

۱. مقدمه
در دهههای اخیر، پیشرفتهای چشمگیر در یادگیری ماشین عمدتاً بر پایه کشف الگوهای آماری و همبستگیهای دادهمحور شکل گرفته است. این رویکردها توانستهاند در پیشبینی، طبقهبندی و تحلیل دادههای بزرگ عملکردی خیرهکننده ارائه دهند؛ اما یک محدودیت بنیادین همچنان پابرجاست: مدلهای سنتی نمیدانند «چرا» یک رویداد رخ میدهد، بلکه تنها میدانند «چه زمانی» احتمال وقوع آن بالاست. این وابستگی به همبستگیهای آماری، سیستمهای هوشمند را در برابر تغییر توزیع دادهها (Distribution Shift)، دادههای خارج از نمونه (Out-of-Distribution) و تصمیمگیریهای حساس آسیبپذیر میکند.
یادگیری علّی (Causal Learning) پاسخی به این خلأ ساختاری است. این پارادایم، تمرکز را از مشاهده صرف به استدلال درباره سازوکار تولید داده منتقل میکند و ماشین را قادر میسازد اثر واقعی مداخلات را تحلیل کند. به بیان دیگر، به جای پرسیدن «اگر X را ببینیم، Y چقدر محتمل است؟» میپرسیم «اگر X را عمداً تغییر دهیم، چه بر سر Y خواهد آمد؟» این تغییر ظاهراً ساده، جهشی بنیادین در توان استدلال سیستمهای هوش مصنوعی ایجاد میکند و آنها را از سطح پیشبینی به سطح تصمیمسازی مبتنی بر علت و معلول ارتقا میدهد.
در این مقاله، ابتدا مفاهیم پایه علیت و تفاوت آن با همبستگی را بررسی میکنیم، سپس چارچوبهایی مانند مدلهای ساختاری علّی (SCM)، گرافهای جهتدار بدون دور (DAG) و عملگر مداخلهای do را معرفی میکنیم. در ادامه، تکنیکها و الگوریتمهای پیشرفته، پیادهسازی عملی و کاربردهای صنعتی این رویکرد تحلیل خواهند شد.
۲. تعریف یادگیری علّی (Causal Learning)
یادگیری علّی شاخهای پیشرفته از هوش مصنوعی است که هدف آن کشف و مدلسازی روابط علت و معلولی میان متغیرهاست. در این معماری، مدل به جای یادگیری صرفِ الگوهای مشاهدهشده، به دنبال شناسایی تأثیر واقعی مداخلات (Interventions) و درک مکانیزمهای پنهان دادهها است. این سیستمها به پرسشهای تحلیلی نظیر اگر یک متغیر را تعمداً تغییر دهیم، چه پیامدی خواهد داشت؟ یا اگر در گذشته تصمیم متفاوتی اتخاذ میشد، خروجی چگونه تغییر میکرد؟ پاسخ میدهند.
برای دستیابی به این سطح از استدلال، یادگیری علّی از ابزارهای ریاضی و منطقی زیر بهره میبرد:
- مدلهای ساختاری علّی (SCM): برای تعیین نحوه تولید دادهها.
- نمودارهای گرافی جهتدار (DAG): برای نمایش بصری و ریاضیاتی وابستگیهای متغیرها.
- عملگر مداخلهای (do-operator): برای جداسازی اثر خالص یک عامل از تأثیر متغیرهای مخدوشکننده (Confounders).
.
3.اهداف استراتژیک یادگیری ماشین علّی
توسعه مدلهای مبتنی بر یادگیری علّی، اهداف زیرساختی زیر را در سیستمهای هوش مصنوعی دنبال میکند:
- تمرکز بر ویژگیهای علّی و پایداری (Robustness): این مدلها با تکیه بر محرکهای علت و معلولی، دقت و پایداری سیستم را حتی در شرایط تغییر توزیع دادهها (Data Shifts) حفظ کرده و ارتقا میدهند.
- تحلیل سناریوهای ضدِواقع (What-If Scenarios): این معماری امکان شبیهسازی مداخلات و استدلال پیرامون نتایج جایگزین را پیش از اجرای فیزیکی فراهم میسازد.
- تولید بینشهای عملیاتی (Actionable Insights): ارائه راهکارهای مبتنی بر شواهد برای تصمیمسازی در حوزههای حساس نظیر بهداشت و درمان، اقتصاد، بازاریابی و سیاستگذاری کلان.
- ارتقای اعتماد و شفافیت (Trust and Transparency): با استوار کردن پیشبینیها بر پایه منطق علت و معلول (به جای همبستگیِ صرف)، سطح شفافیت مدلهای هوش مصنوعی افزایش یافته و مشکل «جعبه سیاه» برطرف میشود.
.
4. تفاوت بنیادین همبستگی (Correlation) و علیت (Causation)
در علم داده، همرخدادی دو پدیده لزوماً به معنای وجود رابطه علت و معلولی میان آنها نیست.
- همبستگی (Correlation): رشد قد کودکان با افزایش دایره لغات آنها همزمان است (حرکت موازی دو متغیر).
- علیت (Causation): افزایش قد، عامل ایجاد دایره لغات نیست؛ بلکه متغیر سومی به نام افزایش سن، علت مشترک (Common Cause) هر دو پدیده است.
