

1.مقدمه
الگوریتم K-Medoids یکی از روشهای مهم خوشهبندی در یادگیری بدون نظارت است که با هدف گروهبندی دادههای مشابه و انتخاب نمایندهای واقعی برای هر خوشه طراحی شده است. برخلاف K-Means که مرکز هر خوشه را بر اساس میانگین نقاط تعیین میکند، K-Medoids یک نمونه واقعی از دادهها را بهعنوان مرکز خوشه یا Medoid انتخاب میکند. این ویژگی باعث میشود الگوریتم در برابر دادههای پرت و نویز مقاومتر باشد و در بسیاری از مسائل واقعی عملکرد پایدارتری ارائه دهد.
K-Medoids در حوزههایی مانند تحلیل مشتریان، بیوانفورماتیک، سیستمهای توصیهگر، امنیت سایبری و پردازش دادههای پیچیده کاربرد گستردهای دارد. همچنین توانایی استفاده از انواع معیارهای فاصله، این الگوریتم را به گزینهای مناسب برای دادههایی تبدیل کرده است که مفهوم میانگین در آنها معنا یا کارایی مناسبی ندارد.
در این مقاله، سازوکار الگوریتم K-Medoids، تفاوت آن با K-Means، معیارهای فاصله، مزایا و محدودیتها، کاربردهای عملی و مسیر توسعه این الگوریتم را بررسی میکنیم تا درک جامعی از یکی از مهمترین روشهای خوشهبندی مقاوم در برابر نویز به دست آوریم.
2.تعریف
الگوریتم K-Medoids که در متون مرجع علم داده با عنوان PAM (Partitioning Around Medoids) نیز شناخته میشود، یک الگوریتم خوشهبندی مبتنی بر افراز (Partition-based Clustering) در حوزه یادگیری بدون نظارت است که اولین بار توسط دانشمندان برجسته، کافمن (Kaufman) و روسیو (Rousseeuw) معرفی شد.
این الگوریتم از نظر ساختار تکرارشونده شباهت ساختاری بالایی با الگوریتم معروف K-Means دارد، اما از یک مزیت استراتژیک برخوردار است: مقاومت بسیار بالا در برابر دادههای پرت. (Robustness to Outliers)
در مکانیزم خط لوله K-Means، مرکز هر خوشه بر اساس میانگین حسابی (Mean) نقاط محاسبه میشود؛ این میانگین یک نقطه انتزاعی و فرضی در فضا است که در صورت وجود نویز یا دادههای پرت، به شدت دچار انحرافِ هندسی میشود. در مقابل، الگوریتم K-Medoids این بنبست را با یک منطق صلب حل میکند؛ این مدل مأمور است تا یک نقطه داده واقعی و موجود در خود مجموعه داده را که کمترین میزان عدم شباهت (Dissimilarity) را نسبت به سایر اعضای کلاستر دارد، به عنوان نماینده یا مدوید (Medoid) انتخاب کند.
مدوید (Medoid) چیست؟
یک مدوید، مرکزیترین نقطه داده واقعی مستقر در یک خوشه (کلاستر) است. این نقطه بر اساس یک قید ریاضی انتخاب میشود تا مجموع کل عدم شباهتها (Total Dissimilarity) را نسبت به سایر نقاط موجود در آن خوشه به حداقل برساند. میزان عدم شباهت بین یک مدوید (Ci) و یک شیء داده (Pi) با فرمول خطی زیر محاسبه میشود:
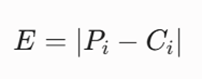
معرفی متغیرها:
- E: میزان هزینه یا تفاضل مطلق عدم شباهت میان نقطه داده و مرکز خوشه.
- Pi: بردار ویژگیهای مربوط به نقطه داده iام درون خوشه.
- Ci: بردار ویژگیهای مربوط به مدوید (نقطه واقعی شاخص) همان خوشه.
.
مثال
برای درک تفاوت بنیادین این دو ساختار، فرض کنید میخواهیم مرکز جغرافیایی یک کلاس درس را برای استقرار میز استاد تعیین کنیم:
- رویکرد K-Means (میانگین فرضی): مختصات جغرافیایی تکتک دانشآموزان را جمع کرده و میانگین میگیرد. نقطه حاصل ممکن است دقیقاً در فضای خالی بین میزها یا وسط راهرو بیفتد (یک نقطه فرضی که هیچ دانشآموزی آنجا ننشسته است). حال اگر یک دانشآموز به عنوان داده پرت، ته کلاس و با فاصله بسیار زیاد از بقیه بنشیند، میانگین فضا به شدت به سمت او کشیده میشود و مرکز اصلی کلاستر منحرف خواهد شد.
- رویکرد K-Medoids (نقطه واقعی): الگوریتم دیتابیس را بررسی کرده و خودِ یکی از دانشآموزان را که در متراکمترین و مرکزیترین بخش کلاس نشسته است، به عنوان نماینده و مرکز خوشه انتخاب میکند. در این حالت، حتی اگر یک دانشآموز در دورترین نقطه کلاس بنشیند، انتخاب نماینده اصلی تغییر نمیکند؛ زیرا او همچنان یک داده پرت است و میزان عدم شباهت کل سیستم با انتخاب او به عنوان مرکز، به شدت افزایش مییابد. در نتیجه، مدل در برابر نویز کاملاً مصون میماند.
.
۳. مقایسه K-Means و K-Medoids
در حوزه یادگیری ماشین بدون نظارت، فرآیند افراز صلب دادهها عمدتاً حول دو محور پایداری محاسباتی یا سرعت ترابری داده میچرخد. برای درک عمیق تمایزهای ساختاری این دو الگوریتم، خطوط لوله محاسباتی آنها بر اساس ۵ متریک حیاتی بررسی شدهاند:
- نماینده خوشه: سنتروید در برابر مدوید (Centroid vs. Medoid)
- پایداری در مواجهه با نویز (Sensitivity to Outliers)
- متریکها و توابع سنجش فاصله (Distance Measures)
- پیچیدگی و بار محاسباتی (Computational Complexity)
- پدیده همگرایی و بهینه سراسری (Convergence)
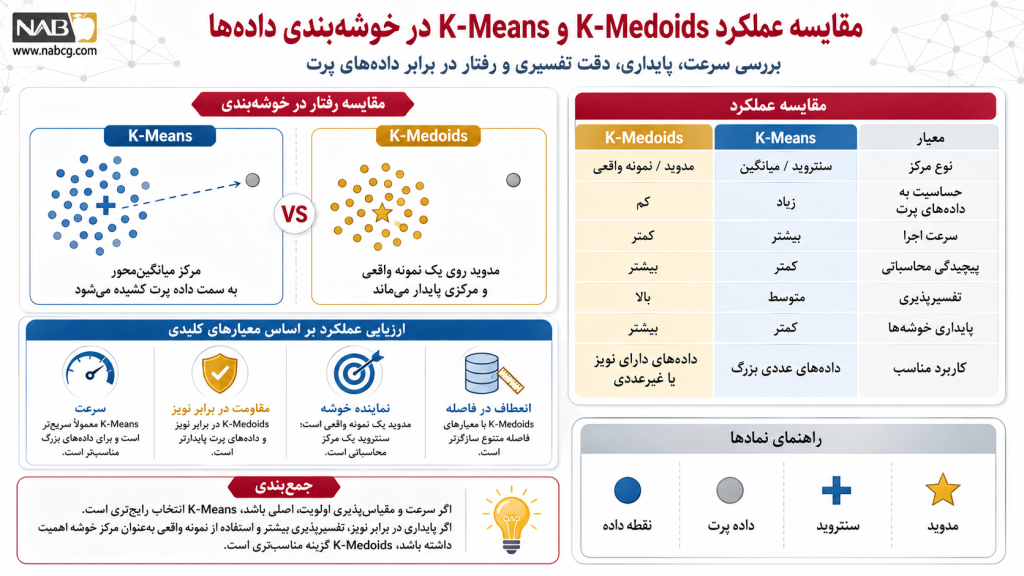
نماینده خوشه: سنتروید در برابر مدوید (Centroid vs. Medoid)
- K-Means: قطب مرکز خوشه را به عنوان سنتروید (Centroid) تعریف میکند که حاصل میانگین حسابی مختصات تمام نقاط آن کلاستر است. این مرکز، نقطه خطی انتزاعی و فرضی است و لزوماً معادل یک داده واقعی در دیتابیس نیست.
- K-Medoids: قطب مرکز را مستقیماً از میان دادههای واقعی و موجود در دیتابیس (Medoid) انتخاب میکند. مدوید نقطهای است که مجموع عدم شباهت و فاصله آن با سایر اعضای خوشه کمترین مقدار ممکن باشد؛ این ویژگی تفسیرپذیری مدل را به شدت افزایش میدهد.
.
پایداری در مواجهه با نویز (Sensitivity to Outliers)
- K-Means: به شدت در برابر دادههای پرت (Outliers) آسیبپذیر است. از آنجا که این مدل بر پایه تابع میانگین حرکت میکند، حضور حتی یک داده ناهنجار شدید، مرکز خوشه را به سمت خود کشیده و مرزهای ورونوی سیستم را دچار انحرافِ هندسی میکند.
- K-Medoids: فوقالعاده در برابر نویز و دادههای پرت مقاوم (Robust) است. انتخاب یک عضو واقعی و مرکزی به عنوان مدوید، تضمین میکند که دادههای منزوی و حاشیهای تأثیری روی پایداری قطب کلاستر نخواهند داشت.
.
