

مقدمه
هوش مصنوعی در سالهای اخیر، جهشی باورنکردنی را تجربه کرده است. امروزه دیگر فقط با ماشینهای محاسباتی طرف نیستیم؛ بلکه با سیستمهایی روبهروایم که میبینند، میشنوند، مینویسند و حتی در دوراهیهای سخت، تصمیم میگیرند.
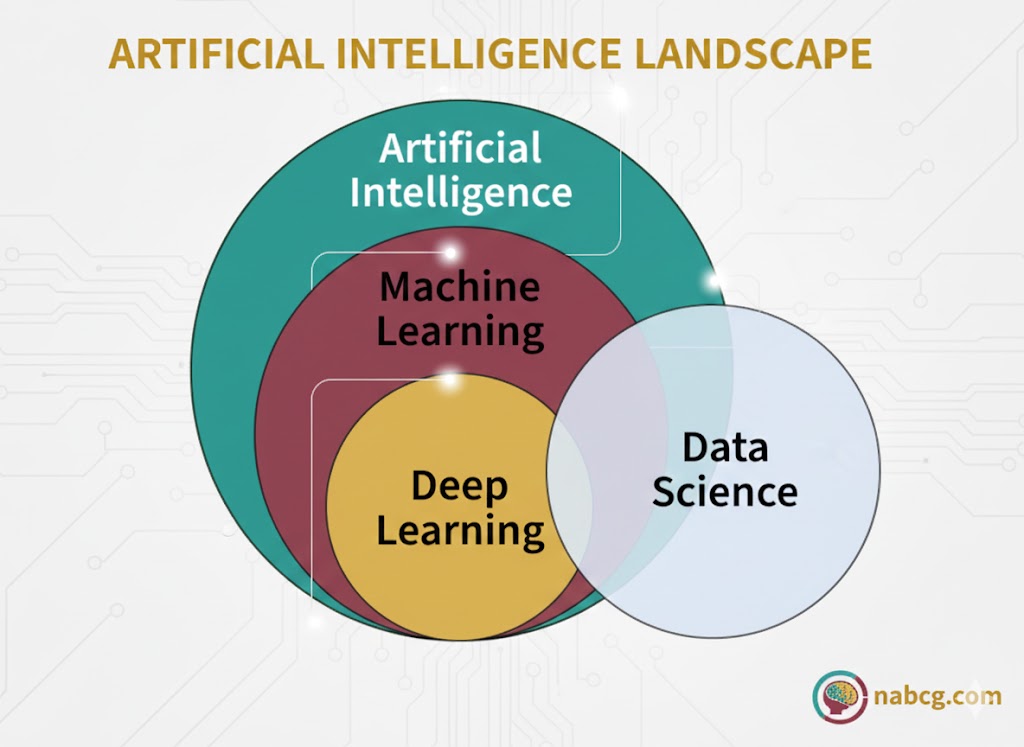
اما قهرمان اصلی در پشت صحنهی تمام این شگفتیها، یادگیری عمیق (Deep Learning) است. فناوری قدرتمندی که قواعد بازی را تغییر داده و زیربنای هوش مصنوعی مدرن را ساخته است.
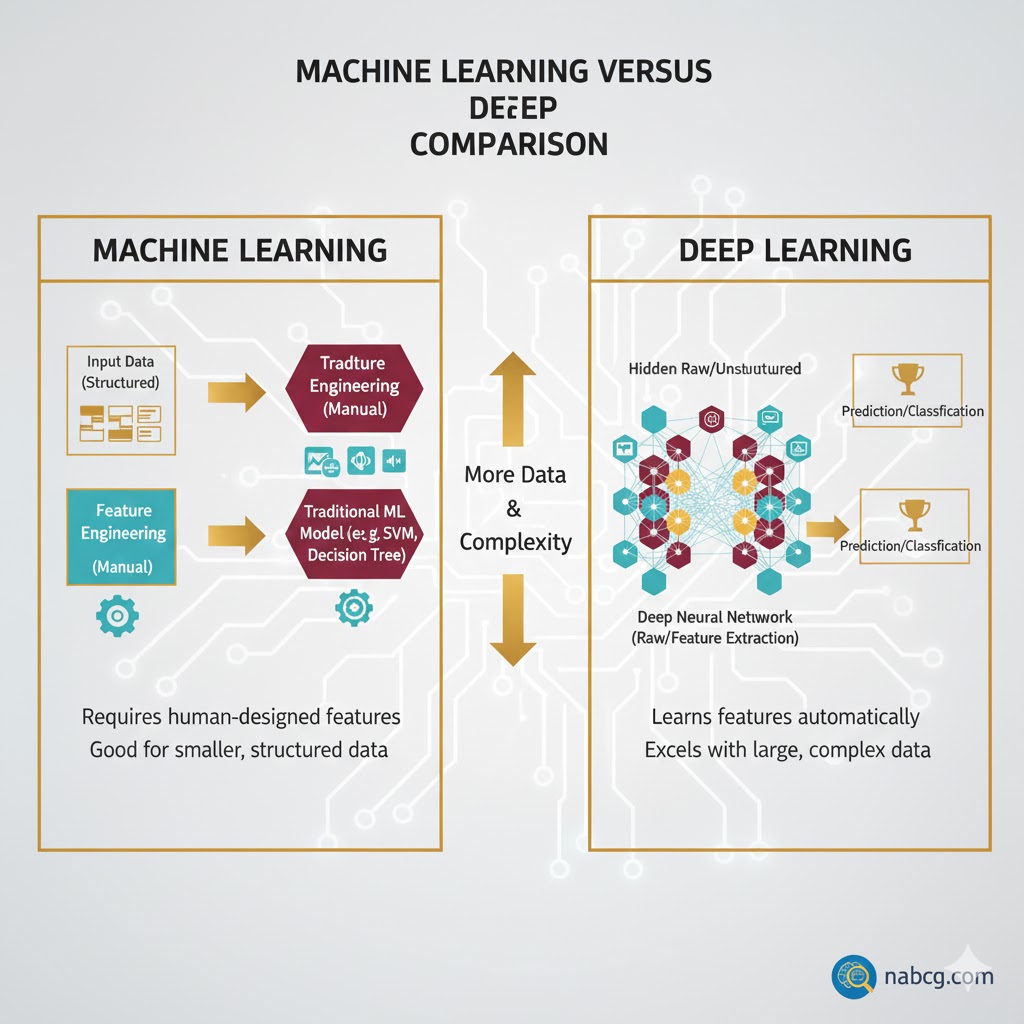
تفاوت اصلی کجاست؟ برخلاف روشهای سنتی که انسان باید ویژگیها را دستی به سیستم میداد، یادگیری عمیق مستقل عمل میکند. این تکنولوژی تلاش میکند الگوها را مستقیماً از دلِ دادههای خام بیرون بکشد.
همین ویژگی باعث شده تا در حل مسائل پیچیده با حجم دادهی بالا—مثل تشخیص تصویر، درک زبان انسان و گفتار—عملکردی خیرهکننده داشته باشد. به همین دلیل، امروز به یکی از ستونهای اصلی هوش مصنوعی تبدیل شده است.
