

مقدمه
در بسیاری از پروژههای هوش مصنوعی، بزرگترین مانع نه کمبود ایده و الگوریتم، بلکه کمبود دادهی کافی و باکیفیت است. آموزش یک مدل از صفر معمولاً به زمان زیاد، منابع محاسباتی سنگین و حجم عظیمی از دادههای برچسبدار نیاز دارد؛ چیزی که برای بسیاری از کسبوکارها و حتی پروژههای پژوهشی عملاً غیرممکن است. اینجاست که یادگیری انتقالی (Transfer Learning) بهعنوان یک میانبُر هوشمندانه وارد عمل میشود.
یادگیری انتقالی به مدلها اجازه میدهد از دانش و تجربههای قبلی خود استفاده کنند و آنها را برای حل مسائل جدید و مرتبط به کار بگیرند؛ درست شبیه انسانها که با تکیه بر مهارتهای گذشته، سریعتر چیزهای تازه یاد میگیرند. بهجای شروع از نقطه صفر، مدل با یک پایهی دانشی قوی آغاز میکند و تنها بخشهای لازم را برای وظیفهی جدید یاد میگیرد.
در این مقاله با مفهوم، نحوهٔ عملکرد، تفاوت با آموزش سنتی و Fine-tuning، انواع و کاربردهای یادگیری انتقالی در بینایی، NLP، پزشکی و صنعت آشنا میشویم تا بفهمیم چرا به ستونی اصلی از هوش مصنوعی مدرن بدل شده است.
تعریف
یادگیری انتقالی (Transfer Learning) تکنیکی هوشمندانه در یادگیری ماشین است که از دوبارهکاری جلوگیری میکند. ایدهٔ اصلی ساده است: دانشی را که مدل از حل یک مسئله (یا دیتاست) کسب کرده، ذخیره و برای حل مسئلهای مرتبط اما متفاوت بهکار میبریم.
به زبان دیگر، یادگیری انتقالی یعنی استفاده از تجربیات گذشته برای بهبود عملکرد در موقعیتهای جدید؛ درست مثل انسانها.
یک مثال ساده
تصور کنید شما دوچرخهسواری را کاملاً بلد هستید. حالا میخواهید موتورسواری یاد بگیرید.
- روش سنتی: انگار هیچچیز نمیدانید! باید از صفر یاد بگیرید چطور تعادل خود را حفظ کنید، چطور فرمان را بگیرید و چطور ترمز کنید.
- روش یادگیری انتقالی: شما از دانش قبلی خود (حفظ تعادل روی دو چرخ) استفاده میکنید. لازم نیست تعادل را دوباره یاد بگیرید؛ فقط باید چیزهای جدید (مثل کلاچ و گاز) را یاد بگیرید. اینطوری خیلی سریعتر موتورسوار میشوید.
چرا یادگیری انتقالی مهم است؟
این تکنیک کاربردهای گستردهای دارد: از حل مسائل رگرسیون در علم داده تا آموزش مدلهای پیچیده؛ اما جذابیت اصلی آن در یادگیری عمیق (Deep Learning) نمایان میشود.
چرا؟ ساخت شبکههای عمیق نیازمند دادهٔ زیادی است، درحالیکه جمعآوری و برچسبزنی آن گران و زمانبر است. یادگیری انتقالی اجازه میدهد با دادهٔ کم هم مدل قدرتمند ساخت — چون از صفر شروع نمیکند.
مقایسه یادگیری سنتی و یادگیری انتقالی
برای درک بهتر، بیایید تفاوت نگاه این دو روش را بررسی کنیم:
۱. فرآیند یادگیری سنتی (اختراع دوباره چرخ)
در روشهای سنتی یادگیری ماشین، برای هر کار جدید، یک مدل جدید از صفر ساخته میشود.
- فرض غلط: این روش فرض میکند که دادههای آموزش (Training) و دادههای تست (Test) دقیقاً از یک جنس و فضا هستند.
- مشکل: اگر ماهیت دادهها کمی تغییر کند، باید مدل قبلی را دور بریزید و یک مدل جدید را با دادههای جدید آموزش دهید.
- مثال: شما یک مدل ساختهاید که نظرات مردم را درباره فیلمهای سینمایی تحلیل میکند (مثبت یا منفی). حالا میخواهید نظرات درباره موسیقی را تحلیل کنید. در روش سنتی، باید مدل سینمایی را دور بریزید و یک مدل جدید برای موسیقی بسازید.