متریکها و توابع سنجش فاصله (Distance Measures)
- K-Means: به طور پیشفرض اسیر و مقید به فاصله اقلیدسی (Euclidean Distance) است تا بتواند واریانس درونخوشهای (Inertia) را کمینه کند. این امر استفاده از دادههای کیفی را ناممکن میسازد.
- K-Medoids: انعطافپذیری بالایی دارد و میتواند با هر نوع تابع عدم شباهت دلخواه (مانند فاصله منهتن، جاکارد یا کسینوسی) پیکربندی شود؛ این انعطاف، خوشهبندی دادههای غیرعددی و دستهای (Categorical) را میسر میسازد.
.
پیچیدگی و بار محاسباتی (Computational Complexity)
- K-Means: بسیار چابک، سبک و سریع است. مرتبه زمانی خطی آن O(t . K . n) پتانسیل بالایی برای پردازش کلاندادهها (Big Data) و دیتابیسهای فوقالعاده بزرگ دارد.
- K-Medoids: به شدت مصرفکننده منابع محاسباتی (Computationally Intensive) است. فرآیند ارزیابی و جایگزینی مداوم نقاط غیرمدوید در فاز جابهجایی (Swap)، مرتبه محاسباتی سنگین O(t . K . (n-K)^2) را تحمیل میکند که آن را برای دادههای بزرگ کند میسازد.
.
پدیده همگرایی و بهینه سراسری (Convergence)
- K-Means: سرعت همگرایی بسیار بالایی دارد اما به دلیل ماهیت حریصانه، احتمال سقوط آن در تله کمینههای محلی (Local Minima) بالا است.
- K-Medoids: هرچند هزینه محاسباتی بالاتری دارد، اما در فاز تکرار بهینهسازی، شانس بسیار بیشتری برای فرار از کمینههای محلی و یافتن بهینه سراسری (Global Optimum) دارا است.
.
4.دلایل اهمیت و ضرورت بهکارگیری الگوریتم K-Medoids
در توسعه خط لولههای پیشرفته داده (Data Pipelines) و الگوریتمهای یادگیری ماشین، انتخاب مدل خوشهبندی ارتباط مستقیمی با پایداری سیستم دارد. الگوریتم K-Medoids (یا همان PAM) صرفاً یک گزینه جایگزین برای K-Means نیست؛ بلکه یک ضرورت استراتژیک برای مهار چالشهایی است که مدلهای مرکزثقلمحور سنتی را به زانو درمیآورند.
دلایل کلیدی اهمیت و ضرورت استفاده از این الگوریتم در فرآیندهای صنعتی عبارتند از:
- مصونسازی مدل در برابر «دادههای کثیف» و تاریک: در دیتابیسهای واقعی، حضور نویزها و دادههای پرت (Outliers) اجتنابناپذیر است. الگوریتم K-Means با محاسبه میانگین حسابی، مرکز خوشه را به شدت تحت تاثیر دادههای گسیخته قرار میدهد و مرزبندیها را منحرف میکند K-Medoids. با انتخاب یک نقطه داده واقعی به عنوان نماینده، اثر نویزها را به طور کامل خنثی کرده و ثبات ساختاری خوشهها را تضمین میکند.
- آزادی عمل در انتخاب متریکهای ریاضی عدم شباهت: الگوریتم K-Means ذاتاً اسیر و مقید به فاصله اقلیدسی است. اما در سناریوهای واقعی مهندسی داده، بسیاری از ویژگیها فراتر از اعداد پیوسته خطی هستند. K-Medoids به طراحان این امکان را میدهد که از هر نوع تابع عدم شباهت دلخواه (مانند فاصله منهتن، جاکارد یا کسینوسی) استفاده کنند.
- امکان خوشهبندی دادههای غیرعددی و کیفی (Categorical Data): هنگامی که با دادههای متنی، گرافها، توالیهای ژنتیکی یا ویژگیهای دستهای روبهرو هستیم، مفهوم «میانگین» ریاضی کاملاً بیمعناست (مثلاً میانگین دو کلمه یا دو گروه خونی وجود خارجی ندارد). ضرورت استفاده از K-Medoids در اینجا آشکار میشود؛ چرا که این الگوریتم با تکیه بر «یک شیء واقعی موجود در دیتابیس» به عنوان هسته مرکزی، امکان خوشهبندی صلب را برای ساختارهای غیرعددی فراهم میسازد.
.
۵. نحوه کارکرد و خط لوله محاسباتی الگوریتم K-Medoids
الگوریتم K-Medoids (بهویژه پیادهسازی مرجع آن یعنی معماری PAM) از یک فرآیند تکرارشونده و حریصانه (Greedy Heuristic) برای افراز صلب فضای ویژگیها استفاده میکند. این خط لوله عملیاتی تضمین میکند که آرایش خوشهها در هر گام به سمت یک وضعیت پایدار هندسی حرکت کند.
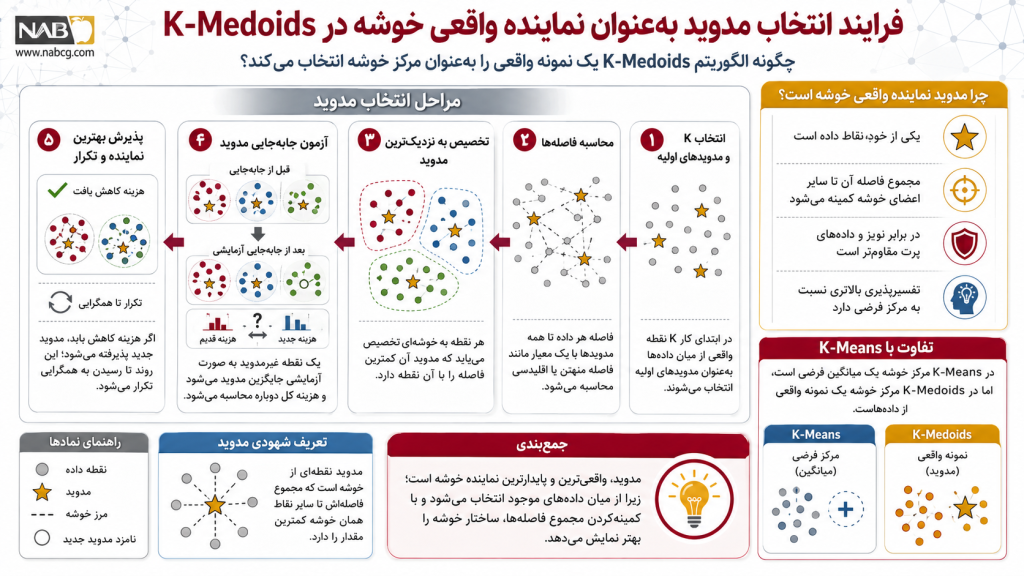
گامهای چهارگانه عملیاتی الگوریتم
گام اول: مقداردهی اولیه (Initialization)
در ابتدای فرآیند، هایپرپارامتر K (تعداد خوشههای مورد نیاز) توسط طراح مشخص میشود. سپس الگوریتم به صورت تصادفی، تعداد K نقطه داده واقعی را از درون خود دیتابیس انتخاب کرده و آنها را به عنوان مدویدهای اولیه (Initial Medoids) در فضا مستقر میکند. این نقاط به عنوان قطبها و نمایندگان اصلی خوشهها در تکرار اول عمل میکنند.
گام دوم: تخصیص صلب نقاط (Point Assignment)
با استفاده از یک متریک سنجش فاصله مشخص (مانند فاصله منهتن یا اقلیدسی)، فاصله هندسی تکتک نقاط داده غیرمدوید باقیمانده در دیتابیس تا تمام K مدوید مستقر در فضا محاسبه میشود. هر نقطه داده بر اساس اصل کمینهسازی فاصله، به صلبترین شکل ممکن به نزدیکترین مدوید متصل شده و بدنه کلاسترهای اولیه را تشکیل میدهد.
گام سوم: فاز جایگزینی و بیشینهسازی (Update Step / Swap)
این مرحله هسته هوشمند الگوریتم K-Medoids است که پایداری آن را در برابر نویز تضمین میکند. مدل برای ارتقای کیفیت کلاسترها، یک فرآیند تبادل آزمایشی را طبق پروتکل زیر پیش میگیرد:
- الگوریتم به صورت فرضی، جایگاه یکی از مدویدهای فعلی (m) را با یکی از نقاط داده غیرمدوید (o) تعویض (Swap) میکند.
- تابع هزینه و اعوجاج کل سیستم برای این پیکربندی جدید مجدداً محاسبه میشود.
- میزان تغییرات هزینه سنجیده میشود:
- اگر تعویض فرضی باعث کاهش هزینه کل سیستم شود، این جایگزینی رسماً تایید شده و نقطه o به عنوان مدوید جدید جایگزین m میشود.
- اگر جایگزینی باعث افزایش یا ثبات هزینه شود، تعویض رد شده و سیستم به آرایش پایدار قبلی بازمیگردد.
