

1.مقدمه
در دنیای امروز، مدلهای یادگیری ماشین در قلب بسیاری از فناوریهای هوشمند قرار دارند — از توصیهگرهای فیلم گرفته تا سیستمهای تشخیص تصویر و گفتار.اما هر مدل موفق، قبل از رسیدن به عملکرد مطلوب، از مراحلی مشخص عبور میکند.
در این مقاله با «چرخه حیات یادگیری ماشین» آشنا میشویم، تفاوت طبقهبندی و رگرسیون را میبینیم، و در ادامه نگاهی به مهمترین کتابخانههای یادگیری عمیق در پایتون خواهیم انداخت.
2.چرخه حیات یادگیری ماشین
چرخه حیات یک مدل یادگیری ماشین به طور معمول به هفت گام تقسیم میشود:
- جمعآوری دادهها
- آمادهسازی دادهها
- انتخاب مدل
- آموزش مدل
- ارزیابی مدل
- تنظیم پارامترها
- استقرار مدل
.
3.جمعآوری دادهها:
دادهها اساس هر وظیفه یادگیری ماشین را تشکیل میدهند. این مرحله ممکن است شامل اجرای آزمایشها، ورود دستی مقادیر، منبعیابی دادههای عمومی، یا مجموعهای از روشهای دیگر (مانندتولید دادههای مصنوعی) باشد.
4.آمادهسازی دادهها:
دادههای خام اغلب در قالبی مناسب برای الگوریتمهای یادگیری ماشین نیستند. همچنین ممکن است دارای مقادیر تکراری یا گمشده باشند یا حاوی دادههای پرت (outliers) باشند که دادهها را متمایل میکنند. این نوع ناسازگاریها ممکن است نیاز به تنظیم دستی داشته باشند. شبکههای عصبی با دادههای نرمالسازیشده که مقادیر آنها برای جایگیری در یک دامنه استاندارد مقیاسبندی شدهاند، بهترین عملکرد را دارند. بخش کلیدی دیگر آمادهسازی دادهها، جدا کردن آنها به مجموعههای متمایز است: آموزش ، اعتبارسنجی و آزمون. دادههای آموزشی برای آموزش مدل استفاده میشوند (گام ۴). دادههای اعتبارسنجی و آزمون کنار گذاشته شده و برای ارزیابی عملکرد مدل رزرو میشوند (گام ۵).
5.انتخاب مدل:
معماری شبکه عصبی را طراحی کنید. مدلهای مختلف برای انواع خاصی از دادهها و خروجیها مناسبتر هستند.
6.آموزش مدل:
بخش آموزشی دادهها را از طریق مدل تغذیه کنید و به مدل اجازه دهید تا وزنهای شبکه عصبی را بر اساس خطاهای آن تنظیم کند. این فرآیند به عنوان بهینهسازی شناخته میشود: مدل وزنها را طوری تنظیم میکند که کمترین تعداد خطا را در پی داشته باشد.
7.ارزیابی مدل:
دادههای آزمونی را که در گام ۲ کنار گذاشته شد، به یاد بیاورید؟ از آنجا که آن دادهها در آموزش استفاده نشدهاند، ابزاری برای ارزیابی این است که مدل چقدر خوب بر روی دادههای جدید و دیدهنشده عمل میکند.
8.تنظیم پارامترها:
فرآیند آموزش تحت تأثیر مجموعهای از پارامترها (که اغلب hyperparameters نامیده میشوند) مانند نرخ یادگیری است، که تعیین میکند مدل چقدر باید وزنهای خود را بر اساس خطاهای پیشبینی تنظیم کند. با تنظیم دقیق این پارامترها و بازبینی مجدد گامهای ۴ (آموزش)، ۳ (انتخاب مدل)، و حتی ۲ (آمادهسازی دادهها)، میتوانید اغلب عملکرد مدل را بهبود بخشید.
9.استقرار مدل:
هنگامی که مدل آموزش داده شد و عملکرد آن به طور رضایتبخش ارزیابی شد، زمان آن است که مدل را در دنیای واقعی با دادههای جدید به کار ببرید!
