

1 . مقدمه و مفاهیم پایه
1.1مقدمه
در بسیاری از سیستمها، دادههای مربوط به یک موجودیت واحد اغلب نسخههای متفاوت، ناقص یا حتی متناقضی از همان واقعیت را نشان میدهند.
مثلاً یک مشتری ممکن است در سیستم بانکی با نام کامل ثبت شده باشد، در سیستم رابطه با مشتری (CRM) با نام مخفف، در سیستم پیامکی فقط با شماره تلفنش شناسایی شود و در سوابق خرید، آدرسی متفاوت داشته باشد. این پراکندگی و ناسازگاری باعث میشود هیچ منبع واحدی نتواند تصویری کامل و دقیق از آن مشتری ارائه دهد.
ادغام دادهها (Data Fusion) راهحلی مؤثر برای این چالش است. این فرآیند با ترکیب دادههای چند منبع متفاوت، تضادها را شناسایی و برطرف میکند، دادههای ناقص را تکمیل میکند و در نهایت، یک نمای یکپارچه، دقیق و قابل اعتماد از موجودیت موردنظر تولید میکند.
ادغام دادهها نقشی کلیدی در تحلیلهای پیشرفته، سیستمهای هوش مصنوعی، تصمیمگیریهای سازمانی و کاربردهای حیاتی—مانند پزشکی، امنیت و دفاع، بانکداری و خودروهای خودران— ایفا میکند.
Data Fusion آخرین و مهمترین مرحله در زنجیره یکپارچهسازی دادهها است. اگر Integration وظیفه جمعآوری دادهها را داشته باشد، Fusion وظیفه دارد “حقیقت واحد” را تولید کند.
1.2تعریف Data Fusion
Data Fusion فرآیند ترکیب دادههایی است که از چند منبع مختلف جمعآوری شدهاند، با هدف تولید یک رکورد یا نتیجه نهایی دقیقتر، کاملتر و بدون تناقض.
هر منبع داده فقط بخشی از واقعیت را منعکس میکند؛ اما هنگامی که سیستم دادههای چندمنبعی را ترکیب میکند، میتواند تصمیماتی هوشمندانهتر، دقیقتر و قابل اتکاتر اتخاذ کند. این ادغام به مدلها و سیستمها کمک میکند تا یک تصویر یکپارچه، جامع و وفادار به واقعیت از موجودیتها یا رویدادها بسازند.
به زبان ساده:اگر دربارهی یک مشتری یا یک حسگر، چندین رکورد مختلف وجود داشته باشد، Data Fusion تعیین میکند:
- کدام مقدار صحیحتر است؟
- کدام داده ناقص باید تکمیل شود؟
- کدام مقدار باید حذف، اصلاح یا ترکیب شود؟
- و در نهایت “حقیقت واحد” چیست؟
هدف اصلی Data Fusion تولید یک Truth واحد و قابل اعتماد است.
1.3مفاهیم پایه مورد نیاز در Fusion
برای درک درست فرآیند ادغام دادهها، شناخت چند مفهوم کلیدی ضروری است. این مفاهیم نحوهی عملکرد سیستمهای Fusion را روشن میکنند.
Object (شیء)
موجودیت واقعی که دادهها درباره آن جمعآوری میشوند، مانند:مشتری، کالا، تراکنش بانکی، بیمار، دستگاه IoT، خودرو، حسگر و…
Attributes (ویژگیها)
ویژگیهای توصیفی مربوط به شیء که معمولاً در رکوردها ذخیره میشوند، مانند:نام، سن، شهر، آدرس، زمان ثبت، مقدار اندازهگیریشده، وضعیت، موقعیت مکانی.
Sources (منابع)
منابعی که اطلاعات یا اندازهگیریها را تولید میکنند، مانند:
- سیستمهای CRM
- حسگرهای سختافزاری (GPS، دوربین، لیدار، رادار و…)
- سرویسهای آنلاین
- اپلیکیشنها و دستگاههای شخصی
- هر منبع کیفیت، زمان ثبت و میزان اعتماد متفاوتی دارد.
Conflicts (تضادها)
زمانی رخ میدهد که چند منبع مقدارهای متفاوتی برای یک ویژگی ثبت کنند:
City = Berlin / London
Age = 30 / 31
Evidence (شواهد)
هر مقداری همراه با شواهدی است مثل:
- کیفیت منبع
- زمان ثبت
این شواهد کمک میکند Data Fusion بهترین مقدار را انتخاب کند.
Truth (حقیقت)
نتیجهای که پس از ادغام تضادها، حذف نویز، اصلاح خطاها و ترکیب دادهها تولید میشود.
Truth مقدار واحد، کامل و بدون تناقضی است که سیستم بر اساس آن تصمیم میگیرد.
1.4تفاوت Data Fusion و Data Integration
بسیاری این دو را اشتباه میگیرند، اما تفاوت عمیق دارند:
| ویژگی | Data Integration | Data Fusion |
|---|---|---|
| هدف | جمعآوری و یکپارچهسازی منابع | تولید حقیقت واحد |
| تمرکز | ساختارها، فرمتها، اتصال منابع | مقادیر و رفع تناقض |
| خروجی | مجموعه داده یکپارچه | رکورد نهایی، تمیز و سازگار |
| مرحله | مرحله میانی | مرحله نهایی |
| پرسش | دادهها را از کجا بیاوریم؟ | کدام مقدار صحیح است؟ |
- Integration زیرساخت است.
