

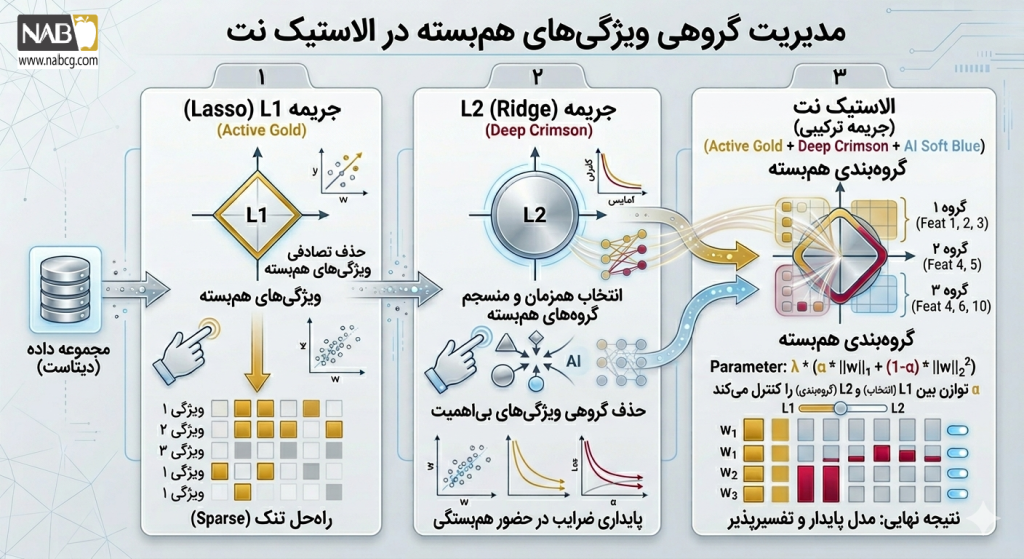
1.مقدمه
رگرسیون الاستیک نت (Elastic Net Regression) یک الگوریتم یادگیری ماشین قدرتمند است که به منظور حل مشکلات رگرسیون خطی معمولی در حضور دادههای با تعداد ویژگی زیاد و همبستگی بالا طراحی شده است. این روش با ترکیب ویژگیهای دو روش Regularization یعنی Lasso (L1) و Ridge (L2)، همزمان مزایای هر دو را ارائه میدهد: انتخاب ویژگیها و کاهش پیچیدگی مدل. چنین رویکردی به ویژه در سناریوهای صنعتی، مالی و علمی که دادهها همخطی یا پرنویز هستند، بسیار کاربردی است.
الاستیک نت به مدلها امکان میدهد بدون قربانی کردن دقت، با دادههای با ابعاد بالا کار کنند و همزمان ویژگیهای غیرمؤثر را حذف و وزن ویژگیهای مهم را تقویت کنند. این الگوریتم در تحلیل پیشبینی طول عمر مشتریان، پیشبینی مصرف انرژی، قیمتگذاری محصولات و بسیاری از مسائل اقتصادی و علمی استفاده میشود. در این مقاله، ابتدا مبانی نظری و ریاضی الاستیک نت، سپس نحوه ترکیب L1 و L2، انتخاب Hyperparameterها و پیادهسازی عملی آن بررسی میشود. در ادامه نیز کاربردهای صنعتی و مزایای این روش نسبت به روشهای مشابه تحلیل خواهند شد.
2.تعریف
رگرسیون «الاستیک نت» یک روش پیشرفته در خانواده مدلهای رگرسیون منظمسازیشده (Regularized Regression) است که به عنوان یک راهکار ترکیبی برای مقابله با دو چالش بزرگ در یادگیری ماشین و دادهکاوی، یعنی «بیشبرازش» (Overfitting) و «همخطی شدید» (Multicollinearity) توسعه یافته است. نام این الگوریتم از دنیای فیزیک الهام گرفته شده؛ همانطور که یک شبکه کشسان (Elastic Net) میتواند در عین حفظ ساختار و شکل خود، تغییر شکل دهد، این مدل نیز میتواند با انعطافپذیری بالا با ساختار پیچیده دادهها سازگار شود.

۳. اهمیت و جایگاه رگرسیون الاستیک نت (Elastic Net)
در توسعه مدلهای پیشرفته یادگیری ماشین، مواجهه با چالشهای ساختاری دادهها امری اجتنابناپذیر است. الگوریتم منظمسازی الاستیک نت با تلفیق هوشمندانه جریمههای L1 (لاسو) و L2 (ریج)، چالشهای مهندسی داده را به شکل زیر واکاوی و حل میکند:
- مهار همخطی چندگانه (Multicollinearity)
در رگرسیون سنتی، همبستگی شدید متغیرهای ورودی باعث بیثباتی ضرایب میشود. لاسو در این شرایط یک ویژگی را تصادفی انتخاب و باقی را حذف میکند که به ظرفیت دانش مدل آسیب میزند. الاستیک نت با ترکیب جریمهها، ویژگیهای مرتبط را به صورت یک گروه هماهنگ مدیریت کرده و وزنها را منطقی بین آنها توزیع میکند.
