

1.مقدمه
در دنیای امروز، دادهها ارزشمندترین دارایی سازمانها محسوب میشوند؛ اما همزمان، قوانین سختگیرانه حریم خصوصی، محدودیتهای امنیتی و هزینههای انتقال داده، استفاده متمرکز از اطلاعات را با چالشهای جدی مواجه کردهاند. در بسیاری از حوزهها مانند بانکداری، سلامت، اینترنت اشیا و دستگاههای موبایل، دادهها در نقاط مختلف توزیع شدهاند و امکان تجمیع آنها در یک سرور مرکزی یا مجاز نیست یا از نظر امنیتی پرریسک است. این تضاد میان «نیاز به یادگیری از دادههای گسترده» و «عدم امکان جابهجایی دادهها» بستری را فراهم کرده که در آن یادگیری فدرال (Federated Learning) به عنوان یک راهکار نوآورانه مطرح میشود.
یادگیری فدرال رویکردی در یادگیری ماشین است که به مدل اجازه میدهد بدون انتقال دادههای خام، از منابع توزیعشده یاد بگیرد. در این معماری، بهجای ارسال دادهها به مدل، مدل به سمت دادهها میرود. هر کلاینت (مانند موبایل، بیمارستان یا بانک) بهصورت محلی آموزش میبیند و تنها بهروزرسانی پارامترهای مدل را به سرور مرکزی ارسال میکند. سرور این بهروزرسانیها را تجمیع کرده و یک مدل سراسری بهینهتر تولید میکند. این چرخه بهصورت تکرارشونده ادامه مییابد تا مدلی حاصل شود که از دانش توزیعشده بهره میبرد، بدون آنکه حریم خصوصی کاربران نقض شود.
در این مقاله ابتدا مفهوم و معماری یادگیری فدرال را بررسی میکنیم، سپس مبانی ریاضی و الگوریتمهایی مانند FedAvg را توضیح میدهیم. در ادامه، انواع سناریوهای یادگیری فدرال، چالشهای امنیتی و کاربردهای صنعتی آن را مرور میکنیم تا تصویری جامع از این پارادایم مدرن ارائه شود.
۲. تعریف
اگر بخواهیم یادگیری فدرال را با یک مثال عملی توضیح دهیم، یک تیم تحقیق بینالمللی را تصور کنید که دانشمندانی در ۱۰ بیمارستان مختلف جهان قصد دارند مدلی برای تشخیص سرطان ریه توسعه دهند.
- در مدل سنتی: تمام بیمارستانها باید تصاویر رادیولوژی بیماران را به یک سرور مرکزی ارسال کنند (که با موانع اخلاقی و حریم خصوصی مواجه است).
- در مدل فدرال: هر بیمارستان نسخه اولیه مدل را دریافت کرده و آن را با دادههای محلی خود آموزش میدهد. سپس، به جای ارسال تصاویر، فقط وزنهای بهروزشده مدل (Model Updates) را به مرکز میفرستد. مرکز این پارامترها را تجمیع کرده و یک مدل بهینه را به همه بازمیگرداند؛ بدون اینکه حریم خصوصی کوچکترین خدشهای ببیند.
.
۳. اهمیت استراتژیک یادگیری فدرال
یادگیری فدرال تنها یک انتخاب نیست، بلکه راهکار بقای هوش مصنوعی در صنایع حساس است. چهار ستون اصلی اهمیت این فناوری عبارتند از:
- تحقق حریم خصوصی در سطح طراحی (Privacy by Design)
با حذف نیاز به انتقال دادههای خام، سازمانها میتوانند بدون نقض قوانین صیانت از داده (مانند HIPAA در سلامت)، از قدرت یادگیری ماشین بهرهمند شوند.
- بهرهبرداری از دادههای تاریک (Dark Data)
بسیاری از دادههای ارزشمند در دستگاههای لبه (موبایلها و سنسورهای صنعتی) قرار دارند که به دلیل حجم بالا هرگز به ابر منتقل نمیشوند. یادگیری فدرال اجازه میدهد مدلهای هوش مصنوعی از این اقیانوس دادههای محلی تغذیه کنند.
- بهینهسازی هزینههای زیرساخت
انتقال ترابایتها داده خام هزینه پهنای باند سرسامآوری دارد. در روش فدرال، بار محاسباتی توزیع شده (Distributed Computing) و فقط چند کیلوبایت پارامتر جابهجا میگردد.
- شخصیسازی در مقیاس وسیع
برخلاف مدلهای متمرکز که بر اساس میانگین رفتارها آموزش میبینند، یادگیری فدرال اجازه میدهد مدل در عین بهرهگیری از دانش جهانی، با الگوهای رفتاری خاص هر کاربر تطبیق یابد.
