

یادگیری ماشین (Machine Learning) یکی از تکنیکهای هوش مصنوعی است که به کامپیوترها آموزش میدهد چطور دقیقاً مثل انسان، از تجربیات خود درس بگیرند.
در این روش، الگوریتمها به جای اینکه منتظر فرمولها یا معادلات از پیش تعیینشده باشند، مستقیماً به دلِ دادهها میروند و اطلاعات را از آنها «یاد میگیرند». ویژگی اصلی این الگوریتمها این است که هرچه دادهها و نمونههای بیشتری در اختیارشان قرار دهید، باهوشتر میشوند و عملکردشان به مرور زمان بهتر میشود.
نکته: یادگیری عمیق (Deep Learning) هم در واقع شاخهای تخصصی و پیشرفتهتر از همین یادگیری ماشین است.
یادگیری ماشین چطور کار میکند؟
یادگیری ماشین برای یادگیری از دو روش یا تکنیک اصلی استفاده میکند: یادگیری نظارتشده (Supervised Learning) که در آن مدل با استفاده از دادههای ورودی و خروجیِ مشخص آموزش میبیند تا بتواند نتایج آینده را پیشبینی کند، و یادگیری بدون نظارت (Unsupervised Learning) که به دنبال کشف الگوهای پنهان یا ساختارهای درونی در دادههای ورودی است.
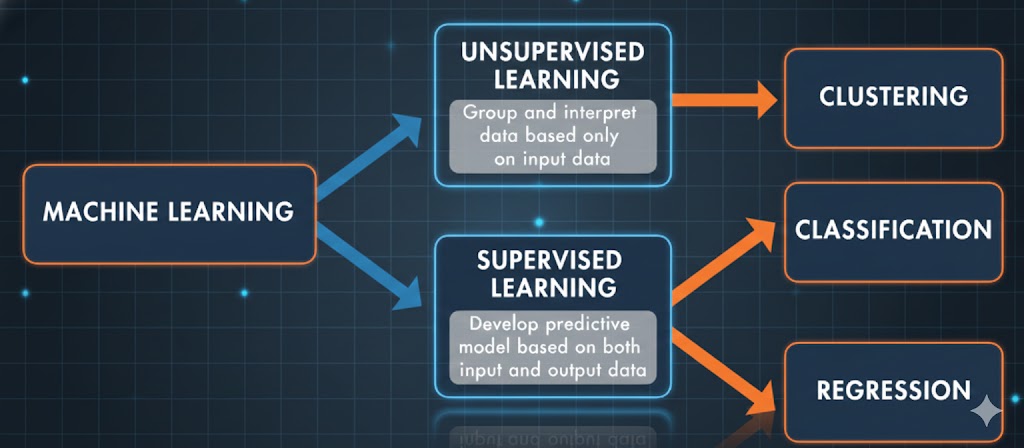
شکل ۱. تکنیکهای یادگیری ماشین شامل هر دو روش «یادگیری نظارتشده» و «یادگیری بدون نظارت» میشود.
یادگیری نظارتشده (Supervised Learning)
در یادگیری ماشین نظارتشده، ما مدلی میسازیم که بتواند بر اساس شواهد موجود، پیشبینی کند (حتی زمانی که عدم قطعیت وجود دارد). روش کار اینگونه است: یک الگوریتم یادگیری نظارتشده، مجموعهای از دادههای ورودی را به همراه پاسخهای صحیح آنها (خروجی) دریافت میکند. سپس مدلی را آموزش میدهد تا بتواند پاسخ درست را برای دادههای جدیدی که تا به حال ندیده است، پیشبینی کند.
قانون کلی: هر وقت دادههایی دارید که جواب نهاییشان را میدانید و میخواهید خروجی موارد مشابه را پیشبینی کنید، باید از یادگیری نظارتشده استفاده کنید.
یادگیری نظارتشده برای ساخت مدلهای خود عمدتاً از دو تکنیک استفاده میکند: طبقهبندی (Classification) و رگرسیون (Regression).
