

مقدمه
دادههای پرت فقط مقادیر عجیب در میان دادهها نیستند؛ بلکه میتوانند منبع خطا، نشانهای از مشکل پنهان یا حتی سرنخی برای کشف علمی باشند. در سادهترین تعریف، دادهی پرت مشاهدهای است که رفتاری چنان متفاوت دارد که تردید به همگونی فرآیند تولیدش ایجاد میشود. این پدیده در حوزههای گوناگونی مانند آمار، روانشناسی، یادگیری ماشین، مالی و امنیت سایبری رخ میدهد . در صورت نادیده گرفتن، میتواند تحلیلها و تصمیمگیریها را بهشدت منحرف کند.
مقاله ابتدا دادههای پرت را تعریف میکند و دلایل اهمیت توجه به آنها را شرح میدهد. سپس نشان میدهد که چگونه رویکردها به این پدیده از اخترشناسان قرن هجدهم تا متخصصان امروزیِ یادگیری عمیق تکامل یافتهاند. همچنین روشن میکند که چرا مدیریت پرتها امروزه یکی از ارکان اساسی علم داده است. در ادامه، پنج منشأ اصلی پیدایش دادههای پرت — از جمله خطاهای اندازهگیری، مشکلات ورود و پردازش داده، نمونهبرداری نادرست، تقلب یا گزارشدهی اشتباه، و رویدادهای واقعی ولی نادر — را بررسی میکند. هر یک از این منابع را با مثالهای عینی و مطالعات موردی شهودی همراه میسازد.
در ادامه، چارچوبی جامع برای طبقهبندی دادههای پرت ارائه میشود — از تقسیمبندیهای کلاسیک (سراسری، زمینهای و جمعی) و تمایز تکمتغیره در مقابل چندمتغیره تا دیدگاههای مبتنی بر منشأ و دامنه ناهنجاری. تأکید اصلی بر این است که پیش از انتخاب روش تشخیص یا تصمیم درباره نحوه برخورد با پرتها، درک دقیق «نوع» و «منشأ» آنها ضروری است. چنین درکی میتواند کیفیت تحلیلها، مدلها و فرآیندهای تصمیمگیری را بهطور چشمگیری بهبود بخشد.

1. داده پرت چیست؟ (فراتر از یک عدد دورافتاده)
وقتی از دادههای دنیای واقعی حرف میزنیم، تقریباً هیچوقت با یک جدول تمیز و مرتب شبیه مثالهای کتاب درسی مواجه نمیشویم. در میان هر مجموعه دادهی واقعی، همیشه چند مقدار پیدا میشود که «به چشم میآیند»: بیش از حد بزرگ، بیش از حد کوچک، یا به شکلی غیرمنتظره متفاوت از سایر نمونهها. اینها همان چیزی هستند که از آنها با عنوان دادههای پرت (Outliers) یاد میکنیم.
تعریف شهودی Outlier
بهصورت شهودی، دادهی پرت مشاهدهای است که فاصلهاش از سایر دادهها آنقدر زیاد است که ما را به این سؤال میکشاند: آیا از همان مکانیسم معمول تولید شده است؟ شاید این انحراف ناشی از خطا باشد، یا شاید سرنخی از یک رویداد واقعی ولی نادر باشد.
پیامد های وجود Outlier در تحلیل
این تفاوت ظاهراً ساده، پیامدهای عملی بسیار عمیقی دارد. اگر یک دادهی پرت ناشی از خطا باشد — مثلاً ثبت ۲۵۰ درجه بهجای ۲۵ درجه — نگهداشتن آن میتواند تحلیل را بهطور جدی تحریف کند. اما اگر همان مقدار واقعاً نشانهای از یک رویداد واقعی باشد — مثلاً افزایش غیرعادی دما بهدلیل نقص فنی در یک توربین یا راکتور — حذف آن یعنی گم کردن یک هشدار حیاتی.
