

تعریف و ماهیت
یادگیری نظارتشده یکی از پایهایترین روشهای یادگیری ماشین است که با استفاده از دادههای برچسبدار (شامل ویژگیهای ورودی و حقیقت مبنا — یعنی خروجی صحیح)، به مدل میآموزد چگونه روابط بین ورودی و خروجی را پیشبینی کند.
الگوریتم در طول آموزش، با مقایسه پیشبینیهای خود با برچسبهای واقعی، پارامترهایش را تکراراً تنظیم میکند تا خطای مدل کمینه و برازش (Fit) بهینه حاصل شود.
این فرآیند، شبیه به روشِ مربیگری یک دانشآموز است: هر نمونه، یک «سوال» است و برچسب، «پاسخ صحیح» آن.
دادههای حقیقت مبنا چیست؟
دادههای حقیقت مبنا (Ground Truth) مجموعهای از خروجیهای تأییدشده هستند که صحت آنها با استناد به مشاهدات یا قضاوت انسانهای متخصص (مانند برچسبگذاری دستی) تثبیت شده است. این دادهها به عنوان مبنای معتبری برای آموزش، اعتبارسنجی و ارزیابی عملکرد مدلهای یادگیری ماشین به کار میروند و نشاندهنده «پاسخ صحیح» برای هر نمونه ورودی در دنیای واقعی هستند.
یادگیری نظارتشده برای آموزش روابط بین ورودیها و خروجیها به مدل، به دادههای حقیقت مبنا وابسته است. مجموعه دادههای برچسبداری که در یادگیری نظارتشده استفاده میشوند، همان دادههای حقیقت مبنا هستند. مدلهای آموزشدیده از درک خود نسبت به آن دادهها استفاده میکنند تا بر اساس دادههای جدید و دیدهنشده (Unseen)، پیشبینی انجام دهند.
چگونگی عملکرد یادگیری نظارتشده
یادگیری نظارتشده با استفاده از مجموعهدادههای برچسبدار (حاوی ورودیها و خروجیهای صحیح یا حقیقت مبنا)، به مدل میآموزد چگونه رابطه بین ویژگیها و برچسبها را شناسایی کند. این مدلها سپس قادرند برای دادههای جدید و دیدهنشده، خروجیهای دقیقی پیشبینی کنند.
در طول آموزش، الگوریتم — معمولاً مبتنی بر روشهایی مانند کاهش گرادیان تصادفی — از طریق تابع زیان خطای پیشبینیها را اندازهگیری و پارامترهای مدل را بهگونهای بهروز میکند که خطا بهینه شود. عملکرد نهایی مدل با دادههای آزمایشی و تکنیکهایی مانند اعتبارسنجی متقابل ارزیابی میشود.
برای مدیریت پیچیدگی دادههای پُرُبعد، از تکنیکهای کاهش ابعاد استفاده میشود تا تنها ویژگیهای مؤثر و معنادار در مدل حفظ شوند؛ این کار نهتنها هزینههای محاسباتی را کاهش میدهد، بلکه دقت مدل و تفسیرپذیری نتایج را نیز بهبود میبخشد.
انواع یادگیری نظارتشده
وظایف یادگیری نظارتشده را میتوان به دو دسته کلی تقسیم کرد: مسائل طبقهبندی و مسائل رگرسیون.

۱. طبقهبندی (Classification)
در یادگیری ماشین، طبقهبندی از یک الگوریتم استفاده میکند تا دادهها را به دستههای مختلف مرتب کند. این روش موجودیتهای خاصی را در مجموعه داده شناسایی کرده و تلاش میکند تعیین کند که این موجودیتها چگونه باید برچسبگذاری یا تعریف شوند.
- الگوریتمهای رایج: طبقهبندهای خطی، ماشین بردار پشتیبان (SVM)، درخت تصمیم، -Kنزدیکترین همسایه (KNN)، رگرسیون لجستیک و جنگل تصادفی.
