

1.مقدمه
بخش بزرگی از پیشرفتهای یادگیری ماشین بر پایه دسترسی به دادههای عظیم و برچسبدار شکل گرفته است. با این حال، در بسیاری از کاربردهای واقعی، چنین دادهای برای تمام کلاسها یا مفاهیم جدید در دسترس نیست. محصولات نوظهور، گونههای نادر، تهدیدهای سایبری روز صفر یا بیماریهای تازهظهور نمونههایی هستند که مدلهای سنتی در مواجهه با آنها دچار ناتوانی میشوند؛ زیرا هرگز در طول آموزش نمونهای از آنها ندیدهاند. این محدودیت بنیادین، انگیزه شکلگیری یادگیری صفرنمونه (Zero-Shot Learning یا ZSL) بوده است.
یادگیری صفرنمونه پارادایمی است که به مدل اجازه میدهد بدون مشاهده حتی یک نمونه برچسبدار از یک کلاس جدید، آن را شناسایی یا طبقهبندی کند. این توانایی از طریق ایجاد یک پل معنایی میان دانش پیشین مدل و توصیفات انتزاعی کلاسهای ناشناخته حاصل میشود. به جای اتکا به دادههای عینی، ZSL بر بازنماییهای مشترک میان تصویر و متن، ویژگیهای توصیفی (Attributes) و فضاهای جاسازی معنایی (Semantic Embeddings) تکیه دارد.
در این مقاله، ابتدا مفهوم و ضرورت یادگیری صفرنمونه را بررسی میکنیم، سپس مکانیزم عملکرد، معماریهای فنی و روشهای پیادهسازی آن را تحلیل میکنیم. در ادامه، با مثالهای عملی و مطالعات موردی صنعتی، نشان میدهیم چگونه این رویکرد میتواند وابستگی هوش مصنوعی به دادههای گسترده را کاهش دهد و تعمیمپذیری مدلها را به سطحی بالاتر ارتقا دهد.
۲. تعریف
یادگیری صفرنمونه (ZSL) یک تکنیک پیشرفته در یادگیری ماشین است که به مدلها اجازه میدهد وظایفی را انجام دهند یا اشیائی را شناسایی کنند که هرگز در طول دوره آموزش با آنها مواجه نشدهاند. این روش برخلاف یادگیری سنتی، بر پایه انتقال دانش استوار است؛ به این معنا که مدل از آموختههای پیشین خود برای درک و تحلیل موقعیتهای کاملاً جدید استفاده میکند، بدون آنکه نیاز به دادههای آموزشی مستقیم برای آن تسک خاص داشته باشد.
برای درک بهتر این مفهوم، سناریوی شناسایی حیوانات را در نظر بگیرید. فرض کنید مدلی برای شناسایی انواع جانوران آموزش دیده است. اما در مجموعه دادههای آموزشی آن، هیچ تصویری از گورخر وجود ندارد. در حالت عادی، مدل در مواجهه با تصویر گورخر دچار خطا میشود، اما در چارچوب ZSL، مدل میتواند از طریق یک توصیف منطقی به ماهیت آن پی ببرد.
این فرآیند استنتاجی طی گامهای زیر عملیاتی میشود:
- شناسایی ویژگیهای پایه: مدل از قبل با ویژگیهای فیزیکی و زیستی مختلفی مانند داشتن چهار پا، زیستگاه ساوانا یا الگوهای خطدار پوست آشنا شده است.
- دریافت توصیف معنایی: در مرحله مواجهه با موجود ناشناخته، یک توصیف متنی به مدل ارائه میشود: حیوانی شبیه به اسب، دارای خطوط سیاه و سفید که در چمنزارهای آفریقا زندگی میکند.
- تطبیق و استنتاج: مدل با استفاده از درک خود از ویژگیهای آناتومیک و محیطی و انطباق آنها با توصیف ارائه شده. نتیجه میگیرد که تصویر پیشرو به احتمال بسیار زیاد یک گورخر است. در حالی که پیش از آن هرگز تصویری از این حیوان را پردازش نکرده بود.
.
۳. مقایسه تحلیلی: یادگیری صفرنمونه (ZSL) در مقابل یادگیری کمنمونه (FSL)
در دنیای هوش مصنوعی، یادگیری صفرنمونه و کمنمونه هر دو با هدف غلبه بر چالش کمبود داده توسعه یافتهاند. با این حال، تفاوت بنیادی آنها در میزان تکیه بر توصیفات انتزاعی نسبت به نمونههای عینی است. در حالی که ZSL کاملاً بر پیوند میان مفاهیم (Semantic Bridge) تکیه دارد. FSL از تعداد اندکی داده برای تنظیم دقیق (Fine-tuning) مرزهای تصمیمگیری خود استفاده میکند.
