

1.مقدمه
یادگیری ماشین امروز یکی از مهمترین موتورهای پیشبرنده هوش مصنوعی است؛ فناوری که به سیستمها اجازه میدهد از دادهها تجربه کسب کنند، الگوها را تشخیص دهند و تصمیمهای هوشمندانه بگیرند. بسیاری از ابزارهایی که هر روز با آنها سروکار داریم—از جستجوی اینترنتی و شبکههای اجتماعی گرفته تا خودروهای خودران و سیستمهای پزشکی—بر پایه همین مفهوم کار میکنند.
در این مقاله با انواع مختلف یادگیری ماشین آشنا میشویم؛ اینکه هرکدام چه کاری انجام میدهند، چگونه آموزش میبینند و در چه شرایطی بهترین عملکرد را دارند. هدف این مطلب ارائه یک دید روشن و ساده از دنیای یادگیری ماشین است؛ دیدی که هم برای افراد تازهکار قابل فهم باشد و هم برای علاقهمندان حرفهای ارزش آموزشی داشته باشد.
2.یادگیری ماشین چیست؟
یادگیری ماشین (Machine Learning) شاخهای از هوش مصنوعی است که به کامپیوترها توانایی «یادگیری از دادهها» را میدهد. در این روش، مدل با مشاهده نمونههای گذشته، الگوهای پنهان را پیدا میکند و از همان الگوها برای پیشبینی یا تصمیمگیری درباره دادههای جدید استفاده میکند—بدون آنکه برای هر مرحله برنامهنویسی شده باشد.
به بیان ساده، یادگیری ماشین یعنی یک سیستم با تجربه بهتر میشود: داده بیشتری ببیند، دقیقتر میشود؛ داده جدید ببیند، یاد میگیرد چگونه با آن برخورد کند. همین ویژگی باعث شده ML در بسیاری از کاربردهای امروزی نقش کلیدی داشته باشد.
3.طبقهبندی جامع یادگیری ماشین
A. طبقهبندی بر اساس نوع یادگیری (Learning Paradigm)
1.یادگیری نظارتشده(Supervised Learning)
2.یادگیری بدون نظارت(Unsupervised Learning)
3.یادگیری تقویتی(Reinforcement Learning)
4.یادگیری نیمهنظارتی(Semi-supervised Learning)
5.یادگیری خودنظارتی(Self-supervised Learning)
6.یادگیری انتقالی(Transfer Learning)
7.یادگیری چندوظیفهای(Multi-task Learning)
8.یادگیری کمنمونهای(Few-shot Learning)
9.یادگیری فدراسیونی/ توزیعشده (Federated Learning)
10.یادگیری پیوسته / مادامالعمر(Continual / Lifelong Learning)
11.یادگیری بیزی(Bayesian Learning)
12.یادگیری علّی(Causal Learning)
13.یادگیری تکاملی(Evolutionary Learning)
14.یادگیری درونگرا (In-context Learning)
15.یادگیری خودمختار/ خودمستقل (Autonomous Learning)
16. فرا-یادگیری / یادگیری فراگیر(Meta-learning)
17. یادگیری چندرسانهای / چندوجهی (Multimodal Learning)
18. یادگیری صفرنمونهای (Zero-shot Learning)
19. یادگیری مشارکتی (Collaborative Learning)
20. یادگیری فعال (Active Learning)

A. طبقهبندی بر اساس نوع یادگیری (Learning Paradigm)
1.یادگیری نظارتشده
- یادگیری تحت نظارت نوعی از روشهای یادگیری ماشین (ML) است که در آن مدل از دادههای برچسبگذاری شده (Labeled Data) برای یادگیری یک رابطه مستقیم بین ورودیها و خروجیهای صحیح استفاده میکند. مدل با استفاده از این رابطه آموخته شده (نگاشت)، قادر است برای دادههای جدید، پیشبینی انجام دهد.
- مثال کاربردی
پیشبینی قیمت مسکن: مدل با استفاده از دادههای تاریخی (شامل اندازه خانه و قیمت خانه به عنوان برچسب)، رابطه قیمت را میآموزد و سپس برای یک خانه جدید، قیمت آن را پیشبینی میکند.
- دستهبندیهای اصلی
مدلهای یادگیری تحت نظارت به دو دسته گسترده تقسیم میشوند که نوع خروجی نهایی آنها را مشخص میکند:
- رگرسیون (Regression)
- دستهبندی (Classification)
2.یادگیری بدون نظارت
- یادگیری بدون نظارت نوعی روش یادگیری ماشین است که از دادههای فاقد برچسب استفاده میکند تا الگوها و ساختارهای پنهان را مستقیماً از خود ورودیها کشف کند. هدف اصلی این روش، یادگیری روابط درونی دادهها بدون هدایت بیرونی (Outsourcing) است.
- مثال کاربردی
یک شرکت میتواند از این روش برای بخشبندی خودکار مشتریان بر اساس عادات خریدشان استفاده کند، بدون آنکه از قبل بداند این گروهها چه ویژگیهایی دارند.