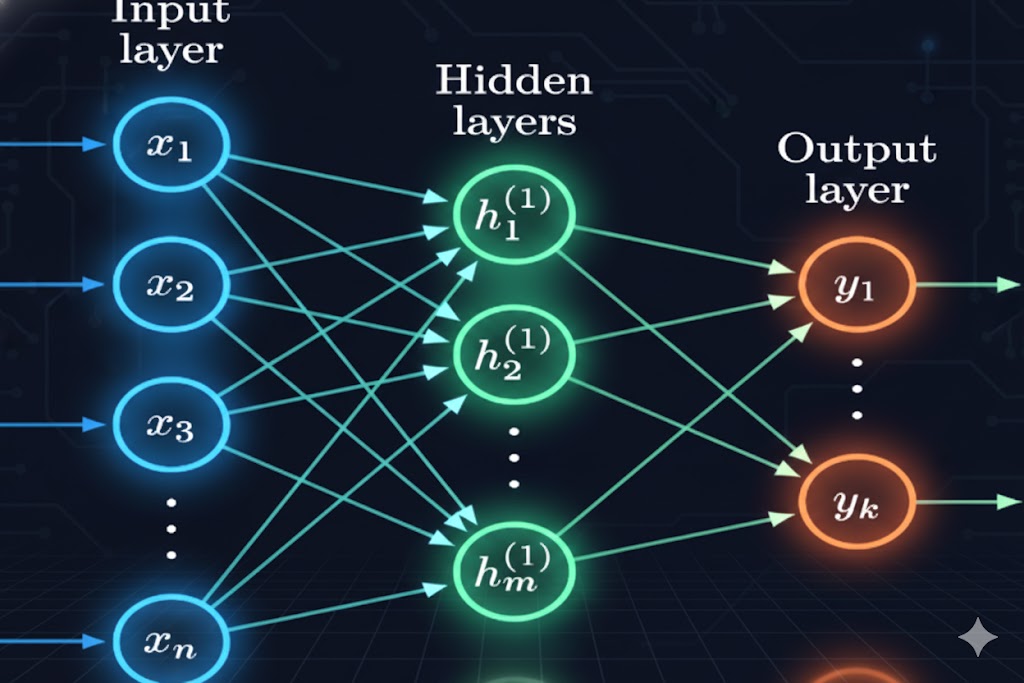
شبکههای عصبی: این شبکهها در مدیریت مسائل پیچیده طبقهبندی تبحر دارند. یک شبکه عصبی، معماری یادگیری عمیقی است که دادههای آموزشی را با لایههایی از گرهها (Nodes) پردازش میکند تا عملکرد مغز انسان را تقلید کند.
- ساختار: هر گره از ورودیها، وزنها، یک بایاس (یا آستانه) و یک خروجی تشکیل شده است.
- فعالسازی: اگر مقدار خروجی از یک آستانه از پیش تعیینشده فراتر رود، گره شلیک میکند (یا فعال میشود) و دادهها را به لایه بعدی شبکه میفرستد.
۲. رگرسیون (Regression)
رگرسیون برای درک رابطه بین متغیرهای وابسته و مستقل استفاده میشود.
- خروجی: در مسائل رگرسیون، خروجی یک مقدار پیوسته است و مدلها تلاش میکنند این خروجی هدف را پیشبینی کنند.
- کاربردها: شامل پیشبینی درآمد فروش یا برنامهریزیهای مالی.
- الگوریتمها: رگرسیون خطی، رگرسیون لاسو (Lasso)، رگرسیون ریج (Ridge) و رگرسیون چندجملهای.

۳. یادگیری گروهی (Ensemble Learning)
یادگیری گروهی یک رویکرد متا (Meta-approach) در یادگیری نظارتشده است که در آن چندین مدل روی یک وظیفه طبقهبندی یا رگرسیون واحد آموزش میبینند. نتایج تمام مدلهای موجود در این استخر با هم ترکیب (تجمیع) میشوند تا بهترین رویکرد کلی برای حل چالش کشف شود.
