

1.مقدمه
یادگیری گروهی (Ensemble Learning) یکی از قدرتمندترین رویکردها در یادگیری ماشین است که بر یک ایده ساده اما بسیار مؤثر استوار است: «چند مدل معمولی، وقتی هوشمندانه با هم ترکیب شوند، میتوانند از یک مدل قویِ تنها بهتر عمل کنند.» در بسیاری از مسائل واقعی، یک مدل منفرد ممکن است دچار بیشبرازش (Overfitting)، کمبرازش (Underfitting) یا نوسان بالا در پیشبینی شود. یادگیری گروهی با ترکیب چندین مدل پایه (Base Learners) تلاش میکند خطا را کاهش دهد، پایداری را افزایش دهد و عملکرد کلی سیستم را بهبود بخشد.
این رویکرد بهویژه در رقابتهای علم داده، سیستمهای مالی، تشخیص تقلب، پزشکی و موتورهای توصیهگر بهطور گسترده استفاده میشود. دلیل محبوبیت آن این است که بدون نیاز به اختراع یک الگوریتم کاملاً جدید، میتوان با ترکیب هوشمندانه مدلهای موجود، به نتایج دقیقتر و قابلاعتمادتر رسید.
در این مقاله ابتدا مفهوم یادگیری گروهی و ارتباط آن با تحلیل بایاس–واریانس را بررسی میکنیم، سپس سه استراتژی اصلی آن یعنی Bagging، Boosting و Stacking را بهصورت مفهومی و عملی تحلیل میکنیم. در ادامه نیز با مثالهای صنعتی و پیادهسازی در پایتون، نحوه استفاده از این تکنیک در مسائل واقعی را مشاهده خواهیم کرد.
2.تعریف
در مهندسی یادگیری ماشین، یک اصلِ بنیادی وجود دارد: یک دست صدا ندارد، اما هزاران دست غوغا میکنند! یادگیری گروهی یا Ensemble Learning دقیقاً از همین منطق انسانی الهام گرفته است. در دنیای واقعی، ما برای جراحیهای حساس یا تصمیمات استراتژیک، به نظر یک پزشک یا یک مشاور بسنده نمیکنیم؛ بلکه یک کمیته تشکیل میدهیم.
یادگیری گروهی نیز دقیقاً همین خرد جمعی (Wisdom of the Crowd) را وارد دنیای الگوریتمها میکند. این تکنیک بهجای تکیه بر یک مدل واحد (مثل یک شبکه عصبی یا یک درخت تصمیم تنها)، چندین مدل یادگیرنده را با هم ترکیب میکند تا سیستمی بسازد که دقت و اعتمادپذیری آن فراتر از توانِ تکتک اعضایش باشد.
3.اصطلاحات کلیدی
برای درک عمیق این مبحث، باید با سه نقش اصلی در این سناریو آشنا شویم:
۱. یادگیرنده پایه (Base Learner)
به هر کدام از مدلهای تکنفرهای که در ساختار گروهی استفاده میشوند، یادگیرنده پایه، مدل پایه یا تخمینگر پایه میگویند. اینها در واقع اعضای تیم ما هستند.
۲. یادگیرنده ضعیف (Weak Learner)
اینها مدلهایی هستند که عملکردشان کمی بهتر از شانس تصادفی است.
- تعریف فنی: در یک مسئله طبقهبندی دوتایی (مثلاً تشخیص شیر یا خط)، اگر مدلی حدود ۵۰٪ دقت داشته باشد (یعنی شانسی عمل کند)، یک یادگیرنده ضعیف است.
- مثال: فرض کنید مدلی دارید که میخواهد پیشبینی کند فردا باران میآید یا نه. اگر این مدل فقط با پرتاب سکه بگوید بله یا خیر، یک یادگیرنده ضعیف است. اما در یادگیری گروهی، ما با تکنیکهایی (مثل Boosting) همین مدلهای ضعیف را با هم ترکیب میکنیم تا یک مدل قوی بسازیم.
.
۳. یادگیرنده قوی (Strong Learner)
این مدلها عملکرد پیشبینی فوقالعادهای دارند.
- تعریف فنی: در همان مسئله دوتایی، اگر دقت مدل ۸۰٪ یا بیشتر باشد، یک یادگیرنده قوی محسوب میشود. هدف نهایی یادگیری گروهی این است که مجموعهای از مدلهای ضعیف یا متوسط را به یک یادگیرنده قوی تبدیل کند.
.
4.چرا یادگیری گروهی مهم است ؟ معمای بایاس و واریانس
یادگیری گروهی (Ensemble Learning) فقط برای افزایش دقت نیست؛ بلکه راهحلی هوشمندانه برای یکی از قدیمیترین و سختترین چالشهای یادگیری ماشین است: مبادله بایاس و واریانس. (Bias-Variance Tradeoff)
در دنیای مدلسازی، ما همیشه با سه نوع خطا روبرو هستیم که مجموع آنها خطای کل مدل را میسازد . هنر یادگیری گروهی این است که بین این خطاها تعادل ایجاد کند. بیایید آنها را بشناسیم:
۱. بایاس (Bias)
بایاس میانگینِ اختلاف بین پیشبینیهای مدل و مقادیر واقعی است.
- بایاس بالا: وقتی بایاس زیاد باشد، یعنی مدل الگوهای داده را یاد نگرفته است. (Underfitting) در این حالت، دقت مدل روی دادههای آموزشی پایین است.
- هدف: تلاش برای کاهش بایاس را بهینهسازی (Optimization) میگویند.
- مثال: دانشجویی که اصلاً درس نخوانده و سر جلسه امتحان به همه سوالات پاسخ یکسان (مثلاً گزینه “الف”) میدهد. او بایاس دارد و نمرهاش کم میشود.
.
۲. واریانس (Variance)
واریانس میزان تغییرات و پراکندگیِ پیشبینیهای مدل را در شرایط مختلف نشان میدهد.
- واریانس بالا :وقتی واریانس زیاد باشد، یعنی مدل دادههای آموزشی را حفظ کرده (Overfitting). در این حالت، روی دادههای آموزشی عالی عمل میکند، اما روی دادههای جدید (تست) عملکردش افتضاح است.
- هدف: تلاش برای کاهش واریانس را تعمیمپذیری میگویند.
- مثال: دانشجویی که کل کتاب را طوطیوار حفظ کرده است. اگر سوال عین کتاب باشد، عالی جواب میدهد؛ اما اگر استاد سوال را کمی بپیچاند (داده جدید)، دانشجو گیج میشود و غلط مینویسد.
