

مقدمه
رگرسیون خطی (Linear Regression) یکی از سادهترین و در عین حال پرکاربردترین الگوریتمهای یادگیری ماشین است که هدف آن پیدا کردن یک رابطهی تقریبی بین یک یا چند ویژگی (Feature) و یک متغیر هدف (Target) است. این مدل تلاش میکند با برازش یک خط (در حالت تکمتغیره) یا یک صفحه/ابرصفحه (در حالت چندمتغیره)، مقدار خروجی را به شکلی قابلتفسیر و قابلپیشبینی تخمین بزند. به دلیل سادگی، سرعت بالا و قابلیت توضیحپذیری، رگرسیون خطی معمولاً اولین مدلی است که برای تحلیل دادهها، ساخت مدلهای پیشبینی و حتی مقایسهی عملکرد سایر روشها استفاده میشود.
در این مقاله ابتدا مفهوم رگرسیون خطی و ایدهی کلی برازش مدل را توضیح میدهیم، سپس به تابع هزینه و روش یادگیری پارامترها (مانند کمترین مربعات و گرادیان نزولی) میپردازیم. سپس معیارهای ارزیابی مانند MSE و R²، فرضیات مهم رگرسیون خطی، خطرات overfitting/underfitting و نقش regularization (L1/L2) را مرور میکنیم. در نهایت، با یک مثال عددی و چند مطالعهی موردی واقعی، پیادهسازی عملی مدل در پایتون را نشان میدهیم تا خواننده بتواند از مرحلهی «درک مفهوم» به مرحلهی «اجرا و تحلیل نتیجه» برسد. پیشنیاز پیشنهادی این متن، آشنایی مقدماتی با مفاهیم داده، میانگین/واریانس و کمی جبر خطی ساده است.
تعریف
رگرسیون خطی یکی از بنیادیترین الگوریتمهای یادگیری نظارتشده (Supervised Learning) است که وظیفهی مدلسازی رابطه بین دو متغیر را بر عهده دارد: متغیر وابسته و متغیر مستقل. در واقع، این الگوریتم تلاش میکند بهترین خط مستقیمی را پیدا کند که رابطهی ریاضی بین این دو متغیر را نشان میدهد. این روش آماری ساده، ابزاری قدرتمند برای تحلیلهای پیشبینیگر و تخمین نتایج در آینده است.
چرا رگرسیون خطی اینقدر مهم است؟
این الگوریتم صرفاً یک فرمول ریاضی نیست؛ بلکه الفبای درک دادههاست.
- سادگی و تفسیرپذیری: درک و تفسیر آن بسیار آسان است، به همین خاطر بهترین نقطه برای شروع یادگیریِ جدیِ هوش مصنوعی است.
- قدرت پیشبینی: به ما کمک میکند تا نتایج آینده را بر اساس دادههای گذشته پیشبینی کنیم؛ ابزاری که در حوزههایی مثل مالی، سلامت و بازاریابی عصای دستِ تحلیلگران است.
- سنگ بنای مدلهای دیگر: بسیاری از الگوریتمهای پیشرفته مثل رگرسیون لجستیک یا حتی شبکههای عصبی عمیق، بر روی مفاهیم پایه رگرسیون خطی بنا شدهاند.
- کارایی محاسباتی: این مدل بسیار سبک است و برای مسائلی که رابطه خطی دارند، با سرعت و دقتِ فوقالعادهای عمل میکند.
- تحلیل روابط: فراتر از پیشبینی، به ما میگوید که هر متغیر دقیقاً چقدر بر روی خروجی نهایی تأثیر دارد (مثلاً چقدر متراژ خانه روی قیمت اثرگذار است).
.
رگرسیون خطی چگونه کار میکند؟
Linear Regression(رگرسیون خطی )سادهترین و در عین حال پرکاربردترین تکنیک آماری در یادگیری ماشین برای تحلیلهای پیشبینیگر است. این روش به دنبال یافتن رابطه خطی بین یک متغیر مستقل (Predictor) روی محور X و یک متغیر وابسته (Output) روی محور Y است.
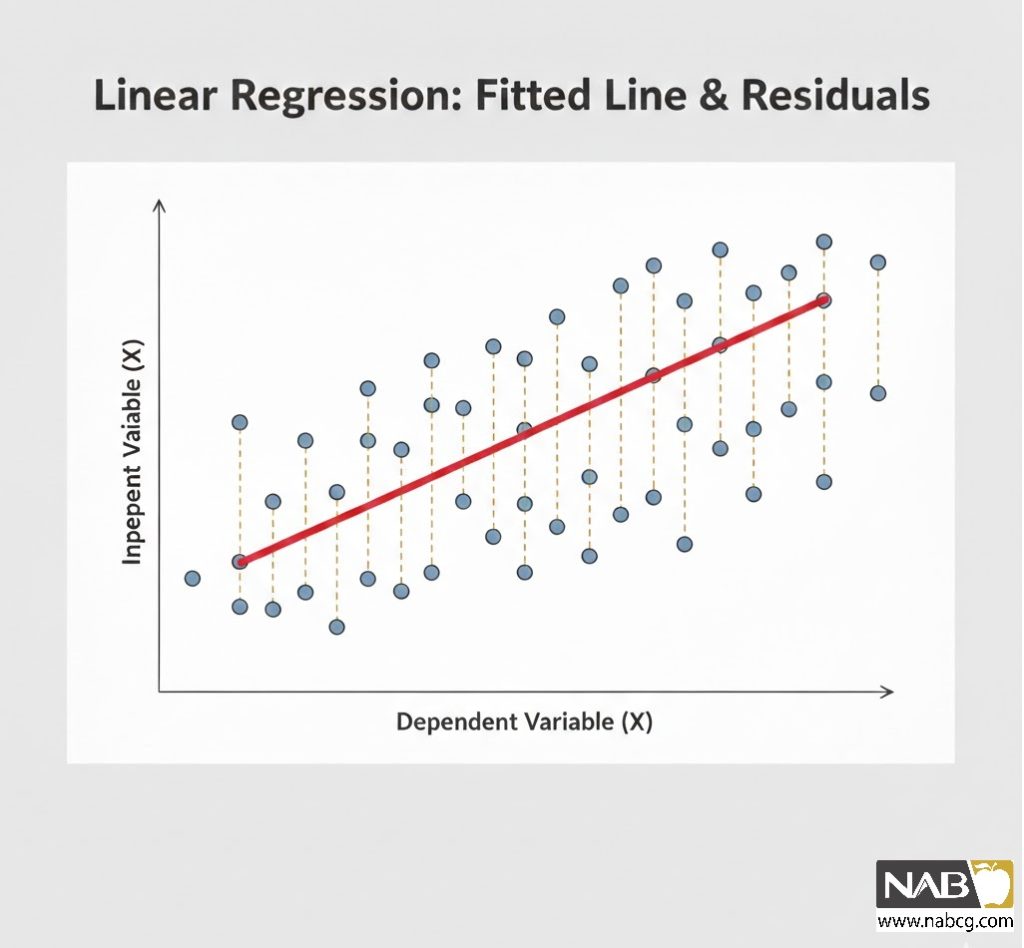
.