- یادگیرندههای ضعیف: الگوریتمهای انفرادی در این گروه بزرگتر، به عنوان یادگیرندههای ضعیف یا مدلهای پایه شناخته میشوند.
- تعادل بایاس-واریانس: برخی یادگیرندههای ضعیف بایاس بالا و برخی دیگر واریانس بالا دارند؛ در تئوری، ترکیب بهترین بخشهای هر کدام، این مصالحه (Tradeoff) را تعدیل میکند.
الگوریتمهای یادگیری نظارتشده
الگوریتمهای بهینهسازی مانند کاهش گرادیان ، طیف وسیعی از الگوریتمهای یادگیری ماشین را که در وظایف نظارتشده عالی عمل میکنند، آموزش میدهند.
1. نایو بیز:
یک الگوریتم طبقهبندی است که اصل استقلال شرطی کلاس را از قضیه بیز وام میگیرد.
- مفهوم: یعنی وجود یک ویژگی، تاثیری بر وجود ویژگی دیگر در احتمالِ یک نتیجه ندارد و هر پیشبینیکننده تاثیری برابر بر آن نتیجه دارد.
- انواع و کاربرد: شامل چندجملهای (Multinomial)، برنولی و گاوسی است و اغلب در طبقهبندی متن، شناسایی اسپم و سیستمهای توصیهگر استفاده میشود.
2. رگرسیون خطی:
برای شناسایی رابطه بین یک متغیر وابسته پیوسته و یک یا چند متغیر مستقل استفاده میشود و معمولاً برای پیشبینی نتایج آینده کاربرد دارد.
- خط راست: این الگوریتم رابطه بین متغیرها را به صورت یک خط راست بیان میکند.
- ساده و چندگانه: اگر یک متغیر مستقل و یک وابسته داشته باشیم، رگرسیون خطی ساده و با افزایش متغیرهای مستقل، رگرسیون خطی چندگانه نامیده میشود.
3. رگرسیون غیرخطی:
گاهی اوقات خروجی را نمیتوان از ورودیهای خطی بازتولید کرد؛ در این موارد خروجی باید با یک تابع غیرخطی مدلسازی شود.
- این رگرسیون رابطه بین متغیرها را از طریق یک خط غیرخطی (منحنی) بیان میکند و میتواند روابط پیچیده با پارامترهای زیاد را مدیریت کند.
4. رگرسیون لجستیک:
این مدل متغیرهای وابسته دستهای را مدیریت میکند؛ یعنی زمانی که خروجیها دوتایی (Binary) هستند، مثل درست/غلط یا مثبت/منفی.
- در حالی که مدلهای خطی به دنبال درک روابط هستند، رگرسیون لجستیک عمدتاً مسائل طبقهبندی دوتایی (مثل تشخیص اسپم) را حل میکند.
5. رگرسیون چندجملهای:
مشابه سایر مدلهای رگرسیون، رابطه بین متغیرها را روی نمودار مدل میکند، اما توابع استفاده شده در آن، این رابطه را از طریق درجههای نمایی (Exponential Degree) بیان میکنند.
- این حالت خاصی از رگرسیون است که در آن ویژگیهای ورودی به توان میرسند و به مدلهای خطی اجازه میدهند تا الگوهای غیرخطی را برازش دهند.
6. ماشین بردار پشتیبان(SVM):
هم برای طبقهبندی و هم رگرسیون استفاده میشود، اما معمولاً در مسائل طبقهبندی کاربرد دارد.
- ابرصفحه: SVM کلاسهای نقاط داده را با یک مرز تصمیم یا ابرصفحه جدا میکند. هدف الگوریتم رسم ابرصفحهای است که فاصله بین گروههای داده را به حداکثر برساند.