در این مقاله چه خواهیم خواند؟ در ادامه، ابتدا تعریف دقیقی از یادگیری عمیق ارائه میدهیم. سپس منطق عملکرد آن را بررسی میکنیم و در نهایت، جایگاه آن را در مقایسه با سایر روشهای یادگیری ماشین مشخص خواهیم کرد.
تعریف
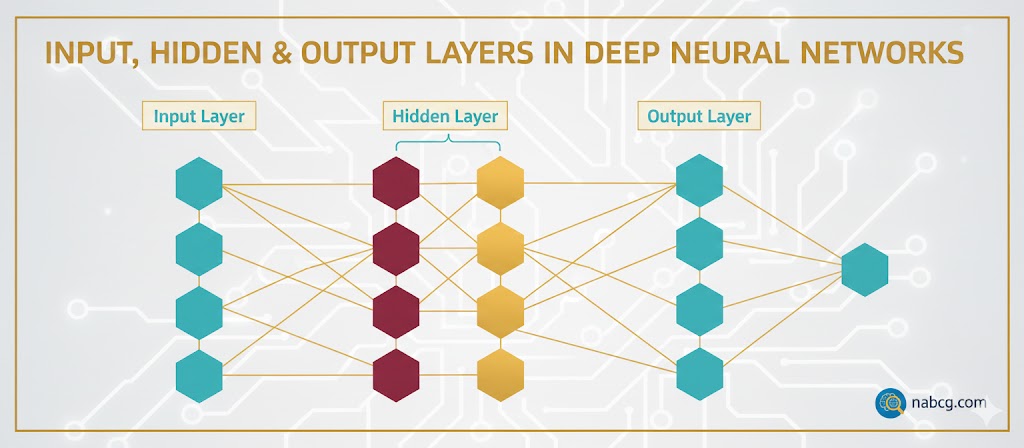
یادگیری عمیق شاخهای از یادگیری ماشین است که از شبکههای عصبی مصنوعی با لایههای متعدد (Deep Neural Networks) برای یادگیری الگوهای پیچیده از دادهها استفاده میکند. این شبکهها با الهام از ساختار مغز انسان طراحی شدهاند و قادرند دادهها را بهصورت سلسلهمراتبی پردازش کنند؛ به این معنا که هر لایه، ویژگیهای پیچیدهتری نسبت به لایه قبل استخراج میکند.
یادگیری عمیق چگونه کار میکند؟
یادگیری عمیق شاید اولین نگاه پیچیده باشد، اما اساس کار آن بسیار شبیه به یک تیم ورزشی هماهنگ است.
شبکههای عصبی از چندین لایه تشکیل شدهاند که در آنها گرهها (Nodes) یا همان نورونهای مصنوعی به هم متصل هستند. درست مثل اعضای یک تیم فوتبال که توپ را پاسکاری میکنند تا به گل برسند، این نورونها هم با همکاری یکدیگر دادههای ورودی را پردازش میکنند تا به نتیجه نهایی برسند.