این گامها سنگ بنای یادگیری تحت نظارت هستند. با این حال، حتی اگر ۷ یک عدد واقعاً عالی باشد، ما فکر میکنیم یک گام حیاتی دیگر را از دست دادهایم. ما آن را گام صفر مینامیم:
10.چرا شناسایی مسئله اولین گام حیاتی است؟
گام صفر: شناسایی مسئله: این گام اولیه، مسئلهای را که نیاز به حل دارد، تعریف میکند. هدف چیست؟ با مدل یادگیری ماشین خود به دنبال انجام یا پیشبینی چه چیزی هستید؟
این گام صفر به تمام گامهای دیگر در این فرآیند جهت میدهد. به هر حال، چگونه قرار است دادههای خود را جمعآوری کنید و مدلی را انتخاب نمایید، بدون اینکه حتی بدانید دقیقاً به دنبال انجام چه کاری هستید؟ آیا در حال پیشبینی یک عدد هستید؟ یک دسته؟ یک توالی؟ آیا یک انتخاب دودویی است یا گزینههای زیادی وجود دارد؟ این نوع سؤالات اغلب به انتخاب بین دو نوع وظیفه که اکثریت کاربردهای یادگیری ماشین در آنها قرار میگیرند، خلاصه میشود: طبقهبندی و رگرسیون.
11.طبقهبندی و رگرسیون (Classification and Regression)
طبقهبندی نوعی از مسئله یادگیری ماشین است که شامل پیشبینی یک برچسب (که دسته یا کلاس نیز نامیده میشود) برای یک قطعه داده است. اگر این آشنا به نظر میرسد، به این دلیل است که همینطور است: پرسپترون ساده در مثال برای طبقهبندی نقاط به عنوان بالای خط یا پایین خط آموزش داده شد. به عنوان مثال دیگر، یک طبقهبندیکننده تصویر ممکن است سعی کند حدس بزند که آیا یک عکس از یک گربه است یا یک سگ و برچسب متناظر را اختصاص دهد.

شکل ۱: برچسبگذاری تصاویر به عنوان گربه یا سگ.
طبقهبندی با جادو اتفاق نمیافتد. مدل باید ابتدا با برچسبهای صحیح، مثالهای زیادی از سگها و گربهها را ببیند تا بتواند وزنهای تمام اتصالات را به درستی پیکربندی کند. این همان بخش «آموزش» (training) یادگیری تحت نظارت است.
12.مجموعه داده MNIST و «Hello, world!» یادگیری ماشین
نمایش کلاسیک «Hello, world! » یادگیری ماشین و یادگیری تحت نظارت، یک مسئله طبقهبندی مجموعه داده MNIST است.
MNIST که مخفف مؤسسه ملی استانداردها و فناوری اصلاحشده است، یک مجموعه داده است که توسط یان لِکون ، کورینا کورتس ، و کریستوفر جی. سی. بورگس جمعآوری و پردازش شده است. این مجموعه داده که به طور گسترده برای آموزش و آزمون در حوزه یادگیری ماشین استفاده میشود، شامل 70,000 رقم دستنویس از 0 تا 9است؛ هر کدام یک تصویر 28 × 28 پیکسلی با مقیاس خاکستری است . هر تصویر با رقم متناظر خود برچسبگذاری شده است.

شکل2 :مجموعهای از ارقام دستنویس 0 تا 9 از مجموعه داده MNIST با اجازه از Suvanjanprasai
13.کد برای مجموعه داده MNIST
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# بارگذاری داده
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# نرمالسازی دادهها
X_train = X_train.reshape(-1, 28*28) / 255.0
X_test = X_test.reshape(-1, 28*28) / 255.0
# برچسبها را به One-Hot تبدیل کن
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print("شکل دادههای آموزش:", X_train.shape)
MNIST یک مثال کانونی از یک مجموعه داده آموزشی برای طبقهبندی تصویر است: مدل یک تعداد گسسته از دستهبندیها (دقیقاً 10 مورد—نه بیشتر، نه کمتر) برای انتخاب دارد. پس از آموزش مدل بر روی 70,000 تصویر برچسبگذاریشده، هدف این است که تصاویر جدید را طبقهبندی کند و برچسب مناسب (رقمی از 0 تا 9) را به آنها اختصاص دهد.