۲. فرآیند یادگیری انتقالی (استفاده از تجربه)
این الگوریتمها به جای شروع از صفر، یک مدلِ از پیش آموزشدیده (Pre-trained Model) را به عنوان نقطه شروع انتخاب میکنند.
- راهکار: دانش کسبشده در وظیفه اول (منبع) به وظیفه دوم (هدف) منتقل میشود.
- مثال: همان مدل تحلیلگر فیلم را در نظر بگیرید. این مدل قبلاً یاد گرفته که کلماتی مثل عالی، خستهکننده یا شاهکار چه بار معنایی دارند. در یادگیری انتقالی، ما از همین دانش زبانی برای تحلیل نظرات موسیقی استفاده میکنیم. چون زبان و کلمات احساسی در هر دو حوزه مشترک هستند، مدل جدید با سرعت و دقت بسیار بالاتری یاد میگیرد.
خلاصه
یادگیری انتقالی یعنی: چرخ را دوباره اختراع نکن؛ آن را بردار و روی ماشین جدیدت نصب کن!
یادگیری انتقالی چطور کار میکند؟
برای اینکه بفهمیم یادگیری انتقالی چطور کار میکند، نباید به آن به چشم یک جادو نگاه کنیم. این یک فرآیند مهندسی دقیق است که در آن، مغزِ یک مدل هوشمند جراحی میشود!
به طور کلی، این فرآیند در ۳ مرحله اصلی اتفاق میافتد:
۱. مرحله اول: پیشآموزش (Pre-training)؛ دوران تحصیل
همه چیز با یک مدل مادر (Source Model) شروع میشود. این مدل روی یک دیتاست بسیار عظیم (مثل ImageNet که ۱۴ میلیون تصویر دارد) آموزش میبیند. در این مرحله، مدل میلیونها پارامتر (وزنهای شبکه عصبی) را تنظیم میکند تا دنیا را بشناسد.
- چی یاد میگیرد؟ لایههای اول شبکه، ویژگیهای ساده مثل خطوط، لبهها و رنگها را یاد میگیرند. لایههای عمیقتر، اشکال پیچیده مثل چشم، گوش، چرخ و پر را میشناسند.
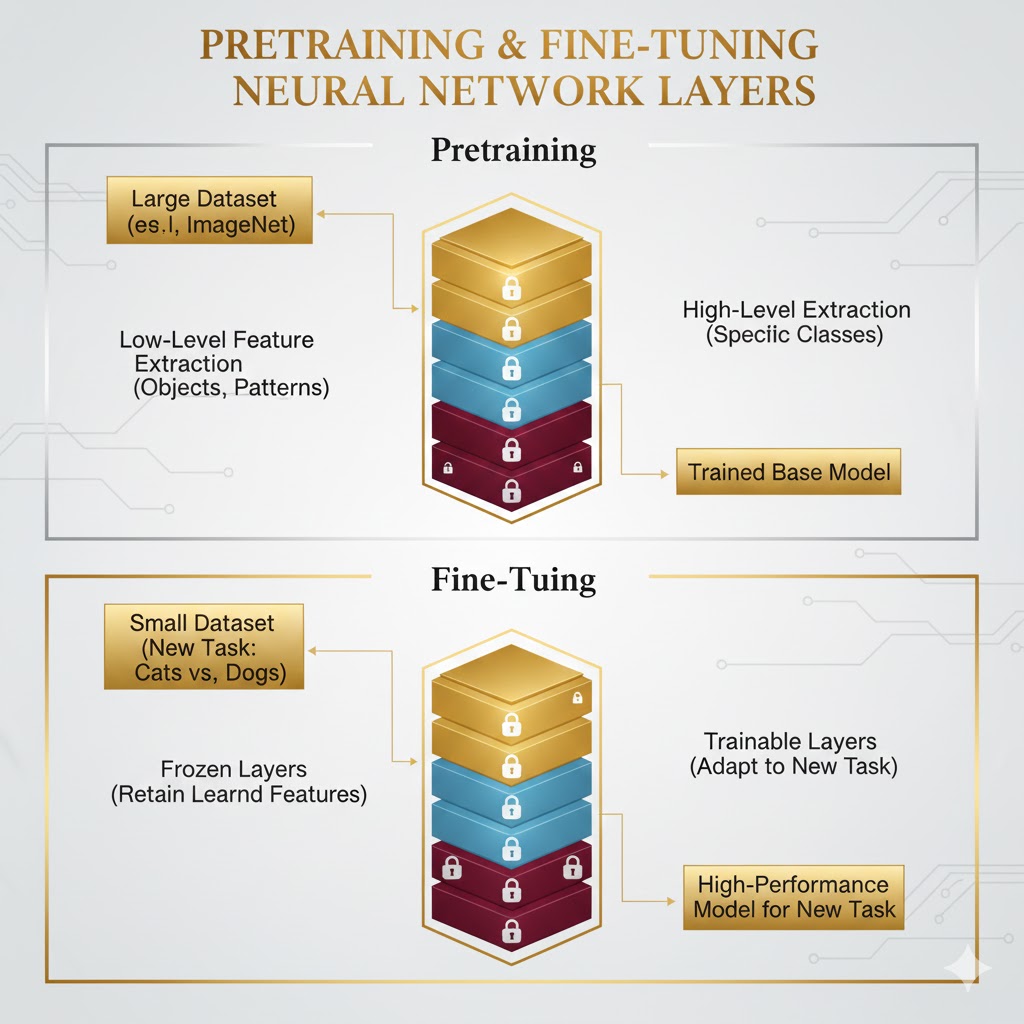
۲. مرحله دوم: انتقال دانش (Transfer)؛ جراحی مغز
حالا ما این مدلِ باسواد را برمیداریم تا روی مسئله خودمان (Target Task) استفاده کنیم. اما نمیتوانیم آن را دقیقاً همانطور که هست به کار ببریم، چون هدف ما فرق دارد.
در اینجا دو اتفاق مهم میافتد:
الف) فریز کردن لایهها (Freezing)
