

مقدمه
در دنیای امروز که دادهها با سرعتی سرسامآور تولید میشوند، یادگیری ماشین تنها زمانی معنا پیدا میکند که بتوانیم روش درست تحلیل دادهها را انتخاب کنیم. دو رویکرد اصلی در این مسیر، یادگیری نظارتشده و یادگیری نظارتنشده هستند.دو ستون بنیادی که تقریباً تمام مدلهای هوش مصنوعی بر آنها استوارند.
یادگیری نظارتشده زمانی کاربرد دارد که دادهها برچسبدار باشند و مدل بتواند از نمونههای صحیح برای پیشبینی آینده استفاده کند. در مقابل، یادگیری نظارتنشده زمانی به کار میرود که دادهها بدون برچسباند و ما به دنبال کشف ساختارهای پنهان، الگوهای ناشناخته و گروهبندیهای طبیعی در دل دادهها هستیم.
شناخت تفاوت این دو روش برای هر کسی که با علم داده، هوش مصنوعی یا تحلیل داده سروکار دارد ضروری است؛ زیرا انتخاب نادرست میتواند منجر به خطاهای تحلیلی، اتلاف منابع و نتایج نامعتبر شود. در این مقاله، این دو رویکرد را از نظر نحوه عملکرد، انواع الگوریتمها، کاربردها، مزایا و معایب مقایسه میکنیم تا مسیر انتخاب روش درست برای مسائل واقعی روشنتر شود.
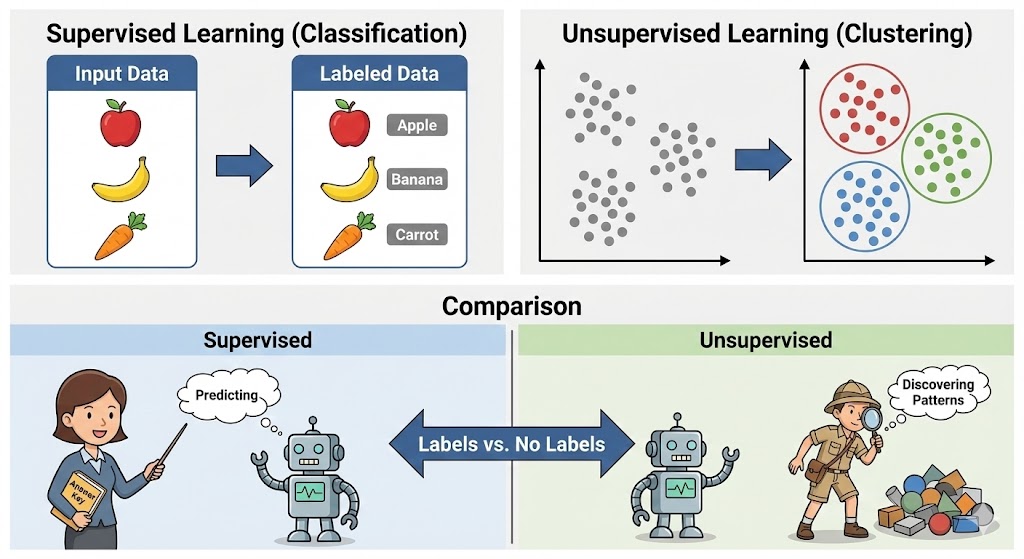
یادگیری نظارتشده چیست؟
یادگیری نظارتشده شاخهای از یادگیری ماشین است که در آن مدل با استفاده از دادههای برچسبدار آموزش میبیند. این بدان معناست که دادههای ورودی به همراه پاسخ صحیح (خروجی) به سیستم داده میشوند و مدل یاد میگیرد که چگونه بر اساس ورودیها، خروجیها را پیشبینی کند.
برای دستیابی به پیشبینیهای دقیق، دادههای ورودی با برچسبهایی که نشاندهنده پاسخ صحیح هستند، نشانهگذاری میشوند (مثل معلمی که پاسخ صحیح را به دانشآموز نشان میدهد).
انواع یادگیری نظارتشده
به خاطر داشته باشید که تمامی الگوریتمهای یادگیری نظارتشده، در واقع الگوریتمهای پیچیدهای هستند که اساساً در دو دسته اصلی طبقهبندی میشوند: مدلهای طبقهبندی و مدلهای رگرسیون.
