

1. مقدمه
خوشهبندی افرازی (Partitional Clustering) یکی از مهمترین خانوادههای روشهای خوشهبندی در یادگیری بدونناظر است که هدف آن، تقسیم دادهها به چند گروه مجزا و همگن بر اساس میزان شباهت میان نمونههاست. در این رویکرد، هر داده معمولاً به یک خوشه اختصاص مییابد و الگوریتم تلاش میکند ساختاری بهینه از دادهها را با کمینهسازی فاصله یا عدمشباهت درونخوشهای به دست آورد. این ویژگی باعث شده است که خوشهبندی افرازی در تحلیل اکتشافی دادهها، استخراج الگوهای پنهان و تصمیمگیری دادهمحور جایگاه ویژهای داشته باشد.
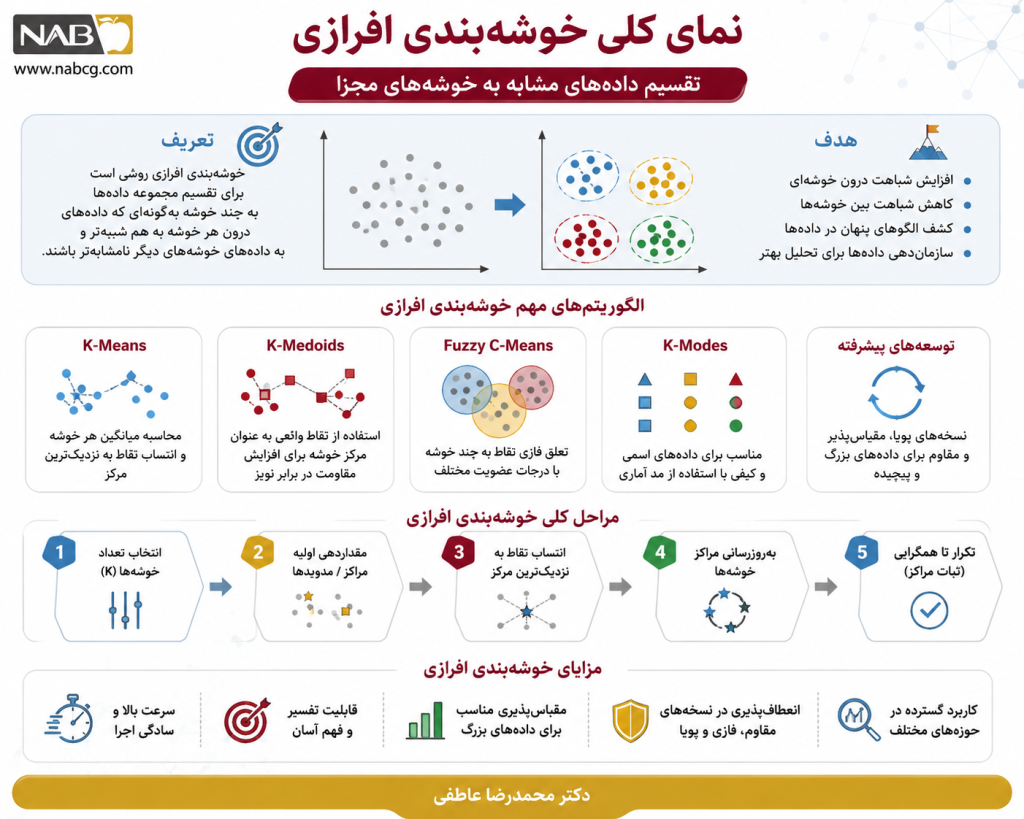
2. الگوریتمهای خوشهبندی افرازی (Partitional Clustering)
مهمترین الگوریتمهای خوشهبندی افرازی عبارتاند از:
- K-Means
الگوریتمی سریع و پرکاربرد که دادهها را بر اساس فاصله از مراکز خوشه به گروههای مجزا تقسیم میکند.
- K-Medoids
نسخهای مقاومتر از K-Means که بهجای میانگین، از نقاط واقعی داده به عنوان مرکز خوشه استفاده میکند.
- PAM (Partitioning Around Medoids)
یکی از اصلیترین پیادهسازیهای K-Medoids که با جستجوی حریصانه، بهترین مدویدها را انتخاب میکند.
- CLARA (Clustering Large Applications)
نسخهای مقیاسپذیر از K-Medoids که برای مجموعهدادههای بزرگ از نمونهبرداری تصادفی استفاده میکند.
- CLARANS
الگوریتمی پیشرفتهتر که با جستجوی تصادفی در فضای همسایگی، توازن بهتری میان دقت و سرعت ایجاد میکند.
- K-Modes
مناسب برای دادههای اسمی و کیفی که بهجای میانگین، از مد آماری استفاده میکند.
- Fuzzy C-Means (FCM)
الگوریتمی فازی که به هر داده امکان تعلق همزمان به چند خوشه با درجات عضویت مختلف را میدهد.
- FCM با خوشههای پویا (FCMdc)
نسخه توسعهیافته FCM که تعداد خوشهها را در طول فرایند بهصورت پویا تنظیم میکند.
- Fanny
الگوریتمی فازی و مبتنی بر ماتریس عدمشباهت که برای دادههای پیچیده و غیر اقلیدسی مناسب است.
3. رویکرد های خوشهبندی افرازی (Partitional Clustering)
فلسفه محاسباتی و مکانیزم عملکرد
مکتب خوشهبندی افرازی، فضای چندبعدی ویژگیها را به صورت صلب یا نرم به مجموعهای از گروههای مجزا خرد میکند. فرضیه بنیادین و استراتژیک در این رویکرد این است که دادهها باید حول محور نمایندگان اصلی کلاستر (که میتوانند میانگینها، مدها یا نقاط مرکزی فازی باشند) سازماندهی و بهینهسازی شوند. الگوریتم با یک فرآیند تکرارشونده و پویا (Iterative Process)، مرتباً موقعیت این نمایندگان را تغییر میدهد تا فواصل و خطای هندسی نقاط تا مراکز کلاستر به حداقل ممکن برسد.
3.۱. الگوریتم K-Means
یک الگوریتم تفکیکی صلب و نمونهمحور (Centroid-based) است که با هدف کمینهسازی واریانس درونخوشهای، فضای چندبعدی دادهها را به K بخش مجزا و محدب (سلولهای ورونوی – Voronoi Cells) تقسیم میکند. این روش فرض را بر کروی بودن هندسه خوشهها میگذارد.
