

1.مقدمه
بازنمایی دانش یکی از بنیادیترین مباحث در هوش مصنوعی است و نقش آن فراتر از ذخیرهسازی ساده اطلاعات است. هدف اصلی بازنمایی دانش، ایجاد ساختاری است که ماشین بتواند نهتنها اطلاعات را ذخیره کند، بلکه آن را بفهمد، روی آن استدلال کند و از آن برای حل مسئله استفاده نماید. همانطور که ذهن انسان برای تفکر نیاز به زبان و نماد دارد، هوش مصنوعی نیز بدون چارچوبی رسمی برای نمایش مفاهیم، روابط و قوانین، نمیتواند هوشمندانه رفتار کند.
در دنیای امروز که حجم عظیمی از دادهها با سرعت زیاد تولید میشود، استفاده از روشهایی که بتوانند این دانش را سازماندهی و قابل تفسیر کنند، ضرورتی انکارناپذیر است. سیستمهای هوش مصنوعی با تکیه بر بازنمایی دانش میتوانند اطلاعات پراکنده را به شکل ساختاریافته درآورند، استنتاج انجام دهند، تصمیمگیری دقیقتری ارائه کنند و در شرایط جدید سازگار شوند.
این مقاله با هدف ارائه نگاهی جامع به بازنمایی دانش تهیه شده است؛ ابتدا انواع مختلف دانش بررسی میشود، سپس چرخه دانش در هوش مصنوعی توضیح داده میشود. در ادامه، روشهای کلاسیک و مدرن بازنمایی دانش (از منطق و شبکههای معنایی گرفته تا گرافهای دانش، تعبیهها و روشهای نوروسیمبولیک) تحلیل میگردد. همچنین کاربردهای عملی KR در حوزههایی مانند موتورهای جستجو، پزشکی، NLP، وب معنایی و رباتیک بیان شده و در نهایت مزایا و محدودیتهای این رویکرد مورد ارزیابی قرار میگیرد. هدف نهایی مقاله، ارائه تصویری یکپارچه از اهمیت KR در ساخت سیستمهای هوشمند و نقش آن در آینده هوش مصنوعی است.
2.تعریف بازنمایی دانش
بازنمایی دانش یعنی استفاده از روشها و چارچوبهایی برای کدگذاری و ذخیره دانش، به طوری که ماشین بتواند با آن “استدلال” کند. این فناوری:
- حجم عظیمی از دادههای پیچیده را ساده و ساختاریافته میکند.
- به ماشینها اجازه میدهد از تجربیات گذشته یاد بگیرند.
- یادگیری ماشین (Machine Learning) را با ارائه ساختارهای دادهای بهتر تقویت میکند تا الگوها راحتتر شناسایی شوند.
- در حوزههای مختلفی مثل پزشکی، رباتیک و امور مالی کاربرد دارد و باعث میشود تصمیمات سریعتر و آگاهانهتری گرفته شود.
3. انواع دانش در هوش مصنوعی
سیستمهای هوش مصنوعی برای عملکرد کارآمد به انواع مختلفی از دانش متکی هستند. هر نوع نقش خاصی در استدلال، تصمیمگیری و حل مسئله ایفا میکند. در زیر انواع اصلی دانش مورد استفاده در هوش مصنوعی آمده است:
3.1. دانش بیانی (دانش توصیفی)
دانش اعلانی شامل حقایق و اطلاعاتی درباره جهان است که سیستمهای هوش مصنوعی ذخیره و در صورت نیاز بازیابی میکنند. این دانش نشان دهنده «چه چیزی» است که شناخته شده است، نه «چگونه» انجام کاری. این نوع دانش اغلب در قالبهای ساختاریافته مانند پایگاههای داده، هستیشناسیها و نمودارهای دانش ذخیره میشود .
برای مثال، حقیقتی مانند «پاریس پایتخت فرانسه است» دانش اخباری است. برنامههای هوش مصنوعی مانند موتورهای جستجو و دستیاران مجازی از این نوع دانش برای پاسخ به پرسشهای واقعی و ارائه اطلاعات مرتبط استفاده میکنند.
3.2 دانش رویهای (دانش چگونگی انجام کار)
دانش رویهای، مراحل یا روشهای مورد نیاز برای انجام وظایف خاص را تعریف میکند . این دانش به جای بیان صرف یک واقعیت، نشان دهندهی «چگونگی» انجام کاری است .
برای مثال، دانستن چگونگی حل یک معادله درجه دوم یا نحوه رانندگی با ماشین، در زمره دانش رویهای قرار میگیرد. سیستمهای هوش مصنوعی، مانند سیستمهای خبره و رباتیک، از دانش رویهای برای اجرای وظایفی که نیاز به توالی اقدامات دارند، استفاده میکنند. این نوع دانش اغلب در سیستمهای مبتنی بر قانون، درختهای تصمیمگیری و مدلهای یادگیری ماشین کدگذاری میشود.
3.3 فرا-دانش (دانش درباره دانش)
به دانشی در مورد چگونگی ساختاردهی، استفاده و اعتبارسنجی اطلاعات اشاره دارد . این به هوش مصنوعی کمک میکند تا قابلیت اطمینان، مرتبط بودن و کاربردپذیری دانش را در سناریوهای مختلف تعیین کند.
برای مثال، یک سیستم هوش مصنوعی که تصمیم میگیرد یک توصیه پزشکی از یک منبع علمی معتبر آمده یا یک پست وبلاگ تصادفی، از فرادانش استفاده میکند. این نوع دانش در مدلهای هوش مصنوعی برای فیلتر کردن اطلاعات نادرست، بهینهسازی استراتژیهای یادگیری و بهبود تصمیمگیری بسیار مهم است.