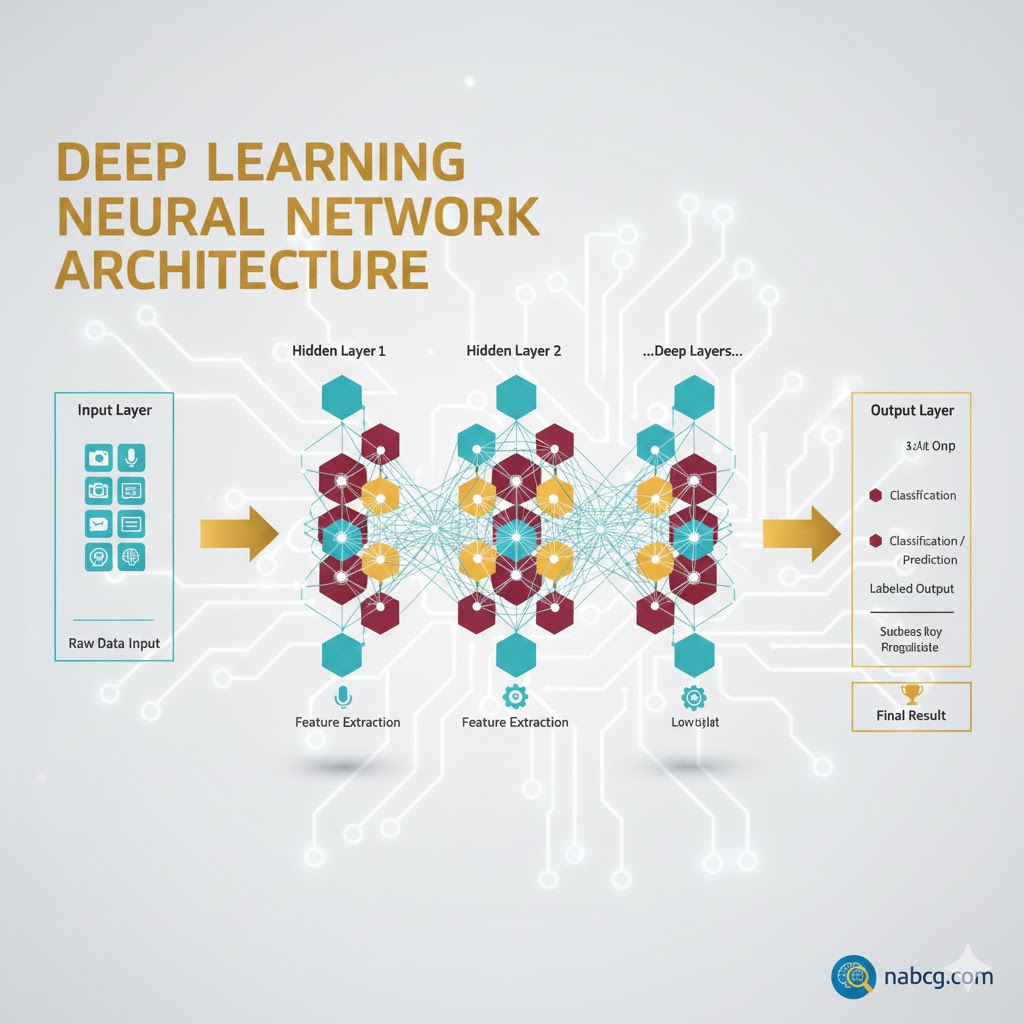
در یک شبکهٔ عصبی عمیق تماممتصل (Fully Connected)، دادهها مانند جریان آب از لایهای به لایهٔ دیگر جریان مییابند. نکتهٔ کلیدی این است که هر نورون یک تبدیل غیرخطی (non-linear transformation) روی ورودی خود اعمال میکند.
💡 چرا غیرخطی؟ اگر همه چیز خطی بود، کامپیوتر فقط میتوانست خطهای صاف را بفهمد! همین ویژگی «غیرخطی بودن» است که به مدل اجازه میدهد پیچیدهترین الگوها (مثل انحنای لبخند در یک عکس یا لحن طعنهآمیز در یک متن) را درک کند.
جریان دادهها در شبکه عصبی
۱. لایه ورودی (Input Layer)؛ دروازه ورود این لایه دادههای خام را تحویل میگیرد. هیچ پردازشی اینجا انجام نمیشود، فقط مشاهده است.
- مثال: وقتی به عکس یک گل نگاه میکنید، این لایه فقط پیکسلهای رنگی و نوری را دریافت میکند.
۲. لایههای پنهان (Hidden Layers)؛ کارخانه پردازش جادوی اصلی اینجا رخ میدهد! دادهها از این لایهها عبور میکنند و با استفاده از توابع ریاضی پیچیده و غیرخطی، تغییر شکل میدهند تا ویژگیهایشان استخراج شود.
- مثال: در همان عکس گل، لایه اول خطوط ساقه را میشناسد، لایه بعدی شکل گلبرگها را تشخیص میدهد و لایه آخر بافت رنگی آن را تحلیل میکند.
۳. لایه خروجی (Output Layer)؛ قضاوت نهایی نتیجه تمام پردازشها به این لایه میرسد تا پیشبینی نهایی تولید شود.
- مثال: شبکه با اطمینان اعلام میکند: «این عکس یک گل رز قرمز است» (نه یک لاله).