مبانی ریاضی: معادله و پارامترها
در سادهترین حالت، رگرسیون خطی به دنبال یافتن پارامترهایی است که خروجی را به ورودی متصل میکنند.
الف) رگرسیون خطی ساده (Simple Linear Regression)
معادله استاندارد برای یک ویژگی ورودی به صورت زیر است:
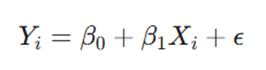
- Yi: متغیر وابسته یا هدفی که قصد پیشبینی آن را داریم (مثلاً قیمت خانه).
- Xi: متغیر مستقل یا ویژگی ورودی (مثلاً متراژ).
- β0: عرض از مبدأ؛ نقطهای که خط محور Y را قطع میکند (مقدار هدف وقتی ورودی صفر است).
- β1: شیب خط؛ نشاندهنده میزان حساسیت Y نسبت به تغییرات X.
- ε: خطای تصادفی که مدل قادر به توضیح آن نیست.
.
ب) رگرسیون خطی چندگانه (Multiple Linear Regression)
زمانی که بیش از یک ویژگی داریم، معادله گسترش مییابد:
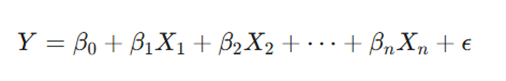
در اینجا هر ویژگی Xi وزن مختص به خود را دارد که اهمیت آن را در پیشبینی نهایی تعیین میکند.
تابع هزینه (Cost Function)
مدل از تابع میانگین مربعات خطا (MSE) استفاده میکند تا تفاوت بین واقعیت و پیشبینی را بسنجد:

- yi: مقدار واقعی.
- y^: مقدار پیشبینی شده.
.
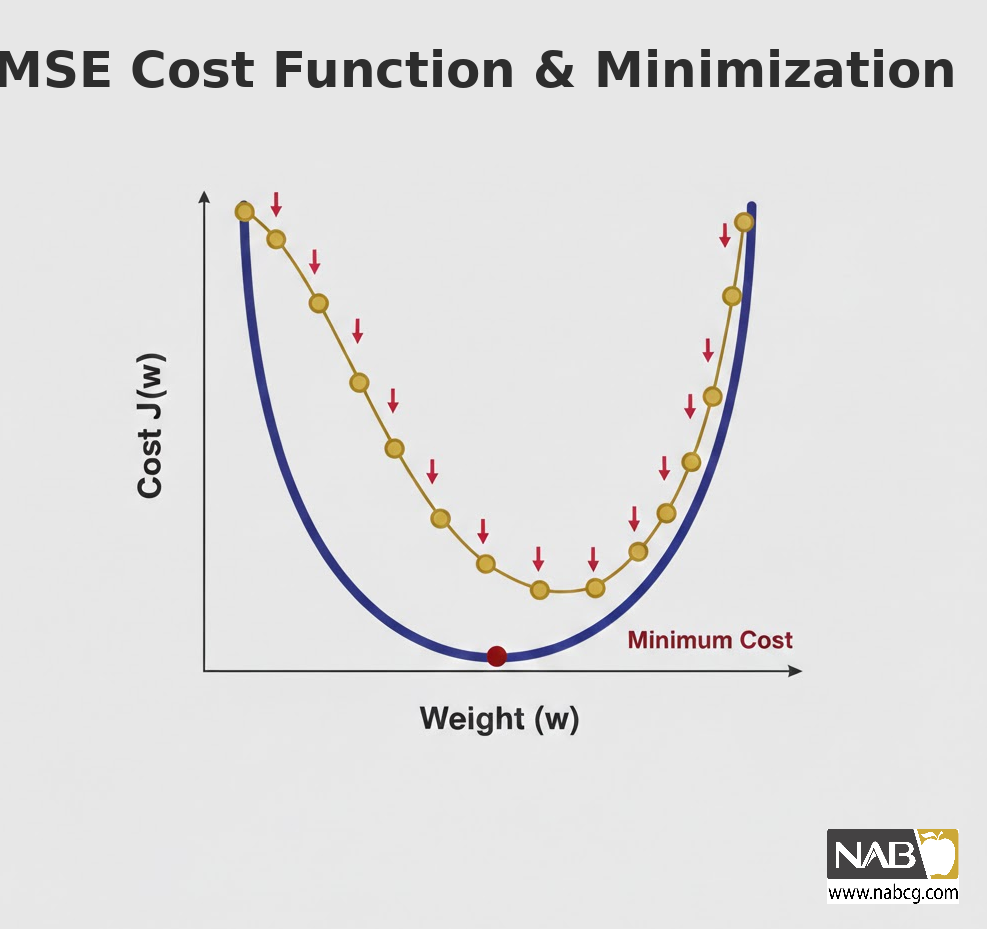
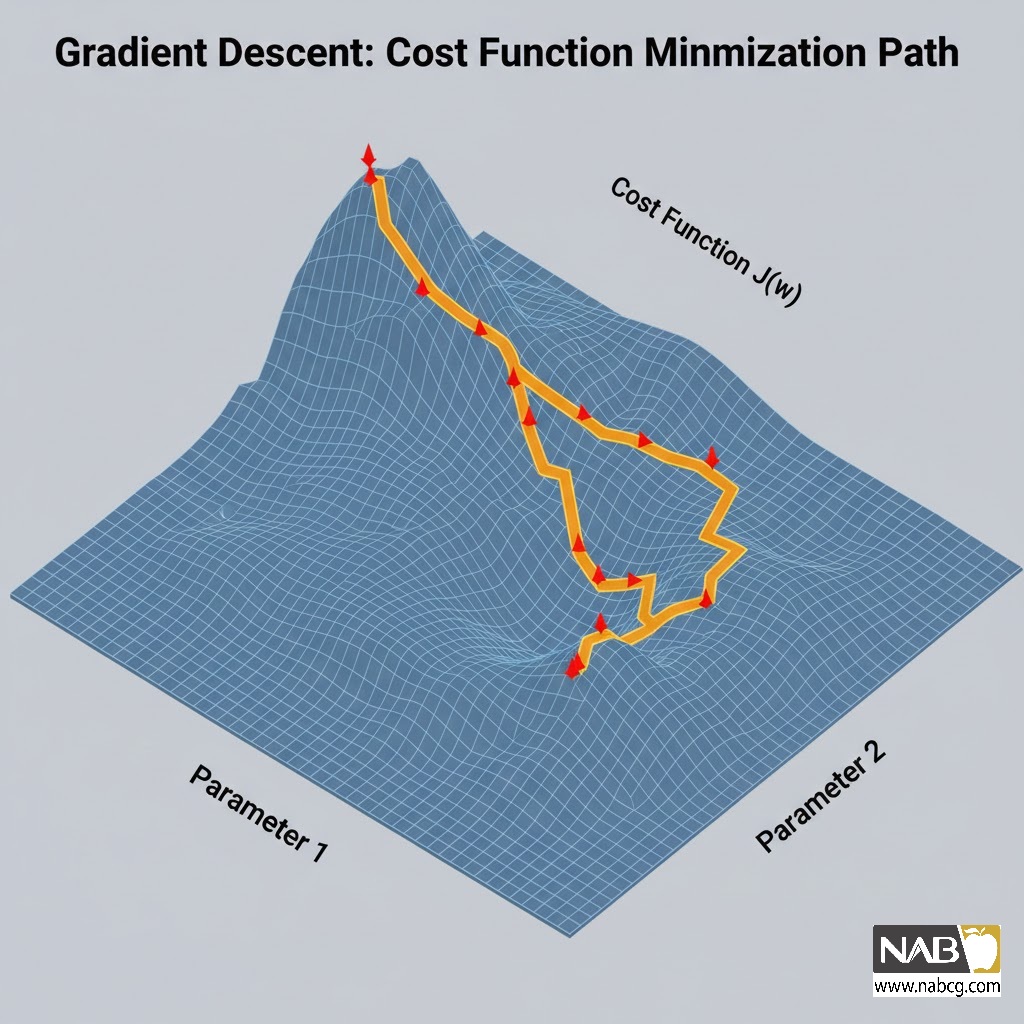
گرادیان کاهشی (Gradient Descent)
این الگوریتم با حرکت در جهت معین، پارامترهای β را طوری تغییر میدهد که MSE به حداقل برسد. این فرآیند شامل مراحل زیر است:
- مقداردهی اولیه تصادفی به پارامترها.
- محاسبه مشتق تابع هزینه نسبت به هر پارامتر (پیدا کردن جهت شیب).
- بهروزرسانی پارامترها با گامهای مشخص (نرخ یادگیری یا Learning Rate).
.
فرضیات رگرسیون خطی
رگرسیون خطی یک رویکرد پارامتری است؛ به این معنا که برای عملکرد صحیح، پیشفرضهایی را درباره ماهیت دادهها در نظر میگیرد. پیش از آنکه به نتایج مدل خود اعتماد کنید، باید این ۴ فرمان طلایی را اعتبارسنجی کنید:
۱. خطی بودن (Linearity)
اولین و بدیهیترین فرض این است که رابطه بین متغیر مستقل (X) و متغیر وابسته (Y) واقعاً یک خط مستقیم باشد. اگر رابطه دادههای شما منحنیشکل باشد، رگرسیون خطی به سادگی شکست میخورد.