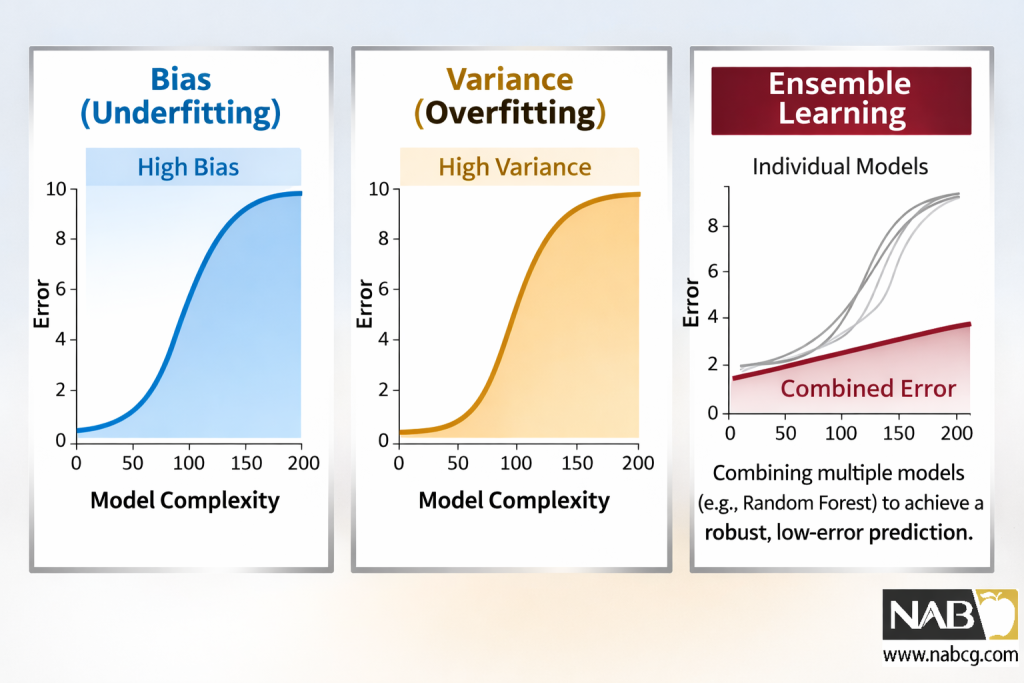
۳. خطای کاهشناپذیر (Irreducible Error)
این بخش سومِ خطای کل است.
- معنی ساده: این خطا ناشی از نویز و تصادفی بودنِ ذاتیِ خودِ دادههاست. هیچ مدلی (حتی بهترین مدل جهان) نمیتواند این خطا را از بین ببرد، چون طبیعتِ دنیا غیرقابلپیشبینی است.
.
فرمول طلایی خطای مدل
رابطه بین این سه عامل به صورت زیر تعریف میشود:
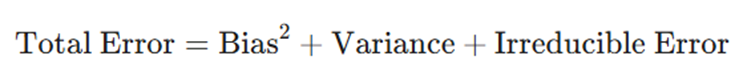
.
5.یادگیری گروهی چگونه کار میکند؟
این یادگیری بر پایهی این فرضیه بنا شده است که خرد جمعی (Wisdom of the Crowd) میتواند سوگیریها و خطاهای فردی مدلها را خنثی کند. در این استراتژی، هدف نهایی تبدیل مجموعهای از یادگیرندههای ضعیف (مدلهایی با دقت اندک) به یک سیستم پیشبینیکننده استوار و دقیق است.
این فرآیند در چهار سطح استراتژیک مدیریت میشود:
- معماری تیم و استراتژی تنوع (Diversity)
- فرآیند آموزش و مدیریت خطا (Bias vs Variance)
- مکانیسمهای اجماع و تصمیمگیری نهایی
- فرآیند Stacking و یادگیری لایه دوم (Meta-Learning)
.
معماری تیم و استراتژی تنوع (Diversity)
موفقیت یک سیستم گروهی مستقیماً به میزان تنوع اعضای آن بستگی دارد؛ چرا که اگر همهی مدلها اشتباه مشابهی مرتکب شوند، ترکیب آنها خروجی مفیدی نخواهد داشت.
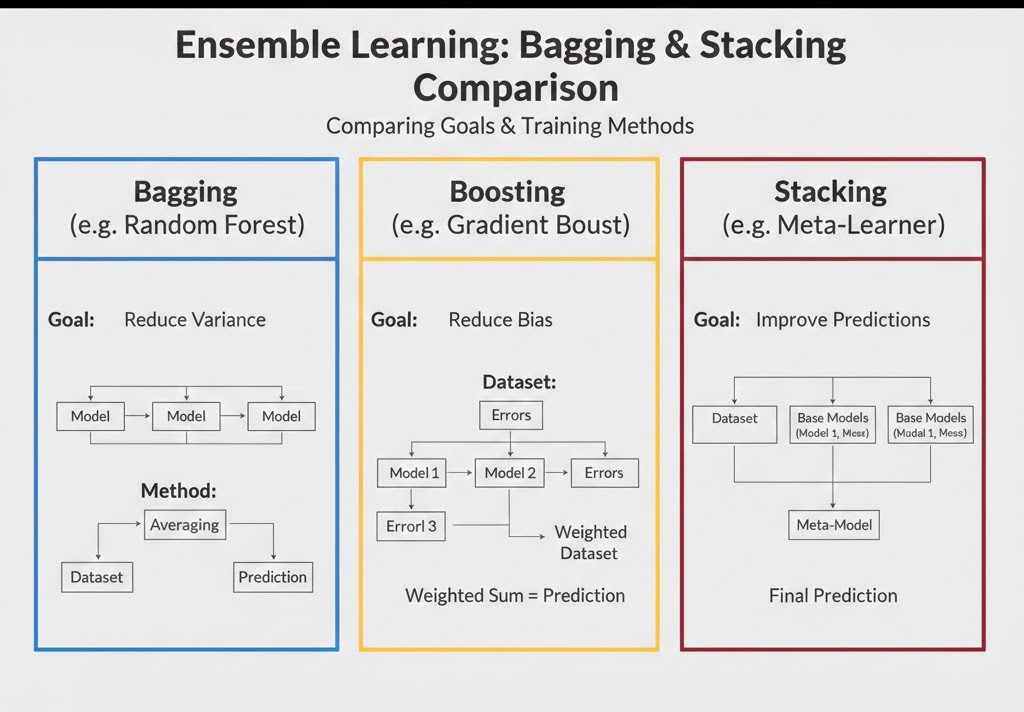
- تیم همگن(Homogeneous): در این ساختار، از چندین نسخه از یک الگوریتم واحد (معمولاً درختهای تصمیم) استفاده میشود. تنوع در اینجا نه از طریق نوع الگوریتم، بلکه با تغییر در دادههای ورودی ایجاد میشود (مانند آنچه در Random Forest رخ میدهد) تا هر مدل بخش متفاوتی از فضا را تحلیل کند.