۱. تکنیکهای طبقهبندی (Classification)
این تکنیکها پاسخهای گسسته (دستهبندی شده) را پیشبینی میکنند.
- مثال: تشخیص اینکه آیا یک ایمیل «اسپم» است یا «واقعی»؟ یا اینکه آیا یک تومور «سرطانی» است یا «خوشخیم»؟
مدلهای طبقهبندی، دادههای ورودی را در گروهها یا دستههای مشخصی قرار میدهند. کاربردهای رایج آن شامل تصویربرداری پزشکی، تشخیص گفتار و امتیازدهی اعتباری (Credit Scoring) است.
چه زمانی از طبقهبندی استفاده کنیم؟
زمانی که دادههای شما قابلیت برچسبگذاری، دستهبندی یا تفکیک شدن به گروههای خاص را دارند. برای مثال، برنامههای تشخیص دستخط از طبقهبندی استفاده میکنند تا بفهمند یک شکل خاص، کدام حرف یا عدد است. (البته در حوزههایی مثل پردازش تصویر و بینایی ماشین، گاهی برای تشخیص اشیاء از تکنیکهای شناسایی الگوی بدون نظارت هم استفاده میشود).
۲. تکنیکهای رگرسیون (Regression)
این تکنیکها پاسخهای پیوسته (اعداد و مقادیر) را پیشبینی میکنند.
- مثال: پیشبینی کمیتهایی که اندازهگیریشان سخت است، مثل «میزان دقیق شارژ باتری»، «بار الکتریکی شبکه برق» یا «قیمت داراییهای مالی».
کاربردهای رایج شامل حسگرهای مجازی، پیشبینی مصرف برق و معاملات الگوریتمی در بورس است.
چه زمانی از رگرسیون استفاده کنیم؟
اگر با دامنهای از دادهها سر و کار دارید یا ماهیت پاسخ شما یک «عدد واقعی» است (مثل دما یا مدت زمان باقیمانده تا خرابی یک دستگاه)، باید از تکنیکهای رگرسیون استفاده کنید.
یادگیری بدون نظارت (Unsupervised Learning)
یادگیری بدون نظارت دقیقاً مثل کشف رمز است؛ هدف آن پیدا کردن الگوهای پنهان یا ساختارهای درونی در دادههاست. این روش زمانی استفاده میشود که ما فقط دادههای ورودی را داریم، اما هیچ جواب یا برچسب مشخصی (Labeled Responses) برای آنها وجود ندارد و سیستم باید خودش منطق پشت دادهها را استخراج کند.
– خوشهبندی(Clustering)
رایجترین تکنیک در یادگیری بدون نظارت، «خوشهبندی» است. از این تکنیک برای تحلیل اکتشافی دادهها استفاده میشود تا گروهبندیها یا الگوهایی که در نگاه اول دیده نمیشوند، آشکار شوند. کاربردهای تحلیل خوشهای بسیار گسترده است؛ از تحلیل ژنتیک (توالی ژنها) و تحقیقات بازار گرفته تا تشخیص اشیاء.
یک مثال کاربردی: فرض کنید یک شرکت مخابراتی میخواهد مکان نصب دکلهای آنتندهی خود را بهینه کند. آنها میتوانند از یادگیری ماشین استفاده کنند تا ببینند مشتریانشان در کدام مناطق تجمع کردهاند (تخمین خوشههای جمعیتی). از آنجا که هر گوشی موبایل در هر لحظه فقط میتواند به یک دکل وصل شود، تیم فنی با استفاده از الگوریتمهای خوشهبندی، بهترین مکانها را برای نصب دکل طراحی میکند. نتیجه این کار، دریافت سیگنال عالی برای گروهها (خوشهها)ی مختلف مشتریان خواهد بود.