همین دوگانگی است که کار با دادههای پرت را از یک وظیفهی سادهی «پاکسازی جدول» به یک مسئلهی روششناختی عمیق تبدیل میکند؛ مسئلهای که بهشدت وابسته به زمینهی کاربرد، هدف تحلیل و دانش حوزهای است.
1.1. چرا دادههای پرت مهماند؟
وجود دادههای پرت میتواند در چند سطح اصلی مشکلساز شود:
تحریف آمار توصیفی:
یک یا دو مقدار خیلی بزرگ یا کوچک میتوانند میانگین و انحراف معیار را بهطور جدی جابهجا کنند و تصویری غلط از مرکز و پراکندگی داده ارائه دهند. به همین دلیل، در حضور دادههای پرت معمولاً توصیه میشود به معیارهای مقاوم مثل میانه، دامنهی بین چارکی (IQR) و انحراف مطلق میانه (MAD) تکیه کنیم.
نقض مفروضات استنباط آماری:
بسیاری از روشهای کلاسیک آماری (رگرسیون حداقل مربعات، آزمون t، ANOVA و…) روی فرضهایی مثل نرمال بودن خطاها، همسانی واریانس و نبود چند نقطهی بسیار اثرگذار تکیه دارند. دادههای پرت میتوانند این مفروضات را بر هم بزنند و باعث شوند ضریبها، مقادیر p و بازههای اطمینان ظاهراً دقیق اما در واقع گمراهکننده باشند.
کاهش عملکرد مدلهای یادگیری ماشین:
بسیاری از الگوریتمهای یادگیری ماشین – به خصوص آنهایی که بر فاصله یا واریانس متکی هستند مثل KNN، K-Means، SVM، PCA، –LDA نسبت به دادههای پرت حساساند. چند نقطهی پرت میتوانند مرز تصمیم را منحرف کنند، مراکز خوشهها را جابهجا کنند، یا جهتهای اصلی در PCA را به سمت خود بکشند؛ در نتیجه مدل روی دادهی جدید ضعیف عمل میکند.
پنهان کردن مسائل واقعی یا سیگنالهای مهم:
گاهی دادههای پرت دقیقاً همان چیزی هستند که باید رویشان تمرکز کنیم: نشانهی تقلب، حملهی سایبری، خرابی یک دستگاه، بیماری در دادههای پزشکی، یا تغییر حالت در یک سیستم پویا. اگر بیدقت با آنها برخورد کنیم، ممکن است مهمترین اطلاعات را از دست بدهیم.
بنابراین، کار با دادههای پرت فقط یک پیشپردازش ساده نیست؛ بلکه جزئی جداییناپذیر از علم دادهی مسئولانه و قابل اتکا است.
برای مطالعهی عمیقتر درباره تأثیر دادههای پرت بر آمار توصیفی، مفروضات آماری و مدلهای یادگیری ماشین، مقاله «اهمیت و تأثیرات دادههای پرت» را بخوانید.
2.یک سفر تاریخی از اخترشناسان تا یادگیری ماشین
برخورد با دادههای عجیب بههیچوجه محصول عصر یادگیری ماشین نیست. از همان زمانی که انسان شروع کرد به اندازهگیری و ثبت، با مسئلهی «عددهای مشکوک» روبهرو شد.
2.1. از اخترشناسان تا گاوس
در قرنهای هفدهم و هجدهم، اخترشناسان در تلاش بودند موقعیت ستارهها و سیارات را با دقت بالا اندازهگیری کنند. آنها مجموعهای از قرائتها داشتند که تقریباً نزدیک هم بودند، و هر از گاهی یک مقدار که کاملاً از بقیه جدا بود. آن زمان هنوز نظریهی رسمی دربارهی احتمال و توزیع خطا وجود نداشت، اما دانشمندان بهطور تجربی بعضی اندازهگیریها را کنار میگذاشتند چون «غیرقابلاعتماد» به نظر میرسیدند.
