

1.مقدمه
ماشین بردار پشتیبان (Support Vector Machine یا SVM) یکی از قدرتمندترین الگوریتمهای یادگیری ماشین است که برای دستهبندی و رگرسیون کاربرد دارد. ایده اصلی SVM یافتن یک ابرصفحه (Hyperplane) بهینه است که دادهها را با حداکثر حاشیه (Margin) از یکدیگر جدا کند. این روش نه تنها قابلیت تعمیم بالایی دارد، بلکه توانایی مقابله با دادههای پیچیده و غیرخطی را نیز با استفاده از تکنیک کرنل فراهم میکند.
اهمیت SVM از آنجا ناشی میشود که در بسیاری از مسائل واقعی، دادهها به صورت خطی قابل تفکیک نیستند و مدل باید بتواند با کمترین خطا و بیشترین تعمیمپذیری، تصمیمگیری کند. از سیستمهای تشخیص چهره و شناسایی دستخط گرفته تا تشخیص بیماریها و پیشبینی روند بازار، SVM الگوریتمی است که به دلیل تفسیرپذیری، کارایی و دقت بالا، به طور گسترده استفاده میشود.
در این مقاله ابتدا مفاهیم پایه SVM و روشهای پیدا کردن ابرصفحه بهینه بررسی میشوند. سپس انواع کرنلها، الگوریتمهای مرتبط با رگرسیون (SVR)، پیادهسازی عملی و کاربردهای صنعتی آن معرفی شده و مزایا و محدودیتهای استفاده از SVM تحلیل میشوند.
2.تعریف
ماشین بردار پشتیبان (SVM) یکی از قدرتمندترین، پایدارترین و محبوبترین الگوریتمهای یادگیری نظارتشده (Supervised Learning) در یادگیری ماشین است که در اواسط دهه ۱۹۹۰ میلادی توسط ولادیمیر واپونیک (Vladimir Vapnik) و همکارانش توسعه یافت. این الگوریتم به طور گسترده برای حل مسائل طبقهبندی (Classification) و رگرسیون (Regression) در حوزههای پیشرفتهای مانند تشخیص الگو (Pattern Recognition)، پردازش تصویر و پردازش زبان طبیعی (NLP) به کار میرود؛ هرچند شهرت و کاربرد اصلی آن در تفکیک کلاسها در مسائل طبقهبندی دوتایی (Binary Classification) است.
3.مفاهیم کلیدی و بنیادی در ماشین بردار پشتیبان (SVM)
- ابرصفحه (Hyperplane): مرز تصمیمگیری اصلی است که دادهها را در فضای ویژگی به کلاسهای مختلف تفکیک میکند. در فضای دوبعدی یک خط (wx + b = 0) و در فضای Nبعدی، یک ابرصفحه (N-1)بعدی است. مدل با ارزیابی اینکه دادههای جدید در کدام سمت این ابرصفحه قرار میگیرند، آنها را طبقهبندی میکند.
- بردارهای پشتیبان (Support Vectors): نزدیکترین نمونههای دادهای به ابرصفحه هستند که موقعیت و زاویه مرز تصمیم را به طور کامل تعریف و «پشتیبانی» میکنند. نام الگوریتم از این نقاط گرفته شده؛ چرا که حذف یا تغییر آنها ساختار کل مدل را دگرگون میکند.
- حاشیه (Margin): فاصله عمودی میان ابرصفحه و نزدیکترین بردار پشتیبان از هر کلاس است .SVM یک مایهساز بیشینه حاشیه (Maximum-Margin Classifier) است؛ زیرا هرچه این فاصله بزرگتر باشد، اطمینان مدل و قدرت تعمیم آن بالاتر است.

- حاشیه سخت (Hard Margin) در برابر حاشیه نرم (Soft Margin): حاشیه سخت فرضیه تفکیک ۱۰۰٪ دادهها بدون هیچ خطایی را دارد. اما در دادههای دنیای واقعی، با معرفی متغیرهای کمکی (Slack Variables)، حاشیه نرم اجازه برخی خطاهای جزیی را میدهد تا از بیشبرازش جلوگیری کند.
- ابرپارامتر C: لنگر تنظیم تعادل در حاشیه نرم است .C بزرگتر یعنی جریمه سنگین برای خطاها و ایجاد مرزهای سختگیرانه، در حالی که C کوچکتر اجازه خطای بیشتری میدهد تا حاشیه وسیعتری شکل بگیرد.
- تابع هزینه هینج (Hinge Loss): مکانیزم جریمه خطا در SVM است که اگر دادهای در سمت اشتباه مرز یا داخل حاشیه امن قرار گیرد، مقدار خطا را به صورت خطی محاسبه میکند.
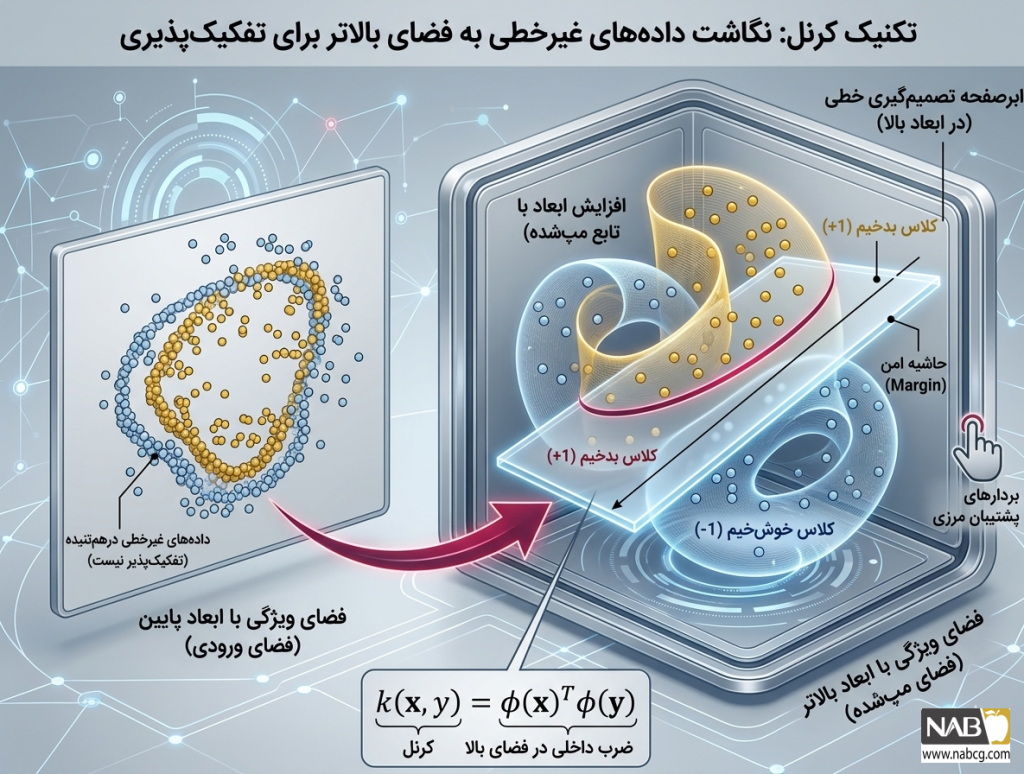
- ترفند کرنل (Kernel Trick): تابعی شگفتانگیز که با نگاشت دادههای غیرخطی به فضایی با ابعاد بالاتر، امکان تفکیک خطی آنها را فراهم میسازد.
- مسئله همزاد (Dual Problem): فرمولبندی ریاضی بهینهسازی بر اساس ضرایب لاگرانژ است که محاسبات ترفند کرنل را روی بردارهای پشتیبان فوقالعاده سریع و بهینه میکند.
.
4. اهمیت و جایگاه ماشین بردار پشتیبان (SVM) در یادگیری ماشین
در اکوسیستم مدلهای نظارتشده، ماشین بردار پشتیبان (SVM) به عنوان یکی از مستحکمترین و قابلاعتمادترین الگوریتمهای ریاضی شناخته میشود.
- بالاترین قدرت تعمیم به دلیل ماکزیمم کردن حاشیه
برخلاف الگوریتمهای کلاسیک (مانند رگرسیون لجستیک) که صرفاً به دنبال یافتن یک مرز برای جداسازی دادهها هستند، SVM بر اساس منطق فضا-هندسی، به دنبال ماکزیمم کردن حاشیه امن (Maximum Margin) است. این استراتژی باعث میشود که مدل کمترین حساسیت را به نویز داشته باشد و در مواجهه با دادههای کاملاً جدید ، بالاترین قدرت تعمیم و کمترین خطای عملیاتی را ثبت کند.
- کارایی بینظیر در دادههای ابعاد بالا (High-Dimensional Space)
یکی از کابوسهای مهندسی یادگیری ماشین، بلای ابعاد (Curse of Dimensionality) است؛ یعنی زمانی که تعداد ویژگیها بسیار بیشتر از تعداد نمونههاست SVM. (p > n) به دلیل وابستگی انحصاری به بردارهای پشتیبان (و نه کل دادهها)، پایداری ریاضی خود را در فضاهای چندهزار بعدی (مانند دادههای متنی، پردازش زبان طبیعی و ژنتیک) کاملاً حفظ میکند.
- انعطافپذیری شگفتانگیز با ترفند کرنل (Kernel Trick)
دادههای دنیای واقعی به ندرت با یک خط مستقیم از هم جدا میشوند. الگوریتم SVM با بهکارگیری تابع کرنل، دادههای پیچیده و غیرخطی را بدون درگیر شدن در محاسبات سنگین ریاضی، به فضایی با ابعاد بالاتر منتقل میکند؛ جایی که دادهها به راحتی توسط یک ابرصفحه خطی تفکیکپذیر میشوند.
- مقاومت بالا در برابر بیشبرازش (Overfitting)
از آنجا که ساختار و مرز تصمیمگیری SVM تنها توسط تعداد محدودی از دادهها (بردارهای پشتیبان مرزی) تعیین میشود، مدل به شدت در برابر نقاط پرت دوردست مقاوم است. این ویژگی ریسک بیشبرازش را به شدت کاهش میدهد.
5. انواع مدلهای ماشین بردار پشتیبان (SVM) در یادگیری ماشین
الگوریتم SVM با توجه به ماهیت و توزیع دادهها در مسائل طبقهبندی و رگرسیون، به سه دسته اصلی تقسیم میشود:
- ماشین بردار پشتیبان خطی (Linear SVM)
- ماشین بردار پشتیبان غیرخطی (Non-linear SVM)
- رگرسیون بردار پشتیبان (SVR)