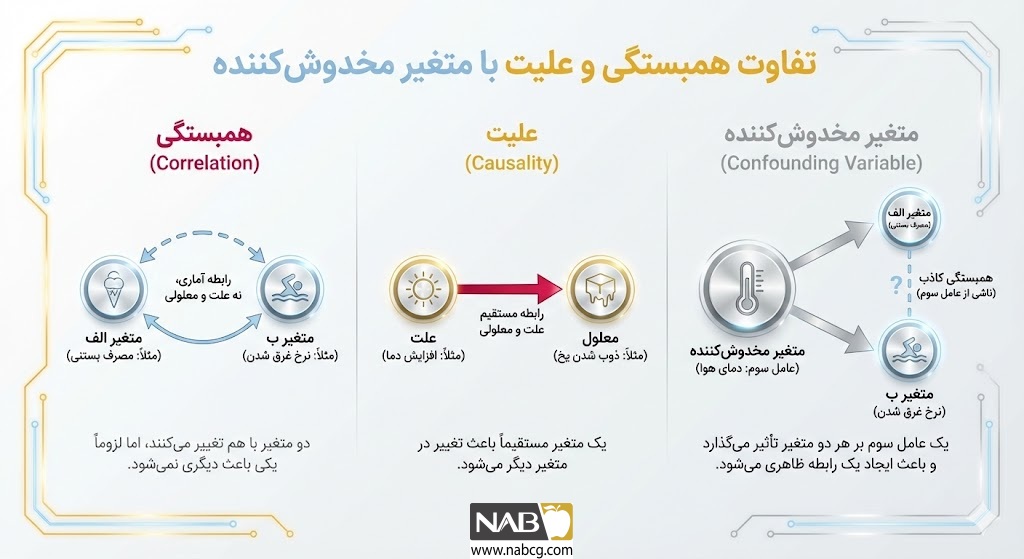
تفاوت در فرمولبندی ریاضی:
- در همبستگی آماری، احتمال شرطی به صورت P(Y | X) نمایش داده میشود (احتمال مشاهده Y به شرط دیدن X).
- در علیت، از عملگر مداخله استفاده میشود: P(Y | do(X))؛ به این معنا که اگر متغیر X به صورت تعمدی و سیستماتیک تغییر کند، تغییرات متغیر Y چقدر خواهد بود.
.
5. نردبان علیت (The Ladder of Causation): از مشاهده تا تخیل
پروفسور جودیا پرل (Judea Pearl) برای طبقهبندی سطح استدلال در سیستمهای هوشمند، چارچوبی تحت عنوان نردبان علیت طراحی کرده است که شامل سه سطح پردازشی است:
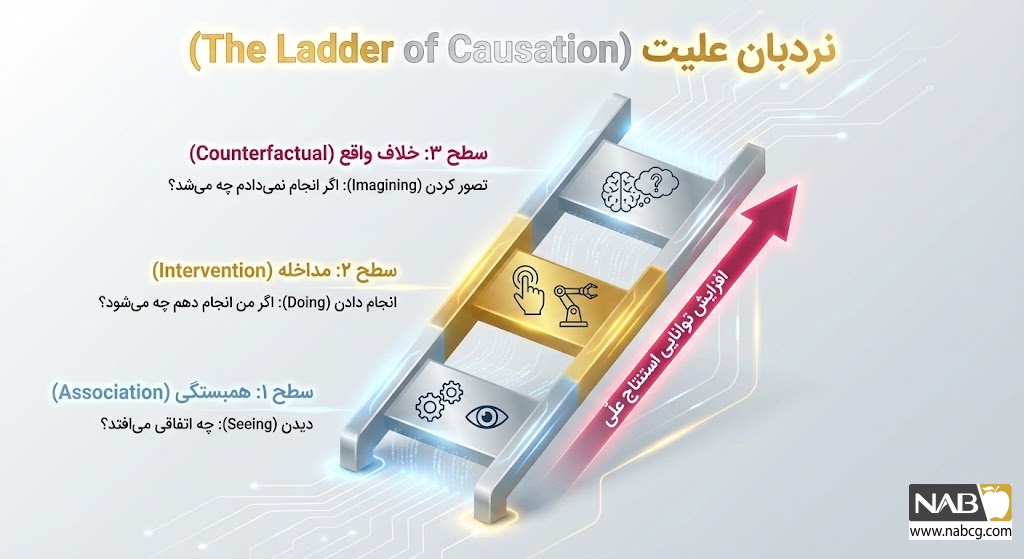
الف.پله اول: مشاهده و ارتباطیابی (Association)
- منطق پردازشی: اگر متغیر A مشاهده شود، چه اطلاعاتی درباره متغیر B به دست میآید؟
- مثال کاربردی: سیستمهای توصیهگر تشخیص میدهند خریداران لپتاپ، معمولاً کیف لپتاپ نیز تهیه میکنند.
- محدودیت: این سطح تنها الگوها را ردیابی میکند و توان پیشبینی اثر تغییرات متغیرها (مانند تغییر قیمت لپتاپ بر حجم فروش کیف) را ندارد.
.
ب. پله دوم: اقدام و مداخله (Intervention)
- منطق پردازشی: اگر متغیر A به صورت تعمدی تغییر داده شود، چه تأثیری بر متغیر B خواهد داشت؟
- مثال کاربردی: شبیهسازی تأثیر کاهش ۱۰ درصدی قیمت محصول بر حاشیه سود نهایی.
- اهمیت فنی: شبکههای عصبی علّی پیشرفته (نظیر CCNets) در این سطح وارد عمل میشوند تا پیامدهای یک تصمیم را پیش از اجرای فیزیکی و صرف هزینه، مدلسازی کنند.
.
ج.پله سوم: استدلال ضدِواقع (Counterfactuals)
- منطق پردازشی: اگر در گذشته تصمیم متفاوتی اتخاذ میشد، وضعیت فعلی خروجی چگونه بود؟
- مثال کاربردی: در یک سناریوی تحلیل پزشکی، بررسی اینکه اگر اکسیژنرسانی ۳۰ دقیقه زودتر انجام میشد، آیا تغییر در نتیجه نهایی (زنده ماندن بیمار) حاصل میگردید؟
- اهمیت فنی: این پله بالاترین درجه از استدلال در هوش مصنوعی است و پیادهسازی آن برای سیستمهای تصمیمساز حیاتی (Mission-critical) نظیر جراحی رباتیک و کنترلرهای صنعتی، الزامی است.
