
")
چرخه حیات یادگیری ماشین، در واقع یک نقشه راهِ ساختاریافته است که مسیرِ تولد تا تکامل یک مدل هوش مصنوعی را مشخص میکند. این فرآیند دقیقاً تعریف میکند که مدلهای یادگیری ماشین (ML) چگونه باید ساخته شوند، به مرحله اجرا (Deployment) برسند و در نهایت چگونه باید از آنها نگهداری شود.
اهداف
این چرخه شامل مجموعهای از گامهای پیوسته است که هدفشان فقط ساختن مدل نیست؛ بلکه تضمین میکنند که مدل نهایی:
۱. دقیق باشد (Accuracy)،
۲. قابل اعتماد باشد (Reliability)،
۳. قابلیت مقیاسپذیری (Scalability)
داشته باشد تا بتواند در ابعاد بزرگتر هم کار کند.
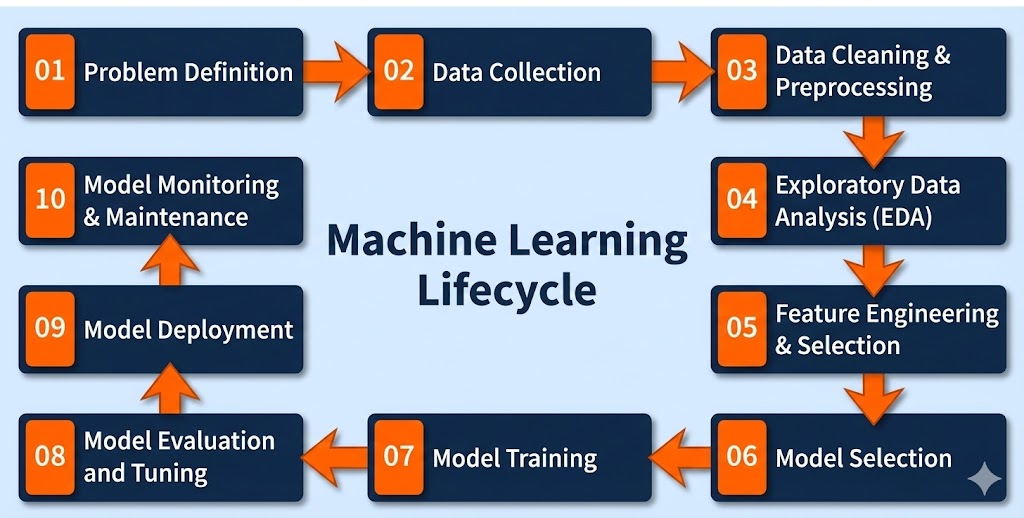
این چرخه شامل مراحل به هم پیوستهای است که از تعریف دقیق مسئله شروع میشود. سپس نوبت به جمعآوری و آمادهسازی دادهها، کشف الگوهای پنهان و مهندسی ویژگیها میرسد.
در مراحل بعدی، مدلها آموزش دیده و ارزیابی میشوند و نهایتاً در محیط عملیاتی (Production) مستقر میگردند. اما کار اینجا تمام نمیشود؛ عملکرد مدل باید به صورت مداوم پایش شود تا مشکلاتی مثل «رانش داده» ( تغییر رفتار دادهها در طول زمان) شناسایی شده و در صورت نیاز، مدل مجدداً بازآموزی شود.
در ادامه، گامهای کلیدی چرخه حیات یادگیری ماشین را با جزئیات مرور میکنیم:
این چرخه شامل مراحل به هم پیوستهای است که از تعریف دقیق مسئله شروع میشود. سپس نوبت به جمعآوری و آمادهسازی دادهها، کشف الگوهای پنهان و مهندسی ویژگیها میرسد.
در مراحل بعدی، مدلها آموزش دیده و ارزیابی میشوند و نهایتاً در محیط عملیاتی (Production) مستقر میگردند. اما کار اینجا تمام نمیشود؛ عملکرد مدل باید به صورت مداوم پایش شود تا مشکلاتی مثل «رانش داده» (-Data Drift تغییر رفتار دادهها در طول زمان) شناسایی شده و در صورت نیاز، مدل مجدداً بازآموزی شود.