7. K-نزدیکترین همسایه(KNN):
یک الگوریتم ناپارامتری است که نقاط داده را بر اساس نزدیکی (Proximity) و ارتباطشان با سایر دادههای موجود طبقهبندی میکند. فرض بر این است که نقاط داده مشابه را میتوان در ریاضیات نزدیک به هم پیدا کرد.
- مزایا و معایب: سهولت استفاده و زمان محاسباتی پایین، آن را برای موتورهای توصیه و تشخیص تصویر کارآمد میکند؛ اما با رشد مجموعه داده تست، زمان پردازش طولانی میشود که برای طبقهبندیهای سنگین جذاب نیست.
8.جنگل تصادفی:
یک الگوریتم منعطف است که هم برای طبقهبندی و هم رگرسیون استفاده میشود.
- جنگل: واژه جنگل به مجموعهای از درختهای تصمیم غیرهمبسته اشاره دارد که با هم ادغام میشوند تا واریانس را کاهش داده و دقت را افزایش دهند.
مقایسه با سایر روشهای یادگیری
یادگیری نظارتشده تنها روش آموزش مدلهای یادگیری ماشین نیست. سایر انواع عبارتند از:
- یادگیری نظارتنشده (Unsupervised)
- یادگیری نیمهنظارتشده (Semi-supervised)
- یادگیری خودنظارتشده (Self-supervised)
- یادگیری تقویتی (Reinforcement Learning)
یادگیری نظارتشده در برابر یادگیری نظارتنشده
تفاوت اصلی بین یادگیری نظارتشده و نظارتنشده در این است که یادگیری ماشین نظارتنشده از دادههای بدون برچسب و بدون هیچگونه حقیقت مبنای (Ground Truth) عینی استفاده میکند. در این روش، مدل به حال خود رها میشود تا الگوها و روابط موجود در دادهها را خودش کشف کند. جالب است بدانید که بسیاری از مدلهای هوش مصنوعی مولد (Generative AI) ابتدا با یادگیری نظارتنشده آموزش میبینند و سپس برای افزایش تخصص دامنه، تحت یادگیری نظارتشده قرار میگیرند.
یادگیری نظارتنشده میتواند به حل مسائل خوشهبندی یا تداعی (انجمنی) کمک کند؛ مسائلی که در آنها ویژگیهای مشترک درون یک دیتاست نامشخص هستند. الگوریتمهای رایج خوشهبندی شامل مدلهای سلسلهمراتبی، K-means و مدلهای مخلوط گاوسی هستند.
یادگیری نظارتشده در برابر یادگیری تقویتی
یادگیری تقویتی (Reinforcement Learning) روشی است که به عاملهای خودگردان مانند رباتها یا خودروهای خودران کمک میکند تا از طریق تعامل مستمر با محیط، تصمیمگیری بهینه را بیاموزند.
برخلاف یادگیری نظارتشده، این روش به دادههای برچسبدار نیازی ندارد؛ و در مقایسه با یادگیری نظارتنشده، هدفش صرفاً کشف ساختارهای پنهان در داده نیست. بلکه، عامل با آزمون و خطا رفتار میکند و بر اساس بازخوردِ سیستم پاداش (reward signal)، رفتارهای موفق را تقویت و راهبردهای ناکارآمد را کنار میگذارد.
مزایای یادگیری تقویتی
- حل وظایف پیچیده: فرآیند آموزشِ آزمون و خطا میتواند مدل را به سمت کشف نحوه برخورد با چالشهای استراتژیک و پیچیده هدایت کند.
- عدم وابستگی به برچسبگذاری: مدلها به صورت تجربی یاد میگیرند، نه به صورت تئوری و از طریق تطبیق ورودیها با خروجیها.
- خوداصلاحگر: مدلها رفتار خود را با اشتباه کردن در حین آموزش اصلاح و دقیقتر میکنند.
- انطباقپذیر: مدلها میتوانند خود را با اطلاعات جدید و شرایط متغیر که در آن نتایج از پیش تعریف نشدهاند، وفق دهند.