- نحوه بررسی: استفاده از نمودار Scatter Plot. اگر نقاط حول یک خط مستقیم پخش شده باشند، این فرض برقرار است.
.
۲. استقلال باقیماندهها (Independence of Residuals)
جملات خطا نباید هیچ الگوی زمانی یا ترتیبی نسبت به هم داشته باشند. به عبارت دیگر، خطای پیشبینی برای یک داده نباید روی خطای داده بعدی اثر بگذارد. این موضوع در دادههای سری زمانی (Time-Series) بسیار حساس است.
- خودهمبستگی (Autocorrelation): اگر این فرض نقض شود، با پدیده خودهمبستگی روبرو هستیم که باعث میشود مدل شما بیش از حد به دادههای قبلی وابسته شود.
- نحوه بررسی: استفاده از آزمون دوربین-واتسون (Durbin-Watson test).
.
۳. توزیع نرمال خطاها (Normality of Residuals)
برای اینکه آزمونهای آماری (مثل P-value) معتبر باشند، خطاهای مدل (باقیماندهها) باید از یک توزیع نرمال با میانگین صفر پیروی کنند. اگر خطاها نرمال نباشند، یعنی مدل شما بخشی از اطلاعات مهم یا الگوهای غیرمعمول را نادیده گرفته است.
- نحوه بررسی: استفاده از نمودار Q-Q Plot یا آزمونهای آماری مثل Shapiro-Wilk.
.
۴. همسانی واریانس (Homoscedasticity)
این کلمه به زبان ساده یعنی واریانس خطاها باید در تمام طول خط رگرسیون ثابت باشد. اگر با افزایش مقدار X، خطای پیشبینی شما بزرگ و بزرگتر شود (شبیه به شکل یک قیف یا بادبزن)، شما دچار ناهمسانی واریانس (Heteroscedasticity) شدهاید.
- چرا خطرناک است؟ چون باعث میشود مدل در برخی نواحی بسیار دقیق و در برخی نواحی کاملاً غیرقابل اعتماد باشد.
.
معیارهای ارزیابی در رگرسیون خطی
سنجش کیفیت یک مدل رگرسیون، صرفاً به دست آوردن یک عدد نیست؛ بلکه هنرِ انتخاب معیار مناسب بر اساس ماهیت دادهها و هدف پروژه است. این معیارها به ما نشان میدهند که مدل چقدر در تولید خروجیهای مشابه با واقعیت موفق بوده است. در اینجا ۵ معیار اصلی را کالبدشکافی میکنیم:
- میانگین قدر مطلق خطا (Mean Absolute Error – MAE)
- میانگین مربعات خطا (Mean Squared Error – MSE)
- ریشه میانگین مربعات خطا (Root Mean Squared Error – RMSE)
- ضریب تعیین (R^2 – R-Squared)
- ضریب تعیین تعدیلشده (Adjusted R-Squared)
.