در ادامه، گامهای کلیدی چرخه حیات یادگیری ماشین را با جزئیات مرور میکنیم:
گام اول: تعریف مسئله (Problem Definition)
اولین و شاید مهمترین قدم، شناسایی و تعریفِ شفافِ چالش یا مشکلی است که کسبوکار با آن دستوپنج نرم میکند. یک صورتمسئلهی دقیق و خوشتعریف، سنگبنای کلِ چرخه حیات پروژه را میسازد. در این مرحله است که جزئیات حیاتی مثل اهداف پروژه، خروجیهای مورد انتظار و محدوده کار با دقت و وسواس طراحی میشوند.
اقدامات کلیدی:
- همکاری با ذینفعان: تعامل نزدیک با مدیران و افراد کلیدی برای درک عمیق اهداف تجاری.
- تعیین چهارچوبها: تعریف دقیق اهداف پروژه، دامنه کار و معیارهایی که «موفقیت» پروژه را با آنها میسنجیم .
- شفافسازی خروجیها: اطمینان حاصل کردن از اینکه همه دقیقاً میدانند چه نتیجهای قرار است در نهایت حاصل شود.
گام دوم: جمعآوری دادهها (Data Collection)
فاز جمعآوری دادهها، حکمِ تأمین مواد اولیه را دارد. در این مرحله، ما به صورت سیستماتیک و روشمند، دیتاستهایی را گردآوری میکنیم که قرار است به عنوان «داده خام» برای آموزش مدل استفاده شوند. یک قانون طلایی در اینجا وجود دارد: کیفیت و تنوع دادهها، سرنوشت مدل شما را تعیین میکند. اگر دادهی بد وارد کنید، مدلِ بد تحویل میگیرید.
ویژگیهای حیاتی در جمعآوری دادهها :
- ارتباط: هر دادهای به کار ما نمیآید. دادهها باید دقیقاً با مسئلهای که تعریف کردهایم مرتبط باشند و ویژگیهای لازم را داشته باشند.
- کیفیت: فقط جمعآوری کافی نیست؛ باید مطمئن شویم که دادهها دقیق هستند و اصول اخلاقی در جمعآوری آنها رعایت شده است.
- کمیت: مدلهای هوشمند گرسنهی داده هستند. باید حجم کافی از داده را جمع کنید تا مدلتان قوی و پایدار شود.
- تنوع: دادهها نباید یکدست باشند. باید مجموعهای متنوع از دادهها را داشته باشید تا بتوانید طیف وسیعی از سناریوها و الگوهای مختلف را پوشش دهید.
گام سوم: پاکسازی و پیشپردازش دادهها (Data Cleaning & Preprocessing)
دادههای خام معمولاً نامرتب، آشفته و بدون ساختار هستند. استفاده مستقیم از این دادهها دقیقاً مثل آشپزی با مواد اولیه کثیف است؛ نتیجه نهایی قطعاً مدلی با دقت پایین و عملکرد ضعیف خواهد بود.
بنابراین، قبل از هر کاری باید دستی به سر و روی دادهها بکشیم:
- پاکسازی داده (Data Cleaning): این مرحله شبیه به گردگیری است. باید مشکلاتی مثل مقادیر گمشده (جاهای خالی در دیتاست)، دادههای پرت (اعداد عجیب و غریب که با بقیه همخوانی ندارند) و تناقضات را شناسایی و برطرف کنیم.
- پیشپردازش (Data Preprocessing):اینجا دادهها را برای فهمِ ماشین استاندارد میکنیم. کارهایی مثل یکسانسازی فرمتها، مقیاسبندی اعداد (Scaling) و تبدیل متغیرهای کیفی به کدهای عددی (Encoding) در این مرحله انجام میشود تا همه چیز یکدست شود.