معایب یادگیری تقویتی
- مستعد نتایج ناپایدار: یادگیری مبتنی بر آزمون و خطا، بهویژه در شروع آموزش، ممکن است تصادفی و غیرقابل پیشبینی به نظر برسد.
- نیاز به دادههای محیطی: یادگیری تقویتی نیازمند این است که مدلها از پیامدهای اقدامات خود درس بگیرند، که این امر مستلزم حجم زیادی از دادههای محیطی است. البته عاملها میتوانند در محیطهای شبیهسازیشده نیز آموزش ببینند.
- هک پاداش: مدلها ممکن است از خلأهای موجود در الگوریتمِ پاداش سوءاستفاده کنند تا بدون انجام صحیح وظایف، پاداش دریافت کنند.
- مختص به وظیفه: یادگیری تقویتی در آموزش مدلها برای یک عملکرد خاص عالی است؛ اما این مدلها ممکن است در انتقال آموختههای خود به وظایف جدید دچار مشکل شوند.
یادگیری نظارتشده در برابر یادگیری نیمهنظارتشده
یادگیری نیمهنظارتشده : شامل آموزش یک مدل بر روی بخش کوچکی از دادههای ورودی برچسبدار به همراه بخش بزرگتری از دادههای بدون برچسب است. از آنجا که تکیه بر تخصصِ دامنه برای برچسبگذاری مناسب دادهها (جهت یادگیری نظارتشده) میتواند زمانبر و پرهزینه باشد، یادگیری نیمهنظارتشده میتواند جایگزین جذابی باشد.
مزایای یادگیری نیمهنظارتشده
- وابستگی کمتر به برچسبگذاری: در مقایسه با روش نظارتشده، به برچسبگذاری کمتری نیاز دارد که موانع ورود برای آموزش مدل را کاهش میدهد.
- کشف الگوهای پنهان: مانند روش نظارتنشده، استفاده از دادههای بدون برچسب در اینجا نیز میتواند منجر به کشف الگوها، روابط و ناهنجاریهایی شود که در غیر این صورت نادیده گرفته میشدند.
- انعطافپذیری بیشتر: این روش با دادههای حقیقت مبنا یک پایه میسازد، سپس آن را با دیتاستهای بدون برچسب تقویت میکند تا مدلها تعمیمپذیرتر شوند.
معایب یادگیری نیمهنظارتشده
- حساسیت به نویز: دیتاستهای بدون برچسب که دارای نویز بالایی هستند، میتوانند نتایج آموزش را منحرف کرده و عملکرد مدل را تضعیف کنند.
- حساسیت به سوگیری: اگر دیتاستهای بدون برچسب برای سوگیریهای ضمنی غربالگری نشوند، آن سوگیریها میتوانند به مدلهای در حال آموزش منتقل شوند.
یادگیری نظارتشده در برابر یادگیری خودنظارتشده
یادگیری خودنظارتشده (Self-supervised Learning – SSL) اغلب به عنوان پلی بین یادگیری نظارتشده و نظارتنشده توصیف میشود. در این روش، به جای استفاده از برچسبهایی که دستی ایجاد شدهاند، وظایف SSL به گونهای پیکربندی میشوند که مدل بتواند سیگنالهای نظارتی خودش (برچسبهای ضمنی یا شبهبرچسبها) را تولید کند و حقیقت مبنا را از دادههای بدون ساختار تشخیص دهد. سپس تابع زیانِ مدل از آن برچسبها به جای برچسبهای واقعی برای ارزیابی عملکرد استفاده میکند.

روش SSL اغلب همراه با یادگیری انتقالی استفاده میشود؛ فرآیندی که در آن یک مدل از پیش آموزشدیده (Pretrained) برای یک وظیفه پاییندستی به کار گرفته میشود. یادگیری خودنظارتشده کاربرد گستردهای در وظایف بینایی ماشین و پردازش زبان طبیعی (NLP) دارد که نیازمند دیتاستهای بزرگی هستند که برچسبگذاری آنها به شدت گران و زمانبر است.
