

مقدمه
در دنیایی که هر روز میلیاردها داده خام تولید میشود، بزرگترین چالش هوش مصنوعی نه کمبود داده، بلکه کمبود داده برچسبدار است. برچسبگذاری دادهها زمانبر، پرهزینه و نیازمند نیروی انسانی متخصص است؛ چالشی که رشد بسیاری از پروژههای یادگیری ماشین را کند کرده است. دقیقاً در همین نقطه، یادگیری خودنظارتی (Self-Supervised Learning) بهعنوان یک راهحل هوشمندانه و تحولآفرین وارد میدان میشود.
یادگیری خودنظارتی به مدلها این توانایی را میدهد که بدون نیاز به برچسبگذاری انسانی، مستقیماً از دادههای خام بیاموزند. مدل بهجای دریافت جوابهای آماده، خودش مسئله طراحی میکند، بخشهایی از داده را پنهان میکند، پیشبینی میکند و همان داده را بهعنوان حقیقت مبنا در نظر میگیرد. این رویکرد پلی میان یادگیری نظارتشده و بدون نظارت میزند و مسیری تازه را برای آموزش مدلهای هوشمند باز میکند.
در این مقاله، بهصورت گامبهگام با مفهوم یادگیری خود-نظارتی، نحوه عملکرد آن، روشها و معماریهای مهم، تفاوتش با سایر رویکردهای یادگیری ماشین و کاربردهای واقعی آن در حوزههایی مانند پردازش زبان طبیعی، بینایی ماشین، پزشکی و سیستمهای هوشمند آشنا میشویم.
تعریف
یادگیری خود-نظارتی یا SSL، یک تکنیک پیشرفته در یادگیری ماشین است که قواعد بازی را تغییر داده است. این روش، شکاف بین یادگیری نظارتشده و یادگیری بدون نظارت را پر میکند.
به زبان ساده، در حالی که روشهای سنتی برای یادگیری نیاز به معلم (دادههای برچسبدار) دارند، مدلهای خود-نظارتی آنقدر هوشمند هستند که میتوانند از دلِ دادههای خام و بدون ساختار، برای خودشان تمرین و مسئله طرح کنند و یاد بگیرند.
ویژگیهای کلیدی یادگیری خود-نظارتی (SSL)؛ چرا این روش خاص است؟
یادگیری خود-نظارتی (SSL) فقط یک تکنیک جدید نیست؛ بلکه یک تغییر پارادایم در نحوه یادگیری ماشینهاست. بیایید ۶ ویژگی طلایی این روش را که آن را از سایر متدها متمایز میکند، بررسی کنیم:
۱. استفاده از دادههای بدون برچسب (استقلال از انسان)
این مدل مستقیماً از دادههای خام (Raw Data) یاد میگیرد و نیازی ندارد که انسانها هزاران ساعت وقت صرف کنند تا دادهها را دستی برچسبگذاری کنند.
- مثال: مانند کودکی که فقط با شنیدن حرف اطرافیان (دادهٔ خام) زبان میآموزد، نه با اینکه کسی مدام قواعد گرامری را برایش دیکته کند (برچسبگذاری).
۲. تولید پویای برچسبها
مدل منتظر نمیماند کسی به او بگوید چه چیزی درست است؛ بلکه با درک ساختار داده، خودش برای خودش سوال و جواب طراحی میکند و برچسبهای آموزشی را تولید میکند.
- مثال: مدل یک جمله را میخواند، کلمه آخر را حذف میکند و سعی میکند آن را حدس بزند. در اینجا، کلمه حذف شده همان برچسبی است که خود مدل ساخته است.
۳. ترکیبی از روشهای یادگیری (پل میان دو دنیا)
یادگیری خود-نظارتی یک «مسیر میانه هوشمندانه است. از نظر فنی شبیه یادگیری نظارتشده است (چون هدف و تابع زیان دارد)، اما از نظر دادهای شبیه یادگیری بدون نظارت است (چون دادهها برچسب ندارند).
۴. یادگیری ویژگیهای مفید (فهم عمیق الگوها)
چون مدل مجبور است ساختار داده را بازسازی یا پیشبینی کند، یاد میگیرد که به جزئیات و الگوهای مهم توجه کند. این باعث میشود درک عمیقتری از محتوا داشته باشد.
- مثال: در تشخیص چهره، مدل ابتدا یاد میگیرد که چشم، بینی و لبهها چه شکلی هستند (ویژگیهای مفید)، قبل از اینکه بخواهد کل چهره را شناسایی کند.
۵. کاربردهای گسترده (آچار فرانسه هوش مصنوعی)
این روش در حوزههایی که دادههای برچسبدار کمیاب یا گران هستند، پادشاهی میکند.
- بینایی ماشین
- پردازش زبان طبیعی
- تشخیص گفتار
۶. کمک به یادگیری انتقال (سکوی پرتاب)
SSL فرآیند تطبیق مدلها با کارهای جدید را بسیار آسان میکند. ما مدل را روی دادههای عمومی پیشآموزش میدهیم و سپس دانش کسبشده را به یک مسئله خاص منتقل میکنیم.
- مثال: یک مدل ابتدا روی کل ویکیپدیا آموزش میبیند (پیشآموزش SSL) تا زبان را یاد بگیرد. سپس همان مدل با کمی تمرین، تبدیل به یک دستیار حقوقی تخصصی میشود (یادگیری انتقال). دیگر لازم نیست دستور زبان را از صفر به او یاد بدهیم.
یادگیری خود-نظارتی (SSL) چگونه کار میکند؟
یادگیری خود-نظارتی با یک ایده هوشمندانه کار میکند: طراحی وظایفی که در آن تابع زیان (Loss Function) بتواند از خودِ دادههای ورودیِ بدون برچسب به عنوان حقیقت مبنا (Ground Truth) استفاده کند. این روش به مدل اجازه میدهد تا بدون نیاز به هیچگونه برچسب یا حاشیهنویسی انسانی، بازنماییهای دقیق و معناداری از دادههای ورودی را یاد بگیرد.