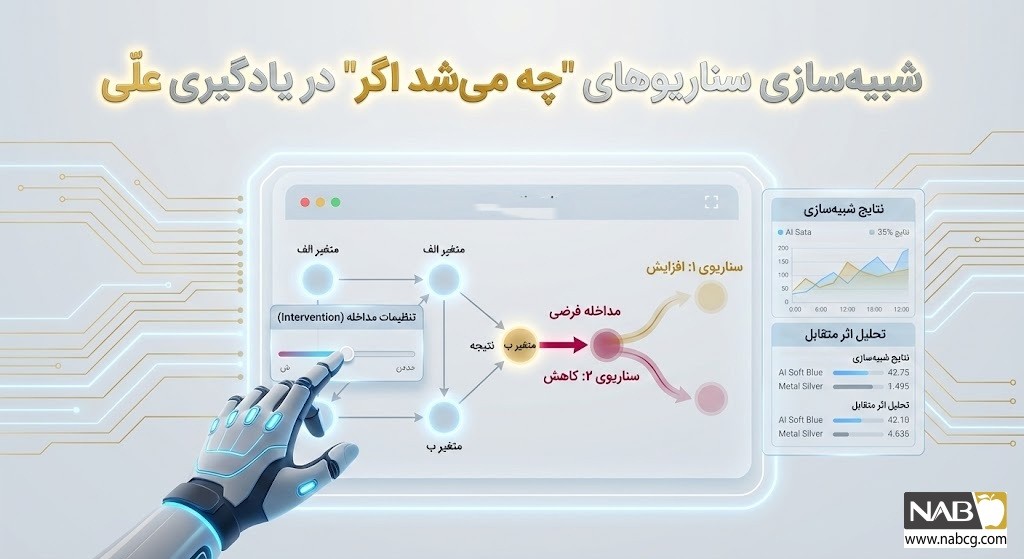
6. مکانیزم عملکرد: یادگیری علّی چگونه کار میکند؟
یادگیری علّی بر یک چارچوب ریاضیِ ساختاریافته بنا شده است که به جای تمرکز بر توزیع دادههای مشاهدهشده، بر فرآیند تولید داده (Data-Generating Process) تمرکز دارد. عملیاتیسازی این پارادایم در سیستمهای هوش مصنوعی شامل سه گام بنیادین است:
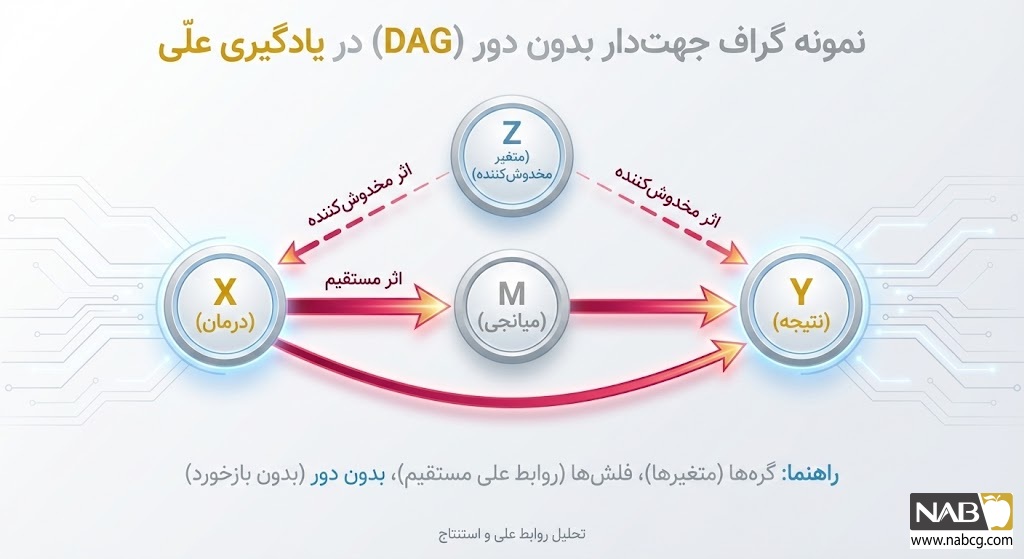
گام اول: مدلسازی ساختاری با گرافهای جهتدار (DAG)
پیش از هرگونه محاسبه، سیستم باید فرضیات علّی پیرامون محیط را درک کند. این کار با استفاده از نمودارهای جهتدار بدون دور (Directed Acyclic Graphs – DAG) انجام میشود. در این گرافها، گرهها (Nodes) نشاندهنده متغیرها و یالهای جهتدار (Edges) نشاندهنده مسیر و جهتِ اثر علّی هستند. گراف DAG به ماشین میفهماند که اطلاعات چگونه در سیستم جریان دارد و کدام متغیر، علتِ متغیر دیگر است.
گام دوم: مداخله و عملگرِ “do” (The do-Calculus)
هسته مرکزی یادگیری علّی، توانایی شبیهسازی مداخلات است. در آمار کلاسیک، ما احتمال شرطی P(Y|X) را محاسبه میکنیم (احتمال مشاهده Y وقتی متوجه میشویم X رخ داده است). اما در یادگیری علّی، ماشین از عملگر مداخله (do-operator) استفاده میکند تا اثر تغییرِ تعمدی را بسنجد.
فرمول مداخله:
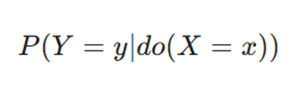
معرفی متغیرها:
- Y: متغیر هدف یا پیامد – (Outcome) مثلاً میزان فروش.
- X: متغیر مداخله یا درمان – (Treatment) مثلاً قیمتگذاری محصول.
- do(X=x): عملگر ریاضی که نشان میدهد متغیر X به صورت فیزیکی یا شبیهسازیشده روی مقدار x تنظیم شده است (قطع ارتباط X با علل طبیعیِ گذشتهاش).
.
گام سوم: کنترل مخدوشکنندهها (Backdoor Adjustment)
بزرگترین چالش در استخراج علیت از دادههای مشاهدهای، وجود متغیرهای مخدوشکننده (Confounders) است؛ عواملی که همزمان بر علت و معلول تأثیر میگذارند و باعث ایجاد یک همبستگی کاذب میشوند.