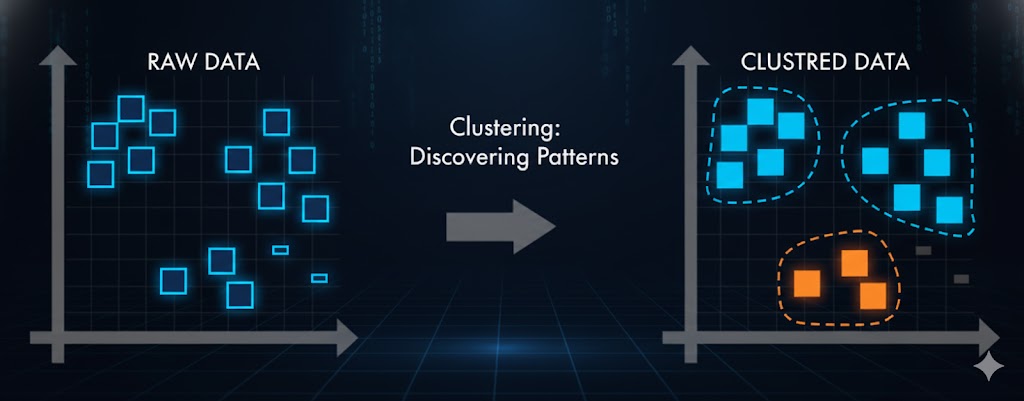
شکل ۲. تکنیک خوشهبندی، الگوهای پنهان را در دادههای شما پیدا میکند.
چطور الگوریتم مناسب یادگیری ماشین را انتخاب کنیم؟
انتخاب الگوریتم درست ممکن است در نگاه اول کمی ترسناک و گیجکننده به نظر برسد؛ دلیلش هم روشن است: دهها الگوریتم مختلف (چه نظارتشده و چه بدون نظارت) وجود دارند که هر کدام با سبک و سیاق متفاوتی یاد میگیرند.
نکته مهم اینجاست که هیچ «بهترین روش مطلقی» وجود ندارد و نمیتوان یک نسخه واحد را برای همه مسائل پیچید. پیدا کردن الگوریتم مناسب، تا حد زیادی به آزمون و خطا وابسته است. جالب است بدانید که حتی دانشمندان دادهی بسیار باتجربه هم نمیتوانند بدون تست کردن، با اطمینان بگویند که آیا یک الگوریتم خاص روی دادههای شما جواب میدهد یا نه.
با این حال، انتخاب الگوریتم به چند فاکتور کلیدی دیگر هم بستگی دارد:
- حجم و نوع دادههایی که با آن کار میکنید.
- بینش و نتیجهای که میخواهید از دادهها استخراج کنید.
- و اینکه قرار است از این نتایج در نهایت چگونه استفاده شود.
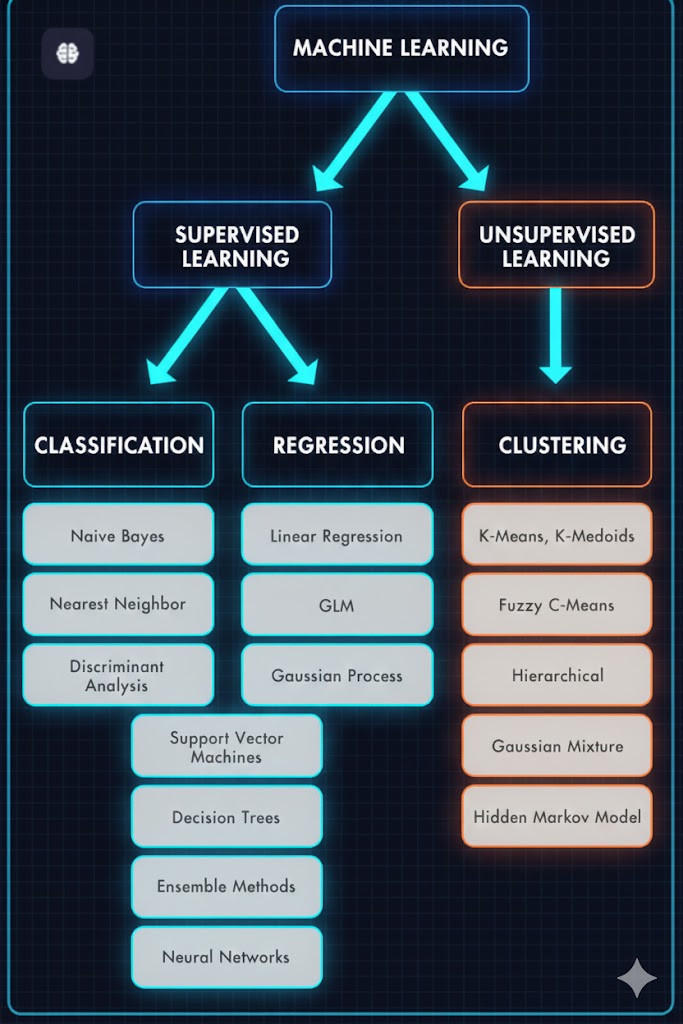
شکل ۳. انواع تکنیکها و روشهای یادگیری ماشین.
در اینجا چند راهنمای کاربردی برای انتخاب بین این دو روش آورده شده است:
۱. چه زمانی یادگیری نظارتشده (Supervised) را انتخاب کنیم؟ اگر هدف اصلی شما آموزش مدلی است که بتواند پیشبینی کند، باید سراغ این روش بروید.
- مثلاً پیشبینی مقدار آینده یک متغیر (مثل دمای هوا یا قیمت سهام).
- یا انجام طبقهبندی (Classification)؛ مثلاً اینکه سیستم بتواند از روی تصویر دوربین وبکم، تشخیص دهد که سازنده یک خودرو کیست.