هدف نهایی SSL، کاهش یا جایگزینی کامل نیاز به دادههای برچسبدار است. چرا؟ چون دادههای برچسبدار کمیاب و گران هستند، در حالی که دادههای بدون برچسب فراوان و ارزاناند.
مفهوم وظایف ساختگی (Pretext Tasks)
در این روش، مدلها با انجام وظایف ساختگی یا Pretext Tasks آموزش میبینند. این وظایف برچسبهای کاذب (Pseudo-labels) را از دلِ دادههای خام بیرون میکشند.
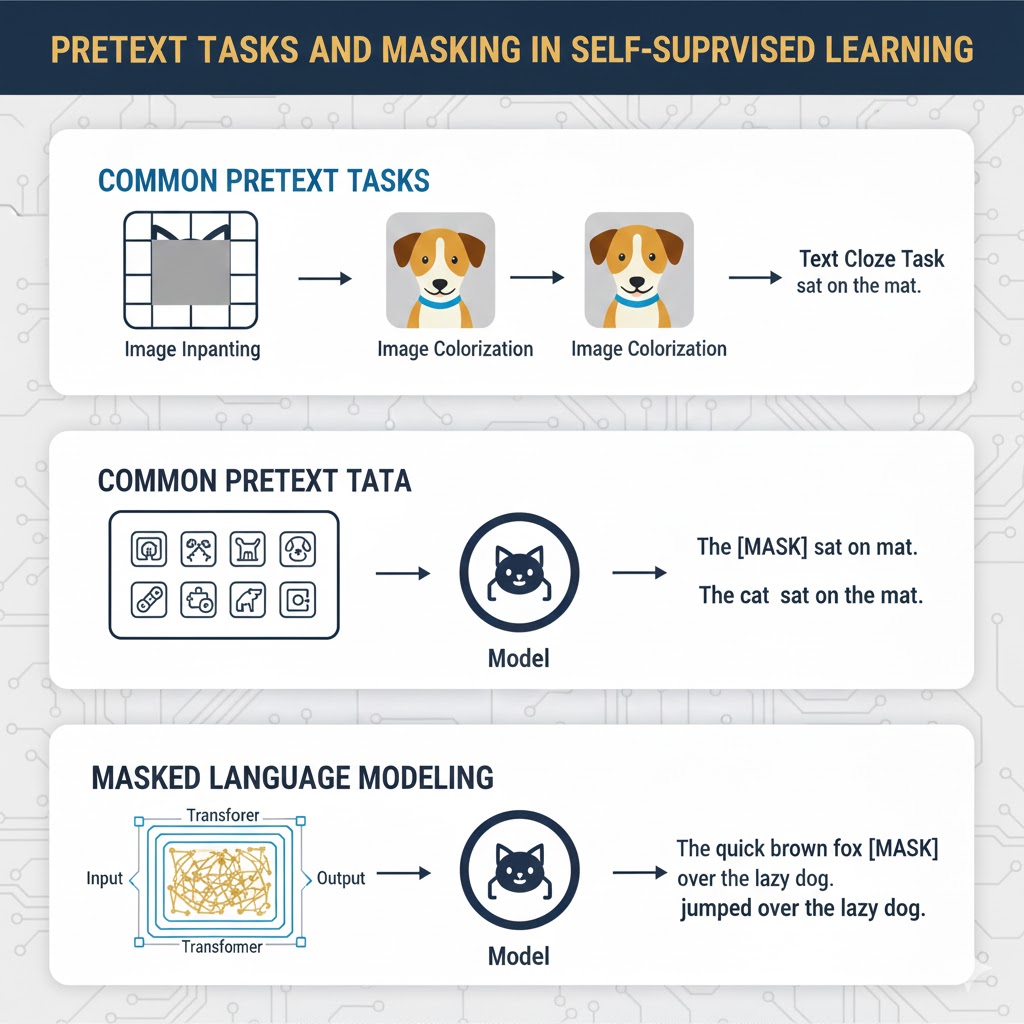
- چرا ساختگی؟ چون انجام این وظیفه به خودی خود هدف ما نیست؛ بلکه فقط بهانهای است تا مدل ساختار دادهها را یاد بگیرد (Representation Learning) تا بتواند در مراحل بعدی (Downstream Tasks) عملکرد بهتری داشته باشد.
- تنظیم دقیق (Fine-tuning): مدلهایی که با SSL پیشآموزش میبینند، اغلب برای وظایف اصلی و نهایی خود تنظیم دقیق میشوند؛ این مرحله معمولاً شامل یادگیری نظارتشده واقعی است، اما با این تفاوت که به دادههای برچسبدار بسیار کمتری نیاز دارد.
اگرچه دنیای SSL بسیار متنوع است، اما اکثر مدلها از یکی (یا هر دو) تکنیک اصلی زیر استفاده میکنند: یادگیری خود-پیشگو (Self-predictive) و یادگیری تقابلی (Contrastive).