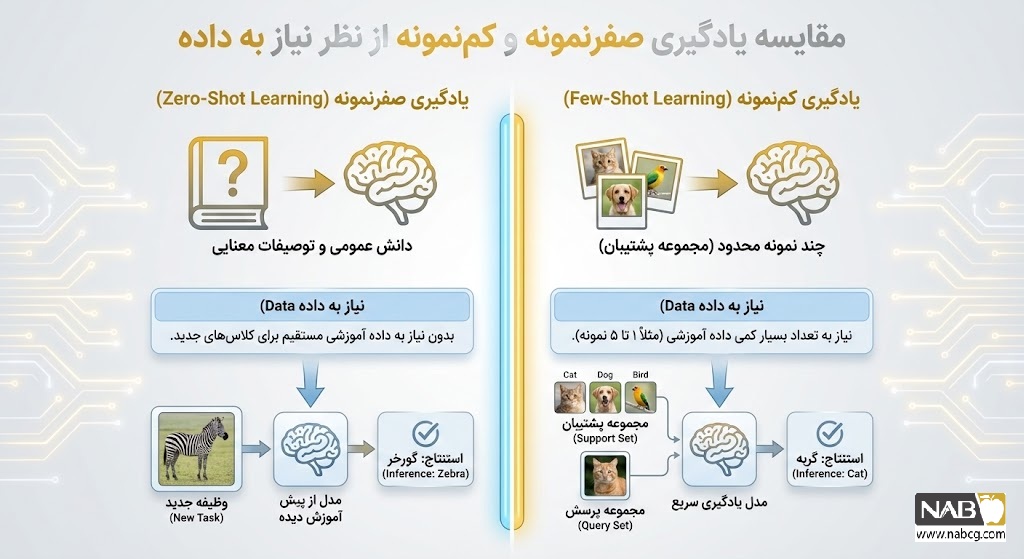
جدول زیر، مقایسهای جامع از ابعاد فنی و کاربردی این دو پارادایم ارائه میدهد:
| وجه تمایز | یادگیری صفرنمونه (ZSL) | یادگیری کمنمونه (FSL) |
| ماهیت عملکرد | مدیریت وظایف جدید بدون هیچگونه داده برچسبدار آموزشی. | یادگیری وظایف جدید از طریق تعداد بسیار محدودی نمونه (1 تا 5 نمونه). |
| مکانیسم یادگیری | استنتاج دستههای جدید از طریق نگاشت توصیفات به دانش پیشین. | شناسایی الگوها و خوشهبندی بر اساس نمونههای عینی ارائه شده. |
| نیاز به داده | به صفر نمونه آموزشی برای کلاسهای هدف نیاز دارد. | به ۱ تا ۵ نمونه آموزشی برای هر کلاس جدید نیاز دارد. |
| تکیه بر دانش پیشین | بر روابط معنایی بین مفاهیم و ویژگیهای انتزاعی استوار است. | از دانش پیشین استفاده میکند اما آن را با دادههای جدید بهروزرسانی میکند. |
| دقت و انطباقپذیری | تعمیمپذیری بالا به وظایف کاملاً ناشناخته، اما دقت نسبتاً پایینتر. | انطباق سریع با وظایف خاص و معمولاً دارای دقت بالاتر نسبت به ZSL. |
| مثال کاربردی ۱ | تشخیص اسپم: شناسایی ایمیلهای مخرب صرفاً بر اساس تعریف لینکهای مشکوک. | تحلیل قصد مشتری: شناسایی قصد لغو اشتراک پس از دیدن تنها چند مکالمه مشابه. |
| مثال کاربردی ۲ | تحلیل احساسات: تشخیص وضعیتهای روحی پیچیده تنها با استفاده از تعاریف لغوی. | دستهبندی اسناد: یادگیری تشخیص فاکتور خرید پس از مشاهده چند نمونه فیزیکی. |
4.اهمیت و ضرورت راهبردی یادگیری صفرنمونه (Zero-Shot Learning)
در عصر انفجار اطلاعات، یادگیری نظارتشده (Supervised) با چالشی به نام گلوگاه داده روبروست. ضرورت استفاده از ZSL زمانی آشکار میشود که بدانیم هوش مصنوعی سنتی در مواجهه با مفاهیم خارج از مجموعه آموزشی (Out-of-Distribution)، کاملاً ناتوان است. اهمیت این فناوری در محورهای زیر خلاصه میشود:
- مدیریت کلاسهای نایاب و دمدراز (Long-tail Distribution): در دنیای واقعی، توزیع دادهها یکنواخت نیست. برای برخی پدیدهها (مثل برندهای خاص یا بیماریهای نادر) میلیونها نمونه وجود دارد، اما برای هزاران دسته دیگر، دادهها بسیار اندک یا صفر هستند. ZSL با توانمندسازی مدل برای شناسایی این دستههای کمتکرار، عدالت توزیعی در تشخیص را برقرار میکند.
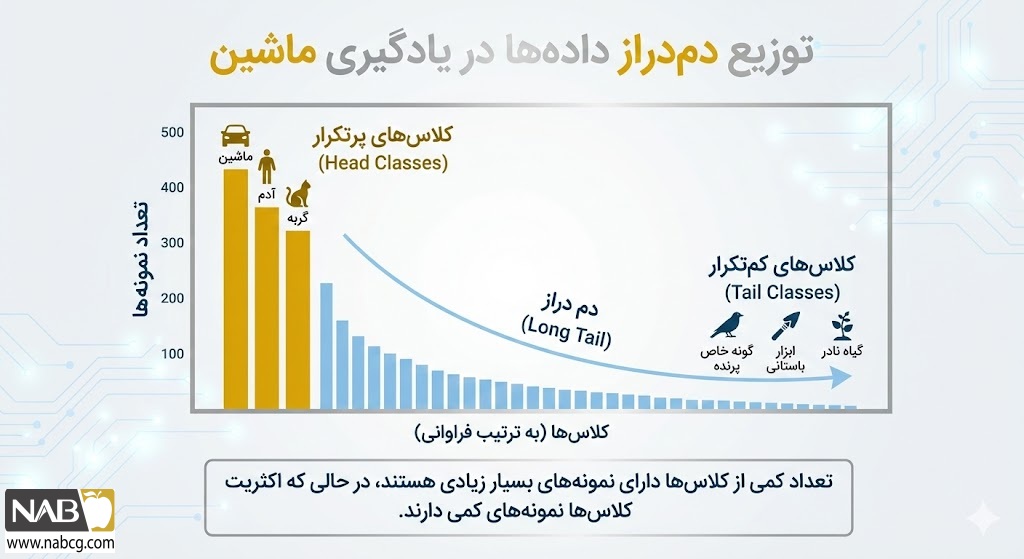
- کاهش وابستگی به برچسبگذاری انسانی: فرآیند برچسبگذاری داده (Annotation) نه تنها هزینهبر و زمانبر است، بلکه در حوزههای تخصصی (مانند تفسیر تصاویر پاتولوژی) نیازمند حضور خبرگان گرانقیمت است. ضرورت ZSL در اینجا، رهاسازی هوش مصنوعی از این وابستگی و حرکت به سوی خودکفایی در یادگیری است.