تفاوت یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning)؛ نبرد هوشها 🤖🧠
یادگیری ماشین (ML) و یادگیری عمیق (DL) هر دو فرزندان خانواده بزرگ هوش مصنوعی (AI) هستند. با اینکه این دو شباهتهای زیادی دارند، اما تفاوتهای بنیادین آنهاست که تعیین میکند برای چه پروژهای سراغ کدامیک برویم.
در ادامه، این تفاوتها را در جنبههای مختلف بررسی میکنیم.
۱. ایده اصلی
- یادگیری ماشین: بر پایه الگوریتمهای آماری و ریاضی بنا شده است تا الگوها را از دادهها یاد بگیرد. (مثل پیدا کردن خطی که نقاط نمودار را به هم وصل میکند).
- یادگیری عمیق با الهام از ساختار مغز انسان طراحی شده است و از شبکههای عصبی مصنوعی چندلایه برای درک الگوهای پیچیده در دادهها بهره میبرد.
۲. نیاز به داده
- یادگیری ماشین: با دادههای کم تا متوسط هم کارش راه میافتد و نتایج خوبی میدهد.
- یادگیری عمیق مانند یک موتور جت عمل میکند: برای رسیدن به عملکردی دقیق و پرقدرت، به سوختی فراوان نیاز دارد — و آن سوخت، دادهٔ حجیم (Big Data) است.
۳. استخراج ویژگی
- یادگیری ماشین: ویژگیها باید دستی انتخاب شوند.
- مثال: برای تشخیص “سیب”، شما باید به سیستم بگویید: “دنبال جسم گرد و قرمز باش”. اگر ویژگیها را اشتباه تعریف کنید، مدل شکست میخورد.
- یادگیری عمیق: ویژگیها به صورت خودکار استخراج میشوند.
- مثال: شما فقط هزاران عکس سیب به مدل میدهید. خودش لایهبهلایه یاد میگیرد که لبهها، رنگ و شکل سیب چه ویژگیهایی دارند.
۴. سختافزار مورد نیاز
- یادگیری ماشین: سبک است و روی CPU (حتی لپتاپ معمولی) اجرا میشود.
- یادگیری عمیق: محاسبات سنگین ماتریسی دارد و به GPU (کارت گرافیک قدرتمند) و سیستمهای با عملکرد بالا نیاز دارد.
۵. فرآیند یادگیری و زمان آموزش (Training)
- یادگیری ماشین:
- زمان آموزش کوتاه است (چند دقیقه تا چند ساعت).
- معمولاً فرآیند یادگیری به قطعات مجزا تقسیم میشود (Not end-to-end).
- یادگیری عمیق:
- زمان آموزش طولانی است (چند روز تا چند هفته).
- یادگیری به صورت End-to-End است؛ یعنی داده خام وارد میشود و نتیجه نهایی خارج میشود، بدون دخالت مرحلهبهمرحله انسان.
۶. تفسیرپذیری (Interpretability)
- یادگیری ماشین: شفاف است. شما میفهمید چرا مدل تصمیم گرفت (مثلاً چون وزن این متغیر بالا بود).
- یادگیری عمیق: مثل یک جعبه سیاه است. حتی سازندگانش هم دقیقاً نمیدانند داخل میلیونها لایه عصبی چه میگذرد و چرا مدل به این نتیجه خاص رسیده است.
جدول مقایسه
| جنبه مقایسه | یادگیری ماشین (Machine Learning) | یادگیری عمیق (Deep Learning) |
| ایده پایه | استفاده از الگوریتمهای آماری برای یافتن الگوها | استفاده از شبکههای عصبی مصنوعی (تقلید از مغز) |
| نیاز به داده | با دادههای کم و متوسط خوب کار میکند | تشنهی داده است (نیاز به حجم بالا دارد) |
| پیچیدگی وظایف | مناسب برای کارهای ساده و دادههای ساختاریافته (جداول) | عالی برای کارهای پیچیده (تصویر، صدا، متن) |
| زمان آموزش | کوتاه و سریع | طولانی و زمانبر |
| استخراج ویژگی | دستی (توسط انسان انجام میشود) | خودکار (توسط مدل یاد گرفته میشود) |
| فرآیند یادگیری | معمولاً مرحلهبهمرحله است | یکپارچه و انتها-به-انتها (End-to-end) |
| پیچیدگی مدل | سادهتر | بسیار پیچیده (چند لایه) |
| تفسیرپذیری | شفاف و قابل فهم | دشوار و مبهم (جعبه سیاه) |
| سختافزار | روی CPU معمولی اجرا میشود | نیاز به GPU و پردازش موازی دارد |
| مثال کاربردی | تشخیص اسپم ایمیل، سیستمهای توصیهگر ساده (مثل پیشنهاد موزیک) | خودروهای خودران، تشخیص چهره، چتباتهای پیشرفته (مثل ChatGPT) |
تکامل معماریهای عصبی 🧬🤖
برای اینکه قدرت یادگیری عمیق امروزی را درک کنیم، باید به گذشته سفر کنیم و ببینیم این مغزهای مصنوعی چطور از یک «سلول ساده» به «شبکههای پیچیده» تبدیل شدند. این داستانِ تکامل است.
۱. پرسپترون (Perceptron)؛ دهه ۱۹۵۰ میلادی
همه چیز با پرسپترون شروع شد. میتوان آن را «پدربزرگ» تمام شبکههای عصبی امروزی دانست.
