

1.مقدمه
در دنیای واقعیِ هوش مصنوعی، دادهها معمولاً یکباره و ثابت به دست ما نمیرسند. جهان دائم در حال تغییر است: رفتار کاربران در سیستمهای توصیهگر عوض میشود، الگوهای کلاهبرداری بانکی بهروز میشوند و شرایط محیطی در رباتیک از روزی به روز دیگر فرق میکند. بنابراین مدلهای هوشمند باید بتوانند همراه با این تغییرات، یاد بگیرند و خودشان را تطبیق دهند.
اما یک مشکل مهم وجود دارد: شبکههای عصبی سنتی وقتی اطلاعات جدید یاد میگیرند، ممکن است بخش زیادی از آموختههای قبلی را از دست بدهند؛ پدیدهای که به آن فراموشی فاجعهبار (Catastrophic Forgetting) میگویند.
یادگیری پیوسته (Continual Learning) پاسخی مستقیم به همین چالش است. در این رویکرد، مدل میتواند از یک جریان طولانی از وظایف یا دادههای متوالی یاد بگیرد، بدون اینکه مجبور شود هر بار از اول آموزش ببیند یا مهارتهای قبلیاش را قربانی کند. هستهی اصلی یادگیری پیوسته، حل یک تعارض کلیدی است:
چطور مدلی بسازیم که هم سریع با دادههای جدید سازگار شود، و هم دانش گذشته را حفظ کند؟
به این مسئله، معمای پایداری–انعطافپذیری (Stability–Plasticity Dilemma) گفته میشود.
در این مقاله، ابتدا مفهوم یادگیری پیوسته و تفاوت آن با یادگیری سنتی (Batch Learning) و یادگیری انتقالی (Transfer Learning) را شفاف میکنیم. سپس با سه سناریوی مهم آن یعنی Task-IL، Domain-IL و Class-IL آشنا میشویم. در ادامه، متریکهای ارزیابی، روشهای رایج برای جلوگیری از فراموشی، ابزارهای عملی و چند مطالعهی موردی صنعتی را مرور میکنیم تا یک تصویر کامل و کاربردی از این حوزه به دست آورید.
2.تعریف
در محافل آکادمیک، یادگیری پیوسته را توانایی یک سیستم هوشمند برای یادگیری از توالی نامحدودی از وظایف (Sequence of Tasks) تعریف میکنیم. اما اگر بخواهیم عمیقتر نگاه کنیم، یادگیری پیوسته هنرِ مدیریت یک تضاد بزرگ است: معمای پایداری-انعطافپذیری.
- انعطافپذیری: توانایی مدل برای جذب دانش جدید و تطبیق با تغییرات.
- پایداری: توانایی مدل برای حفظ دانش گذشته و جلوگیری از پاک شدن حافظه (فراموشی فاجعهبار).
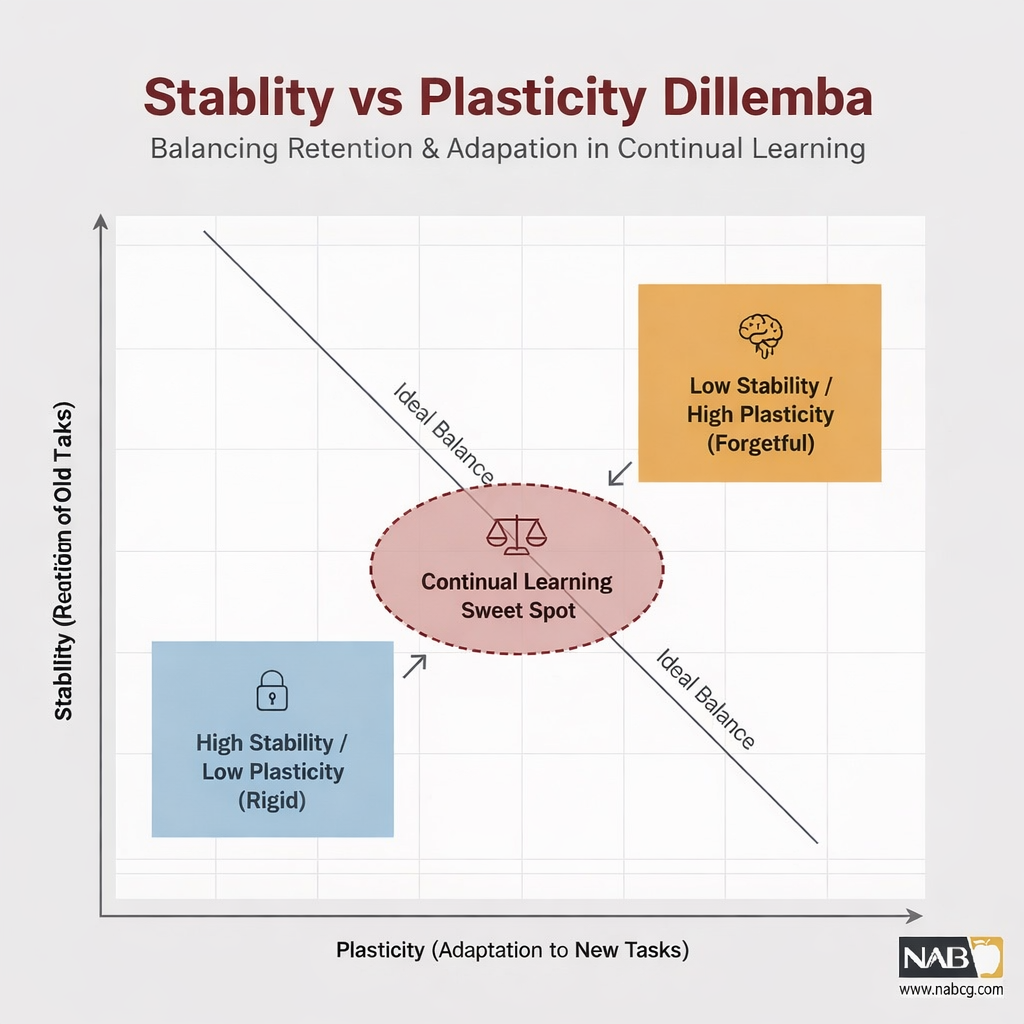
یک سیستم یادگیری پیوسته ایدهآل، مدلی است که مانند مغز انسان، مرز میان آموزش و اجرا را از بین میبرد و در حین کار، تکامل مییابد.