۱. میانگین قدر مطلق خطا (Mean Absolute Error – MAE)
این معیار میانگین تفاوتهای مطلق بین مقادیر پیشبینی شده و مقادیر واقعی را محاسبه میکند. در واقع، MAE به ما میگوید که به طور متوسط، پیشبینیهای مدل چقدر از واقعیت فاصله دارند.
فرمول:
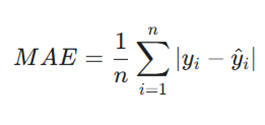
معرفی متغیرها:
- n: تعداد کل مشاهدات (تعداد دادهها).
- yi: مقدار واقعی مشاهده شده برای دادهی iام.
- y^: مقدار پیشبینی شده توسط مدل برای دادهی iام.
- | … |: علامت قدر مطلق که باعث میشود جهت خطا (مثبت یا منفی) حذف شود.
- مزایا: به دلیل عدم استفاده از توان دوم، نسبت به دادههای پرت (Outliers) مقاوم است. همچنین واحد آن دقیقاً با واحد متغیر هدف یکسان است.
- معایب: از نظر ریاضی در نقطه صفر مشتقپذیر نیست، بنابراین در برخی الگوریتمهای بهینهسازی پیچیده، استفاده از آن دشوارتر از MSE است.
- کاربرد: زمانی که دادههای پرت زیادی دارید و نمیخواهید این نویزها تأثیر غیرمنطقی روی ارزیابی مدل بگذارند.
.
۲. میانگین مربعات خطا (Mean Squared Error – MSE)
MSE میانگین مجذور (توان دوم) تفاوتهای بین مقادیر واقعی و پیشبینی شده است. این معیار محبوبترین تابع هزینه در یادگیری ماشین است.
فرمول:
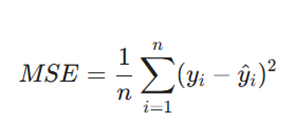
معرفی متغیرها:
- n: تعداد کل دادهها.
- yi: مقدار واقعی.
- مزایا: به دلیل ماهیت سهموی و مشتقپذیری عالی، بهترین گزینه برای الگوریتمهای بهینهسازی مانند گرادیان کاهشی (Gradient Descent) است.
- معایب: به شدت به دادههای پرت حساس است. چون خطاها به توان دو میرسند، یک خطای بزرگ به تنهایی میتواند مقدار MSE را به شدت بالا ببرد.
- کاربرد: زمانی که میخواهید مدل را بابت خطاهای بزرگ به شدت تنبیه کنید (مثلاً در سیستمهای حساس که خطای زیاد قابل چشمپوشی نیست).
.
۳. ریشه میانگین مربعات خطا (Root Mean Squared Error – RMSE)
RMSE سادهترین راه برای تبدیل MSE به واحد اصلی متغیر هدف است. در واقع RMSE جذرِ واریانس باقیماندههاست.
فرمول:
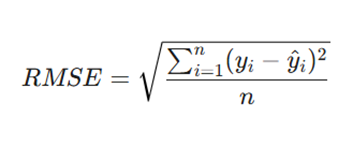
معرفی متغیرها:
- 2^(yi – y^)∑: مجموع مربعات باقیماندهها (RSS).
- n: تعداد مشاهدات.
- مزایا: تفسیرپذیری بسیار بالایی دارد. اگر هدف شما پیشبینی قیمت به تومان باشد، خروجی RMSE نیز به تومان خواهد بود.
- معایب: مشابه MSE، همچنان تحت تأثیر شدید دادههای پرت قرار دارد.
- کاربرد: به عنوان یک معیار استاندارد در گزارشهای فنی و مقالات علمی رگرسیون برای نمایش خطای نهایی مدل.
.
۴. ضریب تعیین (R^2 – R-Squared)
R^2 یک معیار آماری است که نشان میدهد چه نسبتی از تغییرات (واریانس) متغیر وابسته توسط متغیرهای مستقل در مدل توضیح داده شده است.
فرمول:
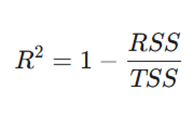
معرفی متغیرها:
- RSS (Residual Sum of Squares): مجموع مربعات باقیماندهها که میزان تفاوت بین واقعیت و پیشبینی را نشان میدهد.
- TSS (Total Sum of Squares): مجموع کل مربعات که تفاوت دادهها از میانگین را نشان میدهد.
- مزایا: مستقل از واحد است و عددی بین ۰ و ۱ میدهد که درک کلی از خوبیِ برازش مدل فراهم میکند.
- معایب: با اضافه کردن هر ویژگی جدید به مدل (حتی اگر بیربط باشد)، مقدار آن ثابت میماند یا افزایش مییابد؛ بنابراین میتواند فریبدهنده باشد.
- کاربرد: سنجش قدرت کلی تبیین مدل در مسائل رگرسیون ساده.
.
۵. ضریب تعیین تعدیلشده (Adjusted R-Squared)
این معیار، نسخهی بهبودیافته R^2 است که بر اساس تعداد متغیرهای ورودی اصلاح شده است.
فرمول:
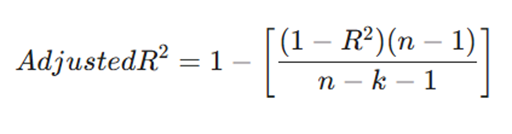
معرفی متغیرها:
- R^2: ضریب تعیین معمولی.
- n: تعداد کل مشاهدات (نمونهها).
- k: تعداد متغیرهای مستقل (ویژگیها) در مدل.
- مزایا: مدل را بابت اضافه کردن ویژگیهای غیرضروری جریمه میکند. تنها در صورتی افزایش مییابد که متغیر جدید واقعاً به بهبود پیشبینی کمک کند.
- معایب: محاسبات آن کمی پیچیدهتر است و ممکن است در مدلهای بسیار ساده ضروری نباشد.
- کاربرد: در رگرسیون چندگانه برای جلوگیری از بیشبرازش (Overfitting) و انتخاب بهترین ترکیب از ویژگیها.
.
کدام معیار را انتخاب کنیم؟
- اگر دادههای شما دارای نویز و نقاط پرت زیاد است، از MAE استفاده کنید.
- اگر میخواهید خطاهای بزرگ را جریمه کنید و از گرادیان کاهشی استفاده میکنید، MSE انتخاب اصلی است.
- برای گزارش نهایی به مدیران، همیشه RMSE و R^2 را در کنار هم ارائه دهید.