- انطباقپذیری با دنیای پویا: جهان به سرعت در حال تغییر است و مفاهیم جدید (مانند محصولات تکنولوژیک نوظهور یا ویروسهای جهشیافته) هر روز پدیدار میشوند. مدلی که برای شناسایی آنها نیاز به بازآموزی (Retraining) مداوم داشته باشد، ناکارآمد است. ZSL ضرورتِ یادگیری در لحظه را از طریق توصیفات متنی پوشش میدهد.
- پیشنیاز رسیدن به هوش مصنوعی عمومی (AGI): انسانها برای شناخت یک مفهوم جدید نیازی به دیدن هزاران نمونه ندارند. انتقال دانش از مفاهیم مشابه، پایه هوش انسانی است. توسعه ZSL گامی حیاتی برای نزدیک کردن ماشین به درک مفهومی و انتزاعی، مشابه مغز انسان، محسوب میشود.
.
5. یادگیری صفرنمونه چگونه کار میکند؟
مکانیسم عملکرد یادگیری صفرنمونه (ZSL) بر پایه انتقال دانش از دستههای دیده شده (Seen) به دستههای دیده نشده (Unseen) استوار است. این فرآیند برخلاف یادگیری سنتی که بر مرزهای تصمیمگیری مستقیم تکیه دارد، از یک فضای معنایی مشترک (Joint Embedding Space) استفاده میکند. در واقع، مدل یاد میگیرد که ویژگیهای بصری را به توصیفات انتزاعی متصل کند.
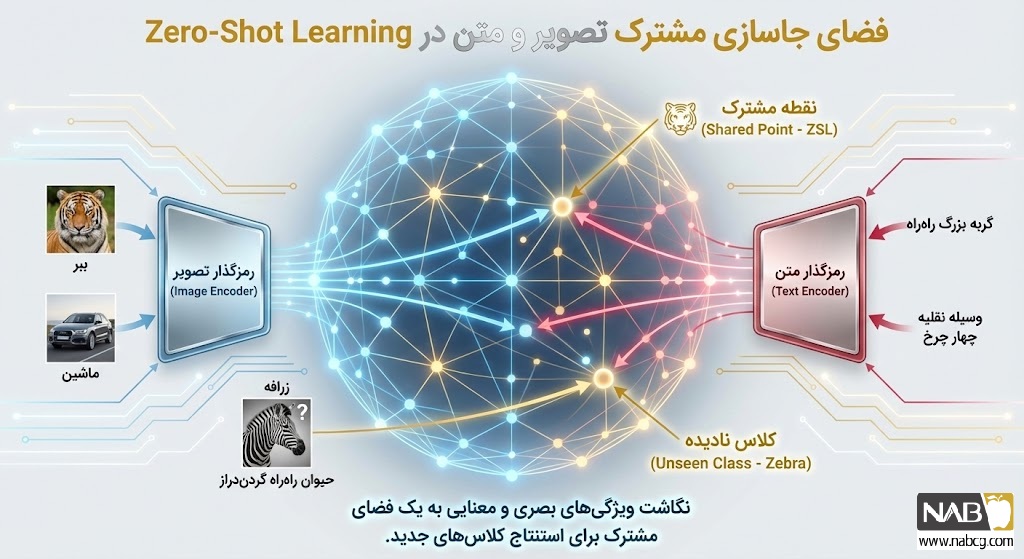
فرآیند عملیاتی ZSL را میتوان در سه گام اصلی خلاصه کرد:
- استخراج ویژگی و فضای معنایی: در مرحله آموزش، مدل با استفاده از شبکههای عصبی پیشآموزشدیده (مانند ResNet برای تصویر یا BERT برای متن)، دادهها را به بردارهای ریاضی تبدیل میکند. این بردارها در یک فضای معنایی قرار میگیرند که در آن کلماتی با معانی مشابه (مثلاً ببر و پلنگ) در فاصله نزدیکی از یکدیگر قرار دارند.
- استفاده از اطلاعات کمکی (Auxiliary Information): از آنجا که نمونهای برای کلاس جدید وجود ندارد، مدل از توصیفات متنی، ویژگیهای فیزیکی (Attributes) یا بردارهای واژگانی استفاده میکند. برای مثال، مدل با یادگیری ویژگی راه-راه بودن از گورخر و زرد بودن از قناری، میتواند مفهوم زنبور را به عنوان یک حشره پرنده زرد و راه-راه استنتاج کند.
- ترازیابی و استنتاج (Inference): در مرحله نهایی، مدل تصویر ورودی ناشناخته را به فضای معنایی منتقل کرده و آن را با توصیفات موجود مقایسه میکند. با استفاده از معیارهای فاصله مانند شباهت کسینوسی (Cosine Similarity) یا فاصله اقلیدسی، نزدیکترین مفهوم متنی به تصویر ورودی به عنوان برچسب نهایی انتخاب میشود.
علاوه بر این، مدلهای مولد مانند GANها و VAEها نیز در این حوزه نقش ایفا میکنند. به این صورت که با استفاده از توصیفات متنی، نمونههای مصنوعی از کلاسهای دیده نشده تولید میکنند تا مسئله را به یک یادگیری نظارتشده استاندارد تبدیل کنند. این رویکرد تعامل میان بینایی ماشین و پردازش زبان طبیعی را به اوج خود میرساند.
6.روشهای پیادهسازی و معماریها در ZSL
الف) روشهای مبتنی بر ویژگی (Attribute-based): بر پایه منطق تجزیهگرا بنا شده است. به جای آموزش مدل روی کل تصویر، طبقهبندها روی ویژگیهای مجزا نظیر رنگ، الگو یا آناتومی آموزش میبینند.