- تضمین کیفیت (Data Quality): هدف نهایی این است که مطمئن شویم دادهها آنقدر منظم و سازمانیافته هستند که برای یک تحلیل دقیق و معنادار آماده باشند.
گام چهارم تحلیل اکتشافی دادهها (EDA):
برای پیدا کردن رازها و ویژگیهای پنهان در دلِ دادهها، از روشی به نام تحلیل اکتشافی دادهها (EDA) استفاده میکنیم. هدف این مرحله، درک عمیق ساختار دیتاست و بیرون کشیدن اطلاعاتی است که در نگاه اول دیده نمیشوند.
در طول فرایند EDA، الگوها و روندهایی آشکار میشوند که هرگز با چشم غیرمسلح قابل تشخیص نیستند. این اطلاعات ارزشمند، چراغ راهی برای تصمیمگیریهای هوشمندانه در مراحل بعدی خواهند بود.
ارکان اصلی تحلیل اکتشافی: (EDA)
- کاوشگری : استفاده از ابزارهای آماری و نمودارهای بصری برای جستوجو در دادهها و کشف الگوها.
- الگوها و روندها : شناسایی ساختارهای زیرپوستی، روند تغییرات و چالشهای احتمالی که در عمق دیتاست مخفی شدهاند.
- بینش : استخراج اطلاعات ارزشمندی که باعث میشوند در مراحل جلوتر، با چشمان باز تصمیم بگیرید.
- تصمیمگیری: استفاده از نتایج EDA برای انجام کارهای فنی مهم، مثل «مهندسی ویژگیها» و «انتخاب مدل مناسب».
گام پنجم: مهندسی و انتخاب ویژگیها (Feature Engineering & Selection)
این مرحله را میتوان هنرِ کیمیاگری دادهها نامید. مهندسی و انتخاب ویژگیها یک فرآیند تحولآفرین است که در آن دادههای خام به ورودیهایی تبدیل میشوند که مدل بتواند آنها را بهتر هضم کند. هدف نهایی این است که فقط ویژگیهای واقعاً مهم و تأثیرگذار را نگه داریم تا کارایی مدل بالا برود و از پیچیدگیهای غیرضروری کاسته شود.
این فرآیند شامل چهار رکن اصلی است:
- مهندسی ویژگی: همیشه دادههای موجود کافی نیستند. گاهی باید خلاقیت به خرج دهیم و ویژگیهای جدیدی بسازیم یا ویژگیهای فعلی را تغییر شکل دهیم تا الگوها و روابط پنهان، بهتر خودشان را نشان دهند.
- انتخاب ویژگی: قرار نیست همه اطلاعات را به خورد مدل بدهیم. در این بخش، زیرمجموعهای از ویژگیها را گلچین میکنیم که بیشترین تأثیر مثبت را روی عملکرد نهایی مدل دارند (حذف موارد اضافی).
- تخصص دامنه: اینجا دانش انسانی وارد بازی میشود. استفاده از دانش تخصصیِ مربوط به آن حوزه (مثلاً دانش پزشکی یا مالی) کمک میکند تا ویژگیهایی بسازیم که برای پیشبینی واقعاً معنادار هستند.
- بهینهسازی: ایجاد یک تعادل طلایی بین «دقت بالا» و «سادگی محاسباتی». یعنی با کمترین تعداد ویژگی، به بهترین نتیجه ممکن برسیم.
گام ششم: انتخاب مدل (Model Selection)
رسیدیم به یکی از حساسترین مراحل کار: انتخاب سلاح مناسب برای میدان نبرد! انتخاب مدل، قلب تپندهی یک پروژه یادگیری ماشین است. ما نمیتوانیم هر الگوریتمی را برداریم و استفاده کنیم؛ بلکه باید به دنبال گزینهای باشیم که دقیقاً با ماهیت مسئله، جنس دادهها، میزان پیچیدگی کار و خروجی که انتظار داریم، همخوانی داشته باشد.
نکات کلیدی:
- پیچیدگی: سنگ بزرگ علامت نزدن است! هنگام انتخاب مدل، حتماً به میزان پیچیدگی مسئله و نوع دادههایتان نگاه کنید. گاهی یک مدل ساده، بهتر از یک شبکه عصبی پیچیده جواب میدهد.
