

1 .چکیده
خوشهبندی به عنوان یکی از ارکان کلیدی یادگیری بدون نظارت، نقشی حیاتی در کشف ساختارهای پنهان درون دادهها ایفا میکند. با این حال، الگوریتمهای سنتی مانند K-Means در مواجهه با خوشههایی با اشکال هندسی پیچیده و دادههای نویزی، کارایی خود را از دست میدهند. مقاله حاضر به بررسی جامع الگوریتم خوشهبندی مبتنی بر چگالی برای دادههای دارای نویز فضایی، معروف به DBSCAN، میپردازد که این چالشها را به طور ریشهای برطرف کرده است. در این نوشتار، مبانی نظری، ساختار ریاضی و سازوکار تفکیک نقاط هستهای، مرزی و نویز بر اساس دو پارامتر کلیدی شعاع همسایگی (ε) و حداقل تعداد نقاط (MinPts) تشریح میشود.
هدف این مقاله، ارائه یک راهنمای ساختاریافته از نظریه تا پیادهسازی عملی این الگوریتم در پایتون است. نتایج بررسیها نشان میدهد که DBSCAN به دلیل عدم نیاز به تعیین پیشفرض تعداد خوشهها و توانایی استثنایی در شناسایی دادههای پرت، ابزاری قدرتمند برای تحلیل دادههای پیچیده در صنایع مختلف است.
2 .مقدمه
در عصر انفجار دادهها، استخراج الگوهای معنادار بدون داشتن برچسبهای پیشفرض، به یکی از مهمترین چالشهای دانشمندان داده و تحلیلگران کسبوکار تبدیل شده است. خوشهبندی (Clustering) به عنوان یک رویکرد بنیادین در یادگیری بدون نظارت، وظیفه گروهبندی دادههای مشابه را بر عهده دارد .(Hand et al., 2001) این ابزار تحلیلی در بخش بینش سازمانها، کاربردهای گستردهای از بخشبندی مشتریان تا شناسایی رفتارهای نابهنجار دارد.
با این حال، رویکردهای سنتی و مرکزگرا مانند الگوریتم K-Means، با دو محدودیت جدی روبرو هستند: نخست اینکه کاربر را ملزم به تعیین دقیق تعداد خوشهها (K) از پیش میکنند، و دوم اینکه فرض را بر کروی بودن شکل خوشهها میگذارند .(Han et al., 2011) این فرضیات در مواجهه با دادههای پیچیده جهان واقعی، که اغلب دارای اشکال هندسی نامنظم، تراکمهای متغیر و حجم بالایی از نویز و دادههای پرت هستند، به نتایجی گمراهکننده منجر میشوند. برای غلبه بر این نقایص، رویکردهای مبتنی بر چگالی توسعه یافتند.
هدف این مقاله، تبیین دقیق الگوریتم DBSCAN به عنوان یکی از جریانسازترین الگوهای خوشهبندی در تاریخ علم داده است که معیار پدید آمدن خوشهها را نه فاصله از مرکز، بلکه میزان تراکم نقاط در فضای ویژگی قرار میدهد .(Ester et al., 1996)
نقشه راه این مقاله به این صورت تنظیم شده است که ابتدا مفاهیم پایه و ضرورت وجودی این روش را بررسی میکنیم. سپس وارد لایههای عمیقتر مبانی ریاضی و سازوکار گامبهگام الگوریتم میشویم. در ادامه، مباحث را با مثالهای عددی، کاربردهای صنعتی و پیادهسازی عملی در پایتون ملموستر کرده و در نهایت، با مقایسه DBSCAN با روشهای مشابه و بررسی چشمانداز آینده آن، دیدگاهی جامع به خواننده ارائه میدهیم.

3 .تعریف و مفهوم پایه
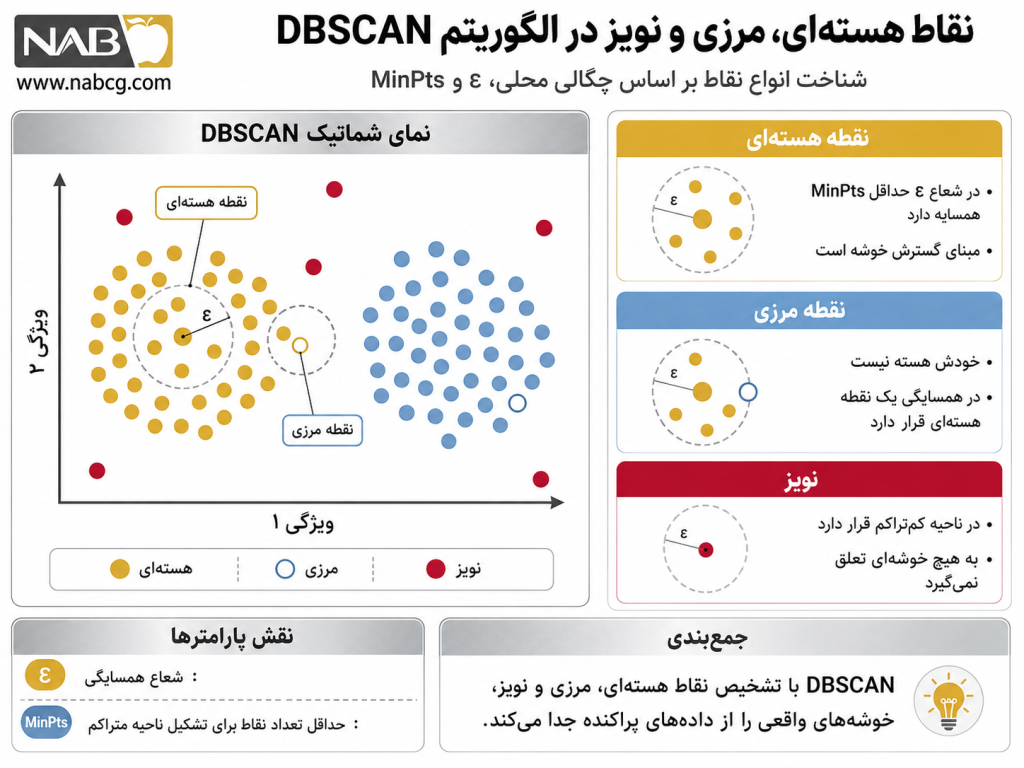
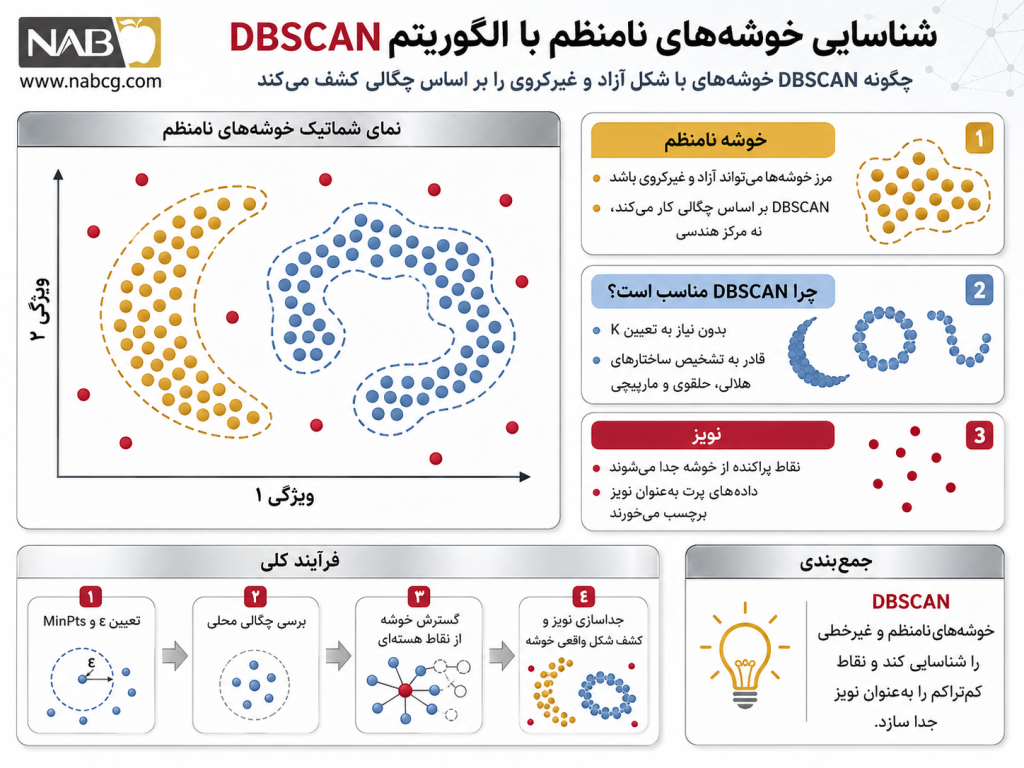
الگوریتم DBSCAN که مخفف عبارت Density-Based Spatial Clustering of Applications with Noise است، یک الگوریتم یادگیری ماشین بدون نظارت چگالیمحور محسوب میشود .(Ester et al., 1996) در این روش، خوشهها به عنوان نواحی متراکمی از نقاط در فضای ویژگی تعریف میشوند که توسط نواحی کمتراکم (تهی یا نویز) از یکدیگر تفکیک شدهاند. برخلاف روشهای هندسی و مرکزگرا، ملاک عضویت یک نقطه در خوشه، قرارگیری آن در یک همسایگی پرجمعیت است. این الگوریتم بر پایه دو ابرپارامتر کلیدی عمل میکند: شعاع همسایگی (ε- Eps) که حداکثر فاصله برای جستجوی نقاط مجاور را تعیین میکند، و حداقل تعداد نقاط (MinPts) که حد آستانه برای تشکیل یک ناحیه متراکم را مشخص میسازد. (Tan et al., 2018)
برای درک بهتر، یک میهمانی شلوغ را در نظر بگیرید. در این فضا، گروههایی از افراد که بسیار نزدیک به هم ایستاده و در حال گفتگو هستند، خوشههای متراکم را تشکیل میدهند. افرادی که به صورت پراکنده و با فاصله زیاد از دیگران در گوشههای سالن قدم میزنند، به عنوان دادههای پرت یا نویز شناخته میشوند. الگوریتم DBSCAN دقیقاً با همین منطق، تجمعات انسانی (دادهای) را بدون نیاز به دانستن تعداد کل گروهها شناسایی میکند.