با کارهای گاوس و لژاندر در اوایل قرن نوزدهم و معرفی روش حداقل مربعات و توزیع نرمال خطاها، نخستین چارچوب رسمی برای فکر کردن به دادههای پرت شکل گرفت. اگر فرض کنیم خطاها نرمالاند، میتوانیم بپرسیم: «احتمال دیدن خطایی به این بزرگی چقدر است؟»
اگر این احتمال خیلی کم باشد، شاید آن نقطه را بهعنوان مشاهدهی مشکوک یا پرت کنار بگذاریم.
2.2. آمار مقاوم و EDA
تا نیمهی قرن بیستم، کمکم روشن شد که روشهای کلاسیک مثل میانگین و حداقل مربعات، بیش از حد به دادههای پرت حساساند.همین جا بود که ایدهی آمار مقاوم مطرح شد.
جان توکی، با مطرح کردن تحلیل اکتشافی دادهها (EDA)، تأکید کرد که قبل از هر مدلسازی پیچیده، باید داده را دید، نمودار کشید، و نقاط مشکوک را تشخیص داد. او نمودار جعبهای و معیارهایی مثل IQR را برای شناسایی دادههای پرت معرفی کرد.
در همین دوره، پژوهشگرانی مثل هوبر و همپل بهصورت نظری نشان دادند که میتوان تخمینگرهایی طراحی کرد که حتی اگر بخشی از دادهها آلوده یا پرت باشد، هنوز رفتار خوبی داشته باشند. مفاهیمی مانند نقطهی شکست (حداکثر درصد آلودگی که یک روش میتواند تحمل کند) و تابع تأثیر (اندازهگیری تأثیر یک نقطهی منفرد بر برآورد) در همین جریان شکل گرفت. روشهایی مانند LMS، LTS، MCD و MVE نیز برای برازش مقاوم رگرسیون و کوواریانس توسعه یافتند.
2.3. رویکرد علوم کامپیوتر و الگوریتم های مدرن
از اواخر قرن بیستم، با رشد پایگاههای دادهی بزرگ و چندبعدی، رویکرد تشخیص ناهنجاری در علوم کامپیوتر شکل گرفت. در این رویکرد، دادهی پرت دیگر فقط «خطای آزمایش» نبود؛ بلکه میتوانست نشانهی تقلب، حملهی شبکه، رفتار غیرعادی کاربر یا اشکال در سیستم باشد.
الگوریتمهایی مانند تشخیص پرت مبتنی بر نزدیکترین همسایه (KNN-based)، عامل پرت محلی (LOF)، روشهای مبتنی بر خوشهبندی، One-Class SVM، روشهای تجمیعی مثل Isolation Forest و در سالهای اخیر روشهای مبتنی بر یادگیری عمیق (Autoencoderها، VAE، GAN، LSTM برای سریهای زمانی) بهطور خاص برای شناسایی الگوهای پیچیدهی ناهنجاری طراحی شدند.
این مسیر تاریخی نشان میدهد که مسئله دادههای پرت از یک دغدغه تخصصی در نجوم، به یک حوزه بینرشتهای تبدیل شده است که آمار، علوم کامپیوتر و دانش تخصصی حوزهای در آن همافزایی میکنند.
3. منشأ داده های پرت :چرا Outlier ایجاد میشود؟

برای اینکه بدانیم با یک دادهی پرت چه کار کنیم، اول باید بفهمیم چرا به وجود آمده است. منبع یا منشأ دادهی پرت تا حد زیادی تعیینکنندهی نوع واکنش ماست.
3.1. خطاهای اندازهگیری و ابزار
یکی از شایعترین منابع دادههای پرت، خطا در ابزار اندازهگیری است:
- نویز یا خرابی حسگرها: سنسور دما ناگهان صفر درجه گزارش میکند در حالی که محیط گرم است؛ یا حسگر ارتعاش بهخاطر نویز الکترومغناطیس مقادیر غیرواقعی ثبت میکند.