- عملکرد: مدل ویژگی خالدار را از یوزپلنگ و گردن دراز را از شترمرغ میآموزد و سپس زرافه را به عنوان ترکیبی از این صفات شناسایی میکند.
- چالش: این روش به شدت به دقتِ برچسبگذاری دستی وابسته است و در مواجهه با تغییرات ظریفِ گونهها دچار خطا میشود.
.
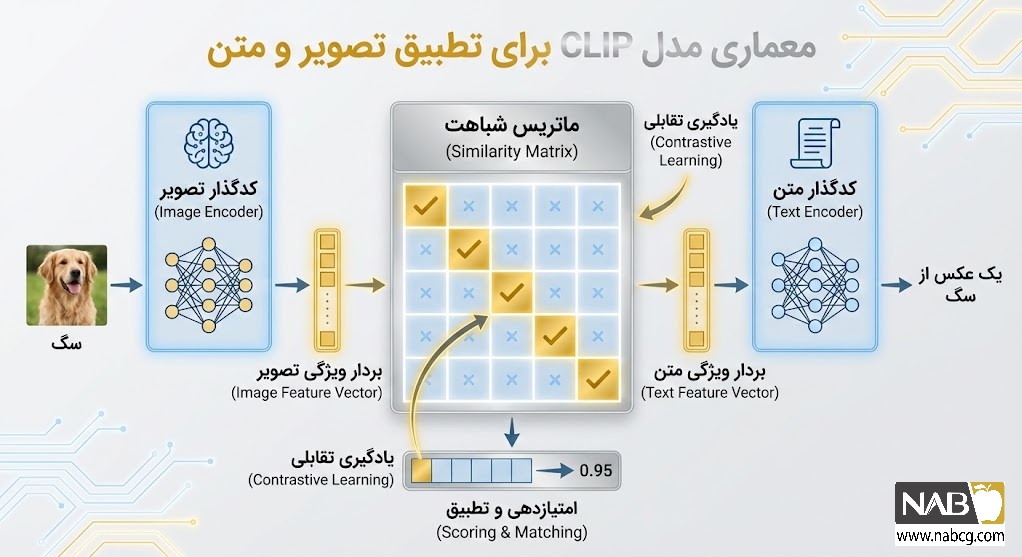
ب) روشهای مبتنی بر جاسازی (Embedding-based): در این پارادایم، تصاویر و مفاهیم متنی به بردارهای ریاضی (Semantic Embeddings) تبدیل میشوند.
- فضای جاسازی مشترک (Joint Embedding Space): کلید موفقیت در این روش، انتقال تصویر و متن به یک زبان ریاضی واحد است. مدلهایی نظیر CLIP با آموزش روی ۴۰۰ میلیون جفت تصویر-متن، فضایی ایجاد کردهاند که در آن بردار تصویری یک موجود با بردار واژگانی آن در یک نقطه منطبق میشوند. تشخیص نهایی با محاسبه میزان شباهت انجام میگردد.
ج) روشهای مبتنی بر مدلهای مولد : این روش با استفاده از هوش مصنوعی مولد، صورتمسئله را تغییر میدهد.
- تولید دادههای مصنوعی: مدل از توصیفات متنی برای تولید نمونههای تصویری خیالی از کلاسهای دیده نشده استفاده میکند. با این کار، مسئله از حالت صفرنمونه به یک یادگیری نظارتشده استاندارد تبدیل میشود
- معماریهای VAE و GAN: مدلهای VAE پایداری بالایی دارند اما خروجی آنها گاهی تار است، در حالی که GANها تصاویری با کیفیت خیرهکننده اما فرآیند آموزشی ناپایدار دارند. ترکیب این دو تحت عنوان VAEGAN، قدرتمندترین ابزار کنونی در این حوزه است.
نقش مدلهای زبانی بزرگ (LLMs): مدلهایی مانند GPT وظیفه تولید توصیفات غنی را بر عهده دارند. این دادههای متنی به عنوان سوخت اصلی به مدلهای بینایی ماشین تزریق میشوند تا دقت استنتاج در محیطهای ناشناخته به حداکثر برسد.
7.چگونگی انتخاب روش مناسب در یادگیری صفرنمونه
انتخاب یک متدولوژی کارآمد در ZSL به نوع دسترسی ما به دادههای جانبی و ماهیت فضای معنایی بستگی دارد. به طور کلی، رویکردهای موجود به دو دسته اصلی تقسیم میشوند:
۱. روشهای مبتنی بر طبقهبند (Classifier-based)
این روشها از استراتژی یکدربرابرهمه (One-versus-Rest) برای آموزش مدل استفاده میکنند. هدف اصلی، ساخت یک طبقهبند برای کلاسهای دیده نشده است. این دسته خود به سه زیرمجموعه تقسیم میشود:
- روشهای تناظری (Correspondence): یادگیری یک تابع نگاشت که بین پروتوتایپ معنایی یک کلاس و طبقهبند باینری آن در فضای ویژگی ارتباط برقرار میکند.
- روشهای رابطهای (Relationship): ساخت طبقهبند برای کلاسهای جدید بر اساس روابط درونی و بینکلاسی. به عنوان مثال، اگر مدل رابطه بین ماشین و کامیون را در فضای معنایی درک کند، میتواند طبقهبند کامیون را بر اساس دانش قبلی خود از ماشین بازسازی کند.
- روشهای ترکیبی (Combination): در این دیدگاه، هر کلاس ترکیبی از عناصر پایه (مانند داشتن دم، خز یا بال) است. مدل با یادگیری طبقهبند برای این عناصر، میتواند هر کلاس جدید را به عنوان ترکیبی از این قطعات شناسایی کند.
.
