72 و 74 درجه هستند.
این احتمالاً یک خطای خوانش لحظهای است.
4. محدودسازی / وینسورایز کردن (Capping / Winsorization)
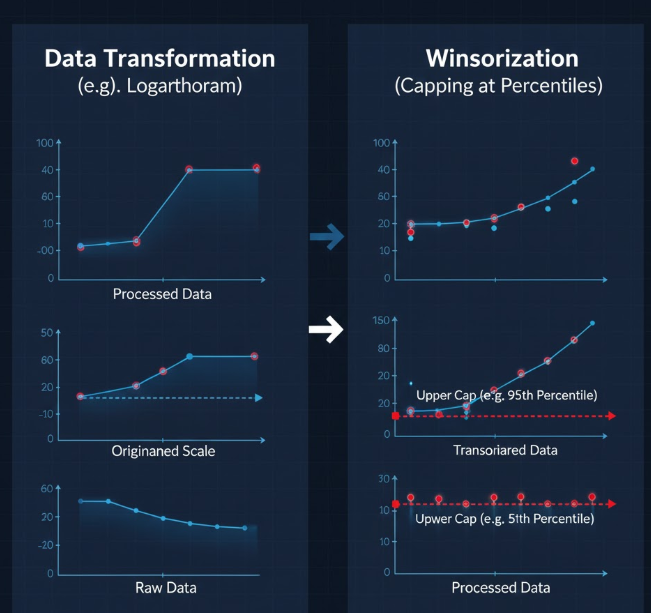
اینجا نه داده را حذف میکنیم و نه کاملاً جایگزین؛ فقط «شدت» آن را محدود میکنیم.
روش کار:
- انتخاب دو صدک (مثلاً ۱ و ۹۹ یا ۵ و ۹۵)
- هر مقداری بالاتر از صدک بالایی، با خودِ آن صدک جایگزین میشود؛
- هر مقداری پایینتر از صدک پایینی، با آن صدک پایین جایگزین میشود.
به این ترتیب نقاط بسیار شدید «به لبهها چسبانده» میشوند.
مزایا
- هیچ ردیفی حذف نمیشود؛
- عملیاتی و ساده است؛
- در حوزه مالی بهطور گسترده برای کنترل اثر بازدههای افراطی استفاده میشود.
معایب
- تغییر مقادیر همچنان خودسرانه است؛
- انتخاب صدکها میتواند نتیجه تحلیل را عوض کند؛
- در مرزها خوشه مصنوعی درست میشود و شکل توزیع دمها تحریف میگردد.
مثال – بازده سهام
- در تحلیل بازده سهام ۲۰ ساله، چند مقدار +180٪ و −90٪ وجود دارد
که مربوط به رویدادهای استثنایی و غیرقابل تکرار هستند.
با وینسورینگ ۱٪:
- مقادیر > صدک ۹۹ → جایگزین با صدک ۹۹
- مقادیر < صدک ۱ → جایگزین با صدک ۱
این کار اثر انفجاری Outlierهای مالی را کنترل میکند
بدون اینکه کل ردیف حذف شود.
برای مشاهده تأثیر حذف یا تغییر Outlier بر آمار و مدلها، مقاله «تأثیر دادههای پرت» مفید است.
5. استفاده از روشهای آماری مقاوم (Robust Methods)
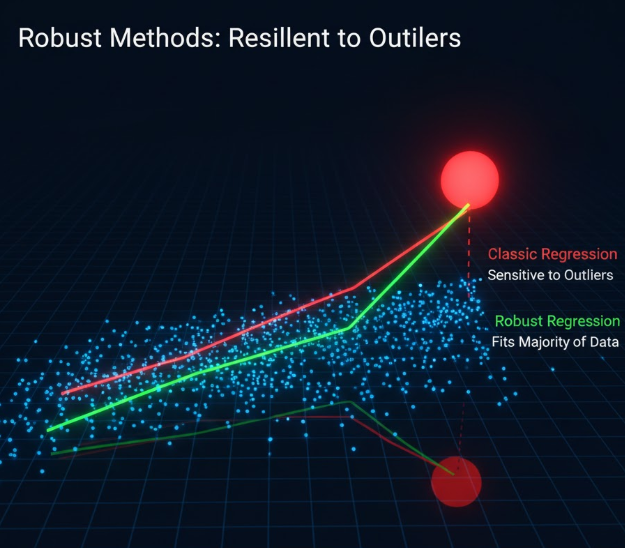
در این رویکرد، بهجای دستکاری دادهها، خودِ روش تحلیل را عوض میکنیم تا ذاتاً نسبت به دادههای پرت حساسیت کمتری داشته باشد.