- Fusion مغز تصمیمگیرنده است.
2 . اهداف و ضرورت Data Fusion
این بخش به صورت مستقل بیان میکند Fusion چه مشکلی را حل میکند و چرا لازم است.
ضرورت Data Fusion
۱. کاهش پراکندگی اطلاعات: دادهها در سازمانها در دهها سیستم مختلف ذخیره میشوند Fusion. این پراکندگی را تبدیل به یک خروجی یکپارچه میکند.
۲. حل تناقضها و اختلاف مقادیر :سیستمهای مختلف مقادیر مختلفی ثبت میکنند Fusion. نسخه نهایی را تعیین میکند.
۳. تولید رکورد واحد (Golden Record) :در سیستمهای بانکی و پزشکی، وجود یک رکورد واحد حیاتی است. Golden Record قلب Fusion است.
۴. تکمیل دادههای ناقص : اگر هر منبع بخشی از واقعیت را بداند، Fusion مجموع آنها را میسازد.
۵. افزایش اعتماد به تحلیل و تصمیمگیری Fusion : خطاهای انسانی و سیستمی را به حداقل میرساند.
اهداف اصلی Data Fusion
۱. کاملسازی (Completeness) : ترکیب ویژگیهای چند منبع برای تشکیل یک رکورد غنی.
مثال:
A: نام + شهر
B :سن + شغل
C :وضعیت + درآمد
رکورد نهایی = همه این ویژگیها
۲. کاهش تکرار (Conciseness) : بهجای ۵ رکورد مشابه، فقط یک رکورد واحد داشته باشیم.
۳. سازگاری (Consistency) :رفع اختلاف مقادیر.اگر سه مقدار مختلف برای یک ویژگی وجود دارد، Fusion مقدار درست را انتخاب یا محاسبه میکند.
۴. افزایش صحت Fusion : (Accuracy)با روشهای آماری، احتمالاتی و الگوریتمی، مقدار دقیقتر را پیدا میکند.
۵. ایجاد Single Source of Truth (SSOT) :تمام سیستمها بعد از Fusion به یک حقیقت واحد متصل میشوند.
مثال کامل برای فهم اهداف Fusion
سه سیستم اطلاعات زیر را میدهند:
| وضعیت | شهر | سن | منبع |
|---|---|---|---|
| Good | Berlin | 30 | A |
| NULL | London | 31 | B |
| Very Good | NULL | 30 | C |
Fusion چه میکند؟
- سن = 30
(چون دو منبع همنظرند) - شهر: London =یا Berlin
بسته به: وزن منبع، زمان ثبت، الگوریتم - وضعیت = ترکیب Good و Very Good
مثلاً انتخاب بهترین مقدار
بدون Fusion، تحلیل و تصمیمگیری دچار خطا میشود.
3 . انواع تضاد و ناسازگاری در دادهها
در بیشتر پروژههای دادهمحور، منابع مختلف اطلاعات را به شکل متفاوت ثبت میکنند.یک بیمار ممکن است در بیمارستان A با کد ملی ثبت شود، در بیمارستان B با شماره پرونده، و در آزمایشگاه با نام ناقص.این تفاوتها باعث ایجاد تضادهای ساختاری، رکوردی و مقداری میشود.درک و طبقهبندی این تضادها اولین قدم برای Fusion موفق است.اگر ندانیم تضاد از کدام نوع است، انتخاب تابع Fusion صحیح غیرممکن است.