۲. چه زمانی «یادگیری بدون نظارت» (Unsupervised) را انتخاب کنیم؟ اگر نیاز دارید در دادههایتان کاوش کنید و ساختار پنهان آنها را بفهمید، این روش مناسب شماست.
- در اینجا هدف پیدا کردن یک بازنمایی درونی خوب از دادههاست؛ مثل زمانی که میخواهید دادههای درهمریخته را به گروههای منظم و شبیه به هم (خوشهها) تقسیم کنید.
چرا یادگیری ماشین (Machine Learning) اینقدر مهم است؟
با انفجار «کلاندادهها» (Big Data)، یادگیری ماشین از یک تکنولوژی لوکس به ابزاری حیاتی برای حل چالشهای بزرگ تبدیل شده است. امروزه ردپای این فناوری را در صنایع کلیدی میبینیم، از جمله:
- صنعت خودروسازی
- هوافضا و صنایع دفاعی
- تحلیل فرآیندهای تولید
- تجهیزات پزشکی
- پردازش سیگنال
دادههای بیشتر، پاسخهای دقیقتر
الگوریتمهای یادگیری ماشین، متخصص پیدا کردن الگوهای طبیعی و پنهان در دادهها هستند؛ الگوهایی که با چشم غیرمسلح دیده نمیشوند. این الگوها به شما بینشی میدهند که بتوانید تصمیمات هوشمندانهتر بگیرید و آینده را دقیقتر پیشبینی کنید.
همین حالا، تصمیمات حیاتی دنیا بر پایه این تکنولوژی گرفته میشود:
- در پزشکی برای تشخیص بیماریها.
- در بورس برای خرید و فروش سهام.
- در انرژی برای پیشبینی بار مصرفی برق.
یک مثال ملموس: سایتهای پخش مدیا (مثل نتفلیکس یا اسپاتیفای) چطور دقیقاً همان چیزی را پیشنهاد میدهند که دوست دارید؟ آنها با کمک یادگیری ماشین، میلیونها گزینه را غربال میکنند تا سلیقه شما را حدس بزنند. فروشگاههای بزرگ هم با همین روش میفهمند مشتریانشان دقیقاً چه چیزی و کِی میخرند.