ویژگیهای بنیادین که یک سیستم را پیوسته میکند:
- جریان دادههای متوالی(Data Streams): برخلاف مدلهای کلاسیک، دادهها به صورت یکباره (Batch) در دسترس نیستند، بلکه به صورت جریانی همیشگی وارد سیستم میشوند.
- محدودیت حافظه تاریخی: به دلیل مسائل حریم خصوصی یا محدودیت سختافزاری، ما حق نداریم تمام دادههای گذشته را ذخیره کنیم.
- انتقال دانش دوطرفه (Knowledge Transfer)
- انتقال رو به جلو(Forward): استفاده از تجربههای قبلی برای یادگیری سریعترِ وظیفه جدید.
- انتقال رو به عقب(Backward): یادگیریِ مطلبِ جدید باعث شود مدل در انجام کارهای قدیمیاش هم هوشمندتر شود (بهبود تخصص قبلی).
.
3.مقایسه یادگیری پیوسته با یادگیری سنتی و یادگیری انتقالی
| ویژگی | یادگیری سنتی (Batch) | یادگیری انتقالی (Transfer) | یادگیری پیوسته (Continual) |
| دسترسی به داده قدیمی | الزامی و کامل (بازآموزی) | نیاز نیست | بسیار محدود یا غیرممکن |
| تعداد وظایف | یک وظیفه ثابت | دو وظیفه (مبدأ به مقصد) | نامحدود و متوالی |
| حفظ تخصصهای قبلی | ۱۰۰٪ (هزینه بالا) | ضعیف (فراموشی رخ میدهد) | بسیار بالا (اولویت اول) |
| هزینه محاسباتی | تکراری و بسیار سنگین | متوسط | پایین و بهینه |
| انتقال دانش | ندارد | فقط رو به جلو (Forward) | دوطرفه (Forward & Backward) |
4.سطوح یادگیری پیوسته
.
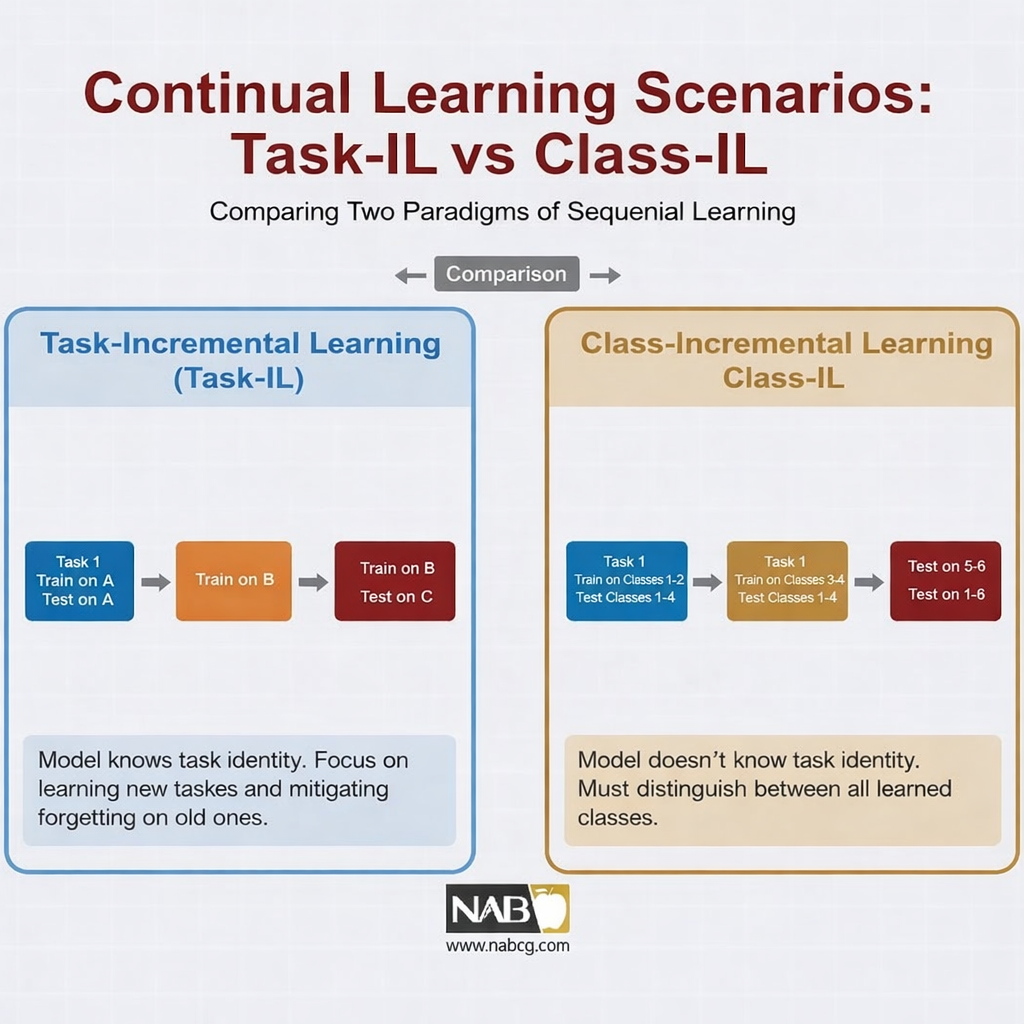
یادگیری پیوسته در سطح وظیفه(Task-IL)
در این سناریو، مدل میداند که در حال انجام کدام وظیفه است. مثلاً به او اطلاع میدهیم: «اکنون باید تصویر سگ را تشخیص بدهی». این حالت سادهترین نوع یادگیری پیوسته است، چون مدل با آگاهی از هویت وظیفه، میتواند دانش مربوط به آن را بهصورت هدفمند بازیابی کند.