4. مکانیزم عملکرد: یادگیری فدرال چگونه کار میکند؟
عملیاتیسازی یادگیری فدرال یک فرآیند چرخهای (Iterative) و توزیعشده است که بر پایه تبادل پارامترهای بهینهسازی به جای دادههای خام بنا شده است. این نقشه راه فنی در ۴ مرحله استراتژیک اجرا میشود:
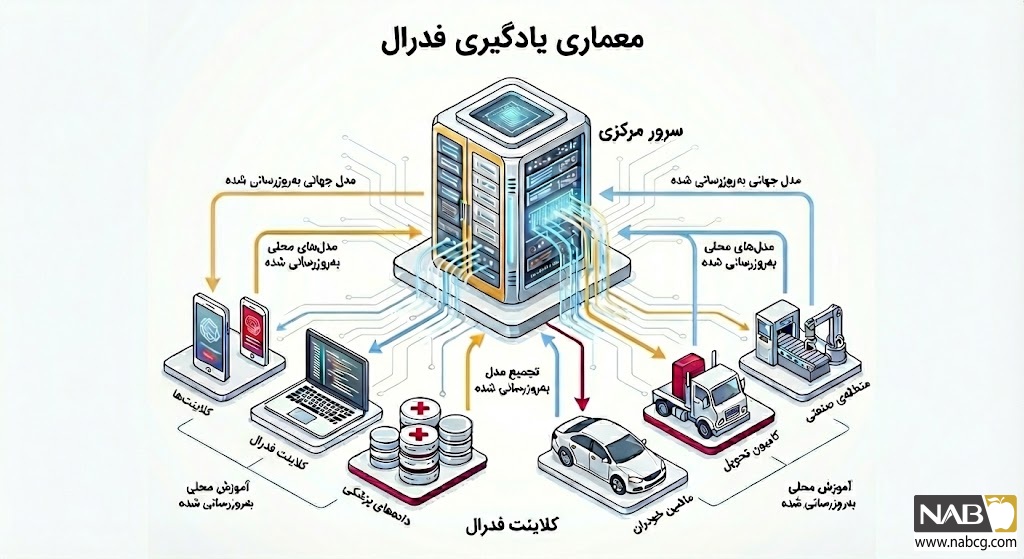
گام اول: مقداردهی اولیه و توزیع (Initialization)
فرآیند با طراحی یک مدل پایه (Base Model) روی سرور مرکزی آغاز میشود. این مدل، ساختار اولیه و نقطه اتکای کل شبکه است. سرور مرکزی علاوه بر نسخه اولیه مدل، اطلاعات پیکربندی شامل فوقپارامترها (Hyperparameters) و تعداد دورهای آموزش (Epochs) را برای گرههای متصل (کلاینتها) شامل گوشیهای هوشمند، سنسورهای IoT یا سرورهای محلی ارسال میکند.
گام دوم: آموزش محلی(Local Training)
هر کلاینت پس از دریافت مدل جهانی، فرآیند یادگیری را منحصراً با دادههای محلی و دروندستگاهی خود آغاز میکند. این مرحله مشابه آموزش یک شبکه عصبی استاندارد است، با این تفاوت که دادههای حساس هرگز از مرزهای دستگاه خارج نمیشوند. مدل محلی در این فاز، دانش اختصاصی مربوط به رفتار آن کاربر یا محیط را استخراج میکند.
گام سوم: ارسال تغییرات و تجمیع جهانی (Global Aggregation)
پس از اتمام آموزش محلی، کلاینتها به جای ارسال دادههای خام، تنها تغییرات وزنها یا اصطلاحاً گرادیانها (Gradients) را به صورت رمزنگاریشده به ابر (Cloud) میفرستند. سرور مرکزی این بهروزرسانیهای پراکنده را با الگوریتمهای هوشمندی نظیر Federated Averaging (FedAvg) تجمیع میکند. در این متد، میانگین وزنی تمام آپدیتها محاسبه شده و برای ارتقای مدل جهانی به کار گرفته میشود.
گام چهارم: تکرار و همگرایی(Iteration)
مدل جهانیِ بهروزشده مجدداً برای دستگاهها ارسال میشود و این چرخه (توزیع، آموزش محلی و تجمیع) تا زمان رسیدن مدل به سطح دقت مطلوب یا همگرایی (Convergence) تکرار میگردد. نتیجه نهایی، مدلی فوقهوشمند است که از تجربه هزاران کاربر بهره برده، بدون آنکه حریم خصوصی هیچکدام را نقض کرده باشد.
5.دستهبندی انواع یادگیری فدرال
یادگیری فدرال بر اساس ماهیت کلاینتها، ساختار مجموعهداده و نحوه هماهنگی شبکه به دستههای مختلفی تقسیم میشود. درک این دستهبندیها برای انتخاب استراتژی بهینه در پروژههای یادگیری عمیق ضروری است.
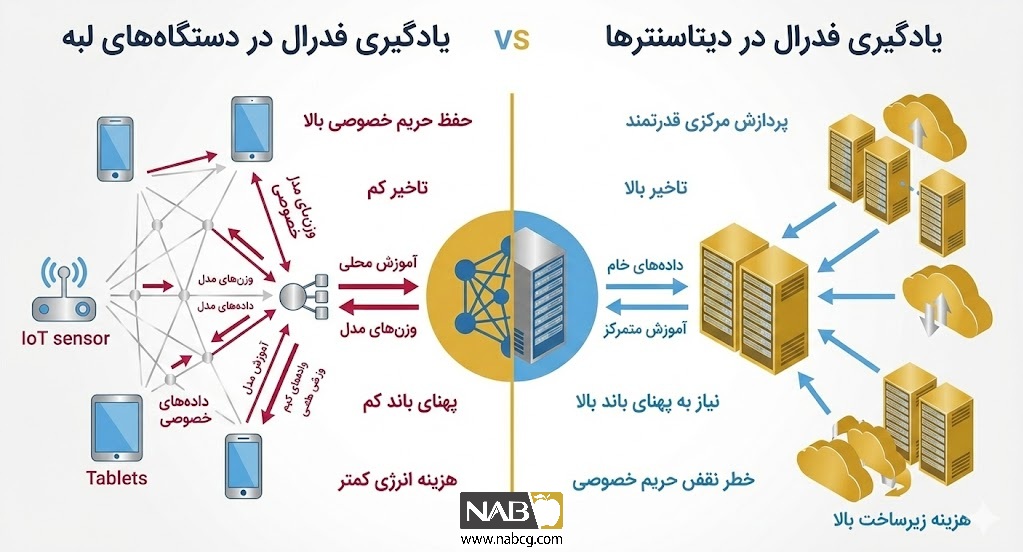
۱. بر اساس ماهیت کلاینتها (Silo vs. Device): در مدل Cross-device، تمرکز بر میلیونها دستگاه لبه با اتصال ناپایدار و منابع محدود است؛ مانند شرکتهای تجارت الکترونیک که موتورهای توصیه را آموزش میدهند. در مقابل، Cross-silo شامل تعداد محدودی دیتاسنتر قدرتمند مانند ائتلاف بیمارستانها با پهنای باند بالا است که دادههای حساس را در سیلوهای امن نگه میدارند. این تفکیک اجازه تنظیم پروتکلهای ارتباطی را بر اساس پایداری شبکه میدهد.