نمونهها
- استفاده از میانه، IQR و MAD بهجای میانگین و انحراف معیار؛
- همبستگی رتبهای (اسپیرمن، کندال) بهجای پیرسون؛
- رگرسیون مقاوم (M-estimator، LTS، LMS، RANSAC، تیل–سن و …)؛
- برآورد کوواریانس مقاوم (MCD، MVE) و نسخههای مقاوم PCA و LDA؛
- استفاده از مدلهای یادگیری ماشین نسبتاً مقاوم، مثل جنگل تصادفی و گرادیان بوستینگ با تابع زیان مقاوم.
مزایا
- دادهها دستنخورده باقی میمانند؛
- ساختار «اکثریت تمیز» داده بهتر نمایان میشود؛
- کمتر از حذف و وینسور کردن خودسرانه است.
معایب
- پیادهسازی و درک آماری پیچیدهتر است؛
- در دادههای کاملاً منظم و بدون پرت، ممکن است کمی ناکارآمدتر از روشهای کلاسیک باشد؛
- در همهی نرمافزارها به اندازهی روشهای سنتی در دسترس نیست، هرچند در R و Python پوشش خوبی دارد.
مثال – رگرسیون با اثر پرت
- در یک مطالعه روی رابطه قد–وزن، یک فرد با «وزن = 310 کیلوگرم» در داده وجود دارد.
- اگر رگرسیون OLS استفاده شود، خط رگرسیون بهطور مصنوعی بالا میرود.
با استفاده از رگرسیون مقاوم :Huber
- این نقطه وزن کمتر میگیرد
- خط رگرسیون بر اساس اکثریت داده تنظیم میشود
بدون نیاز به حذف داده، مدل پایدار میشود.
مثال – همبستگی مقاوم
- پرتهای مالی باعث میشوند ضریب پیرسون غیرواقعی شود.
- با اسپیرمن، اثر کاهش مییابد.
6 . دستهبندی / گسستهسازی (Binning / Discretization)
اینجا متغیر پیوسته را به چند بازهی دستهای تبدیل میکنیم (مثلاً کم، متوسط، زیاد).
اثر ضمنی:
نقاط بسیار بزرگ و بسیار کوچک در بازههای «انباشتگی» انتهایی قرار میگیرند و اثر عددی دقیق آنها از بین میرود.
مزایا
- ساده و سریع؛
- برای بعضی الگوریتمها (مثل برخی مدلهای مبتنی بر قوانین) مفید است؛
- بهطور خودکار اثر عددی پرتها را کم میکند.
معایب
- اطلاعات زیادی از بین میرود؛
- نتیجه به انتخاب نوع و تعداد بازهها بسیار حساس است؛
- مرزهای مصنوعی ایجاد میکند و میتواند روابط را مخدوش کند.
به همین دلیل، معمولاً فقط وقتی توصیه میشود که خودِ مسئله ماهیت دستهای داشته باشد، نه صرفاً برای فرار از دادههای پرت.
مثال – گروهبندی سطح درآمد
در مدلهایی که ورودی باید «کم/متوسط/زیاد» باشد،
ورودی خام مثلاً:
- ۵ میلیون
- ۲۰ میلیون
- ۱۵۰ میلیون
با سه بازه طبقهبندی میشوند.