- ساختار: بسیار ساده! فقط یک لایه داشت (ورودی مستقیماً به خروجی وصل میشد).
- قدرت: مثل یک خطکش بود. فقط میتوانست مسائل ساده و خطی را حل کند.
- مثال: اگر بخواهید سیبهای قرمز و سبز را که جدا از هم روی میز هستند با یک خط صاف جدا کنید، پرسپترون موفق میشود.
- شکست بزرگ (مسئلهXOR): اما اگر سیبها قاطی باشند و نتوان با یک خط صاف آنها را جدا کرد (مسائل غیرخطی مثلXOR)، پرسپترون کاملاً گیج میشد و شکست میخورد. همین محدودیت باعث شد هوش مصنوعی برای مدتی به «زمستان» برود.
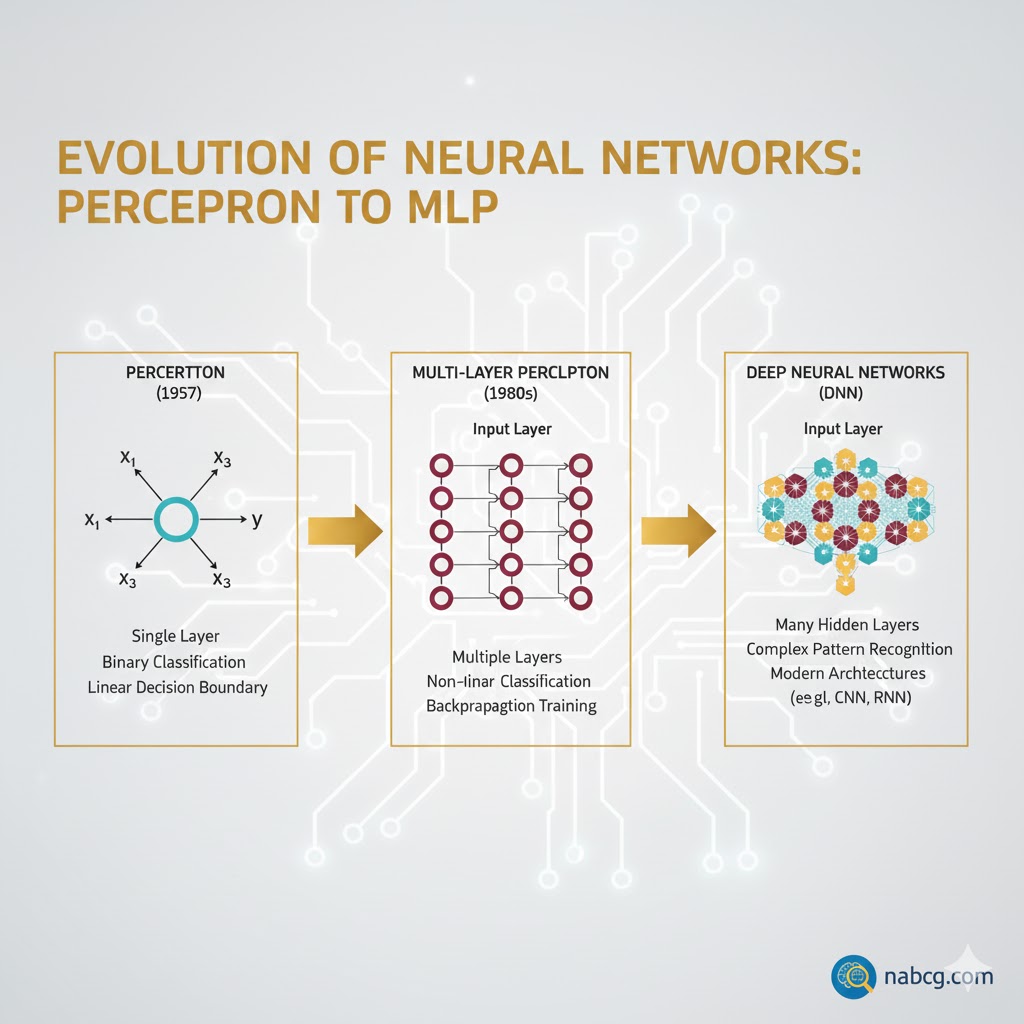
۲. پرسپترونهای چندلایه (MLPs)
دانشمندان ناامید نشدند و MLP را اختراع کردند. این همان نقطهای بود که هوش مصنوعی دوباره زنده شد.
- نوآوری کلیدی: اضافه کردن لایههای پنهان (Hidden Layers) و توابع فعالساز غیرخطی.
- قدرت: حالا شبکه میتوانست خطوط منحنی و پیچیده بکشد و روابط غیرخطی را درک کند.
- نحوه یادگیری: با روشی به نام پسانتشار (Backpropagation)، شبکه یاد میگرفت که چطور از اشتباهاتش درس بگیرد و وزنها را اصلاح کند.
نتیجه: MLPها جهش بزرگی بودند که ثابت کردند شبکههای عصبی میتوانند مسائل پیچیدهای را حل کنند که مدلهای خطی قدیمی حتی خوابش را هم نمیدیدند.