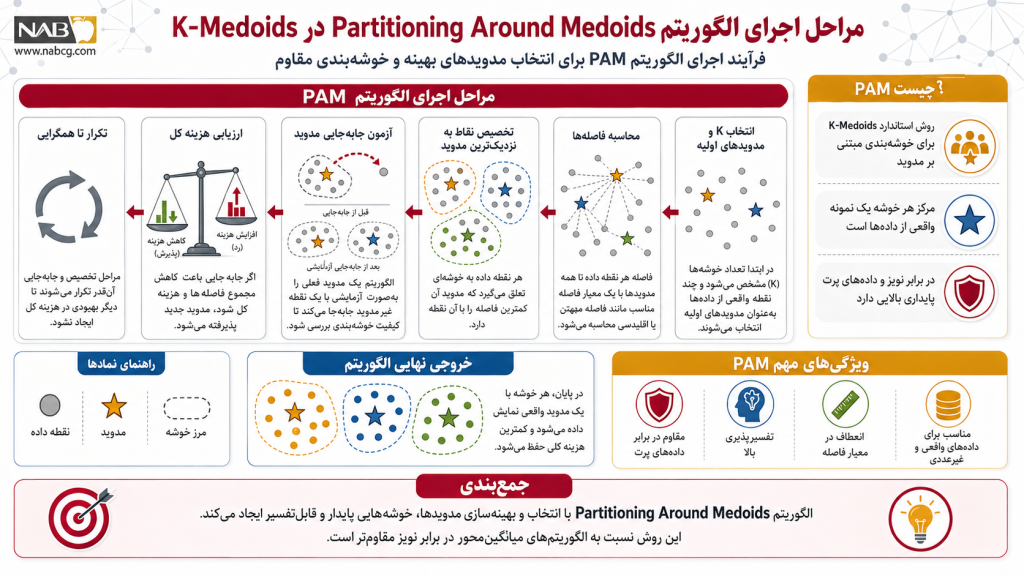
گام چهارم: تکرار و تست همگرایی
چرخه گام دوم و سوم (تخصیص مجدد نقاط و فاز تبادل مدویدها) آنقدر تکرار میشود تا مدل به همگرایی کامل (Convergence) برسد؛ یعنی هیچ جابهجایی و تعویض دیگری در فضا نتواند تابع هزینه کل سیستم را کاهش دهد.
۶. مبانی ریاضی و تئوری بهینهسازی
برخلاف K-Means که بر پایه کمینهسازی خطای مربعات درونخوشهای (Inertia) استوار است، الگوریتم K-Medoids بر پایه کمینهسازی مجموع مطلق عدم شباهتها (Total Dissimilarity) طراحی شده است. از آنجا که این تابع به جای توان دوم فواصل، بر خطای مطلق استوار است، به طور ذاتی اثر دادههای پرت و نویزها را مهار میکند.
فرمولاسیون تابع هدف اصلی (Objective Function)
معادله محاسباتی کلانی که مدل در طول فاز آموزش مأمور به بهینهسازی و کمینهسازی هندسی آن است، به صورت زیر فرمولهبندی میشود:
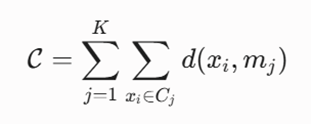
معرفی متغیرها:
- C: مقدار کل هزینه، میزان اعوجاج یا عدم شباهت کل (Total Cost / Dissimilarity) در کل سیستم دادهها که الگوریتم باید آن را به حداقل برساند.
- K: هایپرپارامتر مقتدر تعداد خوشههای متمایز و مجزا در فضای ویژگیها.
- j: شاخص شمارنده خوشهها که گامبهگام از عدد 1 تا K حرکت میکند.
- Cj: قلمرو و مجموعه نقاط دادهای که بر اساس کمترین فاصله، به خوشه jام تخصیص یافتهاند.
- xi: بردار ویژگیهای مربوط به نقطه داده iام که در حال حاضر عضو خوشه Cj است.
- mj: بردار ویژگیهای مدوید رسمی (یک شیء واقعی و موجود در خود دیتابیس) که به عنوان مرکز ثقل پایدار خوشه Cj انتخاب شده است.
- d(xi, mj): تابع یا متریک ریاضی سنجش میزان فاصله و عدم شباهت میان نقطه داده واقعی xi و مدوید. mj
.
متریکهای فاصله و هندسه فضا (Distance Metrics)
انعطافپذیری ریاضی K-Medoids به طراح این اجازه را میدهد که بر اساس ساختار دادهها، یکی از متریکهای زیر را برای محاسبه تابع فاصله یعنی d(xi, mj) اعمال کند:
الف) فاصله منهتن (Manhattan Distance – L1Norm)
بهترین و مقاومترین گزینه در برابر دادههای پرت است که به صورت مجموع مطلق تفاضل مختصات هندسی تعریف میشود:
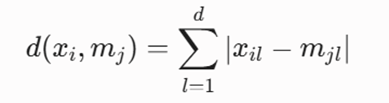
معرفی متغیرها:
- d: تعداد کل ابعاد یا ویژگیهای (Features) موجود در بردار داده.
- l: شاخص شمارنده ابعاد ویژگیها که از بعد 1 تا بعد نهایی d تغییر میکند.
- xil: مقدار ویژگی در بعد lام برای نقطه داده iام.
- mjl: مقدار ویژگی در بعد lام برای مدوید (مرکز خوشه) jام.
.
ب) فاصله اقلیدسی (Euclidean Distance – L2Norm)
فاصله مستقیم هندسی بین دو نقطه در فضای کمبعدی پیوسته:
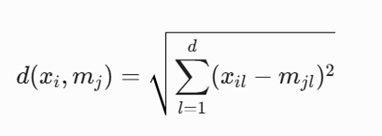
معرفی متغیرها:
- d: تعداد کل ابعاد یا ویژگیهای موجود در بردار ویژگی دیتابیس.
- l: شاخص شمارنده لایههای ابعاد داده از 1 تا. d
- mjl: مؤلفه عددی بعد lام برای بردار مدوید jام.
.
ج) فاصله کسینوسی (Cosine Distance)
برای دادههای ابعاد بالا مانند پردازش زبان طبیعی (NLP) که زاویه بین بردارها اهمیت بیشتری نسبت به طول هندسی آنها دارد:
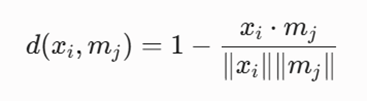
معرفی متغیرها:
- xi .mj: حاصلضرب داخلی (Dot Product) بردار داده xi در بردار مدویدmj.
- ||xi||: طول یا نرم اقلیدسی (Magnitude) بردار داده xi.
- ||mj||: طول یا نرم اقلیدسی بردار مدوید mj .
.
منطق محاسباتی هزینه جابهجایی (Swap Cost Analytics)
در فاز بهینهسازی و جابهجایی، به ازای هر تعویض فرضی بین مدوید فعلی m و نقطه غیرمدوید o، تغییر هزینه کل سیستم (ΔC) محاسبه میشود:
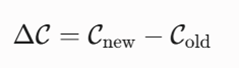
معرفی متغیرها:
- ΔC: میزان تغییرات تابع هزینه کل سیستم پس از اعمال جابهجایی آزمایشی.
- Cnew: هزینه کل سیستم در صورتی که نقطه غیرمدوید فرضی جایگزین مدوید فعلی شود.
- Cold: هزینه کل سیستم با آرایش و مدویدهای فعلی قبل از انجام هرگونه جابهجایی.
الگوریتم بر اساس علامت خروجی تفاضل ΔC به صورت حریصانه تصمیمگیری صلب میکند:
- اگر ΔC < 0: جایگزینی فرضی سبب کاهش خطای سیستم شده است؛ تعویض تایید میشود (mupdated = o).
- اگر ΔC ≥ 0: تعویض فرضی آرایش فضا را بدتر کرده است؛ ساختار بدون تغییر حفظ میشود.
.
7. مثال
مثال ۱: سطح پایه (یکبعدی) – مدیریت زنجیره تأمین و هاب توزیع کالا
مسئله: یک شرکت پخش کالا میخواهد از بین ۴ فروشگاه تحت پوشش خود در یک اتوبان خطی، ۱ انبار مرکزی (K=1) احداث کند. مختصات مکانی این فروشگاهها روی محور خروجی اتوبان عبارت است از:
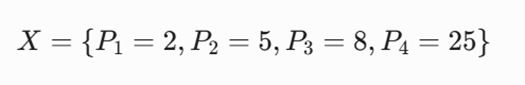
نقطه P4=25 یک داده پرت (Outlier) است. با استفاده از الگوریتم K-Medoids و متریک فاصله مطلق خطی، مکان بهینه انبار را بیابید و نشان دهید چرا این مدل نسبت به K-Means پایدارتر است.
حل گامبهگام با فرمول:
-گام اول: فرمولهسازی تابع هدف تابع هزینه بر اساس فرمول مجموع مطلق عدم شباهت تعریف میشود:
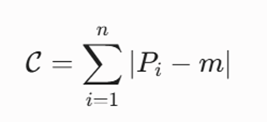
که در آن m مدوید انتخابی (که باید حتماً یکی از نقاط واقعی P1 تا P4 باشد) و Pi نقاط فروشگاهها هستند.