۱. مدلهای طبقهبندی:
این مدلها برای حل مسائلی به کار میروند که در آنها متغیر خروجی را میتوان دستهبندی کرد؛ مانند بله یا خیر، قبول یا رد.
- هدف: مدلهای طبقهبندی برای پیشبینی دستهای که دادهها به آن تعلق دارند، استفاده میشوند.
- مثالهای واقعی: تشخیص ایمیلهای اسپم، تحلیل احساسات (مثبت/منفی)، پیشبینی نتیجه آزمون (قبولی/مردودی) و غیره.
۲. مدلهای رگرسیون:
این مدلها برای مسائلی مناسب هستند که متغیر خروجی یک مقدار حقیقی (Real Value) و پیوسته است؛ مانند یک عدد خاص، مبلغ پول، میزان حقوق، وزن یا فشار.
- هدف: کاربرد اصلی آنها پیشبینی مقادیر عددی دقیق بر اساس مشاهدات دادههای پیشین است.
- الگوریتمهای رایج: برخی از مشهورترین الگوریتمهای این دسته شامل رگرسیون خطی، رگرسیون لجستیک (که البته معمولاً برای طبقهبندی استفاده میشود اما ریشه رگرسیونی دارد)، رگرسیون چندجملهای و رگرسیون ریج (Ridge) هستند.
ارزیابی مدلهای یادگیری نظارتشده
ارزیابی مدلهای یادگیری نظارتشده به معنای سنجش این است که مدل چقدر وظیفه خود را به درستی انجام میدهد. از آنجا که مدل با دادههای برچسبدار (جایی که پاسخهای صحیح مشخص هستند) آموزش دیده است، ما میتوانیم پیشبینیهای آن را با پاسخهای واقعی مقایسه کنیم تا دقت و اثربخشی آن را اندازهگیری نماییم.
این فرآیند به زبان ساده اینگونه کار میکند:
مقایسه پیشبینیها با برچسبهای واقعی
پس از پایان آموزش، مدل روی دادههای جدید پیشبینی انجام میدهد. ما این پیشبینیها را با برچسبهای واقعی (پاسخهای صحیح) مقایسه میکنیم تا ببینیم چقدر به هم نزدیک هستند.
استفاده از معیارهای ارزیابی (Evaluation Metrics)
بسته به نوع مسئله (طبقهبندی یا رگرسیون)، از معیارهای متفاوتی استفاده میشود:
الف) برای طبقهبندی (مانند تشخیص اسپم):
در این مسائل خروجی ما دستهبندی شده است (مثلاً سالم/بیمار یا اسپم/غیر اسپم).
- دقت (Accuracy): درصدِ کلِ پیشبینیهای درست. (مثلاً: مدل ۹۰٪ تصاویر را درست تشخیص داد).
- صحت (Precision): از بین مواردی که مدل پیشبینی کرد مثبت هستند، چند درصد واقعاً درست بودند؟
مثال: در تشخیص اسپم، صحت بالا مهم است. یعنی اگر مدل ایمیلی را اسپم تشخیص داد، واقعاً اسپم باشد (تا ایمیلهای مهمِ کاری اشتباهاً به پوشه اسپم نروند).
- بازیابی: از بین تمام موارد مثبت واقعی، مدل چند درصد را توانست پیدا کند؟
مثال: در تشخیص سرطان، بازیابی بالا حیاتی است. ما میخواهیم تمام بیماران سرطانی شناسایی شوند، حتی اگر به قیمتِ شک کردن به چند فرد سالم تمام شود (چون از دست دادن یک بیمار خطرناکتر است).
- امتیاز F1 (F1-Score): میانگین وزنی و تعادلی میان صحت و بازیابی. زمانی که بین این دو معیار تضاد وجود دارد، F1 دید بهتری میدهد.
ب) برای رگرسیون (مانند پیشبینی قیمت مسکن):
در این مسائل خروجی ما یک عدد پیوسته است.
- میانگین مربعات خطا (MSE): اندازه میگیرد که پیشبینیها چقدر از مقادیر واقعی فاصله دارند (هرچه کمتر، بهتر).
- ضریب تعیین (R^2): نشان میدهد که مدل چقدر توانسته تغییرات دادهها را توضیح دهد (هرچه به ۱ نزدیکتر، بهتر).