- انتخاب خودکار ویژگیها (Feature Selection)
شناسایی متغیرهای مؤثر در دیتابیسهای بزرگ برای سادهسازی مدل و افزایش تفسیرپذیری (Interpretability) حیاتی است. الاستیک نت با الگوبرداری از لاسو، ضرایب ویژگیهای زائد را به صفر مطلق میرساند. این گزینش خودکار، پیچیدگی ریاضی را کاهش داده و ریسک بیشبرازش (Overfitting) را مهار میکند.
- منظمسازی پویا و انعطافپذیر
بسته به توزیع دادهها، گاهی به حذف تهاجمی ویژگیها و گاهی به پایداری نرم ضرایب نیاز است. الاستیک نت با تنظیم ابرپارامتر نسبت ترکیب (l1_ratio)، آزادی عمل بالایی به مهندسان هوش مصنوعی میدهد تا تعادل بهینهای میان رفتار لاسو و ریج بر اساس نیاز دیتاسِت برقرار کنند.
- پایداری در دادههای ابعاد بالا (High-Dimensional Data)
رگرسیونهای کلاسیک هنگام مواجهه با دادههای «عریض» که در آنها تعداد ویژگیها بسیار بیشتر از نمونههاست (p > n)، کارایی خود را از دست میدهند. الاستیک نت به دلیل ساختار جریمه دوگانه، پایدارترین ابزار برای تحلیل دادههای پیچیده (مانند دادههای مالی و ژنتیکی) در شرایط محدودیت نمونه است.
- انطباقپذیری همهجانبه
در مراحل اولیه پروژه یادگیری ماشین، روابط پنهان دادهها ناشناخته است. الاستیک نت به عنوان «استاندارد طلایی» و گزینه پیشفرض متخصصان، عدم قطعیت را از بین میبرد؛ زیرا خود را به طور خودکار با ساختار درونی دادهها سازگار میکند.
4.منظمسازی الاستیک نت (Elastic Net Regularization)؛ معماری هوشمند برای مدیریت دیتابیسهای پیچیده
در سناریوهای واقعی یادگیری ماشین و دادهکاوی، توسعهدهندگان به ندرت با دادههای ایزوله و ایدهآل سروکار دارند. مواجهه با دیتابیسهای ابعاد بالا (High-Dimensional Data) که در آنها پدیده بیشبرازش (Overfitting) یا همخطی شدید (Multicollinearity) رخ میدهد، یک چالش همیشگی است. الگوریتم منظمسازی الاستیک نت (Elastic Net) دقیقاً به عنوان یک راهکار ترکیبی و هوشمند برای مهار همزمان این دو چالش طراحی شده است.
5.الاستیک نت چگونه کار میکند؟
در رگرسیون خطی استاندارد (بدون جریمه)، اگر دو یا چند متغیر ورودی همبستگی شدیدی با یکدیگر داشته باشند، ماتریس محاسباتی مدل بدرفتار (Ill-conditioned) میشود؛ در نتیجه، ضرایب ریاضی (β) دچار نوسانات شدید و وزنهای غیرواقعی میشوند که قدرت تعمیم مدل را به شدت کاهش میدهد.
برای حل این بحران، دو رویکرد کلاسیک منظمسازی وجود دارد:
- رگرسیون لاسو (Lasso – L1 Regularization): با اضافه کردن قدرمطلق ضرایب به تابع هزینه، برخی وزنها را دقیقاً به صفر میرساند. این کار یک مکانیزم داخلی برای انتخاب ویژگی (Feature Selection) ایجاد میکند. اما نقطه ضعف بزرگ لاسو این است که اگر با گروهی از ویژگیهای شدیداً همبسته مواجه شود، به صورت کاملاً تصادفی یکی را انتخاب کرده و مابقی را حذف میکند. این رفتار در دادهکاوی منجر به از دست رفتن اطلاعات کلیدی دیتابیس میشود.
- رگرسیون ریج (Ridge – L2 Regularization): با اضافه کردن مجذور ضرایب به تابع هزینه، وزنها را به سمت صفر میل میدهد اما هیچگاه آنها را دقیقاً صفر نمیکند. ریج اطلاعات را حفظ میکند و در برابر همخطی پایدار است، اما توانایی خلوتسازی و حذف ویژگیهای کاملاً زائد را ندارد.