یادگیری پیوسته در سطح دامنه(Domain-IL)
در اینجا ساختار وظیفه ثابت میماند، اما ماهیت یا توزیع دادهها تغییر میکند. برای مثال، مدلی را در نظر بگیرید که وظیفهاش تشخیص اعداد است. ابتدا مدل را با تصاویر سیاهسفید آموزش میدهیم، سپس در مرحله بعد باید همان اعداد را در تصاویر دارای نویز شدید تشخیص دهد. مدل باید درک کند که با وجود تغییر در ظاهر داده، مفهوم اصلی وظیفه (تشخیص اعداد) تغییر نمیکند.
یادگیری پیوسته در سطح کلاس(Class-IL)
چالشبرانگیزترین حالت، یادگیری در سطح کلاس است. در این سناریو، مدل بهتدریج کلاسهای جدید را میآموزد؛ مثلاً امروز کلاسهای ۱ و ۲ را یاد میگیرد، فردا کلاسهای ۳ و ۴ را، بیآنکه بداند هر داده به کدام مرحله از آموزش تعلق دارد. در نهایت، مدل باید بین تمام کلاسهایی که تاکنون دیده است تمایز قائل شود. این سناریو به یادگیری انسان شباهت دارد: ما هنگام مواجهه با مفاهیم جدید، نیازی به برچسبگذاری مرحله آموزش نداریم و میتوانیم بین همه مفاهیم تمایز قائل شویم.
5.معیارهای ارزیابی در یادگیری پیوسته
دقت میانگین (Average Accuracy – ACC)
این متریک نشان میدهد که مدل پس از آموزش روی تمام وظایف، به طور متوسط چقدر در انجام آنها موفق است.
فرمول:
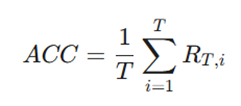
- متغیرها:
- T: تعداد کل وظایف (Tasks).
- RT,i: دقت مدل روی وظیفه i پس از اینکه آموزش روی وظیفهT تمام شده است.
- تفسیر: هرچه بالاتر باشد، یعنی مدل در مجموع باهوشتر است.
.
فراموشی میانگین (Average Forgetting – AF)
این حیاتیترین متریک برای سنجش فراموشی فاجعهبار است. AF اندازهگیری میکند که دقت مدل روی وظایف قبلی، پس از یادگیری وظایف جدید چقدر افت کرده است.
فرمول:
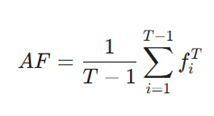
که در آن فراموشی برای هر وظیفه به صورت زیر محاسبه میشود:
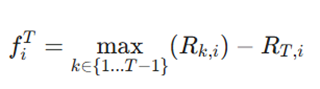
- متغیرها:
- Rk,i: بالاترین دقتی که مدل در گذشته برای وظیفه i به دست آورده بود.
- RT,i: دقت فعلی مدل روی همان وظیفه i (پس از یادگیری آخرین وظیفه).
- تفسیر: هرچه این عدد به صفر نزدیکتر باشد، یعنی مدل کمتر فراموش کرده است.
.
انتقال دانش (Knowledge Transfer)
این متریک به دو بخش تقسیم میشود و نشان میدهد یادگیری وظایف چطور بر یکدیگر اثر میگذارند:
- انتقال رو به عقب (Backward Transfer – BWT): توانایی یادگیری وظیفه جدید برای بهبود عملکرد در وظایف قبلی.
- اگر BWT > 0: یادگیری جدید به فهم مطالب قدیمی کمک کرده است.
- اگر BWT < 0: فراموشی رخ داده است.
- انتقال رو به جلو (Forward Transfer – FWT): تأثیر دانش قبلی در سرعت و کیفیت یادگیری وظایف آینده.
- اگر FWT > 0: یعنی مدل از تجربیاتش برای یادگیری سریعترِ وظیفه جدید استفاده کرده است.
.
6.یادگیری پیوسته چگونه کار میکند؟
عبور از یادگیری سنتی به سمت مدلهای پویا، نیازمند فرآیندی مهندسیشده است تا مدل بدون ابطال دانش گذشته، تخصصهای جدید کسب کند. این مسیر هوشمندانه در ۱۲ گام کلیدی خلاصه میشود:
۱. مقداردهی اولیه(Initialization): شروع با یک مدل پیشآموزشدیده (Pre-trained) روی مجموعهدادههای عظیم که به عنوان زیربنای معرفتی و نقطه اتکای مدل عمل میکند.