- کالیبراسیون ناقص: اگر یک ترازو درست تنظیم نشده باشد، همهی اندازهگیریها چند گرم یا چند کیلو خطا دارند و بخشی از دادهها نسبت به سایر منابع یا دستگاههای دیگر «پرت» به نظر میرسند.
- عدم رعایت پروتکل آزمایش: در آزمایشهای شیمی، پزشکی یا مهندسی، تفاوت در دما، زمان، غلظت مواد و آلودگی نمونه میتواند از یک سری آزمایش تا سری دیگر نتایج غیرعادی ایجاد کند.
در این موارد، اگر مطمئن باشیم خطا ابزاری است، معمولاً استراتژی درست اصلاح یا حذف آن داده است.
3.2. خطا در ورود، انتقال و پردازش داده
حتی اگر اندازهگیری صحیح باشد، در مراحل بعدی هم امکان تولید دادهی پرت وجود دارد:
- اشتباه تایپی (۲۵۰ به جای ۲۵، ۱.۲ به جای ۱۲)، جابهجایی اعشار، واحد اشتباه (پوند به جای کیلوگرم)، کدگذاری غلط مقادیر دستهای؛
- خطا در انتقال داده از فرم کاغذی به سیستم، یا در تبدیل بین فرمتهای مختلف؛
- اشتباه در ادغام چند منبع داده ( Join اشتباه، تکراری شدن رکوردها، قاطی شدن رکورد دو نفر با هم).
در یک پروژه فروش چند شعبه، اگر واحد پول شعبهای یورو و شعبهی دیگر دلار باشد ولی بدون تبدیل ادغام شوند، مقادیر یک شعبه به صورت «پرت» در دیتاست نهایی ظاهر میشوند، در حالی که در واقع خطای پردازش داریم.
3.3. خطاهای نمونهبرداری
گاهی دادهی جمعآوریشده بهدرستی ثبت شده، اما نمونه اصلاً نمایندهی جمعیت هدف نیست:
- وارد شدن اعضای یک جمعیت دیگر در نمونه؛
- استفاده از نمونهگیری در دسترس و جانبدار؛
- آلودگی فیزیکی نمونههای بیولوژیک یا شیمیایی.
در این حالت، نقطهی پرت نسبت به جمعیت مورد نظر ما پرت است، نه نسبت به جمعیت واقعی خودش.
3.4. گزارش نادرست و رفتار مخرب
در برخی حوزهها دادههای پرت عمدی هستند:
- پاسخهای دروغ یا اغراقآمیز در پرسشنامههای حساس (درآمد، مصرف، عقاید).
- تراکنشهای غیرمعمول در کارتهای بانکی، ادعاهای عجیب در بیمه، حملات باتنت و تولید ترافیک غیرعادی در شبکه.
- دادههای دستکاریشده برای گمراه کردن سامانههای تشخیص (نمونههای خصمانه در یادگیری ماشین).
اینجا Outlier نه خطاست، نه چیزی برای حذف؛ بلکه سیگنال اصلی است که باید روی آن متمرکز شویم.
3.5. خرابی داده
خرابی فایل، از کار افتادن رسانهی ذخیرهسازی، نویز روی خطوط ارتباطی و… هم میتواند دادههای بیمعنی تولید کند. معمولاً این نوع دادهها با بررسیهای فنی و کنترلهای صحت (چکسام، لاگها) قابل تشخیصاند.
3.6. رویدادهای نادر اما واقعی
شاید مهمترین و حساسترین دسته، دادههای پرت واقعی و معنادار باشند:
- در توزیع درآمد، چند فرد بسیار ثروتمند.
- در بازار سهام، سقوطها و جهشهای بزرگ.
- در زلزله، چند رخداد با بزرگی بسیار بالا.