این الگوریتم جریمههای L1 و L2 را با یکدیگر ترکیب میکند. نام این مدل از فیزیک الهام گرفته شده است؛ مانند یک شبکه کشسان (Elastic Net) که در عین انعطافپذیری بالا و کش آمدن برای انطباق با دادهها، ساختار و همبستگی درونی خود را حفظ میکند.
بزرگترین مزیت الاستیک نت در یادگیری ماشین، پدیدهای به نام «اثر گروهی» است. برخلاف لاسو که متغیرهای همبسته را به صورت تصادفی حذف میکرد، الاستیک نت با متغیرهای مرتبط به صورت یک گروه رفتار میکند؛ یعنی یا کل گروه را با هم در مدل حفظ کرده و وزنهایشان را به صورت متعادل توزیع میکند، یا در صورت زائد بودن، کل گروه را به طور همزمان از مدل حذف میکند.
6.مبانی ریاضی و تابع هزینه الاستیک نت
در یادگیری ماشین، آموزش مدل به معنای یافتن ضرایبی است که کمترین خطا و کمترین پیچیدگی را ایجاد کنند. تابع هزینه (Loss Function) در رگرسیون الاستیک نت که الگوریتمهای بهینهسازی (مانند گرادیان کاهشی) برای مینیمم کردن آن تلاش میکنند، به صورت زیر فرمولبندی میشود:
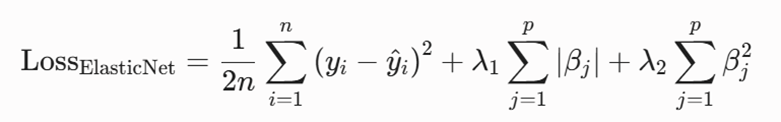
برای تسهیل در فرآیند تنظیم ابرپارامترها (Hyperparameter Tuning) در ابزارهای مدرن مانند کتابخانه Scikit-Learn پایتون، این فرمول بر اساس دو پارامتر بهینهسازی کلیدی یعنی α (شدت کل جریمه) و ρ (نسبت اثر دو جریمه) بازنویسی و استانداردسازی شده است:

تشریح کامل و دقیق متغیرها:
- MSE (میانگین مجذور خطاها): بخش سنتی تابع هزینه رگرسیون که فاصلهی بین پیشبینیهای مدل و واقعیت را میسنجد. هدف آن بالا بردن دقت مدل روی دادههای آموزش است.
- n: تعداد کل نمونههای آماری یا رکوردهای موجود در دیتابیس آموزشی.
- p: تعداد کل ویژگیهای ورودی (متغیرهای مستقل) که مدل باید برای آنها ضریب تعیین کند.
- yi: مقدار واقعی، هدف و برچسب حقیقی برای نمونه iام.
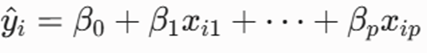
- βj: ضریب یا وزن اختصاص داده شده به ویژگی jام. جریمهها مستقیماً بر روی این مقادیر اعمال میشوند.

.
- α (آلفا alpha/): ضریب تنظیمکننده شدت کل جریمه (Penalty Complexity).
- اگر 0 = α باشد، جریمهها کاملاً خنثی شده و مدل به یک رگرسیون خطی معمولی (OLS) تبدیل میشود.
- هرچه α بزرگتر شود، شدت جریمه بیشتر شده، ضرایب کوچکتر میشوند و مدل از بیشبرازش فاصله میگیرد.
- ρ: پارامتر نسبت جریمه لاسو به ریج که عددی در بازه [0, 1] است و نقش لنگر تعادل را دارد:
- اگر 1 = ρ باشد، جریمه ریج صفر شده و مدل دقیقاً به رگرسیون لاسو (Lasso) تبدیل میشود.
- اگر 0 = ρ باشد، جریمه لاسو صفر شده و مدل دقیقاً به رگرسیون ریج (Ridge) تبدیل میشود.
- اگر ρ بین 0 و 1 باشد (مثلاً 0.5)، مدل ترکیبی مساوی از هر دو مکانیزم حذف ویژگی (L1) و حفظ پایداری گروهی (L2) را اعمال خواهد کرد.
.
7.چه زمانی در پروژههای یادگیری ماشین از الاستیک نت استفاده کنیم؟
متخصصان دادهکاوی و مهندسان هوش مصنوعی در سه سناریوی کلیدی رگرسیون خطی معمولی یا لاسو را رها کرده و به سراغ الاستیک نت میروند:
- وقتی p > n باشد: یعنی تعداد ویژگیهای ثبت شده از تعداد نمونههای دیتابیس بیشتر باشد (مثلاً در دادههای ژنتیک یا تحلیل متن).