.
چالشهای مدلسازی و تعادل میان سادگی و پیچیدگی
در یادگیری ماشین، مدلی که روی دادههای آموزشی موفق اما در تست شکست میخورد، با چالش بایاس (Bias) و واریانس (Variance) روبروست.
۱. بایاس (Bias)
بایاس (سوگیری) خطای ناشی از سادهسازی بیش از حد مدل است که زمانی رخ میدهد که مدل نتواند الگوهای پیچیده دادهها را یاد بگیرد (مثلاً استفاده از مدل خطی برای دادههای غیرخطی). توجه داشته باشید: رگرسیون خطی ذاتاً بایاس بالا ندارد؛ اگر رابطه واقعی خطی باشد، بایاس آن پایین است. بنابراین، بایاس بالا نشاندهنده عدم تطابق مدل با پیچیدگی دادهها است، نه سادگی ذاتی الگوریتم.
۲. واریانس (Variance)
واریانس واکنش مدل به تغییرات ورودی است. اگر مدل با تغییری اندک در آموزش، خروجیهای متفاوتی بدهد، دچار واریانس بالا شده است. مدل ایدهآل باید الگوها را بیابد، نه نوسانات تصادفی.
۳. موازنه بایاس و واریانس (The Tradeoff)
افزایش یکی منجر به کاهش دیگری میشود. هنر متخصص داده، یافتن نقطهی تعادلی برای حداقل کردن مجموع خطاهاست.
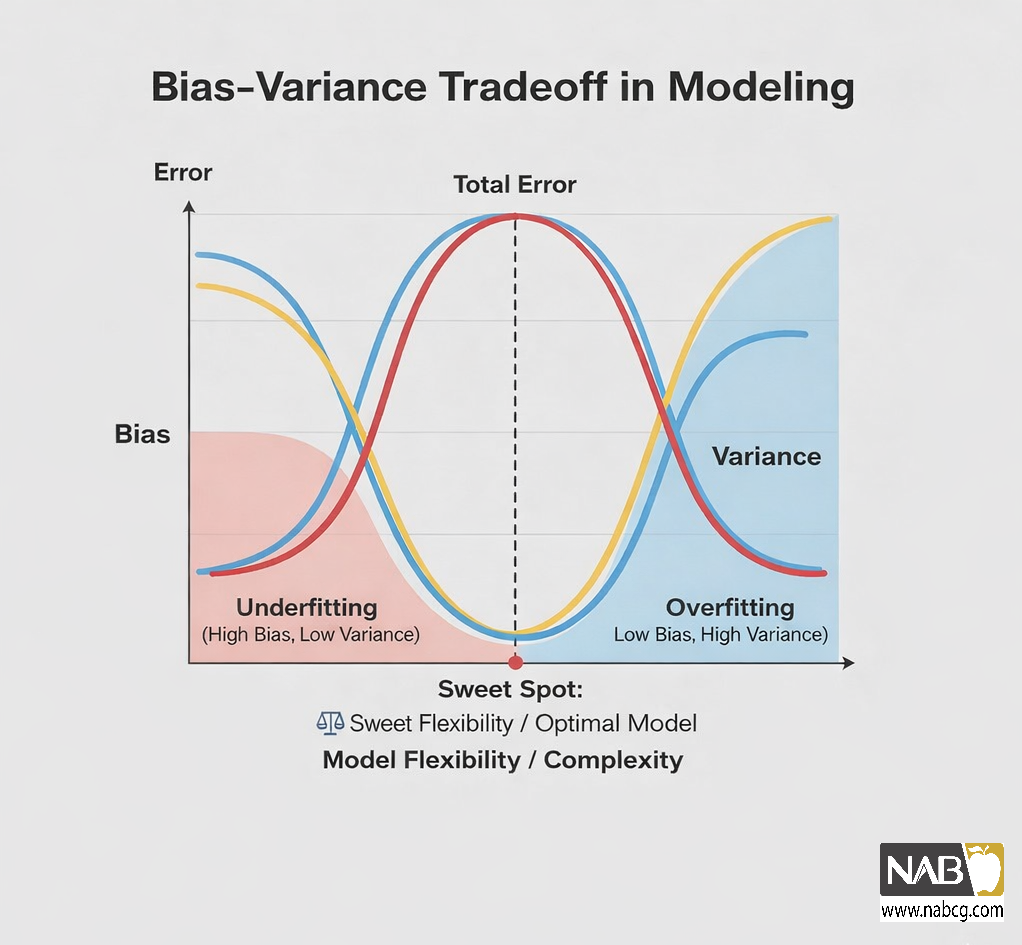
۴. بیشبرازش (Overfitting)
زمانی که مدل درگیر نویزهای آموزشی شده و قدرت تعمیمدهی را از دست میدهد، نویز را الگویی واقعی تفسیر میکند.
- نشانهها: دقت بالا در آموزش و دقت پایین در تست.
- مقابله: اعتبارسنجی متقاطع (Cross-validation)، افزودن داده و منظمسازی (Regularization).
.
۵. کمبرازش (Underfitting)
زمانی است که مدل نه از آموزش یاد میگیرد و نه روی تست تعمیم مییابد؛ مدل الگوهای اصلی را هم نمیبیند.
- نشانهها: دقت پایین در هر دو مجموعه.
- مقابله: افزایش پیچیدگی (چندجملهایها)، افزودن ویژگی و حذف نویز.
.
تکنیکهای منظمسازی (Regularization)
در یادگیری ماشین، گاهی اوقات مدل ما زیادی زرنگ میشود و به جای یادگیریِ الگو، شروع به حفظ کردن دادهها میکند. منظمسازی تکنیکی است که با اضافه کردن یک جریمه (Penalty) به تابع هزینه، مانع از بزرگ شدن بیش از حد ضرایب مدل و در نتیجه بیشبرازش میشود.

۱. رگرسیون لاسو (Lasso Regression – L1)
رگرسیون لاسو نه تنها از بیشبرازش جلوگیری میکند، بلکه میتواند به عنوان یک ابزار انتخاب ویژگی (Feature Selection) هم عمل کند؛ چون این قدرت را دارد که ضریب ویژگیهای بیاهمیت را دقیقاً به صفر برساند.
تابع هدف (Objective Function):
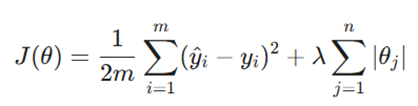
- بخش اول (Least Squares Loss): مجموع توان دوم تفاوت بین واقعیت و پیشبینی.