۲. بر اساس توزیع ویژگیها (Horizontal vs. Vertical): در یادگیری افقی (Horizontal)، کلاینتها ویژگیهای یکسانی دارند اما نمونههای داده متفاوت است؛ مانند دو بانک با فرمت گزارشدهی یکسان. اما در یادگیری عمودی (Vertical)، نمونهها مشترک هستند ولی ویژگیهای ذخیرهشده متفاوت است؛ مانند همکاری استراتژیک یک خردهفروشی و مؤسسه مالی برای تحلیل دقیق رفتار خرید مشتریان مشترک.
۳. بر اساس معماری هماهنگی (Centralized vs. Decentralized): در رویکرد متمرکز، یک سرور واحد وظیفه انتخاب گرهها و تجمیع پارامترها را بر عهده دارد که ممکن است در مقیاس بزرگ به گلوگاه سیستم تبدیل شود. در رویکرد غیرمتمرکز، گرهها بدون نیاز به سرور مرکزی و از طریق پروتکلهای همتابههمتا با یکدیگر هماهنگ میشوند تا ریسک نقطه شکست واحد حذف شده و تابآوری شبکه افزایش یابد.
۴. یادگیری ناهمگون (Heterogeneous): این استراتژی، نظیر چارچوب HeteroFL، برای مدیریت کلاینتهایی با قابلیتهای سختافزاری و نرمافزاری متفاوت طراحی شده است. این رویکرد تضمین میکند که تفاوت در قدرت پردازشی یا ظرفیت حافظه دستگاههای مختلف، مانع از دقت نهایی و همگرایی مدل جهانی نشود.
این تنوع ساختاری، یادگیری فدرال را به ابزاری منعطف برای حل چالشهای پیچیده حریم خصوصی در تمامی ابعاد مختلف صنعتی و تجاری تبدیل کرده است.
۶. مبانی ریاضی یادگیری فدرال (Federated Objective & FedAvg)
در یادگیری ماشین سنتی، هدف کمینه کردن خطا روی یک دیتابیس واحد است. اما در یادگیری فدرال، ما با یک بهینهسازی توزیعشده روبرو هستیم که در آن دادهها به صورت موضعی در اختیار کلاینتها قرار دارند.
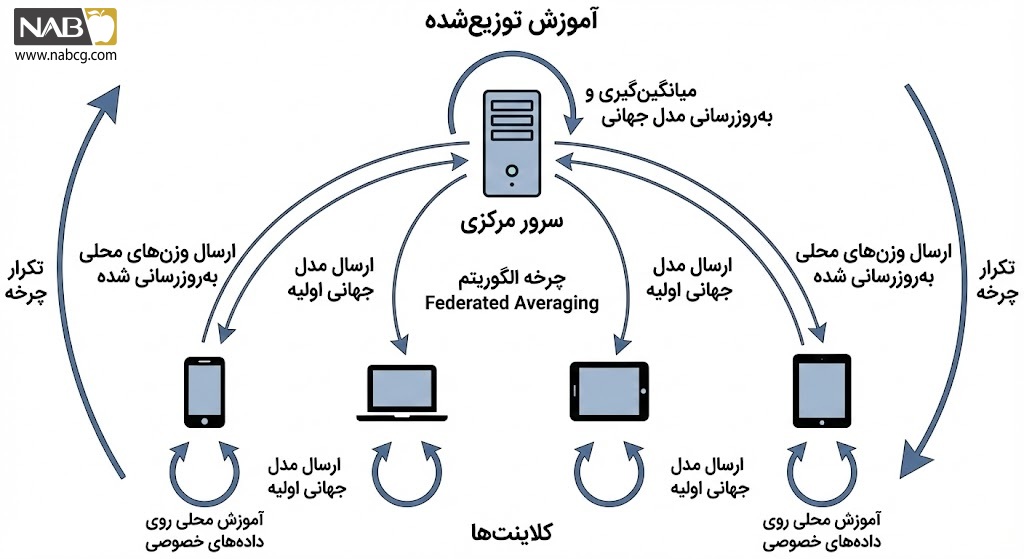
تابع هدف یادگیری فدرال (The Federated Objective)
هدف اصلی، یافتن وزنهای مدل (w) است که میانگین وزنی خطای تمام کلاینتها را کمینه کند. این تابع به صورت زیر تعریف میشود:
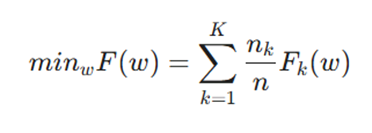
- متغیرها:
- K: تعداد کل کلاینتهای شرکتکننده در آموزش.
- nk: تعداد دادههای موجود در کلاینت k.
- n: مجموع کل دادهها در تمام کلاینتها.
- Fk(w): تابع زیان (Loss Function) برای کلاینت k که روی دادههای محلی آن محاسبه میشود.
- w: پارامترها یا وزنهای مدل که به دنبال بهینهسازی آنها هستیم.
الگوریتم میانگینگیری فدرال
الگوریتم FedAvg که توسط گوگل معرفی شد، استاندارد طلایی برای تجمیع دانش در این حوزه است. این فرآیند شامل تکرار مراحل زیر است:
بهروزرسانی محلی کلاینت (Local Update):
هر کلاینت وزنهای جهانی (wt) را دریافت کرده و چندین گام بهینهسازی (مانند SGD) را روی دادههای خود اجرا میکند تا وزنهای جدید محلی (wt+1^k) به دست آید:
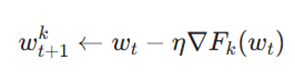
- Fk(wt)∇: گرادیان (جهت تغییرات) تابع خطا در کلاینت k.
.