مثال های واقعی از کاربردهای یادگیری ماشین
یادگیری ماشین دیگر آن بچه درسخوانی نیست که گوشه اتاق فقط با اعداد بازی میکرد؛ حالا وارد میدان شده، خلاقیت به خرج میدهد و با ما حرف میزند:
- هوش مصنوعی مولد (Generative AI):خالقهای دیجیتال ابزارهایی مثل ChatGPT و Midjourney فقط دادهها را دستهبندی نمیکنند، بلکه “خلق” میکنند. آنها از مدلهای پیشرفته یادگیری ماشین استفاده میکنند تا شعری بگویند که هرگز سروده نشده، یا تصویری بکشند که هرگز وجود نداشته است. این یعنی گذار از تکرار به نوآوری.
- رانندگی خودکار: چشمان بیدار تسلا شرکتهایی مثل تسلا به خودروها «بینایی» دادهاند. الگوریتمهای یادگیری ماشین در این خودروها، میلیونها فریم ویدیویی را در ثانیه میبلعند تا فرق بین یک کودک، یک درخت و چراغ قرمز را تشخیص دهند. اینجا هوش مصنوعی فقط راننده نیست، بلکه فرشته نجاتی است که هرگز پلک نمیزند.
- دستیارهای صوتی: فراتر از یک ضبط صوت وقتی با Siri یا Google Assistant درددل میکنید، این یادگیری ماشین است که صدای شما را میشنود، به متن تبدیل میکند و از همه مهمتر، “معنای” پشت کلمات شما را میفهمد تا پاسخی هوشمندانه بدهد.
مطالعات موردی
بیایید ببینیم شرکتهای بزرگ چگونه با استفاده از یادگیری ماشین، بازی را تغییر دادهاند:
1. آمازون (Amazon): فروشندهای که ذهنخوانی میکند
غول خردهفروشی جهان، آمازون، بخش عظیمی از درآمدش را مدیون جمله معروف “کسانی که این را خریدند، آن را هم خریدند“ است. تخمین زده میشود که ۳۵ درصد از کل فروش آمازون ناشی از موتور توصیهگر آن است. این یعنی یادگیری ماشین با تحلیل سبد خرید میلیونها نفر، نیاز شما را قبل از اینکه خودتان بدانید، تشخیص میدهد.
2. اسنپ (Snapp): قیمتگذاری هوشمند در ایران 🇮🇷
یک مثال ملموس در کشور خودمان، سیستم «قیمتگذاری پویا» در تاکسیهای اینترنتی مثل اسنپ است. تا حالا فکر کردهاید چرا قیمت یک مسیر ثابت در ساعت ۵ عصر با ۱۰ شب فرق دارد؟ اینجا هیچ اپراتوری قیمت را دستی بالا و پایین نمیکند. این الگوریتمهای یادگیری ماشین هستند که همزمان فاکتورهایی مثل «حجم ترافیک»، «تعداد مسافران منتظر»، «تعداد رانندگان موجود» و حتی «وضعیت آبوهوا» را تحلیل میکنند تا قیمت تعادلی را در لحظه محاسبه کنند. این هوش مصنوعی است که تلاش میکند تعادلی بین راضی نگه داشتن راننده و مسافر ایجاد کند.
کِی باید از یادگیری ماشین استفاده کنیم؟
هر وقت با مسئلهای پیچیده روبرو شدید که ویژگیهای زیر را داشت، بهترین راه حل «یادگیری ماشین» است:
- حجم عظیمی از داده دارید.
- با تعداد زیادی متغیر سر و کار دارید.
- و مهمتر از همه: هیچ فرمول یا معادله مشخصی برای حل آن وجود ندارد.