۲. توالیبندی وظایف(Task Sequencing): طراحی زنجیرهای از چالشها یا جریانهای دادهای متوالی که مدل باید به ترتیب با آنها روبرو شود.
۳. آموزش متمرکز: استفاده از الگوریتمهای بهینهسازی مانند Gradient Descent برای ایجاد تخصص عمیق در اولین وظیفه از زنجیره یادگیری.
۴. تنظیمگری(Regularization): بهکارگیری متدهایی نظیر EWC برای شناسایی و محافظت از پارامترهای حیاتی مربوط به وظایف قبلی و جلوگیری از تغییرات مخرب در آنها.
۵. تقطیر دانش(Distillation): انتقال هوشمندانه آموختهها از نسخه استاد به شاگرد برای حفظ میراث یادگیری در معماریهای جدید.
۶. ارزیابی چندجانبه: پایش همزمان دقت در وظیفه جاری و سنجش پایداری عملکرد در تمامی وظایف گذشته جهت اطمینان از عدم فراموشی.
۷. ذخیرهسازی هوشمند: نگهداری بازنماییهای کلیدی در یک بافر حافظه جهت بازپخش (Replay) و یادآوری دورهای خاطرات فنی به مدل.
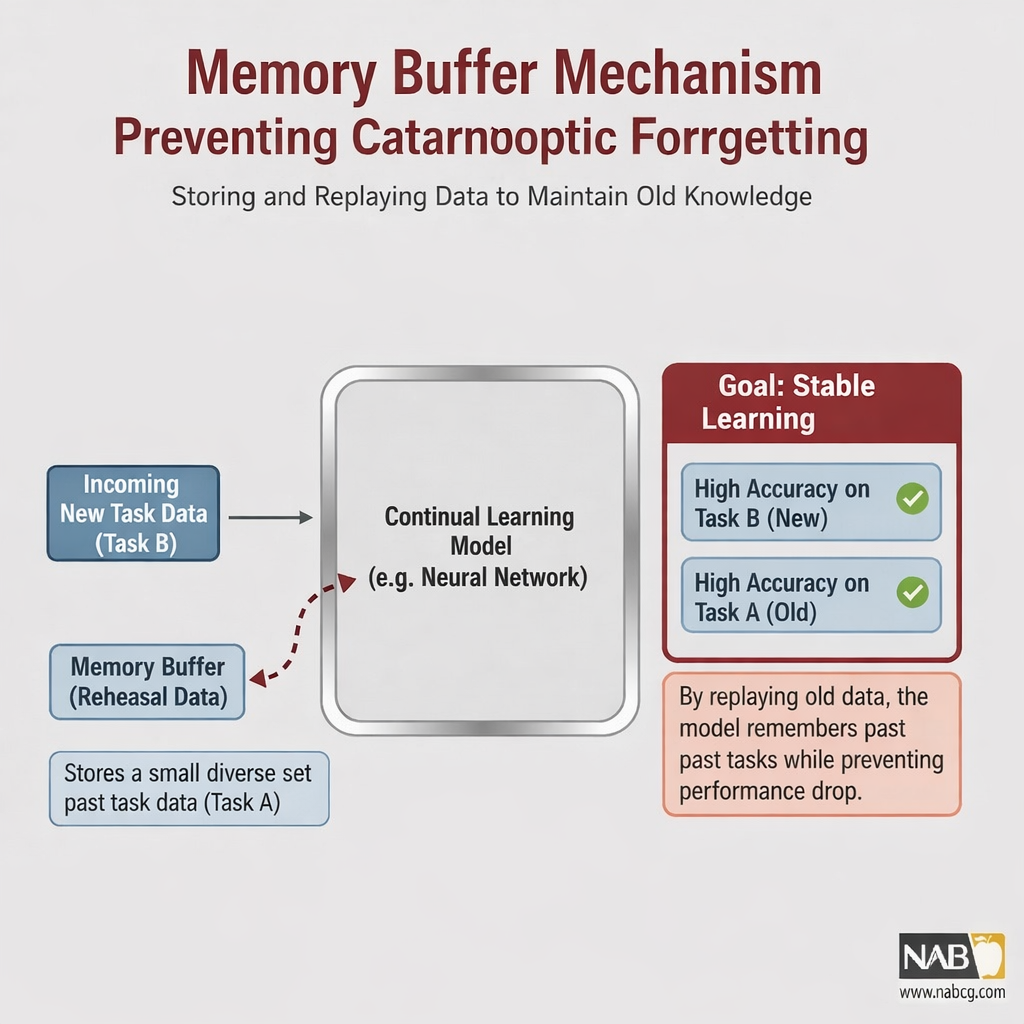
۸. جابجایی وظایف: حرکت به سمت چالش بعدی با مدیریت دقیق تعادل میان انطباقپذیری (Plasticity) و پایداری (Stability).
۹. یادگیری تکرارشونده: تکرار چرخهای فرآیند برای هر وظیفه نوظهور، جهت تقویت مستمر قدرت تعمیمپذیری و بلوغ شبکه عصبی.
۱۰. پایش مداوم: زیر نظر گرفتن دقیق نشانههای فراموشی فاجعهبار و اصلاحِ فوری استراتژیهای بازپخش در صورت مشاهده افت عملکرد.
۱۱. تنظیم فوقپارامترها: بهینهسازی حساس نرخ یادگیری (Learning Rate) برای اعمال تغییرات نرم و محافظت از ساختار دانش تثبیتشده.