- فاکتورهای تصمیمگیری: فقط به «دقت» نگاه نکنید. باید فاکتورهای دیگری را هم وزنکشی کنید:
- عملکرد: چقدر دقیق است؟
- تفسیرپذیری: آیا میتوانیم دلیل تصمیمات مدل را بفهمیم و توضیح دهیم؟ (یا یک جعبه سیاه است؟)
- مقیاسپذیری: اگر حجم دادهها ۱۰ برابر شد، این مدل کم نمیآورد؟
- آزمایش و خطا: هیچ فرمول جادویی وجود ندارد. باید آستینها را بالا بزنید و مدلهای مختلف را روی دادههایتان تست کنید تا ببینید کدامیک بهترین عملکرد (Best Fit) را برای مسئله خاص شما دارد.
گام هفتم: آموزش مدل (Model Training)
حالا که مدل مناسب را انتخاب کردیم، نوبت به مرحله هیجانانگیز آموزش مدل میرسد. اینجا دقیقاً همان جایی است که «یادگیری» اتفاق میافتد! در این فرآیند، مدل را در معرض دادههای تاریخی قرار میدهیم تا مثل یک دانشآموز کوشا، الگوها، روابط و وابستگیهای موجود در دیتاست را کشف و درک کند.
ویژگیهای کلیدی:
- فرآیند تکرارپذیر: آموزش، یک اتفاق یکباره نیست؛ بلکه یک چرخه است. مدل بارها و بارها تمرین میکند و در هر دور، پارامترهایش تنظیم میشوند تا خطاها به حداقل برسند و دقت ذرهذره افزایش یابد.
- بهینهسازی: در این بخش، مدل را اصطلاحاً «تنظیم دقیق» (Fine-tune) میکنیم تا قدرت پیشبینی آن به بالاترین حد ممکن برسد.
- اعتبارسنجی: آموزش باید سختگیرانه باشد. هدف فقط یاد گرفتن دادههای قدیمی نیست؛ بلکه باید مطمئن شویم وقتی مدل با دادههای جدید و دیدهنشده (Unseen Data) روبرو میشود، باز هم دقیق و قابل اعتماد عمل میکند.
گام هشتم: ارزیابی و تنظیم دقیق مدل (Model Evaluation & Tuning)
این مرحله، «لحظه حقیقت» برای مدل شماست. ارزیابی مدل یعنی انجام تستهای سختگیرانه با استفاده از دادههای اعتبارسنجی (Validation) یا تست. هدف این است که ببینیم مدل وقتی با دادههای جدید و دیدهنشده روبرو میشود، چقدر دقیق عمل میکند. این کار دقیقاً نقاط قوت و ضعف مدل را برملا میکند.
اگر مدل نتواند نمره قبولی بگیرد یا به سطح عملکرد مورد نظر نرسد، باید دوباره دست به آچار شویم؛ یعنی مدل را مجدداً تنظیم کنیم و هایپرپارامترها را تغییر دهیم تا دقت پیشبینی بالا برود.
ویژگیهای اصلی:
- معیارهای ارزیابی: فقط گفتنِ اینکه “مدل خوب است” کافی نیست. ما از معیارهای دقیق ریاضی مثل دقت (Accuracy)، صحت (Precision)، فراخوانی (Recall) و امتیاز F1 استفاده میکنیم تا کارنامه عملکرد مدل را با جزئیات کامل بسنجیم.
- نقاط قوت و ضعف: تستهای دقیق به ما نشان میدهند که مدل در چه سناریوهایی عالی عمل میکند و در چه جاهایی لنگ میزند (نقطه ضعف دارد).
- بهبود تکرارپذیر: کار با یک بار تست تمام نمیشود. فرآیند تنظیم مدل (Tuning) شروع میشود؛ پارامترها را تغییر میدهیم و دوباره تست میکنیم تا دقت پیشبینی بهتر و بهتر شود.