- در پزشکی، علائم نادری که بیماری جدید یا وضعیت بحرانی را نشان میدهند.
- در علوم، اندازهگیریهایی که ممکن است حاکی از کشف یک ذرهی جدید یا یک پدیدهی ناشناخته باشند.
در سیستمهای پویا، این نقاط میتوانند نشانهی تغییر فاز یا گذار ناگهانی از یک حالت به حالت دیگر باشند. حذف آنها یعنی کور کردن خود نسبت به اتفاقات مهم.
به همین دلیل، درک منشأ دادههای پرت یک کار صرفاً تکنیکی نیست. بیشتر شبیه کارآگاهبازی است و نیاز به ترکیب نمودارکشی، تشخیصهای آماری، بررسی متادیتا و مشورت با متخصصان حوزه دارد.
4. طبقهبندی دادههای پرت: زبان مشترک تحلیل Outlier ها
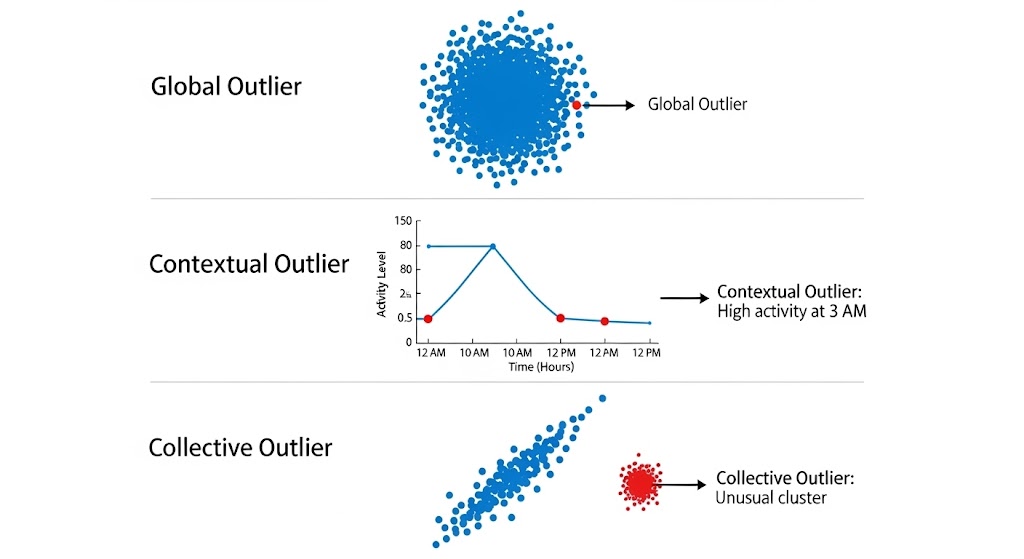
از آنجا که دادههای پرت از نظر شکل، منشأ و رفتار بسیار متنوعاند، لازم است یک زبان مشترک برای دستهبندی آنها داشته باشیم. این طبقهبندی مستقیماً روی انتخاب روش تشخیص و نحوهی برخورد اثر میگذارد.
- سراسری (Point)، زمینهای (Contextual) و جمعی (Collective)
- تکمتغیره در برابر چندمتغیره
حال به بررسی هر یک می پردازیم.
4.1. سراسری، زمینهای و جمعی
یکی از رایجترین تقسیمبندیها سه دستهی زیر است:
4.1.1. دادههای پرت سراسری (Global / Point Outliers)
اینها نقاطی هستند که در مقیاس کل دیتاست، بهوضوح از بقیه جدا هستند.
مثلاً:
- سن ۱۵۰ سال در دیتاست جمعیت عمومی.
- تراکنش ۱۰ میلیون دلاری در میان تراکنشهای ۱۰۰ تا ۱۰۰۰ دلاری.