انواع شبکههای عصبی؛ جعبهابزار هوش مصنوعی 🛠️🧠
دنیای یادگیری عمیق یکشکل نیست. مهندسان هوش مصنوعی برای هر مشکل خاص، ابزار (یا همان شبکه) مخصوصی طراحی کردهاند. بیایید با ۶ نوع اصلی و پرکاربرد این شبکهها آشنا شویم.
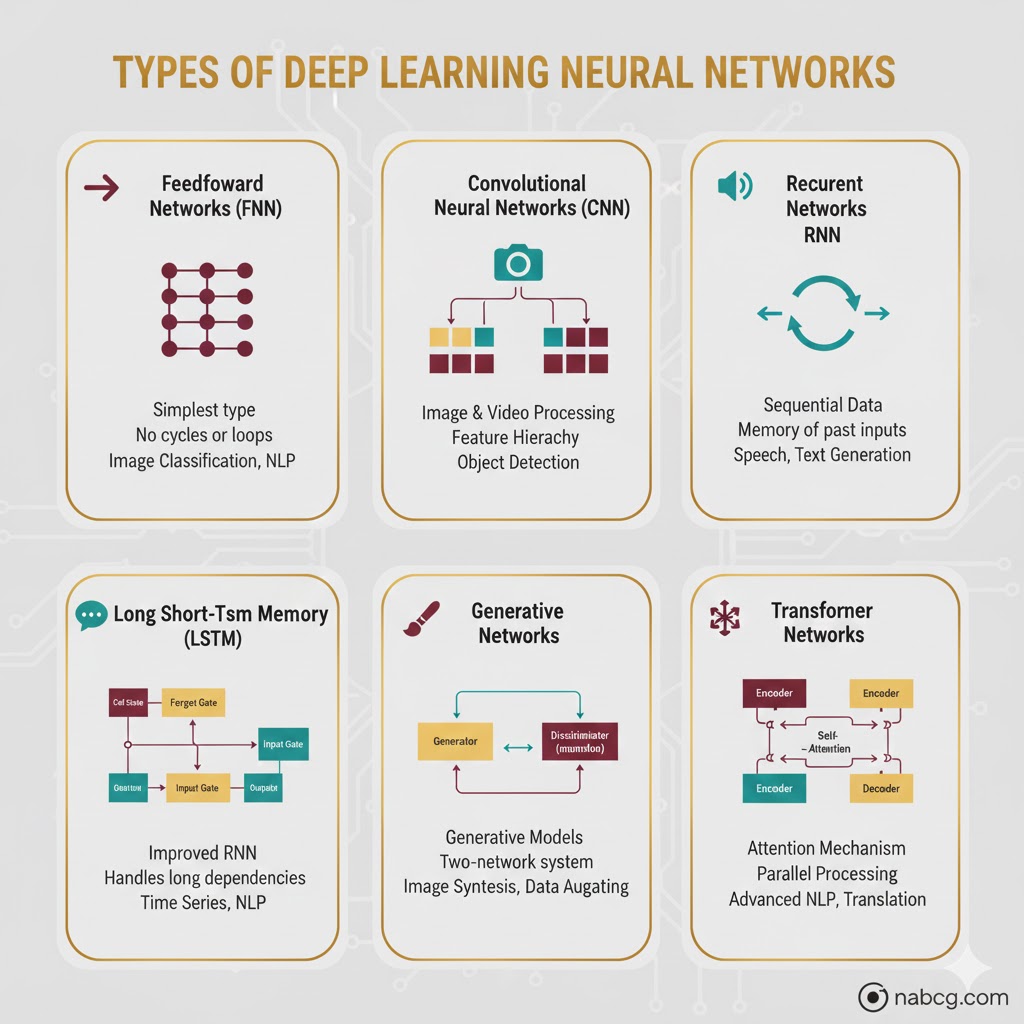
۱. شبکههای عصبی پیشخور (FNNs)
اینها سادهترین نوع شبکههای عصبی مصنوعی هستند.
- نحوه کار: جریان داده یکطرفه است؛ اطلاعات از ورودی وارد شده و مستقیماً به خروجی میرود (بدون هیچ حلقه یا بازگشتی).
- کاربرد: برای کارهای پایه و ساده مثل طبقهبندی استفاده میشوند.
- مثال: تشخیص اینکه آیا یک مشتری وام را پس میدهد یا نه (بر اساس سن و درآمد).
۲. شبکههای عصبی کانولوشنال (CNNs)
این شبکهها متخصص پردازش دادههای شبکهای (مثل پیکسلهای عکس) هستند.
- نحوه کار: از فیلترهایی به نام «لایه کانولوشن» استفاده میکنند تا ویژگیهای مکانی و سلسلهمراتب تصویر را درک کنند (مثلاً اول خطوط را میبینند، بعد شکلها و در نهایت کل صورت را).
- کاربرد: پادشاه مطلقِ بینایی ماشین.
- مثال: تشخیص چهره در گوشی موبایل یا تشخیص تومور در عکسهای رادیولوژی.
۳. شبکههای عصبی بازگشتی (RNNs)
برخلاف مدلهای قبلی، این شبکهها حافظه دارند و میتوانند دادههای متوالی (مثل زمان یا متن) را پردازش کنند.