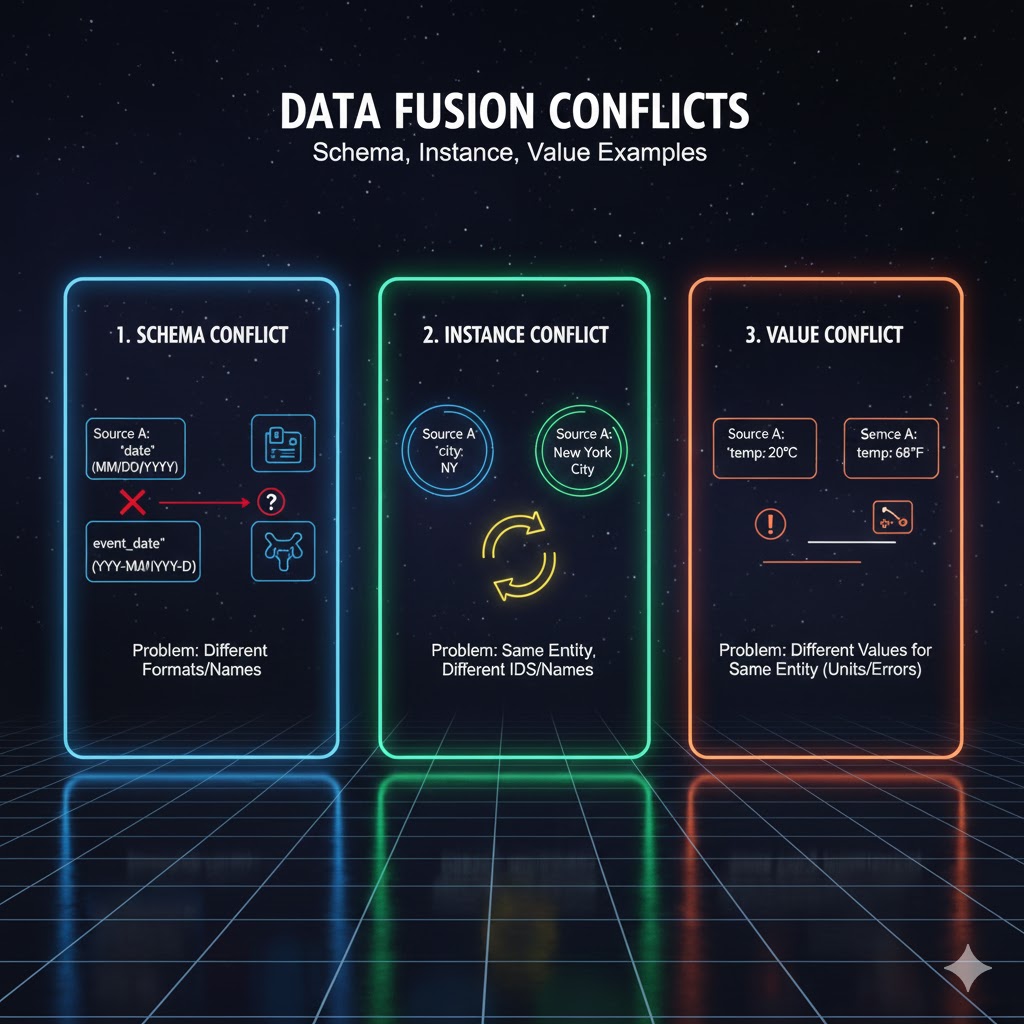
3.1 تضادهای سطح الگو (Schema-Level Conflicts)
این تضادها مربوط به ساختار، نامگذاری و نوع دادهها است. انواع تضادهای: Schema
A.اختلاف نام (Naming Conflicts)
- CustID ↔ Customer_Identifier
- BirthCity ↔ PlaceOfBirth
B.اختلاف نوع داده (Data Type Conflicts)
- سن در یک منبع عددی، در منبع دیگر متنی
- تاریخ : YYYY/MM/DD ↔ DD-MM-YYYY
C.اختلاف واحد اندازهگیری
- فاصله: متر ↔ کیلومتر
- وزن: پوند ↔ کیلوگرم
D.اختلاف ساختار داده (Structural Conflicts)
- آدرس بهصورت یک فیلد
- آدرس بهصورت سه فیلد (شهر، خیابان، پلاک)
مثال واقعی:
سیستم A : Age: “30”
سیستمB : Age: “Thirty”
قبل از Fusion باید تبدیل (Transformation) انجام شود.
3.2. تضادهای سطح رکورد (Instance-Level Conflicts)
این تضادها زمانی رخ میدهد که رکوردهای مشابه وجود دارند، اما الزاماً یک فرد نیستند.
A.نمایش متفاوت یک موجودیت واحد
- “Ali Ahmadi”
- “Ahmadi, A.”
- “A. Ahmadi”
B.شبهتکراریها (Pseudo-Duplicates)
رکوردهایی که شبیهاند اما یکسان نیستند.
مثال:
- Paul Smith از Berlin
- Paul Smith از London
آیا یک نفر هستند؟
Fusion باید قبل از ترکیب، این موضوع را مشخص کند (Entity Resolution).
C.مشکلات چند هویتی (Multiple Identities)
مثلاً یک بیمار در سیستمهای مختلف با شناسههای مختلف ثبت شده.
3.3. تضادهای سطح مقدار (Value Conflicts)
این تضادها مربوط به اختلاف مقادیر یک ویژگی هستند.
A.تضاد قوی (Strong Conflict)
مقادیر کاملاً متفاوت:
City = Berlin
City = London
B.تضاد ضعیف (Weak Conflict)
مقادیر نزدیک به هم یا قابل ادغام:
Weight = 70kg / 71kg
Temperature = 36.9 / 37.1
C.اختلاف دادههای زمانی (Temporal Conflicts)
- آدرس ماه قبل: تهران
- آدرس جدید: آنکارا
در این موارد زمان ثبت تعیینکننده است.
D.اختلاف دقت اندازهگیری
- سنسور اول: 20.45درجه سانتی گراد
- سنسور دوم: 20درجه سانتی گراد
Fusion باید تصمیم بگیرد کدام معتبرتر است.
3.4. دادههای ناقص، زائد و متناقض
A.دادههای ناقص (Missing Data)
مثلاً وضعیت شغلی مشتری در یک منبع ثبت نشده.
B.دادههای زائد (Redundant Data)
وجود ۳ نسخه تکراری از یک رکورد با اختلافهای جزئی.
C.دادههای متناقض (Conflicting Data)
مثلاً سن در یک منبع ۲۹ و در منبع دیگر ۳۳ است.