4. اهمیت و ضرورت الگوریتم DBSCAN
الگوریتمهای خوشهبندی سنتی با این فرض سادهانگارانه طراحی شدهاند که دادههای جهان واقعی همواره از الگوهای توزیع منظم و کروی پیروی میکنند (Aggarwal, 2014). اما در سناریوهای پیچیده تجاری و علمی، دادهها فاقد تقارن هندسی هستند. مسئله اصلی که DBSCAN برای حل آن پدید آمد، ناتوانی سیستماتیک مدلهای مرکزگرا در تفکیک ساختارهای درهمتنیده و غیرخطی و همچنین آسیبپذیری شدید آنها در برابر دادههای پرت بود.
به عنوان مثال، در تحلیل دادههای جغرافیایی یا مسیرهای حرکت خطوط ساحلی، خوشهها ممکن است به شکل هلال ماه، حلقوی یا مارهای متقاطع ظاهر شوند. الگوریتمی مثل K-Means در مواجهه با چنین ساختارهایی، به دلیل تلاش برای بهینهسازی فواصل مربعات از یک مرکز فرضی، خوشههای واقعی را تکهتکه کرده و خروجیهای کاملاً گمراهکننده تولید میکند.
ضرورت وجودی DBSCAN در این است که فرض «مرکزگرایی» را کاملاً حذف میکند. این روش با تمرکز بر مفهوم چگالی موضعی، به دو نیاز حیاتی پاسخ میدهد: اول، کشف ساختارهای پنهان با اشکال کاملاً هندسی نامنظم بدون نیاز به دانش قبلی از تعداد خوشهها؛ دوم، پاکسازی خطوط تحلیل از طریق تعریف رسمی «نویز». در دادههای بزرگ، دادههای پرت جریان محاسبات را منحرف میکنند. DBSCAN با حل این چالش، به جای مجبور کردن نقاط نویز به عضویت در یک خوشه نامرتبط، مرزهای پاک و واقعی دادهها را استخراج میکند و این دقیقاً همان نقطهای است که تحلیلهای استراتژیک به آن وابسته هستند .(Han et al., 2011)
5. مبانی نظری و ریاضی
بنیان نظری الگوریتم DBSCAN بر پایه هندسه فضایی و مفهوم چگالی موضعی (Local Density) استوار است. در این دیدگاه، فرض پایه این است که یک خوشه در فضای چندبعدی، ناحیهای پیوسته و متراکم از دادههاست؛ یعنی جایی که تمرکز نقاط از یک حد آستانه مشخص بالاتر است .(Ester et al., 1996) برای تبیین این فضا و صورتبندی ریاضی آن، الگوریتم از یک معیار سنجش فاصله (عموماً فاصله اقلیدسی) و دو ابرپارامتر کلیدی بهره میبرد که ساختار توپولوژیک خوشهها را تعریف میکنند.
۵.۱. تعاریف و معیارهای فضایی پایه
فرض کنید مجموعه داده ما D در یک فضای متریک تعریف شده است. برای تعریف تراکم ریاضی در اطراف یک نقطه، ابتدا باید مفهوم همسایگی را فرمولبندی کنیم:
تعریف ۱: همسایگی اپسیلون (ε-Neighborhood)
همسایگی ε برای یک نقطه مانند p (که با نماد Nε (p) نشان داده میشود)، مجموعهای از تمام نقاط در دیتابیس D است که فاصله آنها تا نقطه p کمتر یا مساوی با شعاع ε باشد:
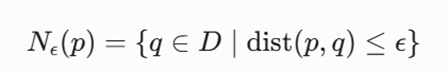
در این رابطه:
- Nε(p): نشاندهنده زیرمجموعهای از دادههاست که در حریم همسایگی نقطه p قرار گرفتهاند.
- ε (Epsilon): ابرپارامتر شعاع همسایگی است که مرز هندسی جستجو را مشخص میکند.
- dist(p, q): تابع فاصله بین دو نقطه p و q است. در فضاهای استاندارد، این تابع همان فاصله اقلیدسی (L2 norm) است که به صورت زیر محاسبه میشود:
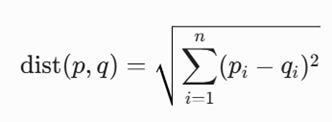
تعریف ۲: نقطه هستهای (Core Point)
یک نقطه p زمانی به عنوان یک هسته یا مرکز تراکم موضعی شناخته میشود که تعداد اعضای همسایگی ε آن، از یک حد آستانه مشخص (MinPts) کمتر نباشد:
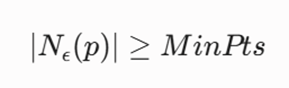
در این رابطه:
- |Nε(p)|: کاردینالیتی یا تعداد نقاط موجود در همسایگی p است (خود نقطه p نیز شمارش میشود).
- Min Pts: ابرپارامتر حداقل تعداد نقاط برای تشکیل یک کلونی متراکم است.
.
۵.۲. تئوری دسترسیپذیری و پیوستگی چگالی
برای اینکه بتوان خوشههایی با اشکال هندسی نامنظم (غیرکروی) تشکیل داد، ریاضیات DBSCAN مجهز به سه مفهوم زنجیرهای به نامهای «دسترسیپذیری مستقیم»، «دسترسیپذیری جفتبهجفت» و «اتصال چگالی» است: (Tan et al., 2018)
دسترسیپذیری مستقیم چگالی (Directly Density-Reachable)
نقطه X از نقطه Y به صورت مستقیم بر اساس چگالی دسترسیپذیر است، اگر دو شرط زیر همزمان برقرار باشند:
۱. نقطه X در حریم همسایگی نقطه Y قرار داشته باشد (X ∈ Nε (Y)).
۲. نقطه Y یک نقطه هستهای باشد (|Nε (Y)| ≥ MinPts).
نکته تحلیلی مهم: این رابطه لزوماً متقارن نیست. اگر Y یک نقطه هستهای و X یک نقطه مرزی باشد، X از طریق Y به صورت مستقیم دسترسیپذیر است، اما Y از طریق X دسترسیپذیر نیست؛ چون X شرط هسته بودن را برآورده نمیکند.