14.تعریف رگرسیون و تفاوت آن با طبقه بندی
رگرسیون، در مقابل، یک وظیفه یادگیری ماشین است که پیشبینی آن یک مقدار پیوسته، معمولاً یک عدد اعشاری ، است. یک مسئله رگرسیون میتواند شامل خروجیهای متعدد باشد، اما شروع با تنها یک خروجی اغلب سادهتر است. به عنوان مثال، یک مدل یادگیری ماشین را در نظر بگیرید که مصرف روزانه برق یک خانه را بر اساس عوامل ورودی مانند تعداد ساکنان، اندازه خانه، و دمای بیرون پیشبینی میکند.

شکل 3: عواملی مانند آب و هوا و اندازه و تعداد ساکنان یک خانه میتوانند بر مصرف روزانه برق آن تأثیر بگذارند.
به جای انتخاب از یک مجموعه گسسته از گزینههای خروجی، اکنون هدف شبکه عصبی حدس زدن یک عدد است—هر عددی. آیا آن خانه در آن روز 30.5 کیلووات ساعت برق مصرف خواهد کرد؟ یا 48.7 کیلووات ساعت؟ یا 100.2 کیلووات ساعت؟ پیشبینی خروجی میتواند هر مقداری از یک دامنه پیوسته باشد.
دانستن اینکه چه مسئلهای را میخواهید حل کنید (گام صفر) همچنین تأثیر قابل توجهی بر طراحی شبکه عصبی دارد—به ویژه بر لایههای ورودی و خروجی آن.
این را با یک مثال کلاسیک دیگر «Hello, world! » از حوزه علم داده و یادگیری ماشین نشان خواهیم داد: مجموعه داده .Iris این مجموعه داده، که میتوان آن را در مخزن یادگیری ماشین دانشگاه کالیفرنیا، ایروین یافت، از کار اِدگار اندرسون ، گیاهشناس آمریکایی، نشأت گرفته است.
برای اطلاعات بیشتر در مورد خاستگاه این مجموعه داده مشهور، به مقاله مجموعه داده Iris :در جستجوی منبع Virginica از آنتونی آنوین و کیم کلاینمن مراجعه کنید. پس از تجزیه و تحلیل دقیق دادهها، اندرسون جدولی را برای طبقهبندی گلهای زنبق (Iris) به سه گونه متمایز ساخت Iris setosa:، Iris versicolor و Iris virginica برای مشاهده به شکل مراجعه کنید).
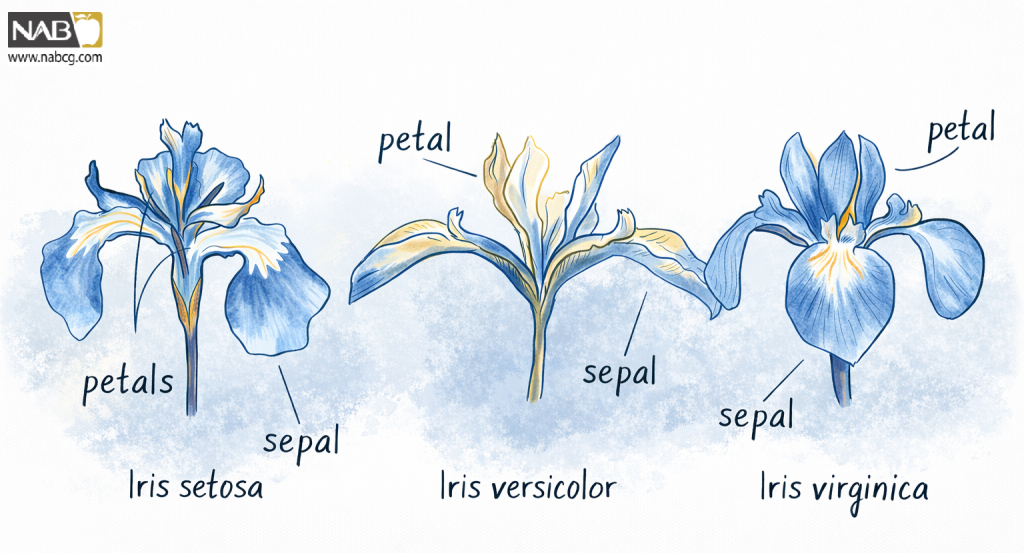
شکل 4: سه گونه متمایز از گلهای زنبق (iris)