- وجود همبستگیهای شبکه ای: زمانی که مطمئن هستیم متغیرهای ورودی به شدت به یکدیگر وابسته هستند و حذف تکی آنها به ساختار پیشبینی آسیب میزند.
- جلوگیری از رفتار تصادفی لاسو: هنگامی که به ویژگیهای تنک (Sparsity) نیاز داریم اما میخواهیم ثبات مدل در تکرارهای مختلف حفظ شود.
.
8.مثال
برای درک عمیق محاسبات، یک سناریوی واقعی در حوزه سنجش رضایت مشتریان و نرخ تکرار خرید را بررسی میکنیم.
سناریوی مسئله:
یک پلتفرم هوشمند میخواهد «میزان تکرار خرید مشتری در ماه» (y) را بر اساس دو متغیر همبسته پیشبینی کند:
- امتیاز رضایت از کیفیت خدمات (x1)
- امتیاز رضایت از پشتیبانی فنی (x2)
از آنجا که این دو متغیر ورودی همبستگی بالایی با یکدیگر دارند، رگرسیون معمولی دچار خطا میشود. دادههای فرضی ما برای ۳ مشتری به شرح زیر است:
| مشتری (i) | کیفیت خدمات (x1) | پشتیبانی فنی (x2) | تعداد خرید واقعی (y) |
| ۱ | ۱ | ۲ | ۲ |
| ۲ | ۲ | ۴ | ۵ |
| ۳ | ۳ | ۵ | ۷ |
تنظیمات فرضی مدل الاستیک نت برای این مسئله:
- عرض از مبدأ (β0) به جهت سادگی صفر فرض میشود.
- پارامتر تنظیم جریمه: α = 2
- نسبت ترکیب: ρ = 0.5 (ترکیب مساوی از لاسو و ریج)
مدل میخواهد وزنهای β1 و β2 را طوری حدس بزند که تابع هزینه به حداقل برسد. فرض کنید در یک گام از فرآیند بهینهسازی، مدل وزنهای فرضی β1= 1 و β2=1 را انتخاب کرده است. بیایید هزینه این گام را محاسبه کنیم.
الف: محاسبه مقادیر پیشبینیشده
فرمول پیشبینی مدل:
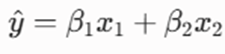
- برای مشتری ۱:

- برای مشتری ۲:

- برای مشتری ۳:
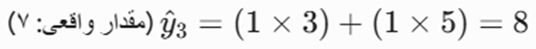
ب: محاسبه بخش خطای پیشبینی (MSE)
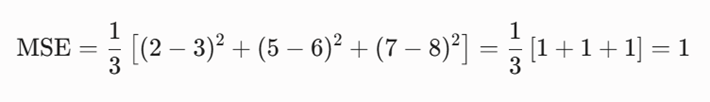
ج: محاسبه جریمه لاسو (L1 Penalty)
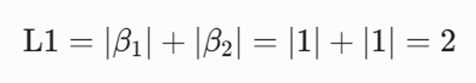
د: محاسبه جریمه ریج (L2 Penalty)

ه: محاسبه هزینه کل الاستیک نت
حالا مقادیر به دست آمده را در تابع هزینه جایگذاری میکنیم:
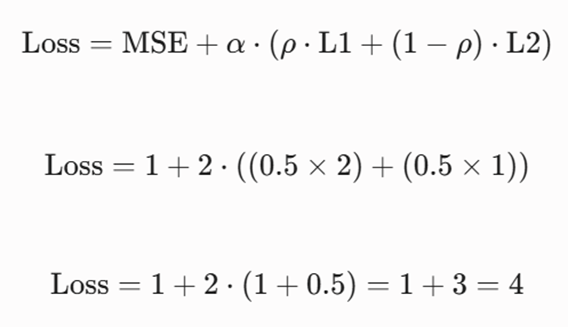
نتیجه این گام: هزینه کل مدل برابر با ۴ به دست آمد. الگوریتمهای بهینهسازی (مانند گرادیان کاهشی) در گامهای بعدی وزنهای β1= 1 و β2=1 را تغییر میدهند تا این عدد ۴ را به کمترین مقدار ممکن برسانند. در نهایت، به دلیل وجود جریمهها، ضرایب این دو ویژگی همبسته به شکلی متعادل و پایدار استخراج خواهند شد، بدون اینکه یکی از آنها به طور تصادفی حذف شود.