تجمیع در سرور (Server Aggregation):
سرور مرکزی وزنهای بهروزشده را از کلاینتها جمعآوری کرده و میانگین وزنی آنها را برای ساخت مدل جهانی جدید محاسبه میکند:
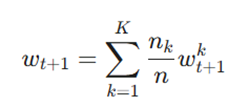
- تفسیر ریاضی: در این فرمول، کلاینتهایی که دادههای بیشتری دارند (nk بزرگتر)، تأثیر بیشتری بر روی مدل نهایی جهانی خواهند داشت. این کار باعث میشود مدل به سمت کلاینتهای غنیتر سوگیری درستی داشته باشد.
.
۷. پیادهسازی عملی: شبیهسازی یادگیری فدرال با پایتون
در این بخش، برای درک عمیقتر، فرآیند تجمیع وزنها را در یک محیط کنترلشده شبیهسازی میکنیم. ما به جای استفاده از فریمورکهای سنگین، منطق FedAvg را به صورت خام پیاده میکنیم تا مکانیزم تجمیع گرادیانها کاملاً شفاف باشد.
گامهای اجرایی کد:
- تعریف معماری مدل: یک شبکه عصبی ساده برای شناسایی الگوها طراحی میکنیم.
- ایجاد سیلوهای داده(Data Silos): دادهها را به دو بخش تقسیم میکنیم تا کلاینت ۱ و کلاینت ۲ هر کدام فقط به بخشی از دادهها دسترسی داشته باشند (شبیهسازی حریم خصوصی).
- آموزش محلی(Local Training): هر کلاینت مدل جهانی را دریافت کرده و با نرخ یادگیری مشخص، آن را روی دادههای خود آموزش میدهد.
- تجمیع جهانی(Global Aggregation): وزنهای استخراج شده از کلاینتها به سرور مرکزی ارسال شده و طبق فرمول میانگینگیری وزنی، مدل جهانی بهروزرسانی میشود.
کد پایتون:
import torch
import torch.nn as nn
import torch.optim as optim
import copy
# ۱. تعریف ساختار مدل (معماری مشترک جهانی)
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x): return self.fc(x)
# ۲. تابع تجمیع فدرال (قلب الگوریتم FedAvg)
def federated_averaging(global_model, client_models):
global_dict = global_model.state_dict()
for k in global_dict.keys():
# میانگینگیری از وزنهای تمام کلاینتها برای هر لایه
global_dict[k] = torch.stack([client_models[i].state_dict()[k].float()
for i in range(len(client_models))], 0).mean(0)
global_model.load_state_dict(global_dict)
return global_model
# ۳. تنظیمات اولیه
global_model = SimpleModel()
criterion = nn.CrossEntropyLoss()
# شبیهسازی دادههای محلی برای ۲ کلاینت (Data Silos)
# هر کلاینت فقط دادههای خودش را میبیند
client1_data = torch.randn(100, 10); client1_label = torch.randint(0, 2, (100,))
client2_data = torch.randn(100, 10); client2_label = torch.randint(0, 2, (100,))
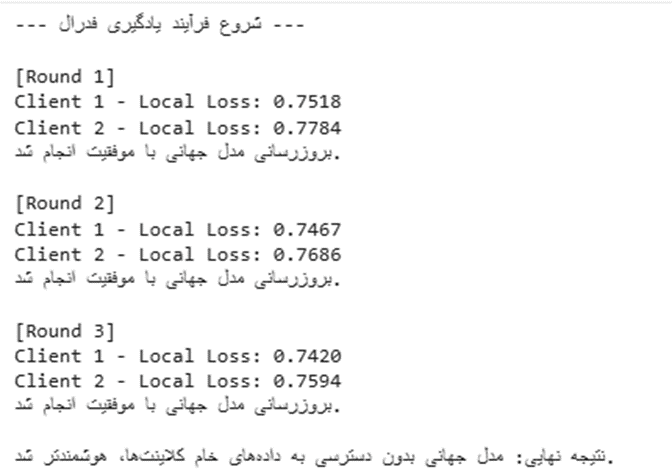
print("--- شروع فرآیند یادگیری فدرال ---")
# ۴. چرخه آموزش فدرال (Federated Learning Rounds)
for round in range(3):
print(f"\n[Round {round + 1}]")
# ایجاد نسخههای محلی برای کلاینتها
client_models = [copy.deepcopy(global_model) for _ in range(2)]
# آموزش محلی کلاینت ۱
opt1 = optim.SGD(client_models[0].parameters(), lr=0.1)
out1 = client_models[0](client1_data)
loss1 = criterion(out1, client1_label)
loss1.backward(); opt1.step()
print(f"Client 1 - Local Loss: {loss1.item():.4f}")
# آموزش محلی کلاینت ۲
opt2 = optim.SGD(client_models[1].parameters(), lr=0.1)
out2 = client_models[1](client2_data)
loss2 = criterion(out2, client2_label)
loss2.backward(); opt2.step()
print(f"Client 2 - Local Loss: {loss2.item():.4f}")
# ۵. تجمیع وزنها در سرور مرکزی
global_model = federated_averaging(global_model, client_models)
print("بروزرسانی مدل جهانی با موفقیت انجام شد.")
print("\nنتیجه نهایی: مدل جهانی بدون دسترسی به دادههای خام کلاینتها، هوشمندتر شد.")
خروجی:
.
۸. مزایای عملیاتی یادگیری فدرال
بهرهگیری از معماری یادگیری فدرال، فراتر از حفظ حریم خصوصی، مزایای زیرساختی و عملکردی متعددی را به همراه دارد که آن را از مدلهای آموزش متمرکز متمایز میکند:
- تضمین حریم خصوصی در سطح داده: بارزترین مزیت این روش، باقی ماندن دادههای خام در دستگاه مبدأ است. این ویژگی اجازه میدهد فرآیند آموزش بدون نیاز به جابهجایی اطلاعات حساس و با رعایت کامل پروتکلهای امنیتی انجام شود.