- تیم ناهمگن(Heterogeneous): این رویکرد از الگوریتمهایی با ماهیت ریاضی متفاوت)ترکیب SVM، رگرسیون لجستیک و شبکههای عصبی) بهره میبرد. هدف این است که نقاط کور مدلهای خطی توسط انعطافپذیری مدلهای غیرخطی پوشش داده شود تا سیستم در برابر دادههای ناشناخته، پایداری بیشتری داشته باشد.
.
فرآیند آموزش و مدیریت خطا (Bias vs Variance)
در مهندسی یادگیری ماشین، دو منبع اصلی شکست وجود دارد: بایاس (سادهانگاری بیش از حد) و واریانس (حساسیت بیش از حد به نویز). یادگیری گروهی با دو رویکرد زیر این خطاها را مهار میکند:
الف) رویکرد موازی (Parallel)– تکنیک Bagging
این روش بر کاهش واریانس و جلوگیری از بیشبرازش (Overfitting) تمرکز دارد.
- تکنیک:Bootstrap Aggregation دادهها به صورت تصادفی و با جایگذاری تقسیم میشوند. این یعنی یک داده ممکن است در آموزش چندین مدل حضور داشته باشد و برخی دادهها اصلاً دیده نشوند که خود معیاری برای اعتبارسنجی مدل است.
- استقلال محاسباتی: به دلیل عدم ارتباط مدلها با یکدیگر، فرآیند آموزش میتواند به صورت موازی بر روی چندین هسته پردازشی اجرا شود که سرعت عملیاتی را به شکل چشمگیری افزایش میدهد.
.
ب) رویکرد متوالی (Sequential)– تکنیک Boosting
این روش بر کاهش بایاس و ارتقای دقت مدلهای ساده تمرکز دارد.
- وزندهی تطبیقی: در هر گام، دادههایی که مدلهای قبلی در تشخیص آنها ناکام بودهاند، اهمیت بیشتری پیدا میکنند.
- زنجیره اصلاحگر: هر مدل جدید موظف است تمرکز خود را بر روی نقاط سخت و چالشبرانگیز بگذارد. این فرآیند باعث میشود الگوریتمهایی مانند XGBoost یا CatBoost در برابر الگوهای پیچیده، عملکردی دقیق داشته باشند.
.
مکانیسمهای اجماع و تصمیمگیری نهایی
پس از اتمام آموزش، چالش اصلی نحوه ترکیب نظرات متفاوت مدلها برای رسیدن به یک واحد منسجم است:
- رأیگیری اکثریت(Hard Voting): هر مدل یک رأی قطعی به یک کلاس میدهد و کلاسی که بیشترین رأی را بیاورد انتخاب میشود.
- رأیگیری نرم(Soft Voting): مدلها میزان احتمال یا اطمینان خود را اعلام میکنند. میانگین این احتمالات معمولاً دقت بالاتری نسبت به رأیگیری سخت فراهم میکند.
- رأیگیری وزنی(Weighted Voting): به مدلهایی که در دوران آزمون دقت بالاتری داشتهاند، حق رأی یا ضریب نفوذ بیشتری داده میشود.
- میانگینگیری(Averaging): در مسائل رگرسیون، از میانگین خروجیها برای حذف اثر دادههای پرت و صیقل دادن پیشبینی نهایی استفاده میشود.
.
فرآیند Stacking و یادگیری لایه دوم (Meta-Learning)
این مرحله پیچیدهترین سطح یادگیری گروهی است که در آن از یک مدل ثانویه برای ترکیب هوشمندانه نتایج استفاده میشود.
- معماری دو لایه: خروجیهای تولید شده توسط مدلهای پایه به عنوان ورودی (Features) برای یک مدل جدید در لایه دوم عمل میکنند.
- مدل ناظر(Meta-Learner): این مدل آموزش میبیند تا الگوهای رفتاری مدلهای لایه اول را بشناسد. برای مثال یاد میگیرد که در چه شرایطی باید به خروجی یک شبکه عصبی بیشتر از یک درخت تصمیم اعتماد کند.
- کاربرد رقابتی: این روش قادر است روابط غیرخطی پنهان میان پیشبینیها را کشف کند و به همین دلیل در رقابتهای بزرگ دادهکاوی، اغلب روش برنده است.
.
6.مثال: سیستم هوشمند تأیید وام بانکی
تصور کنید یک بانک بزرگ برای کاهش ریسک مالی، بهجای تکیه بر قضاوتهای فردی، از معماری پیشرفته Stacking برای اعتبارسنجی متقاضیان وام استفاده میکند. این فرآیند هوشمند در چهار گام استراتژیک اجرا میشود:
گام اول: تشکیل تیم متخصصان پایه
در لایه اول، سه الگوریتم با دیدگاههای متفاوت آموزش میبینند:
۱. رگرسیون لجستیک :تمرکز بر دادههای عددی پایدار مانند درآمد سالانه و سن (تحلیل الگوهای خطی)
۲. جنگل تصادفی(Random Forest): متخصص تحلیل شرایط پیچیده و روابط غیرخطی (مثلاً ترکیبِ داشتن سند ملکی با نوسانات شغلی)
۳. شبکه عصبی عمیق: تحلیل رفتارشناسی دقیق و دادههای غیرساختاریافته (مانند ریزِ تراکنشهای بانکی شش ماه اخیر).
گام دوم: مواجهه با تضاد آرا
فرض کنید برای یک مشتری خاص، نتایج متناقض است: رگرسیون لجستیک به دلیل درآمد بالا رای به «تأیید» میدهد؛ جنگل تصادفی به دلیل سوابق صنفی، رای به «رد» میدهد و شبکه عصبی گزینه «تأیید با احتیاط» را انتخاب میکند. در روشهای سنتی، این آرا هم را خنثی میکنند، اما در Stacking هوشمندی لایه دوم وارد عمل میشود.