- بخش دوم (L1 Penalty): جریمهای معادل مجموع قدر مطلق ضرایب (θj).
- λ: قدرت منظمسازی؛ هرچه بزرگتر باشد، سختگیری مدل بیشتر میشود.
- m: تعداد نمونههای داده.
.
۲. رگرسیون ریج (Ridge Regression – L2)
این تکنیک زمانی که با مشکل همخطی (Multicollinearity) روبرو هستیم (یعنی وقتی متغیرهای ورودی همبستگی شدیدی با هم دارند)، بسیار عالی عمل میکند. برخلاف لاسو، ریج ضرایب را به سمت صفر میل میدهد اما آنها را کاملاً حذف نمیکند.
تابع هدف:

۳. رگرسیون الاستیک نت (Elastic Net Regression)
اگر بین انتخاب لاسو و ریج مردد هستید، الاستیک نت بهترین گزینه است. این روش ترکیبی هوشمندانه از هر دو جریمه L1 و L2 است.
تابع هدف:
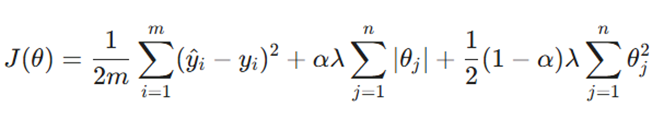
- α: کنترلکنندهی ترکیب؛ اگر ۱ باشد مدل همان لاسو است و اگر ۰ باشد مدل تبدیل به ریج میشود.
- توازن: این روش به مدل اجازه میدهد در عین حال که ویژگیهای بیاهمیت را حذف میکند، پایداری خود را در برابر همخطی (مانند ریج) حفظ کند.
.
مثال عددی:پیشبینی درآمد بر اساس بودجه تبلیغاتی
فرض کنید مدیر دیتاساینس یک استارتاپ هستید و میخواهید بدانید به ازای هر ۱ میلیون تومان هزینهی اضافی در گوگل ادز، درآمد شرکت چقدر تغییر میکند.
۱. مجموعه دادهها
ما ۵ ماه اخیر را بررسی کردهایم (اعداد به میلیون تومان):
- ماه اول: هزینه تبلیغات (X=10)←درآمد (Y=25)
- ماه دوم: هزینه تبلیغات (X=20)←درآمد (Y=45)
- ماه سوم: هزینه تبلیغات (X=30)←درآمد (Y=75)
- ماه چهارم: هزینه تبلیغات (X=40)←درآمد (Y=100)
- ماه پنجم: هزینه تبلیغات (X=50)←درآمد (Y=125)
.
۲. گام اول: استخراج آمارهای پایه
- میانگین هزینه تبلیغات:

- میانگین درآمد :
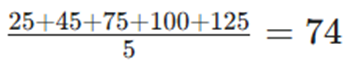
۳. گام دوم: جدول محاسبات ماتریسی (برای یافتن β1)
برای یافتن شیب خط ، باید انحراف هر نقطه از میانگین را محاسبه کنیم:

۴. گام سوم: استخراج ضرایب بهینه (Weights)
حالا با استفاده از متد کمترین مربعات:
- شیب خط :
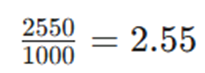
- عرض از مبدأ :
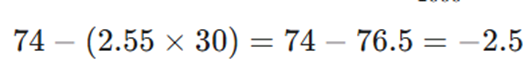
معادله نهایی مدل:

۵. تحلیل عمیق و پیشبینی
ضریب عرض از مبدأ (β₀ = -2.5) نشان میدهد که اگر هزینه تبلیغات صفر باشد، مدل درآمد را ۲.۵ میلیون تومان منفی پیشبینی میکند. این مقدار از نظر اقتصادی بیمعناست و صرفاً نشاندهنده محدودیت مدل در خارج از محدوده دادههای آموزشی (که هزینه تبلیغات از ۱۰ میلیون تومان شروع میشود) است. بنابراین، استفاده از این مدل برای پیشبینی در سطوح بسیار پایین هزینه تبلیغات توصیه نمیشود.
حالا اگر بخواهیم برای ماه آینده ۶۰ میلیون تومان بودجه تخصیص دهیم، درآمد چقدر خواهد بود؟

پیشبینی مدل: ۱۵۰.۵ میلیون تومان درآمد.
۶. سنجش خطا (دقت مدل)
بیایید خطای ماه سوم را چک کنیم:
- واقعیت: ۷۵
- پیشبینی مدل: 74=2.5-30✕2.55
- باقیمانده: 1 =74 – 75
- خطای مربعی: 1=2^1
.
پیاده سازی در پایتون
در این بخش، یاد میگیریم که چگونه با استفاده از کتابخانههای محبوب پایتون، یک مدل رگرسیون خطی را از صفر بسازیم، آموزش دهیم و عملکرد آن را بسنجیم.
گامهای اجرایی:
- آمادهسازی کتابخانهها: ابتدا ابزارهای مهندسی خود یعنی Pandas برای مدیریت داده، Matplotlib برای بصریسازی و Sklearn برای مدلسازی را فراخوانی میکنیم.
- تولید دادههای فرضی: یک مجموعه داده شامل «متراژ خانه» و «قیمت» ایجاد میکنیم که در آن رابطه به صورت تقریبی خطی است.
- آموزش مدل: با استفاده از الگوریتم Linear Regression و متد .()fit، بهترین خط برازش را پیدا میکنیم.
- ارزیابی عملکرد: از معیارهای R^2 و MSE برای سنجش دقت مدل استفاده میکنیم.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# ۱. تعریف دادهها (متراژ و قیمت)
X = np.array([[50], [60], [80], [100], [120], [150], [180], [200], [220], [250]])
y = np.array([250, 310, 390, 480, 560, 710, 850, 920, 1050, 1180])
# ۲. آموزش مدل رگرسیون خطی
model = LinearRegression().fit(X, y)
y_pred = model.predict(X)
# ۳. محاسبه معیارهای ارزیابی
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Squared Error (MSE): {mse:.2f}")
print(f"R-squared (R2): {r2:.2f}")
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='#DC143C', label='Actual Data (Crimson)', s=80, alpha=0.8, edgecolors='black')
plt.plot(X, y_pred, color='#4A90E2', linewidth=3, label='Regression Line (AI Soft Blue)')
plt.title("Linear Regression Analysis: House Prices", color='#FFD700', fontsize=16, fontweight='bold')
plt.xlabel("Area (sqm)", color='#A8A8A8', fontsize=12)
plt.ylabel("Price (Millions)", color='#A8A8A8', fontsize=12)
plt.legend()
plt.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
خروجی:

.