9.مثال پیشبینی ارزش طول عمر مشتری (Customer Lifetime Value – CLV)
سناریوی مسئله:
یک تیم مهندسی یادگیری ماشین در یک پلتفرم تجارت الکترونیک بزرگ میخواهد «ارزش مالی طول عمر مشتری» (y – به میلیون تومان) را پیشبینی کند. برای این کار، سه ویژگی استخراج شده است که دو مورد از آنها به دلیل ماهیت رفتار کاربر، همبستگی شدید (Multicollinearity) دارند:
- مجموع مبالغ خریدهای قبلی (x1)
- تعداد کل تراکنشها (x2) (همبسته با x1)
- مدت زمان عضویت به ماه (x3)
۱. دیتابیس آموزشی (۳ نمونه پیچیده)
| مشتری (i) | مجموع خرید (x1) | تعداد تراکنش (x2) | مدت عضویت (x3) | ارزش طول عمر واقعی (y) |
| ۱ | ۲ | ۴ | ۱۲ | ۲۰ |
| ۲ | ۵ | ۱۰ | ۲۴ | ۴۵ |
| ۳ | ۸ | ۱۶ | ۳۶ | ۷۰ |
۲. تنظیمات و ابرپارامترهای مدل (Hyperparameters)
- ضریب شدت جریمه کل: 1.5 = α
- نسبت اثر لاسو به ریج: 0.6 = ρ (یعنی ۶۰٪ وزن جریمه روی لاسو و ۴۰٪ روی ریج است)
۳. وضعیت فرضی مدل در یک گام از آموزش (Epoch)
فرض کنید الگوریتم بهینهسازی (مانند Gradient Descent) در این تکرار، وزنهای زیر را برای پارامترها و عرض از مبدأ حدس زده است:
- β0 = 5 (عرض از مبدأ)
- β1 = 3
- β2 = 1.5
- β3 = 0.5
حالا باید به صورت گامبهگام و با جزئیات دقیق ریاضی، هزینه (Loss) این تکرار را محاسبه کنیم.
محاسبات مرحله به مرحله (Step-by-Step Resolution)
گام اول: محاسبه مقادیر پیشبینیشده
فرمول فرضی مدل:
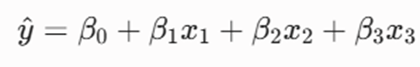
- پیشبینی برای مشتری ۱:

- پیشبینی برای مشتری ۲:
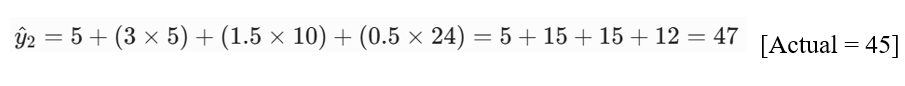
- پیشبینی برای مشتری ۳:
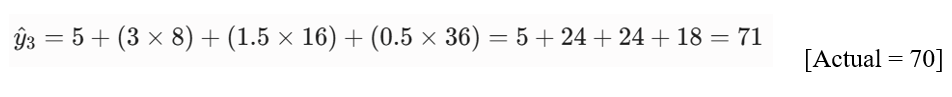
گام دوم: محاسبه میانگین مجذور خطاها (MSE)
خطای هر نمونه را به توان ۲ میرسانیم و میانگین میگیریم (n=3):
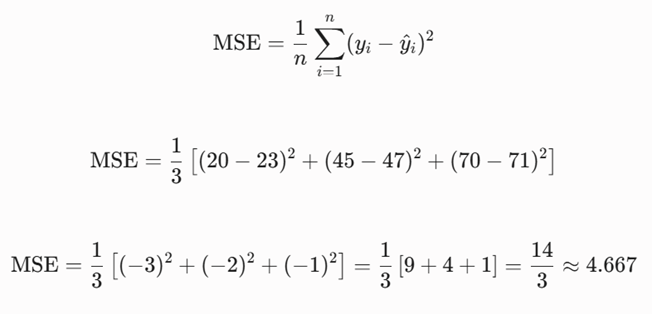
گام سوم: محاسبه جریمه لاسو (L1 Penalty)
نکته مهم آکادمیک: طبق استانداردهای یادگیری ماشین، عرض از مبدأ (β0) هیچگاه وارد جریمههای L1 و L2 نمیشود.

گام چهارم: محاسبه جریمه ریج (L2 Penalty)

گام پنجم: محاسبه هزینه کل الاستیک نت (Elastic Net Total Loss)
فرمول استاندارد تابع هزینه را بازنویسی و مقادیر را جایگذاری میکنیم:

تحلیل مهندسی خروجی این گام:
هزینه نهایی این تکرار برابر با ۱۲.۶۱۷ محاسبه شد. در گامهای بعدی، موتور یادگیری ماشین (مثلاً از طریق مشتقگیری جزئی و پسانتشار خطا):
- متوجه میشود که ویژگیهای x1 و x2 همبستگی شدیدی دارند، بنابراین به کمک اثر جریمه ریج (L2)، وزنهای β1 و β2 را به جای رفتارهای تصادفی، به صورت هماهنگ تعدیل میکند.