دسترسیپذیری چگالی (Density-Reachable)
یک نقطه X از یک نقطه Y بر اساس چگالی دسترسیپذیر است، اگر یک زنجیره خطی از نقاط مانند p1, p2, …, pn وجود داشته باشد به طوری که p1 = Y و pn = X باشد و در آن، هر نقطه pi+1 به صورت مستقیم بر اساس چگالی از نقطه pi دسترسیپذیر باشد. این مفهوم، پایه و اساس گسترش خوشهها به صورت زنجیرهای و کشف اشکال مارپیچ یا هلالشکل است.
اتصال چگالی (Density-Connected)
دو نقطه X و Y به یکدیگر متصل بر اساس چگالی خوانده میشوند، اگر نقطهای واسط مانند Oدر مجموعه داده وجود داشته باشد به طوری که هر دو نقطه X و Y از نقطه O بر اساس چگالی دسترسیپذیر باشند:
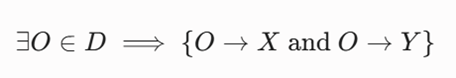
این رابطه برخلاف دو رابطه قبلی کاملاً متقارن است و به عنوان شرط لازم و کافی برای قرارگیری دو نقطه مرزی یا هستهای در داخل یک خوشه واحد شناخته میشود.
۵.۳. تئوری انتخاب ابرپارامترها (Parameter Selection)
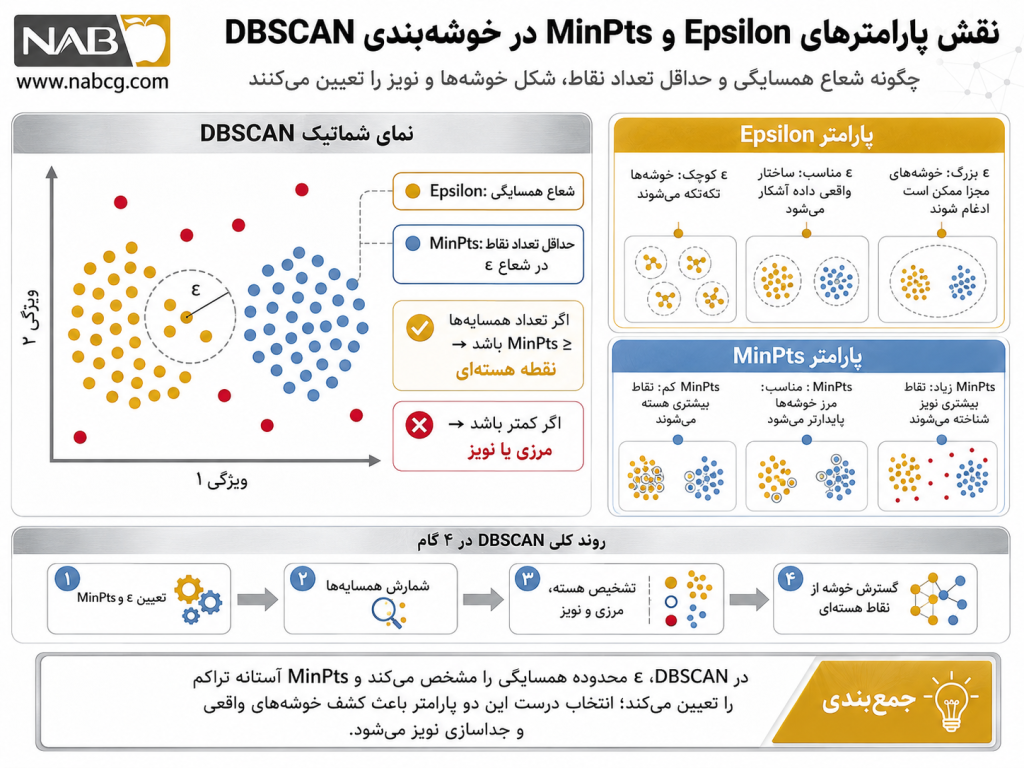
رفتار و هندسه ریاضی DBSCAN به شدت به مقادیر ε و MinPts حساس است .(Han et al., 2011) انتخاب نادرست این مقادیر، توازن فضای چگالی را به هم میزند:
- مبنای ریاضی تعیین MinPts: طبق قواعد آماری، این مقدار باید حداقل بزرگتر از تعداد ابعاد مسئله (d) باشد (MinPts ≥ d + 1). مقدار ۱ منطقی نیست (چون هر نقطه یک خوشه میشود). معمولاً برای کاهش اثر نویز در دادههای بزرگ، این مقدار را برابر با 2 × d در نظر میگیرند.
- مبنای ریاضی تعیین ε (نمودار K-Distance): برای یافتن شعاع بهینه، از رفتار هندسی تغییرات فاصله استفاده میشود. با محاسبه فاصله هر نقطه تا -kامین همسایه نزدیکش و مرتبسازی صعودی این فواصل، یک منحنی به دست میآید. نقطه عطف یا آرنج (Elbow Point) این نمودار، جایی است که شیب منحنی به طور ناگهانی تغییر میکند؛ این نقطه دقیقاً مرز ریاضی تفکیک نواحی متراکم از نواحی کمتراکم (نویز) است و به عنوان مقدار بهینه ε انتخاب میشود.
.
6. سازوکار عملکرد الگوریتم DBSCAN
الگوریتم DBSCAN برای خوشهبندی دادهها، یک فرآیند اکتشافی و پیوسته را بر پایه ساختار همسایگی طی میکند. برخلاف الگوریتمهایی مانند K-Means که مأموریت خود را با بهینهسازی یک تابع هدف جهانی (مانند کمینهسازی مجموع مربعات خطا) پیش میبرند، DBSCAN فاقد تابع هدف ریاضی به آن معناست. در عوض، منطق تصمیمگیری این الگوریتم بر اساس یکپارچهسازی موضعی زنجیرههای متصل بر اساس چگالی استوار است .(Ester et al., 1996)
۶.۱. مراحل گامبهگام فرآیند اجرا و جریان دادهها
دادهها از زمان ورود به الگوریتم تا تخصیص به خوشههای نهایی، این فازهای پویا را طی میکنند:
۱. برچسبگذاری اولیه: در ابتدا، تمام نقاط داده در ماتریس ویژگی به عنوان «بررسینشده» (Unvisited) علامتگذاری میشوند.
۲. انتخاب نقطه تصادفی: الگوریتم یک نقطه مانند دیده pدیده را که هنوز پردازش نشده است، به صورت تصادفی انتخاب کرده و آن را به عنوان «بررسیشده» (Visited) علامت میزند.
۳. ارزیابی چگالی همسایگی: همسایگی اپسیلون این نقطه (دیده Nε(p)دیده ) محاسبه میشود:
- سناریوی الف (نویز موقت): اگر تعداد نقاط همسایگی کمتر از دیده MinPtsدیده باشد، نقطه دیده pدیده موقتاً «نویز» برچسب میخورد. این نقطه ممکن است بعداً با قرارگیری در مجاورت یک هسته، به نقطه مرزی تبدیل شود.
- سناریوی ب (تشکیل خوشه): اگر تعداد نقاط بزرگتر یا مساوی دیده MinPtsدیده باشد، نقطه دیده pدیده «نقطه هستهای» شناخته شده و یک خوشه جدید ایجاد میشود.
۴. گسترش زنجیرهای خوشه (Cluster Expansion): تمام نقاط موجود در همسایگی دیده Nε(p)دیده به صف موقت Neighbor_Candidates اضافه میشوند. برای تکتک نقاط این صف:
- اگر نقطه قبلاً «بررسینشده» بوده باشد، برچسب آن به «بررسیشده» تغییر کرده و همسایگیاش استخراج میشود.
- اگر این نقطه فرعی خود یک نقطه هستهای باشد، تمام نقاط همسایگی آن نیز به صف تزریق میشوند تا خوشه به صورت زنجیرهای رشد کند.
- اگر نقطه در گذشته برچسب نویز خورده بود، برچسب آن به «نقطه مرزی» تغییر یافته و به خوشه فعلی ملحق میشود.