- دستهبندیهای اصلی
یادگیری بدون نظارت به سه شیوه اصلی برای کشف ساختار دادهها متکی است:
- خوشهبندی (Clustering)
- انجمن (Association)
- کاهش ابعاد (Dimensionality Reduction)
3.یادگیری تقویتی
- یادگیری تقویتی نوعی از الگوریتمهای یادگیری ماشین است که در آن یک عامل (Agent) از طریق آزمون و خطا و تعامل با محیط خود، یاد میگیرد که چگونه عمل کند. هدف اصلی عامل این است که بهترین توالی از اقدامات را کشف کند تا پاداش (Reward) تجمعی خود را در طول زمان به حداکثر برساند.
- مثال کاربردی
رباتیک و ناوبری: یک ربات (عامل) در یک محیط ناشناخته قرار میگیرد. با انجام هر اقدام (مانند حرکت یا چرخش)، محیط بازخوردی به شکل پاداش (برای موفقیت) یا جریمه (برای خطا) به او میدهد. ربات پس از تکرار این فرآیند، بهترین سیاست (Policy) را برای رسیدن به هدف نهایی (مانند رسیدن به یک نقطه خاص) یاد میگیرد، بدون آنکه نیاز به آموزش صریح یا برچسبگذاری قبلی داشته باشد.
- دستهبندیهای اصلی
یادگیری تقویتی بر اساس نحوه کشف سیاست بهینه، به دستهبندیهای اصلی زیر تقسیم میشود:
- مبتنی بر مدل (Model-Based RL)
- بدون مدل (Model-Free RL)
4.یادگیری نیمهنظارتی
- یادگیری نیمهنظارتی نوعی از روشهای یادگیری ماشین است که از هر دو نوع داده برای آموزش مدل استفاده میکند: حجم زیادی از دادههای بدون برچسب و حجم کمی از دادههای برچسبگذاری شده. این روش تلاش میکند تا با ترکیب این دو منبع، از ساختار پنهان دادههای بدون برچسب برای تقویت دقت مدل در مواجهه با کمبود دادههای برچسبگذاری شده استفاده کند.
- مثال کاربردی
دستهبندی اسناد سازمانی: در یک شرکت، هزاران سند (داده بدون برچسب) وجود دارد، اما تنها صدها سند توسط متخصصان برچسبگذاری شدهاند (داده برچسبگذاری شده). مدل SSL از ساختار کلی هزاران سند برای بهبود مرزهای دستهبندی و افزایش دقت خود در طبقهبندی اسناد جدید استفاده میکند.
- دستهبندیهای اصلی
یادگیری نیمهنظارتی بر اساس فرضیاتی که در مورد نحوه ارتباط دادههای برچسبگذاری شده و بدون برچسب دارد، به دستهبندیهای زیر تقسیم میشود:
- روشهای مبتنی بر پیچیدگی
- روشهای مبتنی بر گراف
- روشهای مبتنی بر مدل مولد
5.یادگیری خودنظارتی
- یادگیری خودنظارتی یک روش نسبتاً جدید در یادگیری ماشین است که از دادههای بدون برچسب استفاده میکند تا بهطور خودکار، برچسبهای آموزشی خود را تولید کند. در واقع، مدل با استفاده از قسمتی از دادههای ورودی، قسمتی دیگر از همان دادهها را پیشبینی میکند و این کار باعث میشود تا مدل، ساختار درونی دادهها را بیاموزد. هدف اصلی SSL، ایجاد یک وظیفه ساختگی (Pretext Task) است که به مدل اجازه میدهد بدون نیاز به نیروی انسانی برای برچسبگذاری، خود را آموزش دهد.
- مثال کاربردی
پیشبینی کلمه پنهان: در مدلهای زبانی بزرگ (مانند BERT)، قسمتی از یک جمله (کلمه) پنهان میشود و مدل وظیفه دارد آن کلمه پنهان را بر اساس سایر کلمات جمله پیشبینی کند. با انجام این کار، مدل دانش عمیقی از دستور زبان، معناشناسی و ساختار زبان به دست میآورد، در حالی که تمام دادههای آموزشی (متون) از ابتدا بدون برچسب بودند.
- دستهبندیهای اصلی
تکنیکهای یادگیری خودنظارتی اغلب در حوزه مدلهای مولد (Generative Models) و پردازش زبان طبیعی (NLP) استفاده میشوند و به روشهای زیر دستهبندی میشوند:
- یادگیری متضاد
- خودرمزگذارهای نویززدا
- وظایف ساختگی
6.یادگیری انتقالی
- یادگیری انتقالی یک روش پیشرفته در یادگیری ماشین است که در آن، یک مدل آموزشدیده بر روی یک وظیفه (Task) اولیه به عنوان نقطه شروع برای حل یک وظیفه جدید اما مرتبط استفاده میشود. در واقع، مدل به جای شروع از صفر، دانش و ویژگیهای آموخته شده از دامنه اول را به دامنه دوم منتقل میکند تا به دادههای آموزشی کمتری نیاز داشته باشد.
- مثال کاربردی
- تشخیص تودههای سرطانی: برای تشخیص تودههای سرطانی از روی تصاویر پزشکی، به جای آموزش مدل از ابتدا، از یک مدل آموزشدیده بر روی میلیونها تصویر عمومی استفاده میشود. سپس وزنهای این مدل اولیه فقط با حجم کمی از تصاویر پزشکی برای وظیفه جدید تنظیم و بهینهسازی میشود.