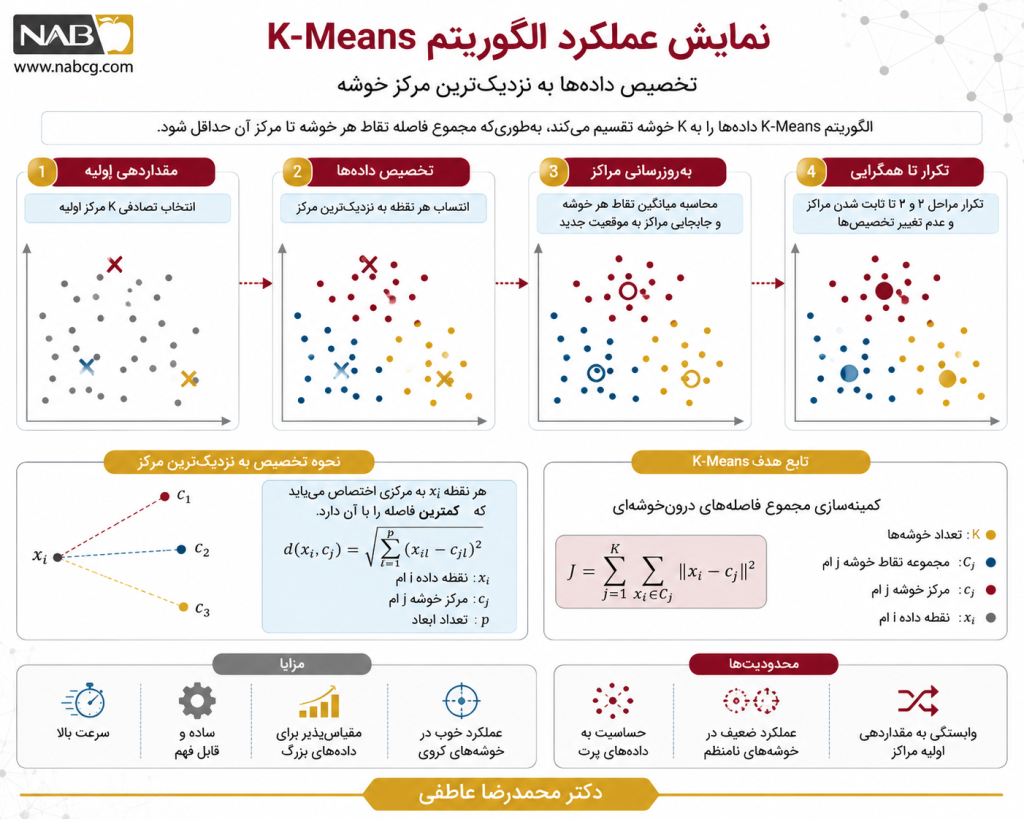
نحوه عملکرد و گامهای اجرایی
- مقداردهی اولیه (Initialization): انتخاب تصادفی K نقطه در فضا به عنوان مراکز ثقل اولیه (Centroids).
- تخصیص صلب (Assignment): محاسبه فاصله تکتک دادهها تا همه مراکز و انتساب هر نقطه به نزدیکترین مرکز بر اساس معیار اقلیدسی.
- بهروزرسانی (Update): محاسبه مجدد مختصات هر مرکز ثقل از طریق میانگینگیری هندسی از تمام نقاط تخصیصیافته به آن خوشه.
- تکرار (Iteration): تکرار مداوم گامهای ۲ و ۳ تا زمان ارضای شرط توقف (عدم تغییر مکان مراکز یا رسیدن به سقف تکرار تعیینشده).
فرمول ریاضی و تابع هدف:
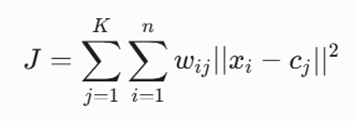
معرفی متغیرها:
- K: تعداد خوشههای هدف (تعیینشده از سوی کاربر).
- n: تعداد کل نقاط داده در دیتاست.
- xi: بردار ویژگیهای نقطه داده i-ام.
- wij: بردار وزن تخصیص باینری؛ اگر نقطه xi به خوشه j تخصیص یابد مقدار آن 1 و در غیر این صورت 0 است.
.
مزایا و نقاط قوت
- سرعت محاسباتی بالا
- سادگی مفرط: درک منطق ریاضی و پیادهسازی کد آن بسیار آسان است.
- مقیاسپذیری: به راحتی با تعداد دادههای زیاد تطبیق پیدا میکند.
.
معایب و محدودیتها
- وابستگی به مقداردهی اولیه
- حساسیت شدید به دادههای پرت (Outliers)
- ناتوانی در کشف اشکال نامنظم
.
کاربردهای واقعی
- بخشبندی مشتریان (Customer Segmentation)
- فشردهسازی تصویر (Image Quantization)
- پیشپردازش دادهها
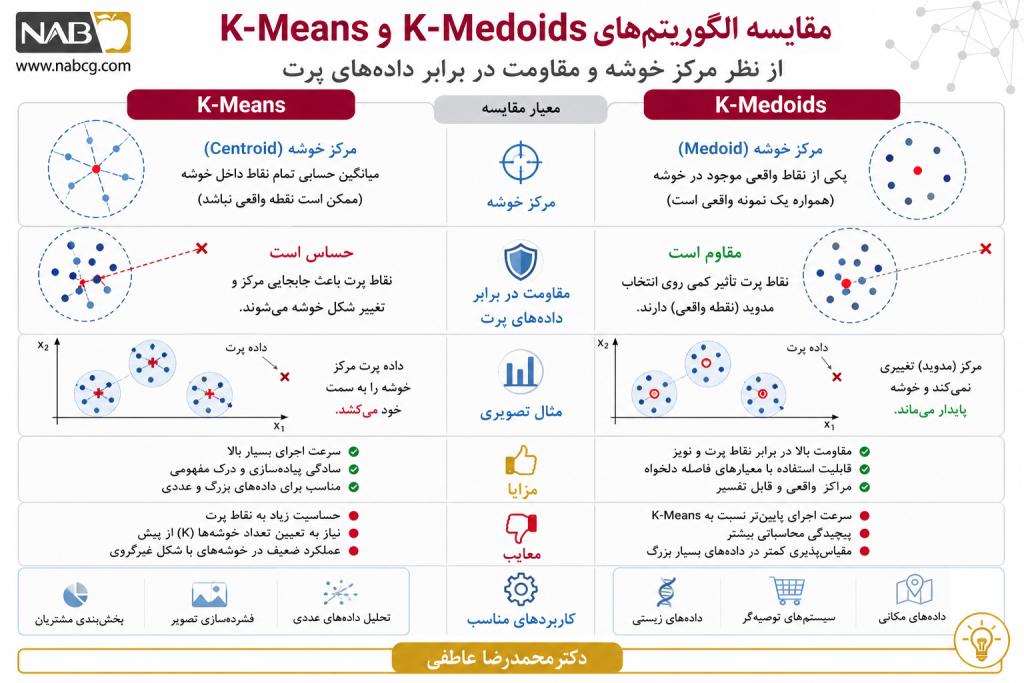
3.۲. الگوریتم K-Medoids
یک الگوریتم تفکیکی صلب و نمونهمحور است که به عنوان نسخه مقاوم و مستحکم (Robust) الگوریتم K-Means شناخته میشود. این الگوریتم با هدف کاهش حساسیت شدید به نویزها و دادههای پرت طراحی شده است. تفاوت بنیادی آن با K-Means در این است که مرکز خوشه (Centroid) در اینجا یک میانگین ریاضی فرضی نیست، بلکه باید لزوماً یک نقطه واقعی و موجود در دیتاست (Medoid) باشد.
نحوه عملکرد و گامهای اجرایی
- انتخاب مدویدهای اولیه (Initialization): انتخاب تصادفی K نقطه واقعی از میان دادهها به عنوان مدویدهای اولیه.
- تخصیص صلب (Assignment): محاسبه فاصله تمام نقاط داده تا K مدوید انتخابشده و انتساب هر نقطه به نزدیکترین مدوید (معمولاً بر اساس معیار منهتن).
- ارزیابی و جابهجایی (Swap): به ازای هر خوشه، یک نقطه غیرمرکزی جایگزین مدوید فعلی میشود و میزان بهبود یا کاهش تابع هزینه کل محاسبه میگردد. اگر این جابهجایی هزینه را کاهش دهد، نقطهی جدید به عنوان مدوید جایگزین میشود.
- تکرار (Iteration): تکرار مداوم گامهای ۲ و ۳ تا زمانی که هیچ جابهجایی جدیدی نتواند هزینه کل سیستم را کاهش دهد و مدویدها کاملاً ثابت شوند.
تابع هدف
این الگوریتم به دنبال کمینهسازی مجموع فواصل مطلق یا میزان عدمشباهت میان نقاط و مدوید مربوطه است:
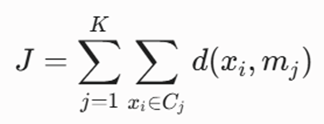
- معرفی متغیرها:
- Cj: مجموعه نقاط قرار گرفته در خوشه j-ام.
- K: تعداد خوشههای هدف.
- mj: بردار ویژگیهای نقطه واقعی انتخابشده به عنوان مرکز (Medoid) خوشه j-ام.