برای جداسازی اثر واقعی X بر Y، سیستم از معیار مسیرِ پشتی (Backdoor Criterion) استفاده میکند تا اثر متغیرهای مخدوشکننده را مسدود (Block) کند.
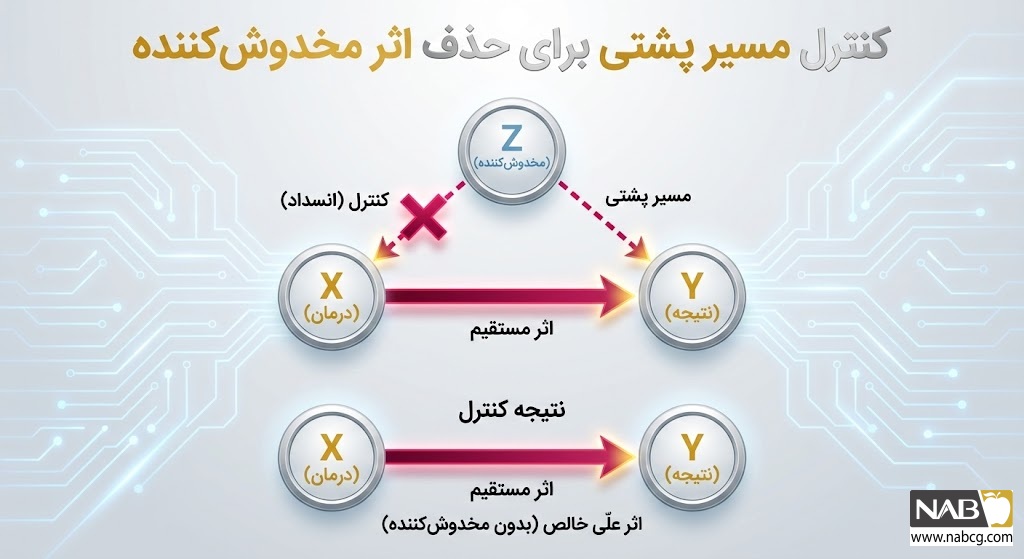
فرمول تعدیل مسیر پشتی (Backdoor Adjustment Formula):
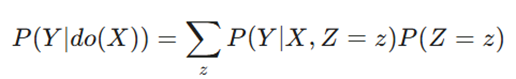
معرفی متغیرها:
- P(Y | do(X)): توزیع احتمال علّی (اثر خالص و واقعی X بر Y).
- Z: مجموعهای از متغیرهای مخدوشکننده (Confounders) که باید کنترل شوند (مثلاً وضعیت اقتصادی مشتری).
- P(Y | X, Z=z): احتمال مشاهده Y به شرطی که X را انجام دهیم و متغیر مخدوشکننده Z برابر با مقدار خاصِ z باشد.
- P(Z=z): احتمال یا وزنِ رخ دادن متغیر مخدوشکننده در کل جامعه.
تحلیل فرمول: این معادله به هوش مصنوعی اجازه میدهد تا اثر علّی را مستقیماً از روی دادههای تاریخی (بدون نیاز به انجام تستهای فیزیکی گرانقیمت مانند A/B Testing) محاسبه کند، مشروط بر اینکه تمام متغیرهای مخدوشکننده (Z) شناسایی و اندازهگیری شده باشند.
7.تکنیکهای کلیدی در یادگیری ماشین علّی
یادگیری ماشین علّی بر پایه چندین تکنیک بنیادین بنا شده است که منطق استدلال علّی را با مدلسازی پیشبینانه ترکیب میکنند:
- یادگیری نظارتشده علّی (Causal Supervised Learning): این تکنیک بر آموزش مدلهای پیشبینیکنندهای تمرکز دارد که به جای تکیه بر همبستگیهای کاذب (Spurious Correlations)، بر ویژگیهای علّیِ واقعی استوار هستند. این رویکرد تعمیمپذیری (Generalization) مدل را در توزیعهای مختلف داده تضمین میکند.
- تولید دادههای علّی (Causal Data Generation): فرآیند ایجاد دادههای مصنوعی (Synthetic Data) که دقیقاً با ساختارهای علّیِ سیستم همسو هستند. این تکنیک، زیرساخت لازم برای شبیهسازی مداخلات و ارزیابی سناریوهای ضدِواقع را فراهم میکند.
- توضیحات علّی (Causal Explanations): ارائه بینشهای قابل تفسیر از پیشبینیهای مدل، از طریق تشریح دقیق این موضوع که چگونه تغییر در متغیرهای خاص، خروجیهای نهایی را دستخوش تغییر میکند.
- انصاف علّی (Causal Fairness): تضمین عدم سوگیری (Bias) مدل نسبت به ویژگیهای حساس مانند جنسیت یا نژاد. این تکنیک با استفاده از گرافهای علّی (Causal Graphs)، مسیرهای تبعیضآمیز در دادهها را شناسایی کرده و آنها را مسدود میسازد تا پیشبینیها کاملاً بیطرفانه باقی بمانند.
- یادگیری تقویتی علّی (Causal Reinforcement Learning): ادغام منطق استدلال علّی در عاملهای یادگیری تقویتی (RL Agents). این تلفیق منجر به بهبود روند یادگیری سیاستها (Policy Learning)، افزایش تعمیمپذیری در محیطهای جدید و ارتقای چشمگیر بهرهوری نمونهها (Sample Efficiency) میشود.
.
8. رویکردها و الگوریتمهای پیشرفته در یادگیری ماشین علّی
برای تخمین دقیق روابط علت و معلولی و کاهش سوگیری، از الگوریتمهای زیر استفاده میشود:
تخمین حداکثر احتمال هدفمند (TMLE)
الگوریتم TMLE روشی انعطافپذیر است که مشخصات خود را با دادهها تطبیق میدهد. این رویکرد دو گام دارد:
- گام اول (تخمین پیامد و ضدِواقع): با استفاده از دادههای مداخله (Treatment) و متغیرهای کمکی (Covariates)، پیامدها پیشبینی میشوند. در این مرحله، سناریوهای ضدِواقع (Counterfactuals) شبیهسازی میشوند؛ یعنی خروجی یک فردِ تحت درمان در حالتِ عدم دریافت درمان تخمین زده میشود.