15.کد برای مجموعه داده Iris:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = MLPClassifier(hidden_layer_data-sizes=(5,), max_iter=1000)
clf.fit(X_train, y_train)
print("دقت مدل:", accuracy_score(y_test, clf.predict(X_test)))
اندرسون چهار صفت عددی را برای هر گل گنجانده است: طول کاسبرگ، عرض کاسبرگ، طول گلبرگ و عرض گلبرگ، که همگی بر حسب سانتیمتر اندازهگیری شدهاند. (او همچنین اطلاعات رنگ را ثبت کرده بود، اما به نظر میرسد آن دادهها از دست رفتهاند.) سپس هر رکورد با دستهبندی زنبق مناسب جفت میشود:
| طول کاسبرگ (cm) | عرض کاسبرگ (cm) | طول گلبرگ (cm) | عرض گلبرگ (cm) | طبقهبندی (Classification) |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | Iris versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | Iris versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | Iris virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | Iris virginica |
در این مجموعه داده، چهار ستون اول (طول کاسبرگ، عرض کاسبرگ، طول گلبرگ، عرض گلبرگ) به عنوان ورودیهای شبکه عصبی عمل میکنند. خروجی، دستهبندی (Classification) ارائه شده در ستون پنجم است. یک معماری ممکن را برای یک شبکه عصبی که میتواند با این دادهها آموزش ببیند، به تصویر میکشد.
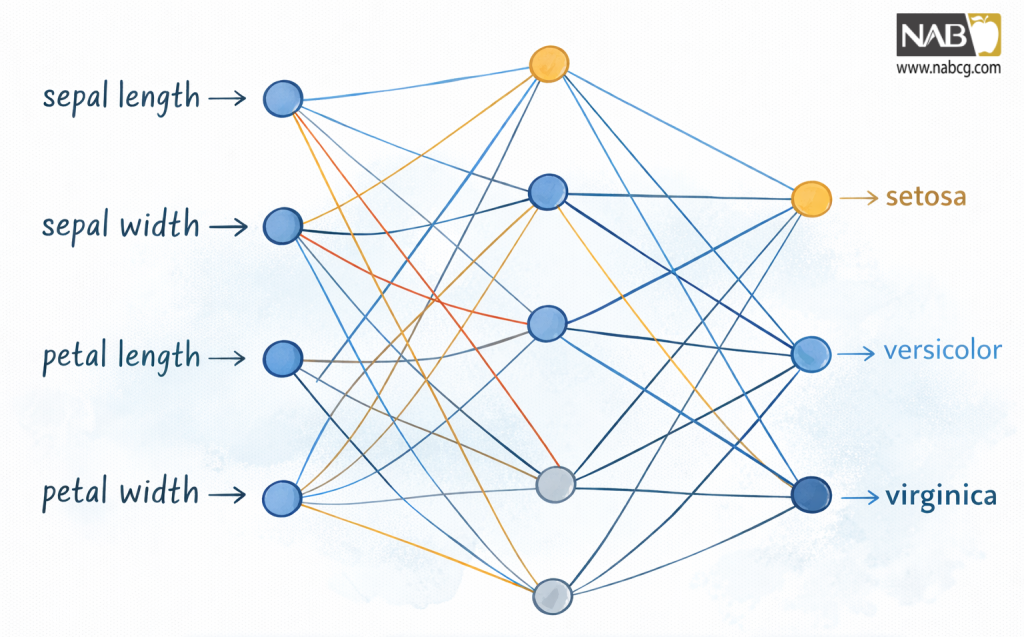
شکل 5: یک معماری شبکه ممکن برای طبقهبندی زنبق (Iris)
توضیحات
سمت چپ، چهار ورودی شبکه قرار دارند که متناظر با چهار ستون اول جدول داده هستند. سمت راست، سه خروجی ممکن قرار دارند که هر کدام نشاندهنده یکی از برچسبهای گونههای زنبق است. در این میان، لایه پنهان قرار دارد، که پیچیدگی را به معماری شبکه اضافه میکند، که برای مدیریت دادههای غیرخطی قابل تفکیک ضروری است. هر گره در لایه پنهان به هر گرهای که قبل و بعد از آن میآید، متصل است. این معمولاً یک لایه کاملاً متصل (fully connected) یا متراکم (dense) نامیده میشود.