ما لایههای ابتدایی و میانی مدل را قفل یا فریز میکنیم.
- چرا؟ چون دانش این لایهها (شناخت خط و دایره و بافت) عمومی است و در کار جدید ما هم به درد میخورد. ما نمیخواهیم این اطلاعات ارزشمند تغییر کنند یا خراب شوند.
ب) تعویض سر مدل (Replacing the Head)
لایه آخر شبکه (Output Layer) مسئول تصمیمگیری نهایی است (مثلاً میگوید: این عکس گربه است). چون مسئله جدید ما متفاوت است (مثلاً میخواهیم بگوییم: این عکس تومور است)، لایه آخرِ قدیمی را دور میریزیم و یک لایه جدید و تصادفی جایگزین آن میکنیم که مخصوص کلاسهای جدید ماست.
۳. مرحله سوم: تنظیم دقیق (Fine-tuning)؛ تخصص گرفتن
حالا مدل ترکیبی ما آماده است: بدنهای با تجربه (قفل شده) و سَری بیتجربه (جدید). ما مدل را با دیتاست جدید و کوچک خودمان آموزش میدهیم.
- چه اتفاقی میافتد؟ در طول آموزش، وزنهای لایههای قفلشده ثابت میمانند (تغییر نمیکنند)، اما لایه آخر به سرعت یاد میگیرد که چگونه از ویژگیهای استخراجشده توسط بدنه، برای تشخیص جدید استفاده کند.
نکته حرفهای: اگر دادههایمان کافی باشد، میتوانیم کمی از لایههای آخرِ بدنه را هم آنفریز (Unfreeze) کنیم تا آنها هم کمی با کار جدید سازگار شوند. به این کار Fine-tuning عمیق میگویند.
مثال عملی:
نجات جان انسانها (مثال پزشکی) 🩺
چرا این مثال بهتر است؟ چون قدرت واقعی یادگیری انتقال را در شرایطی که داده کم است و هدف حیاتی است نشان میدهد.
۱. مدل اولیه: این مدل را روی ۱۴ میلیون تصویر عمومی (گربه، سگ، صندلی، میوه) آموزش دادهاند. شاید بپرسید: گربه چه ربطی به سرطان دارد؟ نکته این است که مدل در لایههای عمیق، لبهها، برآمدگیها و تفاوتهای بافتی را با دقتی نزدیک به میکروسکوپی یاد گرفته است.
۲. هدف ما: میخواهیم مدلی بسازیم که یک بیماری پوستی نادر را تشخیص دهد. مشکل اینجاست که فقط ۱۰۰ عکس از بیماران داریم (با این تعداد کم، آموزش از صفر غیرممکن است).