- گام دوم (محاسبه امتیاز تمایل): مدل، امتیاز تمایل (Propensity Score) را محاسبه کرده و از طریق گام هدفگذاری (Targeting)، وزنهایی برای بهروزرسانی پیشبینیها و حذف سوگیری اعمال میکند.
.
وزندهی معکوس احتمال تقویتشده (AIPW)
متد AIPW تکنیکی با پایداری دوگانه برای محاسبه میانگین اثر مداخله (ATE) است که از ترکیب رگرسیون پیامد و وزندهی امتیاز تمایل استفاده میکند.
- تفاوت با TMLE: این روش فاقد گام هدفگذاری تکرارشونده است.
- مکانیزم عملکرد: پس از محاسبه مدلهای امتیاز تمایل و پیامد، هر مشاهده بر اساس معکوسِ احتمال درمان وزندهی میشود.
- شبیهسازی کارآزمایی تصادفی: هدف AIPW ایجاد یک جمعیت کاذب است تا دادههای مشاهدهای را به مجموعهدادهای ساختاریافته، مشابه کارآزمایی بالینی تصادفیسازیشده (RCT) تبدیل کند.
.
یادگیری ماشین دوگانه(DML)
الگوریتم DML چارچوبی است که پارامترهایی نظیر ATE را بدون تداخلِ سوگیری منظمسازی (Regularization Bias) تخمین میزند.
- چالش مدلهای سنتی: الگوریتمهای کلاسیک صرفاً برای دقت پیشبینی بهینهسازی شدهاند و کاربرد مستقیم آنها در فرمولهای علّی باعث سوگیری میشود.
- راهکار DML: با ایجاد تابع امتیاز متعامد (Orthogonal Score Function) و آموزش همزمان دو مدل مجزا (پیامد اصلی و مدل کمکی برای مخدوشکنندهها)، سوگیری خنثی میگردد.
- تکنیک برازش متقاطع (Cross-fitting): برای جلوگیری از بیشبرازش (Overfitting)، دادهها به دو بخش تقسیم میشوند؛ یک بخش برای آموزش و بخش دیگر برای تخمین اثر علّی.
.
9. تشریح گامبهگام پیادهسازی
- تولید دادههای شبیهسازی شده: در این مرحله، سه مجموعه داده ایجاد میکنیم. ما عمداً دادهها را به گونهای میسازیم که بهرهوری (Score) هم تحت تأثیر تجربه و هم تحت تأثیر شرکت در دوره باشد. ضریب آموزشی را برابر ۲.۰ قرار میدهیم تا بدانیم خروجی نهایی مدلِ ما باید چه عددی باشد.
- تعریف مدل علّی (Modeling): در اینجا به کمک کلاس CausalModel، صراحتاً به مدل میگوییم که چه چیزی علت (Treatment)، چه چیزی معلول (Outcome) و چه چیزی متغیر مخدوشکننده (Common Causes) است. این تفکیک به پایتون کمک میکند تا اثر «تجربه» را از «آموزش» جدا کند.
- شناسایی اثر علّی (Identification): در این مرحله، مدل با بررسی گراف علّی تعیین میکند که آیا با این شرایط اصلاً میتوان اثر را محاسبه کرد یا خیر. DoWhy از الگوریتمهای گرافیکی استفاده میکند تا مطمئن شود مسیر پنهانی (Backdoor) برای ایجاد سوگیری وجود ندارد.
- تخمین عدد نهایی (Estimation): در این بخش، ریاضیات وارد عمل میشود. با استفاده از روش رگرسیون خطی (backdoor.linear_regression)، مقدار واقعی اثر محاسبه میگردد. اگر از یک رگرسیون معمولی استفاده میکردیم، سیستم اثر تجربه را به پای آموزش مینوشت و عدد اشتباهی گزارش میداد.
- اعتبارسنجی و چالش مدل (Refutation): در این مرحله نهایی، پایداری مدل به چالش کشیده میشود. الگوریتم با افزودن یک متغیر مخدوشکننده تصادفی (random_common_cause)، سیستم را تست میکند تا مشخص شود آیا خروجی مدل در برابر نویز و متغیرهای بیربط مقاوم است، یا عدد تخمینزدهشده تغییر میکند. این گام تضمینکننده اعتبار علمی نتایج است.
کد پایتون:
import numpy as np
import pandas as pd
import logging
from dowhy import CausalModel
# غیرفعال کردن پیامهای اضافی برای وضوح خروجی
logging.getLogger("dowhy").setLevel(logging.ERROR)
print("--- گام ۱: تولید دادههای شبیهسازی شده ---")
np.random.seed(42) # برای تکرارپذیری
n_samples = 1000 # [cite: 639]
# تجربه قبلی (متغیر مخدوشکننده) [cite: 640]
experience = np.random.normal(size=n_samples)
# شرکت در دوره (متغیر مداخله) - افراد با تجربه تمایل بیشتری به آموزش دارند [cite: 641]
# نگهداشتن به صورت Boolean برای سازگاری بهتر با کتابخانه
training = (experience + np.random.normal(size=n_samples)) > 0
# بهرهوری (متغیر هدف) - اثر آموزش دقیقاً 2.0 تنظیم شده است [cite: 643]
score = 0.5 * experience + 2.0 * training + np.random.normal(size=n_samples)
df = pd.DataFrame({
'Experience': experience, # [cite: 645]
'Training': training, # [cite: 646]
'Score': score # [cite: 647]
})
print("--- گام ۲: تعریف مدل علّی (Modeling) ---")
# مشخص کردن علت، معلول و مخدوشکننده برای مدل
# قرار دادن نام متغیرها در لیست برای جلوگیری از خطاهای نسخه جدید DoWhy
model = CausalModel(
data=df,
treatment=['Training'],
outcome=['Score'],
common_causes=['Experience']
)
print("--- گام ۳: شناسایی اثر (Identification) ---")
# بررسی وجود مسیرهای پنهان (Backdoor)
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print("--- گام ۴: تخمین اثر (Estimation) ---")
# محاسبه اثر علّی با استفاده از رگرسیون خطی
estimate = model.estimate_effect(
identified_estimand,
method_name="backdoor.linear_regression"
)
print(f"\n✅ مقدار اثر تخمینی دوره آموزشی بر بهرهوری: {estimate.value:.4f}")
print("(توجه: عدد استخراج شده باید بسیار نزدیک به 2.0 باشد)")
print("\n--- گام ۵: اعتبارسنجی مدل (Refutation) ---")
# تست پایداری مدل با افزودن یک مخدوشکننده تصادفی بیاثر
try:
refute_results = model.refute_estimate(
identified_estimand,
estimate,
method_name="random_common_cause"
)
print("نتایج چالش:")
print(refute_results)
except Exception as e:
print(f"خطا در اعتبارسنجی: {e}")
input("\nبرای خروج کلید Enter را فشار دهید...")