Fusion باید برای این سه نوع داده تصمیم بگیرد:
- حذف کند؟
- انتخاب کند؟
- ترکیب کند؟
- یا مقدار جدید بسازد؟
مثالهای عملی تضادها
مثال: مشتری بانکی
| وضعیت | شهر | سن | منبع |
|---|---|---|---|
| Good | Berlin | 30 | A |
| Very Good | London | 31 | B |
| Good | NULL | 30 | C |
تضادهای موجود:
- سن: 30 ↔ 31
- شهر Berlin ↔ London:
- وضعیت : Good ↔ Very Good
- : Missing شهر در منبع C
۴. طبقهبندی منابع دادهها
وقتی صحبت از Data Fusion میشود، محققان برای درک بهتر ماهیت عملیات، دستهبندیهای مختلفی را تعریف میکنند. این طبقهبندیها به ما کمک میکنند بدانیم چه چیزی در حال ادغام شدن است و چگونه باید آن را مدیریت کرد.
الف) طبقهبندی بر اساس سطح انتزاع (Abstraction Level)
این رایجترین طبقهبندی است و به نوع دادههایی اشاره دارد که در حال ترکیب شدن هستند:
- ادغام سطح پایین (Low-Level Fusion):
- تمرکز: ادغام دادههای خام (Raw Data) یا سیگنالها مستقیماً از حسگرها.
- مثال: ترکیب دادههای شدت سیگنال از دو رادار مختلف که یک هدف را رصد میکنند، قبل از استخراج هر گونه ویژگی.
- مزیت: در این سطح، بیشترین مقدار اطلاعات حفظ میشود که منجر به دقت بالاتر میشود.
- ادغام سطح میانی (Medium-Level Fusion) :
- تمرکز: ادغام ویژگیها (Features) یا خصایص استخراج شده از دادههای خام.
- مثال: ترکیب ویژگیهایی مانند ابعاد هدف، شکل موج، یا سرعت هدف که از دادههای خام استخراج شدهاند.
- مزیت: کاهش شدید حجم داده و پیچیدگی پردازش در مقایسه با سطح پایین.
- ادغام سطح بالا (High-Level Fusion) :
- تمرکز: ادغام تصمیمات (Decisions)، نتایج شناسایی یا نمادهای معنایی. (Symbolic Data)
- مثال: ترکیب نتایج نهایی دو سیستم شناسایی (مثلاً یکی هدف را “هواپیما” و دیگری “هلیکوپتر” تشخیص داده است) برای رسیدن به یک تصمیم نهایی.
- مزیت: کمترین پهنای باند و بیشترین تحمل خطا (به دلیل کم بودن حجم دادههای مبادله شده).
ب) طبقهبندی بر اساس رابطه منابع ورودی
Data Fusion به دلایل مختلفی انجام میشود که بر اساس ارتباط بین منابع تعریف میشوند:
- دادههای مکمل (Complementary): زمانی که منابع مختلف، جنبههای متفاوتی از هدف یا محیط را پوشش میدهند. (مثال: حسگرهای مختلفی که هر کدام یک زاویه دید متفاوت دارند).
- دادههای زائد(Redundant) :زمانی که چندین منبع، اطلاعات مشابهی را گزارش میکنند. این زائد بودن برای افزایش قابلیت اطمینان و کاهش عدم قطعیت حیاتی است. (مثال: دو حسگر دقیقاً یک هدف را در یک زمان رصد میکنند).
- دادههای همکارانه (Cooperative): زمانی که دو منبع، برای تکمیل عملیات یکدیگر نیاز به تبادل اطلاعات دارند. (مثال: یک حسگر اطلاعات مربوط به موقعیت را به حسگر دیگر میدهد تا بهتر جستجو کند).
5 .معماری منابع داده ها