این نوع پرتها با روشهایی مثل Z-Score، IQR، آزمون گرابز، روشهای مبتنی بر توزیع نرمال، و الگوریتمهایی مثل Isolation Forest نسبتاً راحتتر شناسایی میشوند. اما اگر چند پرت شبیه هم وجود داشته باشد، پدیدههایی مثل ماسکینگ و سوامپینگ میتوانند کار را سخت کنند. بعضی پرتها یکدیگر را پنهان میکنند یا باعث میشوند نقاط نرمال ظاهراً پرت به نظر برسند.
4.1.2. دادههای پرت زمینهای (Contextual / Conditional Outliers)
در اینجا، مقدار بهتنهایی لزوماً افراطی نیست، بلکه در یک زمینهی خاص غیرعادی میشود.
مثالها:
- دمای ۲۵ درجه در تابستان تهران عادی است، اما در زمستان استکهلم غیرعادی است.
- خرید ۵۰۰ دلار برای یک خانوادهی مرفه طبیعی است، اما برای یک دانشجو میتواند مشکوک باشد.
- تعداد بازدید زیاد سایت در ساعت ۳ صبح ممکن است ناهنجار باشد، مگر زمانی که رویداد جهانی خاصی در حال پخش باشد.
تشخیص این نوع Outlierها نیازمند مدلسازی رفتار «عادی» مشروط بر زمینه است؛ یعنی باید بدانیم «در این فصل، برای این نوع کاربر، در این منطقه، رفتار معمول چیست؟».
4.1.3. دادههای پرت جمعی (Collective Outliers)
گاهی هیچ نقطهای بهتنهایی خیلی غیرعادی نیست، اما مجموعهای از نقاط با هم رفتاری غیرطبیعی دارند.
مثلاً:
- چند ده تراکنش کوچک در نقاط جغرافیایی مختلف طی چند دقیقه.
- توالی خاصی از ضربان قلب در ECG که بهتنهایی طبیعی به نظر میرسد، اما بهصورت مجموعهای الگوی ریتم غیرعادی را نشان میدهد.
- چند سنسور که همزمان کمی بالا میروند و این الگوی هماهنگ نشانهی یک مشکل سیستمی است.
تشخیص این نوع ناهنجاری معمولاً به روشهای تحلیلی دنبالهای (سری زمانی، RNN/LSTM)، گراف، یا تحلیل ساختار خوشهها و زیرالگوها نیاز دارد.
4.2. تکمتغیره و چندمتغیره
بُعد دیگر طبقهبندی، این است که ناهنجاری در چند ویژگی ظاهر میشود؟
- پرت تکمتغیره: وقتی یک ویژگی بهتنهایی مقدار عجیبی دارد (مثلاً قد ۳ متر). این نوع با نمودار جعبهای، هیستوگرام، Z-Score، IQR و آزمونهای کلاسیک بهخوبی کشف میشود.
- پرت چندمتغیره: وقتی هر ویژگی بهتنهایی ممکن است در محدودهی عادی باشد، اما ترکیب آنها غیرمنطقی است. مثل فردی با قد ۱۶۰ و وزن ۱۲۰ کیلو، یا تراکنشی با مبلغ متوسط و مکان آشنا، اما در زمانی غیرمعمول و با الگویی که هرگز در تاریخ آن حساب دیده نمیشده است.
برای این نوعOutlier ها به روشهایی مثل فاصلهی ماهالانوبیس، کوواریانس مقاوم، PCA، LOF، One-Class SVM، Isolation Forest و سایر الگوریتمهای چندبعدی نیاز داریم.
پس از شناخت انواع Outlier، قدم بعدی بررسی این است که این Outlierها چه تأثیری بر تحلیل داده و مدلسازی دارند. ادامهی این بحث در مقالهی دوم این مجموعه آمده است.