- نحوه کار: این شبکهها دارای حلقههایی هستند که به آنها اجازه میدهد اطلاعات گذشته را حفظ کنند. (البته برای حل مشکل فراموشی در دادههای طولانی، از نسخههای پیشرفتهتری مثل LSTM و GRU استفاده میشود).
- کاربرد: پردازش زبان طبیعی و سریهای زمانی.
- مثال: پیشبینی قیمت بورس یا تبدیل گفتار به متن (مثل سیری و گوگل اسیستنت).
۴. شبکههای مولد تخاصمی (GANs)
این جذابترین نوع شبکه است که از دو دشمن تشکیل شده:
- تولیدکننده (Generator): سعی میکند دادههای جعلی ولی واقعی بسازد.
- تمیزدهنده (Discriminator): سعی میکند مچ تولیدکننده را بگیرد و جعلی بودن را تشخیص دهد.
- نحوه کار: این دو آنقدر با هم رقابت میکنند تا تولیدکننده بتواند دادههایی بسازد که مو لای درزش نرود!
- کاربرد: تولید تصویر، تغییر سبک هنری و افزایش داده.
- مثال: ساخت چهرههای انسانی که وجود خارجی ندارند (Deepfakes) یا تبدیل عکس روز به شب.
۵. اتوانکودرها (Autoencoders)؛
اینها شبکههای بدون ناظری هستند که یاد میگیرند دادهها را خلاصه کنند.
- نحوه کار: داده ورودی را به یک کد فشرده (Latent Space) تبدیل میکنند و سپس سعی میکنند دوباره اصل داده را از روی آن بازسازی کنند.
- کاربرد: کاهش ابعاد داده و حذف نویز.
- مثال: شفاف کردن عکسهای تار و بیکیفیت (حذف نویز) یا فشردهسازی ویدیو.
۶. شبکههای ترنسفورمر (Transformer Networks)
این مدلها دنیای پردازش زبان (NLP) را زیر و رو کردند.
- نحوه کار: از مکانیزمی به نام توجه خودکار (Self-Attention) استفاده میکنند تا بفهمند کدام کلمات در جمله مهمتر هستند و چه ارتباطی با هم دارند)بدون نیاز به پردازش کلمه به کلمه مثل RNN).
- کاربرد: ترجمه ماشینی، تولید متن و تحلیل احساسات.
- مثال: مدلهای GPT و BERT.
کاربردهای یادگیری عمیق
یادگیری عمیق دیگر فقط یک تئوری دانشگاهی نیست؛ بلکه در تار و پود زندگی روزمره ما نفوذ کرده است. بیایید سه قلمرو اصلی که توسط این تکنولوژی فتح شدهاند را بررسی کنیم.
۱. بینایی ماشین (Computer Vision)
در این حوزه، یادگیری عمیق به ماشینها قدرت “دیدن” و “فهمیدن” تصاویر را میدهد.
- تشخیص و شناسایی اشیاء(Object Detection): ماشینها میتوانند اشیاء را در عکس یا ویدیو پیدا کنند.
- مثال: خودروهای خودران که عابر پیاده را از تیر چراغ برق تشخیص میدهند، یا دوربینهای امنیتی هوشمند.
- طبقهبندی تصاویر(Image Classification): مدل میتواند بگوید موضوع کلی عکس چیست (حیوان، گیاه، ساختمان).
- مثال: تشخیص تومورهای سرطانی در تصاویر رادیولوژی پزشکی یا کنترل کیفیت محصولات در کارخانهها.
- قطعهبندی تصویر(Segmentation): تفکیک دقیق اجزای تصویر.
- مثال: جدا کردن پسزمینه از تصویر در تماسهای ویدیویی زوم یا اسکایپ.
۲. پردازش زبان طبیعی (NLP)؛ زبان مشترک انسان و ماشین
اینجا جایی است که ماشینها یاد میگیرند مثل ما حرف بزنند و بفهمند.
- تولید خودکار متن: مدلها با خواندن متون زیاد، یاد میگیرند متنهای جدید بنویسند.
- مثال: نوشتن مقاله، خلاصه کردن اخبار یا حتی نوشتن کد برنامه )مثل کاری که ChatGPT انجام میدهد).
- ترجمه ماشینی: شکستن مرزهای زبانی با ترجمه دقیق و سریع.
- مثال: Google Translate که متون را بین زبانهای مختلف ترجمه میکند.
- تحلیل احساسات: فهمیدن حس نویسنده متن (مثبت، منفی یا خنثی).
- مثال: بررسی نظرات مشتریان در دیجیکالا یا آمازون برای سنجش رضایت آنها.
- تشخیص گفتار: تبدیل صدا به متن.
- مثال: دستیارهای صوتی مثل سیری (Siri) یا تایپ صوتی گوگل.
۳. یادگیری تقویتی (Reinforcement Learning)؛ یادگیری با آزمون و خطا
در این روش، عامل هوشمند (Agent) در محیط رها میشود تا با سیستم پاداش و تنبیه، بهترین رفتار را یاد بگیرد.
- بازیهای کامپیوتری: شکست دادن قهرمانان جهان توسط هوش مصنوعی.
- رباتیک: آموزش کارهای فیزیکی پیچیده به رباتها.