3.4 دانش اکتشافی (دانش مبتنی بر تجربه)
دانش اکتشافی از تجربه، شهود و روشهای آزمون و خطا حاصل میشود و به سیستمهای هوش مصنوعی اجازه میدهد تا در مواقعی که محاسبه پاسخهای دقیق دشوار است، حدسهای آگاهانه یا راهحلهای تقریبی ارائه دهند.
برای مثال، یک سیستم ناوبری که بر اساس الگوهای ترافیکی گذشته، مسیر جایگزینی را پیشنهاد میدهد، از دانش اکتشافی استفاده میکند. الگوریتمهای جستجوی هوش مصنوعی، مانند جستجوی A* و الگوریتمهای ژنتیک، از اکتشافات برای بهینهسازی فرآیندهای حل مسئله استفاده میکنند و تصمیمگیریها را در سناریوهای دنیای واقعی کارآمدتر میکنند.
3.5 دانش مبتنی بر عقل سلیم
دانش مبتنی بر عقل سلیم ، درک اولیهای از جهان است که انسانها به طور طبیعی به دست میآورند، اما یادگیری آن برای هوش مصنوعی چالشبرانگیز است . این دانش شامل حقایقی مانند « آب خیس است» یا «اگر چیزی را رها کنید، میافتد » میشود.
سیستمهای هوش مصنوعی اغلب با این نوع دانش مشکل دارند، زیرا به درک زمینهای فراتر از برنامهنویسی صریح نیاز دارد .
محققان با استفاده از پایگاههای دانش در مقیاس بزرگ مانند ConceptNet، استدلال مبتنی بر عقل سلیم را در هوش مصنوعی ادغام میکنند که به ماشینها کمک میکند منطق روزمره را درک کرده و تعامل خود با انسانها را بهبود بخشند.
3.6 دانش تخصصی
دانش تخصصی بر زمینههای تخصصی مانند پزشکی، امور مالی، حقوق یا مهندسی تمرکز دارد و شامل اطلاعات بسیار دقیق و ساختاریافته مربوط به یک صنعت خاص است.
4. رابطه دانش و هوش در سیستم های هوشمند
در دنیای هوش مصنوعی، “دانش” و “هوش” دو مفهوم جدا اما وابسته به هم هستند:
- دانش مواد اولیه (حقایق و اطلاعات) را فراهم میکند.
- هوش توانایی استفاده از آن مواد برای حل مسئله و تصمیمگیری است.
یک سیستم AI که دانش بیشتری دارد، هوشمندتر به نظر میرسد چون میتواند انتخابهای دقیقتری داشته باشد.
- دانش بدون هوش: صرفاً انبار کردن اطلاعات خام است بدون توانایی استفاده از آنها.
- هوش بدون دانش: مثل ماشینی است که موتور قوی دارد اما سوخت (اطلاعات) ندارد و نمیتواند تصمیم درستی بگیرد.
مثال: فروشگاههای آنلاین از آنچه مشتریان قبلاً دیدهاند (دانش گذشته) استفاده میکنند تا محصولات جدیدی را پیشنهاد دهند (هوش و تصمیمگیری). هوش مصنوعی واقعی زمانی شکل میگیرد که ماشین بتواند دانش را درک کرده و در موقعیتهای جدید پیادهسازی کند.
5. چرخه دانش هوش مصنوعی
چرخه دانش در هوش مصنوعی یک فرآیند پویا و تکرارشونده است که نحوه کسب، ساختاردهی، پردازش، استفاده و پالایش دانش را در سیستمهای هوشمند نشان میدهد. این چرخه تضمین میکند که سیستم قادر باشد با تغییر شرایط، یادگیری مستمر داشته باشد و عملکرد خود را به مرور زمان بهبود دهد.
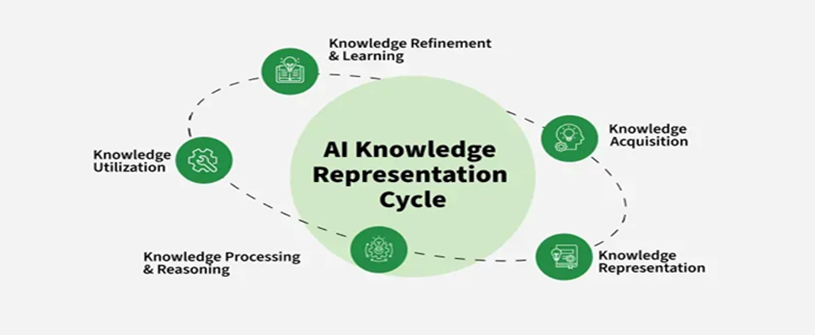
5.1 کسب دانش (Knowledge Acquisition)
در این مرحله، سیستم هوش مصنوعی دادهها را از منابع مختلف مانند پایگاههای داده ساختاریافته، متن، تصویر، صوت و تعاملات دنیای واقعی جمعآوری میکند. ابزارهایی مانند یادگیری ماشین، پردازش زبان طبیعی و بینایی کامپیوتر امکان استخراج دانش اولیه از دادهها را فراهم میکنند.
5.2 بازنمایی دانش (Knowledge Representation)
پس از جمعآوری، دانش باید در قالبی ساختاریافته ذخیره شود تا سیستم بتواند آن را بازیابی و تفسیر کند. روشهای مختلف بازنمایی—از منطق و شبکههای معنایی تا گراف دانش و تعبیهها—در این مرحله به کار گرفته میشوند.