5. تفاوت: نویز (Noise) با داده پرت (Outlier)
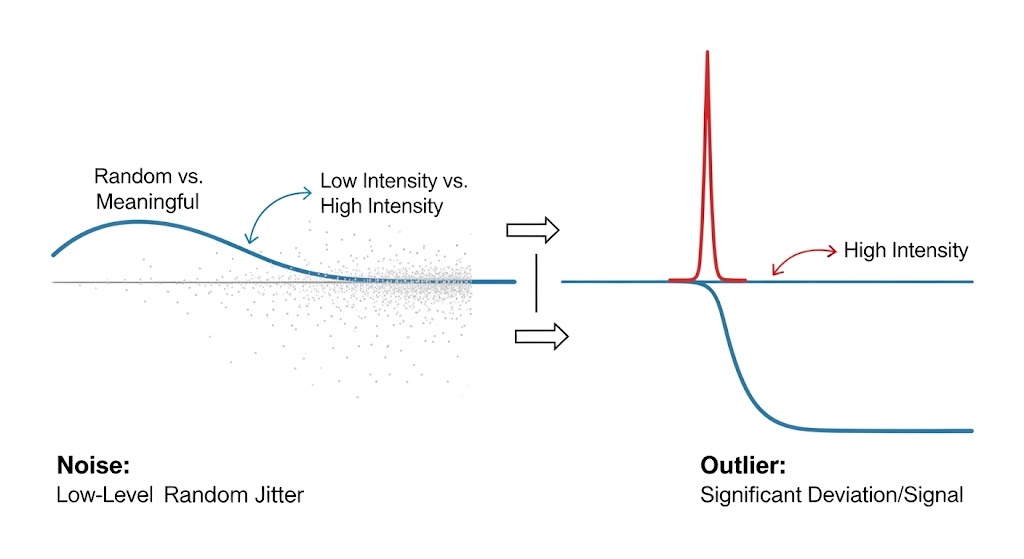
در دنیای دادهها، هر چیزی که با الگوی معمول نمیخواند، لزوماً «داده پرت» نیست. بسیاری از تحلیلگران تازهکار، هر نوسان یا بینظمی را Outlier مینامند، اما از نظر فنی، تمایز مهمی بین نویز و پرت وجود دارد. درک این تفاوت تعیین میکند که آیا باید داده را «صاف» (Smooth) کنید یا آن را «بررسی» (Investigate) نمایید.
5.1. نویز (Noise) چیست؟
به خطای تصادفی یا واریانس در متغیر اندازهگیریشده اشاره دارد. نویز معمولاً فاقد الگوی مشخص است، معنای خاصی ندارد و صرفاً مانعی برای دیدن الگوی اصلی دادههاست.
- ماهیت: خطای تصادفی سطح پایین.
- منشأ: محدودیتهای فیزیکی ابزار اندازهگیری، تداخلات محیطی، یا نوسانات جزئی و طبیعی.
- ارزش تحلیلی: تقریباً صفر. نویز هیچ اطلاعات مفیدی درباره پدیده مورد مطالعه به ما نمیدهد و “سیگنال” را مخفی میکند.
- مثال: صدای “خشخش” در پسزمینه یک فایل صوتی ضبط شده، یا لرزش دست هنگام اندازهگیری وزن یک جسم.
نکته کلیدی: نویز یک “شیء” (Object) نیست؛ بلکه ویژگیای است که روی مقادیر داده سوار میشود. شما نمیتوانید بگویید “این سطر نویز است” (مگر اینکه کل سطر زباله باشد)، بلکه میگویید “این سطر دارای نویز است”.
5.2. (Outlier) چیست؟
داده پرت مشاهدهای است که بهطور معناداری با سایر دادهها متفاوت است. این تفاوت آنقدر زیاد است که شک میکنیم مکانیسم تولید آن با بقیه دادهها یکی باشد.
- ماهیت: انحراف شدید و معنادار.
- منشأ: میتواند ناشی از یک خطای بزرگ (مثل خرابی سنسور) باشد، یا ناشی از یک رویداد واقعی و کمیاب (مثل یک تراکنش بانکی میلیاردی).