- استحکام مدل: هدف نهاییِ این تنظیماتِ پیدرپی، رسیدن به مدلی است که نه تنها دقیق باشد، بلکه جانسخت و قابلاعتماد باشد و در شرایط مختلف پایداری خود را حفظ کند.
گام نهم: استقرار مدل (Model Deployment)
حالا نوبت به «روز اجرا» رسیده است! مدل آماده است تا از محیط آزمایشگاهی خارج شده و وارد دنیای واقعی شود. استقرار مدل یعنی ادغام کردن مدلِ پیشبینیکننده با سیستمها و نرمافزارهای فعلی شرکت، تا کسبوکار بتواند از قدرت آن برای تصمیمگیریهای هوشمندانه و واقعی استفاده کند. به زبان ساده، اینجا جایی است که مدل شروع به بازگرداندن سرمایه میکند.
ویژگیهای اصلی:
- یکپارچهسازی با سیستمهای موجود: مدل نباید مثل یک جزیره جداافتاده عمل کند؛ بلکه باید با زیرساختها و نرمافزارهای فعلی شرکت «جفتوجور» و ادغام شود.
- فعالسازی تصمیمگیری: هدف فقط داشتن مدل نیست؛ هدف این است که مدیران یا سیستمهای خودکار بتوانند بر اساس پیشبینیهای این مدل، تصمیمات بهتری بگیرند.
- تضمین امنیت و مقیاسپذیری: باید مطمئن شویم که اگر فردا تعداد کاربران ۱۰ برابر شد، سیستم از کار نمیافتد (مقیاسپذیری) و همچنین در برابر نفوذ و سرقت اطلاعات مقاوم است (امنیت).
- ارائه APIها و پایپلاینها: برای اینکه بقیه نرمافزارها بتوانند به راحتی با مدل حرف بزنند و از آن استفاده کنند، باید پلهای ارتباطی استانداردی (مثل APIها) برای استفاده در محیط عملیاتی (Production) فراهم کنیم.
گام دهم: پایش و نگهداری مدل (Model Monitoring and Maintenance)
بعد از اینکه مدل مستقر شد، کار تمام نیست؛ تازه مراقبتها شروع میشود. مدلها باید به صورت مداوم پایش شوند تا مطمئن شویم در گذر زمان همچنان عملکرد خوبی دارند. رصد کردن دائمی به ما کمک میکند تا مواردی مثل رانش داده، افت دقت یا تغییر الگوها را سریع تشخیص دهیم. در دنیای واقعی، برای اینکه مدل قابلاطمینان باقی بماند، ممکن است نیاز باشد آن را دوباره آموزش دهیم.
ویژگیهای اصلی:
- رصد عملکرد در گذر زمان: عملکرد مدل را مثل علائم حیاتی، لحظهبهلحظه زیر نظر بگیرید.
- تشخیص رانش داده یا رانش مفهوم: شناسایی تغییرات ناگهانی یا تدریجی در دادههای ورودی یا مفاهیم، که باعث میشوند دانش قبلی مدل بیاستفاده شود.
- بروزرسانی و بازآموزی: هر وقت دقت مدل افت کرد، باید آن را آپدیت کرد و با دادههای تازه دوباره آموزش داد.
- ثبت وقایع و هشدارها: نگهداری لاگها (Logs) و تنظیم هشدارهای آنی برای باخبر شدن از مشکلات در لحظه وقوع.
مطالعه موردی
مطالعه موردی1: فروشنده ذهنخوان (Recommendation System)
پروژه: سیستم پیشنهاد محصول هوشمند (شبیه دیجیکالا یا آمازون)
۱. تعریف مسئله (Problem Definition)
- مشکل: کاربران در بین هزاران کالا گم میشوند و بدون خرید سایت را ترک میکنند.
- هدف: افزایش فروش با پیشنهاد دادن کالاهایی که کاربر به احتمال زیاد دوست دارد (Cross-selling).
- خروجی: بخشی در زیر هر محصول با عنوان “کسانی که این را دیدند، اینها را هم خریدند”.