گام سوم: مدیریت هوشمند توسط مدل ناظر (Meta-Learner)
در لایه دوم، یک مدل ناظر (مانند XGBoost) قرار دارد که آموزش دیده تا «رفتارِ مدلهای لایه اول» را بشناسد. او آموخته است که مثلاً در شرایط نوسانی بازار مسکن، باید به خروجی جنگل تصادفی بیش از بقیه اعتماد کند.
گام چهارم: تصمیمگیری استراتژیک نهایی
مدل ناظر خروجی هر سه مدل را بهعنوان ورودیهای جدید دریافت میکند. با تشخیص اینکه متقاضی یک «کارآفرین حوزه مسکن» است، او وزنِ اصلی را به پیشبینیِ منفیِ جنگل تصادفی میدهد. نتیجه؟ درخواست وام با هوشمندی رد میشود تا از ضرر احتمالی بانک جلوگیری شود. این یعنی تبدیل تضاد آرا به یک تصمیم دقیق و سودآور.
6.دستهبندی استراتژیک روشهای یادگیری گروهی
یادگیری گروهی بر پایه سه استراتژی بنیادین بنا شده است که هر کدام برای حل چالش مشخصی در دقت مدل (مانند خطای بایاس یا واریانس) طراحی شدهاند. انتخاب میان این روشها، مرز بین یک مدل معمولی و یک سیستم پیشبینی تراز اول را تعیین میکند.
- رویکرد Bagging
- رویکرد Boosting
- رویکرد Stacking
.
رویکرد Bagging؛ تمرکز بر پایداری و موازات
روش Bagging که مخفف Bootstrap Aggregating است، بر اصل دموکراسی و میانگینگیری تمرکز دارد. هدف اصلی این روش، مهار واریانس و جلوگیری از حساسیت بیش از حد مدل به نویزهای داده (Overfitting) است.
- مکانیسم اجرایی: در این روش، دادهها با استفاده از تکنیک Bootstrapping به چندین زیرمجموعه تصادفی تقسیم میشوند. هر مدل به صورت کاملاً مستقل و همزمان روی یکی از این بخشها آموزش میببینند که این امر امکان پردازش موازی و سریع را فراهم میکند.
- الگوریتمهای شاخص:
- Random Forest (جنگل تصادفی): این الگوریتم با ترکیب دهها یا صدها درخت تصمیم و انتخاب تصادفی ویژگیها در هر گره، تنوع مدلها را به حداکثر میرساند تا خروجی نهایی پایداری فوقالعادهای داشته باشد.
- Bagged Decision Trees: استفاده از مجموعهای از درختهای تصمیم ساده برای کاهش خطا و رسیدن به یک میانگین خروجی صیقلیافته.
.
رویکرد Boosting؛ هنر اصلاح و تکامل متوالی
در روش Boosting، تمرکز بر کاهش بایاس و تبدیل مدلهای ساده (Weak Learners) به یک سیستم پیشبینی قدرتمند است. برخلاف روش قبلی، در اینجا مدلها به صورت متوالی (Sequential) و زنجیروار آموزش میبینند.
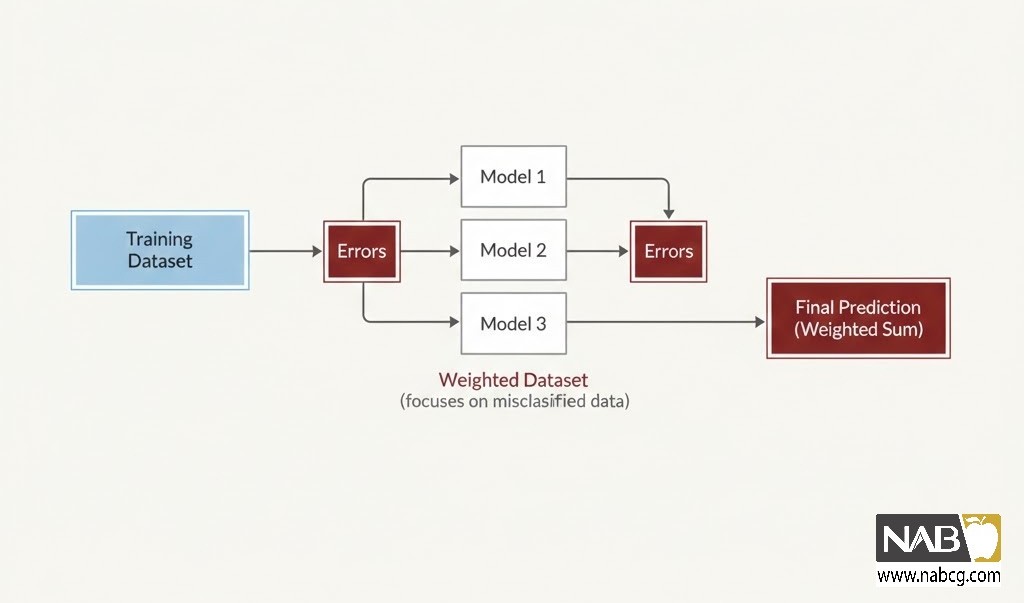
- مکانیسم اجرایی: هر مدل جدید وظیفه دارد اشتباهات مدل قبلی را اصلاح کند. دادههایی که در مرحله قبل اشتباه تشخیص داده شدهاند، وزن بیشتری میگیرند تا مدل جدید تمام توان خود را بر روی این نقاط دشوار بگذارد.
- الگوریتمهای شاخص:
- AdaBoost: پیشگام این حوزه که با تغییر وزن دادههای سخت در هر گام، دقت را ارتقا میدهد.
- XGBoost: نسخهای فوقسریع و بهینهسازی شده که به دلیل پایداری و قدرت بالا، استاندارد طلایی مسابقات دادهکاوی است.
- LightGBM: محصول مایکروسافت که با استفاده از تکنیک رشد برگمحور (Leaf-wise)، سرعت آموزش را به شدت افزایش و مصرف حافظه را کاهش میدهد.
- CatBoost: متخصصی که بدون نیاز به پیشپردازشهای سنگین، دادههای دستهای (Categorical) را به بهترین شکل مدیریت میکند.
.
رویکرد Stacking؛ مدیریت هوشمند و سلسلهمراتبی
روش Stacking از نظر ساختاری پیشرفتهترین رویکرد است؛ چرا که به جای فرمولهای ساده ریاضی، از یک مدلِ ناظر (Meta-Model) برای ترکیب نتایج استفاده میکند.