5.3 پردازش و استدلال (Reasoning and Processing)
در این مرحله، سیستم با استفاده از استنتاج منطقی، مدلهای احتمالاتی و الگوریتمهای یادگیری عمیق تلاش میکند از دانش موجود، اطلاعات جدید استخراج کند. استدلال قیاسی، استقرایی، جستجوی اکتشافی و بهینهسازی از اصلیترین فرایندهای این بخش هستند.
5.4 بهکارگیری دانش (Knowledge Utilization)
دانش پردازششده در وظایف واقعی به کار میرود، از جمله تصمیمگیری، پیشبینی، تحلیل، طبقهبندی و اتوماسیون. این استفاده میتواند در حوزههایی مانند سیستمهای توصیهگر، دستیارهای هوشمند یا کنترل خودکار انجام شود.
5.5 پالایش و یادگیری (Knowledge Refinement)
در مرحله نهایی، سیستم با استفاده از بازخورد، خطاها، دادههای جدید یا تغییرات محیط، پایگاه دانش خود را بهروزرسانی میکند. روشهایی مانند یادگیری تقویتی، یادگیری فعال و تنظیم دقیق مدلها باعث میشوند سیستم در طول زمان تکامل یابد و دقت آن افزایش یابد.
6.تکنیکهای بازنمایی دانش
A)روشهای کلاسیک بازنمایی دانش
- منطقی (Logical)
- شبکه معنایی (Semantic Network)
- قابها (Frame)
- قوانین تولید (Production Rules)
B)روشهای مدرن بازنمایی دانش
- گراف دانش (Knowledge Graphs)
- تعبیهها و بردارهای معنایی (Embeddings)
- هستیشناسیهای مدرن
- بازنمایی عصبی (Neural KR)
- بازنمایی ترکیبی (Neuro-Symbolic)
- بازنمایی علّی
- بازنمایی چندوجهی
A )روشهای کلاسیک بازنمایی دانش
1.بازنمایی منطقی چیست؟
بازنمایی منطقی یعنی استفاده از نمادها و قوانین برای توصیف جهان. در این روش، حقایق و روابط به زبان دقیق ریاضی نوشته میشوند تا ماشین بتواند بدون هیچ ابهامی استدلال کند. این روش مثل یادگیری گرامر یک زبان جدید است و دو بخش اصلی دارد:
- نحو (Syntax) : همان گرامر یا ساختار ظاهری است. قوانینی که تعیین میکنند چه فرمولی معتبر است.
- مثال: اگر بنویسیم P Q ⭠ ، ماشین گیج میشود چون ساختار غلط است (مثل اینکه در فارسی بگوییم: “علی مدرسه به رفت”). نحو صحیح باید P ⮕ Q باشد تا سیستم بتواند آن را پردازش کند.
- معنا (Semantics) : مفهوم پشت نمادهاست. تعیین میکند که آیا یک جمله درست است یا غلط.
- مثال: فرض کنید P یعنی “باران میبارد” و Q یعنی “جاده خیس است”. فرمول P به Q به لحاظ معنایی یعنی: “اگر باران ببارد، آنگاه جاده خیس میشود”. این بخش به هوش مصنوعی کمک میکند تا صرفاً با نمادها بازی نکند، بلکه معنی آنها را بفهمد و نتیجهگیری کند.
انواع بازنمایی منطقی
- منطق گزارهای (Propositional Logic – PL) : دانش را به صورت گزارههای خبری (گزارهها) که توسط عملگرهای منطقی مانند AND، OR و NOT به هم مرتبط شدهاند، نشان میدهد. برای مثال، “اگر باران ببارد (الف) و زمین خیس باشد (ب)، آنگاه جاده لغزنده است (ج).” اگرچه ساده است، اما با روابط پیچیده مشکل دارد. اغلب از قالب “اگر شرط باشد، آنگاه نتیجه” پیروی میکند.
- منطق مرتبه اول (First-Order Logic – FOL) : نسخه پیشرفتهتر است که شامل “اشیاء”، “روابط” و مفاهیمی مثل “همه” (Quantifiers) میشود.
مزایای بازنمایی منطقی
- دقت مطلق: ابهام و ایهام را از بین میبرد. همه چیز شفاف و صفر و یکی است.
- قدرت استدلال: به سیستم اجازه میدهد بر اساس حقایق موجود، حقایق جدید را اثبات کند (مثل حل مسائل ریاضی).
- پایه علمی: این روش از نظر ریاضی دقیق است و برای ساخت سیستمهای خبره و اثبات قضایا عالی است.
معایب بازنمایی منطقی
- کندی و پیچیدگی: استنتاجهای منطقی (بهخصوص در منطق مرتبه اول) به محاسبات سنگینی نیاز دارند و ممکن است سیستم را کند کنند.
- ضعف در عدم قطعیت: این روش دنیای واقعی را سیاه و سفید میبیند. مدیریت مفاهیمی مثل “شاید”، “احتمالاً” یا دادههای ناقص برایش دشوار است.
- خشکی و عدم انعطاف: همه قوانین باید دقیق تعریف شوند. اگر اطلاعات تغییر کند یا مبهم باشد، سیستم به مشکل میخورد.
- مشکل مقیاسپذیری: هرچه حجم دانش بیشتر شود، مدیریت قوانین و استدلال کردن در بین انبوهی از فرمولها سختتر و ناکارآمدتر میشود.