۲. جمعآوری دادهها (Data Collection)
- ثبت تمام کلیکها، افزودن به سبد خرید، لایکها و جستجوهای کاربران (دادههای ضمنی).
- استفاده از پروفایل کاربران (سن، جنسیت، خریدهای قبلی).
۳. پاکسازی و پیشپردازش (Data Cleaning & Preprocessing)
- پاکسازی: حذف رباتهایی که الکی روی کالاها کلیک میکنند.
- پیشپردازش: تبدیل لیست خریدها به یک “ماتریس کاربر-کالا” (User-Item Matrix) بزرگ و پر از جاهای خالی.
۴. تحلیل اکتشافی (EDA)
- تیم میفهمد که ۸۰٪ فروشها فقط مربوط به ۲۰٪ کالاهای محبوب است (قانون پارتو). این یعنی مدل ممکن است فقط کالاهای معروف را پیشنهاد دهد و کالاهای خاص دیده نشوند .
۵. مهندسی ویژگیها (Feature Engineering)
- رفع مشکل شروع سرد: برای کاربرانی که تازه عضو شدهاند و هیچ کلیکی ندارند، ویژگیهایی بر اساس “مکان جغرافیایی” یا “زمان ورود به سایت” ساخته میشود.
۶. انتخاب مدل (Model Selection)
- استفاده از روش “فیلتر همکاری ” (Collaborative Filtering): پیدا کردن کاربرانی که سلیقه شبیه به هم دارند.
- یا استفاده از Deep Learning برای درک عمیقتر رابطه بین عکس محصول و سلیقه کاربر.
۷. آموزش مدل (Model Training)
- مدل یاد میگیرد که مثلاً کسانی که “گوشی آیفون” خریدند، احتمالاً به “قاب سیلیکونی” و “ایرپاد” هم نیاز دارند، نه “شارژر سامسونگ”.
۸. ارزیابی و تنظیم (Model Evaluation)
- تست A/B: مدل جدید را برای ۱۰٪ کاربران فعال میکنند. اگر میزان کلیک و خرید این گروه بیشتر از بقیه بود، یعنی مدل موفق است.
۹. استقرار مدل (Deployment)
- مدل باید فوقالعاده سریع باشد (زیر ۱۰۰ میلیثانیه) تا وقتی کاربر صفحه را باز میکند، پیشنهادها آماده باشند. برای این کار از دیتابیسهای سریع (NoSQL) استفاده میشود.
۱۰. پایش و نگهداری (Monitoring)
- رانش مفهوم: با شروع فصل مدارس، ناگهان تقاضا برای “لوازم تحریر” بالا میرود اما مدل هنوز دارد “عینک آفتابی” پیشنهاد میدهد.
- اقدام: مدل باید به سرعت با دادههای روزانه آپدیت شود تا ترندهای فصلی را بفهمد.
مطالعه موردی2: پروژه هوشمند تخمین قیمت مسکن (HomePrice AI)
فرض کنید یک شرکت املاک بزرگ میخواهد سیستمی بسازد که قیمت خانهها را دقیقتر از کارشناسان انسانی تخمین بزند. بیایید ببینیم این پروژه چگونه ۱۰ مرحله چرخه حیات یادگیری ماشین را در دنیای واقعی طی میکند:
۱. تعریف مسئله (Problem Definition)
- مشکل: قیمتگذاری دستی توسط مشاوران معمولاً دارای خطا است، زمان زیادی میبرد و گاهی سلیقهای انجام میشود.
- هدف: ساخت مدلی که با دریافت ویژگیهای خانه (مثل متراژ، منطقه، سن بنا)، قیمت فروش را با خطای کمتر از ۵٪ پیشبینی کند.
- خروجی: یک سرویس آنلاین که کاربر مشخصات ملک را وارد کرده و قیمت پیشنهادی را مشاهده میکند.
۲. جمعآوری دادهها (Data Collection)
- تیم داده، اطلاعات ۱۰ سال اخیر معاملات مسکن را از سامانه ثبت املاک و آگهیهای آنلاین جمعآوری میکند.