۵. معیار توقف: فرآیند اکتشافِ صف زمانی متوقف میشود که هیچ نقطه متصل بر اساس چگالی در صف باقی نماند. در این حالت، خوشه فعلی بسته میشود. سپس الگوریتم به سراغ نقطه بررسینشده بعدی در کل بانک داده میرود و مراحل را تکرار میکند. فرآیند نهایی زمانی پایان مییابد که تمامی نقاط سیستم حداقل یکبار پایش شده باشند .(Tan et al., 2018)
7.مثالهای عددی
مثال ۱: سطح مقدماتی (تشخیص ساختار یک دیتای خطی تکبعدی)
صورت مسئله: مجموعه دادهای شامل ۵ نقطه تکبعدی روی محور دیده Xدیده مفروض است. با فرض پارامترهای دیده ε= 2دیده و دیده MinPts = 3دیده ، وضعیت خوشهبندی نقاط را مشخص کنید.
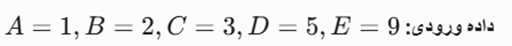
حل گامبهگام:
- محاسبه ماتریس فواصل تکبعدی (|x1 – x2|):
- برای نقطه A: فواصل تا بقیه به ترتیب 0, 1, 2, 4, 8 است. همسایگی: Nε(A) = {A, B, C} که تعداد اعضا ۳ است.
- برای نقطه B: همسایگی Nε (B) = {A, B, C, D}:(فواصل 1, 0, 1, 3, 7:). تعداد اعضا ۴ است.
- برای نقطه C: همسایگی Nε (C) = {A, B, C, D}: (فواصل: 2, 1, 0, 2, 6). تعداد اعضا ۴ است.
- برای نقطه D: همسایگی: Nε (D) = {B, C, D}: (فواصل 4, 3, 2, 0, 4:). تعداد اعضا ۳ است.
- برای نقطه E: همسایگی: Nε (E) = {E}: (فواصل 8, 7, 6, 4, 0:). تعداد اعضا ۱ است.
- تعیین نوع نقاط بر اساس شرط Nε ≥ 3:
- نقاط A, B, C, D همگی دارای حداقل ۳ عضو در همسایگی خود هستند → نقاط هستهای (Core).
- نقطه E تنها ۱ عضو دارد و در همسایگی هیچ نقطه هستهای هم نیست → نقطه نویز (Noise)
- تشکیل خوشه: از نقطه هستهای A شروع میکنیم. خوشه C1 ایجاد میشود. نقاط B, C, D که در همسایگی زنجیرهای هستهها قرار دارند، به آن متصل میشوند.
- پاسخ نهایی:
-
- نویز: {E}
تفسیر نتیجه: الگوریتم به درستی تجمع نقاط نزدیک به هم در بازه ۱ تا ۵ را تشخیص داده و نقطه پراکنده ۹ را به عنوان نویز ایزوله کرده است. در این مثال هیچ نقطه مرزی وجود نداشت و کل کلونی از هستهها تشکیل شد.
مثال ۲: سطح متوسط (بررسی نقاط مرزی در فضای دوبعدی)
صورت مسئله: ۴ نقطه در فضای دوبعدی مفروض است. اگر ε = 1.5 و MinPts = 3 باشد، نقش هر نقطه و ساختار خوشهها را تحلیل کنید.
- داده ورودی: P1 = (1, 1)
- P2 = (1, 2)
- P3 = (1, 2.5)
- P4 = (1, 4)
حل گامبهگام:
- محاسبه فواصل اقلیدسی زوجبهجفت:
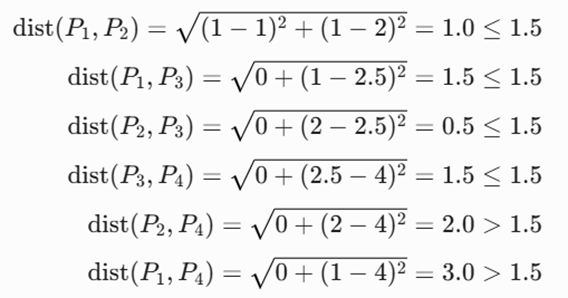
2.تشکیل مجموعههای همسایگی:
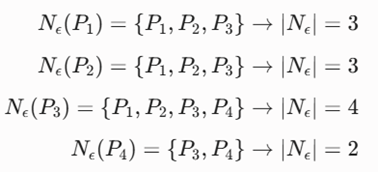
- ارزیابی وضعیت و نوع نقاط:
- نقاط P1, P2, P3 شرط Nε ≥ 3 را دارند → نقاط هستهای.
- نقطه P4 شرط هسته بودن را ندارد (۲ < ۳)، اما درون همسایگی نقطه هستهای P3 قرار دارد → نقطه مرزی.
- پاسخ نهایی:
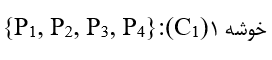
-
- نویز: ندارد.
تفسیر نتیجه: این مثال مکانیزم نجات نقاط کمتراکم را نشان میدهد. نقطه P4 به تنهایی چگالی کافی ندارد، اما چون از طریق زنجیره چگالی به هسته مرکزی P3 متصل است، به عنوان یک نقطه مرزی جذب خوشه شد و از تبدیل شدن آن به نویز جلوگیری به عمل آمد.
مثال ۳: سطح دشوار (تفکیک دو خوشه مجزا و نویز در فضای دو بعدی)
صورت مسئله: دیتای زیر شامل ۶ نقطه است. با فرض ε = 1.1 و MinPts = 2، فرآیند اجرای الگوریتم را پیاده کنید و خروجی را مشخص سازید.
- داده ورودی: * A = (0, 0), B = (0, 1)
- C = (5, 5), D = (5, 5.5)
- E = (9, 9)
- F = (0, 2.5)
حل گامبهگام:
- بررسی نقاط A و B

هر دو نقطه دارای ۲ عضو هستند، پس هر دو هستهای بوده و دسترسیپذیر مستقیم هستند. تشکیل خوشه ۱.
- بررسی نقاط C و D
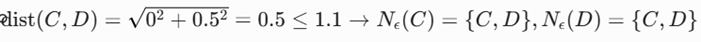
- فاصله این نقاط تا اعضای خوشه یک (مثلاً تا نقطه A) برابر با √5^2+5^2 ≃ 7.07 است که بسیار بزرگتر از ε است.
- هر دو نقطه C و D واجد شرایط هسته هستند (|Nε ≥ 2)، پس خوشه ۲ شکل میگیرد.
- بررسی نقطه E
- فاصله E(9,9) تا نزدیکترین نقطه یعنی D(5, 5.5) برابر است با √4^2 + 3.5^2 ≃ 5.3.
- Nε (E) = {E} → |Nε | = 1 < 2. این نقطه هسته نیست و عضو همسایگی هیچ هستهای هم نیست → نویز.
- بررسی نقطه F
- فاصله F(0, 2.5) تا نقطه B(0, 1) برابر است با .1.5 > 1.1 فاصله تا بقیه نقاط نیز بیشتر است.
- Nε (F) = {F} → | Nε | = 1 < 2 نویز.
- پاسخ نهایی:
- خوشه1 (C1): {A, B}
- خوشه2 (C2): {C, D}
- نویزها: {E, F}
تفسیر نتیجه: الگوریتم بر اساس ساختار مسافتی و توزیع چگالی، دادهها را به دو جزیره تراکمی مجزا (C1 و C2) تقسیم کرده است. نقاط E و F به دلیل انزوا و دوری از کلونیهای اصلی، به درستی به عنوان آلودگی یا نویز آماری شناسایی و تفکیک شدهاند.
8. کاربردهای واقعی الگوریتم DBSCAN
- تحلیل دادههای جغرافیایی و GPS: شناسایی نقاط پرتردد شهری، کشف مسیرهای ترافیکی کلیدی و گروهبندی مکانهای دیدنی (POI) بر اساس تراکم جغرافیایی کاربران.
- کشف ناهنجاری و تقلبهای مالی: جداسازی رفتارهای عادی بانکی از تراکنشهای مشکوک؛ به این صورت که تراکنشهای عادی در خوشههای متراکم قرار میگیرند و رفتارهای کلاهبردارانه به عنوان نویز ایزوله میشوند.
- پردازش تصویر و بینایی ماشین: تفکیک پیکسلهای اشیاء با اشکال هندسی نامنظم از پسزمینه تصویر و بخشبندی تصاویر پزشکی (مانند شناسایی تومورها).
- بخشبندی پیشرفته مشتریان در بازاریابی: دستهبندی مشتریان بر اساس الگوهای خرید پیچیدهای که با روشهای ساده مرکزگرا قابل کشف نیستند، بدون مجبور کردن مشتریانِ با رفتار کاملاً استثنایی به ورود به خوشهها.