- دستهبندیهای اصلی
یادگیری انتقالی بر اساس نحوه استفاده مجدد از مدل اولیه، به دستهبندیهای زیر تقسیم میشود:
- استخراج ویژگی (Feature Extraction)
- فاین-تیونینگ (Fine-Tuning)
- Domain Adaptation
7.یادگیری چندوظیفهای
- یادگیری چندوظیفهای یک رویکرد در یادگیری ماشین است که در آن یک مدل واحد به صورت همزمان برای حل چندین وظیفه مرتبط (Related Tasks) آموزش داده میشود. در این روش، مدل با استفاده از دانش مشترک (Shared Knowledge) آموخته شده از یک وظیفه، به بهبود عملکرد خود در سایر وظایف مرتبط کمک میکند و به طور کلی، مدل قویتر، دقیقتر و کارآمدتری تولید میشود.
- مثال کاربردی
تحلیل زبان طبیعی (NLP) چندگانه: به جای ساخت مدلهای جداگانه برای (۱) تشخیص نام افراد در متن و (۲) تحلیل احساسات ، یک مدل واحد به صورت همزمان برای حل هر دو وظیفه آموزش داده میشود. دانش مدل در مورد ساختار جملات و معنای کلمات به صورت مشترک بین این دو وظیفه استفاده شده و دقت هر دو را بالا میبرد.
- دستهبندیهای اصلی
یادگیری چندوظیفهای بر اساس نحوه اشتراکگذاری پارامترها و معماری شبکه به دستهبندیهای زیر تقسیم میشود:
- اشتراکگذاری سخت پارامترها
- اشتراکگذاری نرم پارامترها
- تعیین وزن وظیفه
8.یادگیری کمنمونهای
- یادگیری کمنمونهای یک رویکرد پیشرفته در یادگیری ماشین است که به مدل اجازه میدهد تا با استفاده از تنها چند نمونه آموزشی در هر کلاس، وظایف جدید را به سرعت یاد بگیرد و انجام دهد. این روش مشکل کمبود دادههای برچسبگذاریشده در سناریوهای واقعی را حل میکند و به مدل کمک میکند تا با الگوهای کمی که میبیند، به سرعت تعمیم دهد و تصمیم بگیرد.

- مثال کاربردی
تشخیص گونههای کمیاب حیوانات: یک مدل FSL برای تشخیص یک گونه پرنده بسیار کمیاب آموزش داده میشود. به جای نیاز به هزاران تصویر از آن پرنده، مدل تنها با دیدن سه یا چهار تصویر از آن گونه، یاد میگیرد که آن را از سایر پرندگان مشابه تشخیص دهد.
- دستهبندیهای اصلی
تکنیکهای یادگیری کمنمونهای معمولاً با استفاده از یادگیری انتقالی یا آموزش مدلی برای “یادگیری نحوه یادگیری”به دستهبندیهای زیر تقسیم میشوند:
- شبکههای متریک
- مدلهای مولد
- متا-لرنینگ
9.یادگیری فدراسیونی
- یادگیری فدراسیونی یک رویکرد یادگیری ماشین غیرمتمرکز (Decentralized) است که به مدل اجازه میدهد از روی دادههای آموزش ببیند که در چندین دستگاه کلاینت محلی (مانند گوشیهای موبایل یا سرورهای محلی) توزیع شدهاند. در این روش، دادههای خام هرگز دستگاه کلاینت را ترک نمیکنند؛ بلکه هر کلاینت مدل را بهصورت محلی آموزش میدهد و تنها بهروزرسانیهای مدل یا وزنهای آموخته شده به یک سرور مرکزی ارسال میشوند تا در نهایت یک مدل سراسری و مشترک ساخته شود. این فرآیند با هدف حفظ حریم خصوصی دادهها در حین استفاده از مجموعههای داده بزرگ و توزیع شده طراحی شده است.