مزایای یادگیری خودنظارتشده
- کارایی: به جای اینکه دانشمندان داده نقاط داده را برچسب بزنند، SSL با محول کردن این وظیفه به مدل، فرآیند برچسبگذاری را خودکار میکند.
- مقیاسپذیری: وابستگی کمتر SSL به برچسبگذاری دستی، آن را برای مقیاسگذاری با استخرهای بزرگترِ دادههای بدون برچسب مناسب میسازد.
- وابستگی کم به برچسبگذاری: در مواردی که دادههای حقیقت مبنای برچسبدار کمیاب هستند، SSL این کمبود را از طریق درکِ تولیدشده توسط خودِ مدل جبران میکند.
- تطبیقپذیری: مدلهای خودنظارتشده ویژگیهای غنی و قابلانتقالی را یاد میگیرند که میتوانند برای بسیاری از وظایف خاصِ دامنه و چندوجهی (Multimodal) تنظیم دقیق (Fine-tune) شوند.
معایب یادگیری خودنظارتشده
- محاسبات سنگین: پردازش دیتاستهای بدون برچسب و تولید برچسبها به قدرت محاسباتی زیادی نیاز دارد.
- پیچیدگی: فرآیند ایجاد وظایف پیشتیمار برای یادگیری نظارتشده—که فاز اولیه یادگیری است—نیازمند درجه بالایی از تخصص است.
- احتمال عدم قابلیت اطمینان: همانند سایر روشهای یادگیری ماشین که فاقد نظارت انسانی هستند، خروجیهای این مدلها بهشدت به کیفیت دادهها وابسته است؛ وجود نویز، سوگیری پنهان یا سایر تحریفات در داده میتواند منجر به تصمیمات گمراهکننده یا ناعادلانه شود.
موارد کاربرد واقعی یادگیری نظارتشده
مدلهای یادگیری نظارتشده میتوانند برنامههای تجاری را از طریق پیشبینی دقیق، شخصیسازی خدمات و اتوماسیون تصمیمگیری، هم طراحی کنند و هم بهطور پویا ارتقا دهند.
۱. تشخیص تصویر و شیء: الگوریتمهای یادگیری نظارتشده میتوانند برای مکانیابی، جداسازی و دستهبندی اشیاء در ویدیوها یا تصاویر استفاده شوند که آنها را برای وظایف بینایی ماشین و تحلیل تصویر بسیار کارآمد میسازد.
۲. تحلیلهای پیشبینیکننده: مدلهای نظارتشده سیستمهای تحلیلی پیشبینیکنندهای میسازند که بینشهای عمیقی ارائه میدهند. این امر به سازمانها اجازه میدهد تا نتایج را بر اساس یک متغیر خروجی پیشبینی کنند و تصمیمات دادهمحور بگیرند؛ که به نوبه خود به مدیران کمک میکند تا انتخابهای خود را توجیه کنند یا جهتگیری سازمان را به نفع کسبوکار تغییر دهند.
- مثال پزشکی: رگرسیون به ارائهدهندگان خدمات درمانی اجازه میدهد تا نتایج را بر اساس معیارهای بیمار و دادههای تاریخی پیشبینی کنند. یک مدل پیشبینیکننده ممکن است ریسک ابتلا به یک بیماری یا وضعیت خاص را بر اساس دادههای بیولوژیکی و سبک زندگی بیمار ارزیابی کند.
۳. تحلیل احساسات مشتری: سازمانها میتوانند اطلاعات مهم (شامل زمینه، احساس و نیت) را از حجم عظیمی از دادهها با حداقل دخالت انسانی استخراج و طبقهبندی کنند. تحلیل احساسات درک بهتری از تعاملات مشتری ارائه میدهد و میتواند برای بهبود تلاشهای تعامل با برند استفاده شود.