شما ممکن است متوجه عدم وجود گرههای بایاس صریح در این نمودار شوید. در حالی که بایاسها نقشی مهم در خروجی هر نورون ایفا میکنند، اغلب از نمایشهای بصری حذف میشوند تا نمودارها تمیز و متمرکز بر جریان اصلی داده باقی بمانند. .
هدف شبکه عصبی این است که «فعال» کند خروجی صحیح را برای دادههای ورودی، درست همانطور که پرسپترون خروجی +1 یا -1 را برای طبقهبندی دودویی واحد خود میداد. در این مورد، مقادیر خروجی مانند سیگنالهایی هستند که به شبکه کمک میکنند تا تصمیم بگیرد کدام برچسب گونه زنبق را اختصاص دهد. بالاترین مقدار محاسبهشده فعال میشود تا بهترین حدس شبکه در مورد طبقهبندی را نشان دهد.
نکته کلیدی در اینجا این است که یک شبکه طبقهبندی باید به اندازه تعداد مقادیر برای هر قلم داده، ورودی داشته باشد، و به اندازه تعداد دستهها، خروجی داشته باشد.
در مورد لایه پنهان، طراحی آن بسیار کمتر مشخص است. لایه پنهان در شکل دارای پنج گره است، اما این عدد کاملاً دلخواه است. معماریهای شبکه عصبی میتوانند به شدت متفاوت باشند، و تعداد گرههای پنهان اغلب از طریق آزمون و خطا یا سایر روشهای حدس مبتنی بر دانش (که روشهای اکتشافی heuristics/ نامیده میشوند) تعیین میشود.
16.مقایسه ساختار شبکه عصبی در دو مسئله
در مورد ورودیها و خروجیها در یک سناریوی رگرسیون، مانند مثال مصرف برق خانگی که قبلاً به آن اشاره کردیم، چطور؟
یک مجموعه داده برای این سناریو خواهیم ساخت، با مقادیری که نشاندهنده تعداد ساکنان و اندازه خانه، دمای روز، و مصرف برق متناظر هستند. این بسیار شبیه به یک مجموعه داده مصنوعی است، با توجه به اینکه دادههای جمعآوریشده برای یک سناریوی دنیای واقعی نیست—اما در حالی که دادههای مصنوعی به طور خودکار تولید میشوند، در اینجا مقادیر را به صورت دستی وارد میکنیم:
| ساکنان (Occupants) | اندازه (m2) | دمای بیرون (∘C) | مصرف برق (kWh) |
|---|---|---|---|
| 4 | 150 | 24 | 25.3 |
| 2 | 100 | 25.5 | 16.2 |
| 1 | 70 | 26.5 | 12.1 |
| 4 | 120 | 23 | 22.1 |
| 2 | 90 | 21.5 | 15.2 |
| 5 | 180 | 20 | 24.4 |
| 1 | 60 | 18.5 | 11.7 |
شبکه عصبی برای این مسئله باید سه گره ورودی داشته باشد که متناظر با سه ستون اول (ساکنان، اندازه، دما) هستند. در عین حال، باید یک گره خروجی داشته باشد که ستون چهارم، یعنی حدس شبکه در مورد مصرف برق، را نمایش میدهد. به صورت دلخواه میگوییم لایه پنهان شبکه باید چهار گره داشته باشد، نه پنج گره. شکل این معماری شبکه را نشان میدهد.