۱۲. استقرار(Deployment): ورود به دنیای واقعی، جایی که مدل به عنوان یک موجودیت پویا، یادگیری مادامالعمر و تکامل بیپایان خود را آغاز میکند.
.
7.مطالعه موردی: دستیار هوشمند “Smart-Office”
این سناریو نشان میدهد که چگونه یک مدل از دانش عمومی به تخصص حرفهای میرسد، بدون آنکه مهارتهای قبلی خود را قربانی کند:
- مقداردهی اولیه: شروع کار با یک مدل زبانی بزرگ (LLM) پیشآموزش دیده که قواعد نگارش و گرامر عمومی را بهخوبی میداند.
- توالیبندی وظایف: تعیین نقشه راه یادگیری؛ ابتدا پاسخ به ایمیل، سپس تنظیم جلسات و در نهایت تحلیل مالی.
- آموزش روی وظیفه جاری: تمرکز بر یادگیری لحن رسمی و عبارات اداری در مکاتبات به عنوان اولین تخصص.
- تنظیمگری: هنگام یادگیری وظیفه دوم (تقویم)، الگوریتم EWC وزنهای مربوط به لحن رسمی را منجمد میکند تا دانش قبلی تخریب نشود.
- تقطیر دانش: نظارت نسخه استاد بر نسخه شاگرد در فاز سوم (تحلیل مالی) برای انتقال صحیح تخصصهای انباشته شده.
- آزمون و ارزیابی: سنجش مدل پس از هر مرحله؛ مثلاً بررسی اینکه آیا پس از یادگیری تحلیل مالی، هنوز میتواند ایمیل رسمی بزند؟
- ذخیرهسازی هوشمند: نگهداری الگوهای کلیدی وظایف قبلی در یک بافر حافظه (Replay Buffer) جهت یادآوری و مرور دورهای مدل.
- سوئیچینگ: توانمندسازی مدل برای تشخیص موقعیت و جابجایی هوشمندانه بین مودهای عملیاتی (مثلاً از اکسل به ایمیل).
- یادگیری تکرارشونده: بهروزرسانی مداوم دانش (مثل قوانین جدید مالیاتی) بدون آسیب به ساختار دانش تثبیتشده قبلی.
- پایش و انطباق: شناسایی نشانههای فراموشی در کار با تقویم و تقویت مکانیزم Replay برای بازیابی خاطرات فنی.
- تنظیم فوقپارامترها: کاهش نرخ یادگیری (Learning Rate) برای اعمال تغییرات بسیار نرم و حفظ پایداری شبکه عصبی.
- استقرار نهایی: ورود دستیار به محیط کار و تبدیل شدن به یک موجودیت پویا که از فیدبک کاربران برای تکامل همیشگی بهره میبرد.
.
8.ابزارهای پیادهسازی (Practical Tools)
- Avalanche : این کتابخانه، آچار فرانسه یادگیری پیوسته است. Avalanche مجموعهای جامع از الگوریتمها، دیتاستها و معیارهای ارزیابی را فراهم میکند تا توسعهدهندگان مجبور نباشند چرخ را از اول اختراع کنند.
- Continuum: اگر چالش اصلی شما مدیریت جریانهای دادهای (Data Streams) و نحوه بارگذاری سناریوهای مختلف (مثل جابجایی کلاسها یا دامنهها) است، Continuum بهترین انتخاب برای ساختاردهی به ورودیهای مدل است.
.
9.پیادهسازی عملی با پایتون
در این بخش، پدیده فراموشی فاجعهبار (Catastrophic Forgetting) را با یک سناریوی ساده روی دیتاست اعداد (MNIST) بررسی میکنیم.
گامهای پیادهسازی:
- آموزش وظیفه ۱: مدل را آموزش میدهیم تا اعداد زوج را شناسایی کند.
- تست اولیه: دقت مدل را روی اعداد زوج میسنجیم (دقت باید بالا باشد).
- آموزش وظیفه ۲: بدون تمهیدات یادگیری پیوسته، مدل را روی اعداد فرد آموزش میدهیم.
- تست نهایی (فاجعه): دوباره دقت مدل را روی اعداد زوج چک میکنیم. خواهید دید که مدل به شکل فاجعهباری دانش قبلی را فراموش کرده است!
کد پایتون:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset, ConcatDataset
import numpy as np
# ۱. تنظیمات و مدل (Initialization)
class SmallBrain(nn.Module):
def __init__(self):
super(SmallBrain, self).__init__()
self.main = nn.Sequential(
nn.Linear(784, 100), nn.ReLU(),
nn.Linear(100, 10)
)
def forward(self, x): return self.main(x.view(-1, 784))
def get_accuracy(model, loader):
correct, total = 0, 0
model.eval()
with torch.no_grad():
for data, target in loader:
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
return 100 * correct / total
# ۲. آمادهسازی دادهها (Task Sequencing)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_set = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_set = datasets.MNIST('./data', train=False, download=True, transform=transform)
# جداسازی وظایف: وظیفه ۱ (0,2,4,6,8) | وظیفه ۲ (1,3,5,7,9)
evens = [i for i, (_, l) in enumerate(train_set) if l % 2 == 0]
odds = [i for i, (_, l) in enumerate(train_set) if l % 2 != 0]
test_evens = DataLoader(Subset(test_set, [i for i, (_, l) in enumerate(test_set) if l % 2 == 0]), batch_size=64)
loader_task1 = DataLoader(Subset(train_set, evens), batch_size=64, shuffle=True)
loader_task2 = DataLoader(Subset(train_set, odds), batch_size=64, shuffle=True)
# ۳. آموزش وظیفه ۱
model = SmallBrain()
optimizer = optim.Adam(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
print("گام ۱: آموزش وظیفه ۱ (اعداد زوج)...")