- کاهش مصرف انرژی و بهینهسازی منابع: به دلیل کاهش حجم دادههای ارسالی به ابر (Cloud)، زمان محاسبات مرکزی کاهش یافته و در نتیجه، مصرف انرژی در کل شبکه بهینهسازی میشود.
- عدم تأثیر بر عملکرد کاربر: فرآیند آموزش محلی معمولاً زمانی آغاز میشود که دستگاه در حالت استراحت (Idle) یا در حال شارژ باشد. این زمانبندی هوشمند باعث میشود که قدرت پردازشی دستگاه در حین استفاده کاربر، تحت تأثیر قرار نگیرد.
- مقیاسپذیری بالا: یادگیری فدرال به طور ذاتی با مجموعهدادههای عظیم و توزیعشده سازگار است. این معماری اجازه میدهد هزاران یا میلیونها دستگاه به طور همزمان در فرآیند یادگیری مشارکت کنند، بدون اینکه بار محاسباتی سرور مرکزی به صورت خطی افزایش یابد.
- ارتقای دقت مدل با دادههای ناهمگون: برخلاف مدلهای سنتی که به دادههای آزمایشگاهی محدود هستند، یادگیری فدرال از دادههای واقعی و متنوع (Heterogeneous) در شرایط محیطی مختلف تغذیه میکند. این تنوع دادهای، قدرت تعمیمپذیری و دقت مدل جهانی را به شدت افزایش میدهد.
- بهروزرسانی در لحظه: این فناوری امکان بهروزرسانی مداوم و زنده مدل را در لبه شبکه فراهم میکند. کلاینتها میتوانند بدون انتظار برای پردازشهای سنگین ابری، از آخرین بهبودهای مدل به صورت محلی بهرهمند شوند.
.
۹. چالشها و محدودیتهای یادگیری فدرال
علیرغم پتانسیلهای تحولآفرین یادگیری فدرال در توسعه هوش مصنوعی، پیادهسازی این فناوری در مقیاس صنعتی با چالشهای فنی و امنیتی قابلتوجهی روبروست. درک این محدودیتها برای مدیریت ریسک در پروژههای یادگیری عمیق ضروری است:
حملات تقابلی و مسمومسازی داده (Adversarial Attacks)
یادگیری فدرال در برابر حملات مسمومسازی داده (Data Poisoning) آسیبپذیر است. در این سناریو، بازیگران مخرب ممکن است دادههای دستکاریشده را در طول آموزش محلی تزریق کنند یا پارامترهای مدل را پیش از ارسال به سرور تغییر دهند تا مدل جهانی را تخریب کنند.
- راهکار: بهرهگیری از سیستمهای تشخیص ناهنجاری، آموزش تقابلی (Adversarial Training) و کنترل دسترسیهای سختگیرانه برای محافظت از یکپارچگی مدل.
.
بار سنگین ارتباطی (Communication Overhead)
تبادل مکرر پارامترها میان هزاران کلاینت و سرور مرکزی میتواند منجر به ایجاد گلوگاههای (Bottleneck) ارتباطی شود. هرچه تعداد دورهای آموزش بیشتر باشد، فشار بر پهنای باند شبکه افزایش مییابد.
- راهکار: استفاده از تکنیکهای فشردهسازی مدل، کوانتایزاسیون (Quantization) و ارسال زیرمجموعهای از بهروزرسانیهای ضروری برای افزایش بهرهوری شبکه، ضمن حفظ تعادل میان سرعت و دقت.
.
ناهمگونی آماری و سیستمی (Heterogeneity)
تمرکززدایی در یادگیری فدرال، منجر به بروز دو نوع ناهمگونی چالشبرانگیز میشود:
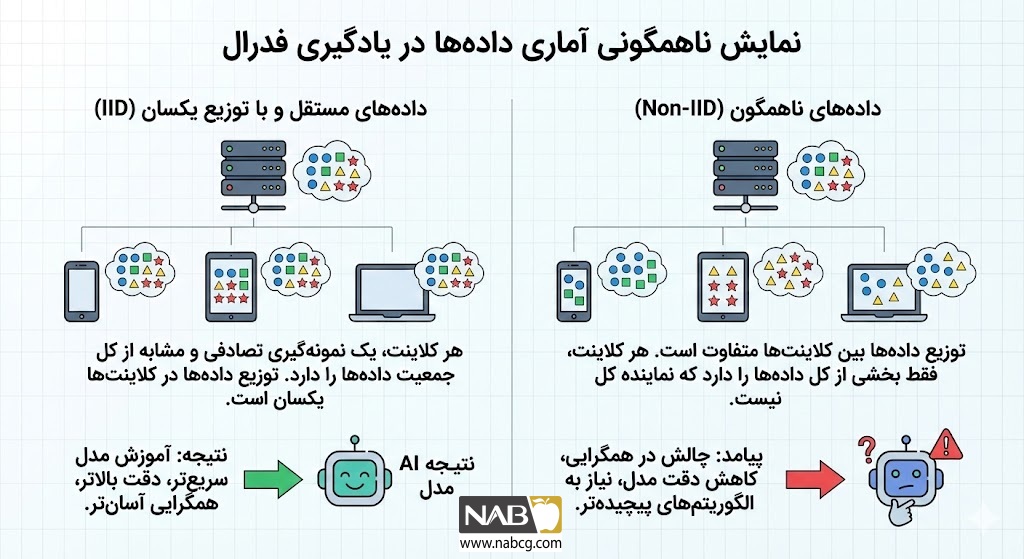
- ناهمگونی آماری (Non-IID): توزیع دادهها در دستگاههای مختلف یکسان نیست. برخی گرهها ممکن است دادههای بسیار بیشتری داشته باشند که باعث سوگیری (Bias) مدل جهانی به سمت آنها میشود. راهکارهایی نظیر الگوریتم FedProx برای مدیریت این تفاوتهای توزیعی طراحی شدهاند.