کاربردهای رگرسیون خطی
.
۱. صنعت املاک و مستغلات
در این حوزه، رگرسیون خطی به سرمایهگذاران و خریداران کمک میکند تا ارزش واقعی یک ملک را تخمین بزنند.
- عوامل تاثیرگذار: قیمت خانه بر اساس متغیرهایی مانند مساحت ، تعداد اتاق خواب، موقعیت جغرافیایی و دسترسی به امکانات رفاهی پیشبینی میشود.
- تحلیل پیشرفته: با استفاده از رگرسیون چندگانه، میتوان تاثیر سن بنا یا فاصله تا ایستگاه مترو را نیز به دقت بر قیمت نهایی سنجید.
.
۲. بازاریابی و فروش (بهینهسازی بودجه)
مدیران مارکتینگ از این الگوریتم برای درک بازگشت سرمایه (ROI) و برنامهریزی کمپینها استفاده میکنند.
- پیشبینی حجم فروش: میزان فروش آینده بر اساس هزینههای انجام شده در تبلیغات (گوگل ادز، شبکههای اجتماعی) تخمین زده میشود.
- تحلیل رفتاری: رگرسیون خطی به شناسایی الگوهای خرید بر اساس تغییرات فصلی و روندهای گذشته کمک میکند.
.
۳. مدیریت منابع انسانی
- رابطه تجربه و درآمد: معمولاً با افزایش سالهای تجربه کاری، میزان حقوق نیز به صورت خطی افزایش مییابد.
- متغیر مستقل و وابسته: در اینجا، سابقه کار متغیر مستقل و میزان حقوق متغیر وابسته است که مدل آن را پیشبینی میکند.
.
۴. مراقبتهای بهداشتی و پزشکی (Healthcare)
- پیشبینی علائم حیاتی: پزشکان میتوانند شاخصهایی مانند فشار خون را بر اساس سن، وزن و رژیم غذایی بیمار تخمین بزنند.
- تأثیر دارو: سنجش میزان اثرگذاری یک دارو بر کاهش سطح قند خون در بیماران دیابتی از طریق این الگوریتم امکانپذیر است.
.
۵. علوم مالی و اقتصاد
- تخمین ریسک: سرمایهگذاران از این روش برای درک رابطه بین نوسانات بازار و قیمت سهام استفاده میکنند.
- پیشبینی تورم: اقتصاددانان میتوانند نرخ تورم آینده را بر اساس نرخ بهره یا حجم نقدینگی در جامعه پیشبینی کنند.
.
۶. کشاورزی و محیط زیست
- تخمین میزان محصول: پیشبینی مقدار برداشت محصول بر اساس میزان بارندگی، دما و مقدار کود مصرفی.
- تحلیل آب و هوا: بررسی رابطه بین افزایش گازهای گلخانهای و دمای میانگین زمین در دهه اخیر.
.
مطالعه موردی1:جذب کاربر در اپلیکیشنهای ورزشی (Marketing ROI)
توضیح: در دنیای پررقابت بازاریابی دیجیتال، هر ریال هزینه باید با منطق عددی توجیه شود. رگرسیون خطی به تیمهای مارکتینگ این قدرت را میدهد که رابطهی مستقیم و دقیق بین «بودجه تزریق شده» و «خروجی بهدست آمده» (تعداد نصب) را درک کنند. این الگوریتم با شفافسازی بازگشت سرمایه (ROI)، از حدس و گمانهای مدیریتی جلوگیری میکند.
- مسئله: تعیین نرخ دقیق تبدیل هزینهی تبلیغات اینستاگرام به نصب اپلیکیشن برای یک بازهی زمانی مشخص.
- هدف: یافتن نقطه بهینه بودجهبندی برای دستیابی به بیشترین رشد، بدون هدررفت منابع مالی در کانالهای غیربهینه.
.
پیادهسازی عملی با پایتون (Scikit-Learn)
در این کد، ما رابطهی بین هزینه (به میلیون تومان) و تعداد نصب را مدلسازی کرده و نرخ رشد را استخراج میکنیم.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# ۱. آمادهسازی دادهها (Ad Spend in M & Installs)
ad_spend = np.array([1, 2, 4, 6, 8, 10, 12]).reshape(-1, 1)
installs = np.array([550, 1080, 2150, 3200, 4350, 5400, 6600])
# ۲. ساخت و آموزش مدل
model = LinearRegression().fit(ad_spend, installs)
y_pred = model.predict(ad_spend)
# ۳. بصریسازی با استایل nabcg.com (English Labels)
plt.figure(figsize=(10, 6))
plt.scatter(ad_spend, installs, color='#DC143C', s=100, label='Actual Data (Installs)', edgecolors='black')
plt.plot(ad_spend, y_pred, color='#4A90E2', linewidth=3, label='ROI Trend Line')
plt.title("Marketing ROI Analysis: Ad Spend vs Installs", color='#FFD700', fontsize=16, fontweight='bold')
plt.xlabel("Ad Spend (Million Tomans)", color='#A8A8A8', fontsize=12)
plt.ylabel("Number of App Installs", color='#A8A8A8', fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.3)
plt.show()
print(f"Installs per 1M spend: {model.coef_[0]:.0f}")
print(f"Model Accuracy (R2): {r2_score(installs, y_pred):.4f}")
خروجی:
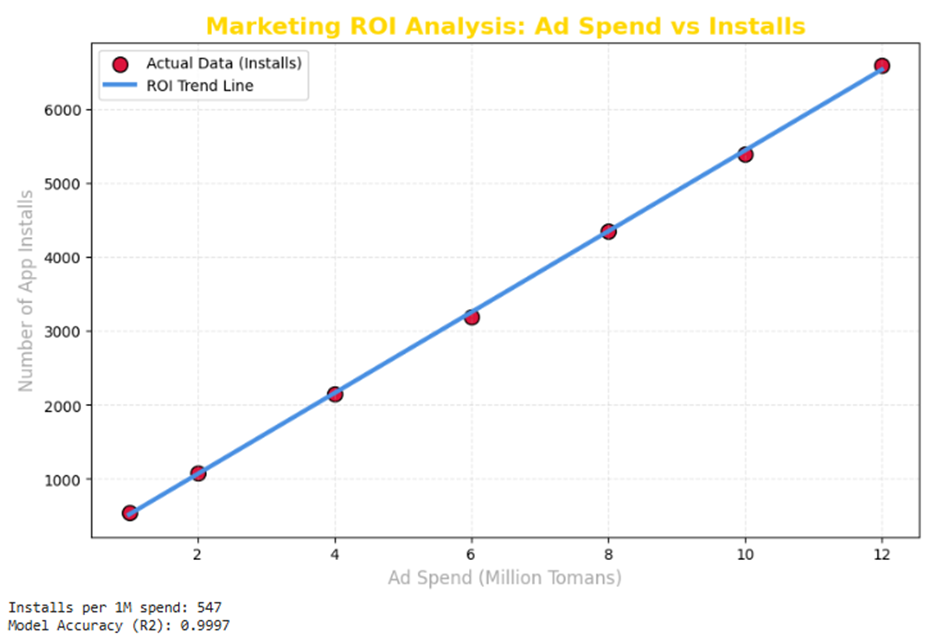
.