- xi: نقاط داده متعلق به آن کلاستر.
.
مزایا و نقاط قوت
- مقاومت فوقالعاده بالا در برابر دادههای پرت
- انعطاف پذیری در معیار فاصله
.
کاربردهای واقعی
- تحلیل دادههای بیوانفورماتیک و ژنتیک
- سیستمهای توصیهگر (Recommender Systems)
.
3.۳. الگوریتم PAM
نخستین، اصیلترین و استانداردترین پیادهسازی هندسی رویکرد K -Medoids است. این متد برای یافتن بهینهترین نقاط واقعی به عنوان مرکز خوشه، یک موتور جستجوی حریصانه (Greedy Search) را به کار میگیرد تا اثر تخریبی دادههای پرت را خنثی کند.
گامهای اجرایی
این الگوریتم به طور کلی در دو فاز اصلی عمل میکند:
- فاز ساخت (Build Phase): الگوریتم با یک استراتژی گامبهگام، K نقطه واقعی از دیتاست را که مجموع فواصل آنها با بقیه نقاط کمینه است، انتخاب کرده و به عنوان مراکز اولیه (Initial Medoids) معرفی میکند.
- فاز جابهجایی (Swap Phase): الگوریتم به صورت مداوم و جفتجفت، نقاط مرکزی فعلی را با نقاط غیرمرکزی جایگزین (Swap) میکند. در هر بارگذاری، میزان تغییر در تابع هزینه کل محاسبه میشود. اگر جابهجایی باعث کاهش هزینه شود، ترکیب جدید حفظ میگردد. این چرخه تا زمانی که هیچ جابهجایی جدیدی نتواند هزینه مطلق را کاهش دهد، ادامه مییابد.
تابع هدف ریاضی
تابع هدف بر اساس کمینهسازی مجموع اختلافات یا فواصل مطلق (L1norm) بین هر نقطه و نزدیکترین مدوید واقعی سنجیده میشود:
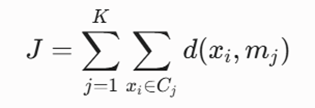
معرفی متغیرها
- K: تعداد خوشههای مدنظر برای افراز دادهها.
- Cj: مجموعه نقاط اختصاصیافته به خوشه j-ام.
- mj: نقطه کاملاً واقعی انتخابشده به عنوان مدوید (Medoid) اصلی خوشه j-ام.
- xi: بردار ویژگیهای نقاط داده متعلق به کلاستر Cj..
- d(xi, mj): شاخص سنجش فاصله منهتن بین نمونه داده و مدوید مربوطه.
.
مزایا و نقاط قوت
- دقت ریاضی فوقالعاده بالا
- مقاومت ذاتی در برابر نویز
.
معایب و محدودیتها
- پیچیدگی زمانی سنگین: پیچیدگی محاسباتی این الگوریتم در فاز جابهجایی به صورت O (K(n-K)^2) ارزیابی میشود. این ابعاد زمانی سنگین، استفاده از PAM را در مجموعهدادههای بزرگ و کلاندادهها عملاً غیرممکن میکند.
.
کاربردهای واقعی
- تحلیل شبکههای توزیع و لجستیک
- خوشهبندی گروههای کوچک بیولوژیکی
.
3.۴. الگوریتم (Clustering LARGE Applications) CLARA
یک الگوریتم تفکیکی و مقیاسپذیر از خانواده K-Medoids است که محدودیتهای شدید محاسباتی و زمانی روش PAM را در مواجهه با مجموعهدادههای بزرگ (Big Data)، از طریق بهکارگیری تئوری نمونهبرداری آماری (Statistical Sampling) برطرف میکند.
گامهای اجرایی
- نمونهبرداری آماری: استخراج تصادفی یک زیرمجموعه یا نمونه کوچک با حجم ثابت از کل مجموعهداده اصلی.
- اجرای الگوریتم مبنا: اعمال فرآیند کامل و سنگین الگوریتم PAM منحصراً روی نمونه تصادفی استخراجشده جهت یافتن مدویدهای بهینه آن بخش.
- ارزیابی و توسعه: تخصیص تکتک دادههای کل دیتابیس اصلی به نزدیکترین مدوید یافتشده و محاسبه میانگین هزینه کل.
- تکرار و بهینهسازی: تکرار تکرارهای چرخه (مراحل ۱ تا ۳) به تعداد مشخص و انتخاب نهایی مدویدهایی که کمترین هزینه مطلق را برای کل دادهها تولید کردهاند.
تابع هدف ریاضی
کمینهسازی میانگین فواصل کل نقاط دیتابیس (n) نسبت به مدویدهای منتخب استخراجشده از نمونه آماری (S)
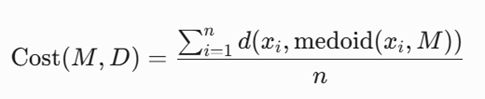
معرفی متغیرها
- K: تعداد خوشههای هدف.
- n: تعداد کل نقاط مجموعهداده اصلی.
- S: حجم نمونه آماری تصادفی (معمولاً بر اساس فرمول استاندارد 40 + 2K تعیین میشود).
- M: مجموعه مدویدهای کاندید و منتخب.
- d: تابع فاصله (معیار فاصله منهتن).
.
مزایا و نقاط قوت
- مقیاسپذیری عالی روی دادههای بزرگ.
- کاهش چشمگیر پیچیدگی زمانی به O (KS^2 + K(n-K)).
- حفظ خاصیت مقاومت در برابر نویز و دادههای پرت.
.
معایب و محدودیتها
- وابستگی شدید خروجی به شانس و کیفیت نمونهبرداریهای تصادفی اولیه.
- افت شدید کیفیت کلاسترینگ در صورت عدم حضور مدویدهای واقعی در نمونههای استخراجشده.
.
کاربردهای واقعی
- بخشبندی مشتریان در دیتابیسهای تجاری بسیار بزرگ.
- معدنکاوی دادههای کلان کلیکرشتهای (Clickstream Data).
.
3.۵. الگوریتم CLARANS
یک الگوریتم تفکیکی پیشرفته از خانواده K-Medoids است که محدودیتهای نمونهبرداری صلب در CLARA را با پویامیک کردن فرآیند استخراج دادهها از بین میبرد. این متد فضای مسئله را به عنوان یک گراف ریاضی مدلسازی کرده و با استفاده از رویکرد جستجوی تصادفی ، تعادلی بهینه میان سرعت محاسباتی و دقت ساختاری برقرار میسازد.
گامهای اجرایی
- مدلسازی گراف فضا: تعریف هر ترکیب فرضی از K مدوید به عنوان یک گره (Node) در یک گراف همسایگی بزرگ.
- انتخاب گره مبدا: استخراج تصادفی یک گره به عنوان نقطه شروع کلاسترینگ و محاسبه هزینه فواصل کل دادهها نسبت به آن.
- کاوش تصادفی همسایگان: ارزیابی موضعی و تصادفی گرههای همسایه (که تنها در یک مدوید با گره فعلی تفاوت دارند).
- جهش پویا: انتقال و جهش فوری به سمت گره همسایه در صورت یافتن هزینه کمتر و نوسازی ساختار کلاسترها.
- ارضای شرط توقف: تکرار فرآیند تا زمانی که سقف مشخصی از تلاشهای تصادفی ناموفق برای یافتن همسایه بهتر سپری شود.
تابع هدف ریاضی
بهینهسازی موضعی تابع هزینه فواصل مطلق در ساختار گراف همسایگی با مکانیزم بازگشت تصادفی دینامیک:
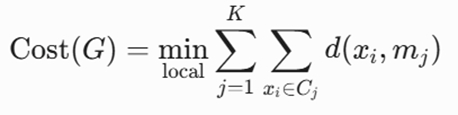
معرفی متغیرها
- K: تعداد خوشههای هدف.
- numlocal: تعداد دفعات تکرار کل فرآیند جستجوی بهینه موضعی برای فرار از بهینههای محلی.