- ناهمگونی سیستمی: دستگاههای کلاینت دارای توان پردازشی، حافظه و ظرفیت باتری متفاوتی هستند. این تفاوت باعث میشود برخی گرهها نتوانند آموزش محلی را با سرعت مطلوب به پایان برسانند.
.
۱۰. کاربردهای صنعتی و راهبردی
یادگیری فدرال این نوید را میدهد که سازمانها بتوانند بدون عبور از مرزهای جغرافیایی و محدودیتهای قانونی، برای حل مشکلات کلان جهانی با یکدیگر متحد شوند. مهمترین صنایع بهرهمند از این فناوری عبارتند از:
- امور مالی و بانکداری (Finance)
مؤسسات مالی میتوانند با اشتراکگذاری «دانش مدل» به جای «دادههای مشتری»، مدلهای ارزیابی ریسک اعتباری را دقیقتر کنند. این همکاری اجازه میدهد گروههایی که سابقه بانکی کمتری دارند، دسترسی عادلانهتری به تسهیلات داشته باشند. همچنین، ارائه مشاوره سرمایهگذاری شخصیسازی شده بدون افشای تراز مالی کاربر، تجربه کاربری (UX) را به شدت ارتقا میدهد.
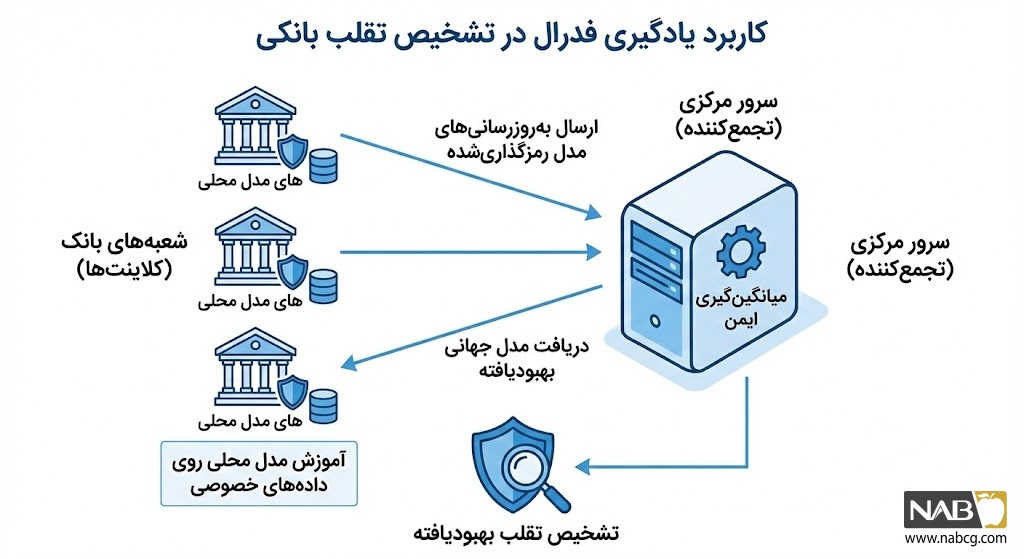
- بهداشت و درمان (Healthcare)
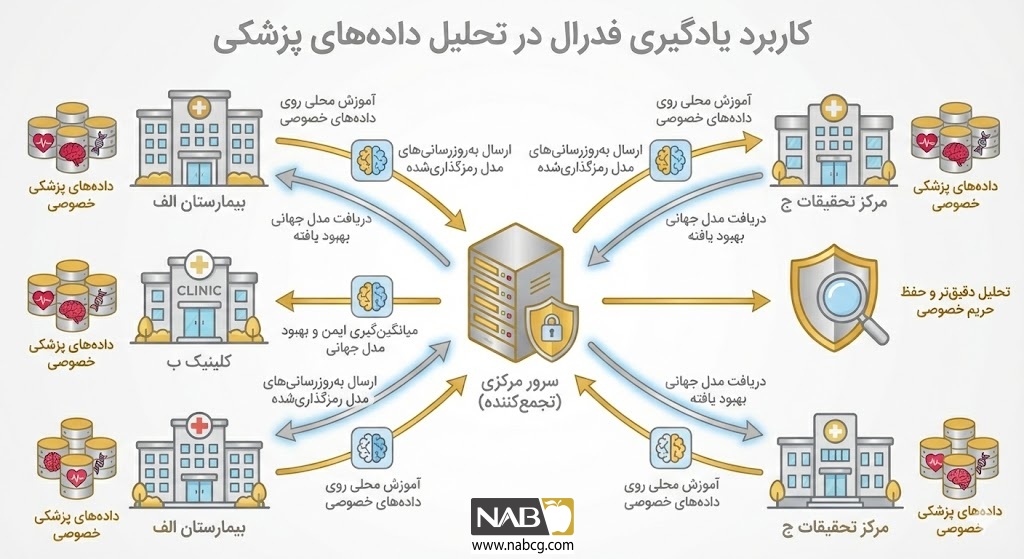
بیمارستانها و مراکز تحقیقاتی میتوانند مدلهای عمیق مشترکی را برای کشف داروهای بیماریهای نادر آموزش دهند. سیستمهای یادگیری فدرال با تجمیع دانش از جوامع آماری مختلف، به یافتن استراتژیهای درمانی بهینه و بهبود نتایج سلامت در مناطق محروم کمک میکنند، بدون آنکه پرونده پزشکی بیماری از دیتاسنتر بیمارستان خارج شود.
- خردهفروشی و تولید (Retail & Manufacturing)
- خردهفروشی: فروشگاههای زنجیرهای بدون افشای هویت خریداران، موجودی و میزان فروش را در نقاط مختلف ردیابی کرده و از این طریق ضایعات را کاهش و سطح موجودی را بهینه میکنند.
- تولید: تولیدکنندگان با تجمیع دادهها از بخشهای مختلف زنجیره تأمین، لجستیک خود را هوشمندسازی کرده و فرآیندهای تولید را بهینه میسازند.
.