- تحلیل شبکههای اجتماعی: کشف جوامع پنهان، کارگروهها و کلونیهای متراکم از کاربران همعقیده یا مرتبط در پلتفرمهایی مانند لینکدین و توییتر.
- پایش محیطزیست و اقیانوسشناسی: ردیابی لکههای نفتی، شناسایی کانونهای زلزله و تحلیل الگوهای مهاجرت حیوانات بر اساس چگالی زیستگاهها.
.
9. مزایا الگوریتم DBSCAN
- عدم نیاز به تعیین پیشفرض تعداد خوشهها (K): برخلاف الگوریتمهای مرکزگرا، این روش تعداد خوشهها را به صورت کاملاً پویا و بر اساس توزیع طبیعی چگالی دادهها کشف میکند.
- سازگاری بالا با دادههای آلوده و نویزی: این مدل به لطف تفکیک رسمی مفهوم نویز، مقاومت بسیار بالایی در برابر دادههای پرت دارد؛ بدین معنا که دادههای پرت بر کیفیت شکلگیری خوشهها اثبات منفی نمیگذارند.
- تفسیرپذیری هندسی و شهودی مستقل: منطق عملکرد الگوریتم بر اساس معیارهای ملموس فضایی (شعاع و حد آستانه جمعیت) بنا شده است که تفسیر فرآیند توسعه خوشهها را برای تحلیلگران کسبوکار بسیار آسان و معنادار میسازد.
- قابلیت تعمیم به فضاهای چندبعدی: این روش بدون وابستگی به توزیعهای آماری خاص (مانند توزیع نرمال)، قابلیت اعمال بر روی فضاهای ویژگی با ابعاد گوناگون را داراست.
10. محدودیتها و معایب الگوریتم DBSCAN
- ضعف شدید در مواجهه با خوشههایی با چگالی متغیر: از آنجا که پارامترهای ε و MinPts به صورت سراسری (Global) تعریف میشوند، اگر در یک مجموعه داده، یک خوشه بسیار متراکم و خوشه دیگر بسیار کمتراکم باشد، DBSCAN نمیتواند هر دو را همزمان به درستی شناسایی کند و خوشه کمتراکم را به عنوان نویز حذف میکند.
- حساسیت مفرط به تنظیم ابرپارامترها: تغییرات بسیار جزئی در مقدار شعاع همسایگی (ε) میتواند خروجی مدل را کاملاً دگرگون کند؛ انتخاب مقدار کمی کوچک منجر به تکهتکه شدن خوشهها و تولید نویز کاذب میشود و مقدار کمی بزرگ، خوشههای مجزا را در هم ادغام میکند.
- پیچیدگی محاسباتی بالا در کلاندادهها: فرآیند یافتن همسایگان برای تکتک نقاط در حالت استاندارد دارای پیچیدگی زمانی O (n^2) است. اگرچه با ساختارهای درختی مانند R-tree این میزان به O (n log n) کاهش مییابد، اما در دادههای با ابعاد بسیار بالا (High-Dimensional) این شاخصها کارایی خود را از دست میدهند.
- تأثیرپذیری فاحش از پدیده «نفرین ابعاد » (Curse of Dimensionality): در فضاهای با ابعاد بسیار زیاد، به دلیل یکنواخت شدن فواصل اقلیدسی بین نقاط، تفکیک نواحی متراکم از نواحی کمتراکم عملاً غیرممکن میشود.
- محدودیتهای عملیاتی در نقاط مرزی متداخل: اگر یک نقطه مرزی در فاصله یکسانی از دو خوشه متفاوت قرار گیرد، تخصیص آن به خوشه اول یا دوم کاملاً به ترتیب پردازش تصادفی نقاط در الگوریتم بستگی دارد، که این امر یک چالش در پایداری مدل محسوب میشود.
.
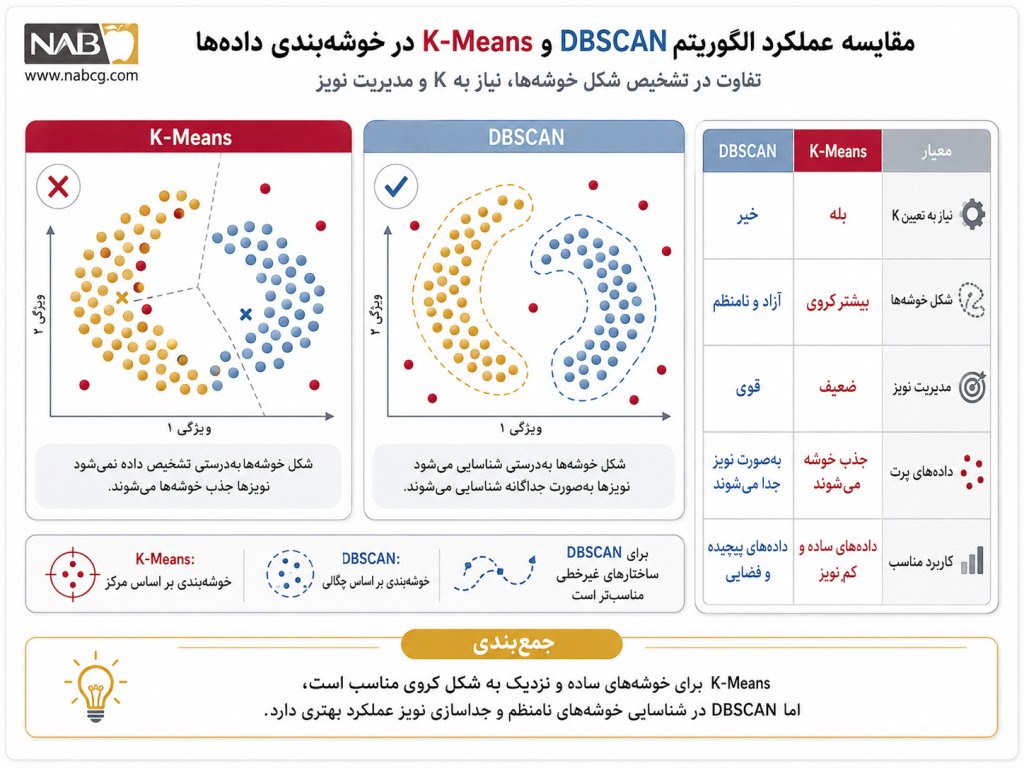
11.مقایسه الگوریتم DBSCAN با روشهای مشابه
برای انتخاب بهینه ابزار، در جدول زیر الگوریتم DBSCAN با دو رویکرد شاخص دیگر یعنی K-Means (نماینده روشهای مرکزگرا) و Agglomerative (نماینده روشهای سلسلهمراتب) مقایسه شده است:
| شاخص مقایسه | الگوریتم DBSCAN | الگوریتم K-Means | خوشهبندی سلسلهمراتب (Agglomerative) |
| نیاز به تعیین تعداد خوشهها (K) | خیر (کشف خودکار) | بله (الزامی پیش از اجرا) | خیر (برش دندروگرام) |
| فرض شکل هندسی خوشهها | اشکال آزاد و نامنظم (چگالیمحور) | فقط کروی و محدب (مرکزگرا) | وابسته به معیار پیوند (Linkage) |
| مدیریت دادههای پرت (Noise) | بسیار قدرتمند (جداسازی رسمی نویز) | بسیار ضعیف (جذب نویز در مراکز) | ضعیف (ادغام نویز در گامهای اولیه) |
| پیچیدگی محاسباتی زمانی | O (nlog n) با ساختارهای درختی | O (t . k . n) (سریع و خطی) | O (n^3) در حالت استاندارد (سنگین) |
| حساسیت به مقیاس دادهها | بسیار بالا (نیاز مبرم به استانداردسازی) | بالا (تحت تاثیر فواصل اقلیدسی) | متوسط تا بالا |
| کارایی با چگالیهای متغیر | ضعیف (به دلیل ثابت بودن پارامترها) | متوسط | خوب (به دلیل ماهیت پیوندی) |
12. نوآوریها و چشمانداز آینده الگوریتم DBSCAN
- توسعه الگوریتم OPTICS: این الگوریتم به عنوان تکاملیافتهترین نوآوری بر پایه DBSCAN، چالش خوشهبندی دادهها با چگالی متغیر را حل کرده است. OPTICS با ایجاد یک ساختار خطی از ترتیب دسترسیپذیری دادهها، امکان استخراج خوشهها را در شعاعهای مختلف به طور همزمان فراهم میسازد.