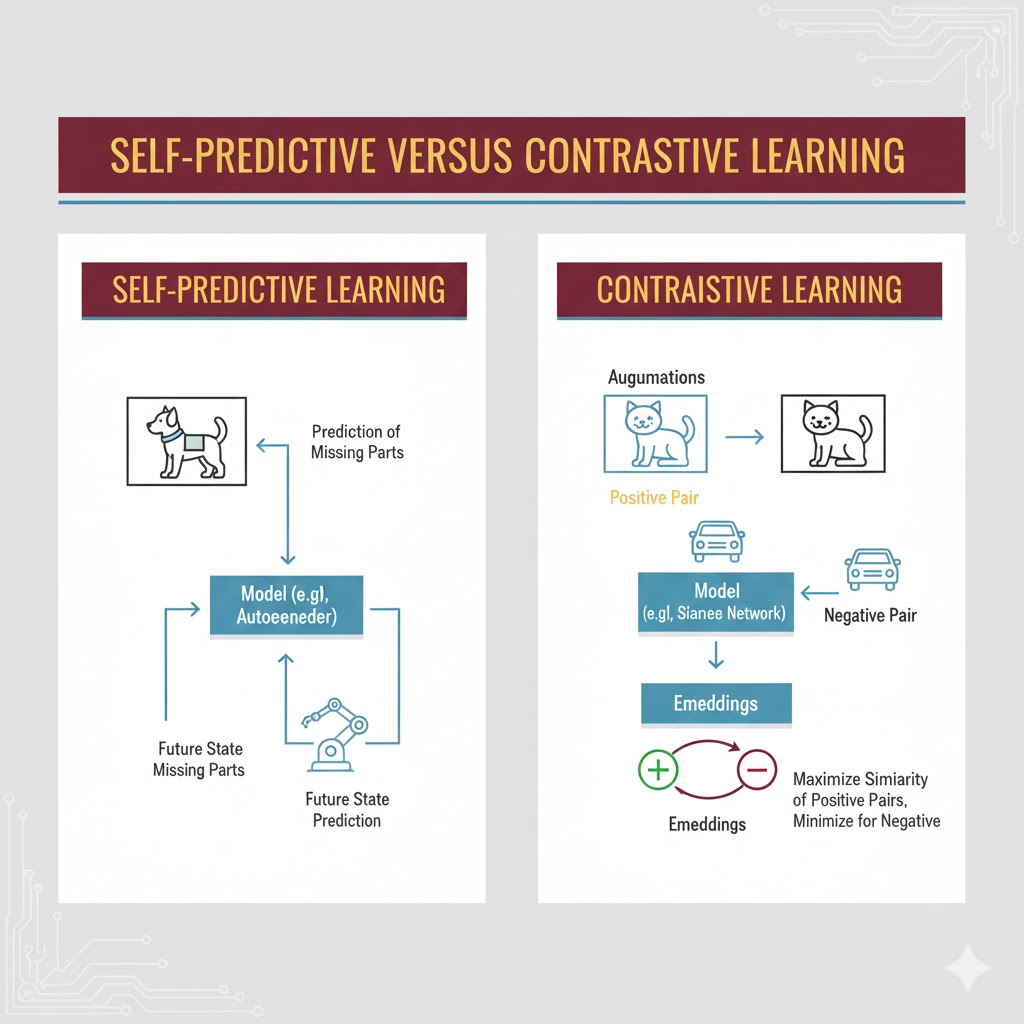
۱. یادگیری خود-پیشگو (Self-predictive Learning)
این روش که به یادگیری خود-نظارتی خود-تداعیگر (Autoassociative) نیز معروف است، به مدل یاد میدهد که با داشتن بخشی از یک داده، بخش دیگر آن را پیشبینی کند. این مدلها معمولاً از نوع تولیدی (Generative) هستند.
یان لکان (Yann LeCun) این روش را به عنوان تمرینِ ساختاریافتهی پر کردن جاهای خالی توصیف کرده است. او فرآیند یادگیری از ساختار زیربنایی دادهها را اینگونه ساده بیان میکند: فرض کنید بخشی از ورودی را نمیدانید و سعی کنید آن را پیشبینی کنید. مثالهایی از این رویکرد عبارتند از:
- پیشبینی آینده با استفاده از گذشته (مثلاً در ویدیو یا متن).
- پیشبینی بخش ماسکشده (پنهان) با استفاده از بخشهای مرئی.
- پیشبینی هر بخش مسدود شده با استفاده از تمام بخشهای موجود.
سیستمهای مبتنی بر این فلسفه از معماریهای خاصی استفاده میکنند:
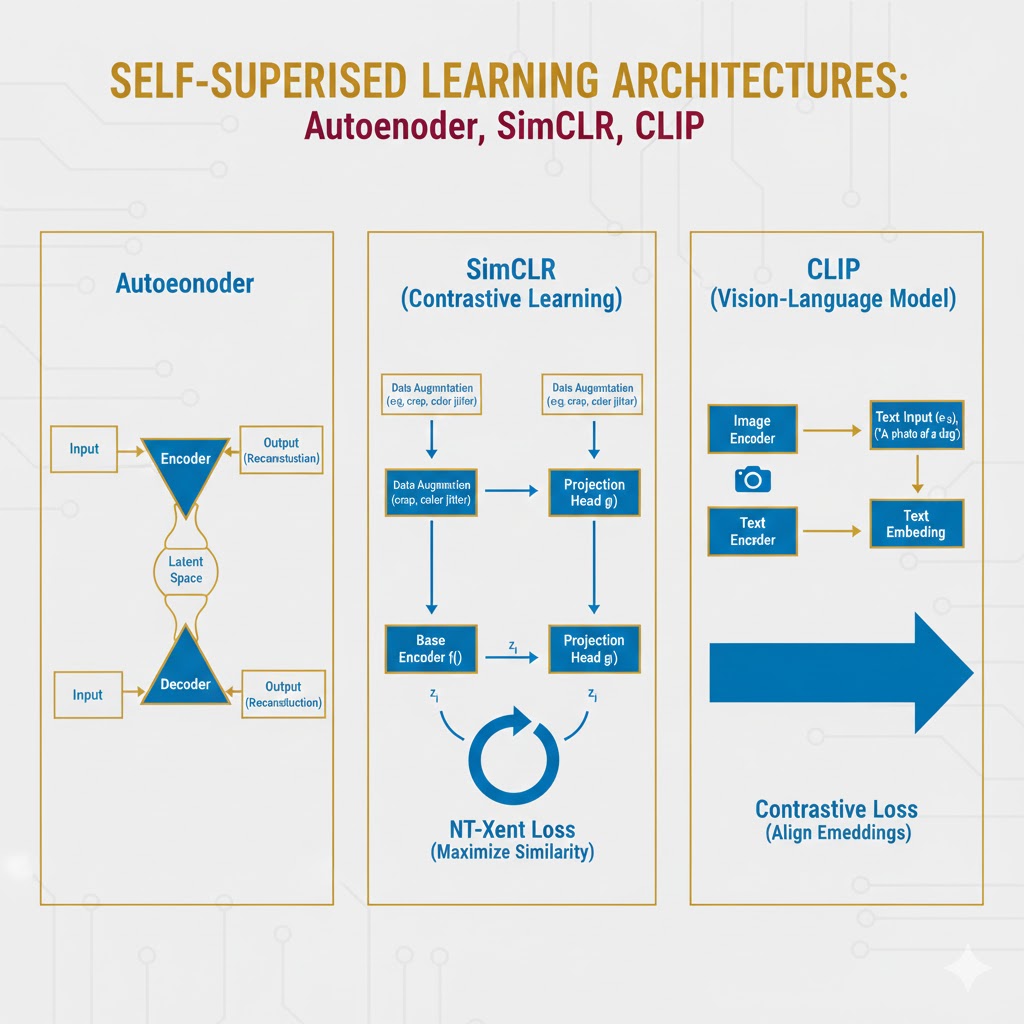
الف) خودکدگذارها (Autoencoders)
یک خودکدگذار، شبکه عصبی است که یاد میگیرد دادههای ورودی را فشرده (Encode) کند و سپس با استفاده از آن نسخه فشرده، ورودی اصلی را بازسازی (Decode) نماید. هدف این است که خطای بازسازی به حداقل برسد و ورودی اصلی نقش حقیقت مبنا را بازی میکند.
- گلوگاه (Bottleneck): این معماریها معمولاً یک گلوگاه ایجاد میکنند؛ یعنی ظرفیت داده در لایهها کاهش مییابد. این کار شبکه را مجبور میکند تا فقط مهمترین الگوهای پنهان (متغیرهای پنهان یا Latent Space) را یاد بگیرد تا بتواند با اطلاعات کمتر، داده اصلی را بازسازی کند.
انواع پیشرفته:
- خودکدگذارهای حذف نویز(Denoising): دادههای ورودیِ خراب یا نویزی دریافت میکنند و یاد میگیرند با حذف اطلاعات بیهوده، نسخه اصلی و سالم را بازسازی کنند (جلوگیری از بیشبرازش).
- خودکدگذارهای تغییرپذیر (VAEs): برخلاف مدلهای معمولی که فضای پنهان گسسته دارند، VAEها مدلهای پیوستهای یاد میگیرند (به صورت توزیع احتمال) که اجازه میدهد دادههای کاملاً جدیدی تولید کنند.
ب) خود-رگرسیونی (Autoregression)