for data, target in loader_task1:
optimizer.zero_grad(); criterion(model(data), target).backward(); optimizer.step()
acc1_after_t1 = get_accuracy(model, test_evens)
print(f"دقت روی وظیفه ۱: {acc1_after_t1:.2f}%")
# ۴. ذخیرهسازی هوشمند (Replay Buffer) - ذخیره ۲۰۰ نمونه از وظیفه ۱
replay_buffer = Subset(train_set, evens[:200])
# ۵. آموزش وظیفه ۲ (بدون Replay vs با Replay)
print("\nگام ۲: آموزش وظیفه ۲ (اعداد فرد) + استفاده از Replay Buffer...")
# ترکیب دادههای جدید با بافر حافظه
combined_dataset = ConcatDataset([Subset(train_set, odds), replay_buffer])
loader_combined = DataLoader(combined_dataset, batch_size=64, shuffle=True)
for data, target in loader_combined:
optimizer.zero_grad(); criterion(model(data), target).backward(); optimizer.step()
# ۶. ارزیابی نهایی
acc1_after_t2 = get_accuracy(model, test_evens)
print(f"دقت روی وظیفه ۱ بعد از یادگیری وظیفه ۲: {acc1_after_t2:.2f}%")
if acc1_after_t2 > 80:
print("\n[نتیجه نهایی]: یادگیری پیوسته موفقیتآمیز بود. بافر حافظه مانع فراموشی شد.")
else:
print("\n[نتیجه نهایی]: فراموشی فاجعهبار رخ داد.")
خروجی:

.
10.کاربردها
.
سیستمهای تشخیص کلاهبرداری بانکی (Fraud Detection)
روشهای کلاهبرداری همگام با تکنولوژی تغییر میکنند. یک مدل تشخیص ناهنجاری که دیروز دقیق بود، ممکن است امروز در برابر یک الگوی حمله جدید (Zero-day) ناتوان باشد.
.
پردازش زبان طبیعی و چتباتها
زبان انسان زنده است؛ کلمات جدید، اصطلاحات روز و موضوعات داغ خبری مدام در حال تغییر هستند.
- کاربرد: مدلهای زبانی بزرگ (LLMs) برای اینکه بهروز بمانند، نیاز به یادگیری پیوسته دارند. به جای اینکه هر هفته یک مدل ۱۰۰ میلیارد پارامتری را از ابتدا آموزش دهیم، با یادگیری پیوسته فقط بخشهای خاصی از شبکه را با اطلاعات جدید (مثلاً اخبار روز) بهروزرسانی میکنیم.
.
پلتفرمهای استریم و سیستمهای توصیهگر (Personalization)
سلیقه کاربران به مرور زمان تغییر میکند. کاربری که پارسال به فیلمهای اکشن علاقه داشت، ممکن است امسال به مستندهای علمی علاقهمند شود.
- پیادهسازی: در پلتفرمهایی مثل نتفلیکس یا یوتیوب، از یادگیری پیوسته استفاده میکنند تا پروفایل کاربر را به صورت لحظهای و بدون از دست دادن تاریخچه کلی علایق او، با ترجیحات جدیدش تطبیق دهند.
.
اینترنت اشیا و دستگاههای Edge
بسیاری از دستگاهها مثل ساعتهای هوشمند یا حسگرهای صنعتی، دسترسی همیشگی به سرورهای قدرتمند برای بازآموزی ندارند.
- بهرهوری:در اینجا یادگیری پیوسته به دستگاه اجازه میدهد روی خودِ سختافزار (On-device) و با مصرف انرژی بسیار کم، از دادههای محیطی یاد بگیرد. این روش حریم خصوصی را حفظ میکند و سرعت پاسخگویی را بهشدت افزایش میدهد.
.
11.مطالعه موردی: سیستم هوشمند شناسایی کلاهبرداری (Fraud Detection)
در این بخش، ما سناریوی بانکی را در دو فاز اجرا میکنیم.
گامهای پیادهسازی بصری:
- Phase 1: آموزش روی الگوی قدیمی (کارت به کارت).
- Phase 2 (Naive): آموزش روی الگوی جدید بدون هیچ تمهیدی (مشاهده فاجعه).
- Phase 2 (Replay): آموزش روی الگوی جدید به همراه بافر حافظه (مشاهده پایداری).
- Visualizing: رسم نمودار میلهای برای مقایسه دقت در هر سه حالت.