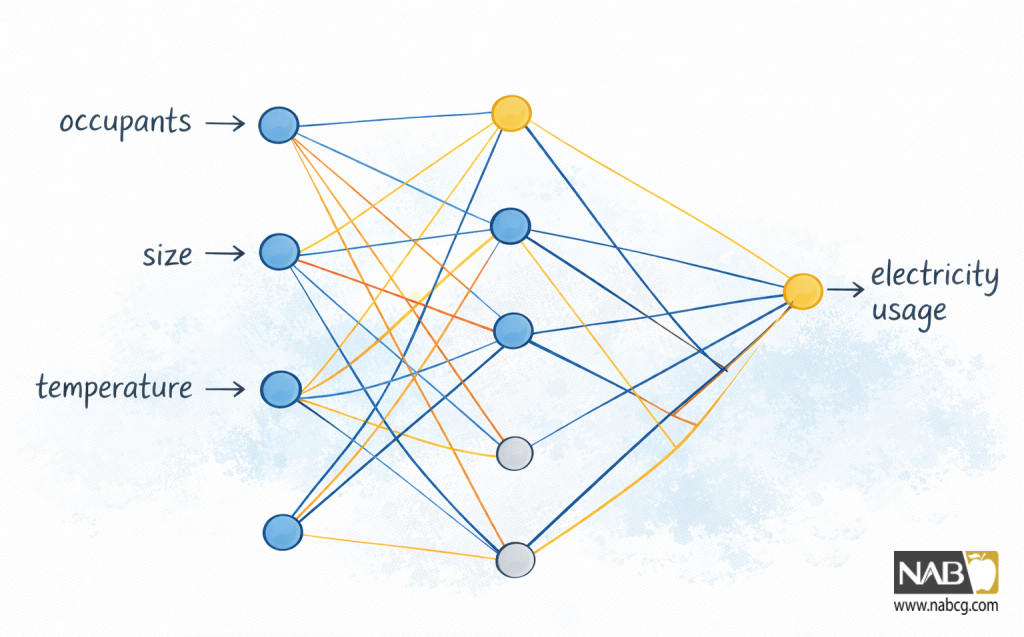
شکل 6: یک معماری شبکه ممکن برای سه ورودی و یک خروجی رگرسیون
برخلاف شبکه طبقهبندی عنبیه که از بین سه برچسب انتخاب میکند و بنابراین سه خروجی دارد، این شبکه سعی دارد فقط یک عدد را پیشبینی کند، بنابراین فقط یک خروجی دارد. با این حال، باید توجه داشت که یک خروجی واحد، الزام رگرسیون نیست. یک مدل یادگیری ماشین همچنین میتواند رگرسیونی انجام دهد که چندین مقدار پیوسته را پیشبینی کند، که در این صورت مدل چندین خروجی خواهد داشت.
17.آشنایی با کتابخانههای یادگیری عمیق و شبکههای عصبی در پایتون
شبکههای عصبی و یادگیری عمیق در دههی گذشته از یک نظریهی آکادمیک به قلب فناوریهای واقعی جهان تبدیل شدهاند. از خودروهای خودران گرفته تا چتباتهایی مثل ChatGPT و سیستمهای پزشکی، تقریباً همهی پیشرفتهای مهم در هوش مصنوعی بر پایهی کتابخانههایی بنا شدهاند که این مفاهیم را از روی کاغذ به کد زنده تبدیل میکنند.
در این مقاله میخواهیم با مهمترین کتابخانههای پیادهسازی شبکههای عصبی آشنا شویم، آنها را از نظر کاربرد، ساختار، سادگی، سرعت و جامعهی کاربری مقایسه کنیم و با چند مثال کوتاه نشان دهیم که هر کدام چه قدرتی دارند.
چرا به کتابخانههای یادگیری عمیق نیاز داریم؟
در تئوری، ساخت یک شبکهی عصبی فقط چند خط کد ریاضی است. اما در عمل، وقتی بخواهیم هزاران نورون، میلیونها وزن و گیگابایت داده را مدیریت کنیم، دیگر نوشتن کد از صفر ممکن نیست.