۳. اجرای یادگیری انتقال:
- حفظ بدنه: مغزِ مدل را (که متخصص تشخیص بافت و لبه است) نگه میداریم. یک تومور هم دقیقاً از لبهها و بافتهای خاص تشکیل شده است.
- تعویض سر: لایه آخر که میگفت این گربه است را حذف میکنیم.
- لایه جدید: یک لایه ساده با ۲ خروجی (سالم / بیمار) اضافه میکنیم.
- آموزش: مدل را با همان ۱۰۰ عکس پزشکی تنظیم دقیق (Fine-tune) میکنیم.
۴. نتیجه: مدل با دقتی نزدیک به یک پزشک متخصص کار میکند! چرا؟ چون او قبلاً دیدن را یاد گرفته بود و فقط لازم داشت بداند در پزشکیبه کجا نگاه کند.
استراتژیهای یادگیری انتقالی بر اساس داده
اینکه دقیقاً چطور عمل کنیم، به دیتای شما بستگی دارد:
| وضعیت دادههای شما | شباهت به دادههای مدل مادر | استراتژی پیشنهادی |
| داده کم | زیاد | فقط لایه آخر را آموزش دهید (جلوگیری از Overfitting). |
| داده کم | کم | ریسک بالاست! شاید بهتر باشد لایههای بیشتری را آموزش دهید یا کلاً روش دیگری انتخاب کنید. |
| داده زیاد | زیاد | میتوانید کل مدل را تنظیم دقیق (Fine-tune) کنید تا بهترین دقت را بگیرید. |
| داده زیاد | کم | میتوانید مدل را از صفر آموزش دهید، اما استفاده از وزنهای مدل مادر به عنوان نقطه شروع باز هم سرعت را بالا میبرد. |
انواع یادگیری انتقالی؛ کدام روش برای پروژه شما مناسب است؟
یادگیری انتقالی (Transfer Learning) یک نسخه واحد برای همه دردها نیست. بسته به اینکه دادههای شما چقدر شبیه به هم هستند و چه کاری میخواهید انجام دهید، این روش به سه دسته اصلی تقسیم میشود. تفاوت این سه روش در رابطه بین دامنه مبدأ (Source)، دامنه هدف (Target) و وظیفهای است که باید انجام شود.
بیایید این سه تفنگدار را بشناسیم:
۱. انتقالی استقرایی (Inductive Transfer)
این رایجترین شکل یادگیری انتقالی است. در اینجا، وظایف (Tasks) متفاوت هستند، مهم نیست که دادهها (دامنهها) شبیه هم باشند یا نه.
- ماجرا چیست؟ شما مدلی دارید که یک کار کلی را یاد گرفته، حالا میخواهید آن را برای یک کار جدید و خاص تربیت کنید. معمولاً در این روش از دادههای برچسبدار استفاده میشود (نوعی یادگیری نظارتشده).
- مثال در بینایی ماشین: یک مدل که روی میلیونها تصویر آموزش دیده تا فقط ویژگیهای کلی (مثل لبهها و بافتها) را استخراج کند، حالا برای یک وظیفه کاملاً جدید مثل تشخیص اشیاء استفاده میشود.
- نکته: یادگیری چندوظيفهای که در آن مدل همزمان دو کار مختلف (مثلاً طبقهبندی تصویر و تشخیص شیء) را روی یک دیتاست یاد میگیرد، نوعی انتقالی استقرایی است.
۲. یادگیری انتقالی بدون نظارت (Unsupervised Transfer Learning)
این روش شبیه به انتقالی استقرایی است (چون وظایف مبدأ و هدف متفاوتاند)، اما یک تفاوت بزرگ دارد: خبری از دادههای برچسبدار نیست.
- ماجرا چیست؟ همانطور که از نامش پیداست، این روش کاملاً بدون نظارت است. مدل باید بدون اینکه کسی جواب درست را به او بگوید، الگوها را کشف کند.
- کاربرد طلایی: تشخیص تقلب.
- مثال: فرض کنید دیتابیسی از تراکنشهای مالی دارید که هیچ برچسبی ندارند (نمیدانید کدام سالم و کدام دزدی است). مدل الگوهای مشترک و تکراری را در تراکنشها یاد میگیرد. سپس، هر رفتاری که از این الگوهای عادی منحرف شود (Deviating behavior) را به عنوان تقلب احتمالی شناسایی میکند.