تقسیم دادهها برای تست
برای اینکه ارزیابی عادلانه باشد، مجموعه داده به دو بخش تقسیم میشود:
- دادههای آموزشی: برای آموزش دادن به مدل استفاده میشود (مثل کتاب درسی).
- دادههای تست: برای ارزیابی عملکرد مدل روی دادههای دیدهنشده استفاده میشود (مثل سوالات امتحان نهایی).
اعتبارسنجی متقابل (Cross-Validation)
برای اطمینان از اینکه مدل روی زیرمجموعههای مختلف داده خوب کار میکند و نتایجش شانسی نیست، از تکنیکهایی مثل اعتبارسنجی متقابل استفاده میکنیم.
- نحوه کار: دادهها به چندین بخش (مثلاً ۵ بخش) تقسیم میشوند. مدل ۵ بار آموزش میبیند؛ هر بار روی ۴ بخش آموزش میبیند و روی ۱ بخش تست میشود. در نهایت میانگین نتایج گرفته میشود تا پایداری مدل تضمین شود.
کاربردهای عملیاتی یادگیری نظارتشده
یادگیری نظارتشده تنها یک مفهوم تئوری نیست؛ بلکه موتوری است که بسیاری از فناوریهای هوشمند روزمره ما را به پیش میبرد. در ادامه، علاوه بر موارد ذکر شده در متن اصلی، چندین کاربرد حیاتی دیگر نیز اضافه شده است:
۱. تشخیص هرزنامه در ایمیلها (Spam Detection)
مدلهای یادگیری نظارتشده با بررسی هزاران ایمیل نمونه (که قبلاً توسط کاربران به عنوان “اسپم” یا “سالم” برچسب خوردهاند)، الگوهای مخرب را یاد میگیرند. نتیجه این است که صندوق ورودی شما به صورت خودکار از شر ایمیلهای مزاحم در امان میماند.
۲. پیشبینی قیمت مسکن و املاک
این یک نمونه کلاسیک از مسائل رگرسیون است. مدلها با یادگیری از دادههای تاریخی (شامل ویژگیهایی مثل متراژ، محله، تعداد اتاق و سال ساخت)، میتوانند قیمت دقیق یک ملک را در شرایط فعلی بازار تخمین بزنند.
۳. تشخیصهای پزشکی و درمانی
این فناوری جان انسانها را نجات میدهد. با تحلیل دادههای بیماران (علائم، نتایج آزمایشگاه، تصاویر رادیولوژی و سوابق پزشکی)، مدلها میتوانند بیماریهای خطرناکی مثل سرطان، دیابت یا نارسایی قلبی را در مراحل اولیه پیشبینی کنند.
۴. تشخیص تصویر و چهره
از باز کردن قفل گوشی با چهره (FaceID) گرفته تا خودروهای خودران؛ مدلها با دیدن میلیونها تصویر برچسبدار (مثلاً “این گربه است”، “این عابر پیاده است”)، یاد میگیرند اشیاء، چهرهها و صحنهها را با دقت بالا شناسایی کنند.
مزایا و معایب یادگیری نظارتشده: یک نگاه واقعبینانه
یادگیری نظارتشده قدرتمندترین ابزار فعلی در جعبهابزار هوش مصنوعی است، اما مانند هر تکنولوژی دیگری، نقاط قوت و ضعف خاص خود را دارد. شناخت این موارد به شما کمک میکند تا انتظارات واقعبینانهای از پروژه خود داشته باشید.
مزایای کلیدی
۱. اهداف شفاف و مشخص : مدل دقیقاً میداند که باید چه چیزی را یاد بگیرد. چون از دادههای برچسبدار تغذیه میکند، هدف نهایی (مثلاً تشخیص گربه از سگ) کاملاً روشن است و جای ابهامی برای الگوریتم باقی نمیماند.
۲. ارزیابی ساده و دقیق: از آنجا که ما پاسخنامه (همان برچسبهای واقعی) را در اختیار داریم، سنجش عملکرد مدل بسیار آسان است. ما میتوانیم دقیقاً محاسبه کنیم که مدل چند درصد خطا داشته و چقدر قابل اطمینان است.