سازماندهی نحوه ارتباط حسگرها و پردازندههای ادغام در یک سیستم، موضوع معماری Data Fusion است. سه مدل اصلی برای این کار وجود دارد:
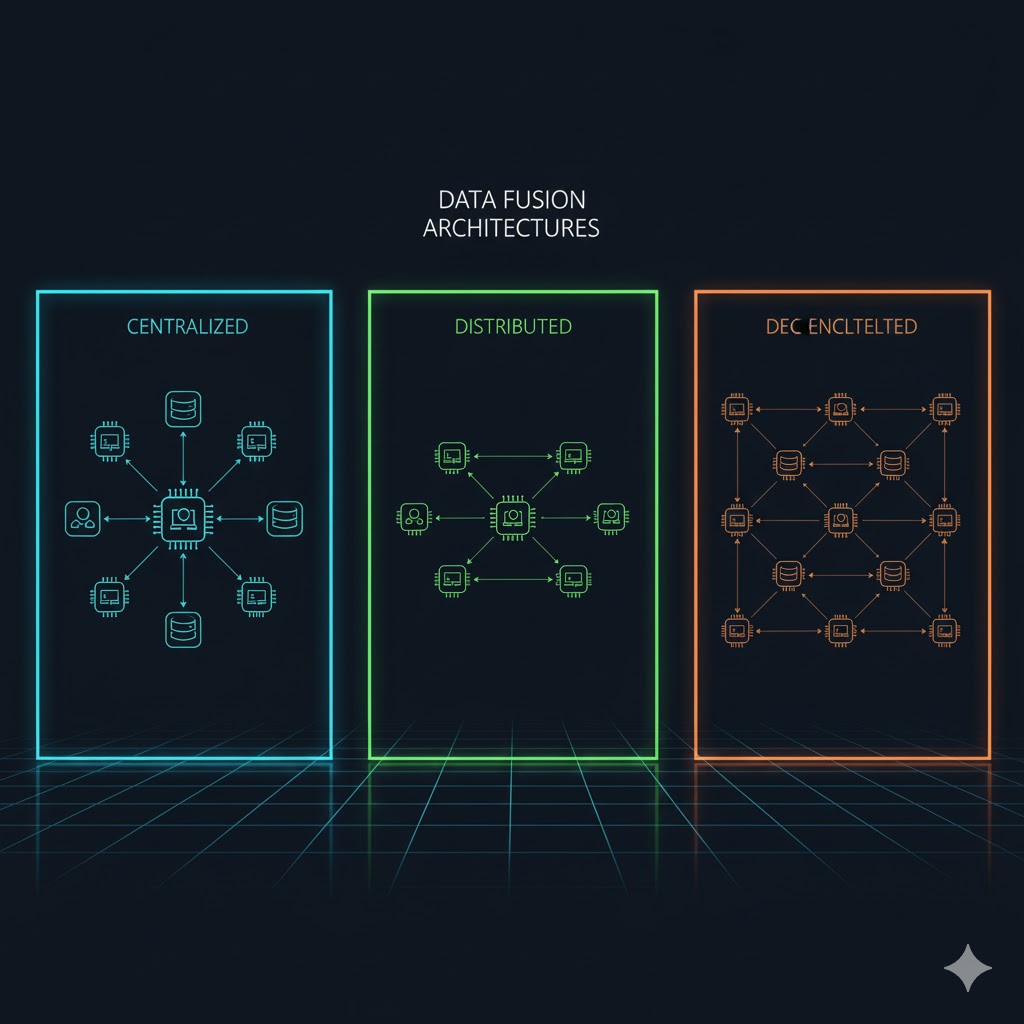
الف) معماری متمرکز (Centralized Architecture)
- نحوه کار: تمام دادههای خام (Raw Data) از تمامی حسگرها مستقیماً به یک پردازشگر مرکزی (Central Processor) ارسال میشود.
- مزیت اصلی: این معماری از لحاظ نظری بهینهترین نتایج را ارائه میدهد، زیرا تمام اطلاعات در یک مکان برای تحلیل در دسترس است و میتوان ساختارهای همبستگی (Correlation) را در نظر گرفت.
- چالش: این مدل نیازمند پهنای باند بسیار بالا برای انتقال انبوه دادههای خام و منابع محاسباتی فوقالعاده قوی در پردازشگر مرکزی است. اگر گره مرکزی از کار بیفتد، کل سیستم مختل میشود (Single Point of Failure).
ب) معماری توزیع شده (Distributed Architecture)
- نحوه کار: هر گره حسگر اندازهگیریهای خود را بهصورت محلی و مستقل پردازش میکند. سپس بهجای ارسال داده خام، تخمینهای حالت (مانند موقعیت و سرعت) را به گره ادغام مرکزی ارسال مینماید.
- مزیت اصلی: این روش پهنای باند ارتباطی را بهطور چشمگیری کاهش میدهد و مقاومت سیستم را در برابر خرابی یک یا چند گره افزایش میدهد.
- چالش: چون تنها تخمینهای حالت منتقل میشوند، داده خام از دست میرود. در نتیجه، الگوریتمهای ادغام باید با همبستگیهای پنهان یا ناشناخته میان تخمینها سروکار داشته باشند — عاملی که معمولاً منجر به کاهش جزئی در بهینگی کلی سیستم میشود.
ج) معماری غیرمتمرکز (Decentralized Architecture)
- نحوه کار: این مدل ترکیبی است. مجموعهای از گرهها وجود دارند که هم قابلیت پردازش محلی دارند و هم میتوانند با گرههای دیگر اطلاعات تبادل کنند. هیچ پردازشگر مرکزی واحدی وجود ندارد، اما گرهها میتوانند به صورت محلی Data Fusion را انجام دهند.
- کاربرد: این مدل در شبکههای پیچیده با قابلیت خودترمیمی (Self-healing) و تحمل خطای بالا استفاده میشود.
6 . توابع و تکنیکهای ادغام دادهها
پس از شناسایی منابع، تشخیص رکوردهای تکراری و تعیین اینکه رکوردها متعلق به یک موجودیت واحد هستند، Fusion باید تصمیم بگیرد:
- کدام مقدار صحیحتر است؟
- کدام ویژگی از کدام منبع انتخاب شود؟
- آیا باید مقادیر با هم ترکیب شوند؟
- اگر مقادیر متعدد وجود دارد، کدام منبع قابل اعتمادتر است؟
این تصمیمها توسط توابع Fusion گرفته میشوند.
6.1 توابع تجمیعی (Aggregation Functions)
این توابع زمانی استفاده میشوند که هدف، ترکیب چند مقدار به یک مقدار نهایی باشد.
Min.A (کمینه)
انتخاب کوچکترین مقدار.
مناسب برای دادههای فیزیکی مانند دما، سرعت باد، سیگنال.
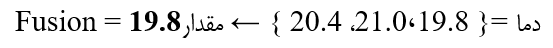
Max.B (بیشینه)
مناسب سناریوهای امنیتی و ریسک.
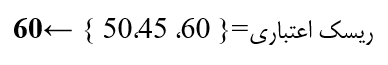
Mean.C(میانگین)
پرتکرارترین تابع در سناریوهای حسگری و دادههای پیوسته.