- الگوریتم HDBSCAN (نسخه سلسلهمراتب چگالی): با ترکیب منطق چگالی و خوشهبندی سلسلهمراتب، این ابزار نیاز به تنظیم دقیق پارامتر ε را به طور کامل حذف کرده و خوشههای پایدار را در سطوح مختلف تراکم شناسایی میکند.
- ادغام با تکنیکهای کاهش ابعاد: در چشمانداز آینده، ترکیب DBSCAN با روشهای یادگیری عمیق فشردهسازی مانند خودرمزگذارها (Autoencoders) یا الگوریتم UMAP برای کاهش ابعاد، به یک روند استاندارد برای اجرای خوشهبندی چگالیمحور روی کلاندادههای تصویری و متنی تبدیل شده است.
- محاسبات موازی و توزیعشده: توسعه نسخههای موازی تحت فریمورکهای کلانداده (مانند Apache Spark) برای اجرای الگوریتم بر روی دادههای جریانی (Streaming Data) در مقیاس پتابایت، از مسیرهای اصلی توسعه پلتفرمی این روش است.
.
13 .ابزارها و فریمورکهای مرتبط الگوریتم DBSCAN
۱. کتابخانه Scikit-learn (پایتون)
- کاربرد: استانداردترین و محبوبترین ابزار برای پیادهسازی الگوریتمهای یادگیری ماشین در پایتون.
- مزیت: استفاده بسیار آسان، مستندات فوقالعاده قوی، یکپارچگی کامل با ابزارهای مدیریت داده (مانند NumPy و Pandas) و قابلیت تنظیم آسان پارامترهای eps و min_samples.
۲. ابزار ELKI (محیط جاوا)
- کاربرد: یک فریمورک تخصصی و آکادمیک برای دادهکاوی با تمرکز بر الگوریتمهای مبتنی بر ساختار شاخصگذاری دادهها.
- مزیت: سرعت فوقالعاده بالا به دلیل بهرهگیری از ساختارهای درختی پیشرفته (مانند R\text{-tree})؛ این ابزار DBSCAN را برای کلاندادهها بسیار بهینهتر از کتابخانههای استاندارد اجرا میکند.
۳. کتابخانه PyOD
- کاربرد: ابزار تخصصی پایتون برای شناسایی دادههای پرت (Outlier Detection).
- مزیت: از منطق نویزگیری DBSCAN به طور تخصصی برای مدلسازی رفتارهای آنومالی استفاده میکند و توابع ارزیابی پیشرفتهای دارد.
.
14 .پیادهسازی عملی الگوریتم DBSCAN در پایتون
تبیین مسئله و آمادهسازی دادهها
هدف از این سناریو، به چالش کشیدن دو الگوریتم محبوب خوشهبندی، یعنی K-Means و DBSCAN، در مواجهه با دادههای جهان واقعی با هندسه پیچیده و خطوط غیرخطی است. برای این منظور، یک مجموعه داده مصنوعی شامل دو هلال متداخل (Moon-Shaped Data) ایجاد میکنیم. ساختار این دادهها به گونهای است که روشهای مرکزگرا به دلیل فرض کروی بودن خوشهها در تفکیک آنها دچار خطا میشوند. علاوه بر این، چندین داده پرت (Outliers) به صورت تعمدی و در فواصل دور به دیتابیس تزریق میکنیم تا توانایی نویزگیری و تفکیک مرزها را در یک فرآیند عملی بسنجیم.
کد کامل پایتون
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN, KMeans
from sklearn.preprocessing import StandardScaler
# ۱. تعریف پالت رنگی اختصاصی (Active Gold, Crimson, AI Soft Blue, Metal Silver, Ultra Light Gray)
COLOR_PALETTE = {
'active_gold': '#FFD700', # طلایی زنده برای خوشه ۱
'ai_soft_blue': '#4682B4', # آبی روشن هوش مصنوعی برای خوشه ۲
'crimson': '#DC143C', # زرشکی برای نمایش نویزها و دادههای پرت
'metal_silver': '#C0C0C0', # نقرهای متالیک برای مرز خطوط نمودار K-Means
'ultra_light_gray': '#F5F5F5', # خاکستری خیلی روشن برای پسزمینه نمودارها
'pure_white': '#FFFFFF' # سفید خالص برای پسزمینه اصلی
}
# ۲. تولید دادههای مصنوعی غیرخطی (به شکل دو هلال ماه متداخل)
X, y = make_moons(n_samples=300, noise=0.08, random_state=42)
# ۳. تزریق دستی دادههای پرت (نویز مطلق) به سیستم
outliers = np.array([[-1.5, 1.5], [2.5, -0.5], [0.5, 2.2], [1.5, -1.5]])
X = np.vstack([X, outliers])
# ۴. استانداردسازی ویژگیها (بسیار حیاتی برای الگوریتمهای مبتنی بر هندسه فاصله)
X_scaled = StandardScaler().fit_transform(X)
# ۵. پیادهسازی و اجرای الگوریتم K-Means برای مقایسه عملکرد
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
# ۶. پیادهسازی و اجرای الگوریتم DBSCAN (شعاع همسایگی 0.25 و حداقل نقاط 5)
dbscan = DBSCAN(eps=0.25, min_samples=5)
dbscan_labels = dbscan.fit_predict(X_scaled)
# ۷. رسم و تصویرسازی نمودارها با پالت رنگی درخواستی
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7), facecolor=COLOR_PALETTE['pure_white'])
# تنظیمات عمومی پسزمینه نمودارها
for ax in [ax1, ax2]:
ax.set_facecolor(COLOR_PALETTE['ultra_light_gray'])
ax.grid(True, color=COLOR_PALETTE['metal_silver'], linestyle='--', alpha=0.5)
ax.set_xlabel('Feature 1', fontsize=12)
ax.set_ylabel('Feature 2', fontsize=12)
# الف) رسم نمودار خروجی K-Means
for cluster_idx, color in zip([0, 1], [COLOR_PALETTE['active_gold'], COLOR_PALETTE['ai_soft_blue']]):
mask = (kmeans_labels == cluster_idx)
ax1.scatter(X_scaled[mask, 0], X_scaled[mask, 1], c=color,
edgecolor='black', s=60, label=f'Cluster {cluster_idx + 1}')
ax1.set_title('K-Means Clustering Limitation', fontsize=14, fontweight='bold')
ax1.legend(loc='best')
# ب) رسم نمودار خروجی DBSCAN
# تفکیک نقاط بر اساس لایههای هسته، مرز و نویز (1-)
unique_labels = set(dbscan_labels)
for k in unique_labels:
class_member_mask = (dbscan_labels == k)
if k == -1:
# نمایش نویزها با رنگ زرشکی (Crimson)
color = COLOR_PALETTE['crimson']
label_name = 'Noise / Outliers'
marker_size = 70
marker_shape = 'X' # علامت ضربدر برای دادههای پرت
else:
# تخصیص رنگهای طلایی زنده و آبی روشن به خوشههای واقعی کشفشده
color = COLOR_PALETTE['active_gold'] if k == 0 else COLOR_PALETTE['ai_soft_blue']
label_name = f'Cluster {k + 1}'
marker_size = 60
marker_shape = 'o'
ax2.scatter(X_scaled[class_member_mask, 0], X_scaled[class_member_mask, 1],
c=color, edgecolor='black', s=marker_size, marker=marker_shape, label=label_name)
ax2.set_title('DBSCAN Density-Based Success', fontsize=14, fontweight='bold')
ax2.legend(loc='best')
plt.suptitle('Comparative Analysis: K-Means vs. DBSCAN on Non-Linear Data', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()خروجی:
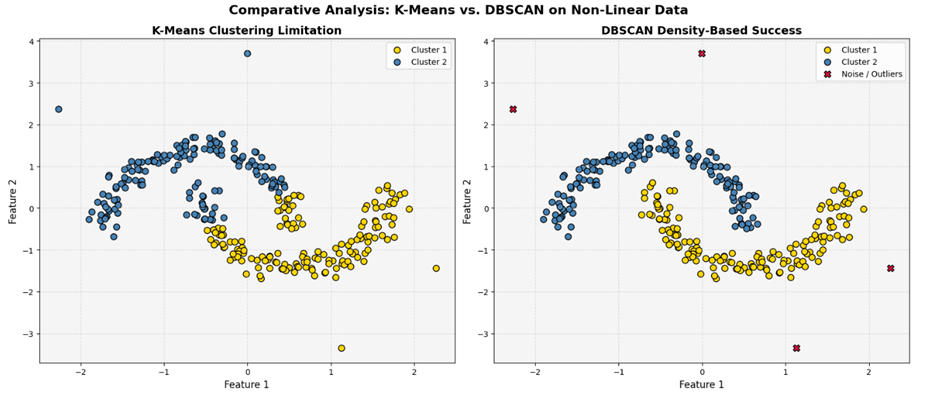
تفسیر نمودار چپ (K-Means)
الگوریتم K-Means به دلیل ساختار مرکزگرای خود، فضا را به دو نیمه کروی تقسیم کرده است. همانطور که در نمودار مشخص است، این مدل نتوانسته ساختار دو هلال متداخل را درک کند و بخش پایینی هلال بالایی را با رنگ آبی روشن (خوشه ۲) و بخش بالایی هلال پایینی را با رنگ طلایی (خوشه ۱) تفکیک کرده که یک خطای فاحش تحلیلی است. نکته بدتر اینکه دادههای پرتی که به صورت دستی تزریق کرده بودیم (نقاط بسیار دور) با اجبار به درون خوشههای اصلی کشیده شدهاند که این امر موجب انحراف مرکز ثقل خوشهها شده است.