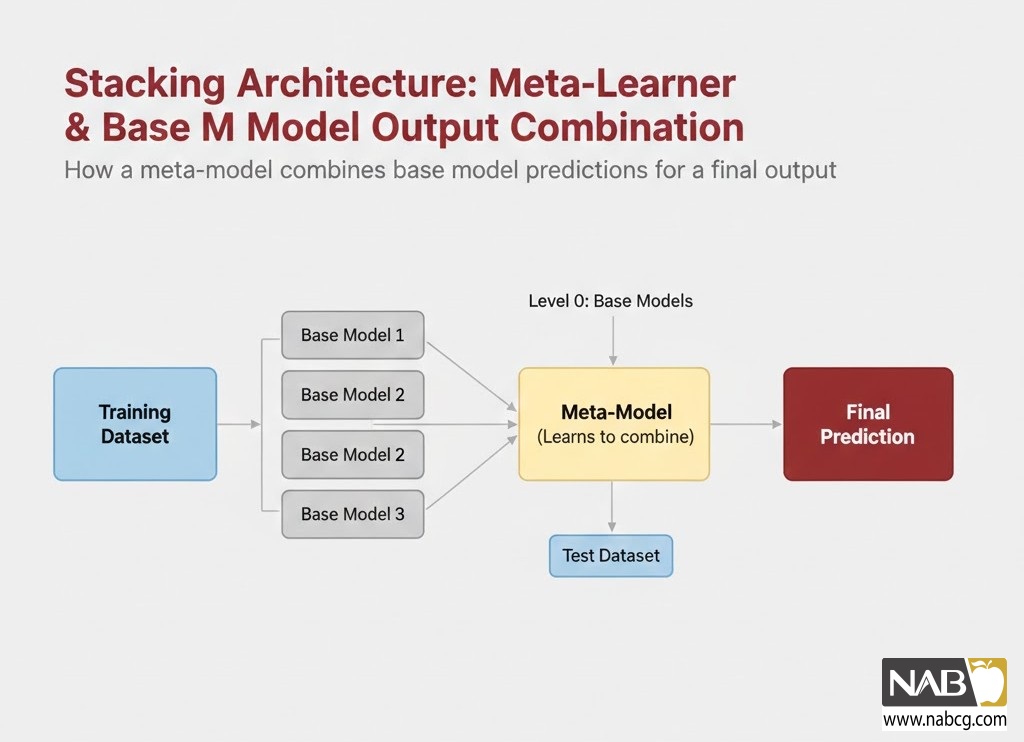
- مکانیسم اجرایی: در لایه اول، چندین مدل متنوع (ناهمگن) مانند SVM و شبکه عصبی آموزش میبینند. در لایه دوم، یک مدل جدید آموزش میبیند تا یاد بگیرد نظرات مدلهای لایه اول را چگونه با هم ترکیب کند.
- انواع پیشرفته:
- Stacking با اعتبارسنجی متقاطع: برای جلوگیری از بیشبرازش در لایه دوم، از تکنیک Cross-Validation استفاده میشود.
- Multi-layer Stacking: ایجاد چندین لایه پیاپی از مدلها که هر لایه خروجیهای لایه قبل را دقیقتر میکند.
.
7.جدول مقایسهای استراتژیک: کدام رویکرد یادگیری گروهی را انتخاب کنیم؟
| ویژگی | Bagging (ثبات و موازات) | Boosting (دقت و تکامل) | Stacking (هوشمندی لایهای) |
| هدف فنی | کاهش واریانس و مهار بیشبرازش (Overfitting)؛ مناسب برای مدلهای پیچیده که به نویز حساساند. | کاهش بایاس و ارتقای دقت؛ تبدیل مدلهای ضعیف به یک ابرمدل قدرتمند و دقیق. | ترکیب نظرات ناهمگن؛ کشف روابط غیرخطی میان پیشبینیهای مدلهای مختلف. |
| نحوه آموزش | موازی و مستقل؛ مدلها هیچ ارتباطی با هم ندارند که باعث سرعت بسیار بالا در پردازش میشود. | متوالی و وابسته؛ هر مدل وظیفه دارد اشتباهات مدل قبلی را اصلاح کند (زنجیره اصلاحگر). | سلسلهمراتبی؛ خروجی مدلهای لایه اول، ورودیِ مدل لایه دوم (Meta-Model) قرار میگیرد. |
| تمرکز بر داده | تکنیک Bootstrap؛ استفاده از نمونهگیری تصادفی با جایگذاری برای ایجاد تنوع در یادگیرندهها. | وزندهی تطبیقی؛ تمرکز ویژه بر روی دادههای سخت و چالشبرانگیز که تشخیص آنها دشوار است. | فراتحلیل؛ مدل ناظر یاد میگیرد که در هر شرایط به کدام مدل پایه اعتماد بیشتری کند. |
| الگوریتم برتر | Random Forest | XGBoost / LightGBM / CatBoost | Meta-Learner Models |
8.از تئوری تا اجرا: اکوسیستم پیادهسازی در پایتون
برای پیادهسازی استراتژیهای یادگیری گروهی، نیازی به بازنویسی الگوریتمها از صفر نیست. زبان پایتون با داشتن کتابخانههای بهینهسازی شده، استاندارد طلایی این حوزه محسوب میشود. برای یک اجرای موفق، ابزارهای زیر در اولویت قرار دارند:
- Scikit-Learn: کتابخانه مرجع برای پیادهسازی روشهای کلاسیک مانند Random Forest، Voting و .Stacking این ابزار به دلیل سادگی و هماهنگی با سایر پکیجها، بهترین نقطه شروع است.
- XGBoost: کتابخانهای اختصاصی برای روش Boosting که به دلیل سرعت و دقت بالا در مسابقات دادهکاوی شهرت جهانی دارد.
- LightGBM: محصول مایکروسافت که برای کار با دادههای حجیم (Big Data) بهینه شده و مصرف حافظه بسیار ناچیزی دارد.
- CatBoost: بهترین انتخاب برای زمانی که دادههای شما شامل دستهبندیهای متنی (Categorical) زیادی است و نمیخواهید زمان زیادی صرف پیشپردازش کنید.
.
9.راهنمای گامبهگام پیادهسازی در پایتون
طبق ساختار مقاله شما، پیادهسازی را در ۵ گام کلیدی انجام میدهیم:
- آمادهسازی دادهها: استفاده از یک مجموعه داده استاندارد برای طبقهبندی.
- ایجاد یادگیرندههای پایه: تعریف مدلهای متنوع (SVM، درخت تصمیم و…).
- پیادهسازی Bagging: استفاده از Random Forest برای کاهش واریانس.