خروجی:

.
10.کاربردهای یادگیری علّی در صنعت
یادگیری علّی با عبور از محدودیتهای سنتی همبستگی آماری، امکان تصمیمگیریهای هوشمندانه و مبتنی بر شواهد قطعی را در حوزههای متنوع صنعتی فراهم میآورد. این فناوری، هوش مصنوعی را از یک پیشبینِ منفعل به یک تصمیمسازِ فعال تبدیل میکند. مهمترین کاربردهای عملی این پارادایم در مقیاس کلان عبارتند از:
- تصمیمگیری در بازاریابی (Marketing Decision Making): این رویکرد به ارزیابی تأثیر واقعی و خالص کمپینهای تبلیغاتی بر میزان تعامل و وفاداری مشتریان کمک میکند. کسبوکارها میتوانند با استفاده از مدلسازی اثرات افزایشی (Uplift Modeling)، استراتژیهای بازاریابی خود را منحصراً بر اساس اقداماتی که دارای اثر علّی اثباتشده هستند، بهینهسازی کنند. این امر مانع از هدررفت بودجه برای مشتریانی میشود که در هر صورت خرید خود را انجام میدادند و نرخ بازگشت سرمایه (ROI) را به حداکثر میرساند.
- بهینهسازی فرآیندهای عملیاتی (Operational Process Optimization): مدلهای علّی در شناسایی ناکارآمدیهای پنهان در خطوط تولید، شبکههای لجستیک و سیستمهای خدماتی بسیار کارآمد هستند. این الگوریتمها از طریق کشف روابط علت و معلولیِ پیچیدهای که محرک واقعی عملکرد سیستم محسوب میشوند، گلوگاههای عملیاتی را پیش از وقوع بحران تشخیص میدهند. به عنوان مثال، در مدیریت زنجیره تأمین، این سیستمها میتوانند علت ریشهای تأخیرها را رهگیری کنند.
- جلوگیری از کلاهبرداری (Fraud Prevention): سیستمهای مبتنی بر علیت به جای تکیه بر همبستگیهای سطحی (که کلاهبرداران به راحتی آنها را دور میزنند)، بر وابستگیهای علّی تمرکز میکنند. این تغییر رویکرد منجر به کشف دقیقتر ناهنجاریهای شبکه و کاهش چشمگیر نرخ هشدارهای کاذب (False Positives) میشود که امنیت تراکنشها را تضمین میسازد.
- شخصیسازی و سیستمهای توصیهگر (Personalization and Recommendations): این فناوری امکان درک چراییِ تعامل کاربران با محصولات یا خدمات خاص را فراهم میسازد. این قابلیت به پلتفرمها اجازه میدهد پیشنهادهایی ارائه دهند که نه تنها بر اساس سلیقه گذشته کاربر، بلکه دقیقاً بر پایه محرکهای علّیِ رفتار او تنظیم شدهاند.
.
11.مزایای کلیدی یادگیری علّی
انتقال از یادگیری ماشین مبتنی بر همبستگی به رویکردهای علّی، مزایای زیرساختی و عملیاتی متعددی را برای سیستمهای هوش مصنوعی به همراه دارد:
- تعمیمپذیری بالا و پایداری (Robustness): مدلهای یادگیری ماشین سنتی در مواجهه با دادههای خارج از توزیع (Out-of-Distribution) عموماً دچار افت شدید عملکرد میشوند. در مقابل، مدلهای علّی با یادگیری قوانین ثابت حاکم بر سیستم، پایداری و دقت خود را در شرایط محیطی متغیر حفظ میکنند.
- تفسیرپذیری و شفافیت (Explainability): یادگیری علّی راهکاری مؤثر برای غلبه بر مشکل جعبه سیاه (Black Box) در هوش مصنوعی است. این معماری امکان ردیابی دقیق هر خروجی تا علت اولیه آن را فراهم میسازد؛ ویژگی مهمی که در صنایع حساس نظیر حقوق، سیستمهای نظامی و خودمختار یک ضرورت قطعی محسوب میشود.
- کاهش نیاز به کلاندادهها (Data Efficiency): برخلاف مدلهای کلاسیک یادگیری عمیق که نیازمند حجم عظیمی از دادهها هستند، یادگیری علّی با ادغام دانش پیشین (Prior Knowledge) و استفاده از ساختارهای گرافیکی، میتواند با حجم کمتری از دادههای آموزشی به استنتاجهای دقیقتری دست یابد.
- شبیهسازی و استدلال ضدِواقع (Counterfactual Thinking): این فناوری امکان ارزیابی نتایجِ مداخلاتِ انجامنشده (سناریوهای چه میشد اگر) را در یک محیط محاسباتی ایمن فراهم میکند. این قابلیت، نیاز به اجرای آزمایشهای پرهزینه یا پرخطر در دنیای واقعی را به حداقل میرساند.