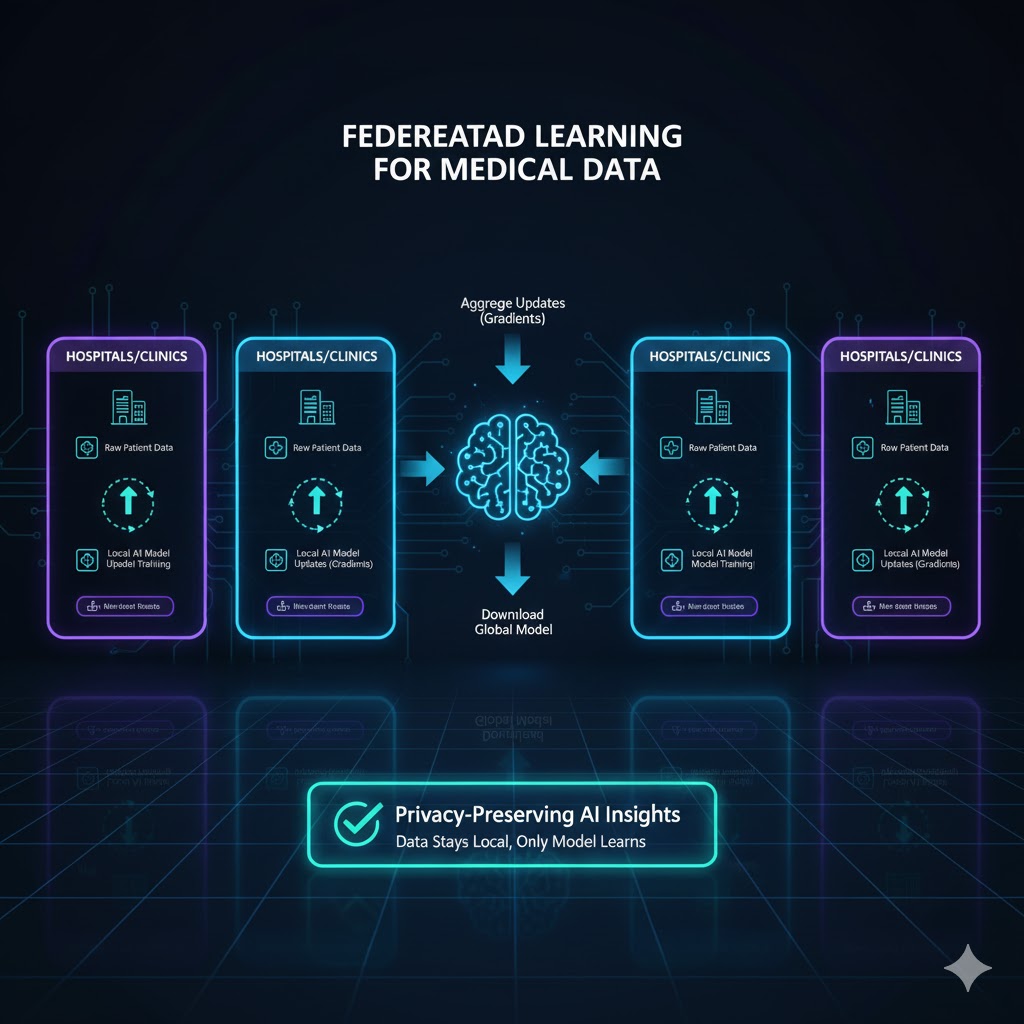
- مثال کاربردی
پیشبینی کلمه در کیبورد موبایل: مدل پیشبینیکننده کیبورد شما (عامل) بهطور مداوم روی دادههای تایپ شما (دادههای محلی) در گوشی آموزش میبیند. به جای ارسال دادههای تایپ شما به سرور مرکزی، فقط نتایج این آموزش محلی (بهروزرسانیهای وزن) به گوگل یا اپل ارسال میشود. این بهروزرسانیها با بهروزرسانیهای میلیونها کاربر دیگر ترکیب شده و یک مدل کیبورد بهتر را برای همه ایجاد میکند.
- دستهبندیهای اصلی
یادگیری فدراسیونی بر اساس نحوه توزیع دادهها در دستگاههای کلاینت به دستهبندیهای زیر تقسیم میشود:
- یادگیری فدراسیونی عمودی
- یادگیری فدراسیونی ناهمگن
- یادگیری فدراسیونی افقی
10.یادگیری پیوسته / مادامالعمر
- یادگیری پیوسته / مادامالعمر یک الگوی یادگیری ماشین است که در آن مدل به صورت متوالی و مستمر، دادهها و وظایف جدید را در طول زمان یاد میگیرد. در این روش، مدل باید بتواند دانش جدید را اکتساب کند، بدون آنکه دانش قبلی خود را در مورد وظایف قدیمی فراموش کند. هدف اصلی CLL، شبیهسازی قابلیت انعطافپذیری و حفظ حافظه در مغز انسان است.
- مثال کاربردی
دستیار شخصی هوشمند: یک دستیار شخصی (Agent) ابتدا برای انجام وظایف ساده (مانند پاسخ به آب و هوا) آموزش میبیند. سپس، در ماههای بعد، برای وظایف کاملاً جدیدی (مانند برنامهریزی سفر) آموزش میبیند. دستیار باید بتواند وظیفه جدید را انجام دهد، در حالی که همچنان وظیفه اصلی (پاسخ به آب و هوا) را به یاد داشته و فراموش نکرده باشد.
- دستهبندیهای اصلی
یادگیری پیوسته بر اساس نحوه مدیریت حافظه و دانش برای جلوگیری از فراموشی فاجعهبار به دستهبندیهای زیر تقسیم میشود:
- بازپخش و خلاصهسازی
- رشد پویا و مبتنی بر معماری
- منظمسازی مبتنی بر پارامتر
11.یادگیری بیزی
- یادگیری بیزی یک چارچوب یادگیری ماشین است که از قضیه بیز (Bayes’ Theorem) برای استنتاجهای آماری و بهروزرسانی احتمالها در مورد پارامترهای مدل استفاده میکند. در این روش، ما پارامترهای مدل را به عنوان متغیرهای تصادفی در نظر میگیریم و با دیدن دادههای جدید، باورهای قبلی خود را بهروزرسانی میکنیم تا به باورهای پسین برسیم. این روش، مدیریت عدم قطعیت و جلوگیری از بیشبرازش (Overfitting) را بهبود میبخشد.