- پیادهسازی Boosting: استفاده از XGBoost برای کاهش بایاس و ارتقای دقت.
- پیادهسازی Stacking: ترکیب هوشمندانه تمام مدلها توسط یک مدل ناظر (Meta-Model).
کد پایتون:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
# ۱. تولید دادههای فرضی (مشابه دادههای واقعی صنعت)
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۲. پیادهسازی Bagging (جنگل تصادفی)
# هدف: کاهش واریانس و جلوگیری از Overfitting
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# ۳. پیادهسازی Boosting (XGBoost)
# هدف: کاهش بایاس و افزایش دقت متوالی
xgb_model = XGBClassifier(use_label_encoder=False, eval_metric='logloss', random_state=42)
xgb_model.fit(X_train, y_train)
xgb_pred = xgb_model.predict(X_test)
# ۴. پیادهسازی Stacking (ترکیب هوشمند)
# تعریف یادگیرندههای پایه (Base Learners)
base_models = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svc', SVC(probability=True, random_state=42))
]
# تعریف مدل ناظر (Meta-Model)
stack_model = StackingClassifier(estimators=base_models, final_estimator=LogisticRegression())
stack_model.fit(X_train, y_train)
stack_pred = stack_model.predict(X_test)
# ۵. خروجی و مقایسه نتایج
print(f"دقت مدل Bagging (Random Forest): {accuracy_score(y_test, rf_pred):.2%}")
print(f"دقت مدل Boosting (XGBoost): {accuracy_score(y_test, xgb_pred):.2%}")
print(f"دقت مدل Stacking (ترکیب مدلها): {accuracy_score(y_test, stack_pred):.2%}")
خروجی:

.
10.مزایا
- کاهش بیشبرازش(Reduction in Overfitting): با تجمیع پیشبینیهای چندین مدل، آنسامبلها میتوانند بیشبرازشی که مدلهای پیچیده تکی ممکن است از خود نشان دهند، کاهش دهند.
- بهبود تعمیمپذیری(Improved Generalization): این روش با به حداقل رساندن واریانس و بایاس، روی دادههای دیدهنشده (Unseen data) بهتر عمل میکند.
- افزایش دقت: ترکیب چندین مدل، دقت پیشبینی بالاتری نسبت به یک مدل واحد ارائه میدهد.
- مقاومت در برابر نویز: با میانگینگیری از پیشبینیهای مدلهای متنوع، اثر دادههای پرت، نویزی یا نادرست تعدیل میشود.
- انعطافپذیری: این روش میتواند با مدلهای متنوعی از جمله درخت تصمیم، شبکههای عصبی و ماشینهای بردار پشتیبان (SVM) کار کند و آنها را بسیار سازگار نماید.
.
11.معایب
- پیچیدگی محاسباتی و هزینه بالا: آموزش همزمان ۱۰۰ مدل (مثل جنگل تصادفی) یا آموزش متوالی آنها (مثل Boosting) به قدرت پردازشی، رم و زمان بسیار بیشتری نسبت به یک مدل تکی نیاز دارد.
- کاهش تفسیرپذیری: توضیح دادن یک درخت تصمیم آسان است (اگر سن < ۲۰ و درآمد < ۱۰… )، اما توضیح دادن نتیجهای که حاصل رأیگیری ۱۰۰۰ درخت مختلف است، برای انسان و مدیران کسبوکار بسیار دشوار است.
- کندی در زمان اجرا (Inference Time): در سیستمهایی که نیاز به پاسخ در میلیثانیه دارند (مثل ترمز اضطراری خودرو)، پردازش تمام مدلهای گروهی ممکن است کند باشد.
.
12.کاربردهای یادگیری گروهی در صنعت
.
فینتک: شناسایی تراکنشهای مشکوک و کلاهبرداری
در صنعت بانکداری، الگوهای کلاهبرداری مدام در حال تغییر هستند و یک مدل ساده نمیتواند همهی آنها را شناسایی کند.
- عملکرد: با استفاده از الگوریتمهای Boosting (مانند XGBoost)، سیستم روی تراکنشهایی که مدلهای قبلی در تشخیص آنها خطا داشتهاند تمرکز میکند.
.
سلامت و پزشکی: تشخیص هوشمند بیماریهای حاد
در حوزهی سلامت، تکیه بر نظر یک مدل واحد ریسک بالایی دارد؛ به همین دلیل از استراتژی خرد جمعی استفاده میشود.
- مطالعه موردی (تشخیص کرونا): در این سیستم، چندین مدل پایه هر کدام روی یک جنبه تمرکز میکنند؛ برای مثال یک مدل صدای سرفه را تحلیل میکند، مدل دیگر علائم بالینی را بررسی کرده و مدل سوم سوابق پزشکی را در نظر میگیرد.
- نتیجه: در نهایت، با استفاده از سیستمهای رأیگیری (Voting) یا Stacking، تمام این نظرات ترکیب شده و تشخیص نهایی با دقتی بسیار بالاتر از یک پزشک یا مدل واحد صادر میشود.
.
تجارت الکترونیک: موتورهای توصیه (Recommendation Systems)
پلتفرمهایی مانند آمازون یا دیجیکالا برای پیشنهاد محصول به کاربران، از یادگیری گروهی بهره میبرند.
- عملکرد: مدلها بر اساس تاریخچه خرید، محصولات مشاهده شده و حتی رفتار کاربران مشابه، پیشبینیهای خود را انجام میدهند.
- نتیجه: ترکیب این پیشبینیها از طریق Bagging باعث میشود پیشنهادات ارائه شده به کاربر کاملاً شخصیسازی شده و پایدار باشند، که مستقیماً منجر به افزایش فروش میشود.
.
موتورهای جستجو: رتبهبندی دقیق محتوا
موتورهای جستجوی مدرن برای تعیین رتبه یک صفحه، از صدها معیار مختلف استفاده میکنند.
- عملکرد: با استفاده از متدهای Gradient Boosting، مدل یاد میگیرد که چگونه فاکتورهایی مثل کلمات کلیدی، اعتبار دامنه و تجربه کاربری را با هم ترکیب کند تا بهترین نتیجه در صدر قرار گیرد.
- مزیت: این روش باعث میشود نتایج جستجو در برابر تلاشهای فریبکارانه (Black-hat SEO) بسیار مقاومتر و دقیقتر عمل کنند.
.