-گام دوم: ارزیابی تکتک کاندیداها به عنوان مدوید (بررسی هزینه) چون K=1 است، تکتک نقاط داده واقعی را به عنوان مرکز فرضی تست میکنیم تا نقطهای با کمترین هزینه کل انتخاب شود:
- اگر m = P1 = 2 باشد:
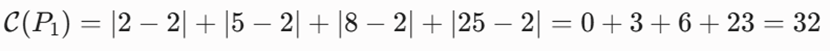
- اگر m = P2 = 5 باشد:
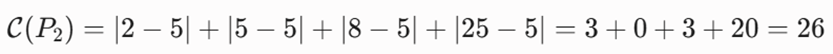
- اگر m = P3 = 8 باشد:
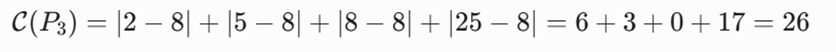
- اگر m = P4 = 25 باشد:
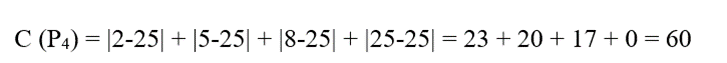
-گام سوم: تحلیل کمینه و همگرایی کمترین هزینه کل برابر با ۲۶ است که به ازای انتخاب نقطه P2=5 یا P3=8 حاصل میشود. الگوریتم به صورت پیشفرض اولین نقطه با کمترین خطای پایدار یعنی m = P2 = 5 را به عنوان مدوید نهایی انتخاب میکند.
تحلیل :اگر از الگوریتم K-Means استفاده میشد، مرکز برابر با میانگین حسابی یعنی 2+5+8+25/4 = 10 به دست میآمد. عدد ۱۰ تحت تاثیر شدید داده پرت (۲۵) قرار گرفته و در نقطهای دور از تمرکز اصلی فروشگاهها قرار میگیرد، اما مدوید روی نقطه واقعی و پایدار ۵ مستقر شد.
مثال ۲: سطح متوسط (دوعددی) – بخشبندی رفتار خرید مشتریان
مسئله: مختصات خرید دو ویژگی (تعداد خرید در ماه، میانگین مبلغ خرید) برای ۵ مشتری به صورت برداری زیر در دیتابیس ثبت شده است:
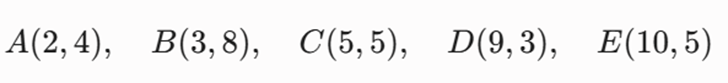
فرض کنید هایپرپارامتر تعداد خوشهها K=2 است. اگر در گام مقداردهی اولیه، نقاط A و B به عنوان مدویدهای اولیه انتخاب شوند ، با استفاده از فاصله منهتن (L1Norm)، فاز تخصیص نقاط و هزینه کل این آرایش را محاسبه کنید.
حل گامبهگام با فرمول:
-گام اول: فرمول فاصله منهتن
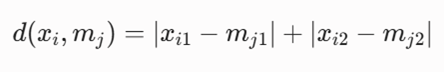
در این ساختار، مدویدهای اولیه ما m1 = A(2, 4) و m2 = B(3, 8) هستند.
-گام دوم: محاسبه فاصله نقاط غیرمدوید (C, D, E) تا مراکز
- بررسی وضعیت نقطه C(5, 5)
- فاصله تا مدوید اول :
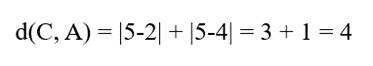
- فاصله تا مدوید دوم:
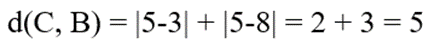
- نتیجه: چون 4 < 5 است، نقطه C به کلاستر مدوید A تخصیص مییابد.
- بررسی وضعیت نقطه D(9, 3)
- فاصله تا مدوید اول:
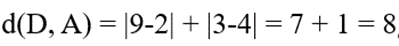
- فاصله تا مدوید دوم:
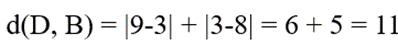
- نتیجه: چون 8 < 11 است، نقطه D به کلاستر مدوید A تخصیص مییابد.
- بررسی وضعیت نقطه E(10, 5)
- فاصله تا مدوید اول:
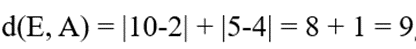
- فاصله تا مدوید دوم:
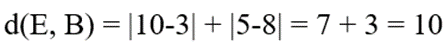
- نتیجه: چون 9 < 10 است، نقطه E به کلاستر مدوید A تخصیص مییابد.
-گام سوم: تشکیل خوشهها و محاسبه هزینه کل *(Cold) خوشه اول(C1) :شامل اعضای {A, C, D, E} با مرکزیت A.
- خوشه دوم (C2): شامل عضو {B} با مرکزیت B .
فرمول محاسبه تابع هزینه کل سیستم:
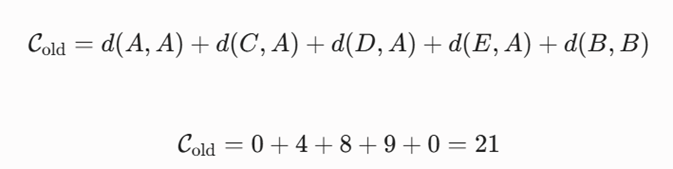
هزینه کل پیکربندی اولیه برابر با ۲۱ است.
مثال ۳: سطح پیشرفته (تحلیل جابهجایی) – مانیتورینگ سلامت شبکه
مسئله: با تکیه بر نتایج شبکه کلاسترینگ مثال ۲، آرایش خوشهها به صورت C1={A, C, D, E} با مدوید m1=A و C2={B} با مدوید m2=B است و هزینه کل معادل Cold = 21 به دست آمد. حال الگوریتم در لایه بهینهسازی (گام سوم – فاز Swap) میخواهد مدوید m1=A را با نقطه غیرمدوید C(5, 5) تعویض کند. تغییر هزینه کل سیستم (ΔC) را محاسبه کرده و مشخص کنید آیا الگوریتم این جابهجایی را میپذیرد یا خیر ؟
حل گامبهگام با فرمول:
– اول: پیکربندی فرضی جدید مدویدها مدویدهای جدید فرضی عبارتند از-: m1^* = C(5, 5) و m2 = B(3, 8).
-دوم: بازتخصیص تمام نقاط داده بر اساس مدویدهای جدید فرضی مجدداً با متریک فاصله منهتن، فاصله تکتک ۵ نقطه فضا را تا مراکز جدید (C و B) میسنجیم:
- نقطه A(2, 4)
- d (A, C) = |2-5| + |4-5| = 4
- d (A, B) = |2-3| + |4-8| = 5
- تخصیص: چون 4 < 5، عضو خوشه C میشود.
- نقطه B(3, 8): خود مدوید دوم است _ (فاصله = ۰)، عضو خوشه B.
- نقطه C(5, 5): خود مدوید اول فرضی است _ (فاصله = ۰)، عضو خوشهC .
- نقطه D(9, 3)
- d (D, C) = |9-5| + |3-5| = 4 + 2 = 6
- d (D, B) = |9-3| + |3-8| = 6 + 5 = 11
- تخصیص: چون 6 < 11، عضو خوشه C میشود.
- نقطه E(10, 5):
- d (E, C) = |10-5| + |5-5| = 5 + 0 = 5
- d (E, B) = |10-3| + |5-8| = 7 + 3 = 10
- تخصیص: چون 5 < 10، عضو خوشه C میشود.
– سوم: محاسبه هزینه ساختار جدید (Cnew)
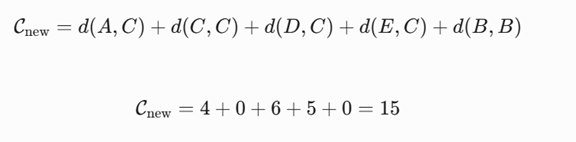
– چهارم: تحلیل ماتریس تفاضل خطای محاسباتی (ΔC) فرمول ارزیابی فاز تبادل حریصانه:
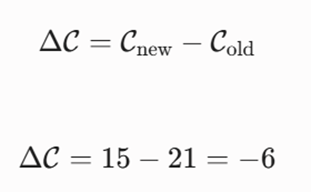
نتیجهگیری پایانی: چون ΔC = -6 < 0 است، این جابهجایی آزمایشی با موفقیت اعوجاج و خطای کل کل سیستم را کاهش داده است. بنابراین، الگوریتم K-Medoids به صورت صلب این جابهجایی را تایید (Accept) کرده، نقطه C رسماً جایگزین A به عنوان مدوید جدید کلاستر اول میشود و مدل به سمت تکرارهای بعدی هدایت میگردد.
8.ابزار ها و فریم ورک های محبوب الگوریتم K-Medoids
کتابخانه Scikit-Learn Extra (محبوبترین فریمورک استاندارد پایتون)
این فریمورک افزونه رسمی و بهینهشده سایکیت-لرن برای الگوریتمهای پیشرفته خوشهبندی است و از معماری صلب PAM استفاده میکند.