- به کمک جریمه لاسو (L1)، اگر متغیری مانند x3 تأثیر کمی در خروجی نهایی داشته باشد، ضریب آن را به سمت صفر مطلق هدایت میکند تا مدل خلوت (Sparse) و بهینه شود.
این مثال به دلیل داشتن متغیرهای بیشتر، عدم صفر بودن β0 و به کارگیری ضرایب اعشاری واقعی، دقیقاً نحوه پیادهسازی این الگوریتم را در هسته کتابخانههایی مانند Scikit-Learn نشان میدهد.
تحلیل مهندسی خروجی این گام:
هزینه نهایی این تکرار برابر با ۱۲.۶۱۷ محاسبه شد. در گامهای بعدی، موتور یادگیری ماشین (مثلاً از طریق مشتقگیری جزئی و پسانتشار خطا):
- متوجه میشود که ویژگیهای x1 و x2 همبستگی شدیدی دارند، بنابراین به کمک اثر جریمه ریج (L2)، وزنهای β1 و β2 را به جای رفتارهای تصادفی، به صورت هماهنگ تعدیل میکند.
- به کمک جریمه لاسو (L1)، اگر متغیری مانند x3 تأثیر کمی در خروجی نهایی داشته باشد، ضریب آن را به سمت صفر مطلق هدایت میکند تا مدل خلوت (Sparse) و بهینه شود.
این مثال به دلیل داشتن متغیرهای بیشتر، عدم صفر بودن β0 و به کارگیری ضرایب اعشاری واقعی، دقیقاً نحوه پیادهسازی این الگوریتم را در هسته کتابخانههایی مانند Scikit-Learn نشان میدهد.
.
10. معیارهای ارزیابی مدل الاستیک نت (Elastic Net Evaluation Metrics)
برای سنجش عملکرد مدل الاستیک نت در یادگیری ماشین و اطمینان از اینکه فرآیند منظمسازی (Regularization) به درستی تعادل میان «بیشبرازش» و «کمبرازش» را برقرار کرده است، از معیارهای ارزیابی رگرسیون استفاده میکنیم. در ادامه، سه معیار کلیدی به همراه فرمولهای ریاضی آنها آورده شده است:
میانگین مجذور خطاها (MSE)
این معیار به دلیل به توان دو رساندن خطاها، جریمه سنگینی برای پیشبینیهای بسیار پرت در نظر میگیرد. در الاستیک نت، هدف ما پس از اعمال جریمهها، رسیدن به کمترین میزان MSE روی دادههای تست است.
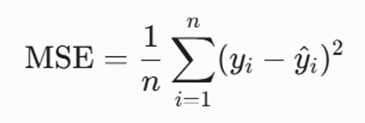
معرفی متغیرها:
- n: تعداد کل مشاهدات (تعداد دادهها).
- yi: مقدار واقعی مشاهده شده برای دادهی iام.
- y^: مقدار پیشبینی شده توسط مدل برای دادهی iام.
- | … |: علامت قدر مطلق که باعث میشود جهت خطا (مثبت یا منفی) حذف شود.
ریشه میانگین مجذور خطاها (RMSE)
از آنجا که واحد MSE به دلیل توان دو با واحد متغیر هدف یکسان نیست، با گرفتن جذر از آن، معیار RMSE به دست میآید که تفسیرپذیری بسیار بالایی برای مهندسان هوش مصنوعی دارد و دقیقاً میانگین انحراف پیشبینیها را با همان واحد دادههای واقعی نشان میدهد.
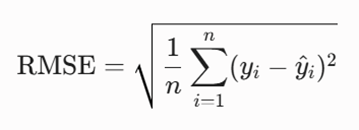
ضریب تعیین تعدیلشده (Adjusted R^2)
در الاستیک نت که مأموریت اصلی آن حذف ویژگیهای زائد (Sparsity) است، معیار R^2 معمولی ابزار فریبندهای است؛ زیرا با اضافه شدن هر ویژگی جدید (حتی نویز)، مقدار آن افزایش مییابد. بنابراین، ما از R^2 تعدیلشده استفاده میکنیم که تعداد ویژگیها (p) را در جریمه خود لحاظ میکند. اگر الاستیک نت ویژگیهای بیآثر را به درستی حذف کرده باشد، این معیار ارتقا مییابد.