مطالعه موردی ۱: پیشبینی نوسانات بازار بورس (نبرد با نویز)
سناریو: یک شرکت سرمایهگذاری میخواهد جهت حرکت قیمت یک سهم را بر اساس شاخصهای فنی پیشبینی کند. دادههای بازار بورس بسیار نوسانی هستند و مدلهای ساده دچار بیشبرازش میشوند.
چالش: وجود نویزهای شدید و تغییرات لحظهای که باعث میشود یک مدل واحد، الگوهای تصادفی را به جای الگوهای واقعی یاد بگیرد (واریانس بالا).
راهحل نهایی: استفاده از . Random Forest (Bagging) این مدل با میانگینگیری از صدها درخت تصمیم که هر کدام روی بخش متفاوتی از دادهها تمرکز دارند، اثر نویز را خنثی کرده و پیشبینی پایداری ارائه میدهد.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
# شبیهسازی دادههای بورس (سینوسی با نویز شدید)
x = np.linspace(0, 10, 100).reshape(-1, 1)
y = np.sin(x).ravel() + np.random.normal(0, 0.2, 100)
# پیادهسازی Bagging
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(x, y)
y_pred = model.predict(x)
# ترسیم نمودار با پالت رنگی nabcg
plt.figure(figsize=(10, 6))
plt.scatter(x, y, color='#A8A9AD', alpha=0.6, label='Noisy Market Data') # Silver
plt.plot(x, y_pred, color='#DC143C', linewidth=3, label='Ensemble Prediction') # Crimson
plt.title('Stock Price Trend Prediction (Bagging)', color='black')
plt.legend()
plt.show()
خروجی:
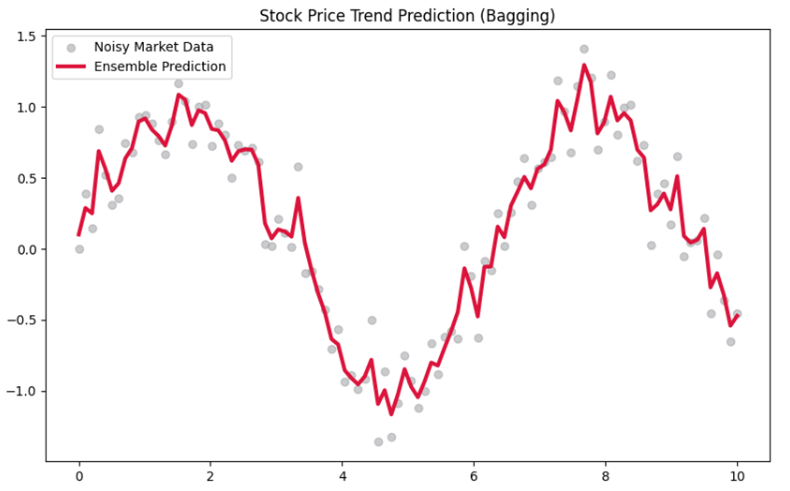
.
مطالعه موردی ۲: امنیت سایبری و تشخیص نفوذ (کشف حملات پنهان)
سناریو: یک مرکز داده (Data Center) با حملات سایبری جدیدی روبروست که از الگوهای پیچیده و پنهان استفاده میکنند. چالش: حملات سایبری معمولاً درصد بسیار کمی از ترافیک شبکه را تشکیل میدهند (خطای بایاس بالا). مدلهای معمولی ترافیکهای مشکوک اما ظریف را نادیده میگیرند.
راهحل نهایی: استفاده از. XGBoost (Boosting)این مدل به صورت زنجیروار کار میکند و در هر مرحله، روی ترافیکهایی که مدل قبلی نتوانسته به عنوان حمله شناسایی کند، تمرکز مضاعف میگذارد.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, classification_report, accuracy_score
from sklearn.datasets import make_classification
# ۱. شبیهسازی دادههای شبکه (نامتوازن: فقط ۵ درصد حملات هستند)
# نمره ویژگیها (Features) نشاندهنده ترافیک شبکه مثل پورت، حجم بسته و... است
X, y = make_classification(n_samples=2000, n_features=10, n_informative=8,
n_redundant=2, weights=[0.95, 0.05], flip_y=0, random_state=42)
# ۲. تقسیم دادهها به بخش آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۳. پیادهسازی Gradient Boosting (بهینه شده برای کاهش بایاس)
# learning_rate پایین و n_estimators بالا به مدل اجازه میدهد با دقت روی خطاها تمرکز کند
gb_security = GradientBoostingClassifier(n_estimators=150, learning_rate=0.05,
max_depth=4, random_state=42)
gb_security.fit(X_train, y_train)
# ۴. پیشبینی و استخراج نتایج
y_pred = gb_security.predict(X_test)
# ۵. خروجی عددی
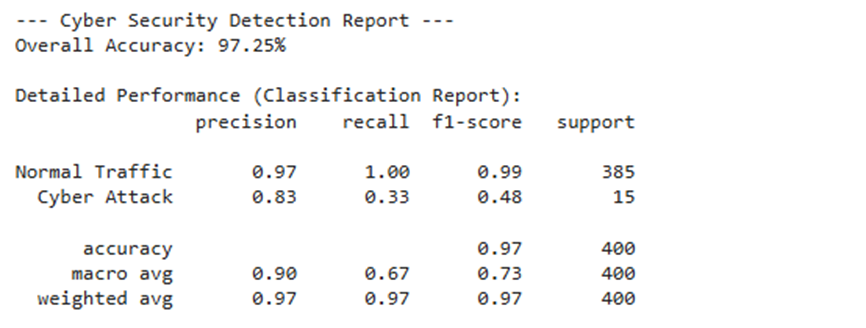
print("--- Cyber Security Detection Report ---")
print(f"Overall Accuracy: {accuracy_score(y_test, y_pred):.2%}")
print("\nDetailed Performance (Classification Report):")
print(classification_report(y_test, y_pred, target_names=['Normal Traffic', 'Cyber Attack']))
# ۶. خروجی بصری (Confusion Matrix) با لیبلهای انگلیسی
fig, ax = plt.subplots(figsize=(8, 6))
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['Normal Traffic', 'Cyber Attack'])
disp.plot(cmap='Reds', ax=ax) # استفاده از رنگ قرمز (Crimson) برای هشدار امنیت
plt.title('Intrusion Detection System: Confusion Matrix', fontsize=14)
plt.show()
خروجی:
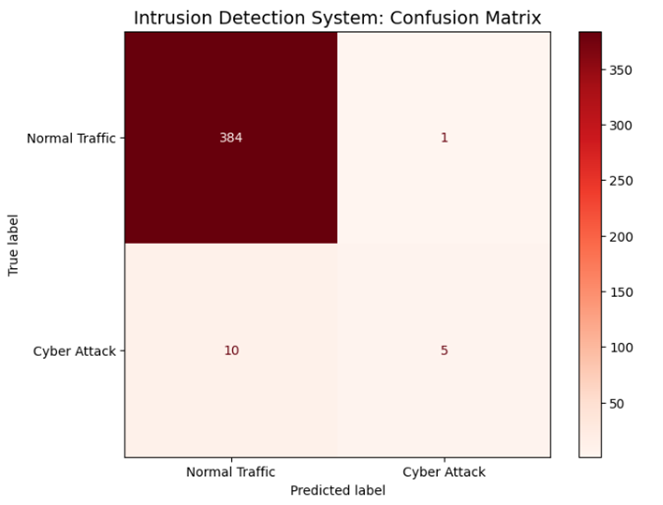
.