2. بازنمایی شبکه معنایی (Semantic Network Representation)
شبکه معنایی روشی برای ساختاردهی دانش است که شبیه یک تارعنکبوت یا نقشه عمل میکند. در این روش، مفاهیم (مثل “سگ”) به عنوان گرهها و روابط بین آنها (مثل “حیوان است”) به عنوان خطوط اتصال در نظر گرفته میشوند.
آن را مثل یک نقشه ذهنی تصور کنید. وقتی ما به “سگ” فکر میکنیم، بلافاصله به “حیوان” هم فکر میکنیم. شبکه معنایی دقیقاً همین کار را میکند. این روش به برنامههای کامپیوتری اجازه میدهد تا با دنبال کردن این خطوط، چیزهای جدیدی را بفهمند.
- مثال: اگر سیستم بداند “سگها حیوان هستند” و “حیوانات غذا میخورند”، به طور خودکار نتیجه میگیرد که “سگها هم غذا میخورند”.
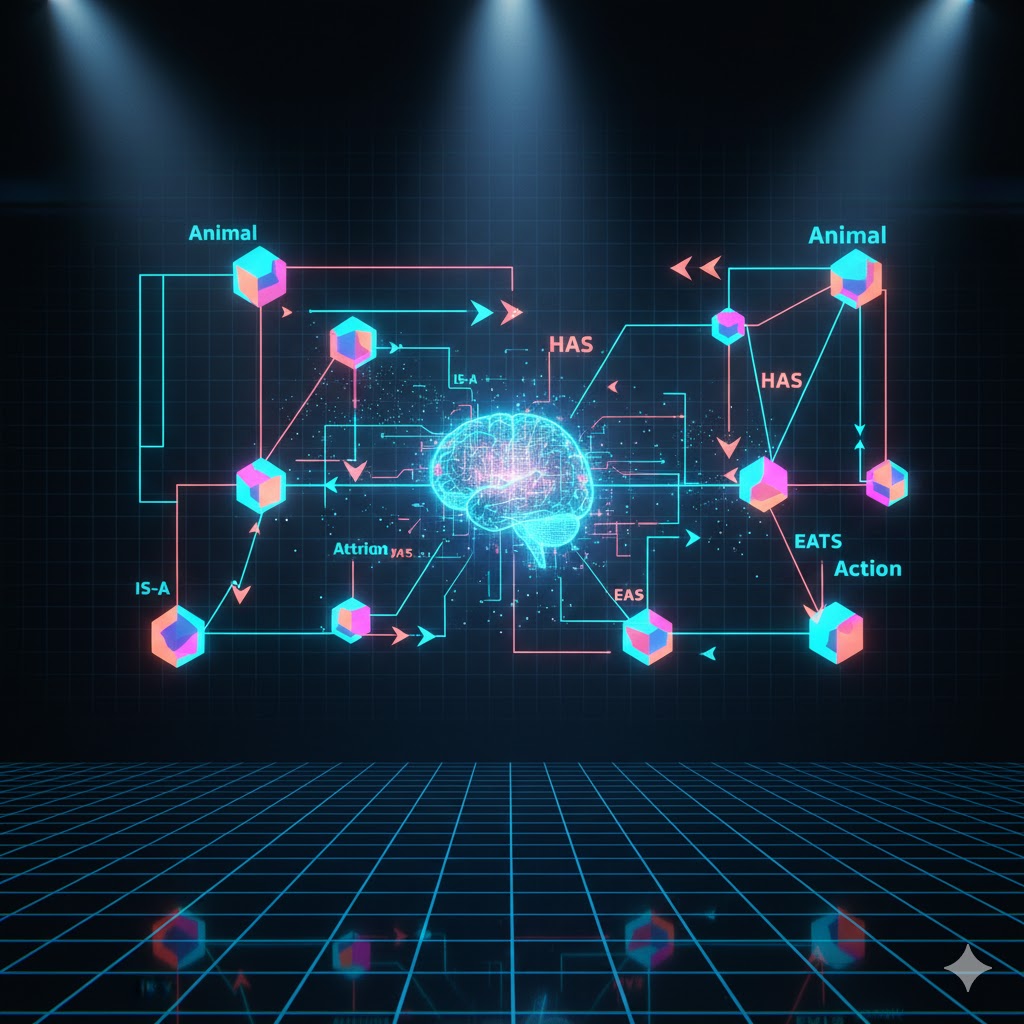
مثال کاربردی: سیستم دانشگاه
بیایید یک سیستم دانشگاهی را با گرهها و خطوط تصور کنیم:
- جان ⭠ دانشجو است.
- جان ⭠ علوم کامپیوتر میخواند.
- علوم کامپیوتر ⭠یک دپارتمان است.
- همه دپارتمانها ⭠متعلق به دانشگاه هستند.
- جان ⭠ لپتاپ دارد.
- جان ⭠ لپتاپ دِل (Dell) دارد.
نتیجهگیری هوش مصنوعی:
با نگاه به این شبکه، سیستم میتواند نتایج جدیدی بگیرد که ما مستقیماً به آن نگفتهایم. مثلاً:
- چون جان “کامپیوتر” میخواند و کامپیوتر جزو “دانشگاه” است، پس جان به دانشگاه وصل است.
- چون جان لپتاپ “دل” دارد، منطقی است فرض کنیم که او از آن برای کارهای درسیاش استفاده میکند.
مزایای شبکه معنایی
- طبیعی و ملموس: ذخیره و بازیابی اطلاعات در این روش بسیار شبیه به دنیای واقعی است.