pip install scikit-learn-extra
!pip install "numpy<2" scikit-learn-extra
import numpy as np
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.datasets import make_blobs
# ۱. تولید دادههای فرضی نمونه (شبیهسازی دیتابیس)
X, _ = make_blobs(n_samples=100, centers=3, cluster_std=1.0, random_state=42)
# ۲. پیکربندی و آموزش مدل K-Medoids با متریک صلب منهتن و مقداردهی هوشمند (++k-medoids)
model = KMedoids(n_clusters=3, metric='manhattan', init='k-medoids++', random_state=42)
labels = model.fit_predict(X)
medoids = model.cluster_centers_
# ۳. تعریف دقیق پالت رنگی اختصاصی سایت شما
custom_colors = ['#D0021B', '#4A90E2', '#7F8C8D'] # زرشکی (Crimson)، آبی ملایم (AI Soft Blue)، خاکستری متالیک
active_gold = '#F5A623' # طلایی فعال برای نمایش مقتدرانه مدویدها
bg_ultra_light = '#F8F9FA' # خاکستری فوقسبک برای پسزمینه نمودار
# ۴. تصویرسازی تخصصی و هندسی خروجی الگوریتم
fig, ax = plt.subplots(figsize=(7, 5), facecolor=bg_ultra_light)
ax.set_facecolor(bg_ultra_light)
# رسم نقاط داده متعلق به هر کلاستر به صورت تفکیکشده
for cluster_idx in range(3):
ax.scatter(X[labels == cluster_idx, 0], X[labels == cluster_idx, 1],
c=custom_colors[cluster_idx], alpha=0.7, edgecolors='#FFFFFF', s=55,
label=f'Cluster {cluster_idx + 1}')
# رسم مدویدهای نهایی (نقاط داده واقعی و بهینه مرکز خوشه) با نماد X بزرگ و رنگ طلایی فعال
ax.scatter(medoids[:, 0], medoids[:, 1],
c=active_gold, marker='X', s=250, edgecolors='#000000', linewidths=1.5,
label='Optimized Medoids (Active Gold)')
# تنظیمات خوانایی، سئو و پارامترهای نمودار با لیبلهای انگلیسی
ax.set_title('Robust Space Partitioning via K-Medoids Architecture', fontsize=12, fontweight='bold', color='#212529')
ax.set_xlabel('Feature Vector Dimension 1', fontsize=10)
ax.set_ylabel('Feature Vector Dimension 2', fontsize=10)
ax.grid(True, linestyle='--', color='#E0E0E0', alpha=0.5)
ax.legend(loc='upper right', facecolor='#FFFFFF', edgecolor='#E0E0E0')
plt.tight_layout()
plt.show()
# چاپ خروجی متنی موفقیتآمیز در ترمینال
print("Model trained successfully.")
print(f"Final total dissimilarity cost (Inertia): {model.inertia_:.4f}")
خروجی:
کتابخانه PyClustering (قدرتمندترین ابزار برای کلاندادهها و مهندسی داده)
این فریمورک تخصصی متدهای بهینهشده فضا مانند PAM، CLARA و CLARANS را به همراه هسته پردازشی سریع C++ پیادهسازی میکند.
!pip install pyclustering
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from pyclustering.cluster.kmedoids import kmedoids
from pyclustering.cluster import cluster_visualizer
# ۱. تولید دادههای فرضی نمونه (شبیهسازی دیتابیس) instead of loading from pyclustering samples
X_pyclustering, _ = make_blobs(n_samples=150, centers=3, cluster_std=1.0, random_state=42)
# ۲. تعیین شاخص (Index) نقاط داده واقعی به عنوان مدویدهای اولیه (randomly pick 3 indices for 3 clusters)
np.random.seed(42) # for reproducibility
initial_medoids_indices = np.random.choice(len(X_pyclustering), 3, replace=False).tolist()
# ۳. مقداردهی و اجرای الگوریتم صلب پیکلسترینگ
kmedoids_instance = kmedoids(X_pyclustering.tolist(), initial_medoids_indices)
kmedoids_instance.process()
# ۴. استخراج خوشهها و مراکز ثقل نهایی
clusters = kmedoids_instance.get_clusters()
final_medoids_indices = kmedoids_instance.get_medoids()
# Convert medoid indices to actual points for plotting (for potential custom plotting later)
final_medoids = X_pyclustering[final_medoids_indices]
# ۵. تصویرسازی تخصصی با فریمورک داخلی ابزار
visualizer = cluster_visualizer()
visualizer.append_clusters(clusters, X_pyclustering)
# Removed: visualizer.append_points(final_medoids, marker='X', markersize=20, color='orange') # This method does not exist in pyclustering's cluster_visualizer
visualizer.show()
print(f"Model trained successfully with pyclustering.")
# pyclustering's kmedoids does not directly expose 'inertia_'.
# One could manually calculate total dissimilarity cost if needed.
خروجی:
9.پیاده سازی گام به گام الگوریتم K-Medoids در پایتون
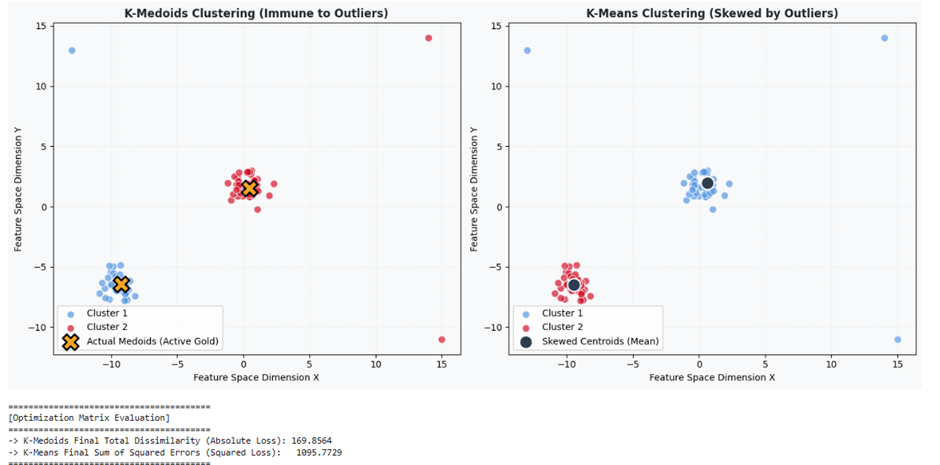
در این بخش، معماری الگوریتم K-Medoids را بر روی یک دیتابیس استاندارد آلوده به نویز پیادهسازی میکنیم. هدف این مطالعه موردی، مشاهده عینی مقاومت صلب K-Medoids در برابر دادههای پرت (Outliers) در مقایسه با انحراف شدید الگوریتم K-Means است.
- گام اول؛ تولید دیتابیس و تزریق دادههای پرت: ابتدا یک مجموعه داده متراکم با هندسه مشخص تولید کرده و سپس عمداً چند داده ناهنجار و پرت شدید (Outliers) به فضا تزریق میکنیم تا رفتار هر دو مدل را در شرایط آلوده بسنجیم.
- گام دوم؛ آموزش صلب مدل K-Medoids: با فراخوانی فریمورک sklearn_extra و تنظیم هایپرپارامتر متریک بر روی manhattan، مدل را مجبور میکنیم تا بر اساس خطای مطلق، مدویدهای واقعی را بدون تاثیرپذیری از نویزها بیابد.
- گام سوم؛ آموزش موازی مدل K-Means: الگوریتم K-Means را روی همین دادههای کثیف آموزش میدهیم تا انحراف سنترویدهای آن را تحت تاثیر دادههای پرت مشاهده کنیم.
- گام چهارم؛ تصویرسازی مقایسهای با پالت اختصاصی
کد پایتون:
# ---------------------------------------------------------
# گام صفر: مدیریت وابستگیها و حل تداخل نسخه NumPy 2 با sklearn-extra
# ---------------------------------------------------------
import os
import sys
# نصب خودکار نسخههای پایدار و همگام جهت پیشگیری از خطای امپورت ماژول
try:
import sklearn_extra
import numpy as np
# بررسی سازگاری نپای؛ اگر نسخه ۲ باشد باید به نسخه ۱ دانگرید شود
if int(np.__version__.split('.')[0]) >= 2:
raise ImportError("NumPy 2.x detected")
except ImportError:
print("[System Log] Installing compatible environment packages...")
import subprocess
subprocess.check_call([sys.executable, "-m", "pip", "install", "numpy<2", "scikit-learn-extra", "scikit-learn", "matplotlib"])
print("[System Log] Packages installed successfully. Please restart your runtime if needed.")