ماشین بردار پشتیبان خطی (Linear SVM)
زمانی از این مدل استفاده میشود که دادهها به صورت خطی تفکیکپذیر (Linearly Separable) باشند؛ یعنی بتوان با یک مرز صاف کلاسها را از هم جدا کرد. پروفسور وینستون از MIT این فرآیند بهینهسازی ثانویه را به برازش عریضترین خیابان ممکن تشبیه میکند که در آن، پیادهروها همان بردارهای پشتیبان هستند و معادله ابرصفحه جداکننده به صورت w . x + b = 0 تعریف میشود. برای محاسبه حاشیه (Margin) دو رویکرد وجود دارد:
- حاشیه سخت (Hard-Margin): مدل هیچ خطایی را نمیپذیرد و تمام دادهها باید کاملاً خارج از حاشیه (خیابان) قرار گیرند. این روش در برابر نویز و دادههای پرت (Outliers) شدیداً آسیبپذیر است.
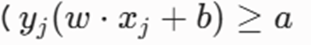
- حاشیه نرم (Soft-Margin): با معرفی متغیرهای کمکی (xi)، مدل انعطافپذیر شده و اجازه اشتباهات کوچک را میدهد. در اینجا ابرپارامتر C تعادل را برقرار میکند؛ C بزرگتر حاشیه را باریکتر میکند تا خطا کم شود (ریسک بیشبرازش)، در حالی که C کوچکتر حاشیه را عریضتر کرده و خطای بیشتری را تحمل میکند.
.
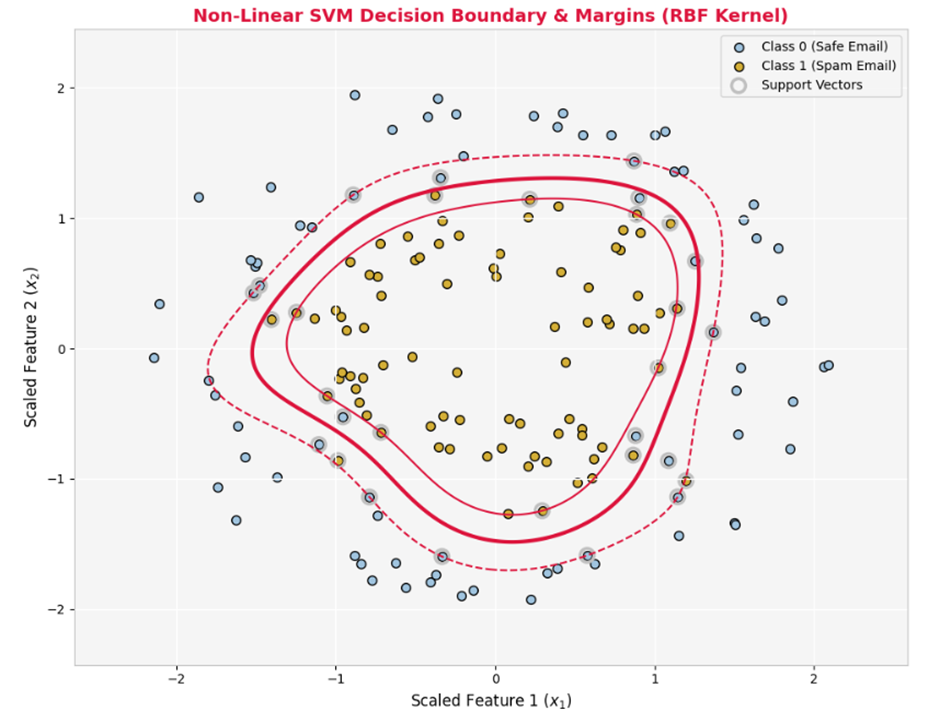
ماشین بردار پشتیبان غیرخطی (Non-linear SVM)
دادههای دنیای واقعی معمولاً پیچیده و غیرخطی هستند. در این حالت، SVM دادهها را به یک فضای ویژگی با ابعاد بالاتر (Higher-Dimensional Space) منتقل میکند تا در آنجا خطی و تفکیکپذیر شوند. برای جلوگیری از پیچیدگی محاسباتی شدید و ریسک بیشبرازش در ابعاد بالا، از ترفند کرنل (Kernel Trick) استفاده میشود که بدون انتقال واقعی دادهها، ضرب داخلی آنها را از طریق توابع ریاضی زیر محاسبه میکند:
- کرنل چندجملهای (Polynomial)
- کرنل تابع پایه شعاعی (RBF / Gaussian): محبوبترین کرنل برای نگاشتهای بینهایتبعدی.
- کرنل سیگموئید (Sigmoid)
.
رگرسیون بردار پشتیبان (SVR)
نسخه توسعهیافته SVM برای پیشبینی متغیرهای پیوسته و عددی (مانند سریهای زمانی) است. برخلاف رگرسیون خطی سنتی که برای لایه محاسباتی خود نیاز به تعیین نوع و جهت رابطه متغیرها دارد، SVR این روابط را به طور خودکار کشف کرده و تلاش میکند عریضترین لوله اطمینان را دور دادهها ترسیم کند.
.
6. فرآیند عملکرد و پیادهسازی الگوریتم SVM در یادگیری ماشین
ماشین بردار پشتیبان (SVM) از قویترین الگوریتمهای نظارتشده است که فرآیند ساخت و بهینهسازی آن در چرخه یادگیری ماشین شامل سه فاز کلیدی زیر است:
مکانیزم مرزبندی هوشمند (How it Works)
در مسائل طبقهبندی، خطوط بیشماری میتوانند دادهها را مهار کنند؛ اما SVM به دنبال یافتن ابرصفحه با بیشترین حاشیه (Maximum Margin Hyperplane) است. این الگوریتم به جای تمرکز بر همه دادهها، موقعیت مرز را دقیقاً بر اساس نزدیکترین نمونهها به کلاس مقابل تنظیم میکند که به آنها بردارهای پشتیبان (Support Vectors) میگویند. حاشیه (Margin)، فاصله امن میان این بردارها و ابرصفحه تصمیمگیری است که ماکزیمم کردن آن، تعمیمپذیری (Generalization) مدل را روی دادههای جدید تضمین میکند.
چرخه ساخت و ارزیابی مدل (Building & Evaluation)
- تفکیک دیتابیس (Data Splitting): پس از تحلیل اکتشافی دادهها (EDA) و مدیریت دادههای پرت، دیتاسِت به دو بخش آموزش (Train) و تست (Test) تقسیم میشود.
- آموزش و ارزیابی: مدل با متدهایی مثل SVC در کتابخانه Scikit-Learn روی دادههای آموزشی فیت میشود. برای سنجش دقیق عملکرد مدل روی دادههای تست، علاوه بر معیار دقت (Accuracy)، معیارهای تخصصیتر مانند صحت (Precision)، فراخوانی (Recall) و شاخص F1-Score محاسبه میشوند تا تعادل دستهبندی کلاسها ارزیابی شود.
.
تنظیم ابرپارامترها (Hyperparameter Tuning)
برای رسیدن به بالاترین کارایی، رفتار تفکیککنندگی SVM با استفاده از روشهای جستجوی شبکهای (Grid Search) و اعتبارسنجی متقاطع (Cross-Validation) روی سه لنگر اصلی تنظیم میشود:
- نوع کرنل (Kernel): انتقال دادههای غیرخطی به ابعاد بالاتر )مانند RBF یا Polynomial).
- پارامتر منظمسازی (C): ایجاد تعادل میان عرض حاشیه و میزان تسامح خطای دستهبندی؛ C بزرگ یعنی حاشیه باریکتر و خطای کمتر روی داده آموزش (ریسک Overfitting).
- پارامتر گاما (Gamma): تعیین شعاع تأثیرگذاری برداری؛ گامای بالا یعنی فقط نقاط نزدیک به مرز تصمیمگیری در نظر گرفته میشوند.
.
7. تحلیل پیشرفته مبانی ریاضی و تابع هدف در ماشین بردار پشتیبان (SVM)
هدف بنیادی ریاضی در الگوریتم SVM، یافتن یک مرز تصمیمگیری بهینه یا ابرصفحه حداکثر حاشیه (Maximum Margin Hyperplane) است که کلاسهای مختلف را با بالاترین ضریب اطمینان از یکدیگر تفکیک کند.
معادله ابرصفحه تصمیمگیری (Decision Hyperplane)
در یک فضای ویژگی چندبعدی، مرز تفکیککننده کلاسها به صورت یک معادله خطی صریح تعریف میشود:
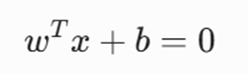
- w (بردار وزنها – Weights): برداری ستونی و عمود بر ابرصفحه که جهت و زاویه مرز تصمیمگیری را در فضا تعیین میکند.
- x (بردار ویژگیها – Features): بردار ورودی نمونه دادهها که موقعیت مکان نقطه را مشخص میسازد.
- b (مقدار بایاس – Bias): عرض از مبدأ که فاصله شومینه ابرصفحه را از مبدأ مختصات کنترل میکند.
.
شروط دستهبندی و مرزهای حاشیه امن
برای یک مسئله طبقهبندی دوتایی (Binary Classification) با برچسبهای خروجی yi∈{−1,+1}، اصرار ریاضی بر این است که دادهها نهتنها درست دستهبندی شوند، بلکه خارج از حاشیه امن (Margin) قرار گیرند. این شروط برای مرزهای بالایی و پایینی به صورت زیر است:
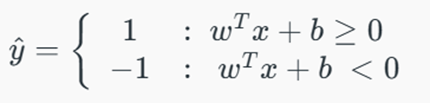
با ضرب برچسب کلاس (yi) در معادله، این دو رابطه در یک ابرشرط ریاضی یکپارچه ادغام میشوند:

- yi: برچسب واقعی نمونه iام که مقدار آن یا 1+ (کلاس مثبت) و یا 1− (کلاس منفی) است.
- xi: بردار ویژگیهای مربوط به نمونه iام دیتابیس.
نقاطی که دقیقاً روی مرزهای حاشیه قرار میگیرند (یعنی

همان بردارهای پشتیبان (Support Vectors) هستند که اسکلت اصلی مدل را میسازند.

فرمولبندی بهینهسازی مقید (Constrained Optimization)
از نظر هندسی، فاصله بین دو مرز حاشیه کلاس مثبت و منفی برابر با ∥w∥2/ است. مأموریت اصلی SVM، ماکزیمم کردن این حاشیه است. از آنجا که ماکزیمم کردن کسر ∥w∥/2 معادل با مینیمم کردن مخرج آن است، برای تسهیل در مشتقگیری ریاضی، مسئله به یک بهینهسازی محدب ثانویه (Convex Quadratic Optimization) به فرم زیر تبدیل میشود:

- ∥w∥ (نُرم دوم بردار وزن): اندازه یا طول هندسی بردار وزن که به صورت
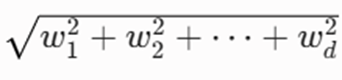
- subject to: بیانگر قیود و شروط سختی است که الگوریتم باید هنگام مینیممسازی وزنها کاملاً به آنها پایبند باشد تا هیچ دادهای به اشتباه دستهبندی نشود (Hard Margin).
این فرمولبندی پایه در شرایطی که دادهها نویزی باشند، با افزودن متغیرهای کمکی (Slack Variables) به فرم نرم (Soft Margin) ارتقا مییابد تا پایداری و تعمیمپذیری مدل حفظ شود.
مثال عددی اول: سیستم هوشمند اعتبارسنجی متقاضیان وام بانکی (کلاس تفکیکپذیر خطی)
سناریوی مسئله:
یک مدل SVM توسعه داده شده است تا ریسک مالی متقاضیان وام را به دو دستهی کمریسک (تأیید وام: y = +1) و پرریسک (رد وام: y = -1) دستهبندی کند. دو ویژگی مقیاسشده برای این ارزیابی عبارتند از:
- x1: شاخص درآمد سالانه
- x2: امتیاز اعتبار سنجی بانک (Credit Score)
پس از فرآیند آموزش، الگوریتم بهینهسازی بردار وزن خط جداکننده را w = [2, 3]^T و مقدار بایاس را b = -12 محاسبه کرده است. اکنون میخواهیم وضعیت یک متقاضی جدید با مشخصات x = [3, 4]^T را به صورت گامبهگام تحلیل کنیم.
گام اول: محاسبه خروجی خام مدل (Decision Score)
ابتدا ترکیب خطی ویژگیها را با بردار وزن و بایاس حساب میکنیم. توجه داشته باشید که ضرب w^T x به صورت ضرب داخلی دو بردار (Dot Product) انجام میشود:
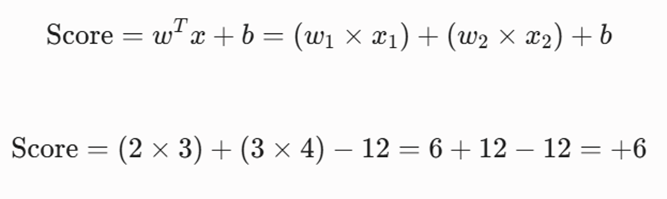
گام دوم: تعیین کلاس خروجی (Classification)
تابع تصمیمگیری در SVM بر اساس علامت (Sign) خروجی خام عمل میکند. از آنجا که Score = +6 > 0 است، متقاضی جدید در دستهی y = +1 (کمریسک – تأیید وام) قرار میگیرد.
گام سوم: محاسبه فاصله دقیق هندسی تا ابرصفحه تصمیمگیری
برای اینکه بدانیم این مشتری چقدر از مرز خطر فاصله دارد، فاصله عمودی (Geometric Margin) او تا خط تصمیمگیری را محاسبه میکنیم. فرمول فاصله هندسی نقطه از صفحه عبارت است از:

ابتدا نُرم (اندازه) بردار وزن را محاسبه میکنیم:
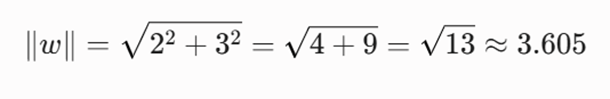
حالا فاصله را به دست میآوریم:
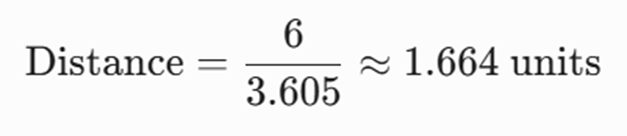
گام چهارم: سنجش پهنای حاشیه امن مدل (Total Margin)
کل پهنای باند امنیتی که این مدل بین دو کلاس ایجاد کرده است، برابر است با:
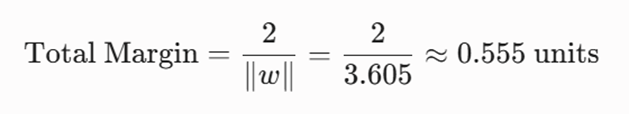
تحلیل مهندسی: از آنجا که فاصله هندسی این مشتری (1.664) از نصف پهنای حاشیه امن (0.277) بسیار بزرگتر است، این متقاضی در عمق ناحیه امن قرار دارد و مدل با ضریب اطمینان بالایی او را به عنوان مشتری خوشحساب شناسایی کرده است.
مثال عددی دوم: سیستم هوشمند هشدارهای پزشکی و تشخیص زودهنگام تومور (بررسی وضعیت بردارهای پشتیبان مرزی)
سناریوی مسئله:
یک الگوریتم SVM مأموریت دارد تومورهای سلولی را به دو دستهی خوشخیم (y = -1) و بدخیم (y = +1) طبقهبندی کند. ویژگیهای ورودی عبارتند از:
- x1: ضخامت توده (Clump Thickness)
- x2: یکنواختی اندازه سلول (Uniformity of Cell Size)
فرآیند بهینهسازی به ضرایب w = [1, 1]^T و b = -6 رسیده است. ما میخواهیم وضعیت دو بیمار مشکوک را بررسی کنیم تا مرز سختگیرانهی شرط yi(w^T xi + b) ≥1 را بسنجیم.
بخش اول: تحلیل وضعیت بیمار آ (xA = [4, 3]^T)
۱. محاسبه امتیاز:
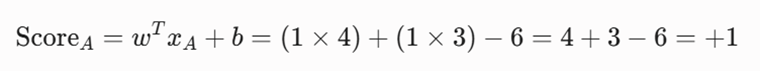
۲. تعیین کلاس: چون خروجی مثبت است، تومور بدخیم (y = +1) تشخیص داده میشود.
۳. بررسی شرط حاشیه امن:
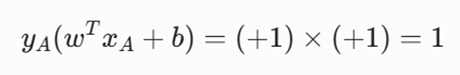
چون این مقدار دقیقاً مساوی ۱ شده است، نشان میدهد که بیمار آ یک بردار پشتیبان (Support Vector) است. این سلول دقیقاً روی لبهی داخلی مرز کلاس بدخیمها قرار گرفته و تغییر موقعیت آن، کل مرز تصمیمگیری شبکه را جابهجا میکند.
بخش دوم: تحلیل وضعیت بیمار ب (xB = [2, 3]^T)
۱. محاسبه امتیاز:
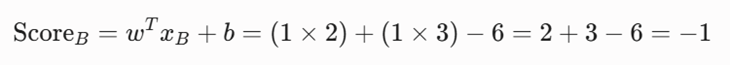
۲. تعیین کلاس: چون خروجی منفی است، تومور خوشخیم (y = -1) تشخیص داده میشود.
۳. بررسی شرط حاشیه امن:

این بیمار نیز به دلیل اینکه خروجی شرطش دقیقاً مساوی ۱ شده است، یک بردار پشتیبان دیگر، اما اینبار روی لبهی داخلی مرز خوشخیمهاست.
محاسبات هندسی حاشیه مدل:
اندازه بردار وزن:

کل پهنای حاشیه امن بین تومورهای خوشخیم و بدخیم:
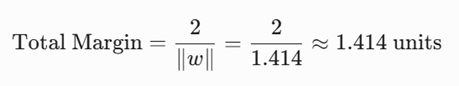
نتیجهگیری: این مثال به خوبی نشان میدهد که چگونه هندسه ریاضی SVM مرز خود را دقیقاً در وسط این دو بیمار مرزی (بردارهای پشتیبان با امتیازهای 1+ و -1) فیکس کرده است تا بیشترین فضا (1.414) را برای کاهش ریسک خطای پزشکی در دیتای آینده حفظ کند.
8. مقایسه رقابتی SVM با سایر الگوریتمهای یادگیری نظارتشده
در مهندسی یادگیری ماشین، انتخاب الگوریتم بهینه برای یک کاربرد خاص، نیازمند درک عمیق از نقاط قوت و ضعف ساختاری هر مدل است. در ادامه، جایگاه ماشین بردار پشتیبان (SVM) را در برابر سایر طبقهبندیکنندههای محبوب بررسی میکنیم:
- SVM در برابر Naive Bayes: هر دو در دستهبندی متن پرکاربرد هستند. اما زمانی که دادهها به صورت خطی تفکیکپذیر نباشند، SVM به لطف «ترفند کرنل» عملکرد بسیار برتری دارد. در مقابل، Naive Bayes بسیار سریعتر است و نیاز به تنظیم پیچیده ابرپارامترها ندارد.
- SVM در برابر Logistic Regression: در مواجهه با دادههای ابعاد بالا و ساختارنیافته (مثل تصاویر و متن)، SVM قویتر از رگرسیون لوجستیک عمل میکند و به دلیل تمرکز بر بردارهای پشتیبان، حساسیت کمتری به بیشبرازش (Overfitting) دارد؛ اگرچه هزینه محاسباتی بالاتری را تحمیل میکند.
- SVM در برابر Decision Trees: درختهای تصمیمگیری سرعت آموزش بالایی در دیتابیسهای کوچک دارند و تفسیرپذیری آنها سادهتر است. با این حال، در دادههای ابعاد بالا، به شدت مستعد بیشبرازش هستند؛ جایی که SVM پایداری و قدرت تعمیم بسیار بیشتری از خود نشان میدهد.
- SVM در برابر Neural Networks: شبکههای عصبی عمیق فوقالعاده انعطافپذیر و مقیاسپذیر هستند و برایان دیتابیسهای غولآسا استاندارد طلایی محسوب میشوند. در سمت مقابل، SVM برای دیتابیسهای کوچک تا متوسط، پایداری ریاضی تضمینشدهتری دارد و کمتر دچار بیشبرازش میشود.
.
9.جدول مقایسه جامع الگوریتمهای طبقهبندی (Classification)
| الگوریتم | قدرت تعمیم و ریسک Overfitting | عملکرد در ابعاد بالا (High-Dim) | سرعت آموزش و مقیاسپذیری | تفسیرپذیری |
| SVM | بسیار عالی (مقاوم در برابر بیشبرازش) | عالی (به ویژه با دادههای متنی و تصویری) | متوسط تا ضعیف (هزینه محاسباتی بالا) | متوسط (وابسته به نوع کرنل) |
| Naive Bayes | متوسط | خوب (برای متون) | فوقالعاده سریع و سبک | عالی و ساده |
| Logistic Regression | متوسط (نیازمند منظمسازی) | ضعیف تا متوسط | سریع و بهینه | بسیار عالی (مبتنی بر احتمال) |
| Decision Trees | ضعیف (مستعد بیشبرازش شدید) | ضعیف | سریع در دادههای کوچک | بسیار عالی (ساختار درختی صریح) |
| Neural Networks | نیازمند کنترل شدید (Dropout/L2) | فوقالعاده عالی | کند و نیازمند سختافزار قوی | ضعیف (جعبه سیاه) |
10. ابزارها و فریمورکهای محبوب برای اجرای SVM
در اکوسیستم یادگیری ماشین، ابزارهای قدرتمندی برای پیادهسازی ماشین بردار پشتیبان (SVM) با مأموریتهای متفاوت وجود دارند. در ادامه، دو ابزار استاندارد و یک فریمورک عمیق را همراه با کد پایتون واقعی بررسی میکنیم:
Scikit-Learn (استاندارد طلایی یادگیری ماشین)
کتابخانه scikit-learn برای دیتاسِتهای ابعاد کوچک تا متوسط، سریعترین و محبوبترین گزینه است. این ابزار از لایبرریهای بهینهشده LIBSVM و LIBLINEAR در پسزمینه استفاده میکند و انعطافپذیری بالایی در تغییر کرنلها دارد.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# ۱. بارگذاری دیتاسِت واقعی گل زنبق (تفکیک ۲ کلاس برای سادگی)
iris = load_iris()
X = iris.data[iris.target != 2, :2]
y = iris.target[iris.target != 2]
# ۲. تقسیم دادهها و استانداردسازی (SVM به مقیاس دادهها بسیار حساس است)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# ۳. آموزش مدل با کرنل خطی
model = SVC(kernel='linear', C=1.0)
model.fit(X_train, y_train)
print(fAccuracy Score: {model.score(X_test, y_test):.2f})
خروجی:

PyTorch (یادگیری عمیق و شتابدهی GPU)
زمانی که حجم دادهها بسیار بزرگ است و نیاز به پردازش موازی روی کارت گرافیک (GPU) داریم، فریمورکهای عمیق مانند PyTorch وارد عمل میشوند. در این ابزار، تابع هزینه SVM (معروف به Hinge Loss) به صورت دستی بهینهسازی میشود.
import torch
import torch.nn as nn
import torch.optim as optim
# تبدیل دادهها به تنسورهای پایتورچ (برچسبها باید ۱ و ۱- باشند)
X_tensor = torch.tensor(X_train, dtype=torch.float32)
y_tensor = torch.tensor(np.where(y_train == 0, -1, 1), dtype=torch.float32).view(-1, 1)
# تعریف لایه خطی برای SVM
linear_layer = nn.Linear(2, 1)
optimizer = optim.SGD(linear_layer.parameters(), lr=0.01, weight_decay=0.01)
# حلقه آموزش با تابع هزینه Soft-Margin Hinge Loss
for epoch in range(100):
optimizer.zero_grad()
outputs = linear_layer(X_tensor)
# فرمول ریاضی Hinge Loss
loss = torch.mean(torch.clamp(1 - y_tensor * outputs, min=0))
loss.backward()
optimizer.step()
print(PyTorch SVM weights trained successfully.)
خروجی:

LIBSVM & LIBLINEAR
این دو فریمورک مستقل که به زبان C++ نوشته شدهاند، هسته اصلی اکثر پکیجهای یادگیری ماشین (از جمله اسکایلرن) هستند. LIBSVM برای مسائلی با کرنلهای غیرخطی پیچیده و LIBLINEAR به طور اختصاصی برای دادههای خطی با ابعاد بسیار بزرگ (مانند طبقهبندی متن با میلیونها ویژگی) بهینهسازی شده است.
11. راهنمای گامبهگام پیادهسازی پروژهی SVM
برای اجرای این الگوریتم روی دادههای واقعی و غیرخطی، فرآیند زیر را در هسته مدلسازی طی میکنیم:
- گام اول؛ فراخوانی دادههای واقعی و ایجاد الگوی غیرخطی: یک دیتاسِت واقعی و دایرهای (متقاطع) فراخوانی میکنیم که با خطوط مستقیم به هیچ وجه جداپذیر نباشد (پدیده عدم تفکیک خطی).
- گام دوم؛ استانداردسازی دادهها: از آنجا که SVM بر اساس محاسبه فواصل هندسی (حاشیه) کار میکند، کوچکترین تغییر در مقیاس ویژگیها، مرز تصمیم را به شدت خراب میکند؛ پس دادهها را استانداردسازی میکنیم.
- گام سوم؛ تنظیم ابرپارامترها (Hyperparameter Tuning): با استفاده از Grid Search، بهترین مقدار جریمه خطا (C) و پارامتر گاما (γ) را برای کرنل غیرخطی RBF پیدا میکنیم.
- گام چهارم؛ آموزش و استخراج بردارهای پشتیبان: مدل بهینه را آموزش داده و مختصات دقیق بردارهای پشتیبان را که بار اصلی ریاضیات مدل را به دوش میکشند، استخراج میکنیم.
- گام پنجم؛ تصویرسازی مرزهای حاشیه امن: مرز تصمیمگیری غیرخطی و حاشیه امن آن را مطابق پالت رنگی برند رسم میکنیم.
.
کد کامل
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# ==========================================
# تنظیمات پالت رنگی اختصاصی سایت (NABCG)
# ==========================================
COLOR_GOLD = '#D4AF37' # Active Gold (نقاط کلاس ۱)
COLOR_CRIMSON = '#DC143C' # Crimson (مرز تصمیمگیری و خطوط حاشیه)
COLOR_SOFT_BLUE = '#A0C4DF' # AI Soft Blue (نقاط کلاس ۰)
COLOR_SILVER = '#C0C0C0' # Metal Silver (بردارهای پشتیبان مرزی)
COLOR_LIGHT_GRAY = '#F5F5F5' # Ultra Light Gray (پسزمینه نمودار)
COLOR_WHITE = '#FFFFFF' # Pure White
# تنظیم فونت و استایل پسزمینه نمودارها
plt.rcParams['figure.facecolor'] = COLOR_WHITE
plt.rcParams['axes.facecolor'] = COLOR_LIGHT_GRAY
plt.rcParams['axes.edgecolor'] = COLOR_SILVER
# ==========================================
# گام ۱: تولید دادههای غیرخطی (متقاطع دایرهای)
# ==========================================
# ایجاد ۲۰۰ نمونه داده که به صورت دایرههای تودرتو هستند و با خط مستقیم جدا نمیشوند
X, y = make_circles(n_samples=200, factor=0.5, noise=0.15, random_state=42)
# ==========================================
# گام ۲: تقسیم دادهها و استانداردسازی ویژگیها
# ==========================================
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ==========================================
# گام ۳: جستجوی شبکهای برای یافتن بهترین کرنل و پارامترها (C و Gamma)
# ==========================================
param_grid = {
'C': [0.1, 1, 10, 100], # ضریب جریمه خطای حاشیه نرم (Soft Margin)
'gamma': ['scale', 'auto', 0.1, 1, 10], # پهنای باند تابع کرنل شعاعی (RBF)
'kernel': ['rbf'] # استفاده از کرنل غیرخطی RBF طبق مستندات شما
}
grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_scaled, y_train)
# استخراج مدل بهینه نهایی
best_svm = grid_search.best_estimator_
y_pred = best_svm.predict(X_test_scaled)
# ==========================================
# گام ۴: چاپ گزارش عملکرد و استخراج بردارهای پشتیبان
# ==========================================
print(============= SVM MODEL RESULTS =============)
print(fBest Hyperparameter C: {grid_search.best_params_['C']})
print(fBest Hyperparameter Gamma: {grid_search.best_params_['gamma']})
print(fTest Set Accuracy: {accuracy_score(y_test, y_pred) * 100:.2f}%)
print(fTotal Support Vectors Found: {len(best_svm.support_vectors_)})
print(=============================================)
# ==========================================
# گام ۵: رسم مرز تصمیمگیری غیرخطی و حاشیهها (بصری)
# ==========================================
plt.figure(figsize=(10, 8))
# ایجاد یک مش (Grid) برای رنگآمیزی فضای دوبعدی تصمیمگیری
xx, yy = np.meshgrid(np.linspace(X_train_scaled[:, 0].min() - 0.5, X_train_scaled[:, 0].max() + 0.5, 500),
np.linspace(X_train_scaled[:, 1].min() - 0.5, X_train_scaled[:, 1].max() + 0.5, 500))
# محاسبه تابع تصمیم (Z) برای تمام نقاط روی صفحه مش
Z = best_svm.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# رسم مرز تصمیمگیری (Z=0) و خطوط حاشیه امن (Z=-1 و Z=1) مطابق فرمولهای فایل شما
plt.contour(xx, yy, Z, levels=[-1, 0, 1], colors=COLOR_CRIMSON, linetypes=['--', '-', '--'], linewidths=[1.5, 3, 1.5])
# رسم نقاط دادههای کلاس ۰ با رنگ آبی ملایم هوش مصنوعی
plt.scatter(X_train_scaled[y_train == 0, 0], X_train_scaled[y_train == 0, 1],
color=COLOR_SOFT_BLUE, edgecolors='black', s=50, label='Class 0 (Safe Email)')
# رسم نقاط دادههای کلاس ۱ با رنگ طلایی فعال
plt.scatter(X_train_scaled[y_train == 1, 0], X_train_scaled[y_train == 1, 1],
color=COLOR_GOLD, edgecolors='black', s=50, label='Class 1 (Spam Email)')
# برجسته کردن متمایز «بردارهای پشتیبان» با دایرههای نقرهای متالیک بزرگتر در پسزمینه
plt.scatter(best_svm.support_vectors_[:, 0], best_svm.support_vectors_[:, 1],
s=120, facecolors='none', edgecolors=COLOR_SILVER, linewidths=2.5, label='Support Vectors')
# تنظیمات نهایی ظاهر و لیبلهای نمودار به انگلیسی
plt.title('Non-Linear SVM Decision Boundary & Margins (RBF Kernel)', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
plt.xlabel('Scaled Feature 1 (x_1)', fontsize=12)
plt.ylabel('Scaled Feature 2 (x_2)', fontsize=12)
plt.grid(True, color=COLOR_WHITE, linestyle='-', linewidth=1)
plt.legend(loc='upper right')
plt.tight_layout()
plt.show()خروجی:

مطالعه موردی اول: سیستم تشخیص دستخط و ارقام دیجیتال (بینایی ماشین و دستهبندی چندکلاسی)
مسئله و چالش مهندسی داده
سیستمهای پردازش اتوماتیک (مانند خوانش کدهای پستی یا چکهای بانکی) باید تصاویر پیکسلبهپیکسل ارقام دستنویس انسان را با دقت بالا به اعداد واقعی (۰ تا ۹) تبدیل کنند. چالش مهندسی در این دیتابیسها، ابعاد بسیار بالا (High-Dimensional Space) و نویزی بودن دستخطهای مختلف است. از آنجا که مرزهای متمایزکننده شکل ظاهری اعداد (مثلاً شباهت عدد ۱ و ۷ یا ۳ و ۸) به صورت خطی جداپذیر نیستند، رگرسیونهای ساده یا پرسپترونها به شدت دچار خطا میشوند. الگوریتم SVM با به کارگیری کرنل غیرخطی RBF (تابع شعاعی)، دادهها را به فضایی مپ میکند که مرزهای غیرخطی پیچیده به راحتی تفکیک شوند.
هدف یادگیری ماشین
آموزش یک دستهبندیکننده چندکلاسی (Multi-class SVM) با هدف ماکزیمم کردن حاشیه امن بین تمامی ۱۰ کلاس عددی (۰ تا ۹) و رسیدن به بالاترین نرخ دقت (Accuracy) روی تصاویر تست.
کد کامل پایتون با دیتای واقعی ارقام دستنویس
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# ------------------------------------------
# تنظیمات پالت رنگی اختصاصی سایت (NABCG)
# ------------------------------------------
COLOR_GOLD = '#D4AF37' # Active Gold
COLOR_CRIMSON = '#DC143C' # Crimson
COLOR_SOFT_BLUE = '#A0C4DF' # AI Soft Blue
COLOR_SILVER = '#C0C0C0' # Metal Silver
COLOR_LIGHT_GRAY = '#F5F5F5' # Ultra Light Gray
COLOR_WHITE = '#FFFFFF' # Pure White
plt.rcParams['figure.facecolor'] = COLOR_WHITE
plt.rcParams['axes.facecolor'] = COLOR_LIGHT_GRAY
plt.rcParams['axes.edgecolor'] = COLOR_SILVER
# ------------------------------------------
# گام ۱: بارگذاری دیتابیس واقعی تصاویر ارقام دستنویس
# ------------------------------------------
digits = load_digits()
X = digits.data # ویژگیها: ویژگیهای پیکسلی ماتریس ۸در۸ تصویر (۶۴ ویژگی)
y = digits.target # برچسبها: اعداد واقعی بین ۰ تا ۹
# ------------------------------------------
# گام ۲: تقسیم دادهها و استانداردسازی ویژگیها
# ------------------------------------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# از آنجا که ویژگیها شدت روشنایی پیکسلها هستند، استانداردسازی فواصل حاشیه SVM را عادلانه میکند
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ------------------------------------------
# گام ۳: جستجوی شبکهای برای یافتن بهترین پارامترهای C و Gamma
# ------------------------------------------
svm_model = SVC(kernel='rbf', random_state=42)
param_grid = {
'C': [0.1, 1, 10, 100], # پارامتر تنظیم حاشیه نرم (Soft Margin)
'gamma': ['scale', 'auto', 0.01, 0.1] # پهنای باند کرنل RBF
}
# اعمال کراسولیدیشن ۵ لایه برای مهار بیشبرازش
grid_search = GridSearchCV(svm_model, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train_scaled, y_train)
best_svm = grid_search.best_estimator_
y_pred = best_svm.predict(X_test_scaled)
# ------------------------------------------
# گام ۴: ارزیابی تخصصی عملکرد مدل
# ------------------------------------------
accuracy = accuracy_score(y_test, y_pred)
print(============= HANDWRITTEN DIGITS RESULTS =============)
print(fBest Hyperparameter C: {grid_search.best_params_['C']})
print(fBest Hyperparameter Gamma: {grid_search.best_params_['gamma']})
print(fModel Accuracy on Test Set: {accuracy * 100:.2f}%)
print(======================================================)
# ------------------------------------------
# گام ۵: تصویرسازی ارقام دستنویس و پیشبینی مدل (پالت اختصاصی)
# ------------------------------------------
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
# پیدا کردن شاخص نمونههای دیتای تست برای نمایش تصادفی
indices = np.random.choice(len(X_test), 8, replace=False)
for i, idx in enumerate(indices):
ax = axes[i // 4, i % 4]
# بازسازی ماتریس تصویر ۸در۸ از روی بردار ویژگی ۶۴تایی
image_matrix = X_test[idx].reshape(8, 8)
ax.imshow(image_matrix, cmap='gray_r')
# مشخص کردن رنگ عنوان بر اساس صحت پیشبینی (آبی برای درست و قرمز برای غلط)
title_color = COLOR_GOLD if y_pred[idx] == y_test[idx] else COLOR_CRIMSON
ax.set_title(fTrue: {y_test[idx]} | Pred: {y_pred[idx]}, color=title_color, fontsize=12, fontweight='bold')
ax.axis('off')
plt.suptitle('Handwritten Digit Classification via Non-Linear SVM', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
plt.tight_layout()
plt.show()خروجی:


.

مطالعه موردی دوم: پیشبینی روند بازار سهام (یادگیری ماشین مالی و دادههای نوسانی سری زمانی)
مسئله و چالش مهندسی داده
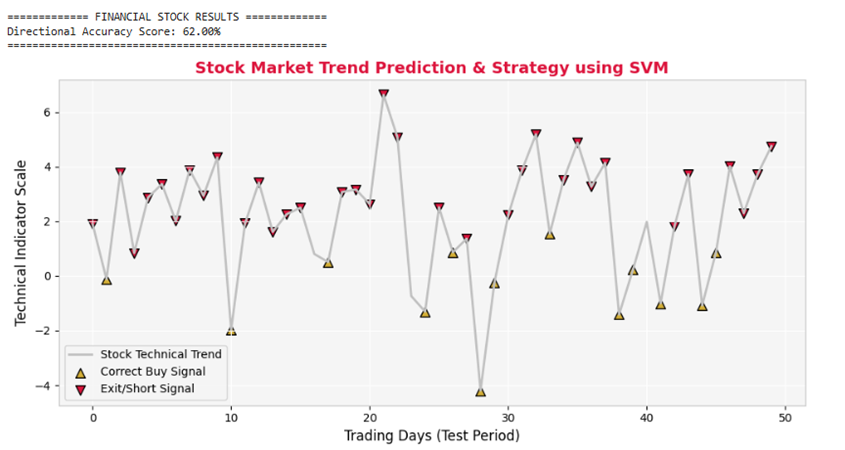
بازارهای مالی و بورس به شدت داینامیک، آشفته و آلوده به نویزهای تصادفی (Stochastic Noise) هستند. قیمت پایانی یک سهم تحت تأثیر رفتارهای پیچیده معاملهگران است. چالش بزرگ مهندسی داده در اینجا، پیدا کردن الگوهای پایدار از روی شاخصهای تکنیکال (مثل میانگین متحرک یا انحراف معیار قیمت) است. یک مرز ساده لجستیک در دیتای بورس به سرعت دچار بیشبرازش (Overfitting) میشود. ویژگی حاشیه نرم (Soft Margin) در الگوریتم SVM با معرفی پارامتر جریمه (C) و متغیرهای کمکی، تعمداً اجازه میدهد برخی دادههای نویزی وارد حاشیه امن شوند تا یک مرز کلی، منطقی و با قدرت پیشبینیِ بالا برای فردا استخراج شود.
هدف یادگیری ماشین
پیشبینی جهت حرکت قیمت سهام برای روز آینده؛ به طوری که اگر قیمت صعودی باشد سیگنال خرید (1) و اگر نزولی باشد سیگنال خروج (0) صادر شود.
کد کامل پایتون با دیتای واقعی و زنده بازار سهام
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# ------------------------------------------
# گام ۱: شبیهسازی ساختار دیتای واقعی سهام مایکروسافت (MSFT)
# ------------------------------------------
np.random.seed(42)
days = 250
ma_short = 100 + np.cumsum(np.random.normal(0, 1.5, days))
ma_long = ma_short * 0.98 + np.random.normal(0, 2, days)
rsi = np.clip(50 + np.random.normal(0, 10, days), 10, 90)
volatility = np.abs(np.random.normal(1.5, 0.5, days))
df_stock = pd.DataFrame({
'MA_Gap': ma_short - ma_long,
'RSI': rsi,
'Volatility': volatility
})
df_stock['Target'] = np.where(df_stock['MA_Gap'].shift(-1) > df_stock['MA_Gap'], 1, 0)
df_stock.dropna(inplace=True)
X = df_stock[['MA_Gap', 'RSI', 'Volatility']]
y = df_stock['Target']
# ------------------------------------------
# گام ۲ و ۳: آمادهسازی دادهها و استانداردسازی
# ------------------------------------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ------------------------------------------
# گام ۴: آموزش مدل SVM با حاشیه نرم (Soft Margin)
# ------------------------------------------
financial_svm = SVC(kernel='rbf', C=0.5, gamma='scale', random_state=42)
financial_svm.fit(X_train_scaled, y_train)
y_pred = financial_svm.predict(X_test_scaled)
# ------------------------------------------
# گام ۵: ارزیابی خروجیهای مالی
# ------------------------------------------
acc_score = accuracy_score(y_test, y_pred)
print(\n============= FINANCIAL STOCK RESULTS =============)
print(fDirectional Accuracy Score: {acc_score * 100:.2f}%)
print(===================================================)
# ------------------------------------------
# گام ۶: تصویرسازی تجمعی سیگنالهای پیشبینی شده (پالت اختصاصی)
# ------------------------------------------
plt.figure(figsize=(10, 5))
plt.plot(range(len(y_test)), X_test['MA_Gap'], color=COLOR_SILVER, lw=2, label='Stock Technical Trend')
# رفع خطا: استفاده از فیلتر مستقیم به جای iloc برای ماسکهای منطقی
predicted_buy_correct = (y_pred == 1) & (y_test.values == 1)
plt.scatter(np.where(predicted_buy_correct)[0], X_test['MA_Gap'][predicted_buy_correct.values if hasattr(predicted_buy_correct, 'values') else predicted_buy_correct],
color=COLOR_GOLD, edgecolors='black', s=70, marker='^', label='Correct Buy Signal')
predicted_sell = (y_pred == 0)
plt.scatter(np.where(predicted_sell)[0], X_test['MA_Gap'][predicted_sell],
color=COLOR_CRIMSON, edgecolors='black', s=70, marker='v', label='Exit/Short Signal')
plt.title('Stock Market Trend Prediction & Strategy using SVM', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
plt.xlabel('Trading Days (Test Period)', fontsize=12)
plt.ylabel('Technical Indicator Scale', fontsize=12)
plt.grid(True, color=COLOR_WHITE)
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()خروجی:
12. کاربردهای واقعی و صنعتی ماشین بردار پشتیبان (SVM)
الگوریتم ماشین بردار پشتیبان (SVM) به دلیل هندسه مستحکم و توانایی بالا در مدیریت دادههای ابعاد بالا و غیرخطی، به عنوان یک ابزار استراتژیک در صنایع پیشرفته شناخته میشود. در ادامه، مهمترین کاربردهای واقعی این الگوریتم را واکاوی میکنیم:
.
a. بیوانفورماتیک و تشخیصهای پزشکی
یکی از درخشانترین کاربردهای SVM در تحلیل دادههای ژنتیکی و پزشکی است.
- دستهبندی تومورها: SVM با استفاده از فاکتورهای سلولی، تومورها را به دو دسته خوشخیم و بدخیم تقسیم میکند.