۳. کاربردهای گسترده و عملی: این روش امتحان خود را در دنیای واقعی پس داده است. از تشخیص اسپم در ایمیلها و تشخیص بیماریهای پیچیده در پزشکی گرفته تا پیشبینی قیمتها در بورس، همه با موفقیت از این روش استفاده میکنند.
۴. درک آسان فرآیند: منطق پشت این روش (ورودی + پاسخ صحیح = یادگیری) ساده است. فرآیند آموزش و تست در این مدلها شفاف است و توضیح آن برای مدیران غیرفنی یا سهامداران راحتتر از سایر روشهای پیچیده (مثل یادگیری تقویتی) است.
معایب
۱. پاشنه آشیل: نیاز به دادههای برچسبدار: بزرگترین چالش این روش، وابستگی شدید به دادههای برچسبدار است. آمادهسازی این دادهها (مثلاً اینکه یک پزشک هزاران عکس رادیولوژی را دستی بررسی و برچسبگذاری کند) بسیار گران، زمانبر و خستهکننده است.
۲. محدود به دانستهها: مدل فقط چیزی را میداند که قبلاً دیده است. اگر با دادهای مواجه شود که خارج از محدوده آموزشهایش باشد (ناشناخته)، احتمالاً شکست میخورد. این مدلها خلاقیت ندارند و نمیتوانند خارج از چارچوب فکر کنند.
۳. خطر بیشبرازش: گاهی مدل به جای یادگیری الگوها، دادهها را حفظ میکند. مثل دانشآموزی که شب امتحان سوالات را حفظ کرده است؛ در امتحان کلاسی نمره ۲۰ میگیرد (روی دادههای آموزشی)، اما در کنکور (دادههای جدید) مردود میشود.
۴. هزینه محاسباتی: آموزش مدلهای نظارتشده روی دیتاستهای عظیم نیازمند قدرت پردازشی بالا و زمان طولانی است که میتواند هزینههای سختافزاری پروژه را افزایش دهد.
۵. ناتوانی در برابر دادههای بدون برچسب: این مدلها نمیتوانند از دادههای خام و بدون برچسب استفاده کنند. این یک محدودیت بزرگ است، زیرا بخش عظیمی از دادههای جهان (عکسها و متنهای موجود در اینترنت) بدون برچسب هستند.
یادگیری نظارتنشده چیست؟
یادگیری نظارتنشده شاخهای از یادگیری ماشین است که در آن مدل بدون دسترسی به هیچ برچسب یا پاسخ صحیح، الگوها را از دادهها میآموزد.
- رویکرد: به جای اینکه به مدل بگوییم به دنبال چه چیزی بگردد، مدل به تنهایی به کاوش دادهها میپردازد تا ساختارها و گروههای پنهان را کشف کند.
- قیاس: این فرآیند شبیه حل کردن یک پازل است، در حالی که نمیدانیم تصویر نهایی پازل باید چگونه به نظر برسد.
- هدف: ماشین باید به گونهای برنامهریزی شود که بتواند به طور مستقل یاد بگیرد و از دادههای ساختاریافته و بدون ساختار، بینشهای معنادار استخراج کند.
انواع یادگیری نظارتنشده
وظایف یادگیری نظارتنشده معمولاً برای اهداف اکتشافی و توصیفی به کار میروند که مهمترین آنها عبارتند از:
۱. خوشهبندی (Clustering)
خوشهبندی یکی از رایجترین متدهای نظارتنشده است. این روش شامل سازماندهی دادههای بدون برچسب به گروههایی شبیه به هم است که خوشه نامیده میشوند.
- هدف اصلی: پیدا کردن شباهتها در نقاط داده و گروهبندی نقاط مشابه در یک خوشه.
- الگوریتمهای رایج: K-Means ، خوشهبندی سلسلهمراتبی (Hierarchical) و DBSCAN.
۲. تشخیص ناهنجاری (Anomaly Detection)
تشخیص ناهنجاری، روش شناسایی موارد، رویدادها یا مشاهدات نادری است که به طور قابل توجهی با اکثریت دادهها تفاوت دارند.
- اهمیت: ما عموماً به دنبال این موارد پرت (Outliers) یا ناهنجاریها هستیم زیرا اغلب مشکوک هستند یا نشاندهنده یک مشکل جدی میباشند.