- ارثبری: (Inheritance) این قابلیت بسیار مهم است. یعنی لازم نیست برای تکتک موجودات ویژگیها را تعریف کنیم. اگر بگوییم “پرندگان پرواز میکنند”، سیستم خودکار میفهمد که “عقاب” هم (که یک پرنده است) پرواز میکند.
- بصری سازی: فهمیدن و گسترش دادن آن آسان است (فقط کافیست گرهها و خطوط جدید اضافه کنید).
- قدرت استدلال: با دنبال کردن خطوط، سیستم میتواند روابط پنهان را کشف کند.
معایب شبکه معنایی
- مدیریت سخت در مقیاس بزرگ: وقتی تعداد مفاهیم و روابط زیاد شود، شبکه چنان پیچیده و درهمتنیده میشود که مدیریت آن کابوس خواهد بود.
- عدم استاندارد: روش یکسانی برای نامگذاری روابط وجود ندارد که ممکن است باعث ناهماهنگی شود.
- هزینه پردازشی بالا: پیدا کردن یک رابطه خاص در یک شبکه غولپیکر، زمان و قدرت پردازشی زیادی میطلبد.
- مشکل با احتمالات: این شبکهها در نشان دادن مفاهیم قطعی خوب هستند، اما در برابر مفاهیم “احتمالی” یا “ناطمئن” (مثلاً شاید باران بیاید) نسبت به مدلهای آماری ضعف دارند.
3.بازنمایی قاب: (Frame Representation) بایگانیِ ذهنِ ماشین
بازنمایی قاب روشی هوشمندانه برای سازماندهی جزئیات درباره اشیاء، رویدادها یا مفاهیم است. ایده اصلی این روش از حافظه انسان گرفته شده است؛ ذهن ما برای یادآوری چیزها از «قالبها» یا «الگوهای آماده» استفاده میکند. در هوش مصنوعی، هر قاب (Frame) مثل یک فرم خالی است که دارای ویژگیها (Slots) و مقادیر (Fillers) است.
مثال ساده: بیایید مفهوم «ماشین» را در نظر بگیریم.
- قاب: ماشین
- ویژگیها (جای خالی): رنگ، مدل، برند، سال ساخت.
- مقادیر (پرکنندهها): قرمز، مدل X، تسلا، ۲۰۲۳. در واقع ما یک فرم خام داشتیم و با اطلاعات خاص آن را پر کردیم.
اجزای اصلی بازنمایی قاب
برای اینکه دانش به درستی ساختاردهی شود، این روش ۵ جزء کلیدی دارد:
- قابها (Frames) : همان ساختار یا پرونده کلی که دادههای مربوط به یک موجودیت یا موقعیت را نگه میدارد. اینها الگوهای اصلی هستند.
- اسلاتها (Slots) : ویژگیها یا صفات آن قاب هستند.
- مثال: در قابِ «انسان»، اسلاتها میتوانند شامل: نام، سن، جنسیت و شغل باشند.
- فیلرها (Fillers) : مقادیر واقعی که در اسلاتها قرار میگیرند.
- مثال: در اسلاتِ «نام»، مقدار «جان دو» قرار میگیرد.
- روابط بین قابها: قابها میتوانند به هم وصل شوند تا روابط را نشان دهند.
- مثال: قابِ «ماشین» میتواند به قابِ «مالک» وصل شود تا نشان دهد ماشین متعلق به چه کسی است.
- مقادیر پیشفرض (Default Values) : مقادیری که سیستم به طور خودکار فرض میکند، مگر اینکه خلافش گفته شود.
- مثال: در قاب «ماشین»، اگر رنگی ذکر نشود، سیستم ممکن است به طور پیشفرض «مشکی» را در نظر بگیرد.
مزایای بازنمایی قاب
- نظم و ترتیب: اطلاعات را به شکلی بسیار قابلفهم و دستهبندی شده سازماندهی میکند که کار برنامهنویسی را راحت میکند.
- انعطافپذیری: توسعه آن آسان است؛ به راحتی میتوان ویژگیها (اسلاتهای) جدید به آن اضافه کرد.
- درک آسان: از آنجا که شبیه فرمهای اطلاعاتی است، انسانها به راحتی میتوانند ساختار دادهها را ببینند و درک کنند.
- کاربردی: برای حوزههایی مثل پردازش زبان طبیعی (NLP) و بینایی ماشین بسیار مناسب است.
معایب بازنمایی قاب
- جستجوی دشوار: پیدا کردن یک اطلاعات خاص در میان انبوهی از قابهای تودرتو میتواند زمانبر و چالشبرانگیز باشد.
- سختی در استنتاج: نوشتن قوانینی که بتوانند از روی این قابها دانش جدیدی استخراج کنند (به خصوص در سیستمهای بزرگ) دشوار است.
- محدودیت در پیچیدگی: مدلسازی دانشهای بسیار پویا یا پیچیده که نیاز به اتصالات متعدد دارند، در این روش سخت است.
- ضعف در ابهام: این سیستم برای دانشهای ساختاریافته عالی است، اما در برابر مفاهیم انتزاعی یا مبهم (که جای مشخصی در فرم ندارند) عملکرد خوبی ندارد.
4. قوانین تولید: (Production Rules) منطقِ «اگر-آنگاه»
قوانین تولید یک تکنیک بازنمایی دانش است که دقیقاً مثل دستورالعملهای شرطی عمل میکند. این روش از مجموعهای از قوانین «اگر-آنگاه» (If-Then) تشکیل شده که برای تصمیمگیری و حل مسئله استفاده میشوند. این قوانین قلب تپنده «سیستمهای خبره» هستند و بر اساس شرایط موجود، اقدام مناسب را انجام میدهند.