۳. انتقالی ترادیسی (Transductive Transfer)
در اینجا بازی برعکس میشود: وظایف (Tasks) یکسان هستند، اما دادهها یا محیط (Domains) متفاوتاند.
- ماجرا چیست؟ معمولاً دادههای مبدأ برچسب دارند، اما دادههای هدف بدون برچسب هستند. به این روش تطبیق دامنه (Domain Adaptation) هم میگویند؛ یعنی دانشی را که در یک محیط یاد گرفتهایم، در محیطی جدید (با توزیع داده متفاوت) اعمال کنیم.
- مثال ملموس: مدلی را در نظر بگیرید که آموزش دیده تا نظرات مردم را درباره رستورانها دستهبندی کند (مثبت یا منفی). حالا از همین مدل استفاده میکنید تا نظرات مردم درباره فیلمهای سینمایی را تحلیل کنید. وظیفه همان است (تحلیل احساسات)، اما دنیا عوض شده است (از پیتزا به سینما!).
تفاوت یادگیری انتقالی در برابر تنظیم دقیق (Fine-tuning)
خیلیها این دو اصطلاح را به جای هم به کار میبرند، اما تفاوت ظریفی بین آنها وجود دارد. درست است که هر دو از مدلهای موجود دوباره استفاده میکنند (به جای آموزش از صفر)، اما شباهتشان همینجا تمام میشود.
تنظیم دقیق (Fine-tuning): متخصص کردنِ مدل
تنظیم دقیق یعنی برداشتن یک مدل و آموزش بیشترِ آن روی یک دیتاست خاص برای بهبود عملکرد در همان وظیفهی اولیه.
- مثال: شما یک مدل کلی تشخیص اشیاء دارید که روی دیتاستهای غولپیکری مثل ImageNet یا COCO آموزش دیده است (میتواند گربه، سگ، میز و… را تشخیص دهد). حالا این مدل را برمیدارید و با یک دیتاست کوچکتر از ماشینها آموزش میدهید تا در تشخیص ماشین استاد شود. شما مدل را برای همان کار (تشخیص) اما با دقت بالاتر روی سوژه خاص، تنظیم دقیق کردهاید.
یادگیری انتقالی (Transfer Learning): تغییر شغلِ مدل
در مقابل، یادگیری انتقالی زمانی است که شما مدل را برای حل یک مسألهی جدید و مرتبط (نه همان مسأله قبلی) سازگار میکنید.
خلاصه:
- Fine-tuning: مدل را صیقل میدهیم تا کارش را بهتر انجام دهد.
- Transfer Learning: دانش مدل را قرض میگیریم تا یک کار جدید انجام دهد.
کاربردهای یادگیری انتقالی
یادگیری انتقالیی فقط یک تئوری دانشگاهی نیست؛ این تکنولوژی نیروی محرکهی بسیاری از سرویسهای هوشمندی است که روزانه با آنها سر و کار داریم. بیایید ببینیم این تکنولوژی دقیقاً کجاها کاربرد دارد:
۱. بینایی ماشین (Computer Vision)
این اصلیترین قلمرو یادگیری انتقالی است.
- کاربرد: مدلهایی که قبلاً روی میلیونها تصویر عمومی (مثل ImageNet) آموزش دیدهاند تا گربه، ماشین و درخت را بشناسند، حالا با کمی تغییر برای کارهای تخصصی استفاده میشوند.
- مثال واقعی: استفاده از یک مدل تشخیص چهره عمومی برای ساخت سیستم احراز هویت بیومتریک در موبایل؛ یا استفاده از مدلی که اشیاء را میشناسد برای تشخیص تومور در تصاویر پزشکی.
۲. پردازش زبان طبیعی (NLP)
انقلاب بزرگ هوش مصنوعی متنی (مثل ChatGPT) مدیون همین روش است.
- کاربرد: مدلهای زبانی غولپیکر (مثل BERT، GPT یا ELMo) که روی کل اینترنت آموزش دیدهاند تا زبان انسان را بفهمند، حالا برای کارهای خاص تنظیم دقیق (Fine-tune) میشوند.
- مثال واقعی: یک شرکت ایرانی به جای ساخت مدل از صفر، مدل GPT را برمیدارد و آن را برای تحلیل احساسات مشتریان در کامنتهای دیجیکالا یا ترجمه تخصصی متون حقوقی آموزش میدهد.