این مدلها با منطق استفاده از گذشته برای پیشبینی آینده کار میکنند و برای دادههای ترتیبی مثل زبان یا صوت عالی هستند.
- تفاوت با رگرسیون خطی سنتی در این است که متغیر مستقل و وابسته در اینجا یکی هستند (رگرسیون روی خودِ متغیر انجام میشود).
- کاربرد: مدلهای زبانی مشهور مثل GPT، LLaMa و Claude از این روش استفاده میکنند. آنها ابتدای یک جمله را میبینند و کلمه بعدی را پیشبینی میکنند، در حالی که کلمه واقعی بعدی به عنوان حقیقت مبنا عمل میکند.
ج) ماسکگذاری (Masking)
در این روش، بخشهایی از داده حذف (ماسک) میشوند و مدل باید آنها را بازسازی کند.
- مدلهای زبانی ماسکگذاری شده (مانند BERT): کلمات تصادفی از جمله حذف میشوند و مدل باید جای خالی را پر کند. مزیت مدلهایی مثل BERT نسبت به مدلهای خود-رگرسیونی (مثل GPT) این است که دو-طرفه (Bidirectional) هستند؛ یعنی برای پیشبینی یک کلمه، هم به کلمات قبلی و هم به کلمات بعدی نگاه میکنند که برای درک عمیق محتوا (مثل ترجمه) عالی است.
د) پیشبینی روابط ذاتی (Innate relationship prediction)
این روش مدل را آموزش میدهد تا درک خود از داده را حتی پس از تغییر حفظ کند. مثلاً یک تصویر چرخانده میشود و مدل باید درجه و جهت چرخش را نسبت به تصویر اصلی حدس بزند.
۲. یادگیری تقابلی (Contrastive Learning)
در این روش، به جای پیشبینی یک بخش از داده، مدل باید رابطه بین چندین نمونه داده را پیشبینی کند. این مدلها معمولاً از نوع تمیزدهنده (Discriminative) هستند.
مدلهای تقابلی روی جفتهای داده-داده کار میکنند (برخلاف مدلهای خود-پیشگو که روی جفت داده-برچسب کار میکردند) و یاد میگیرند بین چیزهای مشابه و نامشابه تمایز قائل شوند.
- افزایش داده (Data Augmentation): این جفتها معمولاً با ایجاد تغییرات در دادههای خام (مثل برش زدن، چرخش، تغییر رنگ یا نویز در تصاویر) ساخته میشوند. این کار باعث میشود مدل بازنماییهای معنایی و پویایی یاد بگیرد.
الف) تمایز نمونه (Instance Discrimination)
این روش آموزش را به یک سری وظایف طبقهبندی دوتایی تبدیل میکند: تشخیص اینکه آیا دو نمونه با هم جفت مثبت (همسان) هستند یا جفت منفی (ناهمسان).