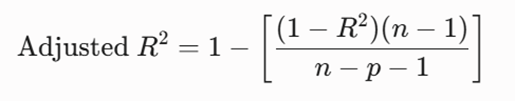
11. ابزارها و فریمورکهای محبوب برای اجرای الاستیک نت (Elastic Net)
در اکوسیستم یادگیری ماشین، پیادهسازی و تنظیم ابرپارامترهای (Hyperparameter Tuning) الگوریتم الاستیک نت اهمیت بالایی دارد؛ زیرا مدیریت همزمان جریمههای L1 و L2 نیازمند ابزارهایی است که بتوانند محاسبات را بهینهسازی و فرآیند پیدا کردن بهترین آلفا (α) و نسبت لاسو (l1_ratio) را تسهیل کنند.
در ادامه، محبوبترین ابزارها و فریمورکهای این حوزه را به همراه کدهای عملیاتی و واقعی پایتون بررسی میکنیم:
کتابخانه Scikit-Learn (استاندارد یادگیری ماشین در پایتون)
این کتابخانه، محبوبترین و پرکاربردترین ابزار برای پیادهسازی الاستیک نت است. کلاس ElasticNet در Scikit-Learn از الگوریتم بهینهسازی «نزول مختصاتی» (Coordinate Descent) استفاده میکند که برای دادههای عریض و ماتریسهای تنک (Sparse) فوقالعاده سریع است. همچنین کلاس ElasticNetCV به صورت خودکار و با استفاده از ارزیابی متقاطع (Cross-Validation)، بهترین مقادیر پارامترها را پیدا میکند.
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# ۱. تولید دادههای نمونه خطی با نویز و ویژگیهای همبسته
np.random.seed(42)
X = np.random.randn(100, 5)
# ایجاد همبستگی شدید بین ویژگی اول و دوم
X[:, 1] = X[:, 0] + np.random.randn(100) * 0.1
y = 2 + 3 * X[:, 0] + 1.5 * X[:, 2] + np.random.randn(100)
# ۲. تقسیم دادهها به دو بخش آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ۳. ساخت و آموزش مدل (alpha=0.5 و ترکیب مساوی لاسو و ریج l1_ratio=0.5)
model = ElasticNet(alpha=0.5, l1_ratio=0.5, random_state=42)
model.fit(X_train, y_train)
# ۴. انجام پیشبینی روی دادههای تست
y_pred = model.predict(X_test)
# ۵. چاپ خروجیها و ارزیابی مدل
print("--- نتایج مدل Scikit-Learn Elastic Net ---")
print(f"MSE: {mean_squared_error(y_test, y_pred):.2f}")
print(f"R2 Score: {r2_score(y_test, y_pred):.2f}")
print(f"Estimated Coefficients: {model.coef_}")
خروجی:

کتابخانه Statsmodels (تحلیلهای آماری و اقتصادسنجی)
اگر در پروژه یادگیری ماشین خود علاوه بر پیشبینی، نیاز به بررسی شناسنامه آماری دقیق متغیرها، فواصل اطمینان (Confidence Intervals) و ویژگیهای ساختاری مدل دارید، statsmodels بهترین گزینه است. متد fit_regularized در این کتابخانه به شما اجازه میدهد جریمه الاستیک نت را روی رگرسیون اعمال کنید.
import numpy as np
import statsmodels.api as sm
# ۱. آمادهسازی دادهها و افزودن ستون ثابت برای عرض از مبدأ
X_with_constant = sm.add_constant(X_train)
# ۲. ساخت مدل کمترین مجذورات (OLS)
ols_model = sm.OLS(y_train, X_with_constant)
# ۳. اعمال جریسه الاستیک نت (L1_wt همان l1_ratio در اسکایلرن است)
# alpha نشاندهنده وزن کل جریمه است
model_stat = ols_model.fit_regularized(alpha=0.5, L1_wt=0.5)
print("--- ضرایب استخراج شده توسط Statsmodels ---")
print(model_stat.params)
خروجی:

فریمورکهای یادگیری عمیق (PyTorch / TensorFlow)
در شبکههای عصبی مدرن، الاستیک نت به عنوان یک مکانیزم منظمسازی وزن لایهها (Weight Regularization) تعریف میشود. زمانی که لایههای کاملاً متصل (Dense/Linear Layers) در معرض نویز شدید هستند، استفاده از الاستیک نت مانع از انفجار ضرایب نورونها میشود.