۳. مراقبتهای بهداشتی و پزشکی (Healthcare)
در پزشکی، داده کم است و جان انسانها در میان است.
- کاربرد: توسعه ابزارهای تشخیصی دقیق با استفاده از دانشِ مدلهای بینایی عمومی.
- مثال واقعی: تشخیص ذاتالریه یا شکستگی استخوان از روی تصاویر X-Ray با کمک مدلی که قبلاً یاد گرفته بود لبهها و بافتها را در تصاویر معمولی تشخیص دهد.
۴. امور مالی (Finance)
پول و امنیت شوخیبردار نیستند و یادگیری انتقالیی اینجا نقش پلیس را بازی میکند.
- کاربرد: تشخیص تقلب، ارزیابی ریسک وام و نمرهدهی اعتباری.
- مثال واقعی: بانکی که تازه تأسیس شده و دادههای زیادی از کلاهبرداری ندارد، از دانش و الگوهای کشف تقلبِ یک بانک قدیمی یا دیتاستهای مالی مشابه استفاده میکند تا از روز اول امنیت داشته باشد.
۵. رباتیک و شبیهسازی
- توضیح: آموزش رباتها در دنیای واقعی خطرناک و پرهزینه است (ممکن است ربات بیفتد و بشکند).
- مثال واقعی: مهندسان ربات را در یک محیط شبیهسازی شده (دنیای مجازی) آموزش میدهند و سپس دانش کسبشده را به ربات واقعی منتقل میکنند (Sim-to-Real Transfer).
مزایا
این روش مثل میانبُری است که شما را از ترافیک سنگین یادگیری ماشین نجات میدهد:
۱. سرعت آموزش خیرهکننده (Speed) به جای اینکه ماهها وقت صرف آموزش مدل کنید، در عرض چند ساعت یا چند روز به نتیجه میرسید.
- دلیل: مدل شما یک ذهن خالی نیست؛ او قبلاً بخش سخت ماجرا (شناخت ویژگیهای پایه) را یاد گرفته است.
۲. عملکرد بهتر و دقیقتر (Performance) شروع کردن با یک مدلِ دانشمند، بهتر از شروع کردن با یک مدلِ نوزاد است!
- دلیل: مدل پیشآموزشدیده دانش و الگوهایی دارد که به دست آوردنشان برای شما ممکن نبود. این باعث میشود نقطه شروع شما بسیار بالاتر باشد.
۳. نجاتدهندهی دیتاستهای کوچک (Small Datasets) این مهمترین مزیت است. اگر استارتاپ هستید و دادههای کمی دارید، یادگیری انتقالیی تنها راه نجات شماست.
- دلیل: این روش از بیشبرازش (Overfitting) جلوگیری میکند؛ چون مدل پیش از آن ویژگیهای کلی را یاد گرفته و با مشاهدهٔ چند نمونهٔ جدید گیج نمیشود.
معایب
با وجود تمام خوبیها، این روش بدون ریسک نیست:
۱. عدم تطابق دامنه یا انتقالی منفی (Negative Transfer) اگر معلم و شاگرد هیچ ربطی به هم نداشته باشند، نتیجه فاجعه است.
۲. خطر بیشبرازش در تنظیم دقیق (Overfitting) اگر در مرحله Fine-tuning زیادهروی کنید و مدل را مجبور کنید که موبهمو دادههای جدید را حفظ کند، دانش قبلی و ارزشمند خود را فراموش میکند.
۳. پیچیدگی و هزینه محاسباتی (Complexity) مدلهای پیشآموزشدیده معمولاً غولپیکر هستند (مثل مدلهای BERT یا ResNet).
مطالعات موردی: یادگیری انتقال در دنیای واقعی 🌍
برای اینکه ببینیم یادگیری انتقال چطور قواعد بازی را عوض میکند، بیایید دو سناریوی واقعی را بررسی کنیم که بدون این تکنولوژی، انجامشان غیرممکن یا بسیار پرهزینه بود.
مطالعه موردی۱: پشتیبانی مشتریان برای استارتاپ نوپا (NLP) 💬
چالش: یک فروشگاه اینترنتی جدید میخواهد بفهمد مشتریان در بخش نظرات چه حسی دارند (راضی، عصبانی، یا خنثی).