- maxneighbor: حداکثر تعداد همسایههای تصادفی ارزیابیشده برای هر گره در هر گام.
- mj: مدویدهای پویا در گراف همسایگی فضا.
- d: تابع فاصله (معیار فاصله منهتن).
.
مزایا و نقاط قوت
- دقت محاسباتی بسیار بالاتر نسبت به الگوریتم .CLARA.
- عدم وابستگی صلب به شانس استخراج نمونه تصادفی اولیه.
- توانایی عالی در کاوش فضاهای غیرخطی و چندبعدی.
.
معایب و محدودیتها
- وابستگی زمان کل اجرای برنامه به تنظیمات پارامترهای کنترلی تکرار.
- پیچیدگی بالای پیادهسازی و فرمولاسیون ریاضی ساختار گراف در مقایسه با روشهای سنتی.
.
کاربردهای واقعی
- کلاسترینگ دادههای مکانی (Spatial Data) و نقشهبرداریهای جغرافیایی چندبعدی.
- شناسایی الگوهای پیچیده در سیستمهای اطلاعات جغرافیایی (GIS).
.
3.۶. الگوریتم K-Modes
یک الگوریتم تفکیکی و صلب (Hard) از خانواده K-Means است که منحصراً برای خوشهبندی دادههای کیفی و اسمی (Categorical Data) بازطراحی شده است. این متد با حذف کامل مفاهیم فواصل هندسی غیراقلیدسی، از شاخصهای آماری فراوانی برای گروهبندی بهره میبرد.
گامهای اجرایی
- تعیین مدهای اولیه: انتخاب تصادفی K نمونه از دادههای اسمی به عنوان مدهای اولیه خوشهها.
- تخصیص دادهها: سنجش شباهت تکتک نمونهها با K مد موجود بر اساس «تابع عدمتطابق فرکانسی» و انتساب هر داده به کلاستری با کمترین امتیاز عدمتطابق.
- بهروزرسانی مراکز: بازسازی و نوسازی بردار ویژگیهای هر مرکز خوشه با محاسبه شاخص آماری نما (Mode) یا همان پرفراوانترین ویژگی اسمی درون هر کلاستر.
- تکرار چرخه: تکرار مداوم گامهای ۲ و ۳ تا زمان ثبات کامل مدهای کلاسترها و عدم تغییر مرزها.
تابع هدف ریاضی
کمینهسازی مجموع امتیازهای عدمتطابق فرکانسی متغیرهای اسمی بین نقاط داده و مدهای مربوطه:
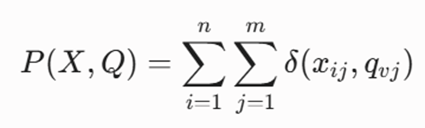
معرفی متغیرها
- K: تعداد خوشههای اسمی هدف.
- X: ماتریس دادههای ورودی حاوی متغیرهای کیفی.
- Q: بردار مدهای (Modes) نهایی کلاسترها.
.
مزایا و نقاط قوت
- پردازش مستقیم دادههای اسمی بدون نیاز به کدگذاریهای عددی تصنعی (مانند One-Hot Encoding).
- حفظ ماهیت و معنای واقعی متغیرهای کیفی.
- سرعت محاسباتی بالا و پیچیدگی زمانی خطی.
.
معایب و محدودیتها
- ناتوانی ذاتی در پردازش مجموعهدادههای ترکیبی (مخلوط همزمان ویژگیهای عددی و اسمی).
- حساسیت بالا به انتخاب مدهای اولیه و احتمال سقوط در بهینههای محلی.
.
کاربردهای واقعی
- متنکاوی و خوشهبندی اسناد متنی بر اساس کلمات کلیدی.
- تحلیل پرسشنامههای کیفی و دستهبندی لاگهای سیستمهای نرمافزاری.
.
3.۷. الگوریتم (Fuzzy C-Means) FCM
یک الگوریتم خوشهبندی افرازی و مبتنی بر منطق فازی (Soft Clustering) است که مرزهای صلب و باینری را حذف میکند. در این روش، هر نقطه داده لزوماً به یک خوشه واحد تعلق ندارد، بلکه میتواند با درجات عضویت (Membership Degrees) مختلف مابین صفر و یک، به طور همزمان عضوی از تمامی خوشهها باشد.
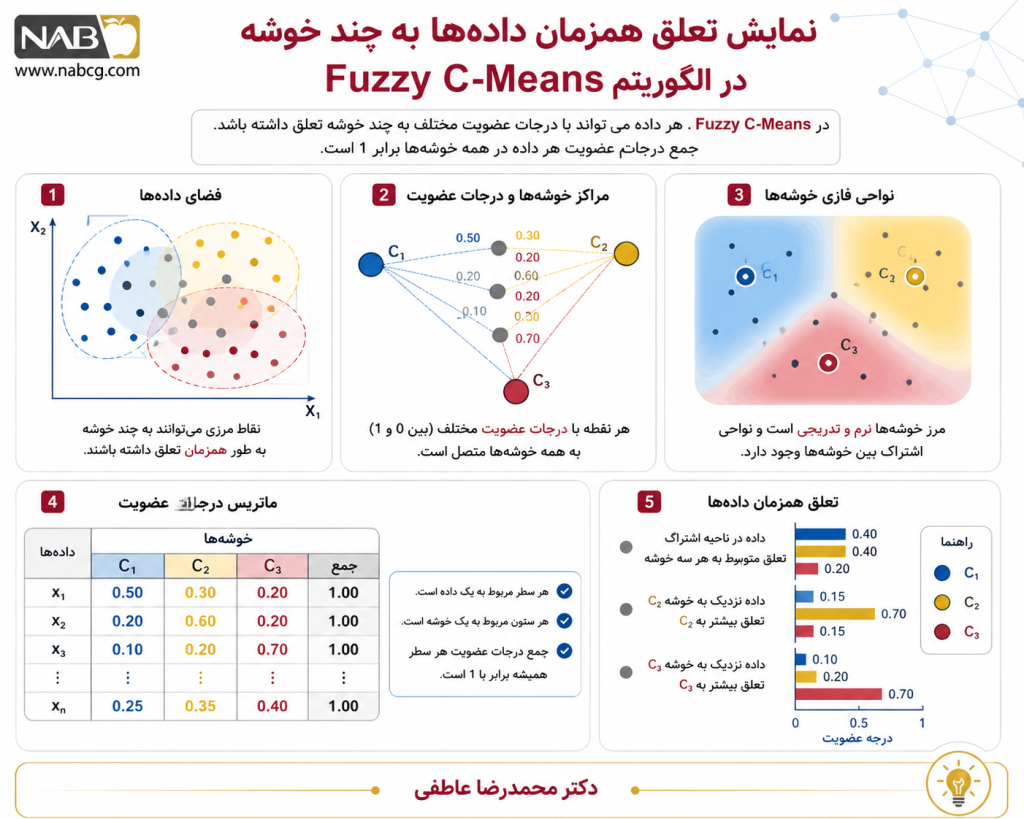
گامهای اجرایی
- مقداردهی اولیه: تعیین تعداد خوشهها (C) و مقداردهی تصادفی به ماتریس درجات عضویت فازی (U).
- محاسبه مراکز فازی: محاسبه مختصات مرکز ثقل هر خوشه فازی بر اساس میانگین وزنی درجات عضویت نقاط داده.
- بهروزرسانی درجات عضویت: محاسبه مجدد ماتریس U برای تکتک نقاط بر اساس میزان فاصله هندسی آنها تا مراکز فازی جدید.
- توقف همگرایی: تکرار مداوم گامهای ۲ و ۳ تا زمانی که تغییرات ماتریس درجات عضویت در دو تکرار متوالی، کمتر از آستانه خطا شود.
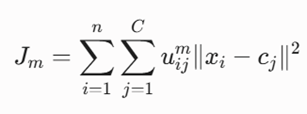
معرفی متغیرها:
- C: تعداد خوشههای فازی هدف.
