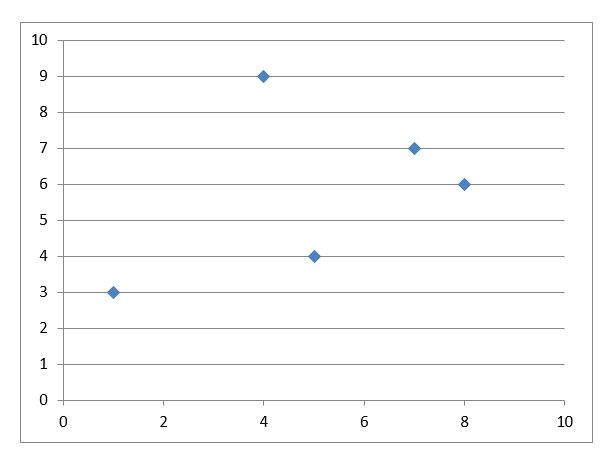
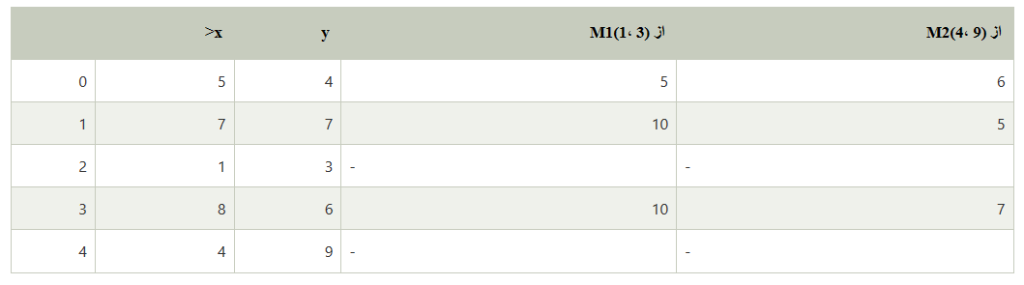
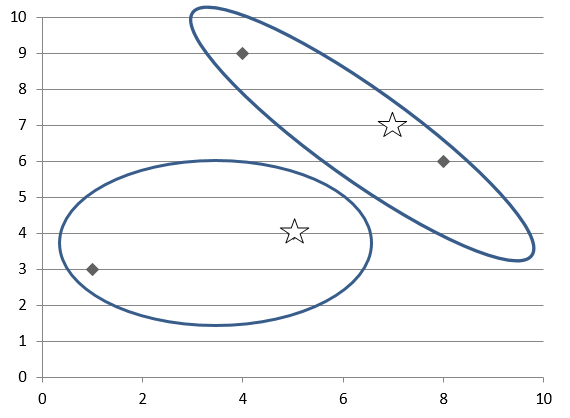
سودکلبدستآمدهراباافزودن i به S بهصورت gi =P محاسبهکنید
آنشی i راانتخابکنیدکه gi رابهحداکثرمیرسانداجازهدهیدS := S ∪ {i} و U = U − {i}.
اینمراحلتازمانیانجاممیشوندکه k شیءانتخابشوند. تصمیماتاتخاذشدهدرارزیابیشی i درشکل 1 نشاندادهشدهاست.فازدوم، SWAP، تلاشمیکندمجموعهاشیاءانتخابشدهرابهبودبخشد