- مثال کاربردی
تشخیص بیماری با سابقه بیمار: یک مدل برای تشخیص یک بیماری نادر استفاده میشود. قبل از دیدن علائم (دادهها)، مدل احتمال وقوع بیماری را بر اساس نرخ شیوع عمومی (باور قبلی) میداند. با مشاهده علائم جدید بیمار، مدل از قضیه بیز برای بهروزرسانی احتمال وقوع بیماری (باور پسین) استفاده میکند تا به یک تشخیص دقیقتر برسد.
- دستهبندیهای اصلی
یادگیری بیزی در مدلهای مختلفی برای انجام استنتاج و مدیریت عدم قطعیت به کار میرود:
- فیلتر کالمنمدلهای بیزی سلسلهمراتبی
- روشهای مونت کارلوی زنجیره مارکوف
- شبکه های بیزی
12.یادگیری علّی
- یادگیری علّی یک چارچوب پیشرفته در یادگیری ماشین است که هدف آن کشف و مدلسازی روابط علت و معلولی بین متغیرها است. این روش، برخلاف مدلهای همبستگی سنتی، صرفاً به دنبال کشف اینکه “چه چیزهایی با هم اتفاق میافتند” نیست، بلکه به دنبال پاسخ به این سؤال است که “چرا این اتفاق میافتد و اگر در یک متغیر مداخله کنیم، چه خواهد شد؟“. این چارچوب برای تصمیمگیریهای حساس که نیازمند تبیین و درک آثار تغییرات هستند، ضروری است.
- مثال کاربردی
تأثیر تبلیغات بر فروش: یک مدل علّی میتواند ارزیابی کند که آیا افزایش فروش (معلول) مستقیماً ناشی از افزایش بودجه تبلیغاتی (علت) بوده است یا اینکه صرفاً همزمان با آن (مثلاً تغییر فصل) رخ داده است. این امر به شرکت اجازه میدهد تا اثر واقعی مداخله (تبلیغات) را اندازهگیری کرده و بودجه خود را بهینه کند.
- دستهبندیهای اصلی
یادگیری علّی با استفاده از ابزارهای مختلف آماری و مدلسازی برای استنتاج روابط علّی به دستهبندیهای زیر تقسیم میشود:
- استنتاج علّیمدلهای ساختاری علّی
- یادگیری علّی تقویتی
- کشف ساختار علّی
13.یادگیری تکاملی
- یادگیری تکاملی یک رویکرد یادگیری ماشین و بهینهسازی است که از اصول بیولوژیکی تکامل طبیعی (مانند انتخاب طبیعی، جهش و ترکیب ژنتیکی) برای حل مسائل پیچیده استفاده میکند. در این روش، به جای آموزش مستقیم مدل، مجموعهای از راهحلهای کاندید تولید میشود که به عنوان نسلشناخته میشوند. سپس این راهحلها با استفاده از فرآیندهای تکامل، جفتگیری و جهش در طول نسلهای متوالی، بهتدریج برای رسیدن به بهترین راهحل بهینه میشوند.
- مثال کاربردی
طراحی بهینه آنتن: یک مهندس به جای طراحی دستی آنتن برای یک فرکانس خاص، مجموعهای از طراحیهای تصادفی آنتن (جمعیت اولیه) را به الگوریتم تکاملی میدهد. الگوریتم با اعمال جهش و ترکیب ژنتیکی، به طور مداوم طرحهایی را که عملکرد بهتری دارند (پاداش بیشتر)، برای نسل بعدی انتخاب میکند تا در نهایت به بهینهترین شکل آنتن برسد.
- دستهبندیهای اصلی
یادگیری تکاملی، که اغلب تحت عنوان محاسبات تکاملی شناخته میشود، به دستهبندیهای زیر تقسیم میشود:
- برنامهریزی تکاملیبرنامهریزی ژنتیکاستراتژیهای تکاملی
- بهینهسازی ازدحام ذرات
- الگوریتمهای ژنتیک
14.یادگیری درونگرا (In-context)
- یادگیری درونگرا یک قابلیت کلیدی در مدلهای زبانی بزرگ (LLMs) است که به مدل اجازه میدهد تا یک وظیفه جدید را صرفاً از طریق نمونههای ارائه شده در ورودی یاد بگیرد، بدون آنکه نیاز به بهروزرسانی پارامترها یا وزنهای شبکه عصبی خود داشته باشد. در واقع، مدل از ورودی کاربر به عنوان یک فضای کاری موقت استفاده میکند و با شناسایی الگوهای درونمتنی، وظیفه را یاد میگیرد.
- دستهبندیهای اصلی
یادگیری درونگرا بر اساس تعداد و کیفیت نمونههای ارائه شده در ورودی، به دستهبندیهای زیر تقسیم میشود:
- یادگیری یک-نمونهای درونگرایادگیری صفر-نمونهای درونگرا
- خود-اصلاحی درونگرا
- یادگیری چند-نمونهای درونگرا
15.یادگیری خودمختار
- یادگیری خودمختار یک مفهوم گسترده در هوش مصنوعی است که سیستمی را توصیف میکند که میتواند به صورت مستقل ، دانش جدید را کسب کند، مهارتها را توسعه دهد و عملکرد خود را در طول زمان بهبود بخشد. برخلاف بسیاری از روشهای دیگر، یادگیری خودمختار بر فرآیند کشف و انطباق مستمر در محیطهای پویا و در حال تغییر تمرکز دارد. این روش اغلب شامل ترکیب چندین مکانیزم یادگیری (مانند تقویتی، بدون نظارت، و یادگیری پیوسته) است.