۴. بخشبندی مشتریان: مدلهای رگرسیون میتوانند رفتار مشتری را بر اساس ویژگیهای مختلف و روندهای تاریخی پیشبینی کنند. کسبوکارها میتوانند از مدلهای پیشبینیکننده برای بخشبندی پایگاه مشتریان خود و ایجاد پرسونای خریدار جهت بهبود بازاریابی و توسعه محصول استفاده کنند.
۵. تشخیص هرزنامه: یکی از کاربردهای کلاسیک یادگیری نظارتشده، تشخیص هرزنامه است. با آموزش مدلهای طبقهبندی (مانند Naive Bayes یا Logistic Regression) بر روی دادههای برچسبدار، سیستم میآموزد الگوهای متنی و رفتاری مربوط به ایمیلهای اسپم را شناسایی کند و پیامهای جدید را بهطور خودکار به دو دسته «هرزنامه» و «غیرهرزنامه» تقسیم نماید.
چالشهای اصلی یادگیری نظارتشده
با وجود قدرت بالای یادگیری نظارتشده در ارائه بینشهای عمیق و اتوماسیون، این روش در همه سناریوها کارآمد نیست و با موانع زیر روبروست:
1. وابستگی به نظارت انسانی :این مدلها توانایی «خودآموزی» ندارند. دانشمندان داده باید دائماً بر خروجیها نظارت کرده و عملکرد مدل را به صورت دستی اعتبارسنجی کنند.
2. زمانبر بودن: پاشنه آشیل این روش، نیاز به برچسبگذاری دستی دادههاست. آمادهسازی مجموعه دادههای آموزشیِ بزرگ و دقیق، فرآیندی بسیار طولانی و خستهکننده است.
3. عدم انعطافپذیری :مدلهای نظارتشده در مواجهه با دادههای جدیدی که خارج از چارچوبِ دادههای آموزشیشان باشند، فلج میشوند (برخلاف مدلهای نظارتنشده که سازگارترند).
4. مشکل بیشبرازش : گاهی مدل به جای یادگیری «الگوها»، جزئیات دادههای آموزشی را «حفظ» میکند. در این حالت، اگرچه دقت در مرحله آموزش بالاست، اما مدل در دنیای واقعی شکست میخورد. (راه حل: تست مدل با دادههای متفاوت).
جمع بندی
یادگیری نظارتشده یکی از مهمترین روشهای یادگیری ماشین است که با استفاده از دادههای برچسبدار، به مدلها میآموزد چگونه رابطه میان ورودیها و خروجیها را یاد بگیرند. دادههای حقیقت مبنا نقش پایهای در این فرآیند دارند و به مدل کمک میکنند الگوهای پنهان را شناسایی کند و برای دادههای جدید پیشبینی دقیق ارائه دهد.
این رویکرد با الگوریتمهای متنوعی مانند طبقهبندی، رگرسیون و یادگیری گروهی، مسائل واقعی مختلف—از تشخیص تصویر تا پیشبینی مالی و تحلیل احساسات—را حل میکند و به همین دلیل یکی از قدرتمندترین ابزارهای هوش مصنوعی بهشمار میرود.
با وجود مزایا، یادگیری نظارتشده چالشهایی مانند نیاز به دادههای برچسبدار، خطر سوگیری و ضعف در مواجهه با دادههای جدید دارد. اما با استفاده از دادههای باکیفیت و انتخاب الگوریتم مناسب، میتوان مدلهایی ساخت که تصمیمگیری را در بسیاری از حوزههای علمی و تجاری هوشمندانهتر و دقیقتر میکنند.
در نهایت، این روش پلی مطمئن میان دادههای واقعی و پیشبینیهای قابلاعتماد است و به سازمانها کمک میکند آینده را روشنتر و بر پایه شواهد دادهمحور مدیریت کنند.