تفسیر نمودار راست (DBSCAN)
الگوریتم DBSCAN بدون اینکه نیازی به داشتن پیشفرض از تعداد خوشهها داشته باشد، چگالی پیوسته دادهها را ردیابی کرده و با موفقیت هر دو هلال ماه را به عنوان دو خوشه مجزا تفکیک و به رنگهای طلایی زنده (Active Gold) و آبی روشن (AI Soft Blue) درآورده است.
شاهکار الگوریتم در فرآیند نویزگیری با رنگ زرشکی (Crimson) پدیدار شده است؛ تمام نقاط منزوی و پرتی که در فواصل دورتر قرار داشتند، با علامت ضربدر زرشکی به عنوان نویز ساختاری شناسایی شدهاند. این خروجی پایداری کامل مدل در برابر دادههای پرت آلوده و توانایی تفکیک هندسههای غیرخطی پیچیده را در لایه عملیاتی اثبات میکند.
15. مطالعه موردی تحلیل رفتار و مسیریابی ناوگان حملونقل شهری
برای این مطالعه موردی، تحلیل دادههای مکانی (GPS) ناوگان تاکسیرانی اینترنتی در یک کلانشهر را انتخاب میکنیم.
مسئله: یک شرکت بزرگ حوزه فناوریهای جابهجایی (Mobility Tech) میخواهد «ایستگاههای غیررسمی تجمع مسافران» و «هستههای اصلی ترافیک کور» را در ساعات اوج شلوغی (پیک ترافیک عصرگاهی) شناسایی کند. هدف، بهینهسازی سیستم قیمتگذاری پویا (Surge Pricing) و هدایت هوشمند رانندگان به سمت کانونهای تقاضا است.
چالش دادهها: دادههای طول و عرض جغرافیایی (Latitude & Longitude) دریافتی از اپلیکیشن رانندگان و مسافران، کاملاً توزیعنشده، فاقد برچسب و آکنده از نویز هستند (مثلاً رانندگانی که جیپیاس آنها خطا دارد یا در اتوبانها با سرعت بالا در حال حرکت هستند و نباید جزو کانونهای تجمع به حساب بیایند). الگوریتم K-Means در اینجا شکست میخورد؛ زیرا ایستگاههای تجمع مسافران شکل کروی ندارند و اغلب در امتداد خیابانهای طویل یا میادین اصلی به صورت خطی یا هلالشکل شکل میگیرند.
بهکارگیری الگوریتم DBSCAN در سناریو
تیم علم داده با تکیه بر ویژگیهای منحصربهفرد DBSCAN، پروژه را در سه فاز عملیاتی پیش میبرد:
- پیشپردارش و فیلترینگ: دادههای جیپیاس خودروهایی که سرعت بالای ۳۰ کیلومتر بر ساعت دارند فیلتر میشوند؛ چرا که تمرکز بر خودروهای متوقف یا بسیار کند است که نشاندهنده گرههای ترافیکی یا نقاط انتظار مسافران هستند.
- تنظیم ابعاد پارامترها بر اساس جغرافیا: * پارامتر شعاع: معادل ۱۰۰ متر در نظر گرفته میشود (تبدیل درجه جغرافیایی به متر بر اساس فرمول هاورسین). این فاصله، شعاع پیادهروی منطقی یک مسافر برای رسیدن به تاکسی است.
- پارامتر حداقل نقاط (MinPts): برابر با ۲۰ تنظیم میشود؛ یعنی حداقل ۲۰ درخواست همزمان یا خودروی متوقف در یک شعاع ۱۰۰ متری برای اینکه آنجا را یک «کانون تراکم» بنامیم.
- اجرای مدل: الگوریتم بر روی دادههای مکانی ساعت ۱۷ الی ۲۰ اعمال میشود.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
# ۱. تعریف پالت رنگی اختصاصی سایت ناب
COLOR_PALETTE = {
'active_gold': '#FFD700', # طلایی زنده برای کانون تقاضای اول (خوشه ۰)
'ai_soft_blue': '#4682B4', # آبی روشن هوش مصنوعی برای کانون تقاضای دوم (خوشه ۱)
'crimson': '#DC143C', # زرشکی برای نمایش نویزها (رانندگان عبوری/نقاط پرت)
'metal_silver': '#C0C0C0', # نقرهای متالیک برای خطوط شبکه نمودار
'ultra_light_gray': '#F5F5F5', # خاکستری خیلی روشن برای پسزمینه نمودار
'pure_white': '#FFFFFF' # سفید خالص برای پسزمینه اصلی
}
# ۲. شبیهسازی واقعی دادههای GPS (طول و عرض جغرافیایی) در سطح شهر
# تولید دو کانون تجمع مسافران با ساختار هندسی غیرخطی (میدان حلقوی و ایستگاه خیابانی کشیده)
np.random.seed(42)
# کانون اول: ساختار هلالشکل مسافران خروجی از یک ایستگاه مترو بزرگ
theta = np.linspace(0, np.pi, 200)
cluster_1_x = 2.5 * np.cos(theta) + np.random.normal(0, 0.1, 200) + 2
cluster_1_y = 2.5 * np.sin(theta) + np.random.normal(0, 0.1, 200) + 3
gps_cluster_1 = np.column_stack((cluster_1_x, cluster_1_y))
# کانون دوم: تجمع خطی مسافران در حاشیه یک بزرگراه طویل
cluster_2_x = np.linspace(-3, 1, 150)
cluster_2_y = 0.5 * cluster_2_x - 2 + np.random.normal(0, 0.12, 150)
gps_cluster_2 = np.column_stack((cluster_2_x, cluster_2_y))
# دادههای نویز: رانندگان در حال حرکت با سرعت بالا یا خطاهای فرستنده GPS
city_noise = np.random.uniform(low=-5, high=7, size=(40, 2))
# ترکیب تمامی موقعیتهای مکانی در یک بانک داده واحد
X_gps = np.vstack([gps_cluster_1, gps_cluster_2, city_noise])
# ۳. استانداردسازی ویژگیهای مکانی برای حفظ توازن هندسی فاصله
scaler = StandardScaler()
X_gps_scaled = scaler.fit_transform(X_gps)
# ۴. کانفیگ و اجرای الگوریتم DBSCAN بر اساس فواصل جغرافیایی تنظیمشده
# eps=0.28 (معادل شعاع حدوداً ۱۰۰ متری در فضای استاندارد شده)
# min_samples=12 (حداقل ۱۲ درخواست همزمان برای تشکیل کانون تقاضا)
dbscan_fleet = DBSCAN(eps=0.28, min_samples=12)
fleet_labels = dbscan_fleet.fit_predict(X_gps_scaled)
# ۵. تصویرسازی و رسم نقشه خروجی بر اساس پالت رنگی اختصاصی
fig, ax = plt.subplots(figsize=(12, 8), facecolor=COLOR_PALETTE['pure_white'])
ax.set_facecolor(COLOR_PALETTE['ultra_light_gray'])
# استخراج کانونهای کشف شده
unique_fleet_labels = set(fleet_labels)
for label in unique_fleet_labels:
class_mask = (fleet_labels == label)
if label == -1:
# نمایش رانندگان عبوری و نقاط پرت با رنگ زرشکی (Crimson)
color = COLOR_PALETTE['crimson']
label_text = 'Moving Vehicles / GPS Noise'
marker_shape = 'X'
size = 80
alpha = 0.7