- uij: درجه یا میزان عضویت نقطه داده xi در خوشه j-ام که مقداری پیوسته در بازه [0, 1] است.
- cj: مرکز فازی و ثقل خوشه j-ام.
- m: پارامتر فازیساز (Fuzzifier)؛ یک عدد بزرگتر از ۱ (معمولاً ۲) که میزان نرمی و نفوذ مرزهای کلاسترها را تنظیم میکند.
.
مزایا و نقاط قوت
- مدلسازی بینقص دادههای مرزی، مبهم و همپوشان در دنیای واقعی.
- همگرایی ریاضی تضمینشده با توابع هدف نرم.
- ارائه اطلاعات غنیتر از ساختار داده به دلیل خروجیهای احتمالی و پیوسته.
.
معایب و محدودیتها
- سرعت همگرایی پایین و بار محاسباتی سنگین به دلیل بهروزرسانی مداوم ماتریس پیوسته .U
- حساسیت شدید به مقداردهی اولیه و ریسک سقوط در بهینههای محلی.
- حساسیت بالا به دادههای پرت و نویزها که میتوانند درجات عضویت را مخدوش کنند.
.
کاربردهای واقعی
- پردازش تصویر و بخشبندی بافتهای تومور در تصاویر پزشکی (مانند MRI).
- سیستمهای توصیهگر هوشمند و سنجش وفاداری چندگانه مشتریان در بازاریابی.
.
3.۸. الگوریتم (Fuzzy C-Means with Dynamic Clusters)FCMdc
یک توسعه هوشمند و غیرصلب (Dynamic) از الگوریتم خوشهبندی فازی FCM است که محدودیت نیاز به تعیین قطعی و پیشفرض تعداد خوشهها (C) را از بین میبرد. این الگوریتم با ارزیابی چگالی هندسی فضا، تعداد کلاسترها را در طول فرآیند یادگیری به طور پویا کم یا زیاد میکند.
نحوه عملکرد و گامهای اجرایی
- مقداردهی پویا: شروع فرآیند خوشهبندی با تعداد اولیهای از خوشهها و مقداردهی به ماتریس عضویت فازی.
- محاسبه مراکز و چگالی موضعی: محاسبه مراکز فازی و ارزیابی شاخص چگالی موضعی (Local Density) هر کلاستر.
- ادغام و حذف (Merge & Delete): اگر فاصله دو مرکز فازی از یک آستانه مشخص کمتر باشد، آن دو خوشه ادغام میشوند. کلاسترهای با چگالی بسیار پایین نیز حذف میگردند.
- تولید کلاستر جدید (Split): در نواحی پرتراکم که خطای فازی بالا است، یک مرکز خوشه جدید تعریف و متولد میشود.
- ارضای شرط همگرایی: تکرار چرخه تا زمان تثبیت نهایی تعداد خوشهها (C) و بهینهشدن ماتریس عضویت.
تابع هدف ریاضی
این الگوریتم تابع هدف FCM را همراه با یک تابع جریمه ریاضی (Ω) برای کنترل و بهینهسازی خودکار تعداد کلاسترها ترکیب میکند:
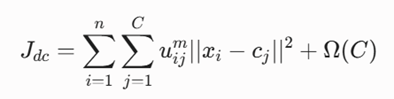
معرفی متغیرها
- C: تعداد خوشهها که مقدار آن در طول اجرای الگوریتم متغیر و پویا است.
- uij: درجه عضویت فازی نقطه i در خوشه j در بازه پیوسته [0, 1].
- m: پارامتر فازیساز (m > 1).
- cj: مختصات مرکز فازی خوشه j-ام.
- Ω (C): تابع جریمه (Penalty Term) جهت جلوگیری از افزایش بیرویه تعداد خوشهها.
.
مزایا و نقاط قوت
- کشف خودکار تعداد بهینه خوشههای فازی بر اساس هندسه واقعی دادهها.
- انعطافپذیری بسیار بالا در مواجهه با دیتابیسهای ناشناخته و فاقد ساختار.
- حذف نیاز به آزمون و خطاهای مکرر برای یافتن پارامتر C.
.
معایب و محدودیتها
- پیچیدگی محاسباتی و فرمولاسیون ریاضی بسیار سنگینتر نسبت به FCM استاندارد.
- حساسیت شدید به تنظیم آستانههای چگالی برای فرآیندهای ادغام و تقسیم خوشهها.
.
کاربردهای واقعی
- سیستمهای مانیتورینگ آنلاین و تشخیص الگو در جریان دادههای در حال تغییر (Data Streams).
- بینایی ماشین و بخشبندی ویدئویی که در آن تعداد اشیاء موجود در تصویر مدام تغییر میکند.
.
3.۹. الگوریتم Fanny
یک الگوریتم خوشهبندی فازی و غیرصلب (Soft Clustering) بسیار مستحکم است که برخلاف روشهای سنتی مانند FCM، بر پایه ماتریس عدمشباهت یا فواصل جفتی دادهها (Dissimilarity Matrix) عمل میکند. این الگوریتم به جای اتکا به مراکز متمرکز فرضی، بر پایداری توپولوژیک و ارتباط کل اعضا در فضا تمرکز دارد.
گامهای اجرایی
- تشکیل ماتریس فواصل: دریافت یا محاسبه مستقیم ماتریس کامل فواصل جفتی (عدمشباهت) بین تکتک نمونههای داده.
- مقداردهی احتمالی: تخصیص درجات عضویت فازی اولیه به نقاط برای ورود به کلاسترها.
- بهینهسازی توزیع فازی: کمینه کردن مجموع فواصل منسجم متقابل نقاط با در نظر گرفتن توان دوم درجات عضویت آنها در هر کلاستر.
- تثبیت مرزها: تکرار محاسبات بهروزرسانی درجات عضویت تا زمان همگرایی کامل و ثبات ابهام در مرزهای فضا.
تابع هدف ریاضی
این الگوریتم مجموع فواصل جفتی وزندهی شده با توان دوم درجات عضویت را کمینه میکند:
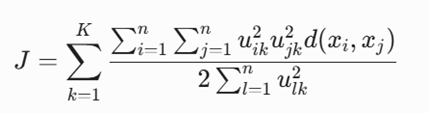
معرفی متغیرها
- K: تعداد خوشههای فازی هدف.
- n: تعداد کل نقاط داده.
- uik: درجه عضویت فازی نقطه i-ام در خوشه k-ام.
.
مزایا و نقاط قوت
- انعطافپذیری هندسی کامل و پایداری فوقالعاده بالا در فضاهای غیراقلیدسی ساختارنیافته.
- عدم نیاز به تعریف و محاسبه مراکز ثقل متمرکز فرضی.
- مقاومت بالا در مواجهه با مجموعهدادههای نامتقارن.
.
معایب و محدودیتها
- مصرف شدید حافظه موقت (RAM) برای ذخیره و پردازش ماتریس کامل فواصل جفتی n ˟ n.
- عدم مقاومت و کارایی محاسباتی در مواجهه با دیتابیسهای مقیاسبزرگ (Big Data).
.
کاربردهای واقعی
- خوشهبندی ساختارهای دادهای پیچیده گرافگونه و تحلیل شبکههای ارتباطی.
- تحلیل عدمشباهتها در متون تخصصی، اسناد و سیستمهای فیلوژنتیک (زیستشناسی تکاملی).
.
4. معایب خوشهبندی افرازی (Partitional Clustering)
با وجود کاربردهای گسترده، خوشهبندی افرازی دارای محدودیتهایی نیز هست:
- نیاز به تعیین تعداد خوشهها از پیش: در بسیاری از الگوریتمها مانند K-Means، مقدار K باید قبل از اجرا مشخص شود.
- حساسیت به مقداردهی اولیه: انتخاب اولیه مراکز میتواند بر کیفیت نهایی خوشهبندی تأثیر جدی بگذارد.