۲. روشهای مبتنی بر نمونه (Instance-based)
هدف این رویکرد، دستیابی به نمونههای برچسبدار برای کلاسهای ناشناخته و سپس آموزش یک طبقهبند استاندارد روی آنهاست:
- روشهای تصویرسازی (Projection): انتقال هر دو فضای ویژگی و فضای پروتوتایپ معنایی به یک فضای مشترک. در این فضای جدید، پروتوتایپها مانند نمونههای برچسبدار واقعی عمل میکنند.
- روشهای قرضگیری نمونه (Instance-borrowing): استفاده از نمونههای کلاسهای مشابه برای آموزش کلاس جدید. مثلاً برای شناسایی کامیون، مدل از نمونههای اتوبوس و سواری به عنوان دادههای مثبت قرضی استفاده میکند.
- روشهای سنتزکننده (Synthesizing): استفاده از مدلهای مولد برای تولید نمونههای مصنوعی (Pseudo-instances) بر اساس توزیع آماری کلاسهای ناشناخته. این روش امروزه به دلیل قدرت مدلهای مولد، محبوبیت بالایی دارد.
.
8.راهنمای گامبهگام پیادهسازی ZSL
- انتخاب فضای معنایی (Semantic Space): طبق بخش ۴ مقاله ، ما به یک فضای مشترک نیاز داریم. در اینجا از یک Encoder متنی و یک Encoder تصویری استفاده میکنیم که تصاویر و کلمات را به بردارهای ریاضی همبعد تبدیل میکنند.
- تعریف کلاسهای دیده نشده (Unseen Classes): ما از دیتاسیت واقعی CIFAR-10 استفاده میکنیم، اما به جای آموزش مدل روی برچسبها، فقط توصیفات متنی کلاسها را به مدل میدهیم. مدل هرگز این تصاویر را با برچسب در فرآیند آموزش ندیده است (Zero-shot).
- استخراج ویژگی و محاسبه شباهت (Inference): تصویر ورودی به یک بردار تبدیل میشود.
- توصیفات متنی (مثل: “تصویری از یک هواپیما”) نیز به بردار تبدیل میشوند.
- با استفاده از شباهت کسینوسی (Cosine Similarity)، نزدیکترین بردار متنی به بردار تصویر پیدا میشود.
- خروجی و بصریسازی: برای تحلیل دقت، از یک هیتمپ (Heatmap) استفاده میکنیم تا میزان اطمینان مدل به هر کلاس را نمایش دهیم.
کد کامل و بهینه پایتون (با دیتاست واقعی CIFAR-10)
برای اجرای این کد، کتابخانه clip و torch مورد نیاز است.
# Install the clip library first
!pip install git+https://github.com/openai/CLIP.git
import torch
import clip
from PIL import Image
from torchvision.datasets import CIFAR10
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# ۱. تنظیمات اولیه و بارگذاری مدل CLIP
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# ۲. بارگذاری دیتاسیت واقعی (CIFAR-10)
dataset = CIFAR10(root="./data", train=False, download=True)
class_names = dataset.classes
# ۳. آمادهسازی توصیفات متنی (Prompts)
text_descriptions = [f"a photo of a {name}" for name in class_names]
text_tokens = clip.tokenize(text_descriptions).to(device)
# ۴. انتخاب ۵ نمونه تصادفی برای آزمایش
indices = np.random.choice(len(dataset), 5, replace=False)
images = []
labels = []
for idx in indices:
img, label = dataset[idx]
images.append(img)
labels.append(label)
# ۵. اجرای فرآیند استنتاج صفرنمونه
processed_images = torch.stack([preprocess(img) for img in images]).to(device)
with torch.no_grad():
image_features = model.encode_image(processed_images)
text_features = model.encode_text(text_tokens)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices_pred = similarity.topk(1)
# ۶. نمایش نتایج عددی و نمودار هیتمپ
print("\n--- نتایج پیشبینی Zero-Shot ---")
for i in range(5):
print(f"نمونه {i+1}: واقعی = {class_names[labels[i]]} | پیشبینی = {class_names[indices_pred[i]]} | اطمینان = {values[i].item()*100:.2f}%")
plt.figure(figsize=(12, 6))
sns.heatmap(similarity.cpu().numpy(), annot=True, cmap="YlGnBu",
xticklabels=class_names, yticklabels=[f"Image {i+1}" for i in range(5)])
plt.title("Zero-Shot Similarity Heatmap (CLIP Model)", color='crimson', fontsize=14)
plt.xlabel("Semantic Classes")
plt.ylabel("Test Images")
plt.show()
خروجی:
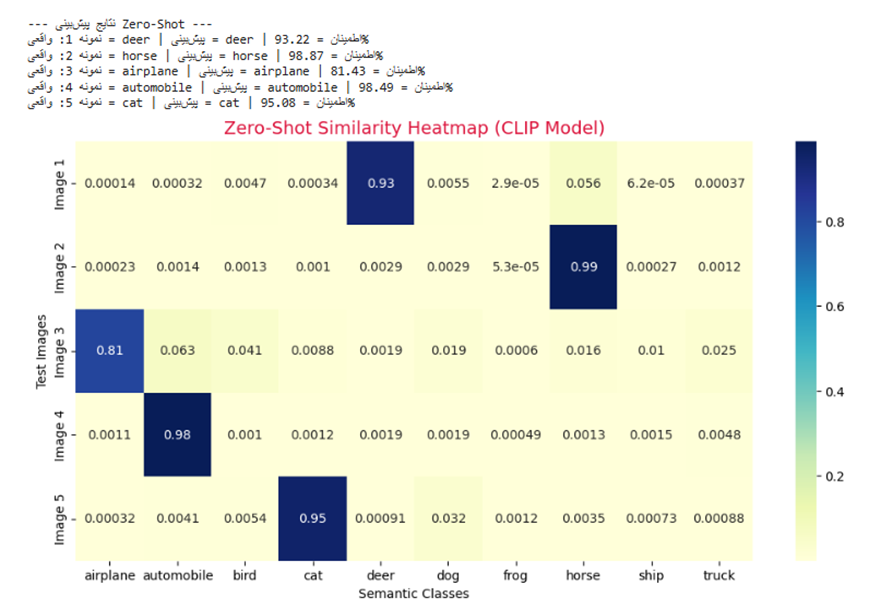
.