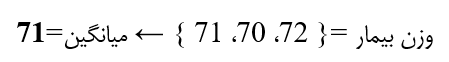
Median.D(میانه)
برای دادههایی که Outlier دارند بهتر از میانگین است.
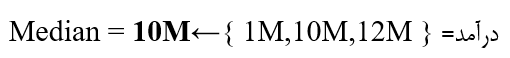
6.2 متدهای رأیگیری (Voting Methods)
این توابع زمانی استفاده میشوند که منابع مختلف یک مقدار گسسته بدهند.
Majority Voting.A
رایجترین روش.
مثال:

Weighted Voting.B
وقتی کیفیت منابع متفاوت است.
مثال:
وزن منبع A = 0.7
وزن منبع B = 0.3
: City
- A → Berlin
- B → London
خروجی =Berlin
6.3 مدل اعتماد به منبع (Source Confidence Models)
هر منبع یک وزن اعتماد دارد.وزنها معمولاً براساس موارد زیر تعیین میشوند:
- سابقه کیفیت
- نرخ خطای گذشته
- زمان ثبت
- نوع سیستم (سیستم هستهای همیشه وزن بیشتر دارد)
وقتی مقادیر متناقض باشند، مقدار منبع با وزن بیشتر انتخاب میشود.
مثال:

6.4 مبتنی بر شواهد (Evidential Fusion) Fusion
این روش برای زمانی است که هیچ منبعی قطعیت کامل ندارد.براساس درجهای از «باور» و «احتمال» تصمیمگیری میکند.
روشهای مشهور:
- Dempster–Shafer Theory
- Evidence Combination Rules
کاربرد:
- پزشکی
- سیستمهای چندسنسوری
- دفاع و امنیت
مثال ساده:
دو حسگر در مورد وجود یک شیء نظر میدهند:
- حسگر ۱: احتمال وجود شیء = 0.7
- حسگر ۲: احتمال وجود شیء = 0.6
← Fusion احتمال ترکیبی 0.82≈
6.5 احتمالاتی Fusion (Probabilistic Fusion)
این روش، احتمال صحیح بودن هر مقدار را محاسبه میکند.
Bayesian Fusion.A
با استفاده از اطلاعات قبلی (Prior) و مشاهدات جدید (Evidence) تصمیم میگیرد.
مثال:
یک مشتری معمولاً در تهران ساکن است.اما در سفر اخیر تراکنشها از وان (Van) ثبت شدهاند.
Bayesian Fusion تشخیص میدهد:
اقامتگاه = تهران
موقعیت لحظهای = وان
Gaussian Models.B
برای Fusion دادههای حسگری دقیق.
6.6 توابع مدیریت تضادها (Conflict Handling Functions)
وقتی چند مقدار موجود باشد، این توابع تعیین میکنند چگونه تضاد برطرف شود.
COALESCE.A
اولین مقدار غیر. Null
مثال:
Status = { NULL, NULL, “Active” }→ Active
Keep Up To Date.B
انتخاب مقدار جدیدتر با استفاده از. Timestamp
مثال:
City(2023) = Berlin
City(2024) = London
→ London
Trust Your Friends.C
انتخاب مقدار منبع ترجیحی.
مثال:اعتماد بیشتر = سیستم هسته بانک← مقدار سیستم بانک انتخاب میشود.
انتخاب تابع Fusion مناسب
انتخاب تابع به موارد زیر وابسته است:
| بهترین روش | نوع داده |
|---|---|
| Majority / Weighted Voting | گسسته |
| Mean / Median / Gaussian | پیوسته |
| Kalman / Particle + Aggregation | دادههای چندسنسوری |
| Conflict Resolution Functions | دادههای متناقض |
| Evidential Fusion / Bayesian | دادههای بدون قطعیت |
7 . کاربردهای Fusion
Data Fusion ستون فقرات بسیاری از سیستمهای پیشرفته هوش مصنوعی، سامانههای حسگری و تحلیلهای سازمانی است. با ترکیب اطلاعات پراکنده از چند منبع، یک تصویر کامل، دقیق و قابل اتکا از محیط یا موجودیت موردنظر ایجاد میشود. در ادامه مهمترین کاربردهای Fusion در صنایع مختلف را بررسی میکنیم.
تشخیصهای پزشکی و سلامت (Healthcare Diagnostics)
ادغام دادههای چندوجهی
- اطلاعات پزشکی از منابع مختلف مانند پرونده الکترونیک بیمار، گزارش پزشک، نتایج آزمایش، سیتیاسکن، MRI و دادههای پوشیدنیها با کمک Fusion در یک نمای واحد ترکیب میشوند.
تحلیلهای پیشبینانه
- با ترکیب این دادهها، مدلهای ML قادر به تشخیص زودهنگام بیماریها، پیشبینی خطرات آینده و ارائه درمانهای شخصیسازی شده میشوند.
وسایل نقلیه خودران (Autonomous Vehicles)

Sensor Fusion (ادغام حسگرها)
- خودروهای خودران دادهها را از حسگرهای مختلف مانند GPS، دوربینها، لیدار، رادار و اولتراسونیک ترکیب میکنند.