مثال کاربردی (کشف تقلب بانکی): یک بانک رفتار تراکنشی عادی میلیونها کاربر خود را به عنوان “الگو” تعریف میکند.
- اگر یک مشتری همیشه در شهر تهران خریدهای کوچک میکند،
- تراکنش ناگهانی ۱۰ میلیون تومانی در یک کشور خارجی به عنوان یک ناهنجاری شناخته میشود. تشخیص ناهنجاری، بدون نیاز به برچسبهای از پیش تعریف شده برای تقلب، میتواند این فعالیت غیرعادی را شناسایی کرده و کارت مشتری را موقتاً مسدود کند. این روش همچنین در تشخیص خطاهای پزشکی یا ایرادات فنی در تجهیزات صنعتی کاربرد فراوان دارد.
3.تداعی یا انجمنی (Association)
کاوش قواعد انجمنی (Association Rule Mining) یک رویکرد مبتنی بر قانون برای آشکار کردن روابط جالب و پنهان بین نقاط داده در مجموعه دادههای بزرگ است.
الگوریتمهای یادگیری نظارتنشده در اینجا به جستجوی تداعیهای مکررِ اگر-آنگاه که به آنها قانون یا Rule میگویند— میپردازند تا همبستگیها، رخدادهای همزمان (Co-occurrences) و اتصالات متفاوت بین اشیاء داده را کشف کنند.
4. کاهش ابعاد (Dimensionality Reduction)
دادههای چندمتغیره (Multivariate) اغلب شامل تعداد زیادی متغیر یا ویژگی هستند. این مسئله میتواند زمان اجرا و حافظه مورد نیاز سیستم را تحت تأثیر قرار دهد. تکنیکهای کاهش ابعاد، تعداد ویژگیها (ابعاد) را کاهش میدهند در حالی که اطلاعات ضروری دادههای اصلی را حفظ میکنند. استفاده از کاهش ابعاد در کنار یادگیری نظارتنشده میتواند به کاهش بار محاسباتی و افزایش سرعت و کارایی الگوریتمهای یادگیری ماشین کمک کند.
ارزیابی مدلهای یادگیری نظارتنشده
ارزیابی مدلهای نظارتنشده بسیار چالشبرانگیزتر از مدلهای نظارتشده است. چرا؟ چون ما حقیقت مبنا (Ground Truth) یا برچسبهای صحیح را نداریم تا خروجی مدل را با آن مقایسه کنیم. مثل این است که یک نقاشی بکشید، اما هیچ مدل یا منظرهای برای مقایسه نداشته باشید تا ببینید چقدر دقیق کشیدهاید.
با این حال، روشهای خاصی برای سنجش کیفیت این مدلها وجود دارد:
استفاده از معیارهای داخلی (Internal Metrics)
در این روش، ما کیفیت خوشهها را بر اساس ساختار خودِ دادهها میسنجیم. دو سوال کلیدی میپرسیم:
- آیا نقاط داخل یک خوشه به هم نزدیک هستند؟ (فشردگی یا Compactness)
- آیا خوشههای مختلف به اندازه کافی از هم دور هستند؟ (جدایی یا Separation)
معیارهای رایج:
- امتیاز سیلوئت (Silhouette Score): عددی بین ۱- تا ۱+ است.
- ۱ +: یعنی خوشهبندی عالی است (نقاط به خوشه خود نزدیک و از بقیه دورند).
- ۰: یعنی همپوشانی وجود دارد.
- ۱–: یعنی دادهها اشتباه خوشهبندی شدهاند.
- شاخص دیویس-بولدین (Davies-Bouldin Index): هر چه این عدد کمتر باشد، مدل بهتر است (یعنی خوشهها متراکمتر و جداتر هستند).
ارزیابی کیفی و تخصصی (Qualitative Evaluation)
از آنجا که ریاضیات همیشه معنای تجاری را نشان نمیدهد، متخصصان دامنه (Domain Experts) باید خروجی را بررسی کنند.
مثال واقعی: فرض کنید الگوریتم خوشهبندی، مشتریان یک فروشگاه را به ۳ گروه تقسیم کرده است.
- بررسی متخصص بازاریابی: او نگاه میکند و میبیند:
- گروه ۱: جوانان دانشجو (خریدهای ارزان و پرتعداد).