- مثال (SimCLR یا MoCo): یک دسته تصویر خام دریافت میشود. تغییرات تصادفی روی آنها اعمال میشود تا جفتهایی ایجاد شود. مدل آموزش میبیند تا تفاوت برداری بین جفتهای مثبت (مشتق شده از یک عکس) را به حداقل و تفاوت بین جفتهای منفی را به حداکثر برساند.
- نتیجه این است که مدل دستهبندیهایی را یاد میگیرد که نسبت به تغییرات جزئی (مثل رنگ یا زاویه دید) مقاوم هستند.
ب) یادگیری غیر-تقابلی (Non-contrastive learning)
شاید نامش عجیب باشد، اما این روش بسیار شبیه یادگیری تقابلی است با این تفاوت که مدل فقط با جفتهای مثبت آموزش میبیند و سعی میکند تفاوت بین بازنمایی آنها را کم کند (بدون نیاز به نمونههای منفی).
- مزیت: چون نیازی به نمونههای منفی نیست، به دستههای (Batch) کوچکتری برای آموزش نیاز دارد و حافظه کمتری مصرف میکند.
- مدلهایی مثل BYOL و Barlow Twins با این روش نتایجی در حد مدلهای نظارتشده کسب کردهاند.
ج) یادگیری چند-وجهی (Multi-modal Learning)
وقتی انواع مختلف داده (مثل متن و تصویر) داریم، روشهای تقابلی میتوانند ارتباط بین آنها را یاد بگیرند.
- مثال (CLIP): این مدل یک کدگذار تصویر و یک کدگذار متن را همزمان آموزش میدهد تا پیشبینی کند کدام توضیح متنی مربوط به کدام تصویر است (با استفاده از میلیونها جفت تصویر-متن از اینترنت).
- این روش برای همگامسازی ویدیو و متن، ویدیو و صدا، و گفتار و متن نیز استفاده شده است.
۳. تکنیکها و معماریهای پیشرفته در SSL
علاوه بر روشهای اصلی بالا، محققان (بهویژه در شرکتهایی مثل گوگل و فیسبوک) چارچوبهای نوآورانهای را توسعه دادهاند که مرزهای یادگیری خود-نظارتی را جابجا کردهاند:
الف) کدگذاری پیشگویانه تقابلی (CPC)
این روش که توسط مهندسان DeepMind گوگل معرفی شده، ترکیبی هوشمندانه از یادگیری تقابلی و پیشبینی است.
- نحوه کار: CPC سعی میکند روابط بین بخشهای مختلف داده را درک کند، اما یک ویژگی جالب دارد: حذف نویز. این مدل یاد میگیرد که جزئیات سطح پایین و بیاهمیت (Noise) را دور بریزد و فقط روی الگوهای کلی و معنادار تمرکز کند.
- کاربرد: هم در پردازش زبان و هم در بینایی ماشین کاربرد دارد.
ب) مدلهای مبتنی بر انرژی (EBM SSL)
در این رویکرد، ما با مفهوم فیزیکی «انرژی سر و کار داریم! در اینجا، انرژی معیاری برای سنجش «سازگاری بین دو ورودی است.
- منطق کار:
- انرژی پایین (Low Energy): نشاندهنده سازگاری بالا است (مثلاً دو عکس مختلف از یک ماشین).
- انرژی بالا (High Energy): نشاندهنده ناسازگاری است (مثلاً عکس ماشین در کنار عکس هواپیما).
- هدف مدل این است که یاد بگیرد به جفتهای درست، انرژی کم و به جفتهای غلط، انرژی زیاد نسبت دهد.
ج) تخصیص خوشههای متضاد (SwAV)
روشهای سنتی خوشهبندی معمولاً آفلاین هستند (یعنی باید کل دادهها را یکجا ببینند). اما روش SwAV (Swapping Assignments between Views) که در سال ۲۰۲۰ معرفی شد، بازی را عوض کرد.
- نواوری: این روش به صورت «آنلاین کار میکند و امکان مقیاسپذیری روی حجم عظیمی از دادهها را فراهم میکند.
- ایده اصلی: به جای اینکه مستقیماً ویژگیهای دو عکس را با هم مقایسه کند، تخصیص خوشهای آنها را با هم مقایسه میکند تا مطمئن شود نماهای مختلف از یک تصویر، به گروه (خوشه) یکسانی تعلق میگیرند.
د) معماری تعبیه مشترک (Joint Embedding Architecture)
این یک تکنیک قدرتمند است که از یک شبکه دو-شاخهای (Two-branch network) با ساختار یکسان استفاده میکند.
- نحوه کار: دو ورودی (مثلاً دو تصویر کمی متفاوت از یک پرنده در حال پرواز) به دو شاخه جداگانه داده میشوند. هر شاخه یک بردار (Vector) تولید میکند.
- هدف: پارامترهای شبکه طوری تنظیم میشوند که فاصله بین این دو بردار در فضای پنهان (Latent Space) کم شود. یعنی شبکه یاد میگیرد که با وجود تفاوتهای ظاهری، این دو تصویر در اصل یکی هستند.
مقایسه یادگیری خود-نظارتی، نظارتشده و بدون نظارت
یادگیری خود-نظارتی (Self-Supervised Learning) را میتوان فرزند دورگه دنیای هوش مصنوعی دانست! اگرچه از نظر فنی زیرمجموعهای از یادگیری بدون نظارت است (چون نیازی به دادههای برچسبدار ندارد)، اما شباهت عجیبی به یادگیری نظارتشده دارد؛ چرا که هدفش بهینهسازی عملکرد بر اساس یک حقیقت مبنا (Ground Truth) است.