کد کامل پایتون :
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# تنظیمات استایل nabcg
GOLD = '#FFD700' # Active Gold
CRIMSON = '#DC143C' # Crimson
BLUE = '#87CEEB' # AI Soft Blue
# ۱. طراحی مدل تشخیص کلاهبرداری
class FraudNet(nn.Module):
def __init__(self):
super(FraudNet, self).__init__()
self.fc = nn.Sequential(nn.Linear(20, 64), nn.ReLU(), nn.Linear(64, 2))
def forward(self, x): return self.fc(x)
# ۲. ایجاد دادههای مصنوعی برای دو نوع کلاهبرداری
def get_data(task_id):
# هر تسک الگوهای توزیع متفاوتی دارد
data = torch.randn(1000, 20) + (task_id * 2)
labels = torch.full((1000,), task_id).long()
return data, labels
t1_data, t1_label = get_data(0) # کارت به کارت
t2_data, t2_label = get_data(1) # درگاه آنلاین
def train_and_eval(model, data, label, test_data, test_label):
opt = optim.Adam(model.parameters(), lr=0.01)
crit = nn.CrossEntropyLoss()
for _ in range(50):
opt.zero_grad(); crit(model(data), label).backward(); opt.step()
with torch.no_grad():
pred = model(test_data).argmax(1)
acc = (pred == test_label).float().mean().item()
return acc * 100
# ۳. اجرای سناریوها
# سناریوی اول: فقط آموزش روی تسک ۱
model_safe = FraudNet()
acc_t1_init = train_and_eval(model_safe, t1_data, t1_label, t1_data, t1_label)
# سناریوی دوم: آموزش تسک ۲ بدون محافظت (فراموشی فاجعهبار)
acc_t1_forget = train_and_eval(model_safe, t2_data, t2_label, t1_data, t1_label)
# سناریوی سوم: استفاده از Replay Buffer (یادگیری پیوسته)
model_cl = FraudNet()
train_and_eval(model_cl, t1_data, t1_label, t1_data, t1_label) # آموزش اولیه
# ترکیب دادههای تسک ۲ با ۱۰٪ از دادههای تسک ۱ (بافر حافظه)
replay_data = torch.cat([t2_data, t1_data[:100]])
replay_label = torch.cat([t2_label, t1_label[:100]])
acc_t1_replay = train_and_eval(model_cl, replay_data, replay_label, t1_data, t1_label)
# ۴. خروجی بصری
labels = ['Initial Task 1', 'After Task 2 (Forget)', 'After Task 2 (Replay)']
values = [acc_t1_init, acc_t1_forget, acc_t1_replay]
colors = [BLUE, CRIMSON, GOLD]
plt.figure(figsize=(10, 6))
bars = plt.bar(labels, values, color=colors)
plt.ylabel('Accuracy (%) on Task 1')
plt.title('Continual Learning Performance: Banking Fraud Case Study')
plt.ylim(0, 110)
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval + 2, f'{yval:.1f}%', ha='center', fontweight='bold')
plt.show()
print(f"خروجی نهایی:")
print(f"دقت اولیه: {acc_t1_init}% | دقت پس از فراموشی: {acc_t1_forget}% | دقت با یادگیری پیوسته: {acc_t1_replay}%")
خروجی:
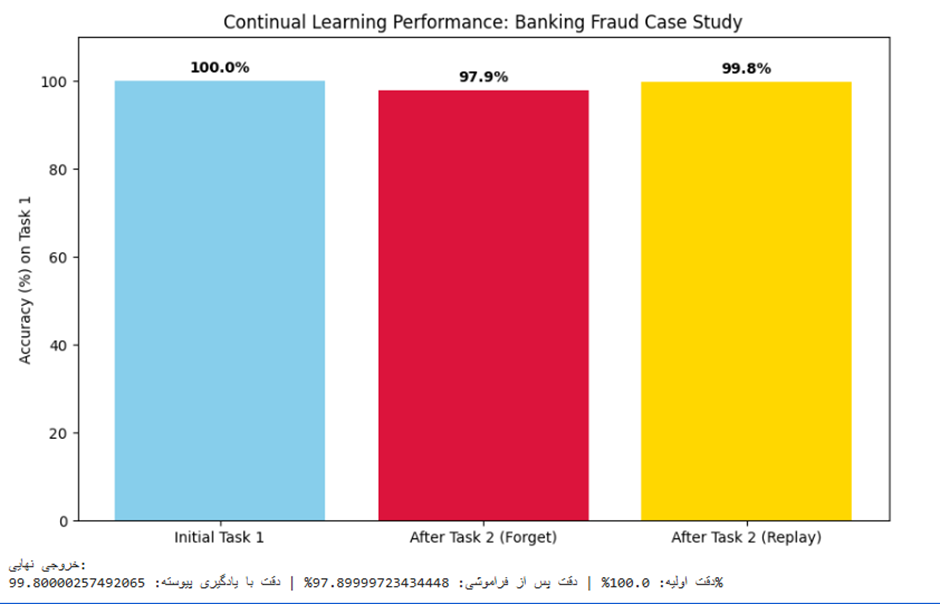
.
12.مزایا
- انطباقپذیری (Adaptability)
در محیطهای پویا که دادهها مدام در حال تغییر هستند، مدلهای ایستا خیلی زود کارایی خود را از دست میدهند. یادگیری پیوسته به مدل اجازه میدهد تا همگام با تغییرات محیط، تکامل یابد. این ویژگی در حوزههایی مانند رباتیک خودگردان و درک زبان طبیعی که در آنها مفاهیم و رفتارها ثابت نیستند، یک ضرورت حیاتی است.
- بهرهوری (Efficiency)
در روشهای سنتی، برای اضافه کردن یک دانش جدید، باید کل مدل را از ابتدا (Scratch) با تمام دادههای قبلی و جدید بازآموزی کرد. یادگیری پیوسته با امکان بهروزرسانی تدریجی، نیاز به محاسبات سنگین را از بین میبرد. این یعنی صرفهجویی عظیم در منابع محاسباتی (GPU) و زمان که در پروژههای بزرگ به معنای کاهش هزینههای هنگفت است.
- کاهش نیاز به ذخیرهسازی داده
با استفاده از تکنیکهایی مانند Generative Replay (بازپخش زایشی)، دیگر نیازی به نگهداری پتابایتها دادهی تاریخی و قدیمی نیست. در این روش، مدل یاد میگیرد که دادههای گذشته را بازسازی کند. این امر پیادهسازی هوش مصنوعی را در دستگاههای با منابع محدود (مثل ساعتهای هوشمند یا گجتهای اینترنت اشیا) ممکن میسازد.