ناوبری دقیق و آگاهی محیطی
- Fusion باعث میشود خودرو محیط خود را دقیقتر درک کند، موانع را بهتر تشخیص دهد و در شرایط پیچیده تصمیمهای امنتری بگیرد.
بخش مالی (Financial Sector)
ارزیابی ریسک و تحلیل بازار
- Fusionبا ترکیب دادههای بازار، شاخصهای اقتصادی، دادههای معاملاتی، رفتار مشتری و اخبار مالی، دید جامعی ایجاد میکند.
تصمیمگیری سرمایهگذاری
- سیستمهای Fusion میتوانند روندهای پنهان بازار را آشکار کرده و مدلهایی با دقت بالاتر برای توصیههای سرمایهگذاری ارائه دهند.
اینترنت اشیا و سیستمهای حسگری (IoT & Sensor Networks)
در سیستمهای هوشمند، داده حسگرها معمولاً ناقص، noisy یا متناقض است.
Fusion باعث میشود:
- خطای اندازهگیری کاهش یابد
- سیگنالها صاف و پایدار شوند
- دادههای حسگری دقیقتر و قابل اعتمادتر شود
مثال: خانه هوشمند، شهر هوشمند، شبکه برق.
دفاع، امنیت و هوافضا (Defense & Aerospace)
سیستمهای دفاعی دادههای چند منبع را ترکیب میکنند:
- رادار
- حسگرهای حرارتی (IR)
- سیستمهای اپتیکی (EO)
- ماهواره
- سیگنالهای رادیویی
Fusion باعث:
- تشخیص بهتر اهداف
- دنبالکردن دقیق مسیر دشمن
- کاهش هشدارهای غلط (False Alarms)
- افزایش قدرت تصمیمگیری فرماندهی
سیستمهای مکانی و GIS
در GIS دادهها از منابع مختلف میآیند:
- GPS
- نقشههای دیجیتال
- تصاویر ماهوارهای
- دادههای پهپاد
Fusion باعث ساخت مدلهای دقیقتر از زمین، پوشش گیاهی، ترافیک و تغییرات محیطی میشود.
حملونقل هوشمند (Intelligent Transportation Systems)
در ITS دادهها از:
- دوربینهای شهری
- حسگرهای جادهای
- GPS خودروها
- اپلیکیشنهای موبایلی
ترکیب میشود تا:
- مسیرهای بهینه پیشنهاد شود
- تراکم ترافیک پیشبینی شود
- تصادفات سریعتر تشخیص داده شوند
8. مطالعات موردی
۱.ادغام دادهها در حملونقل هوشمند
این مثال فرضی به نحوه استفاده یک شهر هوشمند از Data Fusion برای بهینهسازی جریان ترافیک میپردازد.
- منابع داده: شهر دادهها را از منابع مختلفی مانند دوربینهای ترافیک، دستگاههای GPS وسایل نقلیه و حسگرهای آبوهوا جمعآوری میکند.
- فرآیند ادغام: Data Fusion در اینجا با پیشپردازش دادههای خام آغاز میشود و سپس ویژگیهای مرتبط مانند سرعت وسایل نقلیه، تراکم ترافیک و شرایط آبوهوایی را استخراج میکند. این دادهها در نهایت در یک مجموعه داده واحد یکپارچه میشوند.
- خروجی و تحلیل: دادههای ادغام شده سپس با استفاده از روشهای آماری و الگوریتمهای یادگیری ماشین تحلیل میشوند تا الگوهای ترافیکی شناسایی شده، نقاط داغ ازدحام پیشبینی شوند و بهروزرسانیهای ترافیکی بلادرنگ تولید شوند.
- نتیجه نهایی: با ترکیب اطلاعات دقیق موقعیت مکانی از GPS، دادههای بصری دوربینها و دادههای محیطی حسگرهای آبوهوا، شهر میتواند بهطور دقیق حوادث ترافیکی را شناسایی کند، زمانبندی سیگنالهای ترافیکی را تنظیم نماید و مسیرهای بهینه را به رانندگان پیشنهاد دهد.
۲. ادغام دادهها در حوزه دفاع و فضا
این مثال واقعی، کاربرد Data Fusion در سیستمهای دفاعی و نظارت موشکی را نشان میدهد.
- ماهیت پروژه: این پروژه مربوط به قرارداد لایه ردیابی (Tracking Layer) سازمان توسعه فضایی آمریکا (SDA) برای ادغام دادههای حسگر در سطح کل صورت فلکی ماهوارهای و پشتیبانی مرتبط است.
- پلتفرم و هدف: شرکت Numerica Corporation (ارائهدهنده سیستمهای پیشرفته دفاع هوایی و موشکی) برای ارائه قابلیتهای Data Fusion به شرکت L3Harris Technologies انتخاب شد.
- کاربرد عملی: لایه نظارت Tranche 1 برای برنامه ماهوارهای ردیابی (Tracking Layer) طراحی شده است. این لایه برای ارائه هشدارهای محدود جهانی و نظارت بر تهدیدات موشکی متعارف و پیچیده، از جمله سیستمهای موشکی مافوق صوت (hypersonic missile systems)، عمل خواهد کرد.
نتیجهگیری: هر دو مثال نشان میدهند که Data Fusion چگونه با ترکیب منابع دادهای متعدد (+GPSدوربین+حسگرها در مثال ۱، یا حسگرهای ماهوارهای متعدد در مثال ۲( بر محدودیتهای یک منبع واحد غلبه کرده و یک تصویر جامع و بلادرنگ برای تصمیمگیری حیاتی ارائه میدهد.