در این حالت، مقدار «۱۵۰ میلیون» که Outlier است.در بازه «زیاد» قرار میگیرد و اثر شدیدش.در مدلسازی کم میشود.
7. جداسازی و تحلیل مستقل (Treat as Signal)
وقتی پرتها بهجای «نویز»، نقش سیگنال اصلی را بازی میکنند، بهترین کار این است که آنها را جدا کرده و مستقل تحلیل کنیم؛ نه حذف، نه تبدیل.
این رویکرد در مسائلی مثل تشخیص تقلب، امنیت سایبری، نگهداری پیشگویانه، کشف بیماری، کشف علمی و… رایج است.
روال کلی
- نقاط پرت شناساییشده را برچسب زده و از بقیه داده جدا میکنیم؛
- روی همین نقاط، تحلیل توصیفی و اکتشافی دقیق انجام میدهیم؛
- سعی میکنیم با کمک متخصصان حوزه، سازوکار تولید این ناهنجاریها را بفهمیم؛
- در صورت لزوم، مدل مجزایی برای رفتار «غیرعادی» میسازیم (مثلاً مدل تقلب).
مزایا
- برای حوزههایی مانند تقلب، امنیت، صنعت و پزشکی بسیار مفید است؛
- به فهم رفتارهای نادر و رویدادهای بحرانی کمک میکند؛
- باعث میشود مدل اصلی از دستکاری شدید دادهها آسیب نبیند؛
- این رویکرد اجازه میدهد برای Outlierها مدلها یا تحلیلهای جداگانه طراحی شود.
معایب
- تحلیل مستقل نیازمند زمان، هزینه و پردازش بیشتر است؛
- تشخیص اینکه Outlier «سیگنال» است یا «خطا» به متخصص دامنه نیاز دارد؛
- در دیتاستهای بزرگ، حجم نقاط پرت ممکن است مدیریت این رویکرد را دشوار کند؛
- اگر Outlier واقعاً خطا باشد، تحلیل آن وقت و منابع را هدر میدهد؛
- در صورت تفسیر نادرست، ممکن است به نویز اهمیت بیشازحد داده شود.
مثال – تقلب بانکی
یک مشتری معمولاً تراکنشهای ۵۰–۵۰۰ هزار تومانی دارد.
یکباره تراکنش ۴۵ میلیون انجام میشود.
این داده از نظر آماری Outlier است
اما حذف آن خطای فاجعهبار است.
8. چارچوب تصمیمگیری و توصیههای عملی
برای اینکه انتخاب راهبرد صرفاً سلیقهای نباشد، میتوان این گامها را بهعنوان چکلیست در نظر گرفت:
- اول منشأ را بررسی کن.
تصویربرداری، بررسی متادیتا، رجوع به دفتر آزمایش، پرسیدن از کارشناس سیستم… - اگر تردید داری، اول به روشهای مقاوم فکر کن.
این روشها معمولاً امنترین گزینه زمانیاند که نمیدانیم پرت «نویز» است یا «سیگنال». - حذف را فقط با مدرک روشن انجام بده.
هر حذف را مستند کن و در گزارش نهایی بنویس: چه چیزی، چرا و با چه معیاری حذف شد. - تبدیل را آگاهانه و همراه با توضیح استفاده کن.
نوع تبدیل و دلیل انتخاب آن را مشخص کن و اثر آن را روی تفسیر نتایج توضیح بده. - از انتساب ساده و وینسورینگ کورکورانه محتاط باش.
اگر مجبور به انتساب هستی، روشهای پیشرفتهتر مثل MI را در نظر بگیر و در گزارش روشن بگو چه کردهای. - هدف تحلیل را محور تصمیم قرار بده.
اگر هدف کشف ناهنجاری است، باید پرتها در مرکز توجه باشند، نه حذف. اگر هدف برآورد پارامتر جمعیت است، روشهای مقاوم یا تبدیل مناسبترند. - تحلیل حساسیت انجام بده.