9.مزایا و پتانسیلهای یادگیری صفرنمونه
- حذف هزینههای سرسامآور برچسبگذاری: در پروژههای بزرگ، بخش عمدهای از بودجه صرف استخدام نیروی انسانی برای برچسبگذاری دستی میلیونها داده میشود. ZSL با حذف نیاز به نمونههای آموزشی برای کلاسهای جدید، این هزینه را به صفر نزدیک میکند.
- انعطافپذیری و توسعهپذیری آنی: در سیستمهای سنتی، افزودن یک دسته جدید (مثلاً یک محصول جدید در فروشگاه) مستلزم جمعآوری داده و بازآموزی (Retraining) کل مدل است. در ZSL، شما میتوانید تنها با ارائه یک توصیف متنی، کلاس جدید را در لحظه به مدل معرفی کنید.
- کاربرد در سناریوهای نایاب و بحرانی: در حوزههایی مانند پزشکی (بیماریهای نوظهور مانند سویههای جدید ویروسی) یا اخترشناسی (کشف اجرام آسمانی نادیده)، دادهای برای آموزش وجود ندارد. ZSL در اینجا تنها ابزاری است که بر اساس تئوریها و شباهتهای ساختاری، امکان شناسایی را فراهم میکند.
- تعمیمپذیری مشابه هوش انسانی: این مدلها به جای حفظ کردن پیکسلها، مفاهیم را درک میکنند. این مزیت باعث میشود مدل در مواجهه با تغییرات محیطی (مانند تغییر نور یا زاویه در کلاسهای دیده نشده) بسیار هوشمندانهتر و منعطفتر از مدلهای کلاسیک عمل کند.
10.چالشها و محدودیتهای یادگیری صفرنمونه (ZSL)
- نمایش دانش و تفاوتهای ظریف: یکی از جدیترین موانع فنی در مدلهای ZSL، دشواری در بازنمایی تفاوتهای جزئی میان طبقات مشابه است. به عنوان مثال، یک مدل ممکن است در تفکیک پلنگ و یوزپلنگ دچار خطا شود؛ چرا که توصیف متنی هر دو شامل گربه فعال با پوست خالدار است و ویژگیهای متمایزکننده فیزیکی (مانند الگوی خط اشک یا شکل خالها) بهدقت در فضای معنایی ثبت نشدهاند. این مسئله باعث همپوشانی بردارها در فضای ویژگی میشود.
- شکاف دامنه (Domain Gap): زمانی که دادههای جدید تفاوت ساختاری شدیدی با دادههای آموزشی داشته باشند، کارایی مدل به شدت افت میکند. مدلی که روی اشیاء روزمره آموزش دیده، در شناسایی ابزارهای تخصصی جراحی به دلیل تفاوت در توزیع دادهها (از نظر بافت، نورپردازی و شکل)، با چالش جدی روبرو خواهد شد. شکاف میان دادههای دیده شده و دیده نشده پاشنه آشیل مدلهای تعمیمپذیر است.
- سطح دقت و عملکرد: یادگیری صفرنمونه به طور ذاتی دقت پایینتری نسبت به یادگیری نظارتشده (Supervised) دارد. راهکار متعادلکننده برای این چالش، استفاده از رویکرد یادگیری صفرنمونه تعمیمیافته (GZSL) یا ترکیب آن با متدهای تنظیم دقیق (Fine-tuning) روی بخش کوچکی از دادههاست تا ضمن حفظ انعطافپذیری، پایداری خروجی نیز تضمین شود.
- تفسیرپذیری و اخلاق حرفهای: در حوزههای حساسی مانند تشخیص بیماریهای نادر، مدل ممکن است بدون ارائه مستندات عینی، تشخیصی را صادر کند. عدم شفافیت در فرآیند استدلال (Black Box)، اعتماد متخصصان را به خروجی سیستم کاهش میدهد.
- مقیاسپذیری محاسباتی: با افزایش تعداد دستههای جدید، سیستمهای مبتنی بر ZSL ممکن است با کاهش سرعت در بازیابی اطلاعات روبرو شوند. بهینهسازی ساختارهای نمایهسازی (Indexing) برای مدیریت میلیونها محصول در سیستمهای توصیهگر، از ضرورتهای فنی این حوزه است.
.
11.کاربردهای عملیاتی یادگیری صفرنمونه
- پردازش متن و زبان طبیعی (NLP): یادگیری صفرنمونه تحولی بنیادین در طبقهبندی متون ایجاد کرده است. مدلهای مبتنی بر ZSL قادرند محتوا را بدون آموزش قبلی، در دستههای جدید قرار دهند. برای مثال، سیستمهای پایش شبکههای اجتماعی میتوانند محتوای گمراهکننده یا اطلاعات نادرست پزشکی را صرفاً بر اساس تعاریف متنی شناسایی کنند؛ حتی اگر پیش از آن با چنین الگوهایی مواجه نشده باشند.
- بینایی ماشین و بازشناسی بصری: در حوزه تصویر، ZSL با پیوند دادن ویژگیهای بصری به توصیفات متنی، شناسایی اشیاء نادیده را ممکن میسازد. مدلهای پیشرفتهای نظیر CLIP (محصول OpenAI) با تراز کردن فضای ویژگیهای تصویری و متنی، مفاهیم انتزاعی یا گونههای نایاب مانند پاندای قرمز را شناسایی میکنند. این قابلیت در موتورهای جستجوی بصری برای بازیابی دقیق تصاویر بر اساس توصیف کاربر، نقشی حیاتی ایفا میکند.