- مثال کاربردی
رباتهای جستجوگر در فضا: یک مریخنورد (Agent) در یک سیاره ناشناخته رها میشود. مریخنورد باید بهطور خودمختار و بدون راهنمایی مستقیم از زمین، محیط را کاوش کند، تصمیم بگیرد که کدام مسیر ایمن است و کدام دادهها ارزش جمعآوری دارند، و در حین کار، مدلهای داخلی خود را بر اساس شواهد جدید (مانند سطح جدید خاک) بهروزرسانی کند.
- دستهبندیهای اصلی
مدلهای یادگیری تحت نظارت به دو دسته گسترده تقسیم میشوند که نوع خروجی نهایی آنها را مشخص میکند:
-
- دستهبندی
- رگرسیون
16. فرا-یادگیری / یادگیری فراگیر
- فرا-یادگیری (Meta-Learning) که تحت عنوان یادگیری فراگیر نیز شناخته میشود، یک چارچوب پیشرفته در یادگیری ماشین است که در آن، هدف مدل این است که نحوه یادگیری را بیاموزد. برخلاف مدلهای سنتی که پارامترهای خود را برای حل یک وظیفه خاص تنظیم میکنند، مدل فرا-یادگیری پارامترهای سطح بالاتری را یاد میگیرد تا بتواند با دیدن چند نمونه معدود ، به سرعت به وظایف جدید انطباق یابد و عملکرد خود را بهبود بخشد.
- مثال کاربردی
انطباق سریع با تشخیص دستخطهای جدید: یک مدل فرا-یادگیری روی مجموعهای از وظایف مختلف تشخیص دستخط (مثلاً الفبای یونانی، لاتین و ژاپنی) آموزش داده میشود. سپس، زمانی که با یک زبان کاملاً جدید (مثلاً کرهای) مواجه میشود، به جای نیاز به هزاران نمونه، تنها با دیدن ۱۰ نمونه از هر حرف کرهای، به سرعت مدل خود را تنظیم و با دقت بالا، وظیفه جدید را انجام میدهد.
- دستهبندیهای اصلی
فرا-یادگیری بر اساس ماهیت پارامترهایی که میآموزد و نحوه بهروزرسانی مدل پایه، به دستهبندیهای زیر تقسیم میشود:
- مبتنی بر مدل
- مبتنی بر بهینهسازی
- مبتنی بر فاصله
17. یادگیری چندرسانهای / چندوجهی (Multimodal Learning)
- یادگیری چندرسانهای / چندوجهی یک رویکرد پیشرفته در یادگیری ماشین است که در آن مدل به صورت همزمان از دادههای ورودی متعلق به چندین حالت یا حس (مانند متن، تصویر، صدا و ویدیو) آموزش میبیند. هدف اصلی این روش، ایجاد یک درک جامع و کاملتر از جهان اطراف با ترکیب نقاط قوت و اطلاعات مکمل از هر حالت است، زیرا هیچ حسگری بهتنهایی نمیتواند تمام واقعیت را درک کند.
- مثال کاربردی
توصیف خودکار ویدیو: یک مدل چندوجهی ویدیویی از جشن تولد را دریافت میکند. مدل به صورت همزمان تصاویر (برای دیدن کیک و شمع)، صدا (برای شنیدن آهنگ “تولدت مبارک”) و متن (اگر زیرنویس وجود داشته باشد) را پردازش میکند. سپس، با ادغام این حالات، ویدیو را با دقت بالا توصیف میکند: “جشن تولد با کیک و آواز”. این دقت از پردازش هر حالت به تنهایی بسیار بالاتر است.
- دستهبندیهای اصلی
یادگیری چندوجهی بر اساس نحوه و محل ادغام اطلاعات از حالتهای مختلف، به دستهبندیهای زیر تقسیم میشود:
- ادغام اولیه
- ادغام میانی
- ادغام متاخر
18. یادگیری صفرنمونهای (Zero-shot Learning)
- یادگیری صفرنمونهای یک رویکرد پیشرفته در هوش مصنوعی است که به مدل اجازه میدهد تا نمونههایی از یک کلاس یا مقوله جدید را که هرگز در دادههای آموزشی خود ندیده است، شناسایی و دستهبندی کند. این کار با استفاده از اطلاعات معنایی یا توصیفی درباره آن کلاس جدید، که در زمان آموزش در دسترس مدل بوده، انجام میشود.