9 . ابزارها و پلتفرمهای Data Fusion
برای پیادهسازی Fusion در دنیای واقعی، ابزارها و پلتفرمهای مختلفی وجود دارند.این ابزارها به سازمانها اجازه میدهند از دادههای چندمنبعی خروجیهای اینتگرهشده، پاک و قابل اعتماد تولید کنند.
Google Cloud Data Fusion
- ابزار قدرتمند تحت Cloud
- مناسب پروژههای Big Data
- قابلیت طراحی Pipeline بدون کدنویسی
- اتصال آسان به منابع مختلف (BigQuery، Cloud Storage، APIها)
Apache Nifi / Hop
- مدیریت جریان داده (Dataflow)
- مناسب پروژههایی با تعداد زیاد منابع
- امکان تعریف Fusion ساده Validation+
- Open Source
Talend / Informatica
- قدرتمندترین ابزارهای ETL+Fusion در سطح سازمانی
- امکاناتی از قبیل:
- Data Quality
- Master Data Management
- Golden Record Creation
- Metadata Management
IBM Fusion Framework
- برای سازمانهای دولتی و مالی
- طراحیشده برای Fusion چندمنبعی با سطح امنیت بالا
- قدرت بسیار زیاد در مدیریت تعارضها
ابزارهای سبک و متنباز
- Open Data Fusion (ODF)
- ML-based Fusion Libraries
- Graph-based Fusion Tools
این ابزارها برای پروژههای دانشگاهی و کاربردهای سادهتر مناسبند.
انتخاب ابزار مناسب
انتخاب ابزار مناسب بهموارد زیر بستگی دارد:
- نوع منابع داده
- حساسیت کاربرد
- نیاز به Real-time Fusion
- بودجه
10 . روندهای نوظهور در Data Fusion
دنیای Fusion بهسرعت در حال تحول است.با ظهور AI، Graph Data، لبهپردازی و سیستمهای Real-time، Fusion وارد عصر جدیدی شده است.این بخش جدیدترین روندهای علمی و صنعتی Fusion را توضیح میدهد.
Fusion + AI (هوش مصنوعی + ادغام داده)
AI اکنون میتواند:
- بهترین تابع Fusion را انتخاب کند
- کیفیت منابع را تخمین بزند
- تعارضها را بهصورت خودکار تشخیص دهد
- حقیقت را بدون قوانین دستی کشف کند
این رویکرد در سیستمهای پزشکی و حملونقل بسیار پرکاربرد است.
Truth Discovery 3.0
نسل جدید الگوریتمها که بدون نیاز به وزن اولیه یا قواعد دستی، حقیقت را از میان دهها منبع متناقض استخراج میکنند.
کاربردها:
- سیستمهای خبری
- بازارهای مالی
- شبکههای اجتماعی
Knowledge Graph Fusion
ترکیب دادهها با استفاده از گرافهای دانش باعث میشود:
- معنای داده حفظ شود
- روابط پنهان استخراج شود
- Fusion دقیقتر انجام شود
در شرکتهایی مثل Google و Amazon استفاده میشود.
Real-Time Fusion
ادغام داده با تاخیر بسیار کم (millisecond-level):
- خودروهای خودران
- پهپادهای هوشمند
- دفاع و امنیت
- سیستمهای ترافیکی
نیازمند معماریهای بسیار سریع و سبک است.
Edge Fusion (Fusion در لبه شبکه)
Fusion مستقیماً روی دستگاهها انجام میشود:
- خودروها
- رباتها
- حسگرها
- دستگاههای IoT
این باعث کاهش بار شبکه و افزایش سرعت میشود.
Cross-Domain Fusion
ادغام داده از حوزههای کاملاً متفاوت:
- دادههای آبوهوایی + دادههای ترافیکی
- داده پزشکی + داده پوشیدنیها
- داده مالی + داده رفتاری کاربران
این حوزه در AI بسیار مهم شده است.
جمعبندی
ادغام دادهها (Data Fusion)، مرحلهای کلیدی در یکپارچهسازی اطلاعات است: سیستمها دادههای پراکنده، تکراری یا متناقض را از منابع گوناگون جمعآوری و پردازش میکنند تا یک نمای واحد، سازگار و قابل اتکا بسازند.
با کمک مدلها و الگوریتمهای هوشمند، Data Fusion به سازمانها کمک میکند تا در حجم بالای داده، «حقیقت عملیاتی» را شناسایی کرده و تصمیماتی دقیق و مبتنی بر شواهد اتخاذ کنند.
کاربردهای آن گسترده است: از پزشکی و امنیت تا IoT، بانکداری دیجیتال، GIS و تحلیل پیچیده.با گسترش دادههای بلادرنگ و سیستمهای هوش مصنوعی، اهمیت آن روزافزون است.
در نهایت، کیفیت خروجی ادغام دادهها مستقیماً عملکرد سیستمهای بالادستی — از تحلیل تا پیشبینی و تصمیمگیری خودکار — را تعیین میکند.
به اختصار: Data Fusion حلقه حیاتی است که داده خام را به دانش قابل اجرا تبدیل میکند.