- پایش محیطزیست و تصاویر ماهوارهای: ZSL در تحلیل دادههای سنجش از دور بدون نیاز به دادههای برچسبدار انبوه، بسیار کارآمد است. به عنوان مثال، سیستمهای نظارتی میتوانند پدیده جنگلزدایی غیرقانونی را با شناسایی الگوهایی که تحت عنوان کاهش محسوس تاج پوشش در مناطق متراکم تعریف شدهاند، تشخیص دهند؛ حتی اگر مدل صراحتاً روی الگوهای خاص تخریب جنگل آموزش ندیده باشد.
- امنیت سایبری و دفاع دیجیتال: شناسایی بدافزارهای روز صفر (Zero-day) که هیچ امضای دیجیتالی ثبت شدهای ندارند، از کاربردهای راهبردی ZSL است. مدل با تحلیل ویژگیهای رفتاری توصیف شده، تهدیدات نوظهور را در لحظه شناسایی و خنثی میکند.
.
مطالعه موردی ۱: دستهبندی خودکار محصولات در تجارت الکترونیک (Zero-Shot Inventory)
در پلتفرمهای بزرگی مانند دیجیکالا یا آمازون، روزانه هزاران محصول جدید با ویژگیهای متنوع اضافه میشوند. چالش اصلی، قرار دادن این محصولات در دستهبندیهای دقیق است. بدون اینکه مدل قبلاً برای این دستههای خاص آموزش دیده باشد.
مراحل اجرای گامبهگام:
- تعریف فضای ویژگی محصول: به جای برچسب عددی، ویژگیهای متنی محصول را به بردار تبدیل میکنیم.
- استفاده از مدل CLIP: از معماری متقاطع متن-تصویر برای تراز کردن عکس محصول با دستهبندیهای جدید استفاده میشود.
- تزریق دانش کمکی: توصیف دقیق هر دسته به مدل داده میشود تا حتی اگر نام دسته را نداند. از طریق ویژگیها آن را شناسایی کند.
- تصمیمگیری (Inference): مدل تصویر محصول را با تمام دستههای تعریف شده مقایسه کرده و بالاترین شباهت کسینوسی را انتخاب میکند.
کد کامل و بهینه پایتون (E-commerce Case Study):
# Install clip if not present
!pip install git+https://github.com/openai/CLIP.git
import torch
import clip
from PIL import Image
import requests
from io import BytesIO
import matplotlib.pyplot as plt
import numpy as np
# ۱. بارگذاری مدل و تنظیمات
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# ۲. تعریف محصولات جدید
categories = ["Eco-friendly kitchenware", "High-tech wearable", "Vintage leather accessory", "Handmade organic soap"]
text_inputs = clip.tokenize(categories).to(device)
# ۳. دریافت تصویر با مدیریت خطا
url = "https://github.com/openai/CLIP/blob/main/tests/test_images/remote_control.png?raw=true"
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
image_input = Image.open(BytesIO(response.content))
except Exception as e:
print(f"خطا در دریافت تصویر: {e}. استفاده از تصویر تصادفی...")
# ایجاد یک تصویر تصادفی به عنوان جایگزین در صورت خطا
image_input = Image.fromarray(np.uint8(np.random.randint(0, 255, (224, 224, 3))))
image = preprocess(image_input).unsqueeze(0).to(device)
# ۴. پردازش و محاسبه شباهت
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text_inputs)
logits_per_image, _ = model(image, text_inputs)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
# ۵. خروجی بصری
plt.figure(figsize=(10, 5))
plt.barh(categories, probs[0], color='#FFD700')
plt.title("Product Classification Confidence (Zero-Shot)", fontsize=14)
plt.xlabel("Probability")
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.show()
print(f"نتیجه نهایی: محصول به دسته '{categories[probs.argmax()]}' تعلق دارد.")
خروجی:
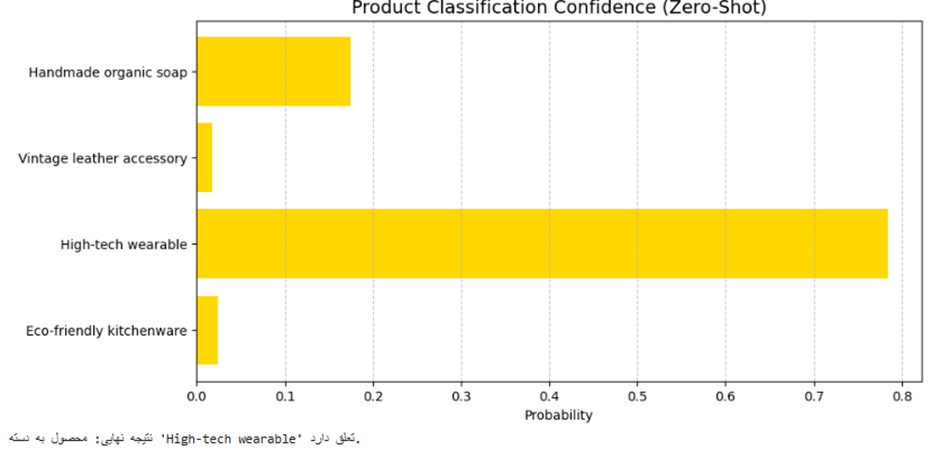
.
مطالعه موردی ۲: پایش هوشمند ایمنی در محیطهای صنعتی (HSE Monitoring)
در کارخانجات، حفظ ایمنی کارگران حیاتی است. اما تعریف تمام موقعیتهای خطرناک برای هوش مصنوعی غیرممکن است. ZSL اجازه میدهد با دادن یک دستورالعمل متنی، مدل بلافاصله آن وضعیت را شناسایی کند.