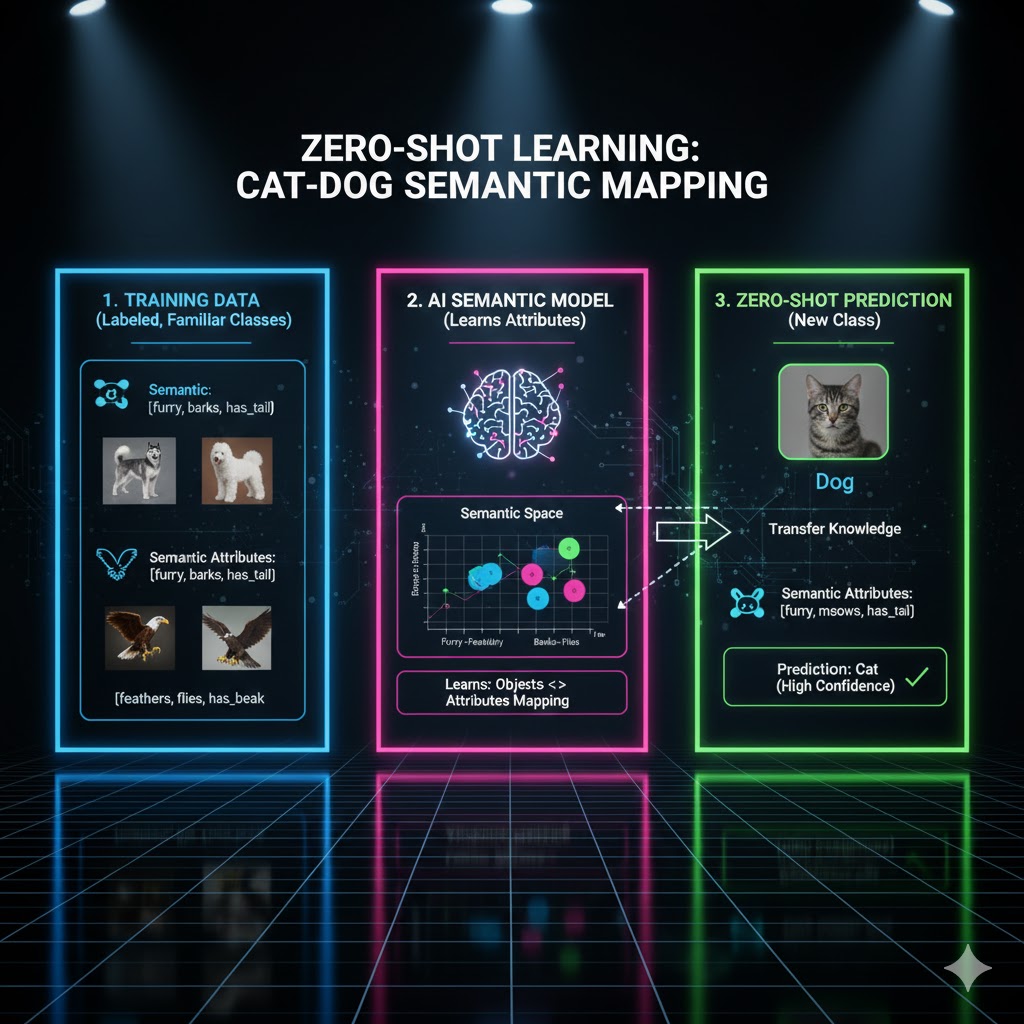
- مثال کاربردی
تشخیص حیوانی جدید: مدل تنها بر روی تصاویر سگ، گربه و اسب (کلاسهای دیده شده) آموزش دیده است. سپس از مدل خواسته میشود یک “پلنگ برفی” (کلاس دیده نشده) را تشخیص دهد. مدل با استفاده از توصیفات متنی (مثلاً “حیوان بزرگ با پوست خالدار سفید”) که در طول آموزش با آن مواجه شده است، موفق به شناسایی پلنگ برفی میشود.
- دستهبندیهای اصلی
تکنیکهای یادگیری صفرنمونهای بر اساس نحوه ارتباط فضای دیداری و فضای معنایی به دستهبندیهای زیر تقسیم میشوند:
- مدلهای مبتنی بر تعمیم
- یادگیری درونگرا
- مدلهای مبتنی بر نگاشت
19. یادگیری مشارکتی (Collaborative Learning)
- یادگیری مشارکتی یک رویکرد گسترده در هوش مصنوعی و سیستمهای چند عاملی (Multi-Agent Systems) است که در آن چندین عامل یا مدل بهطور همزمان و تعاملی با یکدیگر کار میکنند تا یک وظیفه مشترک را حل کرده و عملکرد کلی خود را بهبود بخشند. در این روش، عاملها دانش، تجربه یا تخمینهای خود را با یکدیگر به اشتراک میگذارند تا به یک نتیجه بهتر از آنچه که هر عامل بهتنهایی میتوانست به آن دست یابد، برسند.
- مثال کاربردی
خوشهبندی دادههای حساس بیمارستانی: چندین بیمارستان (عاملها) که نمیتوانند دادههای خام بیماران خود را به دلیل ملاحظات حریم خصوصی به اشتراک بگذارند، به صورت مشارکتی یک مدل خوشهبندی میسازند. هر بیمارستان مدل را روی دادههای محلی خود آموزش میدهد و تنها خلاصهای از نتایج یادگیری را با سایرین به اشتراک میگذارد تا به یک مدل خوشهبندی سراسری و دقیق برای شناسایی الگوهای درمانی مشترک دست یابند.