فرمول کلی: اگر (شرط) برقرار بود، آنگاه (عمل) را انجام بده.
- مثال: اگر دما بالای ۴۰ درجه است، آنگاه فن را روشن کن.
این سیستمها از سه بخش اصلی تشکیل شدهاند: پایگاه قوانین، موتور استنتاج (که قوانین را بررسی میکند) و روشهای استدلال (مثل زنجیرهسازی رو به جلو یا عقب).
مثالهایی از قوانین تولید در دنیای واقعی
اینها نمونههایی هستند از اینکه چگونه شرطها به عمل تبدیل میشوند:
- پزشکی: اگر بیمار تب و سرفه دارد، آنگاه تشخیص آنفلوآنزا است.
- ایمیل: اگر کلماتی مثل “برنده جایزه” یا “پول مفت” در متن بود، آنگاه ایمیل را اسپم کن.
- خانه هوشمند: اگر حرکت در شب تشخیص داده شد، آنگاه چراغها را روشن کن.
- چتبات: اگر کاربر گفت “سلام”، آنگاه پاسخ بده: “سلام! چطور میتونم کمکتون کنم؟”
مزایای قوانین تولید
- سادگی: فهمیدن منطق “اگر-آنگاه” برای همه (حتی غیر برنامهنویسها) بسیار ساده است.
- ماژولار بودن (انعطافپذیری): میتوان قوانین جدید اضافه کرد یا قوانین قدیمی را حذف کرد بدون اینکه کل سیستم به هم بریزد.
- مثال: در یک خانه هوشمند، میتوانید قانون جدیدی اضافه کنید که “اگر دما بالای ۳۰ درجه رفت، کولر را روشن کن” و این قانون تداخلی با قوانین قبلی (مثل روشن کردن چراغ) ندارد.
- جداسازی: دانش (قوانین) از پردازشگر (موتور استنتاج) جداست، بنابراین نگهداری و تعمیر آن آسانتر است.
معایب قوانین تولید
- پیچیدگی در مقیاس بالا: وقتی تعداد قوانین از چند صد یا هزارتا بیشتر شود، مدیریت آنها و جلوگیری از تداخل قوانین بسیار پیچیده میشود.
- کندی سرعت: سیستم باید قوانین را یکییکی چک کند تا ببیند کدام شرط برقرار است؛ این کار میتواند سیستم را کند کند.
- عدم یادگیری: این سیستمها (برخلاف یادگیری ماشین) از تجربیات گذشته درس نمیگیرند و فقط طبق دستورالعمل ثابت رفتار میکنند.
- مشکل با عدم قطعیت: قوانین تولید در شرایط شفاف عالی عمل میکنند، اما وقتی دادهها احتمالی یا مبهم باشند (مثلاً “شاید بیمار تب داشته باشد”)، دچار مشکل میشوند.
B.روشهای مدرن بازنمایی دانش
در کنار روشهای کلاسیک مانند منطق، شبکههای معنایی، قابها و قوانین تولید، نسل جدیدی از روشهای بازنمایی دانش در سالهای اخیر معرفی شدهاند که قدرت بیشتری در درک معنایی، مقیاسپذیری، یادگیری و تحلیل دادههای پیچیده دارند. این روشها برای کار با دادههای بزرگ، متن، تصویر، گراف و زبان طبیعی طراحی شدهاند و نقش مهمی در سیستمهای هوشمند امروزی ایفا میکنند.
1. گراف دانش (Knowledge Graphs)
گراف دانش یکی از قدرتمندترین و رایجترین روشهای مدرن بازنمایی دانش است. در این روش، دانش به صورت گرهها (مفاهیم) و یالها (روابط) نمایش داده میشود. دقیقاً مثل یک «نقشه معنایی عظیم» که از هر مفهوم به مفهوم دیگر پل میزند.
مثال – Google Knowledge Graph: پایگاه دانشی که گوگل برای نمایش اطلاعات افراد، مکانها، سازمانها و هزاران مفهوم استفاده میکند.
مزایا
- نمایش طبیعی رابطهها
- قابلیت استنتاج از طریق پیوند میان مفاهیم
- مقیاسپذیری برای دادههای بسیار بزرگ
- مناسب برای وب معنایی و جستجوی معنایی
معایب
- ساخت و نگهداری آن زمانبر است
- نیازمند استانداردسازی دقیق
- استنتاج در گرافهای بسیار بزرگ هزینهبر است
کاربردها
- موتورهای جستجو
- سیستمهای توصیهگر
- NLP
- وب معنایی (Semantic Web)
2. بازنمایی برداری / تعبیهها (Embeddings)
Embeddings یکی از مهمترین روشهای مدرن است که دانش را به بردارهای عددی با ابعاد کم تبدیل میکند. این روش باعث میشود مفاهیم مختلف در یک «فضای معنایی» قرار گیرند و ماشین بتواند شباهت معنایی را بفهمد.
مثالها Word2Vec : ، GloVe، FastText، BERT Embeddings
مزایا
- توانایی درک معنای پنهان در متن
- قابلیت مدلسازی روابط پیچیده
- مناسب برای یادگیری ماشین و deep learning
- توانایی کار با دادههای بزرگ
معایب
- تفسیرپذیری کم (Black-box)
- نیاز به داده زیاد
- امکان سوگیری معنایی در دادههای آموزشی
کاربردها
- پردازش زبان طبیعی (NLP)
- جستجوی معنایی
- تحلیل احساسات
- مدلهای چندوجهی (تصویر+متن)
3. هستیشناسیهای مدرن (Ontologies)
هستیشناسیها مدلهای دقیق و سازمانیافتهای هستند که مفاهیم یک حوزه و روابط بین آنها را به طور رسمی توصیف میکنند. نسخههای جدید از استانداردهای جهانی مانند OWL و RDF استفاده میکنند.