همین جایگاه بینابینی باعث شد تا دانشمندان احساس کنند دستهبندیهای سنتی برای توصیف آن کافی نیستند و نامی جداگانه برایش انتخاب کنند.
ابداع این اصطلاح اغلب به یان لکان (Yann LeCun)، دانشمند برجسته هوش مصنوعی و برنده جایزه تورینگ نسبت داده میشود. او معتقد بود برای جلوگیری از ابهام و جدا کردن این روش از یادگیری کاملاً بدون نظارت (که آن را اصطلاحی گیجکننده میدانست)، به یک نام جدید نیاز داریم. البته ریشههای این مفهوم به مقالهای در سال ۲۰۰۷ برمیگردد و تکنیکهایی مثل Autoencoders سالها قبل از ابداع این نام وجود داشتهاند.
در ادامه تفاوت این روش را با سایر رویکردها بررسی میکنیم.
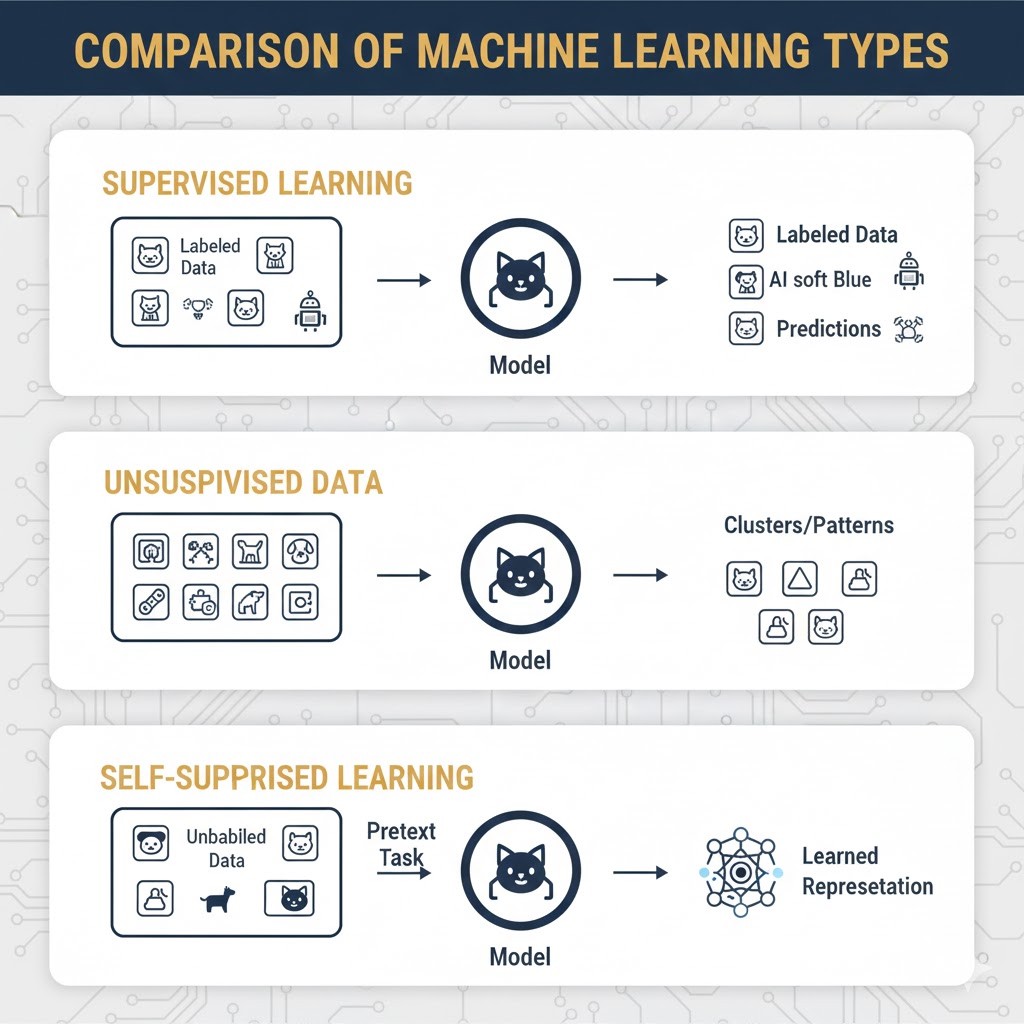
یادگیری خود-نظارتی در برابر یادگیری بدون نظارت
رابطه این دو مثل رابطه مربع و مستطیل است: هر یادگیری خود-نظارتی نوعی یادگیری بدون نظارت است، اما هر یادگیری بدون نظارتی، خود-نظارتی نیست.
شباهتها:
هیچکدام از این دو روش در فرآیند آموزش از برچسب (Label) استفاده نمیکنند. هر دو به دنبال کشف الگوها و روابط درونیِ دادههای خام هستند، نه یادگیری از روی جوابهای آمادهای که انسانها تهیه کردهاند.
تفاوت اصلی: مسئلهی حقیقت مبنا
تفاوت اصلی در هدف و نحوه سنجش موفقیت است:
- یادگیری بدون نظارت (Unsupervised): نتایج را با هیچ حقیقت از پیشتعیینشدهای مقایسه نمیکند.
- مثال: یک سیستم پیشنهاد محصول در فروشگاه اینترنتی را در نظر بگیرید. مدل یاد میگیرد که معمولاً چیپس و ماست با هم خریداری میشوند. اینجا هدف تقلید از پیشبینی انسان نیست، بلکه کشف روابط پنهانی است که شاید حتی انسانها از آن بیخبر باشند.این مدلها معمولاً برای خوشهبندی (Clustering) یا کاهش ابعاد استفاده میشوند و نیازی به تابع زیان (Loss Function) به معنای کلاسیک ندارند.