- آسیبپذیری در برابر دادههای پرت و نویز: برخی الگوریتمها مانند K-Means نسبت به مقادیر غیرعادی بسیار حساساند.
- ناتوانی در شناسایی خوشههای با شکل نامنظم: این روشها معمولاً برای خوشههای کروی یا محدب مناسبتر هستند.
- گیر افتادن در بهینههای محلی: الگوریتم ممکن است بهجای جواب بهینه سراسری، در یک پاسخ محلی متوقف شود.
- محدودیت در دادههای بسیار بزرگ یا بسیار پیچیده: برخی نسخهها مانند PAM از نظر محاسباتی پرهزینهاند.
- عدم انعطاف در تعلق چندگانه در نسخههای صلب: در روشهای سخت، هر نمونه فقط به یک خوشه تعلق میگیرد.
.
5. مزایا خوشهبندی افرازی (Partitional Clustering)
در کنار محدودیتها، خوشهبندی افرازی مزایای مهمی دارد که آن را به یکی از محبوبترین روشهای خوشهبندی تبدیل کرده است:
- سادگی مفهومی و محاسباتی
- سرعت اجرای بالا، بهویژه در الگوریتمهایی مانند K-Means
- مقیاسپذیری مناسب برای دادههای بزرگ
- قابلیت تفسیر بالا و فهم آسان نتایج
- کاربردپذیری گسترده در انواع حوزههای علمی و صنعتی
- امکان توسعه به نسخههای مقاوم، فازی و پویا
- مناسب برای تحلیل اکتشافی و پیشپردازش دادهها
- توانایی استخراج ساختارهای پنهان در دادهها
.
6.کاربرد های واقعی خوشهبندی افرازی (Partitional Clustering)
خوشهبندی افرازی در حوزههای متنوع علمی و صنعتی کاربرد دارد و به دلیل سادگی، سرعت و قابلیت تفسیر، بهطور گسترده مورد استفاده قرار میگیرد. از جمله مهمترین کاربردهای آن میتوان به موارد زیر اشاره کرد:
- بخشبندی مشتریان و بازاریابی هدفمند: گروهبندی کاربران بر اساس رفتار خرید، سطح وفاداری، توان مالی و ترجیحات مصرفی.
- پزشکی و بیوانفورماتیک: شناسایی زیرگروههای بیماران، تحلیل تصاویر پزشکی، و بررسی الگوهای ژنتیکی.
- سیستمهای توصیهگر: گروهبندی کاربران یا محصولات برای ارائه پیشنهادهای دقیقتر و شخصیسازیشده.
- پردازش تصویر: تفکیک نواحی مختلف تصویر بر اساس رنگ، بافت یا شدت روشنایی.
- کشف ناهنجاری: شناسایی نمونههای غیرعادی در تراکنشهای مالی، دادههای شبکه یا سامانههای صنعتی.
- تحلیل دادههای اسمی و کیفی: خوشهبندی اسناد، پرسشنامهها و دادههای دستهای.
- شهر هوشمند و حملونقل: تحلیل الگوهای ترافیکی، مصرف انرژی و رفتار مکانی-زمانی.
.
7. نوآوریهای جدید در خوشهبندی افرازی
خوشهبندی افرازی در سالهای اخیر از الگوریتمهای کلاسیکی مانند K-Means، K-Medoids و Fuzzy C-Means فراتر رفته و به سمت روشهایی حرکت کرده است که بتوانند با دادههای بزرگ، پیچیده، چندوجهی، نویزی، پویا و با ابعاد بالا بهتر کار کنند. نوآوریهای جدید این حوزه عمدتاً با هدف افزایش دقت، پایداری، مقیاسپذیری، تفسیرپذیری، مقاومت در برابر نویز و سازگاری با دادههای مدرن توسعه یافتهاند.
در ادامه، مهمترین جهتگیریها و نوآوریهای جدید در این حوزه معرفی میشوند.
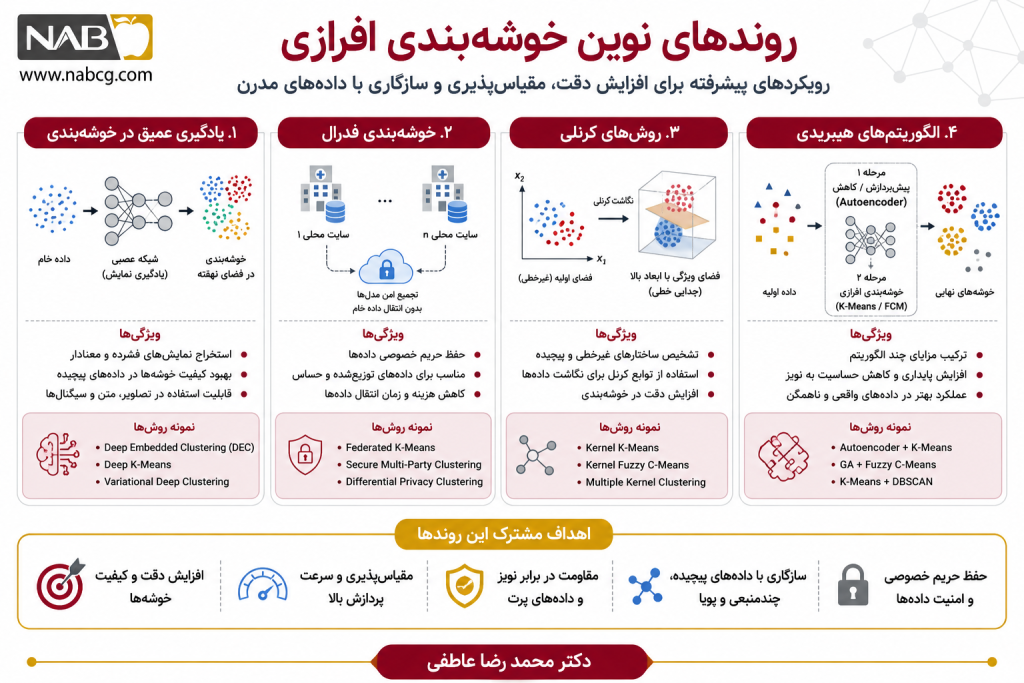
7.1 خوشهبندی افرازی مبتنی بر یادگیری عمیق
یکی از مهمترین تحولات جدید، ترکیب خوشهبندی افرازی با شبکههای عصبی عمیق است. در این رویکرد، دادهها ابتدا به یک فضای نمایش نهفته (Latent Space) نگاشت میشوند و سپس عملیات خوشهبندی در آن فضای فشرده و معنادار انجام میگیرد.
در روشهای کلاسیک، الگوریتمهایی مانند K-Means مستقیماً روی داده خام اجرا میشوند؛ اما در دادههایی مانند تصویر، متن، صوت یا سیگنالهای پیچیده، فضای خام معمولاً برای خوشهبندی مناسب نیست. به همین دلیل، مدلهای عمیق مانند Autoencoder، Variational Autoencoder یا شبکههای کانولوشنی، نمایش بهتری از دادهها یاد میگیرند.
نمونه روشها
- Deep Embedded Clustering (DEC)
- Improved Deep Embedded Clustering (IDEC)
- Deep K-Means
- Variational Deep Clustering
- Contrastive Deep Clustering
مزیت اصلی
این رویکرد باعث میشود خوشهها در فضایی شکل بگیرند که ساختار معنایی داده بهتر حفظ شده است.
مثال کاربردی
در خوشهبندی تصاویر پزشکی، بهجای خوشهبندی مستقیم پیکسلها، ابتدا ویژگیهای عمیق تصویر استخراج میشوند و سپس بیماران یا نواحی تصویر بر اساس ویژگیهای نهفته خوشهبندی میگردند.
.