مراحل اجرای گامبهگام:
- تحلیل سناریوی خطر: تعریف خطرات به صورت جملات توصیفی (Semantic Descriptions).
- پایش بلادرنگ (Real-time Stream): فریمهای ویدئویی به فضای جاسازی مشترک منتقل میشوند.
- تطبیق ویژگیهای بصری با پروتکلها: مدل بررسی میکند آیا ویژگیهای بصری فرد (لباس، موقعیت) با توصیف “عدم رعایت ایمنی” انطباق دارد یا خیر.
- هشدار خودکار: در صورت عبور شباهت از یک آستانه (Threshold) مشخص، سیستم هشدار صادر میکند.
کد کامل و بهینه پایتون (Industrial Safety Case Study):
import torch
import clip
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# ۱. بارگذاری مدل
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# ۲. تعریف سناریوهای ایمنی (بدون آموزش قبلی)
safety_scenarios = [
"A worker wearing a safety helmet",
"A worker NOT wearing a helmet",
"Person walking in restricted zone",
"Safe working environment"
]
text_tokens = clip.tokenize(safety_scenarios).to(device)
# ۳. شبیهسازی تصویر ورودی از محیط کار (استفاده از یک تصویر رندوم برای تست)
# در محیط واقعی اینجا ورودی دوربین (OpenCV) قرار میگیرد
dummy_image = np.random.randint(0, 255, (224, 224, 3), dtype=np.uint8)
image_input = preprocess(Image.fromarray(dummy_image)).unsqueeze(0).to(device)
# ۴. استنتاج و تشخیص خطر
with torch.no_grad():
logits_per_image, _ = model(image_input, text_tokens)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()[0]
# ۵. خروجی عددی و بصری
# ایجاد یک نمودار دایرهای برای نمایش وضعیت ایمنی
colors = ['#4CAF50', '#8B0000', '#FF8C00', '#ADD8E6'] # سبز برای ایمن، قرمز برای خطر
plt.figure(figsize=(8, 8))
plt.pie(probs, labels=safety_scenarios, autopct='%1.1f%%', colors=colors, startangle=140)
plt.title("Industrial Safety Real-time Analysis (Zero-Shot)", color='navy')
plt.show()
# سیستم هشدار
if probs[1] > 0.5 or probs[2] > 0.5:
print("⚠️ هشدار بحرانی: نقض قوانین ایمنی شناسایی شد!")
else:
print("✅ وضعیت محیط کار: ایمن")
خروجی:
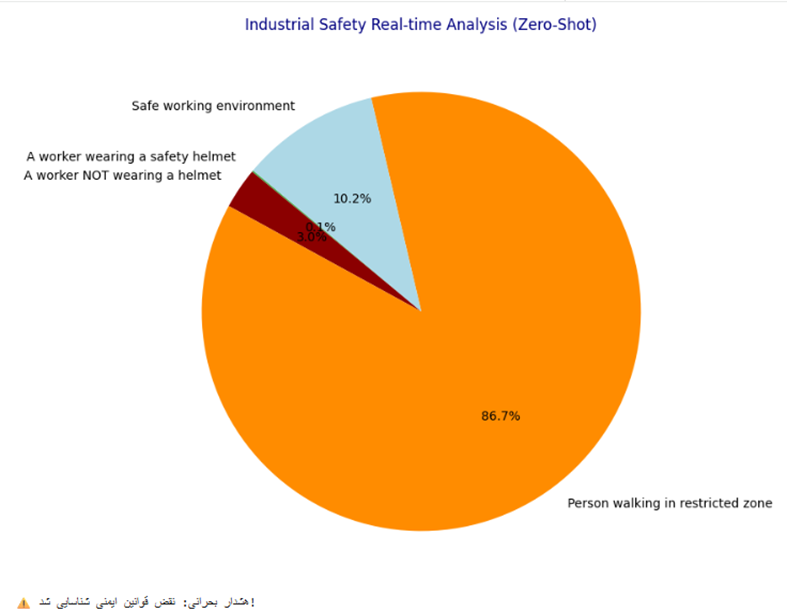
.
جمع بندی
یادگیری صفرنمونه گامی مهم در جهت ساخت سیستمهای هوشمند تعمیمپذیر و مستقل از دادههای برچسبدار گسترده است. همانطور که دیدیم، این رویکرد با انتقال دانش از کلاسهای دیدهشده به کلاسهای دیدهنشده و استفاده از یک فضای معنایی مشترک، امکان شناسایی مفاهیم جدید را بدون آموزش مستقیم فراهم میکند. روشهای مبتنی بر ویژگی، جاسازی مشترک و مدلهای مولد هر یک مسیر متفاوتی برای تحقق این هدف ارائه میدهند .
با وجود مزایای چشمگیر، ZSL با چالشهایی مانند شکاف دامنه، همپوشانی بردارهای معنایی، کاهش دقت نسبت به یادگیری نظارتشده و مسئله تفسیرپذیری مواجه است. رویکردهایی مانند یادگیری صفرنمونه تعمیمیافته (GZSL)، ترکیب با تنظیم دقیق محدود (Fine-tuning) و استفاده از مدلهای چندوجهی قدرتمند مانند CLIP میتوانند بخشی از این محدودیتها را کاهش دهند.
در حوزههایی که داده کمیاب، پرهزینه یا در حال تغییر است.از تجارت الکترونیک و امنیت سایبری گرفته تا پایش محیطهای صنعتی،یادگیری صفرنمونه نهتنها یک مزیت رقابتی، بلکه یک ضرورت عملیاتی محسوب میشود. حرکت به سمت مدلهایی که بتوانند مفاهیم جدید را صرفاً از طریق توصیف درک کنند، گامی مهم در مسیر توسعه هوش مصنوعی انعطافپذیر، مقیاسپذیر و سازگار با دنیای پویا است.