- یادگیری خود-نظارتی (Self-Supervised): این روش نتایج را با یک حقیقت مبنا میسنجد، اما نکته اینجاست که این حقیقت مبنا از دل خودِ دادهها بیرون میآید.
- این مدلها مثل روشهای نظارتشده، از تابع زیان (Loss Function) و الگوریتمهای کاهش گرادیان (Gradient Descent) استفاده میکنند تا خطا را به حداقل برسانند. به همین دلیل، کاربرد آنها بیشتر در مسائل طبقهبندی و رگرسیون است.
یادگیری خود-نظارتی در برابر یادگیری نظارتشده
اگرچه هر دو روش برای حل مسائل مشابهی استفاده میشوند و هر دو برای بهینهسازی به حقیقت مبنا نیاز دارند، اما منبع این حقیقت متفاوت است.
گلوگاهِ برچسبگذاری (Labeling Bottleneck)
- یادگیری نظارتشده (Supervised): برای آموزش به دادههای برچسبدار نیاز دارد. یعنی یک انسان باید قبلاً جواب درست را به مدل نشان داده باشد. اگرچه این روش دقت بالایی دارد، اما برچسبگذاری حجم عظیم دادهها پرهزینه و زمانبر است.
- مثال: در بینایی ماشین برای وظایفی مثل قطعهبندی نمونه (Instance Segmentation)، انسان باید تکتک پیکسلهای تصویر را با دقت رنگآمیزی و مشخص کند. این کار یک گلوگاه بزرگ در تحقیقات است.
- یادگیری خود-نظارتی: این روش با تکنیکهای خلاقانه، نیاز به برچسب را دور میزند و سیگنالهای نظارتی را از ساختار خودِ داده استخراج میکند.
مثال کاربردی: تکنیک Masking
در مدلهای زبانی (مثل BERT)، مدل بخشی از کلمات یک جمله را پنهان (Mask) میکند و سعی میکند با استفاده از کلمات باقیمانده، کلمه مخفی شده را حدس بزند. اینجا خودِ جمله اصلی (بدون دخالت انسان) به عنوان حقیقت مبنا عمل میکند.
یادگیری خود-نظارتی در برابر یادگیری نیمهنظارتی (Semi-Supervised)
اغلب این دو اصطلاح را با هم اشتباه میگیرند، اما نحوهٔ کار آنها متفاوت است.
- یادگیری خود-نظارتی: به هیچ عنوان از دادههای برچسبخورده توسط انسان استفاده نمیکند.
- یادگیری نیمهنظارتی: ترکیبی از هر دو جهان است. این روش از مقدار کمی دادهی برچسبدار (برای جهتدهی اولیه) و مقدار زیادی دادهی بدون برچسب استفاده میکند.
- مثال: مدل ممکن است با استفاده از چند عکس برچسبدار، یاد بگیرد و سپس خودش برچسبهای بقیه دادههای خام را حدس بزند و فرآیند آموزش را با کل دادهها ادامه دهد.
جدول خلاصه مقایسه
| ویژگی | یادگیری نظارتشده | یادگیری بدون نظارت | یادگیری خود-نظارتی |
| نیاز به برچسب انسانی | بله (زیاد) | خیر | خیر |
| حقیقت مبنا (Ground Truth) | دارد (توسط انسان) | ندارد | دارد (استخراج از داده) |
| کاربرد اصلی | طبقهبندی، رگرسیون | خوشهبندی، کشف الگو | طبقهبندی، رگرسیون |
| مثال | تشخیص چهره | گروهبندی مشتریان | مدلهای زبانی (LLMs) |
کاربردهای یادگیری خود-نظارتی
یادگیری خود-نظارتی (SSL) فقط یک تئوری آزمایشگاهی نیست؛ این تکنولوژی همین حالا هم در حال تغییر دنیای اطراف ماست. بیایید ببینیم کجاها حضور دارد:
۱. بینایی ماشین (Computer Vision)
این تکنولوژی به کامپیوترها چشم میدهد تا تصاویر و ویدیوها را بفهمند. SSL با یادگیری از تصاویر بدون برچسب، بازنماییهای بصری قدرتمندی میسازد.
- کاربرد: بهبود تشخیص اشیاء، تحلیل چهره و درک ویدیو.
- مثال واقعی: در سیستمهای امنیتی هوشمند، دوربینها میتوانند بدون اینکه قبلاً هزاران عکس دزد دیده باشند، رفتارهای مشکوک یا چهرههای ناشناس را در میان جمعیت تشخیص دهند. یا در کارخانهها برای پیدا کردن ایرادات ریز روی خط تولید (بدون نیاز به نمونههای خرابی قبلی).
۲. پردازش زبان طبیعی (NLP)
این معروفترین زمین بازیِ SSL است. مدلهایی مثل BERT و GPT با خواندن متنهای اینترنت، دستور زبان و معنی کلمات را یاد میگیرند.
- کاربرد: ترجمه ماشینی، تحلیل احساسات کاربران و دستهبندی متنها.
- مثال واقعی: چتباتهایی مانند ChatGPT یا Google Translate که متون پیچیدهٔ حقوقی را خلاصه میکنند یا لحن غمگین و شاد کاربران را در نظرات اینستاگرام تشخیص میدهند.
۳. تشخیص گفتار (Speech Recognition)
تبدیل صدا به متن و درک زبان گفتاری به حجم عظیمی از دادهٔ صوتی نیاز دارد؛ یادگیری خودنظارتی (SSL) این امکان را فراهم میکند.
- کاربرد: زیرنویسگذاری خودکار و دستیارهای صوتی.
- مثال واقعی: دستیارهای صوتی مثل Siri یا Alexa که میتوانند لهجههای مختلف و حتی صدای شما را در محیط پر سر و صدا تشخیص دهند، چون روی هزاران ساعت صدای بدون برچسب (پادکستها و ویدیوها) آموزش دیدهاند.