.
13.چالشها
- فراموشی فاجعهبار (Catastrophic Forgetting)
حتی با پیشرفتهترین متدهای اصلاحی، شبکههای عصبی همچنان در خطر فراموشی فاجعهبار هستند. این پدیده یعنی مدل با یادگیریِ هر وظیفه جدید، به تدریج مهارتهای قبلی خود را از دست میدهد. درست مثل انسانی که با یادگیری یک زبان جدید، لغات زبان مادریاش را فراموش کند!
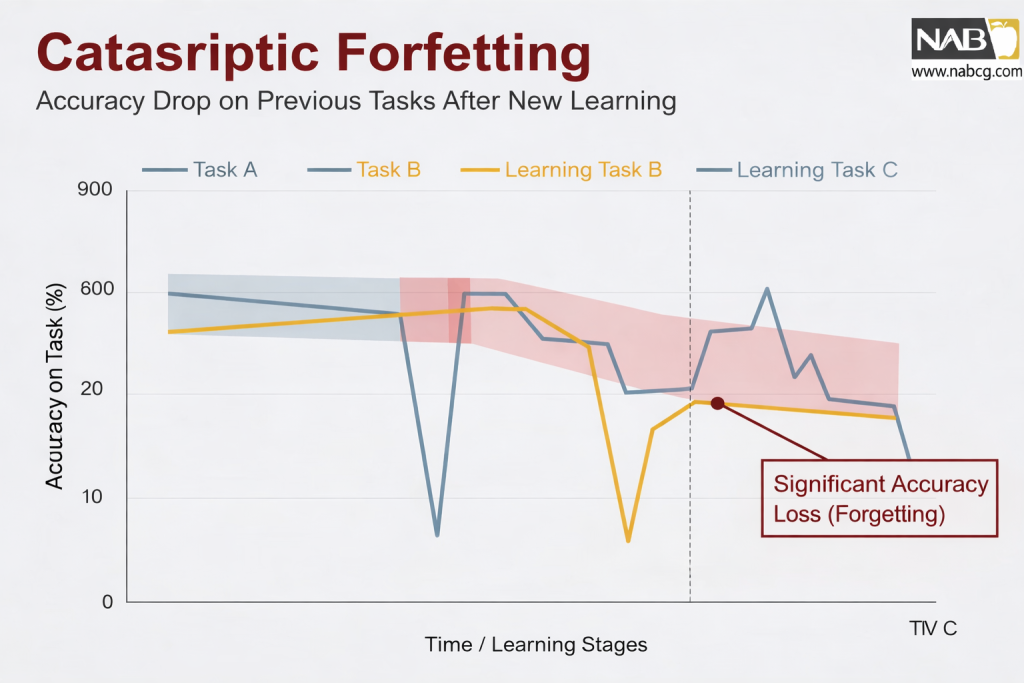
- بیشبرازش روی دادههای قدیمی
برخی روشها برای جلوگیری از فراموشی، بیش از حد بر حفظ دادههای قدیمی تمرکز میکنند. این کار باعث میشود مدل روی گذشته قفل شود (Overfit) و نتواند انعطافپذیری لازم برای یادگیری وظایف یا دامنههای (Domains) جدید را داشته باشد. این عدم تعمیمپذیری، هوش مصنوعی را در گذشته متوقف میکند.
- چالش مقیاسپذیری
با گذشت زمان و انباشت دانش، مدل بزرگتر و سنگینتر میشود. افزایش حجم مدل و نیاز به توان محاسباتی (Computational Requirements) بالا، مقیاسپذیری سیستم را به چالش میکشد. مدیریتِ رشدِ مدل به گونهای که سرعت و کارایی آن فدای دانشِ بیشتر نشود، یک هنر مهندسی است.
جمع بندی
یادگیری پیوسته (Continual Learning) میکوشد هوش مصنوعی را به شیوه یادگیری انسان نزدیک کند؛ یعنی مدلها بتوانند همزمان با کار کردن و دریافت دادههای جدید، خود را بهروز کنند و رشد نمایند. مسئله اصلی در این مسیر، حفظ تعادل بین دو ویژگی مهم است:
- انطباقپذیری (Plasticity): یادگیری سریع اطلاعات جدید
- پایداری (Stability): حفظ دانشهای قبلی و جلوگیری از فراموشی
یک سیستم یادگیری پیوسته موفق، بدون بازآموزی کامل و بدون ذخیرهسازی همه دادههای گذشته، دانش جدید را جذب میکند و در عین حال از فراموشی فاجعهبار جلوگیری میکند.
در این رویکرد، ارزیابی مدل فقط به «دقت نهایی» محدود نیست. متریکهایی مثل ACC، AF، BWT و FWT نشان میدهند مدل در طول زمان چقدر پایدار مانده، چقدر فراموش کرده و آیا یادگیریهای جدید به دانش قبلی کمک کردهاند یا نه. همچنین روشهایی مثل Regularization، استفاده از Replay Buffer و Distillation از ابزارهای کلیدی برای کاهش فراموشی و حفظ عملکرد مدل هستند.
در نهایت، اگر هدف ما ساخت سیستمهای هوشمندِ قابلاعتماد در دنیای واقعی است، «یادگیری مادامالعمر» یکی از پایههای اصلی آینده هوش مصنوعی خواهد بود.