- دستهبندیهای اصلی
یادگیری مشارکتی اغلب در چارچوبهای زیر مورد مطالعه و پیادهسازی قرار میگیرد:
- سیستمهای چند عاملی (Multi-Agent Systems – MAS)یادگیری Ensemble
- یادگیری توزیع شده (Distributed Learning)
- یادگیری فدراسیونی (Federated Learning – FL)
20. یادگیری فعال (Active Learning)
- یادگیری فعال یک الگوی یادگیری ماشین است که در آن، الگوریتم به صورت خودکار و هوشمندانه انتخاب میکند که کدام نمونههای داده را برای برچسبگذاری (Labeling) ارسال کند. این مدل، به جای آموزش دیدن روی تمام دادههای بدون برچسب، بر روی دادههایی متمرکز میشود که بیشترین ارزش اطلاعاتی (Informative Value) را دارند و میتوانند بیشترین تأثیر را بر بهبود عملکرد مدل بگذارند. هدف اصلی، دستیابی به بالاترین دقت ممکن با کمترین حجم دادههای برچسبگذاری شده و کمترین هزینه است.
- مثال کاربردی
تشخیص تصاویر نادر: یک مدل تشخیص تصویر، هنگام مشاهده ۱۰۰۰ عکس، تنها ۲۰ عکسی را که در نزدیکی مرزهای تصمیمگیری (Decision Boundaries) آن قرار دارند (یعنی مدل در مورد آنها عدم قطعیت بالایی دارد)، برای برچسبگذاری به متخصص انسان ارسال میکند. این ۲۰ نمونه، تأثیر بیشتری در آموزش مدل نسبت به ۹۸۰ عکس واضح و ساده دارند.
- دستهبندیهای اصلی
یادگیری فعال بر اساس استراتژی مورد استفاده برای انتخاب داده، به دستهبندیهای زیر تقسیم میشود:
- نمونهگیری مبتنی بر پرسش (Query-By-Committee)
- نمونهگیری مبتنی بر واریانس پیشبینی (Expected Error Reduction)
- نمونهگیری مبتنی بر عدم قطعیت (Uncertainty Sampling)
4.کاربردهای یادگیری ماشین در دنیای واقعی + الگوریتمهای رایج
| الگوریتمها و مدلهای پرکاربرد | نوع یادگیریهای رایج | حوزه کاربردی |
|---|---|---|
| CNN، ResNet، Vision Transformer، Autoencoder، K-means، PCA | Supervised، Self-supervised، Multimodal | بینایی کامپیوتر (CV) |
| CNN، Transformer، Bayesian Models، Autoencoder | Supervised، Self-supervised، Causal، Bayesian | پزشکی و سلامت |
| RL Algorithms (DDPG, PPO)، YOLO، RNN، Bayesian Models | Reinforcement Learning، Multitask، Continual Learning | خودروهای خودران و رباتیک |
| XGBoost، Random Forest، Logistic Regression، LSTM | Supervised، Unsupervised، Bayesian | مالی و بانکداری |
| Clustering (K-means)، MF، Representation Learning | Unsupervised، Collaborative Learning | بازاریابی و تجارت الکترونیک |
| Transformers (BERT, GPT)، LSTM | Self-supervised، In-context Learning | پردازش زبان (NLP) |
| Anomaly Detection، RL، Time-series models | Unsupervised، RL، Continual Learning | صنعت، انرژی و IoT |
| Autoencoder، GNN، Anomaly Detection models | Unsupervised، Deep، Active Learning | امنیت سایبری |
5. جمع بندی
یادگیری ماشین مجموعهای از روشهاست که به کامپیوترها امکان میدهد از دادهها الگو یاد بگیرند و بدون برنامهنویسی مستقیم تصمیم بگیرند. در این فایل با انواع مهم یادگیری ماشین آشنا شدیم؛ از یادگیری نظارتشده و بدون نظارت تا روشهای پیشرفتهتری مانند یادگیری تقویتی، خودنظارتی، انتقالی، چندوظیفهای، فدرال، فراـ یادگیری، کمنمونهای، پیوسته و درونگرا.
هرکدام از این روشها برای حل یک نوع مسئله طراحی شدهاند: بعضی برای پیشبینی، بعضی برای کشف الگو، برخی برای تصمیمگیری در محیطهای پویا و برخی دیگر برای یادگیری با دادههای کم یا بدون برچسب. این تنوع باعث شده یادگیری ماشین در حوزههای مختلفی مثل پزشکی، بینایی کامپیوتر، تحلیل مالی، امنیت، انرژی، رباتیک و پردازش زبان کاربرد گسترده داشته باشد.
شناخت انواع یادگیری ماشین کمک میکند درک کنیم یک مدل چگونه آموزش میبیند، چه نقاط قوتی دارد و در چه شرایطی بهترین عملکرد را ارائه میدهد. این آشنایی قدم مهمی برای ورود به دنیای هوش مصنوعی و ساخت سیستمهای هوشمند است.
این فایل تنها یک مقدمه جامع است. در ادامه، هر روش را بهصورت جداگانه و تخصصی بررسی خواهیم کرد تا تصویر دقیقتر و کاربردیتری از یادگیری ماشین ارائه شود.