مطالعه موردی2: پایش سلامت در ساعتهای هوشمند (Apple Watch)
توضیح: اپلواچ و گجتهای پوشیدنی مشابه، با استفاده از حسگرهای نوری، دادههای ضربان قلب را جمعآوری کرده و با الگوریتمهای رگرسیون، آنها را به کالری مصرفی تبدیل میکنند. این فرآیند بر روی دادههای هزاران کاربر در شرایط مختلف کالیبره شده است.
- مسئله: تخمین میزان کالری مصرفی بر اساس «میانگین ضربان قلب» و «مدت زمان فعالیت».
- هدف: ارائهی گزارشهای دقیق بیومتریک به کاربر برای مدیریت وزن و پایش سلامت روزانه.
.
پیادهسازی با پایتون (Linear Regression)
در این مطالعه موردی، ما از دو ویژگی ورودی (رگرسیون چندگانه) برای پیشبینی دقیقتر استفاده میکنیم.
# ویژگیها: [ضربان قلب (bpm)، مدت زمان (min)]
X_health = np.array([[80, 20], [120, 30], [150, 45], [100, 60], [140, 15], [110, 40]])
# خروجی: کالری مصرفی
calories = np.array([100, 280, 450, 320, 210, 300])
# آموزش مدل رگرسیون چندگانه
health_model = LinearRegression().fit(X_health, calories)
# پیشبینی برای کاربری با ضربان ۱۳۰bpm و فعالیت ۵۰ دقیقهای
user_stats = np.array([[130, 50]])
cal_pred = health_model.predict(user_stats)
print(f"Predicted Calorie Burn: {cal_pred[0]:.2f} kcal")
print(f"Model Confidence (R2): {r2_score(calories, health_model.predict(X_health)):.4f}")
خروجی:

مزایا
- پیادهسازیِ فوری: الگوریتم نسبتاً سادهای است که پیادهسازی و درک آن وقت زیادی از شما نمیگیرد.
- تفسیر ضرایب: شما میتوانید دقیقاً بگویید با تغییر یک واحدی در ورودی، خروجی چقدر جابهجا میشود؛ این همان شفافیتی است که در جعبهسیاههای هوش مصنوعی به دنبالش هستیم.
- مدیریت دادههای حجیم: این الگوریتم بسیار کماشتهاست! یعنی میتواند مجموعه دادههای بزرگ را به سرعت و با کمترین منابع سختافزاری پردازش کند.
- مبنای مقایسه (Baseline): همیشه اولین مدلی که باید اجرا کنید رگرسیون خطی است تا بفهمید مدلهای پیچیدهتر واقعاً چقدر ارزش افزوده ایجاد میکنند.
.
محدودیتها
- فرضِ خطی بودن: این مدل اصرار دارد که همه چیز در دنیا با یک خط مستقیم حل میشود! اگر رابطه دادههای شما منحنی باشد، این مدل شکست میخورد.
- حساسیت به همخطی (Multicollinearity): اگر متغیرهای ورودی شما با هم رابطه خیلی نزدیکی داشته باشند، پیشبینیهای مدل ناپایدار و غیرقابل اعتماد میشود.
- نیاز به مهندسی ویژگی (Feature Engineering): مدل فرض میکند که دادهها در بهترین حالت ممکن هستند؛ بنابراین باید زمان زیادی صرف کنید تا دادهها را به فرمت مناسب برای مدل دربیاورید
.
جمع بندی
رگرسیون خطی یک نقطه شروع عالی برای یادگیری مدلسازی پیشبینی در یادگیری ماشین است، چون هم ساده است و هم بهخوبی نشان میدهد «مدل» چگونه از داده یاد میگیرد و چگونه باید عملکرد آن را ارزیابی کرد. در این مقاله دیدیم که رگرسیون خطی با پیدا کردن ضرایب مناسب برای ویژگیها، تلاش میکند خطای پیشبینی را (معمولاً با معیارهایی مثل MSE) کمینه کند؛ همچنین با معیارهایی مانند R² میتوان میزان توضیحدهندگی مدل نسبت به داده را سنجید. علاوه بر این، بررسی فرضیات (مثل خطی بودن رابطه، استقلال خطاها و همواریانسی) کمک میکند بدانیم چه زمانی این مدل قابل اعتماد است و چه زمانی ممکن است نتیجهی گمراهکننده بدهد.
همچنین یاد گرفتیم که رگرسیون خطی هم مثل سایر مدلها میتواند دچار underfitting یا overfitting شود؛ بنابراین استفاده از روشهایی مثل تقسیم داده به train/test، اعتبارسنجی، و regularization (Ridge/Lasso) برای کنترل پیچیدگی مدل ضروری است. در بخش عملی هم دیدیم که با ابزارهایی مثل scikit-learn میتوان بهسادگی مدل را آموزش داد، ضرایب را تفسیر کرد و با نمودارها و معیارهای عددی نتیجه را تحلیل کرد. اگر بخواهید مسیر یادگیری را ادامه دهید، پیشنهاد میشود بعد از تسلط بر رگرسیون خطی سراغ رگرسیون چندجملهای، رگرسیون مقاوم در برابر دادههای پرت (مثل Huber یا RANSAC)، و سپس مدلهای غیرخطی و پیشرفتهتر بروید تا در مسائل واقعی انتخابهای دقیقتری داشته باشید.