7.2.خوشهبندی افرازی مبتنی بر یادگیری خودنظارتی
یادگیری خودنظارتی (Self-Supervised Learning) یکی از نوآوریهای بسیار مهم در یادگیری ماشین جدید است. در این رویکرد، مدل بدون نیاز به برچسب انسانی، از خود دادهها سیگنال آموزشی تولید میکند.
در خوشهبندی افرازی مدرن، روشهای خودنظارتی برای تولید نمایشهایی استفاده میشوند که برای خوشهبندی مناسبتر هستند. سپس روی این نمایشها الگوریتمهای افرازی مانند K-Means یا نسخههای فازی آن اجرا میشوند.
تکنیکهای رایج
- یادگیری متضاد (Contrastive Learning)
- پیشبینی بخشهای حذفشده داده
- تولید نماهای مختلف از یک نمونه
- خوشهبندی همزمان با یادگیری نمایش
مزیت اصلی
این روشها وابستگی به برچسبهای انسانی را کاهش داده و کیفیت خوشهبندی را در دادههای پیچیده افزایش میدهند.
مثال کاربردی
در تحلیل اسناد، مدل میتواند بدون برچسب، نمایش معنایی جملات و متون را یاد بگیرد و سپس اسناد مشابه را در خوشههای معنایی قرار دهد.
.
7.3. خوشهبندی افرازی مقیاسپذیر برای کلانداده
با افزایش حجم دادهها، الگوریتمهای کلاسیک افرازی بهینه نیستند. برای نمونه، PAM در K-Medoids در دادههای بزرگ هزینه محاسباتی بالایی دارد. نوآوریهای جدید در این زمینه بر توسعه الگوریتمهای سریعتر و مقیاسپذیرتر تمرکز دارند.
رویکردهای نوین
- Mini-Batch K-Means
- Distributed K-Means
- Parallel K-Medoids
- خوشهبندی مبتنی بر Spark و Hadoop
- استفاده از GPU برای محاسبات فاصله
- الگوریتمهای تقریبی و نمونهبرداری هوشمند
مزیت اصلی
این روشها امکان خوشهبندی میلیونها یا حتی میلیاردها نمونه را فراهم میکنند.
مثال کاربردی
در سامانههای فروش آنلاین، رفتار میلیونها کاربر میتواند بهصورت پیوسته خوشهبندی شود تا الگوهای خرید، ریزش مشتری و علاقهمندیهای پنهان شناسایی شوند.
.
7.4. خوشهبندی افرازی برخط و جریانی
در بسیاری از کاربردهای جدید، دادهها بهصورت ایستا در اختیار ما نیستند؛ بلکه به شکل جریان پیوسته وارد سامانه میشوند. دادههای حسگرهای صنعتی، تراکنشهای مالی، ترافیک شبکه، لاگهای سامانه و دادههای اینترنت اشیا نمونههایی از دادههای جریانی هستند.
در این شرایط، الگوریتم باید بتواند بدون بازآموزی کامل، خوشهها را بهروزرسانی کند.
ویژگیهای روشهای جدید
- بهروزرسانی تدریجی مراکز خوشه
- تشخیص تغییر مفهوم (Concept Drift)
- حذف یا ادغام خوشههای قدیمی
- ایجاد خوشههای جدید در زمان ورود الگوهای تازه
- مصرف حافظه محدود
نمونه روشها
- Online K-Means
- Streaming K-Means
- Incremental Fuzzy C-Means
- Evolving Clustering Methods
مثال کاربردی
در تشخیص نفوذ شبکه، الگوهای حمله ممکن است بهمرور زمان تغییر کنند. خوشهبندی جریانی میتواند الگوهای جدید را شناسایی و خوشههای قبلی را بهروزرسانی کند.
.
7.5.خوشهبندی افرازی مقاوم در برابر نویز و دادههای پرت
یکی از ضعفهای اصلی الگوریتمهای کلاسیک، حساسیت آنها نسبت به دادههای پرت است. در سالهای اخیر، روشهای مقاومتری توسعه یافتهاند که میتوانند اثر نمونههای غیرعادی را کاهش دهند.
نوآوریهای مهم
- استفاده از توابع زیان مقاوم
- جایگزینی میانگین با مدوید یا میانگینهای وزنی
- خوشهبندی مبتنی بر trimmed loss
- شناسایی همزمان خوشهها و نقاط پرت
- ترکیب K-Means با روشهای تشخیص ناهنجاری
مزیت اصلی
این روشها کیفیت خوشهبندی را در دادههای واقعی و آلوده به نویز افزایش میدهند.
مثال کاربردی
در دادههای مالی، تراکنشهای غیرعادی ممکن است مراکز خوشه را منحرف کنند. روشهای مقاوم میتوانند این اثر را کاهش داده و الگوی واقعی مشتریان را بهتر استخراج کنند.
.
7.6.خوشهبندی افرازی فازی و احتمالاتی پیشرفته
خوشهبندی فازی از گذشته یکی از شاخههای مهم خوشهبندی افرازی بوده است، اما نسخههای جدید آن انعطاف بیشتری در مدلسازی عدمقطعیت دارند.
در روشهای فازی، هر نمونه بهجای تعلق کامل به یک خوشه، با درجات مختلف به چند خوشه تعلق دارد. این ویژگی برای دادههایی که مرزهای خوشهای مبهم دارند بسیار مفید است.
نوآوریهای جدید
- Fuzzy C-Means مقاوم به نویز
- Possibilistic C-Means
- Gustafson-Kessel Fuzzy Clustering
- Kernel Fuzzy C-Means
- Intuitionistic Fuzzy Clustering
- Type-2 Fuzzy Clustering
مزیت اصلی
این روشها برای دادههایی مناسباند که در آنها مرز بین گروهها کاملاً قطعی نیست.
مثال کاربردی
در پزشکی، یک بیمار ممکن است ویژگیهایی از چند زیرگروه بیماری را همزمان داشته باشد. خوشهبندی فازی میتواند این وضعیت را بهتر از خوشهبندی سخت مدلسازی کند.
.
7.7. خوشهبندی افرازی مبتنی بر کرنل
روشهای کلاسیک مانند K-Means معمولاً خوشههایی با ساختار نسبتاً ساده و محدب را بهتر شناسایی میکنند. اما در دادههای واقعی، خوشهها ممکن است شکلهای پیچیده و غیرخطی داشته باشند.
خوشهبندی مبتنی بر کرنل با نگاشت دادهها به فضای ویژگی با ابعاد بالاتر، امکان شناسایی ساختارهای غیرخطی را فراهم میکند.
نمونه روشها
- Kernel K-Means
- Kernel Fuzzy C-Means
- Multiple Kernel Clustering
مزیت اصلی
توانایی تشخیص خوشههای غیرخطی و پیچیده.
مثال کاربردی
در تحلیل دادههای زیستی، گروههای ژنتیکی ممکن است در فضای خام بهصورت خطی قابل جداسازی نباشند. روشهای کرنلی میتوانند ساختار پنهان آنها را بهتر آشکار کنند.
.
7.8. خوشهبندی افرازی چندنمایی و چندوجهی
دادههای جدید معمولاً فقط از یک منبع یا یک نوع ویژگی تشکیل نشدهاند. برای مثال، درباره یک بیمار ممکن است دادههای ژنتیکی، تصویربرداری پزشکی، سوابق بالینی و دادههای آزمایشگاهی همزمان موجود باشد.
خوشهبندی چندنمایی (Multi-View Clustering) تلاش میکند از تمام این نماها بهصورت همزمان استفاده کند.
ویژگیها
- ترکیب چند نوع داده
- وزندهی به نماهای مختلف
- یادگیری نمایش مشترک
- افزایش پایداری خوشهبندی
- کاهش اثر نویز در یک نمای خاص
مثال کاربردی
در پزشکی شخصیسازیشده، میتوان بیماران را با استفاده همزمان از دادههای ژنومی، بالینی و تصویری خوشهبندی کرد تا زیرگروههای دقیقتری از بیماری شناسایی شوند.