مثال:هستیشناسی پزشکی SNOMED CT که روابط دقیق بین بیماریها، علائم و داروها را مدلسازی میکند.
مزایا
- ساختار رسمی و دقیق
- امکان استنتاج معنایی پیشرفته
- استفاده گسترده در وب معنایی
معایب
- ساخت و نگهداری دشوار
- نیازمند متخصصان حوزه
- عدم سازگاری با دادههای بسیار پویا
کاربردها
- پزشکی
- وب معنایی
- سیستمهای دانشبنیان
4. بازنمایی عصبی (Neural Knowledge Representation)
در این روش دانش با استفاده از شبکههای عمیق مدلسازی میشود. برخلاف روشهای نمادین، این روش الگوهای پیچیده را بدون نیاز به تعریف صریح قوانین استخراج میکند.
مثال Transformer:ها (مثل BERT و GPT) که دانش زبان را در قالب وزنها ذخیره میکنند.
مزایا
- قابلیت یادگیری خودکار
- عملکرد بسیار بالا در زبان و تصویر
- کارآمد برای دادههای بزرگ
معایب
- عدم شفافیت (غیرقابلتفسیر)
- نیازمند سختافزار قوی
- خطر سوگیری داده
کاربردها
- مدلهای زبانی بزرگ (LLM)
- ترجمه ماشینی
- تولید متن و تصویر
5. بازنمایی ترکیبی (Neuro-Symbolic AI)
این روش ترکیبی از بازنمایی نمادین (مثل منطق و گراف) و بازنمایی عصبی (مثل Embeddings) است. هدف آن ایجاد سیستمی است که هم بتواند استنتاج منطقی انجام دهد و هم یادگیری عمیق داشته باشد.
مثال:مدلهایی که روابط منطقی را با شبکه عصبی ترکیب میکنند.
مزایا
- جمع کردن مزایای منطق + شبکه عصبی
- مناسب برای استنتاج پیچیده
- بهبود عملکرد LLMها
معایب
- طراحی پیچیده
- نیازمند منابع محاسباتی بالا
کاربردها
- استنتاج معنایی
- تحلیل دانش در LLMها
- رباتیک هوشمند
6.بازنمایی علّی (Causal Representation)
در این روش، دانش نه فقط بهصورت رابطه، بلکه بهصورت علت و معلول نمایش داده میشود. سیستم میتواند بفهمد «چه چیزی باعث چه چیزی میشود».
مثال:مدلهایی که در پزشکی تعیین میکنند چه عاملی باعث بیماری میشود.
مزایا
- تصمیمگیری دقیقتر
- قابل اعتماد در دادههای پیچیده
- کاربردی در علوم پزشکی و اقتصاد
معایب
- استخراج روابط علّی دشوار
- نیازمند دادههای قوی و کنترلشده
کاربردها
- پزشکی
- تحلیل ریسک
- مدلسازی اقتصادی
7.بازنمایی چندوجهی (Multimodal Representation)
این روش دانش را از منابع متنوع مثل تصویر، متن، صوت، ویدئو به صورت یکپارچه نمایش میدهد.
مثال CLIP: که ارتباط بین تصویر و متن را یاد میگیرد.
مزایا
- درک عمیقتر از جهان
- مناسب برای سیستمهای هوش مصنوعی جامع
- کاربردهای بسیار در بینایی و NLP
معایب
- نیازمند دادههای عظیم
- مدلسازی چندمنبعی پیچیده است
کاربردها
- خودروهای خودران
- مدلهای بینایی–زبانی
- تشخیص صحنه
7.کاربردهای بازنمایی دانش در هوش مصنوعی
بازنمایی دانش نقش کلیدی در بسیاری از فناوریها و سیستمهای هوشمند دارد. زیرا دانش ساختارمند، پایه استدلال، تصمیمگیری و یادگیری هوشمند را تشکیل میدهد. مهمترین کاربردهای آن عبارتند از:
7.1 موتورهای جستجو و سیستمهای بازیابی اطلاعات
- بازنمایی دانش باعث میشود موتورهای جستجو مانند: Google روابط میان مفاهیم را بفهمند ، جستجوی معنایی انجام دهند ، نتایج دقیقتری ارائه دهند
- مثال:گراف دانش گوگل (Google Knowledge Graph) که اطلاعات اشخاص، مکانها و مفاهیم را به شکل گراف ذخیره میکند.
7.2 سیستمهای توصیهگر (Recommendation Systems)
- KR به سیستمهای توصیهگر کمک میکند رفتار و علایق کاربر را بهتر تحلیل کنند.
- کاربردها:پیشنهاد فیلم (Netflix) ، پیشنهاد محصول (Amazon) ، پیشنهاد محتوا در شبکههای اجتماعی.
- مثال:سیستمها با استفاده از دانش پیشین کاربر + روابط میان آیتمها، پیشنهادهای دقیقتری ارائه میکنند.
7.3 پردازش زبان طبیعی (NLP)
- برای درک معنای جملات و استخراج اطلاعات، مدلها به دانش ساختاریافته نیاز دارند.
- کاربردها:چتباتها ، سیستمهای پرسشوپاسخ ، خلاصهسازی متون ، استخراج موجودیتها و روابط
- مثال:هستیشناسیها و گرافهای معنایی برای تحلیل عمق معنایی جملات استفاده میشوند.