- مثال: رباتهایی که یاد میگیرند اجسام را بگیرند یا بدون برخورد با مانع حرکت کنند.
- سیستمهای کنترلی: مدیریت سیستمهای کلان.
- مثال: بهینهسازی شبکه برقرسانی شهر یا مدیریت چراغهای راهنمایی برای کاهش ترافیک.
مزایا و معایب یادگیری عمیق
هر تکنولوژی قدرتمندی، نقاط قوت و ضعف خودش را دارد. یادگیری عمیق هم استثنا نیست.
مزایا
- دقت فوقالعاده: در کارهایی مثل تشخیص چهره یا ترجمه، دقتی در حد (یا حتی بهتر از) انسان دارد.
- مهندسی ویژگی خودکار: برخلاف روشهای سنتی، نیازی نیست ویژگیها را دستی به آن بدهید؛ خودش میفهمد چه چیزی مهم است (مثلاً خودش میفهمد که برای تشخیص گربه، باید به گوشها نگاه کند).
- مقیاسپذیری: هر چه داده بیشتر باشد، بهتر کار میکند و زیر بار حجم زیاد اطلاعات کم نمیآورد.
- انعطافپذیری: تقریباً با هر نوع دادهای کار میکند (متن، عکس، صدا، ویدیو).
معایب
- هزینه محاسباتی سنگین: آموزش این مدلها به سختافزارهای گرانقیمت (GPU و TPU) نیاز دارد که هزینه و مصرف برق بالایی دارند.
- جعبه سیاه: ما ورودی و خروجی را میبینیم، اما فهمیدن اینکه دقیقاً “چرا” و “چگونه” مدل به این نتیجه رسیده، بسیار دشوار است.
- بیشبرازش(Overfitting): اگر مدل بیشازحد روی دادههای آموزشی تمرین کند، آنها را حفظ میکند! در نتیجه روی دادههای جدید و واقعی عملکرد ضعیفی خواهد داشت.
ابزارها و فریم ورک ها 🛠️💻
برای ساخت هوش مصنوعی، نیازی نیست فرمولهای ریاضی پیچیده را از صفر کدنویسی کنید. غولهای تکنولوژی ابزارهای قدرتمند و رایگانی را در اختیار ما گذاشتهاند:
۱. تنسورفلو (TensorFlow)
محصول شرکت گوگل. یک کتابخانه بسیار قدرتمند و حرفهای که هم در پژوهش و هم در ساخت محصولات تجاری (Production) کاربرد دارد.
۲. (Keras)
کراس در واقع یک رابط کاربری ساده و زیباست که روی تنسورفلو سوار میشود. برای مبتدیان بهترین گزینه محسوب میشود.
۳. (PyTorch)
محصول شرکت متا (فیسبوک). این روزها محبوبیت عجیبی بین محققان و دانشگاهیان پیدا کرده است، چون بسیار انعطافپذیر است و دیباگ کردن (عیبیابی) آن راحتتر است.
مسیر پیشنهادی: اگر تازه اول راه هستید، با Keras شروع کنید تا اصول را یاد بگیرید، سپس برای پروژههای پیچیدهتر به سراغ PyTorch بروید.
جمع بندی
یادگیری عمیق، شاخهای پیشرفته از یادگیری ماشین است که با الهام از ساختار سلسلهمراتبی مغز انسان طراحی شده است. این روش از شبکههای عصبی چندلایه استفاده میکند تا بهصورت خودکار الگوهای پیچیده را از دادههای خام استخراج کند. برخلاف روشهای سنتی — که نیازمند مهندسی دستی ویژگیها هستند — یادگیری عمیق بهصورت انتها-به-انتها (end-to-end) یاد میگیرد: دادهٔ خام وارد میشود و خروجی نهایی (مثلاً برچسب یا پیشبینی) مستقیماً تولید میشود، بدون دخالت انسان در میانهٔ فرآیند.
این روش در حوزههایی مانند بینایی ماشین (تشخیص چهره، قطعهبندی تصویر)، پردازش زبان طبیعی (تولید متن، ترجمه، تحلیل احساسات)، و یادگیری تقویتی (رباتیک، سیستمهای کنترلی) عملکردی چشمگیر داشته است. معماریهای متنوعی مانند CNN (برای تصویر)، RNN/LSTM (برای سریزمانی)، Transformer برای زبان، GAN (برای تولید)، و اتوانکودر (برای بازسازی و کاهش نویز) ابزارهای تخصصی این حوزه هستند.
با این حال، یادگیری عمیق نیازمند داده حجیم و باکیفیت، سختافزار قدرتمند (مانند GPU)، و زمان آموزش طولانی است. همچنین، تفسیرپذیری پایین آن («جعبه سیاه» بودن) و احتمال بیشبرازش، چالشهایی هستند که در طراحی مدل باید مدیریت شوند.
در نهایت، وقتی دادههایی بزرگ، پیچیده و بدون ساختار در کنار اولویت دقت بالا قرار گیرند، یادگیری عمیق انتخابی هوشمندانه است — نه بهعنوان جایگزینی جهانشمول، بلکه بهعنوان ابزاری تخصصی و قدرتمند در جعبهابزار هوش مصنوعی مدرن.