تفاوت یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning) چیست؟
یادگیری عمیق در واقع یک شاخه تخصصی و پیشرفته از همان یادگیری ماشین است. اما تفاوت اصلی آنها در نحوه برخورد با دادههاست:
۱. در یادگیری ماشین (روش معمول): همه چیز با دخالت انسان شروع میشود. در این روش، شما باید ویژگیهای مهم (Relevant Features) را بهصورت دستی از تصاویر یا دادهها استخراج کنید. سپس این ویژگیهای دستچین شده را به مدل میدهید تا بتواند اشیاء را دستهبندی کند.
۲. در یادگیری عمیق (Deep Learning):داستان کاملاً متفاوت است؛ استخراج ویژگیها بهصورت خودکار انجام میشود. یادگیری عمیق فرآیندی به نام «یادگیری انتها-به-انتها» (End-to-End Learning) را اجرا میکند. یعنی شما فقط دادههای خام (مثل یک عکس) را به شبکه میدهید و وظیفه (مثلاً دستهبندی) را مشخص میکنید. شبکه خودش به صورت خودکار یاد میگیرد که چه ویژگیهایی مهم هستند و چگونه باید کار را انجام دهد، بدون اینکه نیاز باشد شما ویژگیها را دستی تعریف کنید.

شکل ۴. مقایسه دو رویکرد متفاوت برای دستهبندی خودروها: سمت چپ روش یادگیری ماشین (که نیاز به استخراج دستی ویژگیها دارد) و سمت راست روش یادگیری عمیق (که ویژگیها را خودکار یاد میگیرد) را نشان میدهد.
در یادگیری ماشین، شما باید به صورت دستی ویژگیهای مهم را انتخاب کنید و یک دستهبندیکننده (Classifier) بسازید تا بتوانید تصاویر را مرتب کنید. اما در یادگیری عمیق، داستان متفاوت است؛ مراحل «استخراج ویژگی» و «مدلسازی» همگی به صورت خودکار انجام میشوند.
دوراهی انتخاب: یادگیری ماشین یا یادگیری عمیق؟
یادگیری ماشین دست شما را باز میگذارد؛ طیف وسیعی از تکنیکها و مدلها وجود دارد که میتوانید بسته به نوع پروژهتان، حجم دادهها و ماهیت مسئلهای که میخواهید حل کنید، یکی را انتخاب کنید.
اما موفقیت در یک پروژه «یادگیری عمیق» شرط و شروطی دارد:
- دادههای بسیار زیاد: به حجم عظیمی از داده (مثلاً هزاران تصویر) برای آموزش مدل نیاز دارید.
- سختافزار قدرتمند: حتماً به پردازندههای گرافیکی (GPU) نیاز دارید تا بتوانید این حجم از اطلاعات را با سرعت بالا پردازش کنید.
کدام را انتخاب کنیم؟
موقع انتخاب، اول به امکاناتتان نگاه کنید. آیا GPUهای قدرتمند و انبوهی از دادههای برچسبدار در اختیار دارید؟ اگر جوابتان به هر دو «نه» است، منطقیتر است که دور یادگیری عمیق را خط بکشید و سراغ همان یادگیری ماشین بروید. یادگیری عمیق ذاتاً پیچیدهتر است و برای اینکه نتایجش قابل اعتماد باشد، حداقل باید چند هزار تصویر خوراک به آن بدهید.
مزیت انتخاب یادگیری ماشین: اگر یادگیری ماشین را انتخاب کنید:
- گزینههای زیادی روی میز دارید و میتوانید مدلتان را با روشهای دستهبندی (Classifiers) مختلف آموزش دهید.
- چون خودتان ویژگیها را انتخاب میکنید، میتوانید دقیقاً روی ویژگیهایی دست بگذارید که میدانید بهترین نتیجه را میدهند.
- انعطافپذیری بالایی دارید؛ میتوانید مدلها و ویژگیهای مختلف را با هم ترکیب و تست کنید تا ببینید کدام چیدمان برای دادههای خاص شما، بهترین خروجی را میسازد.