کتابخانههای یادگیری عمیق دقیقاً برای همین ساخته شدند:
- تا مدلسازی، آموزش و بهینهسازی شبکهها را ساده کنند.
- تا بتوانیم GPU و TPU را بهراحتی برای شتابدهی به محاسبات استفاده کنیم.
- و تا پژوهشگران و مهندسان بتوانند سریعتر ایدهها را به واقعیت تبدیل کنند.
.
18.TensorFlow— غول گوگل
TensorFlow یکی از پرکاربردترین و قدرتمندترین کتابخانههای یادگیری عمیق است که در سال ۲۰۱۵ توسط تیم Google Brain منتشر شد. این فریمورک برای کار روی مقیاسهای بزرگ طراحی شده و از دستگاههای کوچک موبایل تا ابررایانهها پشتیبانی میکند.
ویژگیهای کلیدی
- پشتیبانی از GPU و TPU برای سرعت بالا
- محاسبات تنسوری بسیار سریع
- ابزارهای آماده برای بینایی ماشین، پردازش زبان، و صوت
- داشبورد آموزشی TensorBoard برای تجسم فرایند یادگیری
.
مثال ساده TensorFlow
import tensorflow as tf
# تعریف یک مدل ساده
model = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
# کامپایل و آموزش
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())
نکته: نسخهی مدرن TensorFlow تقریباً تمام کدهایش را از طریق رابط Keras API ارائه میدهد تا کار با آن بسیار سادهتر شود.
19.PyTorch— انتخاب پژوهشگران
اگر TensorFlow دنیای صنعتی را تسخیر کرده باشد، PyTorch قلب دانشگاهها و آزمایشگاههای تحقیقاتی است.
توسط شرکت Meta (Facebook) ساخته شد و به دلیل محاسبات پویا (Dynamic Computation Graph) بسیار محبوب شد.
مزایا
- ساختار خوانا و ساده برای پژوهش
- اجرای آنی کدها (Eager Execution)
- ادغام عالی با NumPy و Jupyter Notebook
- جامعهی کاربری فوقالعاده فعال
.
مثال ساده PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
# تعریف شبکه ساده
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(4, 16)
self.fc2 = nn.Linear(16, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=1)
net = Net()
optimizer = optim.Adam(net.parameters(), lr=0.01)
print(net)
نکته: PyTorch برای آموزش مدلهای زبان، بینایی ماشین، و پردازش صوت (ASR) ابزارهای پیشساختهی قوی دارد. نسخهی جدیدش با TorchVision و TorchText بسیار کاملتر شده است.
.
20.Keras — ساده و انسانی
اگر تازهکار هستی یا میخواهی سریع یک ایده را تست کنی، Keras انتخابی ایدهآل است.
Keras در واقع یک رابط سطح بالا برای TensorFlow است که طراحی شبکه را با چند خط کد ممکن میکند.
.
مثال با Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(64, activation='relu', input_shape=(8,)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
print(model.summary())
نکته: در پروژههای آموزشی، استارتآپها و مدلهای سریع، Keras فوقالعاده است چون سرعت توسعه را چند برابر میکند.
21.Scikit-learn— پلی بین یادگیری سنتی و عمیق
در حالی که TensorFlow و PyTorch روی یادگیری عمیق تمرکز دارند، Scikit-learn برای یادگیری سنتی (Classical ML) مثل رگرسیون، درخت تصمیم، و SVM ساخته شده است.اما ترکیب آن با شبکههای عصبی نیز متداول است — مثلاً برای پیشپردازش داده، تقسیم دادهها، یا ارزیابی مدلها.
مثال کوچک Scikit-learn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
clf = MLPClassifier(hidden_layer_data-sizes=(8, 8), activation='relu', max_iter=500)
clf.fit(X_train, y_train)
print("Accuracy:", clf.score(X_test, y_test))
22.FastAI — یادگیری عمیق برای همه
FastAI بر پایهی PyTorch ساخته شده و هدفش دموکراتیزهکردن یادگیری عمیق است. یعنی کاری کند که حتی دانشجویان تازهکار هم بتوانند با چند خط کد مدلهای پیچیده بسازند.