- ارزش تحلیلی: بسیار بالا. (اگر نویز نباشد) Outlierها اغلب حاوی مهمترین اطلاعات دیتاست هستند (کشف تقلب، کشف بیماری، کشف علمی).
- مثال: شنیدن صدای “جیغ” در میان صدای خشخش رادیو. جیغ، خشخش نیست؛ یک رویداد متمایز است.
برای مشاهده تفاوت اثر نویز و دادهی پرت بر تحلیل و مدلسازی، مقالهی «تأثیر دادههای پرت» را ببینید.
جدول مقایسه: نویز در برابر داده پرت
| ویژگی | داده پرت (Outlier) | نویز (Noise) |
|---|---|---|
| تعریف | انحراف چشمگیر از رفتار نرمال | خطای تصادفی یا واریانس ناخواسته |
| شدت انحراف | معمولاً زیاد و شدید | معمولاً کم یا متوسط |
| منشأ | رویداد خاص، خطای فاحش، تغییر فرآیند | محدودیت ابزار، تداخل محیطی |
| اطلاعات | ممکن است “سیگنال اصلی” باشد | مانع اطلاعات است (Garbage) |
| روش برخورد | تشخیص (Detection)، تحلیل، تصمیمگیری | کاهش نویز، هموارسازی (Smoothing)، فیلتر کردن |
| مثال بصری | نقطهای که کاملاً دور از خط رگرسیون افتاده است | نقاطی که کمی بالا و پایین خط رگرسیون میلرزند |
یک مثال شهودی (آنالوژی رادیو)
فرض کنید در حال گوش دادن به یک ایستگاه رادیویی هستید.
- نویز: صدای “فِشفِش” دائمی که در پسزمینه میشنوید. این صدا هیچ معنایی ندارد و شما سعی میکنید با آنتندهی بهتر آن را حذف (Smooth) کنید تا صدای گوینده شفاف شود.
- داده پرت: ناگهان صدای یک “آژیر خطر” بلند پخش میشود که صحبت گوینده را قطع میکند. این صدا نویز نیست؛ یک اتفاق متمایز است. شما نباید آن را فیلتر کنید، بلکه باید توجه کنید که چرا آژیر زده شد.
جمعبندی
آنچه در این بخش انجام دادیم، ادغام چهار محور اصلی بود: تعریف و انگیزهی دادههای پرت، تاریخچهی فشردهی مواجهه با آن، منشأها و ریشههای تولید دادهی پرت و در نهایت چارچوبی برای طبقهبندی انواع آن بود.
پیام کلیدی این است که:
- دادهی پرت نه یک «نقص حاشیهای» در داده، بلکه عنصری مرکزی و تعیینکننده در علم داده عملی محسوب میشود.
- بدون درک منشأ، هر تصمیمی برای حذف، اصلاح یا استفاده از دادهی پرت میتواند خطرناک و گمراهکننده باشد؛
- طبقهبندی روشن انواع Outlier (سراسری، زمینهای، جمعی، تکمتغیره، چندمتغیره، ناشی از خطا، ناشی از رویداد واقعی، عمدی) شرط لازم برای انتخاب روش تشخیص و استراتژی مدیریت آنهاست؛
- ترکیب نگاه آماری، الگوریتمی و دانش حوزهای همان چیزی است که یک کار با دادهی حرفهای را از یک پاکسازی سطحی متمایز میکند.
در گامهای بعدی، میتوان بر همین مبنا به سراغ روشهای تشخیص، الگوریتمها، راهکارهای عملی مدیریت و پیادهسازی در پایتون رفت؛ اما تا وقتی این «زیربنای مفهومی» روشن نشده باشد، هیچ الگوریتم پیچیدهای نمیتواند تضمین کند که برخورد ما با دادههای پرت واقعاً درست و معنادار است.