.
7.9. خوشهبندی افرازی با تعیین خودکار تعداد خوشهها
یکی از مشکلات اصلی خوشهبندی افرازی، نیاز به تعیین تعداد خوشهها از پیش است. نوآوریهای جدید تلاش کردهاند این وابستگی را کاهش دهند.
رویکردها
- استفاده از معیارهای اعتبارسنجی مانند Silhouette، Davies-Bouldin و Calinski-Harabasz
- الگوریتمهای مبتنی بر ادغام و تقسیم خوشهها
- روشهای Bayesian Nonparametric
- Dirichlet Process Clustering
- نسخههای پویا از FCM
- خوشهبندی تکاملی و فراابتکاری
مزیت اصلی
این روشها باعث میشوند تعداد خوشهها بهصورت دادهمحور و نه صرفاً بر اساس حدس اولیه تعیین شود.
مثال کاربردی
در تحلیل کاربران یک پلتفرم آموزشی، ممکن است تعداد واقعی گروههای رفتاری از قبل مشخص نباشد. روشهای خودتنظیم میتوانند این تعداد را بر اساس الگوهای داده تعیین کنند.
.
7.10. خوشهبندی افرازی مبتنی بر الگوریتمهای فراابتکاری
از آنجا که خوشهبندی افرازی معمولاً با مسئله بهینهسازی غیرمحدب روبهروست، احتمال گیر افتادن در بهینههای محلی زیاد است. به همین دلیل، الگوریتمهای فراابتکاری برای بهبود جستجوی فضای پاسخ مورد استفاده قرار گرفتهاند.
الگوریتمهای رایج
- الگوریتم ژنتیک (GA)
- بهینهسازی ازدحام ذرات (PSO)
- الگوریتم کلونی مورچگان (ACO)
- الگوریتم خفاش
- الگوریتم گرگ خاکستری
- الگوریتم وال
- الگوریتمهای ترکیبی Memetic
مزیت اصلی
افزایش احتمال یافتن پاسخ بهتر و کاهش وابستگی به مقداردهی اولیه.
مثال کاربردی
در خوشهبندی دادههای صنعتی با ابعاد بالا، الگوریتمهای فراابتکاری میتوانند مراکز اولیه مناسبتری برای K-Means انتخاب کنند.
.
7.11. خوشهبندی افرازی تفسیرپذیر و قابل اعتماد
در کاربردهای حساس مانند پزشکی، مالی و حقوقی، فقط دقت خوشهبندی کافی نیست؛ بلکه باید بتوان توضیح داد که چرا یک نمونه در یک خوشه قرار گرفته است.
به همین دلیل، پژوهشهای جدید به سمت خوشهبندی تفسیرپذیر (Interpretable Clustering) حرکت کردهاند.
جهتگیریهای جدید
- استخراج قوانین توصیفی برای هر خوشه
- استفاده از ویژگیهای مهم برای تفسیر خوشهها
- ترکیب خوشهبندی با درخت تصمیم
- تولید پروفایل معنایی برای خوشهها
- ارزیابی پایداری و اعتمادپذیری خوشهها
مثال کاربردی
در بخشبندی بیماران، پزشک باید بداند هر خوشه بر اساس چه ویژگیهایی شکل گرفته است؛ برای مثال سن، سطح قند خون، فشار خون یا نشانگرهای ژنتیکی.
.
7.12. خوشهبندی افرازی حفظ حریم خصوصی
با افزایش حساسیت نسبت به دادههای شخصی، روشهای خوشهبندی باید بتوانند بدون افشای اطلاعات کاربران عمل کنند.
نوآوریهای مهم
- خوشهبندی فدرال (Federated Clustering)
- خوشهبندی با حفظ حریم خصوصی تفاضلی (Differential Privacy)
- K-Means فدرال
- Secure Multi-Party Clustering
- رمزنگاری همریخت برای محاسبات فاصله
مزیت اصلی
امکان خوشهبندی دادههای توزیعشده و حساس بدون انتقال مستقیم داده خام.
مثال کاربردی
چند بیمارستان میتوانند بدون اشتراکگذاری مستقیم داده بیماران، مدل خوشهبندی مشترکی برای شناسایی زیرگروههای بیماری ایجاد کنند.
.
7.13. خوشهبندی افرازی برای دادههای با ابعاد بالا
در دادههایی مانند متن، ژنوم، تصاویر و دادههای حسگری، تعداد ویژگیها بسیار زیاد است. این وضعیت باعث مشکل معروف نفرین ابعاد میشود و فاصلههای کلاسیک کارایی خود را از دست میدهند.
نوآوریها
- Subspace Clustering
- Projected K-Means
- Sparse K-Means
- Feature-Weighted Clustering
- خوشهبندی همراه با انتخاب ویژگی
- کاهش بعد با Autoencoder یا UMAP و سپس خوشهبندی
مثال کاربردی
در متنکاوی، هر سند ممکن است هزاران ویژگی واژگانی داشته باشد. روشهای Sparse K-Means میتوانند فقط ویژگیهای مهم را برای تشکیل خوشهها استفاده کنند.
.
7.14. خوشهبندی افرازی ترکیبی یا هیبریدی
یکی دیگر از روندهای مهم، ترکیب خوشهبندی افرازی با سایر روشهای خوشهبندی یا یادگیری ماشین است.
نمونه ترکیبها
- K-Means + DBSCAN
- K-Means + Spectral Clustering
- Autoencoder + K-Means
- Fuzzy C-Means + الگوریتم ژنتیک
- K-Medoids + تشخیص ناهنجاری
- Clustering + Classification
مزیت اصلی
هر روش ضعفهای خاص خود را دارد و ترکیب روشها میتواند عملکرد نهایی را بهبود دهد.
مثال کاربردی
در سامانههای توصیهگر، ابتدا کاربران با K-Means بخشبندی میشوند، سپس برای هر خوشه یک مدل توصیهگر اختصاصی آموزش داده میشود.
.
جمعبندی
نوآوریهای جدید در خوشهبندی افرازی عمدتاً بر حل محدودیتهای روشهای کلاسیک متمرکز هستند. این نوآوریها تلاش میکنند الگوریتمها را برای دادههای واقعی، بزرگ، پیچیده، چندمنبعی، نویزی و پویا مناسبتر کنند.
بهطور خلاصه، مهمترین مسیرهای نوآوری عبارتاند از:
| محور نوآوری | هدف اصلی |
| خوشهبندی عمیق | یادگیری نمایش بهتر برای دادههای پیچیده |
| خوشهبندی خودنظارتی | کاهش نیاز به برچسب و افزایش کیفیت نمایش |
| خوشهبندی مقیاسپذیر | پردازش کلانداده |
| خوشهبندی جریانی | بهروزرسانی خوشهها در دادههای پویا |
| روشهای مقاوم | کاهش اثر نویز و دادههای پرت |
| روشهای فازی پیشرفته | مدلسازی عدمقطعیت و مرزهای مبهم |
| خوشهبندی کرنلی | شناسایی ساختارهای غیرخطی |
| خوشهبندی چندنمایی | ترکیب دادههای چندمنبعی |
| تعیین خودکار تعداد خوشهها | کاهش وابستگی به مقدار اولیه K |
| فراابتکاریها | بهبود بهینهسازی و فرار از بهینه محلی |
| خوشهبندی تفسیرپذیر | افزایش اعتماد و قابلیت توضیح |
| خوشهبندی فدرال | حفظ حریم خصوصی دادهها |
در نتیجه، خوشهبندی افرازی امروز دیگر صرفاً به K-Means کلاسیک محدود نیست؛ بلکه به یک حوزه پویا و چندرشتهای تبدیل شده است که با یادگیری عمیق، یادگیری خودنظارتی، رایانش توزیعشده، حریم خصوصی، فازیسازی، گرافها و هوش مصنوعی قابل اعتماد پیوند خورده است.