۴. حوزه سلامت و پزشکی (Healthcare)
در پزشکی، دادههای برچسبدار بسیار گران و کمیاب هستند. SSL اینجا فرشته نجات است.
- کاربرد: تحلیل تصاویر پزشکی (X-Ray, MRI) و تشخیص بیماری.
- مثال واقعی: مدلی که روی میلیونها تصویر رادیولوژی برچسبنخورده آموزش دیده و اکنون در تشخیص سرطان ریه در مراحل اولیه عملکردی رقابتی دارد — گاهی با دقتی بالاتر از رادیولوژیستهای تازهکار.
۵. سیستمهای خودران و رباتیک
رباتها و ماشینها باید بتوانند محیط اطرافشان را بدون دخالت انسان درک کنند و تصمیم بگیرند.
- کاربرد: ناوبری (مسیریابی)، درک محیط با سنسورها و تصمیمگیری در شرایط پیشبینینشده.
- مثال واقعی: خودروهای تسلا که در هوای بارانی یا برفی (شرایطی که شاید قبلاً دقیقاً ندیده باشند) لاین خیابان را تشخیص میدهند؛ یا رباتهای انباردار آمازون که مسیرشان را در شلوغی پیدا میکنند.
۶. سیستمهای پیشنهاد دهنده
- توضیح: در پلتفرمهایی که دادههای رفتار کاربر زیاد است اما برچسبی وجود ندارد.
- مثال واقعی Netflix یا Spotify :که بدون اینکه شما مستقیماً بگویید من فیلم علمی-تخیلی دوست دارم، از روی تاریخچه تماشای شما الگوها را میفهمند و فیلم بعدی را پیشنهاد میدهند.
مزایا
این روش چند برگ برنده دارد که آن را از روشهای سنتی جلو میاندازد:
۱. کاهش وابستگی به دادههای برچسبدار (صرفهجویی در پول و زمان) دیگر نیازی نیست تیمی از انسانها ماهها وقت بگذارند تا دادهها را دستی برچسب بزنند. مدل از اقیانوس دادههای خام استفاده میکند.
۲. تعمیمپذیری بهتر (هوشِ منعطف) چون مدل ساختار درونی داده را یاد میگیرد (نه فقط حفظ کردن چند مثال)، وقتی با دادههای جدید و ندیده روبرو میشود، عملکرد بهتری دارد و کمتر گیج میشود.
۳. مقیاسپذیری خیرهکننده (مناسب برای Big Data) این روش خوراکِ کلاندادههاست. هرچه داده بیشتر باشد، مدل باهوشتر میشود، بدون اینکه نگران هزینه برچسبگذاری باشید.
محدودیتها
با تمام این مزایا، SSL هنوز کامل نیست و چالشهایی دارد:
۱. کیفیت سیگنال نظارتی (برچسبهای نویزی) برچسبهایی که خودِ مدل تولید میکند (Pseudo-labels)، ممکن است همیشه دقیق نباشند. اگر مدل اشتباه یاد بگیرد، این اشتباه در کل سیستم پخش میشود و دقت نهایی ممکن است کمتر از روشهای نظارتشده (با برچسب دقیق انسانی) باشد.
۲. محدودیت در طراحی وظایف (Task Restrictions) برای دادههای بسیار پیچیده یا بدون ساختار مشخص، طراحی یک وظیفه ساختگی (Pretext Task) که واقعاً مفید باشد، سخت است. همیشه نمیتوان یک پازل خوب برای یادگیری طراحی کرد.
۳. پیچیدگی آموزش و هزینه محاسباتی آموزش این مدلها (مخصوصاً روشهای تقابلی) به سختافزارهای قدرتمند (GPUهای قوی) و تنظیمات بسیار دقیق نیاز دارد. این یعنی هزینه برق و سرور بالاست.
۴. تقویت سوگیریها : چون این مدلها روی دادههای خام اینترنت (که پر از تعصبات انسانی است) آموزش میبینند، ممکن است نژادپرستی، تبعیض جنسیتی یا اطلاعات غلط را هم به عنوان الگو یاد بگیرند و بازتولید کنند.
نتیجه گیری
یادگیری خود-نظارتی را میتوان یکی از مهمترین تحولات سالهای اخیر در دنیای یادگیری ماشین دانست؛ رویکردی که وابستگی به دادههای برچسبدار را به حداقل میرساند و امکان استفادهی حداکثری از دادههای خام و فراوان را فراهم میکند. با طراحی وظایف ساختگی و استخراج حقیقت مبنا از خود دادهها، مدلها قادر میشوند بازنماییهای عمیق، معنادار و قابل تعمیم یاد بگیرند.
این روش بهویژه در مقیاسهای بزرگ و در پروژههایی که برچسبگذاری دشوار یا غیرممکن است، مزیت رقابتی چشمگیری ایجاد میکند. موفقیت مدلهای زبانی بزرگ، سیستمهای تشخیص تصویر، تحلیل گفتار و حتی کاربردهای پزشکی، نشان میدهد که یادگیری خود-نظارتی صرفاً یک ایده تئوریک نیست، بلکه ستون اصلی بسیاری از سیستمهای هوش مصنوعی مدرن است.
با وجود چالشهایی مانند هزینهٔ محاسباتی بالا، حساسیت به طراحی وظایف و احتمال بازتولید سوگیریهای موجود در داده، نمیتوان آیندهٔ هوش مصنوعی را بدون یادگیری خودنظارتی تصور کرد. در نهایت، هر جایی دادهٔ خام فراوان اما برچسب اندکی در دسترس باشد، یادگیری خودنظارتی هوشمندانهترین راهبرد برای ساخت مدلهای دقیق، مقیاسپذیر و آیندهمحور است.