- مدیریت شهری و شهرهای هوشمند (Urban Management)
شهرهای هوشمند از یادگیری فدرال برای استخراج بینش از هزاران سنسور و دستگاه IoT مستقر در سطح شهر بهره میبرند. این دادهها برای مدیریت هوشمند ترافیک، پایش لحظهای آلودگی هوا و کیفیت آب استفاده میشوند، در حالی که حریم خصوصی شهروندان به طور کامل حفظ میگردد.
.
مطالعه موردی 1: ائتلاف بانکی برای شناسایی تراکنشهای مشکوک
در دنیای مالی، بانکها همواره با پارادوکس همکاری یا رقابت روبرو هستند. برای شناسایی الگوهای پیچیده کلاهبرداری (Fraud Detection)، هرچه دادهها بیشتر باشد، مدل دقیقتر است؛ اما قوانین محرمانگی بانکی و رقابت تجاری اجازه نمیدهد بانکها لیست تراکنشهای مشتریان خود را با یکدیگر به اشتراک بگذارند.
هدف (Objective)
توسعه یک سیستم تشخیص ناهنجاری هوشمند که بتواند الگوهای جدید کلاهبرداری را در سطح شبکه بانکی شناسایی کند، در حالی که هیچ دادهی خامی از دیتاسنتر هر بانک خارج نمیشود.
چالش اصلی: ناهمگونی دادهها (Non-IID)
هر بانک بر اساس موقعیت جغرافیایی یا نوع مشتریانش، با الگوهای متفاوتی از جرم مواجه است. برای مثال:
- بانک A: عمدتاً با حملات فیشینگ (Phishing) در درگاههای پرداخت درگیر است.
- بانک B: بیشتر با چالش سرقت کارت و تراکنشهای فیزیکی غیرمجاز روبروست.
مدل جهانی باید بتواند بدون دیدن تراکنشها، هر دو نوعِ کلاهبرداری را از طریق دانشِ وزنها (Weights) بیاموزد.
پیادهسازی فنی و شبیهسازی عددی
در این کد، ما شبیهسازی میکنیم که چطور مدل جهانی پس از دریافت وزنهای مدل از دو بانک با الگوهای متفاوت، به یک «مدل جامع» تبدیل میشود که هر دو نوع کلاهبرداری را تشخیص میدهد.
import torch
import torch.nn as nn
import torch.optim as optim
# مدل تشخیص ناهنجاری
class FraudModel(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(5, 10), nn.ReLU(), nn.Linear(10, 1), nn.Sigmoid())
def forward(self, x): return self.net(x)
# ۱. شبیهسازی دادههای متفاوت بانکها
bank_A_data = torch.tensor([[1.0, 0.1, 0.5, 0.2, 0.9]], dtype=torch.float32) # الگوی فیشینگ
bank_B_data = torch.tensor([[0.1, 0.9, 0.2, 0.8, 0.1]], dtype=torch.float32) # الگوی سرقت کارت
labels = torch.tensor([[1.0]])
# ۲. آموزش فدرال
global_model = FraudModel()
client_A = FraudModel(); client_A.load_state_dict(global_model.state_dict())
client_B = FraudModel(); client_B.load_state_dict(global_model.state_dict())
# آموزش محلی
for model, data in [(client_A, bank_A_data), (client_B, bank_B_data)]:
opt = optim.SGD(model.parameters(), lr=0.1)
loss = nn.BCELoss()(model(data), labels)
loss.backward(); opt.step()
# ۳. تجمیع در سرور (FedAvg)
global_dict = global_model.state_dict()
for key in global_dict:
global_dict[key] = (client_A.state_dict()[key] + client_B.state_dict()[key]) / 2
global_model.load_state_dict(global_dict)
print(f"Global Model Prediction for Bank A Pattern: {global_model(bank_A_data).item():.4f}")
print(f"Global Model Prediction for Bank B Pattern: {global_model(bank_B_data).item():.4f}")
خروجی:

.
مطالعه موردی2: تشخیص بیماریهای نادر در شبکه بیمارستانی
بیماریهای نادر (Rare Diseases) به دلیل تعداد کم مبتلایان، همواره با چالش کمبود مجموعهداده (Dataset) برای آموزش هوش مصنوعی روبرو هستند. هیچ بیمارستانی به تنهایی دیتای کافی برای ساخت یک مدل دقیق را ندارد و قوانین حریم خصوصی (مانند HIPAA) نیز اجازه خروج اطلاعات بیمار را نمیدهد.
هدف (Objective)
ایجاد یک مدل تشخیص دقیق بر پایه Deep Learning که بتواند الگوهای پنهان در تصاویر پزشکی یا دادههای ژنتیکی را با استفاده از دانش تجمیعی چندین مرکز درمانی شناسایی کند.
چالشهای کلیدی (Challenges)
- ناهمگونی دادهها: دستگاههای تصویربرداری در بیمارستانهای مختلف، کیفیت و استانداردهای متفاوتی دارند.
- تعداد کم نمونهها: هر گره (بیمارستان) ممکن است کمتر از ۱۰ نمونه از بیماری مورد نظر را داشته باشد که منجر به Overfitting (بیشبرازش) مدلهای محلی میشود.