- گروه ۲: خانوادهها (خریدهای عمده و آخر هفته).
- گروه ۳: افراد بازنشسته (خریدهای دارو و سلامت).
- نتیجه: چون این دستهبندیها از نظر “منطق کسبوکار” معنا دارند، مدل تایید میشود.
ارزیابی غیرمستقیم (Indirect Evaluation)
در این روش، از خروجی مدل نظارتنشده به عنوان ورودی برای یک مدل نظارتشده استفاده میکنیم. اگر عملکرد مدل دوم بهتر شد، یعنی مدل اول خوب کار کرده است.
مثال: استفاده از خوشهها به عنوان ویژگی جدید برای پیشبینی ریزش مشتری. اگر با افزودن این خوشهها، دقت پیشبینی ریزش بالا رفت، یعنی خوشهبندی کیفیت خوبی داشته است.
کاربردهای کلیدی یادگیری نظارتنشده
۱. بخشبندی مشتریان
این شاید مهمترین کاربرد تجاری باشد. کسبوکارها نمیتوانند با همه مشتریان یکسان رفتار کنند. الگوریتمهای خوشهبندی (مثل K-Means) مشتریان را بر اساس رفتارهای پنهانشان گروهبندی میکنند.
۲. تشخیص ناهنجاری و تقلب
در این روش، مدل یاد میگیرد که “رفتار نرمال” چیست. هر چیزی که از این نرمال فاصله زیادی داشته باشد، به عنوان ناهنجاری (Anomaly) پرچمگذاری میشود.
۳. تحلیل سبد خرید – قوانین انجمنی
این روش به دنبال کشف روابط “اگر-آنگاه” در دادههاست. یعنی اگر مشتری کالای A را خرید، چقدر احتمال دارد کالای B را هم بخرد؟
۴. آمادهسازی دادهها و کاهش ابعاد
گاهی دادهها آنقدر پیچیده و دارای هزاران ویژگی (ستون) هستند که پردازش آنها غیرممکن است. الگوریتمهایی مثل PCA (تحلیل مولفههای اصلی) این دادهها را فشرده میکنند بدون اینکه اطلاعات مهم از دست برود.
مزایا و معایب یادگیری نظارتنشده
یادگیری نظارتنشده مانند کاوش در یک سرزمین ناشناخته است؛ ابزاری قدرتمند برای کشف چیزهایی که حتی نمیدانستید وجود دارند، اما همزمان چالشهای خاص خود را در تفسیر و اعتبارسنجی دارد.
مزایای کلیدی
۱. عدم نیاز به برچسبگذاری: این روش نیازی به دادههای برچسبدار ندارد. این یعنی صرفهجویی عظیم در زمان و انرژی، چرا که دیگر نیازی به تگگذاری دستی هزاران داده نیست.
۲. کشف الگوهای پنهان: الگوریتم به صورت خودکار گروهبندیهای طبیعی یا روابط پنهان در دادهها را کشف میکند.
۳. مدیریت دادههای پیچیده: این روش در مواجهه با مجموعه دادههای بزرگ، درهمریخته و بدون ساختار (مثل پستهای شبکههای اجتماعی یا دادههای خام سنسورها) عالی عمل میکند و آنها را در خوشههای منظم سازماندهی میکند.
۴. مقرونبهصرفه : با حذف نیاز به استخدام افراد برای برچسبگذاری دستی دادهها، هزینههای پروژههای بزرگ به شدت کاهش مییابد.
معایب
۱. نتایج ذهنی و تفسیری: الگوهایی که ماشین پیدا میکند ممکن است همیشه منطق تجاری نداشته باشند. برای درک ارزش واقعی این الگوها، حتماً به قضاوت و تفسیر انسانی نیاز است.
۲. حساسیت به نویز: دادههای بیکیفیت (مثل خطاها، دادههای پرت یا جزئیات نامربوط) میتوانند نتایج را منحرف کرده و منجر به نتیجهگیریهای گمراهکننده شوند.
۳. راهاندازی پیچیده: انتخاب الگوریتم درست و تنظیم دقیق پارامترها (مثلاً تعیین اینکه دادهها باید به چند خوشه تقسیم شوند) نیازمند فرآیند آزمون و خطای زیادی است.