- تنوع: دادهها شامل انواع خانههای ویلایی، آپارتمان، نوساز و کلنگی در تمام مناطق شهر است تا مدل جامع باشد.
۳. پاکسازی و پیشپردازش (Data Cleaning & Preprocessing)
- پاکسازی: رکوردهایی که قیمتشان ثبت نشده یا اطلاعات غلط دارند (مثلاً متراژ صفر متر) حذف میشوند.
- پیشپردازش: نام محلهها (مثل “تجریش” یا “ونک”) که متنی هستند، به کدهای عددی تبدیل میشوند (Encoding) تا مدل بتواند آنها را پردازش کند.
۴. تحلیل اکتشافی (EDA)
- تیم با رسم نمودارها متوجه میشود که خانههای نزدیک به ایستگاه مترو، حدود ۲۰٪ گرانتر هستند (کشف الگو).
- همچنین مشخص میشود دادههای مربوط به سالهای تورم شدید، رفتار متفاوتی دارند و نیاز به بررسی جداگانه دارند.
۵. مهندسی ویژگیها (Feature Engineering)
- خلاقیت: تیم یک ویژگی جدید به نام «عمر بنا» میسازد (سال جاری منهای سال ساخت).
- تخصص دامنه: با مشورت کارشناسان املاک، ویژگی “نورگیر بودن” که تاثیر زیادی بر قیمت دارد، به دادهها اضافه میشود.
۶. انتخاب مدل (Model Selection)
- چون مسئله ما پیشبینی یک عدد پیوسته (قیمت) است، مدلهای رگرسیون مناسب هستند.
- تیم تصمیم میگیرد از مدل XGBoost استفاده کند؛ زیرا تعادل بسیار خوبی بین دقت بالا و سرعت پردازش دارد.
۷. آموزش مدل (Model Training)
- ۸۰٪ از دادههای معاملات گذشته به مدل داده میشود. مدل بارها تمرین میکند تا رابطه ریاضی بین “ویژگیها” (مثل متراژ) و “قیمت” را یاد بگیرد.
- پارامترها طوری تنظیم میشوند که اختلاف قیمت پیشبینی شده با قیمت واقعی در دادههای آموزشی به حداقل برسد.
۸. ارزیابی و تنظیم (Model Evaluation)
- مدل روی ۲۰٪ باقیمانده (دادههای دیدهنشده) تست میشود.
- چالش: نتایج نشان میدهد مدل در قیمتگذاری خانههای لوکس خطای زیادی دارد.
- تنظیم مجدد: هایپرپارامترها تغییر میکنند تا حساسیت مدل به امکانات لوکس (مثل استخر و روفگاردن) بیشتر شود و دوباره تست میشود.
۹. استقرار مدل (Deployment)
- مدل نهایی روی سرورهای شرکت قرار میگیرد و از طریق یک API به اپلیکیشن موبایل متصل میشود.
- حالا کاربران واقعی میتوانند مشخصات خانه خود را وارد کنند و در کسری از ثانیه قیمت دقیق را ببینند.
۱۰. پایش و نگهداری (Monitoring)
- شش ماه بعد، ناگهان بازار مسکن دچار رکود میشود و الگوی قیمتها تغییر میکند (Data Drift).
- سیستم هشدار میدهد که دقت پیشبینیها افت کرده است.
- اقدام: مدل با دادههای جدیدِ ۶ ماه اخیر “بازآموزی” (Retrain) میشود تا خودش را با شرایط جدید بازار وفق دهد.
جمعبندی
تکتک این گامها برای ساختن یک مدل یادگیری ماشینِ موفق ضروری هستند؛ مدلی که بتواند بینشهای ارزشمند و پیشبینیهای دقیق ارائه دهد. با پیروی از این چرخه حیات یادگیری ماشین، سازمانها میتوانند مسائل پیچیده را به روشی علمی حل کنند و از قدرت واقعی هوش مصنوعی بهرهمند شوند.