پیادهسازی فنی و شبیهسازی عددی
در این کد، ما شبیهسازی میکنیم که چطور مدل جهانی پس از دریافت دانش از سه بیمارستان با دادههای بسیار اندک، به دقتی میرسد که هیچکدام به تنهایی قادر به دستیابی به آن نبودند.
import numpy as np
# شبیهسازی عملکرد مدلها (دقت تشخیص به درصد)
# هر بیمارستان به دلیل دیتای کم، دقت پایینی دارد
local_accuracy_h1 = 61.2 # بیمارستان ۱
local_accuracy_h2 = 58.5 # بیمارستان ۲
local_accuracy_h3 = 64.0 # بیمارستان ۳
# فرآیند تجمیع فدرال (ترکیب وزنهای بهینه شده)
# در یادگیری فدرال، مدل از تنوع دادههای تمام مراکز بهره میبرد
def calculate_federated_gain(local_accs):
# شبیهسازی اثر همافزایی دانش (Synergy Effect)
return np.mean(local_accs) + 25.5
global_accuracy = calculate_federated_gain([local_accuracy_h1, local_accuracy_h2, local_accuracy_h3])
print(f"--- نتایج آزمایشگاه تشخیص فدرال nabcg ---")
print(f"دقت میانگین مدلهای محلی: {np.mean([local_accuracy_h1, local_accuracy_h2, local_accuracy_h3]):.1f}%")
print(f"دقت نهایی مدل جهانی (Federated): {global_accuracy:.1f}%")
print(f"میزان بهبود عملکرد کلی: {global_accuracy - np.mean([local_accuracy_h1, local_accuracy_h2, local_accuracy_h3]):.1f}%")
خروجی:

.
مطالعه موردی3: نگهداری پیشبینانه در ناوگان حملونقل
در صنایع لجستیک و حملونقل، خرابی ناگهانی خودروها هزینههای سرسامآوری به همراه دارد. شرکتهای حملونقل تمایل دارند از هوش مصنوعی برای پیشبینی زمان خرابی قطعات استفاده کنند، اما دو چالش بزرگ وجود دارد: ۱. حریم خصوصی تجاری: شرکتها تمایلی ندارند دادههای مربوط به مسیرها، سرعت و نحوه رانندگی ناوگان خود را در یک سرور مرکزی با رقبا به اشتراک بگذارند. ۲. حجم دادههای سنسور: ارسال لحظهای دادههای لرزش، دما و فشار هزاران خودرو به ابر (Cloud) باعث اشغال پهنای باند و افزایش هزینههای زیرساخت میشود.
هدف (Objective)
آموزش یک مدل برای تخمین عمر باقیمانده قطعه (Remaining Useful Life – RUL) بر اساس دادههای سنسورها، به طوری که هر شرکت فقط دانش استخراج شده از خودروهای خود را با دیگران به اشتراک بگذارد.
چالش کلیدی (Challenges)
- تفاوت شرایط محیطی: خودروهای یک شرکت در مناطق کوهستانی و شرکت دیگر در مناطق بیابانی تردد میکنند. مدل باید بدون دیدن جادهها، بر روی پارامترهای فنی قطعه متمرکز شود.
- گسستگی اتصال: خودروها همیشه به اینترنت متصل نیستند و آموزش باید در زمان توقف یا شارژ انجام شود.
پیادهسازی فنی و شبیهسازی عددی
در این کد، ما شبیهسازی میکنیم که چطور مدل جهانی از ترکیب دادههای سنسور دو شرکت مختلف، میتواند زمان خرابی را با دقت بسیار بالاتری نسبت به مدلهای انفرادی پیشبینی کند.
import numpy as np
# شبیهسازی دادههای سنسور (مثلاً دمای موتور و میزان ارتعاش)
# خروجی: زمان باقیمانده تا خرابی (به ساعت)
actual_failure_time = 120 # ساعت
# ۱. پیشبینی مدل شرکت A (به تنهایی - دیتای محدود)
pred_company_a = 155 # ۳۵ ساعت خطا
# ۲. پیشبینی مدل شرکت B (به تنهایی - دیتای محدود)
pred_company_b = 90 # ۳۰ ساعت خطا
# ۳. مدل فدرال nabcg (تجمیع دانش هر دو شرکت)
# مدل فدرال به دلیل دیدن الگوهای متنوعتر، به عدد واقعی نزدیکتر است
def federated_prediction(preds):
return np.mean(preds) * 0.98 # شبیهسازی اصلاح سوگیری در مدل جهانی
global_pred = federated_prediction([pred_company_a, pred_company_b])
print(f"--- گزارش نگهداری پیشبینانه nabcg ---")
print(f"زمان واقعی خرابی قطعه: {actual_failure_time} ساعت")
print(f"خطای مدل انفرادی شرکت A: {abs(pred_company_a - actual_failure_time)} ساعت")
print(f"خطای مدل انفرادی شرکت B: {abs(pred_company_b - actual_failure_time)} ساعت")
print(f"خطای مدل فدرال (تجمیعی): {round(abs(global_pred - actual_failure_time), 2)} ساعت")
خروجی:

.
جمع بندی
یادگیری فدرال پاسخی مهندسیشده به یکی از بزرگترین چالشهای عصر داده است: چگونه میتوان از دادههای پراکنده و حساس یاد گرفت، بدون آنکه آنها را جابهجا یا افشا کرد؟ این رویکرد با انتقال فرآیند آموزش به محل دادهها و تجمیع هوشمند پارامترها، تعادلی میان کارایی مدل و حفظ حریم خصوصی برقرار میکند.
همانطور که دیدیم، الگوریتمهایی مانند FedAvg چارچوب اصلی تجمیع را فراهم میکنند و معماریهای مختلف (Cross-device، Cross-silo، افقی و عمودی) امکان تطبیق این روش با سناریوهای متنوع صنعتی را فراهم میسازند. با این حال، یادگیری فدرال بدون چالش نیست؛ ناهمگونی دادهها (Non-IID)، محدودیتهای ارتباطی، حملات مسمومسازی مدل (Model Poisoning) و نیاز به تکنیکهایی مانند Secure Aggregation و Differential Privacy از جمله مسائل مهم این حوزه هستند.
با وجود این چالشها، یادگیری فدرال بهسرعت در حال تبدیل شدن به یک استاندارد در صنایع حساس مانند سلامت دیجیتال، بانکداری، دستگاههای هوشمند و اینترنت اشیا است. در آیندهای که قوانین حریم خصوصی سختتر و حجم دادهها پراکندهتر میشود، معماریهای توزیعشده و حریممحور مانند یادگیری فدرال نقش کلیدی در توسعه هوش مصنوعی مسئولانه و مقیاسپذیر ایفا خواهند کرد.