۴. دشواری در اعتبارسنجی : چون پاسخ صحیح (برچسب) نداریم، اندازهگیری دقیقِ درستیِ عملکرد مدل یا تایید اینکه آیا الگوهای پیدا شده معنادار هستند یا خیر، بسیار دشوار است.
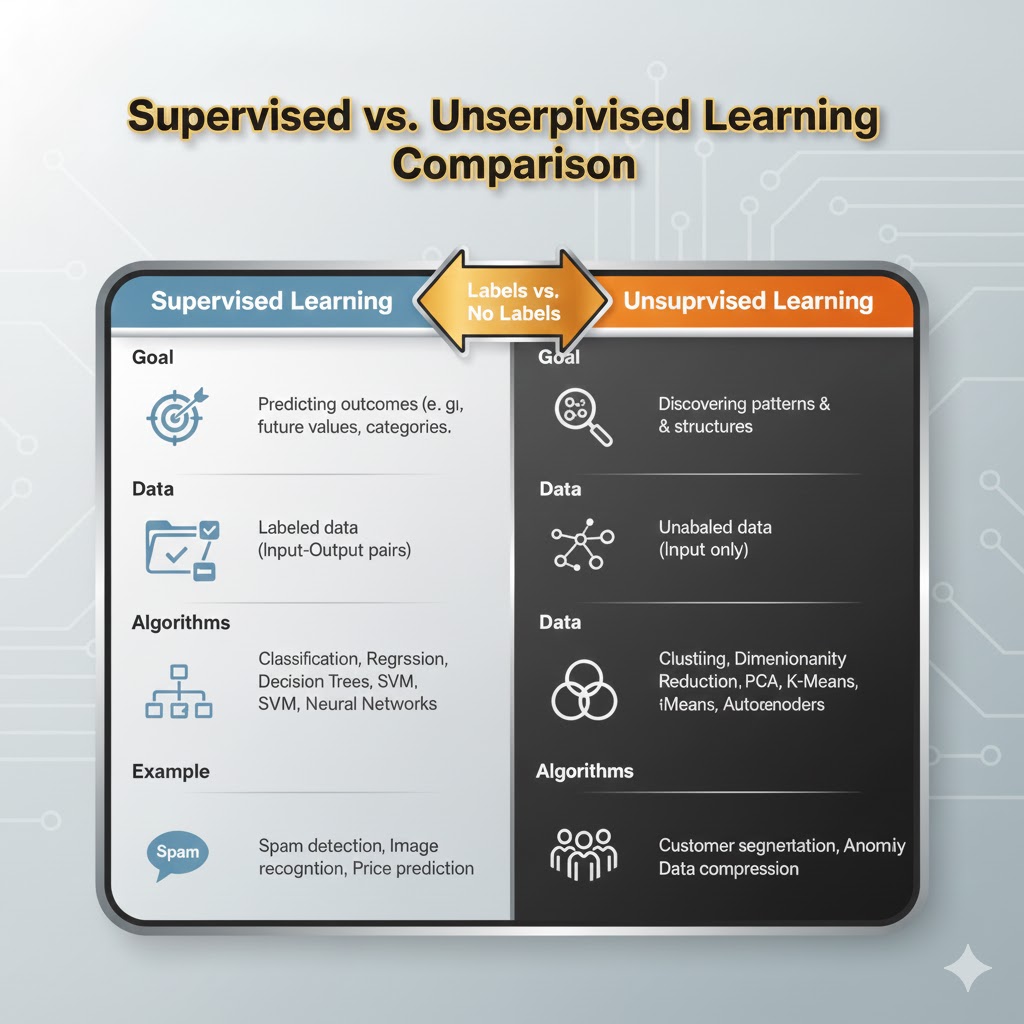
جدول مقایسهای: یادگیری نظارتشده در برابر نظارتنشده
| جنبه (Aspect) | یادگیری نظارتشده (Supervised) | یادگیری نظارتنشده (Unsupervised) |
|---|---|---|
| نیاز دادهای | نیازمند دادههای برچسبدار (جفتهای ورودی-خروجی). | از دادههای بدون برچسب (فقط ورودی) استفاده میکند. |
| هدف | پیشبینی نتایج بر اساس ورودیهای شناختهشده. | کشف الگوها و ساختارهای پنهان در دادهها. |
| تکنیکها | رگرسیون (Regression)، طبقهبندی (Classification). | خوشهبندی (Clustering)، تداعی (Association). |
| دقت | معمولاً به دقت بالایی دست مییابد. | دقت متغیر است و اغلب پایینتر از روش نظارتشده است. |
| دخالت انسانی | نیازمند برچسبگذاری دستی و نظارت است. | به دخالت انسانی کمتری نیاز دارد. |
راهنمای انتخاب: کدام روش برای شما مناسب تر است؟
یادگیری ماشین به دو شاخه اصلی تقسیم میشود: نظارتشده و نظارتنشده. انتخاب میان این دو، کاملاً به نوع دادههای شما و مسئلهای که قصد حل آن را دارید بستگی دارد.