- بهداشت، درمان و سیاستگذاری (Healthcare and Policy): تخمین دقیق اثرات یک روش درمانی یا سیاست کلان با کنترل و تعدیل متغیرهای مخدوشکننده (Confounders). این امر از تصمیمگیریهای شفاف و مبتنی بر شواهد در محیطهای حساس بالینی و حاکمیتی پشتیبانی میکند.
.
12.چالشهای فنی و محدودیتهای توسعه
علیرغم پتانسیلهای گسترده، ادغام یادگیری علّی در سیستمهای مقیاسپذیر هوش مصنوعی با موانع پژوهشی و مهندسی زیر مواجه است:
- محکزنی و استانداردسازی (Benchmarking): در حال حاضر، فقدان مجموعهدادههای استاندارد و چارچوبهای ارزیابی یکپارچه، اندازهگیری پیوسته و مقایسه دقیق متدهای مختلف یادگیری علّی را با دشواری مواجه کرده است.
- چالش دادههای ابعاد بالا (High-Dimensional Data): بسیاری از تکنیکهای کلاسیک استنتاج علّی در برخورد با انواع دادههای پیچیده و حجیم نظیر تصاویر، صوت یا ویدیو کارایی خود را از دست میدهند.
- یادگیری بازنمایی علّی (Representation Learning): استخراج بازنماییهای علّی معنادار و دقیق از دل دادههای خام و بدون ساختار، همچنان یک مسئله باز در تحقیقات هوش مصنوعی محسوب میشود.
- استدلال ضدِواقع (Counterfactual Reasoning): محاسبه کارآمد و اعتبارسنجی نتایج ضدِواقع در معماریهای پیچیده یادگیری عمیق (Deep Learning)، فرآیندی محاسباتی و بسیار پیچیده (Non-trivial) است.
- ادغام با مدلهای تقویتی و زایشی (Integration with RL and Generative Models): ترکیب منطق استدلال علّی با الگوریتمهای یادگیری تقویتی (Reinforcement Learning) و رویکردهای زایشی (Generative AI) هنوز در مراحل اولیه و آزمایشگاهی قرار دارد.
- علیت پویا و زمانی (Dynamic and Temporal Causality): درک روابط علت و معلولی که در طول زمان دستخوش تغییر میشوند یا درون سیستمهای در حال تکامل عمل میکنند، حوزهای است که تا حد زیادی کاوشنشده باقی مانده است.
.
مطالعه موردی1:پزشکی تخصصی: پارادوکس سیمپسون در کشف اثر واقعی دارو
- هدف: ارزیابی دقیق میزان اثربخشی یک داروی جدید (Drug X) بر روی نرخ بهبود بیماران.
- چالش (متغیر مخدوشکننده): پزشکان معمولاً این داروی قوی را فقط برای بیمارانی تجویز میکنند که وضعیت وخیمی دارند. از آنجا که بیماران بدحال به طور طبیعی شانس بهبودی کمتری دارند، هوش مصنوعی کلاسیک با دیدن دادهها نتیجه میگیرد که «مصرف دارو با کاهش نرخ بهبودی همراه است» (یک خطای مرگبار به نام پارادوکس سیمپسون). یادگیری علّی باید اثر «وخامت بیماری» را خنثی کند تا اثر خالص دارو مشخص شود.
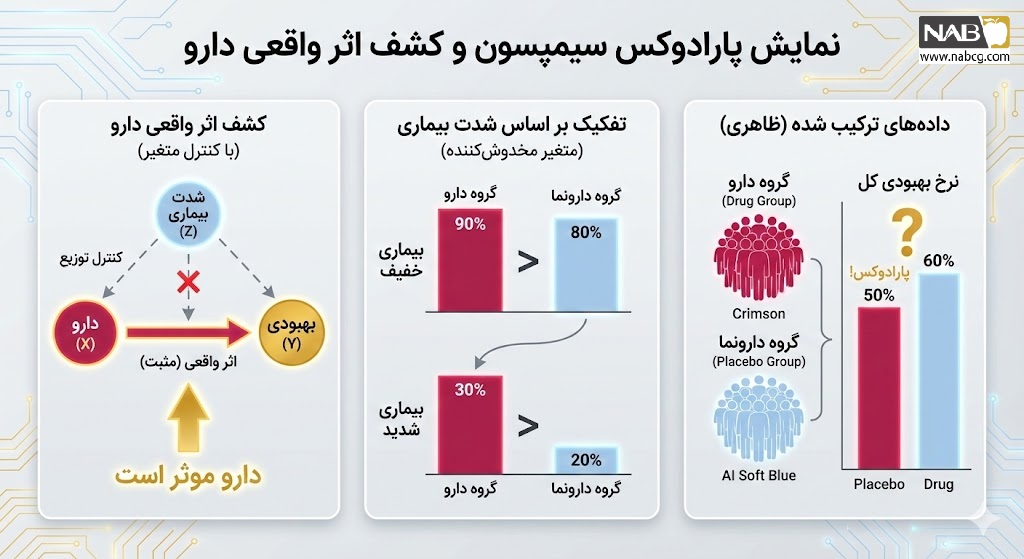
کد پایتون و شبیهسازی: در این کد نشان میدهیم که چگونه آمار معمولی دارو را مضر میداند، اما تحلیل علّی حقیقت را کشف میکند.