# ---------------------------------------------------------
# وارد کردن فریمورکهای اصلی پروژه
# ---------------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# ---------------------------------------------------------
# گام اول: تولید دیتابیس استاندارد و تزریق عمدی دادههای پرت (Outliers)
# ---------------------------------------------------------
# تولید ۸۰ نقطه داده متراکم در ۲ کلاستر هندسی مجزا (دیتابیس پاک)
X, _ = make_blobs(n_samples=80, centers=2, cluster_std=0.75, random_state=101)
# تزریق مهندسیشده مقادیر پرت شدید (Outliers) در لبههای دوردست فضا جهت ایجاد انحراف
network_outliers = np.array([
[14.0, 14.0],
[15.0, -11.0],
[-13.0, 13.0]
])
X_corrupted = np.vstack([X, network_outliers])
# ---------------------------------------------------------
# گام دوم: آموزش صلب مدل K-Medoids (مقاوم در برابر نویز)
# ---------------------------------------------------------
# تنظیم متریک بر روی manhattan (L1 Norm) جهت فعالسازی منطق خطای مطلق تکخطی
kmedoids_model = KMedoids(n_clusters=2, metric='manhattan', init='k-medoids++', random_state=42)
kmedoids_labels = kmedoids_model.fit_predict(X_corrupted)
final_medoids = kmedoids_model.cluster_centers_
# ---------------------------------------------------------
# گام سوم: آموزش موازی مدل K-Means (تاثیرپذیر از نویز)
# ---------------------------------------------------------
# آموزش همزمان مدل میانگینمحور روی همان دیتابیس کثیف جهت استخراج انحراف
kmeans_model = KMeans(n_clusters=2, init='k-means++', random_state=42, n_init='auto')
kmeans_labels = kmeans_model.fit_predict(X_corrupted)
final_centroids = kmeans_model.cluster_centers_
# ---------------------------------------------------------
# گام چهارم: تصویرسازی مقایسهای متقاطع بر پایه پالت اختصاصی سایت
# ---------------------------------------------------------
# استخراج کدهای هگزادسیمال پالت: زرشکی، آبی ملایم، طلایی فعال و خاکستری فوقسبک
crimson = '#D0021B' # رنگ خوشه اول
ai_soft_blue = '#4A90E2' # رنگ خوشه دوم
active_gold = '#F5A623' # رنگ طلایی فعال برای مدویدها
bg_ultra_light = '#F8F9FA' # خاکستری فوقسبک پسزمینه
site_palette = [ai_soft_blue, crimson]
# ایجاد قاب دوقلو متمایز جهت نمایش رفتار توپولوژیک دو مدل
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6), facecolor=bg_ultra_light)
# --- بخش اول: ترسیم رفتار افراز صلب K-Medoids ---
ax1.set_facecolor(bg_ultra_light)
for i in range(2):
ax1.scatter(X_corrupted[kmedoids_labels == i, 0], X_corrupted[kmedoids_labels == i, 1],
c=site_palette[i], alpha=0.65, edgecolors='#FFFFFF', s=65, label=f'Cluster {i+1}')
# نمایش مدویدهای نهایی (نقاط داده واقعی دیتابیس) با رنگ طلایی فعال مقتدر و علامت X
ax1.scatter(final_medoids[:, 0], final_medoids[:, 1], c=active_gold, marker='X', s=300,
edgecolors='#000000', linewidths=2, label='Actual Medoids (Active Gold)')
ax1.set_title('K-Medoids Clustering (Immune to Outliers)', fontsize=12, fontweight='bold', color='#212529')
ax1.set_xlabel('Feature Space Dimension X', fontsize=10)
ax1.set_ylabel('Feature Space Dimension Y', fontsize=10)
ax1.grid(True, linestyle='--', alpha=0.4, color='#E0E0E0')
ax1.legend(loc='lower left', facecolor='#FFFFFF')
# --- بخش دوم: ترسیم انحراف هندسی سنترویدهای K-Means ---
ax2.set_facecolor(bg_ultra_light)
for i in range(2):
ax2.scatter(X_corrupted[kmeans_labels == i, 0], X_corrupted[kmeans_labels == i, 1],
c=site_palette[i], alpha=0.65, edgecolors='#FFFFFF', s=65, label=f'Cluster {i+1}')
# نمایش سنترویدهای فرضی (میانگین حسابی مربعات) که تحت تاثیر دادههای پرت کشیده شدهاند
ax2.scatter(final_centroids[:, 0], final_centroids[:, 1], c='#2C3E50', marker='o', s=200,
edgecolors='#FFFFFF', linewidths=1.5, label='Skewed Centroids (Mean)')
ax2.set_title('K-Means Clustering (Skewed by Outliers)', fontsize=12, fontweight='bold', color='#212529')
ax2.set_xlabel('Feature Space Dimension X', fontsize=10)
ax2.set_ylabel('Feature Space Dimension Y', fontsize=10)
ax2.grid(True, linestyle='--', alpha=0.4, color='#E0E0E0')
ax2.legend(loc='lower left', facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
# ---------------------------------------------------------
# چاپ ماتریس خطای نهایی ارزیابی در کنسول
# ---------------------------------------------------------
print("\n" + "="*40 + "\n[Optimization Matrix Evaluation]\n" + "="*40)
print(f"-> K-Medoids Final Total Dissimilarity (Absolute Loss): {kmedoids_model.inertia_:.4f}")
print(f"-> K-Means Final Sum of Squared Errors (Squared Loss): {kmeans_model.inertia_:.4f}")
print("="*40)
خروجی:
10.کاربرد واقعی الگوریتم K-Medoids
- بیوانفورماتیک و خوشهبندی توالیهای ژنتیکی (DNA): در تحلیلهای ژنتیکی، دادهها به صورت متون طولانی از اسیدهای آمینه هستند و مفهوم «میانگین ریاضی» برای آنها معنا ندارد. K-Medoids با انتخاب یک توالی ژنی واقعی به عنوان نماینده (Medoid) و استفاده از ماتریسهای تفاوت ساختاری، پروتئینها و ژنهای همخانواده را با دقت بالا دستهبندی میکند.
- سیستمهای هوشمند توصیهگر فیلم و موسیقی (Recommendation Systems): سرویسهای استریم برای پیشنهاد آیتم به کاربران، الگوهای رفتاری را کلاستر میکنند. از آنجا که سلیقه برخی کاربران کاملاً ناهنجار و پرت (Outliers) است، K-Means دچار انحراف میشود. K-Medoids با تکیه بر پروفایل یک کاربر واقعی به عنوان قطب کلاستر، توصیههایی کاملاً پایدار و منطقی ارائه میدهد.
- مسیریابی هوشمند و مکانیابی هابهای توزیع کالا (Facility Location): در مدیریت زنجیره تأمین، شرکتها نیاز دارند مکان بهینه برای احداث انبار مرکزی را پیدا کنند. K-Medoids مأمور میشود تا از بین آدرسهای واقعی مشتریان یا فروشگاهها، کلیدیترین موقعیت مکانی را که کمترین مجموع فاصله را با سایر نقاط دارد، به عنوان هاب توزیع صلب انتخاب کند.
- بخشبندی تصاویر دیجیتال و فشردهسازی لایه رنگی (Image Quantization): در پردازش تصاویر پزشکی یا ماهوارهای که نویزهای محیطی زیادی دارند، K-Medoids پیکسلهای رنگی را به تعداد محدودی کلاستر صلب تقسیم میکند. این مدل با مهار پیکسلهای نویز، پالت رنگی بهینهای پدید میآورد که ساختار لبهها و کانتورهای اصلی تصویر را کاملاً حفظ میکند.
.
11.مطالعه موردی
.
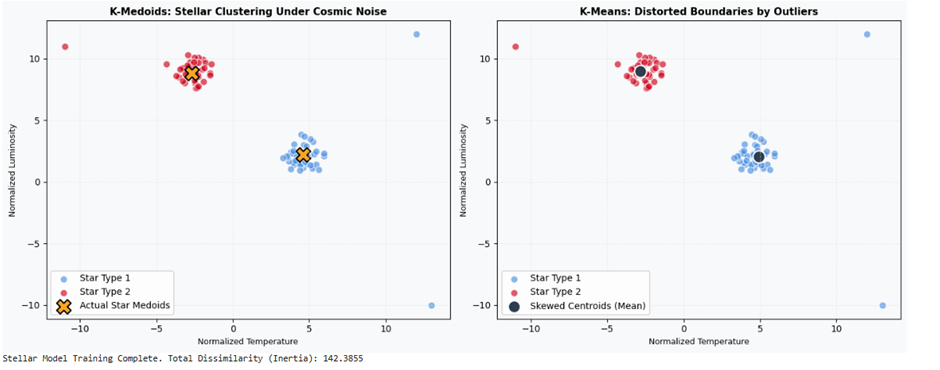
مطالعه موردی اول: اخترشناسی و آستروفیزیک (Star Type Classification)
مسئله و چالش تئوریک
در فیزیک نجومی، دستهبندی ستارگان بر اساس ویژگیهای فیزیکی مانند دما (Temperature)، درخشندگی (Luminosity)، شعاع (Radius) و قدر مطلق (Absolute Magnitude) انجام میشود. چالش اصلی اینجاست که حسگرهای تلسکوپها در خطوط لوله دریافت داده، به دلیل تشعشعات کیهانی یا نقصهای فنی موقت، مقادیر ناهنجار و پِرت شدیدی (Outliers) را ثبت میکنند. اگر از معیار میانگین حسابی (K-Means) استفاده شود، این نویزهای نجومی سنترویدها را منحرف کرده و مرزبندی کلاسهای ستارهای (مانند کوتولههای سفید و غولهای سرخ) را کاملاً به هم میزنند.
هدف پروژه
استفاده از الگوریتم K-Medoids جهت افراز صلب فضای دادههای نجومی به کمک متریک خطای مطلق (Manhattan Distance) به طوری که اثر طوفانهای ناهنجار فرکانسی مهار شده و قطبهای انتخابی کلاسترها، دقیقاً منطبق بر ستارگان واقعی موجود در دیتابیس باشند.