نتایج را در چند سناریو مقایسه کن: با پرتها، بدون پرتها، با روش مقاوم. این مقایسه تصویر روشنی از پایداری نتیجه به دست میدهد. - شفافیت کامل در گزارش.
مهم نیست کدام رویکرد را انتخاب کردهای؛ مهم این است که خواننده دقیقاً بداند چه کردهای و بتواند آن را تکرار کند.
9. حوزههای کاربردی کلیدی تشخیص دادههای پرت
تشخیص ناهنجاری فقط یک ابزار «پیشپردازش» نیست؛ در بسیاری از حوزهها خودِ مسئلهی اصلی است. در ادامه، مهمترین حوزههای کاربردی را مرور میکنیم و برای هر کدام مثال و کاربرد عملی میآوریم.
9.1 خدمات مالی و بیمه
بانکها، شرکتهای بیمه و مؤسسات مالی روزانه با میلیونها تراکنش و درخواست سر و کار دارند. مقدار زیادی از این دادهها کاملاً عادیاند؛ اما چند مورد کوچکِ نادر میتوانند میلیونها دلار خسارت ایجاد کنند.
کاربردهای اصلی
- تشخیص تقلب کارت اعتباری
تراکنشهایی با مبلغ، مکان، نوع فروشنده یا زمان غیرمعمول نسبت به الگوی عادی مشتری علامتگذاری میشوند.
مثلاً کاربری که همیشه خریدهای کوچک داخلی دارد، ناگهان خریدی بزرگ در کشوری دیگر انجام میدهد. - تقلب در بیمه
ادعاهای خسارت با مبلغ غیرمتناسب، فاصلهی زمانی مشکوک بین چند حادثه، یا شبکههای غیرعادی ارتباط بین مدعیان و تعمیرکاران، همگی بهصورت دادههای پرت ظاهر میشوند. - پولشویی و معاملات مشکوک
الگوهای تراکنش زنجیرهای، انتقالهای مکرر بین حسابهای نامرتبط یا حجمهای بسیار بزرگ، بهعنوان ناهنجاری در شبکهی تراکنشها شناسایی میشوند.
مطالعهی موردی کوتاه
یک شرکت کارت اعتباری با ترکیب مدلهای کلاسیک و الگوریتمهایی مانند Isolation Forest و شبکههای عصبی توالیمحور، توانست نرخ کشف تقلب را بالا ببرد و همزمان تعداد هشدارهای کاذب را کاهش دهد. هر تراکنش یک «امتیاز ناهنجاری» میگرفت و تراکنشهای بالای آستانه، برای بررسی انسانی ارسال میشدند.
9.2 امنیت سایبری و شبکه
در امنیت سایبری، دادهی «نرمال» یعنی سیستم سالم؛ دادهی «پرت» یعنی حمله، نفوذ، بدافزار یا رفتار مشکوک.
نمونه کاربردها
- سیستمهای تشخیص نفوذ (IDS)
پایش مداوم ترافیک شبکه برای یافتن حجمهای غیرمعمول، پورتهای غیرمنتظره، الگوهای ارتباطی عجیب یا افزایش ناگهانی ترافیک از یک IP خاص. - تشخیص بدافزار
فایلهایی که از نظر توالی بایت، فراخوانیهای سیستمعامل یا رفتار اجرایی با برنامههای عادی فرق دارند، بهعنوان ناهنجار علامتگذاری میشوند. - تشخیص باتنت
گروهی از کامپیوترها که الگوی ارتباطی هماهنگ و غیرمعمول دارند، بهصورت «پرت جمعی» قابل شناساییاند.
مثال
افزایش ناگهانی و کوتاهمدت حجم ترافیک HTTP به یک سرور، با الگوی تکراری و مشابه درخواستها، میتواند نشانهی حملهی DoS یا اسکن مخرب باشد.