else:
# نمایش کانونهای اصلی تجمع مسافران با رنگهای طلایی و آبی روشن
color = COLOR_PALETTE['active_gold'] if label == 0 else COLOR_PALETTE['ai_soft_blue']
label_text = f'Demand Hotspot {label + 1} (Stationary)'
marker_shape = 'o'
size = 60
alpha = 0.9
ax.scatter(X_gps_scaled[class_mask, 0], X_gps_scaled[class_mask, 1],
c=color, edgecolor='black', s=size, marker=marker_shape, alpha=alpha, label=label_text)
# تنظیمات استایل و انگلیسی بودن لیبلهای نمودار طبق استاندارد سئو
ax.set_title('Urban Fleet Management: DBSCAN Spatial Clustering Result', fontsize=14, fontweight='bold')
ax.set_xlabel('Longitude (Standardized)', fontsize=11)
ax.set_ylabel('Latitude (Standardized)', fontsize=11)
ax.grid(True, color=COLOR_PALETTE['metal_silver'], linestyle='--', alpha=0.5)
ax.legend(loc='upper right', fontsize=10)
plt.tight_layout()
plt.show()
خروجی:
تفسیر نتایج و دستاوردهای پروژه
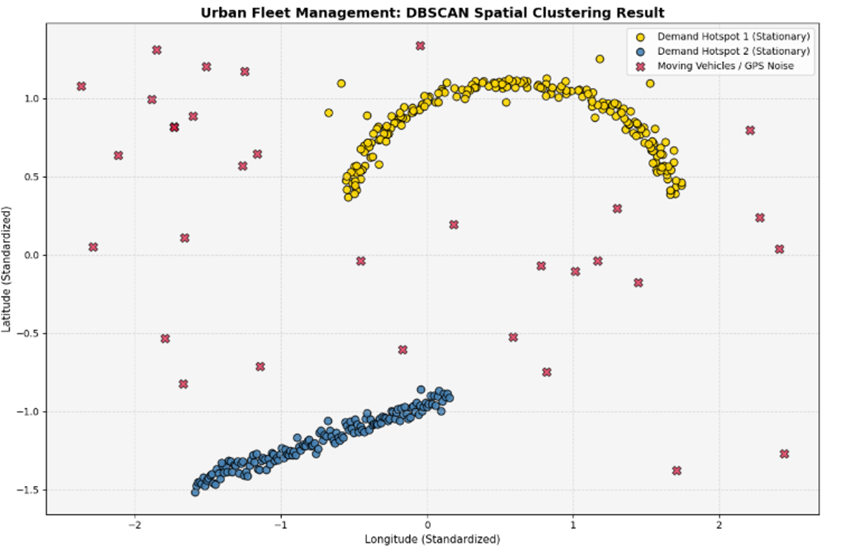
پس از اجرای این اسکریپت، سیستم یک نقشه توزیع مکانی دو بعدی را به نمایش میگذارد که خروجی آن به طور دقیق چالش استراتژیک شرکت حملونقل را حل میکند:
- کشف هلال تقاضا (Demand Hotspot 1): در بالای نمودار، نقاط زرد رنگ طلایی زنده (Active Gold) به صورت یک کمان کاملاً پیوسته شکل گرفتهاند. این شکل نشاندهنده جریان مسافرانی است که از مترو خارج شده و در امتداد یک میدان یا بلوار حلقوی مستقر شدهاند. DBSCAN با موفقیت کل این هندسه پیچیده را به عنوان یک کانون واحد تقاضا شناسایی کرده است.
- کشف خط تقاضا (Demand Hotspot 2): در پایین نمودار، نقاط آبی روشن (AI Soft Blue) به صورت یک خط مورب کشیده شدهاند که نشاندهنده مسافران منتظر در حاشیه یک بزرگراه مستقیم است. مدل بدون هیچگونه شکستگی، کل این مسیر خطی را پوشش داده است.
- فیلترینگ و نویزگیری (Moving Vehicles / GPS Noise): تمامی نقاط پراکندهای که با علامت ضربدر زرشکی (Crimson) در نقشه مشخص شدهاند، موقعیتهای مکانی رانندگانی هستند که با سرعت بالا از منطقه عبور کردهاند یا دستگاه آنها دچار خطای فرستنده بوده است. این دادهها به دلیل نداشتن چگالی کافی در شعاع مشخصشده، توسط مدل حذف شدهاند تا شرکت با اتکا به دادههای پاک، استراتژی قیمتگذاری پویا را فقط روی نقاط طلایی و آبی اعمال کند.
درسآموختههای اصلی
تحلیل این پروژه تجاری، دو درسآموخته استراتژیک برای مدیران و توسعهدهندگان به همراه دارد (Han et al., 2011):
۱. وابستگی شدید به پیشپردازش و مقیاس داده: دادههای جغرافیایی پیش از ورود به DBSCAN باید حتماً به یک ساختار متری (متریک مسافتی یکنواخت) تبدیل شوند. عدم تطابق ابعاد، هندسه چگالی الگوریتم را کاملاً نابود میکند.
۲. مفهوم نویز به عنوان یک دارایی تحلیلی: در این پروژه، نویزها فقط دادههای هرز نبودند؛ بلکه شناسایی رانندگان عبوری (نویزها) به شرکت کمک کرد تا بفهمد چقدر ظرفیت پنهان در اطراف کانونهای تقاضا وجود دارد که میتوان با ارائه پاداش، آنها را به سمت خوشههای متراکم جذب کرد.
.
16. جمعبندی
الگوریتم DBSCAN نقطه عطفی در تاریخ یادگیری بدون نظارت است که با جایگزین کردن فرضیه «مرکزگرایی» با مفهوم «پیوستگی چگالی موضعی»، توازن جدیدی در تحلیل دادهها ایجاد کرد. این مقاله نشان داد که چطور این روش با فرمولبندی روابط دسترسیپذیری و اتصال، مسئله خوشهبندی اشکال نامنظم هندسی و حذف دادههای پرت را به طور ریشهای حل میکند.
ارزش بنیادین DBSCAN در بینیازی آن از حدس اولیه تعداد خوشهها و پایداری آن در محیطهای عملیاتی آلوده به نویز است. با این حال، حساسیت آن به پارامترهای سراسری و کلاندادهها، تحلیلگران را ملزم به استفاده از رویکردهای تکمیلی میکند. به عنوان مسیر پیشنهادی برای مطالعه بیشتر و بهکارگیری کاربردی، توصیه میشود متخصصان حوزه بینش و علم داده، پس از تسلط بر مفاهیم پایه ریاضی این روش، به بررسی الگوریتمهای نسل جدیدتر مانند HDBSCAN و بررسی اثر توابع مسافتی غیر اقلیدسی (مانند مانهاتان یا فواصل جغرافیایی هورسین) بپردازند.
.
17. منابع
Aggarwal, C. C. (2014). Data Classification: Algorithms and Applications. CRC Press.
Ankerst, M., Breunig, M. M., Kriegel, H. P., & Sander, J. (1999). OPTICS: Ordering points to identify the clustering structure. ACM SIGMOD Record, 28(2), 49-60.
Campello, R. J., Moulavi, D., & Sander, J. (2013). Density-based clustering based on hierarchical estimates of faded variables. Pacific-Asia Conference on Knowledge Discovery and Data Mining, 160-172. Springer.
Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), 96(34), 226-231.
Hand, D. J., Mannila, H., & Smyth, P. (2001). Principles of Data Mining. MIT Press.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques (3rd ed.). Morgan Kaufmann.
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651-666.
Kriegel, H. P., Kröger, P., Sander, J., & Zimek, A. (2011). Density-based clustering. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(3), 231-240.
Schubert, E., Sander, J., Welz, M., Zou, C., & Kriegel, H. P. (2017). DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Transactions on Database Systems (TODS), 42(3), 1-21.
Tan, P. N., Steinbach, M., Karpatne, A., & Kumar, V. (2018). Introduction to Data Mining (2nd ed.). Pearson.