7.4 سیستمهای خبره (Expert Systems)
- یکی از اولین و مهمترین کاربردهای KR.
- کاربردها:تشخیص پزشکی ، تحلیل ریسک ، پشتیبانی تصمیمگیری ، مدیریت فرآیندهای صنعتی.
- مثال:سیستم MYCIN که با استفاده از قوانین «اگر–آنگاه» بیماریهای عفونی را تشخیص میداد.
7.5 رباتیک و سیستمهای مبتنی بر ادراک (Robotics)
- رباتها برای فهم محیط ، برنامهریزی حرکت ، تعامل با انسان به دانش ساختاریافته نیاز دارند.
- مثال:رباتها با استفاده از بازنمایی فضایی (Spatial KR) میتوانند اشیا و مسیرها را تشخیص دهند.
7.6 پزشکی و سلامت هوشمند
- در حوزه پزشکی، KR کمک میکند که بیماریها و علائم مدلسازی شوند ،تشخیص و درمان خودکار انجام شود ، اطلاعات بیمار مدیریت شود.
- مثال:گراف دانش پزشکی برای کشف دارو (Drug Discovery) و تحلیل ارتباط بیماریها.
7.7 وب معنایی (Semantic Web)
- وب معنایی یک اکوسیستم جهانی KR است.
- کاربردها:استانداردسازی دانش (OWL, RDF) ، تبدیل وب به ساختار قابل فهم برای ماشین ،اتصال پایگاههای دانش مختلف.
- مثال:ویکیدیتا (Wikidata) یک پایگاه KR عظیم برای کل وب است.
7.8 سیستمهای امنیتی و تشخیص تهدید
- با بازنمایی روابط میان رویدادها و رفتارها -تشخیص نفوذ ،تحلیل رفتار کاربر ، شناسایی الگوهای حمله-انجام میشود.
7.9 مدیریت دانش سازمانی (Knowledge Management)
- شرکتها از KR برای ذخیره تجربه کارکنان ، مدیریت دانش پروژهها ، ساخت سیستمهای تصمیمیار استفاده میکنند.
7.10 آموزش هوشمند (Intelligent Tutoring Systems)
- KR به سیستم کمک میکند دانش دانشآموز را مدلسازی کند ، نقاط ضعف او را تشخیص دهد ، مسیر آموزشی مناسب را پیشنهاد دهد.
7.11حل مسئله و برنامهریزی (Problem Solving & Planning)
- در برنامهریزی خودکار از KR برای توصیف وضعیتها ، نمایش اهداف ، استنتاج مراحل لازم استفاده میشود.
7.12 هوش مصنوعی تعاملی و گفتوگو محور (Conversational AI)
- چتباتهای پیشرفته برای فهم منطق و روابط مفهومی از KR استفاده میکنند، تا بتوانند پاسخ صحیح ، پاسخ مبتنی بر زمینه ، استدلال منطقی ارائه دهند.
مزایا:
- ساختاردهی دانش
- امکان استنتاج
- کاهش پیچیدگی تصمیمگیری
- تعامل بهتر انسان–ماشین
- کمک به ML
- قابلیت استفاده مجدد
- قابلتفسیر بودن
محدودیتها:
- مشکل مقیاسپذیری
- ابهام و ناسازگاری
- هزینه استخراج دانش
- ضعف در عدم قطعیت
- پیچیدگی استنتاج
- سختی بهروزرسانی پویا
- وابستگی به متخصص
- محدودیت در فهم زمینه/احساس
نتیجهگیری
بازنمایی دانش سنگبنای سیستمهای هوشمند است و نقش آن در درک، استدلال و تصمیمگیری ماشین نقشی غیرقابل جایگزین محسوب میشود. همانگونه که بررسی شد، KR به هوش مصنوعی امکان میدهد دانش پیچیده و غیرساختیافته را به ساختارهایی قابلفهم تبدیل کند و از آن در استنتاج، قابلیت توضیح، تعامل با انسان و اجرای وظایف واقعی استفاده نماید.
روشهای کلاسیک مانند منطق، شبکههای معنایی، قابها و قوانین تولید، پایههای اولیه بازنمایی دانش را شکل دادهاند؛ اما روشهای مدرن از جمله گرافهای دانش، تعبیههای معنایی، بازنمایی عصبی و نوروسیمبولیک، توانستهاند محدودیتهای گذشته را برطرف کرده و قابلیتهای جدیدی به سیستمهای هوش مصنوعی بیفزایند. این رویکردهای جدید امکان کار با دادههای بزرگ، یادگیری خودکار، استنتاج معنایی پیشرفته و ترکیب دانش نمادین با یادگیری عمیق را فراهم کردهاند.
با وجود این پیشرفتها، KR همچنان با چالشهایی مانند مقیاسپذیری، ناسازگاری دانش، هزینه بالای استخراج دانش و ضعف در مدیریت عدمقطعیت روبهروست. آینده بازنمایی دانش بهسمت روشهای ترکیبی، مدلهای علّی، نمایهسازی چندوجهی و ادغام عمیقتر با مدلهای زبانی بزرگ در حال حرکت است.
در مجموع، بازنمایی دانش نهتنها برای سیستمهای خبره و وب معنایی، بلکه برای نسل جدید مدلهای AI نیز حیاتی است. هرچه روشهای KR تکامل یابند، هوش مصنوعی بیشتر قادر خواهد بود جهان را بفهمد، استدلال کند و رفتاری نزدیکتر به انسان از خود نشان دهد.