- مشکل: این فروشگاه تازه تأسیس شده و هنوز دادههای تاریخی و نظرات زیادی ندارد تا بتواند مدل اختصاصی خودش را بسازد.
راهحل (استراتژی استقرایی): آنها از یک مدل زبانی پیشآموزشدیده مثل BERT استفاده میکنند.
- منبع: مدل BERT کل ویکیپدیا و هزاران کتاب را خوانده و ساختار زبان، طعنه و اصطلاحات عامیانه را میفهمد.
- انتقال: استارتاپ این مدل را برمیدارد و با تعداد کمی از نظرات دیجیکالا یا توییتر (به عنوان دادههای مرتبط) آن را برای تحلیل احساسات (Sentiment Analysis) آموزش میدهد.
- اقدام: مدل روی دادههای محدود خودِ فروشگاه تنظیم میشود.
نتیجه:
- سیستمی که از روز اول با هوشمندی یک اپراتور باتجربه کار میکند.
- کاهش نیاز به اپراتور انسانی برای دستهبندی شکایات.
- درس کلیدی: حتی بدون داشتن داده، میتوانید از دانش زبانیِ انباشتهشده در مدلهای غولپیکر بهره ببرید.
مطالعه موردی ۲: کنترل کیفیت در کارخانه قطعات خودرو (صنعت) ⚙️
چالش: یک کارخانه تولید پیستون خودرو میخواهد خراشهای ریز میکروسکوپی روی قطعات را با دوربین تشخیص دهد.
- مشکل: قطعات سالم خیلی زیادند، اما قطعات خراب (خراشدار) بسیار نادرند. دیتاسِت به شدت نامتوازن است و مدل نمیتواند خرابی را یاد بگیرد چون نمونه کافی ندیده است.
راهحل (تشخیص ناهنجاری بدون نظارت): آنها از روش انتقال بدون نظارت (Unsupervised Transfer) استفاده میکنند.
- منبع: مدلی که روی هزاران ساعت ویدیوی خط تولید از قطعات سالم آموزش دیده تا وضعیت نرمال را یاد بگیرد.
- انتقال: این مدل حالا روی خط تولید جدید نصب میشود.
- اقدام: مدل به جای اینکه دنبال خراش بگردد (چون نمیداند خراش چیست)، هر چیزی را که با الگوی سالم مغایرت داشته باشد، به عنوان ناهنجاری یا قطعه مشکوک علامتگذاری میکند.
نتیجه:
- کاهش ۳۰ درصدی ضایعات و مرجوعیها.
- مدل توانست حتی انواع جدیدی از خرابیها را که مهندسان پیشبینی نکرده بودند، کشف کند.
- درس کلیدی: گاهی اوقات یادگیری چه چیزی سالم است، آسانتر از یادگیری چه چیزی خراب است میباشد.
نتیجه گیری
یادگیری انتقالی یکی از مؤثرترین راهکارها برای ساخت مدلهای هوشمند است — بهویژه هنگامی که داده کم، زمان محدود و دقت بالا اولویت دارند. این روش دانش را از یک مسئلهٔ آموختهشده به مسئلهای جدید منتقل میکند؛ پس هزینهٔ آموزش را کاهش میدهد، سرعت یادگیری را افزایش میدهد و حتی برای دیتاستهای کوچک امکان بهرهگیری از مدلهای قدرتمند را فراهم میکند.
موفقیت یادگیری انتقالی در حوزههایی مانند تشخیص تصویر، پردازش زبان طبیعی، پزشکی، امور مالی و رباتیک نشان میدهد که این رویکرد صرفاً یک تکنیک کمکی نیست، بلکه یک استراتژی کلیدی در توسعه سیستمهای هوشمند است. البته استفاده نادرست از آن—مثلاً زمانی که دامنهها کاملاً نامرتبط باشند—میتواند به انتقال منفی و افت عملکرد منجر شود؛ بنابراین انتخاب مدل مبدأ و استراتژی انتقال نقش تعیینکنندهای دارد.
در نهایت، هر زمان که بخواهیم سریعتر، هوشمندانهتر و با منابع کمتر به نتیجه برسیم، یادگیری انتقالی بهترین گزینه پیش روی ماست. این روش به ما یادآوری میکند که در هوش مصنوعی، همانند زندگی، استفاده درست از تجربههای گذشته میتواند مسیر موفقیت را بهطور چشمگیری کوتاهتر کند.