9.3 سیستمهای صنعتی و اینترنت اشیا (IoT)
در صنعت، دادههای پرت اغلب اولین نشانهی خرابی هستند؛ اگر قبل از حادثه شناسایی شوند، هزینهها و خسارتها بهطور چشمگیری کاهش مییابد.
- نگهداری پیشبینانه (Preventive / Predictive Maintenance)
نظارت بر لرزش، دما، فشار و جریان الکتریکی موتورها و توربینها برای تشخیص الگوهای غیرعادی قبل از شکست قطعه. - کنترل کیفیت تولید
محصولاتی که ویژگیهایشان (وزن، ابعاد، رنگ، سختی…) خارج از محدودهی معمول است، بهعنوان نقص تولیدی شناسایی میشوند. - شبکههای انرژی و زیرساخت
قرائتهای غیرعادی در مصرف برق، ولتاژ یا جریان میتواند نشاندهندهی خرابی، بیثباتی شبکه یا حتی سرقت انرژی باشد.
مطالعهی موردی کوتاه
در یک خط تولید، حسگرهای لرزش روی یاتاقانها نصب شد. مدلهای تشخیص ناهنجاری سری زمانی، تغییرات ظریف اما سیستماتیک را چند روز قبل از خرابی کامل شناسایی کردند؛ زمان تعمیرات برنامهریزی شد و توقف ناگهانی خط تولید به حداقل رسید.
9.4 مراقبتهای بهداشتی، پزشکی و بیوانفورماتیک
در پزشکی، یک نقطهی پرت میتواند تفاوت بین «حال خوب» و «وضعیت بحرانی» باشد.
کاربردهای رایج
- تحلیل سیگنالهای فیزیولوژیک (ECG، EEG، PPG و …)
ریتمهای غیرطبیعی قلب، امواج مغزی غیرعادی یا تغییرات ناگهانی در علائم حیاتی معمولاً به شکل ناهنجاریهای زمانی ظاهر میشوند. - تصویربرداری پزشکی
لکهها، ضایعات یا ساختارهای غیرمعمول در MRI، CT یا ماموگرافی، در واقع نقاط پرت در فضای تصویر هستند. Autoencoderها و GANها برای کشف این ناهنجاریها بسیار محبوباند. - کارآزماییهای بالینی
پاسخهای بسیار شدید یا غیرمنتظره به دارو، یا الگوهای غیرعادی در دادههای بیماران، میتواند نشانهی عارضهی مهم، خطای اندازهگیری یا حتی تقلب در گزارش داده باشد.
نمونه
یک سیستم نظارت در ICU با پایش پیوستهی ضربان قلب، فشار خون و اکسیژن خون، هر زمان الگوی مقادیر از «الگوی عادی» بیمار فاصلهی زیادی میگیرد، هشدار میدهد. بسیاری از این هشدارها قبل از آن است که تغییرات برای کادر درمان با چشم کاملاً قابل مشاهده باشد.
9.5 محیط زیست و علوم زمین
بخش زیادی از پایش محیطزیست در عمل یعنی «گشتن دنبال ناهنجاری».
- رویدادهای شدید آب و هوایی
موجهای گرما، بارشهای سیلآسا یا بادهای فوقالعاده شدید، همه نقاط پرت در سریهای زمانی دما، بارش و سرعت باد هستند. - نظارت بر آلودگی
جهش ناگهانی در غلظت یک آلاینده میتواند نشانهی نشت صنعتی یا تخلیهی غیرقانونی باشد. - لرزهشناسی و آتشفشانشناسی
سیگنالهای لرزهای غیرمعمول در میان نویز پسزمینه، نقطهی شروع تشخیص زمینلرزه، فعالیت آتشفشان یا حتی انفجارهای ساخت بشر است.
مطالعهی موردی کوتاه
یک شبکهی حسگر کیفیت هوا افزایش تند و کوتاهمدتی در یک آلایندهی خاص را ثبت کرد. تحلیل ناهنجاری نشان داد این تغییر تصادفی نیست. بررسی میدانی بعدی، نشت در یک کارخانهی نزدیک را آشکار کرد و از خسارات بیشتر جلوگیری شد.