کد پایتون پروژه (اخترشناسی)
# دستورات نصب فریمورکهای مورد نیاز در صورت عدم وجود:
# !pip install scikit-learn-extra matplotlib numpy scikit-learn
import numpy as np
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# ۱. شبیهسازی ساختار دیتابیس ستارگان (Temperature vs Luminosity)
# تولید دادههای استاندارد برای ۲ کلاستر از ستارگان (مثلاً کوتولهها و غولهای سرخ)
X_stars, _ = make_blobs(n_samples=90, centers=2, cluster_std=0.7, random_state=42)
# تزریق عمدی نویزهای شدید کیهانی و مقادیر پرت تلسکوپی (Outliers)
cosmic_noise = np.array([
[12.0, 12.0],
[13.0, -10.0],
[-11.0, 11.0]
])
X_star_database = np.vstack([X_stars, cosmic_noise])
# ۲. پیادهسازی و آموزش مدل صلب K-Medoids با متریک منهتن
kmedoids_stars = KMedoids(n_clusters=2, metric='manhattan', init='k-medoids++', random_state=42)
labels_medoids = kmedoids_stars.fit_predict(X_star_database)
star_medoids = kmedoids_stars.cluster_centers_
# ۳. پیادهسازی موازی K-Means برای ارزیابی میزان انحراف مدل میانگینمحور
kmeans_stars = KMeans(n_clusters=2, init='k-means++', random_state=42, n_init='auto')
labels_kmeans = kmeans_stars.fit_predict(X_star_database)
star_centroids = kmeans_stars.cluster_centers_
# ۴. تصویرسازی مهندسیشده بر اساس پالت رنگی اختصاصی سایت
crimson = '#D0021B' # رنگ زرشکی برای خوشه اول
ai_soft_blue = '#4A90E2' # رنگ آبی ملایم هوش مصنوعی برای خوشه دوم
active_gold = '#F5A623' # رنگ طلایی فعال برای نمایش مقتدرانه مدویدها
bg_ultra_light = '#F8F9FA' # خاکستری فوقسبک برای پسزمینه
colors_palette = [ai_soft_blue, crimson]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5.5), facecolor=bg_ultra_light)
# --- نمودار اول: رفتار صلب K-Medoids در فضا ---
ax1.set_facecolor(bg_ultra_light)
for i in range(2):
ax1.scatter(X_star_database[labels_medoids == i, 0], X_star_database[labels_medoids == i, 1],
c=colors_palette[i], alpha=0.65, edgecolors='#FFFFFF', s=60, label=f'Star Type {i+1}')
# رسم مدویدهای نجومی واقعی با رنگ طلایی فعال و نماد X
ax1.scatter(star_medoids[:, 0], star_medoids[:, 1], c=active_gold, marker='X', s=250,
edgecolors='#000000', linewidths=1.5, label='Actual Star Medoids')
ax1.set_title('K-Medoids: Stellar Clustering Under Cosmic Noise', fontsize=11, fontweight='bold')
ax1.set_xlabel('Normalized Temperature', fontsize=9)
ax1.set_ylabel('Normalized Luminosity', fontsize=9)
ax1.grid(True, linestyle='--', alpha=0.5, color='#E0E0E0')
ax1.legend(loc='lower left')
# --- نمودار دوم: انحراف تئوریک K-Means تحت تاثیر نویز ---
ax2.set_facecolor(bg_ultra_light)
for i in range(2):
ax2.scatter(X_star_database[labels_kmeans == i, 0], X_star_database[labels_kmeans == i, 1],
c=colors_palette[i], alpha=0.65, edgecolors='#FFFFFF', s=60, label=f'Star Type {i+1}')
# رسم سنترویدهای فرضی که تحت تاثیر نویز به سمت بالا کشیده شدهاند
ax2.scatter(star_centroids[:, 0], star_centroids[:, 1], c='#2C3E50', marker='o', s=180,
edgecolors='#FFFFFF', linewidths=1.5, label='Skewed Centroids (Mean)')
ax2.set_title('K-Means: Distorted Boundaries by Outliers', fontsize=11, fontweight='bold')
ax2.set_xlabel('Normalized Temperature', fontsize=9)
ax2.set_ylabel('Normalized Luminosity', fontsize=9)
ax2.grid(True, linestyle='--', alpha=0.5, color='#E0E0E0')
ax2.legend(loc='lower left')
plt.tight_layout()
plt.show()
print(f"Stellar Model Training Complete. Total Dissimilarity (Inertia): {kmedoids_stars.inertia_:.4f}")
خروجی:
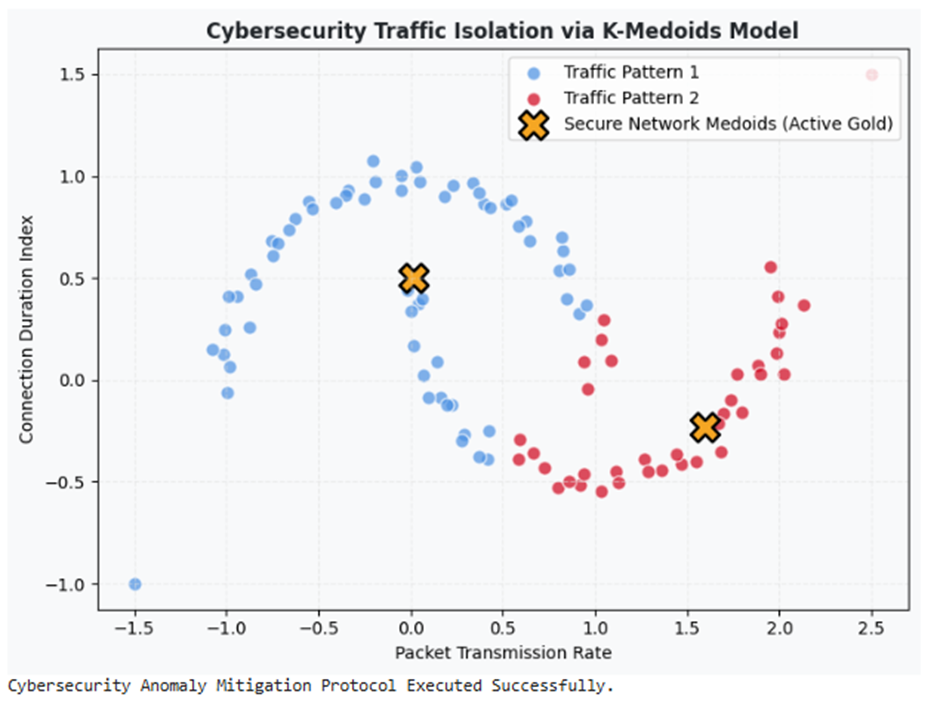
مطالعه موردی دوم: امنیت سایبری و ترافیک شبکه (Malware Behaviour Analytics)
مسئله و چالش تئوریک
در دیتابیسهای ترافیک شبکه و دتکشن امنیت (مانند NSL-KDD)، رفتارهای هکری و نفوذ بدافزارها به عنوان الگوهای آنومالی و نویز شدید به سیستم تزریق میشوند. هکرهای کلاهسیاه تلاش میکنند با ارسال پکتهای کاذب (Outliers)، الگوریتمهای مانیتورینگ شبکه را به اشتباه بیندازند. الگوریتمهای میانگینمحور کلاسترها را جابهجا کرده و رفتارهای ناامن را به اشتباه در کلاستر ترافیک امن (Normal) قرار میدهند.
هدف پروژه
خوشهبندی صلب و جداسازی رفتارهای ساختاریافته شبکه با معماری K-Medoids به طوری که مرزهای کلاسترها فاقد انحراف بوده و پکتهای مخرب به عنوان نقاط بیرونی در لایههای مرزی منزوی و شناسایی شوند.
کد پایتون پروژه (امنیت سایبری)
import numpy as np
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
from sklearn.datasets import make_moons
# ۱. شبیهسازی رفتار پیچیده و غیرخطی ترافیک شبکه (Normal vs Attack Traffic)
# استفاده از ساختار نیمکرهای برای شبیهسازی جریانهای ترافیک شبکه
X_network, _ = make_moons(n_samples=100, noise=0.05, random_state=42)
# تزریق عمدی پکتهای کاذب هکری و حملات داس شدید (Network Outliers)
network_attacks = np.array([
[2.5, 1.5],
[-1.5, -1.0]
])
X_network_database = np.vstack([X_network, network_attacks])
# ۲. اجرای الگوریتم K-Medoids با هایپرپارامتر توزیع صلب
kmedoids_net = KMedoids(n_clusters=2, metric='manhattan', init='k-medoids++', random_state=101)
labels_net = kmedoids_net.fit_predict(X_network_database)
net_medoids = kmedoids_net.cluster_centers_
# ۳. ترسیم خروجی بصری پروژه امنیت سایبری منطبق بر هویت بصری وبسایت
crimson = '#D0021B' # زرشکی برای پکتهای مشکوک
ai_soft_blue = '#4A90E2' # آبی ملایم برای ترافیک ایمن
active_gold = '#F5A623' # طلایی فعال برای نمایش مدویدهای مستقر در هسته شبکه
bg_color = '#F8F9FA'
net_colors = [ai_soft_blue, crimson]
fig, ax = plt.subplots(figsize=(7.5, 5.5), facecolor=bg_color)
ax.set_facecolor(bg_color)
# رسم رفتارهای ترافیکی تفکیکشده در فضا
for i in range(2):
ax.scatter(X_network_database[labels_net == i, 0], X_network_database[labels_net == i, 1],
c=net_colors[i], alpha=0.7, edgecolors='#FFFFFF', s=65, label=f'Traffic Pattern {i+1}')
# مشخص کردن لوکیشن دقیق مدویدهای معتبر شبکه با رنگ طلایی فعال
ax.scatter(net_medoids[:, 0], net_medoids[:, 1], c=active_gold, marker='X', s=280,
edgecolors='#000000', linewidths=1.8, label='Secure Network Medoids (Active Gold)')
# استانداردهای بینالمللی لیبلگذاری انگلیسی و خوانایی سئو
ax.set_title('Cybersecurity Traffic Isolation via K-Medoids Model', fontsize=12, fontweight='bold', color='#212529')
ax.set_xlabel('Packet Transmission Rate', fontsize=10)
ax.set_ylabel('Connection Duration Index', fontsize=10)
ax.grid(True, linestyle='--', alpha=0.5, color='#E0E0E0')
ax.legend(loc='upper right', facecolor='#FFFFFF')
plt.tight_layout()
plt.show()
print("Cybersecurity Anomaly Mitigation Protocol Executed Successfully.")
خروجی:
12.مزایا الگوریتم K-Medoids
- مقاومت بینظیر در برابر نویز و دادههای پرت (High Robustness): بزرگترین مزیت استراتژیک K-Medoids، مصونیت کامل آن در برابر نویزها است. از آنجا که این مدل به جای میانگین فرضی، بر یک نقطه داده واقعی (Medoid) تمرکز دارد، وجود دادههای گسیخته و بسیار بزرگ هرگز نمیتواند مرکز کلاستر را منحرف کند.