زمان استفاده از یادگیری نظارت شده
- وجود دادههای برچسبدار: زمانی که دادههای ورودی شما دارای پاسخهای صحیح (برچسب) هستند.
- مثال: پیشبینی قیمت مسکن (ورودی: ویژگیهای خانه، خروجی: قیمت نهایی).
- هدف شفاف و مشخص: شما میخواهید مدل الگوهایی را یاد بگیرد تا بتواند پیشبینی کند.
- مثال: تشخیص اسپم (ورودی: متن ایمیل، خروجی: اسپم یا سالم).
- الگوریتمهای رایج: رگرسیون خطی، درخت تصمیم، شبکههای عصبی.
زمان استفاده از یادگیری نظارتنشده
- عدم وجود برچسب: شما فقط دادههای خام را در اختیار دارید و هیچ پاسخ از پیش تعریفشدهای ندارید.
- مثال: گروهبندی مشتریان بر اساس رفتار خرید (بدون اینکه از قبل بدانید چه گروههایی وجود دارند).
- الگوهای پنهان: شما میخواهید ساختار نهفته در دادهها را کاوش کنید.
- مثال: پیدا کردن موضوعات (Topics) در مجموعهای از مقالات خبری.
- الگوریتمهای رایج: خوشهبندی K-Means، تحلیل مولفههای اصلی . (PCA)
تفاوت کلیدی و قانون تصمیمگیری
- نظارتشده: به دادههای برچسبدار نیاز دارد؛ کاربرد آن پیشبینی است.
- نظارتنشده: با دادههای بدون برچسب کار میکند؛ کاربرد آن کشف است.
قانون طلایی انتخاب روش:
اگر میدانید دقیقاً چه چیزی را میخواهید پیشبینی کنید، یادگیری نظارتشده را انتخاب کنید. اگر در حال کاوش دادهها هستید و پاسخهای روشنی ندارید، یادگیری نظارتنشده را انتخاب کنید.
نتیجهگیری
یادگیری نظارتشده و نظارتنشده هر دو ابزارهای قدرتمندی در یادگیری ماشین هستند، اما هرکدام برای هدفی متفاوت طراحی شدهاند. وقتی دادهها برچسبدار و هدف مشخص است، یادگیری نظارتشده بهترین گزینه برای پیشبینی دقیق و مدلسازی قابلاعتماد خواهد بود. اما زمانی که با دادههای خام، بزرگ و بدون ساختار روبهرو هستیم و نیاز به کشف الگوها یا بخشبندی داریم، یادگیری نظارتنشده انتخاب اصلی است.
هر دو رویکرد مزایا و چالشهای مخصوص به خود دارند—از دقت بالای مدلهای نظارتشده تا قدرت کشف ناشناختهها در روشهای نظارتنشده. درک این تفاوتها به ما کمک میکند تا نهتنها بهترین الگوریتم را انتخاب کنیم، بلکه تحلیل دادهها را عمیقتر، تصمیمگیری را هوشمندانهتر و مدلسازی را کارآمدتر انجام دهیم.
در نهایت، انتخاب بین این دو روش بستگی به نوع داده، هدف پروژه و میزان دسترسی به برچسبهای معتبر دارد. اگر به دنبال پیشبینی هستیم، نظارتشده مناسبتر است؛ اگر به دنبال کشف الگو هستیم، نظارتنشده راهحل اصلی است. این شناخت، پایهای ضروری برای هر متخصص داده و گامی مهم در مسیر ساخت سیستمهای هوشمند و قابلاعتماد است.