9.6 تجارت الکترونیک، بازاریابی و شبکههای اجتماعی
در دنیای آنلاین، رفتار کاربران بهطور مداوم ثبت میشود و ناهنجاریها میتوانند هم فرصت باشند و هم تهدید.
- تحلیل رفتار کاربر
کاربرانی که الگوی خرید، کلیک یا مصرف محتوای آنها کاملاً با بقیه متفاوت است، ممکن است مشتریان بسیار ارزشمند، کاربران در آستانهی ریزش یا حسابهای متقلب باشند. - سیستمهای توصیهگر
رتبهبندیهای غیرعادی میتوانند نشانهی «حملهی شیلینگ» (تلاش عمدی برای دستکاری امتیاز یک محصول) باشند. - تحلیل شبکههای اجتماعی
حسابهای رباتی، شبکههای انتشار شایعات یا اطلاعات نادرست، و شکلگیری ناگهانی خوشههای بستهی ارتباطی، همه در قالب ناهنجاریهای ساختاری در گراف اجتماعی دیده میشوند.
مثال
افزایش ناگهانی حجم توییتها با یک هشتگ خاص، خارج از الگوی معمول، میتواند نشانهی بروز بحران، کمپین رسانهای بزرگ یا موج شایعات باشد.
9.7 تحقیقات علمی و کشف پدیدههای جدید
در بسیاری از شاخههای علم، «پیشرفت» دقیقاً از همان نقاطی میآید که با مدلهای فعلی نمیخوانند.
- در فیزیک ذرات، رویدادهایی که با پیشبینی مدل استاندارد همخوانی ندارند؛
- در اخترشناسی، منحنیهای نوری غیرمعمول که به کشف ابرنواختر یا پدیدههای گذرای جدید منتهی میشوند؛
- در ژنومیک، الگوهای بیان ژنی غیرعادی که به کشف ژنهای درگیر در بیماریها کمک میکنند.
در همهی این موارد، اگر نقاط پرت را بهطور اتوماتیک «تمیز» کنیم و کنار بگذاریم، احتمالاً بخشی از علم را هم با آنها پاک کردهایم.
9.8 پاکسازی و پیشپردازش عمومی دادهها
حتی در سادهترین تحلیلهای کسبوکار و پژوهش، تشخیص دادههای پرت یک مرحلهی استاندارد است:
- حذف مقادیر غیرمنطقی (سن منفی، قد ۵ متر، فروش منفی و…)؛
- شناسایی رکوردهای ناقص یا متناقض که اغلب بهصورت ناهنجاری ظاهر میشوند؛
- بهبود کلی کیفیت داده قبل از ساخت مدلهای یادگیری ماشین.
یک تیم تحلیل، قبل از ساخت مدل پیشبینی رفتار مشتری، با استفاده از روشهای تشخیص دادهی پرت، رکوردهای عجیب (ترکیب ناممکن ویژگیها، مقادیر خارج از محدوده، ناسازگاری بین فیلدها) را پیدا و اصلاح یا حذف میکند؛ نتیجه، معمولاً جهش محسوسی در دقت مدل است.
10. جمعبندی کاربردی
هیچ راهبرد یکسانی برای مدیریت دادههای پرت وجود ندارد. حذف، اصلاح، مدلسازی، استفاده از روشهای مقاوم یا حتی نگهداشتن هدفمند Outlierها، همگی میتوانند در موقعیت مناسب بهترین انتخاب باشند.
کلید کار این است که:
- ماهیت داده پرت را بشناسیم
- هدف تحلیل را مشخص کنیم
- حساسیت مدلها به Outlier را درک کنیم
- و دانش دامنه را جدی بگیریم
با چنین رویکردی، تصمیمگیری درباره دادههای پرت نهتنها دقیقتر میشود، بلکه باعث بهبود کیفیت تحلیل و افزایش اعتمادپذیری مدلهای یادگیری ماشین خواهد شد.