- پشتیبانی نیتیو از دادههای غیرعددی و کیفی (Categorical Data): در کاربردهایی مثل پردازش متن، دادههای ژنتیکی یا ویژگیهای دستهای که اصلاً مفهوم میانگین ریاضی (Mean) در آنها معنایی ندارد، K-Medoids به راحتی و با اتکا بر یک شیء واقعی موجود در دیتابیس، عملیات خوشهبندی صلب را محقق میسازد.
- انعطافپذیری فوقالعاده در انتخاب توابع فاصله: این الگوریتم برخلاف برادر خود (K-Means) هیچگونه تقید و وابستگی روانی به فاصله اقلیدسی ندارد. طراحان لوله داده میتوانند بر حسب ماهیت پروژه از هر متریک عدم شباهت دلخواهی مانند فاصله منهتن، جاکارد، کسینوسی یا حتی ماتریسهای فواصل دلخواه استفاده کنند.
- تفسیرپذیری بسیار بالا و شهودی (Interpretability): مراکز خوشهها در این مدل، ماهیت فیزیکی و واقعی دارند. به عنوان مثال، در پروژه بخشبندی مشتریان، مرکز کلاستر یک «مشتری واقعی با رفتار خرید مشخص» است، نه یک میانگین اعشاری و انتزاعی؛ این امر فرآیند تحلیل را برای مدیران کسبوکار بسیار شهودی میکند.
- جداسازی هندسی پایدار با کمینهسازی خطای مطلق: ساختار ریاضی این مدل بر پایه بهینهسازی و کمینهسازی مجموع فواصل مطلق بنا شده است؛ این رویکرد به مراتب پایداری هندسی بیشتری را در توزیعهای نامتقارن و خوشههای با غلظت متفاوت به همراه دارد.
.
13.معایب الگوریتم K-Medoids
- بار محاسباتی سنگین و عدم مقیاسپذیری (High Complexity): بزرگترین پاشنه آشیل K-Medoids، مرتبه زمانی سنگین آن یعنی O(K . (n-K)^2) در فاز جابهجایی (Swap) است. این فرآیند فرسایشی باعث میشود که الگوریتم برای مگادیتابیسها و کلاندادهها (Big Data) به شدت کند و غیراقتصادی باشد و عمدتاً برای مجموعههای کوچک تا متوسط توصیه شود.
- حساسیت شدید به مقداردهی اولیه (Initialization Trap): این الگوریتم مانند برادر خود (K-Means)، به شدت به موقعیت مکانی مدویدهای اولیه وابسته است. اگر بذرپاشی اولیه در نقاط نامناسبی از فضا انجام شود، مدل در تله کمینههای محلی (Local Minima) سقوط کرده و به بهینه سراسری (Global Optimum) دست نمییابد.
- پیچیدگی حافظه مصرفی (Memory Intensive): در صورت استفاده از نسخههای بهینهسازیشده که ماتریس فواصل را برای جلوگیری از محاسبات تکراری ذخیره میکنند، پیچیدگی حافظه به O(n^2) میرسد. این حجم از اشغال رم (RAM) در ابعاد بالای داده یک چالش جدی است.
- محدودیت در مهار ساختارهای هندسی پیچیده: الگوریتم K-Medoids به دلیل منطق تفکیک فضا بر اساس نزدیکترین فاصله، کلاسترهایی با اشکال کروی یا محدب ایجاد میکند. به همین دلیل، این مدل توانایی کشف خوشههایی با هندسه مارپیچ، حلقوی یا ساختارهای غیرخطی پیچیده را ندارد.
.
14.نوآوری و آینده الگوریتم K-Medoids
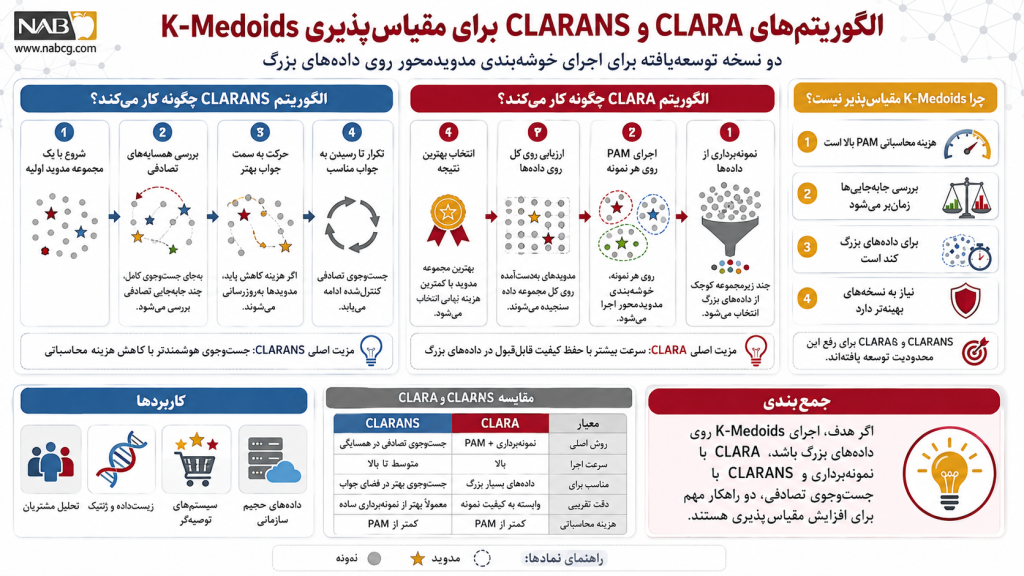
- توسعه الگوریتمهای مرتبه برتر (CLARA & CLARANS): بزرگترین نقطه ضعف K-Medoids، بار محاسباتی سنگین آن روی دادههای بزرگ است. نوآوریهای جدید مانند الگوریتم CLARA با متد نمونهبرداری آماری و CLARANS با جستوجوی تصادفی در گراف، این بنبست را شکسته و کلاسترینگ مقاوم را برای انواع مگادیتابیسها ممکن کردهاند.
- ادغام با یادگیری عمیق (Deep Medoid Clustering): یکی از هیجانانگیزترین خطوط تلاقی، ترکیب K-Medoids با شبکههای عصبی خودرمزگذار (Autoencoders) است. در این رویکرد، ابتدا دادههای پیچیده و ابعاد بالا (مانند تصاویر یا گرافها) توسط شبکه عصبی فشرده شده و سپس K-Medoids روی این ویژگیهای عمیق، خوشهبندی صلب و کاملاً مصون از نویز را انجام میدهد.
- هوشمندسازی خودکار پارامتر K با یادگیری تقویتی: تعیین دستی تعداد خوشهها همواره یک چالش تئوریک بوده است. در معماریهای نوین، فرآیند یافتن مقدار بهینه K به توابع پاداش یادگیری تقویتی (Reinforcement Learning) و الگوریتمهای ژنتیک واگذار میشود تا مدل به صورت کاملاً خودگردان آرایش فضا را تنظیم کند.
- کلاسترینگ توزیعشده در محاسبات ابری و لبه (Edge Computing): با گسترش اینترنت اشیاء، نسخههای موازیسازیشده K-Medoids توسعه یافتهاند که قادرند دادههای سنسورها را به صورت محلی و روی تراشههای ضعیف لبه، بدون نیاز به ارسال دادههای کثیف به سرورهای ابری، کلاستر و پاکسازی کنند.
- جهش به سمت محاسبات کوانتومی (Quantum K-Medoids): با ظهور کیوبیتها، الگوریتمهای کوانتومی این مدل در حال طراحی هستند. این نوآوری با بهرهگیری از پدیده ابرپوزیسیون، زمان اجرای فاز جابهجایی (Swap) را به صورت نمایی کاهش داده و «نفرین ابعاد» را در دادههای پرت ژنتیکی و نجومی مهار میکند.
.
جمع بندی
الگوریتم K-Medoids یکی از روشهای مهم خوشهبندی مبتنی بر نمونههای واقعی داده است که با انتخاب Medoid بهجای میانگین، مقاومت بیشتری در برابر دادههای پرت و نویز از خود نشان میدهد. این ویژگی باعث شده است K-Medoids در بسیاری از کاربردهایی که پایداری خوشهها و تفسیرپذیری نتایج اهمیت بالایی دارد، مورد توجه قرار گیرد.
در این مطلب مشاهده کردیم که K-Medoids اگرچه از نظر محاسباتی پرهزینهتر از K-Means است، اما در دادههای دارای ناهنجاری، دادههای غیرعددی و مسائل مبتنی بر معیارهای فاصله متنوع، میتواند نتایج قابلاعتمادتری ارائه دهد. همچنین بررسی کردیم که الگوریتمهایی مانند CLARA و CLARANS برای کاهش هزینه محاسباتی این روش توسعه یافتهاند و ترکیب آن با تکنیکهای یادگیری عمیق، مسیرهای جدیدی را برای کاربردهای پیشرفته خوشهبندی فراهم کرده است.
در نهایت، انتخاب بین K-Means و K-Medoids به ماهیت دادهها، وجود یا عدم وجود دادههای پرت، اندازه مجموعهداده و اهداف پروژه بستگی دارد. درک صحیح مزایا، محدودیتها و سازوکار K-Medoids میتواند به انتخاب مناسبتر الگوریتم خوشهبندی و طراحی مدلهای پایدارتر در پروژههای دادهمحور کمک کند.