import pandas as pd
import numpy as np
# شبیهسازی دادههای ۱۰۰۰ بیمار
np.random.seed(42)
n = 1000
# متغیر مخدوشکننده: وضعیت وخیم (۱=وخیم، ۰=خفیف)
severe_condition = np.random.binomial(1, 0.5, n)
# تخصیص دارو: بیماران بدحال شانس بیشتری (80%) برای دریافت دارو دارند
prob_treatment = np.where(severe_condition == 1, 0.8, 0.2)
treatment = np.random.binomial(1, prob_treatment)
# شانس بهبودی: بیماری وخیم شانس را کم میکند، اما دارو شانس را 20% بالا میبرد!
prob_recovery = 0.6 - (0.4 * severe_condition) + (0.2 * treatment)
recovery = np.random.binomial(1, prob_recovery)
df = pd.DataFrame({'Severe': severe_condition, 'Treatment': treatment, 'Recovery': recovery})
# ۱. تحلیل هوش مصنوعی سنتی (مشاهده سطحی)
treated_recovery_rate = df[df['Treatment'] == 1]['Recovery'].mean()
untreated_recovery_rate = df[df['Treatment'] == 0]['Recovery'].mean()
# ۲. تحلیل علّی (کنترل متغیر مخدوشکننده با فرمول Backdoor)
causal_effect = 0
for severity in [0, 1]:
prob_y_given_t1 = df[(df['Treatment'] == 1) & (df['Severe'] == severity)]['Recovery'].mean()
prob_y_given_t0 = df[(df['Treatment'] == 0) & (df['Severe'] == severity)]['Recovery'].mean()
weight = (df['Severe'] == severity).mean()
causal_effect += (prob_y_given_t1 - prob_y_given_t0) * weight
print("--- نتایج گزارش پزشکی ---")
print(f"نرخ بهبودی با مصرف دارو (آمار سنتی): {treated_recovery_rate:.1%}")
print(f"نرخ بهبودی بدون دارو (آمار سنتی): {untreated_recovery_rate:.1%}")
print(f"نتیجهگیری غلط هوش مصنوعی: دارو شانس بهبودی را {(untreated_recovery_rate - treated_recovery_rate):.1%} کاهش میدهد!\n")
print(f"✅ اثر علّی واقعی (Causal Effect): دارو به طور خالص شانس بهبودی را {causal_effect:.1%} افزایش میدهد.")خروجی:

.
مطالعه موردی2:لجستیک و زنجیره تأمین: فریبِ همبستگی در هزینهها
هدف: یافتن راهکاری عملیاتی برای کاهش نرخ تأخیر در ناوگان حملونقل کالا.
چالش (متغیر مخدوشکننده): مدیران متوجه یک همبستگی قوی شدهاند: «هر زمان هزینههای حملونقل بالا میرود، تأخیر در تحویل نیز بیشتر میشود». مدلهای پیشبینانه سنتی پیشنهاد میدهند که برای کاهش تأخیر، باید بودجه حملونقل (مثلاً حقوق رانندگان یا هزینه سوخت) کاهش یابد! اما متغیر مخدوشکنندهای به نام «طوفانهای زمستانی» وجود دارد. طوفان هم باعث افزایش مصرف سوخت/هزینه میشود و هم جادهها را مسدود میکند (تأخیر).
کد پایتون و شبیهسازی:
import numpy as np
import statsmodels.api as sm
np.random.seed(100)
n_days = 365
# متغیر مخدوشکننده: شدت طوفان
storms = np.random.normal(5, 2, n_days)
# هزینه حمل (Cost) تحت تاثیر مستقیم طوفان است
costs = 100 + (15 * storms) + np.random.normal(0, 5, n_days)
# تأخیر (Delay) تحت تاثیر طوفان است، نه هزینه! (ضریب هزینه در واقعیت صفر است)
delays = 10 + (8 * storms) + (0 * costs) + np.random.normal(0, 2, n_days)
# ۱. مدلسازی سنتی (رگرسیون خطی تأخیر بر اساس هزینه)
X_traditional = sm.add_constant(costs)
model_traditional = sm.OLS(delays, X_traditional).fit()
# ۲. مدلسازی علّی (اضافه کردن طوفان به عنوان کنترلکننده مسیر پشتی)
X_causal = sm.add_constant(np.column_stack((costs, storms)))
model_causal = sm.OLS(delays, X_causal).fit()
print("--- گزارش هوش مصنوعی در زنجیره تأمین ---")
print(f"پیشنهاد مدل سنتی: به ازای هر ۱ میلیون دلار کاهش هزینه، تأخیرها {model_traditional.params[1]:.2f} روز کم میشود! (خطرناک)")
print(f"✅ کشف مدل علّی: تأثیر واقعی تغییر هزینه بر تأخیر دقیقاً {model_causal.params[1]:.2f} روز است (هیچ اثری ندارد).")
خروجی:

.
جمع بندی
یادگیری علّی تلاشی برای عبور از مرزهای یادگیری ماشین مبتنی بر همبستگی و حرکت به سوی هوش مصنوعی استدلالمحور است. همانطور که مشاهده شد، این رویکرد با تکیه بر مدلسازی ساختاری، مداخلههای کنترلشده و استدلال ضدِواقع، امکان استخراج اثرات واقعی و خالص متغیرها را فراهم میسازد. در چنین چارچوبی، سیستم نهتنها قادر به پیشبینی نتایج است، بلکه میتواند پیامد تصمیمهای جایگزین را نیز تحلیل کند.
چارچوبهایی مانند نردبان علیت پرل نشان میدهند که رسیدن به سطح ضدِواقع (Counterfactual Reasoning) بالاترین مرحله بلوغ استدلال در سیستمهای هوشمند است. ابزارهایی همچون Backdoor Adjustment، TMLE، AIPW و DML امکان تخمین اثرات علّی را در دادههای مشاهدهای فراهم میکنند و راه را برای تصمیمگیریهای دقیقتر در حوزههایی مانند پزشکی، اقتصاد، لجستیک و سیاستگذاری هموار میسازند.
با این حال، یادگیری علّی همچنان با چالشهایی نظیر شناسایی کامل متغیرهای مخدوشکننده، مدیریت دادههای ابعاد بالا و ادغام با معماریهای عمیق مواجه است. آینده این حوزه در گرو توسعه روشهایی است که بتوانند ساختارهای علّی را بهصورت مقیاسپذیر، پویا و سازگار با محیطهای پیچیده استخراج کنند.
در نهایت، اگر هدف توسعه سیستمهای هوشمند قابل اعتماد، پایدار و شفاف است، حرکت از همبستگی به سوی علیت نه یک انتخاب اختیاری، بلکه یک ضرورت راهبردی در تکامل هوش مصنوعی خواهد بود.