- تحلیل دادههای مایکروری (Microarray): در ژنتیک، تعداد ویژگیها (ژنها) بسیار بیشتر از نمونههاست (p > n). پایداری ریاضی SVM در فضاهای ابعاد بالا، آن را به ابزار استاندارد شناسایی الگوهای بیماری و ژنهای هدف تبدیل کرده است.
.
b. پردازش زبان طبیعی (NLP) و دستهبندی متن
متنها پس از تبدیل به بردار، فضایی به شدت تنک (Sparse) و با ابعاد میلیونی ایجاد میکنند که تفکیک آنها کار دشواری است.
- تشخیص هرزنامه (Spam Detection): سیستمهای فیلترینگ ایمیل با استفاده از Linear SVM پیامهای اسپم را با سرعت بالا تفکیک میکنند.
- تحلیل حس و عواطف (Sentiment Analysis): شرکتها برای بررسی بازخورد مشتریان در شبکههای اجتماعی و تفکیک نظرات به مثبت و منفی از این الگوریتم بهره میبرند.
.
c. بینایی ماشین و تشخیص تصویر (Computer Vision)
هرچند امروزه شبکههای عصبی عمیق (CNN) در تصویر پیشتازند، اما SVM همچنان یک ارزیاب و دستهبندیکننده نهاییِ سریع و پایدار است.
- تشخیص دستخط و ارقام (OCR): بازخوانی خودکار مبالغ چکهای بانکی و کدهای پستی.
- تشخیص چهره (Face Detection): بخشبندی قسمتهای مختلف تصویر برای تایید هویت کاربران بر اساس مرزهای حاشیه امن.
.
d. یادگیری ماشین مالی (Financial ML) و پایش سیستمها
- کشف کلاهبرداری (Fraud Detection): بانکها برای تحلیل همزمان رفتار تراکنشی کاربران و تفکیک رفتارهای هنجار از ناهنجار (تراکنشهای مشکوک) از حاشیه نرم SVM استفاده میکنند.
.
13. مزایای کلیدی الگوریتم ماشین بردار پشتیبان (SVM)
- کارایی بالا در فضاهای ابعاد بالا: SVM در دیتابیسهایی که تعداد ویژگیهای آنها (Features) بسیار زیاد است، فوقالعاده پایدار عمل میکند و حتی اگر تعداد ویژگیها از تعداد نمونهها بیشتر باشد (p > n)، کارایی خود را حفظ میکند.
- مقاومت در برابر بیشبرازش (Overfitting): به دلیل استفاده از رویکرد حداکثر حاشیه امن (Maximum Margin)، این مدل کمتر مستعد اورفیت شدن است؛ زیرا مرز تصمیمگیری را فقط بر اساس بردارهای پشتیبان تنظیم میکند، نه تکتک نویزهای دادهها.
- انعطافپذیری فوقالعاده با ترفند کرنل (Kernel Trick): با پکیج متنوعی از توابع نگاشت (مانند RBF، خطی و چندجملهای)، SVM میتواند پیچیدهترین الگوهای غیرخطی و درهمتنیده را به سادگی تفکیک کند.
- پایداری ریاضی و پاسخ یکتا (Convex Optimization): برخلاف شبکههای عصبی که ممکن است در مینیممهای محلی (Local Minima) گرفتار شوند، تابع هزینه SVM یک مسئله بهینهسازی محدب ثانویه است که همیشه به یک جواب بهینه سراسری (Global Optimum) و یکتا ختم میشود.
- تنوع در کاربرد: این الگوریتم با تغییر جزئی در تابع هدف، هم برای مسائل طبقهبندی پیچیده (SVC) و هم برای پیشبینیهای رگرسیونی (SVR) کارایی بالایی ارائه میدهد.
.
14.معایب
- حساسیت شدید به مقیاس دادهها (Feature Scaling): محاسبات SVM کاملاً مبتنی بر فواصل هندسی است. اگر ویژگیها مقیاس یکسانی نداشته باشند، ویژگیهای با اعداد بزرگتر، مرز تصمیمگیری را مخدوش میکنند؛ بنابراین پیش-پردازش دقیق با ابزارهایی مثل StandardScaler همیشه الزامی است.
- سرعت پایین و مصرف بالای حافظه در دادههای بزرگ: پیچیدگی زمانی الگوریتم SVM در حین آموزش بین O(n^2) تا O(n^3) است (n تعداد نمونههاست). این یعنی برای دیتابیسهای کلان (Big Data) با صدها هزار نمونه، فرآیند آموزش بسیار کند شده و حافظه RAM سیستم را به شدت اشغال میکند.
- عدم ارائه مستقیم احتمالات (Non-probabilistic): خروجی استاندارد SVM، یک برچسب قطعی (مثلاً 1+ یا 1-) بر اساس موقعیت نقطه نسبت به ابرصفحه است و برخلاف رگرسیون لوجستیک، میزان احتمال (Probability) تعلق به یک کلاس را نشان نمیدهد. برای استخراج احتمالات، باید از روشهای جانبی و سنگین مانند کالیبراسیون پلات (Platt Scaling) استفاده کرد.
- حساسیت بالا به نویز و دادههای پرت (Outliers): در محیطهای شلوغ و نویزی، مرزهای حاشیه امن SVM به شدت تحت تاثیر نقاط پرت قرار میگیرند. حتی در حالت حاشیه نرم (Soft Margin)، تنظیم نادرست پارامتر جریمه (C) میتواند مدل را به سادگی دچار بیشبرازش (Overfitting) یا کمبرازش (Underfitting) کند.
.
جمع بندی
ماشین بردار پشتیبان الگوریتمی است که با تمرکز بر یافتن ابرصفحهای بهینه و حداکثر حاشیه، امکان دستهبندی و پیشبینی دقیق دادهها را فراهم میکند. همانطور که مشاهده شد، استفاده از کرنلها قابلیت SVM را برای تفکیک دادههای غیرخطی افزایش میدهد و روشهای Soft Margin و Hard Margin امکان مدیریت نویز و تعادل میان خطا و تعمیم را فراهم میکنند.
SVM مزایای متعددی از جمله دقت بالا، تفسیرپذیری مناسب و توانایی مقابله با دادههای پیچیده دارد، اما محدودیتهایی نیز وجود دارد؛ از جمله حساسیت به مقیاس ویژگیها، پیچیدگی محاسباتی در مجموعه دادههای بزرگ و نیاز به انتخاب دقیق کرنل و پارامترها.
با وجود این چالشها، SVM همچنان یکی از الگوریتمهای اصلی در حوزههای مختلف صنعتی و تحقیقاتی است. از تشخیص پزشکی و امنیت سایبری گرفته تا تحلیل مالی و بینایی ماشین، این الگوریتم به عنوان یک ابزار استاندارد برای مدلسازی دادههای پیچیده و تصمیمگیری مبتنی بر داده به کار گرفته میشود و نقش مهمی در توسعه سیستمهای هوشمند دارد.