ویژگیها
- رابط سطح بالا برای PyTorch
- مجموعه دادههای آماده و ابزارهای Data Augmentation
- تمرکز بر پروژههای واقعی: بینایی، متن، صوت و تبادلات مالی
from fastai.vision.all import *
path = untar_data(URLs.MNIST_SAMPLE)
dls = ImageDataLoaders.from_folder(path)
learn = cnn_learner(dls, resnet18, metrics=accuracy)
learn.fine_tune(1)
نکته: FastAI در آموزش بسیار محبوب است و جامعهای از معلمان و پژوهشگران را شکل داده که هدفشان «یادگیری عمیق برای همه» است.
.
23.JAX — نسل جدید یادگیری عمیق
JAX ساختهی گوگل، جدیدترین نسل از کتابخانههای یادگیری عمیق است که بر پایهی سرعت، بردارسازی و سادگی طراحی شده.
JAX در واقع NumPy با قابلیت محاسبهی خودکار مشتقات (Autograd) است.
ویژگیها
- ترکیب ساده با NumPy
- سرعت بسیار بالا با XLA Compiler
- مناسب برای پژوهشهای فیزیک، ریاضی، و شبکههای عصبی سنگین
import jax.numpy as jnp
from jax import grad
def f(x):
return x**2 + 3*x + 2
df = grad(f)
print(df(5)) # خروجی: 13
نکته: پروژههایی مثل DeepMind AlphaFold و DreamFusion از JAX استفاده میکنند، چون کنترل پایینسطح و سرعت بالایی دارد.
سایر کتابخانههای مهم
| نکتهی ویژه | کاربرد | نام کتابخانه |
|---|---|---|
| پایهی اولیه Keras | یکی از قدیمیترین فریمورکها | Theano |
| توسعهی آن متوقف شده | پشتیبانی از شبکههای گفتار و NLP | CNTK (مایکروسافت) |
| مقیاسپذیری بالا | مناسب برای سرویسهای ابری AWS | MXNet (آمازون) |
| برای تبدیل مدلها استفاده میشود | قالب مشترک بین PyTorch و TensorFlow | ONNX |
24.آیندهی یادگیری عمیق و ابزارها
روند آینده در جهت خودکارسازی طراحی مدلها (AutoML)، افزایش بازدهی انرژی و کاهش نیاز به دادههای عظیم است.
کتابخانههایی مثل Hugging Face Transformers و LangChain مسیر تازهای را باز کردهاند که ترکیب مدلهای زبانی و شبکههای عصبی را به سادهترین شکل ممکن در دسترس قرار میدهد.
در آینده، احتمالاً مرز بین «برنامهنویسی سنتی» و «آموزش مدل» محو میشود و برنامهنویسها بیشتر به طراحان رفتار هوشمند تبدیل خواهند شد.
25.نگاه انسانی به آینده هوش مصنوعی
در نهایت، همه این کتابخانهها فقط ابزارند — ابزارهایی که بدون نیت، احساس یا تخیل هستند.این انسان است که تصمیم میگیرد با آنها چه بسازد:سیستمی برای تشخیص سرطان، یا الگوریتمی برای دستکاری دادههای خبری.
هوش مصنوعی شاید روزی از ما در سرعت و دقت جلو بزند،اما خلاقیت، همدلی و ارزشهای انسانی هنوز مرز نهاییاند — همان چیزی که ماشین نمیتواند تقلید کند.
جمعبندی
در این مقاله با مهمترین کتابخانههای یادگیری عمیق آشنا شدیم و دیدیم که هرکدام برای هدفی خاص طراحی شدهاند.
از TensorFlow و PyTorch برای پروژههای صنعتی گرفته تا Keras و FastAI برای آموزش و آزمایش ایدهها.
هر مهندس داده و پژوهشگر باید حداقل یکی از این ابزارها را بشناسد تا بتواند ذهن خلاق خود را به مدلهای هوشمند ترجمه کند.آینده از آنِ کسانی است که میدانند چگونه از ماشینها برای افزایش توانایی انسانی استفاده کنند، نه برای جایگزینی آن.