مطالعه موردی ۳: سیستم توصیهگر هوشمند (ترکیب نظرات ناهمگن)
سناریو: یک سرویس استریم ویدیو میخواهد دقیقترین پیشنهاد فیلم را به کاربر بدهد.
چالش: برخی مدلها روی ژانر فیلم خوب عمل میکنند و برخی دیگر روی سابقه خرید کاربر. ترکیب ساده اینها به نتایج بهینهای منجر نمیشود.
راهحل نهایی: استفاده از. Stacking در اینجا چندین مدل متفاوت (SVM، KNN و…) پیشبینیهای خود را به یک Meta-Model (مانند رگرسیون لجستیک) میدهند تا مدل ناظر یاد بگیرد در چه شرایطی حرف کدام متخصص لایه اول را جدی بگیرد.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier, RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# تنظیم رنگهای اختصاصی nabcg
colors = ['#7289DA', '#A8A9AD', '#FFD700', '#DC143C'] # Blue, Silver, Gold, Crimson
# ۱. ایجاد دادههای فرضی (رفتار کاربر در سرویس استریم)
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۲. تعریف یادگیرندههای پایه (متخصصان لایه اول)
base_models = [
('RandomForest', RandomForestClassifier(n_estimators=10, random_state=42)),
('KNN', KNeighborsClassifier(n_neighbors=5)),
('SVM', SVC(probability=True, random_state=42))
]
# ۳. تعریف مدل ناظر (Meta-Model) و تجمیع در Stacking
stacking_model = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegression(),
cv=5
)
# ۴. آموزش و استخراج نتایج
results = {}
for name, model in base_models:
model.fit(X_train, y_train)
preds = model.predict(X_test)
results[name] = accuracy_score(y_test, preds)
stacking_model.fit(X_train, y_train)
results['Stacking (Final)'] = accuracy_score(y_test, stacking_model.predict(X_test))
# ۵. نمایش خروجی بصری (مقایسه عملکرد)
plt.figure(figsize=(10, 6))
bars = plt.bar(results.keys(), results.values(), color=colors)
plt.ylim(0, 1.1)
plt.title('Accuracy Comparison: Individual Models vs. Stacking', fontsize=14, fontweight='bold')
plt.ylabel('Accuracy Score', fontsize=12)
# اضافه کردن درصدها روی ستونها
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval + 0.02, f'{yval:.2%}', ha='center', fontweight='bold')
plt.grid(axis='y', linestyle='--', alpha=0.3)
plt.show()
# چاپ خروجی متنی در کنسول
for model_name, score in results.items():
print(f"Accuracy of {model_name}: {score:.2%}")
خروجی:
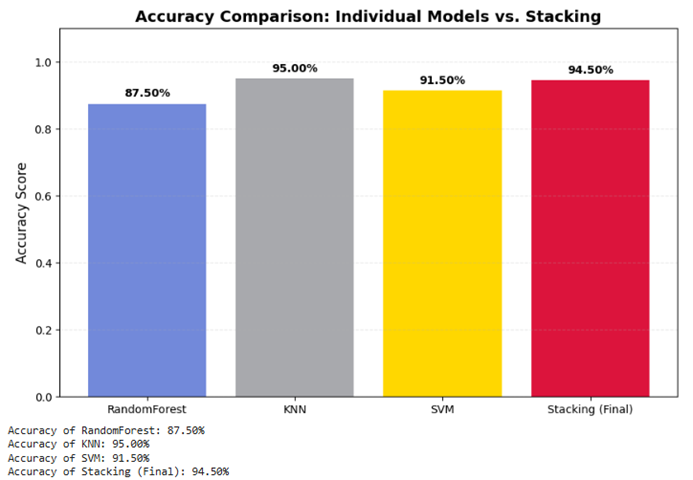
.
جمع بندی
یادگیری گروهی نشان میدهد که در دنیای مدلسازی، «همکاری» اغلب از «توانایی فردی» مؤثرتر است. بهجای تکیه بر یک مدل واحد، ترکیب چندین مدل میتواند باعث کاهش واریانس، کنترل بایاس و افزایش پایداری پیشبینی شود. همانطور که دیدیم، هرکدام از رویکردهای اصلی Ensemble هدف مشخصی دارند:
- Bagging تمرکز بر کاهش واریانس و پایدارسازی مدلها دارد.
- Boosting با تمرکز بر خطاهای قبلی، بایاس را کاهش میدهد و مدل را مرحلهبهمرحله تقویت میکند.
- Stacking تلاش میکند با یادگیری یک مدل ترکیبکننده، بهترین ویژگیهای چند الگوریتم متفاوت را در کنار هم قرار دهد.
در عمل، یادگیری گروهی یکی از مؤثرترین راهکارها برای بهبود عملکرد مدلها بدون پیچیدهتر کردن بیش از حد ساختار آنهاست. با این حال، باید به هزینههای محاسباتی، افزایش پیچیدگی پیادهسازی و کاهش تفسیرپذیری نیز توجه داشت. انتخاب درست نوع Ensemble به ماهیت داده، حجم اطلاعات، نیاز به سرعت اجرا و سطح دقت مورد انتظار بستگی دارد.
اگر بخواهید مسیر یادگیری را ادامه دهید، پیشنهاد میشود پس از تسلط بر مفاهیم پایه، به سراغ پیادهسازی Random Forest، Gradient Boosting، XGBoost و LightGBM بروید و عملکرد آنها را در یک مسئله واقعی مقایسه کنید. این تجربه عملی بهخوبی نشان میدهد که چرا یادگیری گروهی یکی از ستونهای اصلی یادگیری ماشین مدرن محسوب میشود.