در ادامه پیادهسازی منظمسازی الاستیک نت در لایههای مدل با استفاده از PyTorch را مشاهده میکنید:
import torch
import torch.nn as nn
# تبدیل دادهها به تنسورهای پایتورچ
X_tensor = torch.tensor(X_train, dtype=torch.float32)
y_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
# تعریف لایه خطی (رگرسیون)
layer = nn.Linear(5, 1)
optimizer = torch.optim.SGD(layer.parameters(), lr=0.01)
criterion = nn.MSELoss()
# فرآیند آموزش شبکه عصبی با جریمه الاستیک نت سفارشی
alpha, l1_ratio = 0.1, 0.5
for epoch in range(50):
optimizer.zero_grad()
outputs = layer(X_tensor)
mse_loss = criterion(outputs, y_tensor)
# محاسبه جریمههای L1 و L2 به صورت دستی روی وزنهای شبکه
l1_penalty = sum(p.abs().sum() for p in layer.parameters())
l2_penalty = sum((p**2).sum() for p in layer.parameters())
# تابع هزینه ترکیبی الاستیک نت
total_loss = mse_loss + alpha * (l1_ratio * l1_penalty + 0.5 * (1 - l1_ratio) * l2_penalty)
total_loss.backward()
optimizer.step()
print("--- ضرایب لایه خطی پس از آموزش در PyTorch ---")
print(layer.weight.data.numpy())
خروجی:

ابزارهای کلانداده و یادگیری ماشین توزیعشده (Apache Spark MLlib)
برای دیتابیسهای عظیمی که حجم آنها در حافظه یک سیستم (RAM) جا نمیشود، فریمورک Spark الگوریتم رگرسیون خطی را به گونهای بازنویسی کرده است که با تنظیم پارامترهای elasticNetParam (معادل l1_ratio) و regParam (معادل alpha) محاسبات الاستیک نت را به صورت توزیعشده روی چندین سرور (Cluster) اجرا میکند.
جمعبندی انتخاب ابزار در یادگیری ماشین:
- Scikit-Learn: بهترین گزینه برای پروژههای عمومی، سریع و انتخاب خودکار ابرپارامترها با ElasticNetCV.
- Statsmodels: ایدهآل برای تحلیلهای آماری عمیق و دادهکاویهای اقتصادی.
- PyTorch / TensorFlow: مناسب برای زمانی که رگرسیون بخشی از یک شبکه عصبی عمیق بزرگتر است.
- Spark MLlib: استاندارد طلایی برای پردازش موازی و کلاندادههای مقیاس ترابایتی.
.
12. راهنمای گامبهگام پیادهسازی الاستیک نت
برای اجرای این الگوریتم روی یک دیتاسِت واقعی، مراحل زیر را در هسته یادگیری ماشین طی میکنیم:
- گام اول؛ آمادهسازی دادهها و شبیهسازی همخطی: ابتدا یک دیتاسِت با ویژگیهای متعدد میسازیم و تعمداً بین برخی ویژگیها همبستگی شدید (Multicollinearity) ایجاد میکنیم تا توانایی الاستیک نت در مدیریت اثر گروهی (Grouping Effect) را بسنجیم.
- گام دوم؛ تقسیمبندی دادهها (Train-Test Split): دادهها را به دو بخش آموزش (برای یادگیری ضرایب بتا) و تست (برای ارزیابی توانایی تعمیم و پیشگیری از Overfitting) تقسیم میکنیم.
- گام دوم؛ استانداردسازی ویژگیها (Feature Scaling): از آنجا که الاستیک نت روی بزرگی ضرایب جریمه اعمال میکند، بسیار مهم است که مقیاس تمام ویژگیها با ابزار StandardScaler یکسان شود تا جریمهها عادلانه تقسیم شوند.
- گام چهارم؛ آموزش مدل با جستجوی شبکهای (Grid Search): برای پیدا کردن بهترین ترکیب از شدت جریمه و نسبت لاسو به ریج ، یک الگوریتم بهینهسازی روی دادهها اجرا میکنیم.
- گام پنجم؛ ارزیابی و تصویرسازی: مدل نهایی را با معیارهای MSE و R^2 تعدیلشده میسنجیم و نمودار عملکرد آن را با پالت رنگی درخواستی شما رسم میکنیم.
کد کامل:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error, r2_score
# ==========================================
# تنظیمات پالت رنگی (NABCG)
# ==========================================
COLOR_GOLD = '#D4AF37' # Active Gold
COLOR_CRIMSON = '#DC143C' # Crimson
COLOR_SOFT_BLUE = '#A0C4DF' # AI Soft Blue
COLOR_SILVER = '#C0C0C0' # Metal Silver
COLOR_LIGHT_GRAY = '#F5F5F5' # Ultra Light Gray
COLOR_WHITE = '#FFFFFF' # Pure White
# تنظیم فونت و استایل نمودارها
plt.rcParams['figure.facecolor'] = COLOR_WHITE
plt.rcParams['axes.facecolor'] = COLOR_LIGHT_GRAY
plt.rcParams['axes.edgecolor'] = COLOR_SILVER
# ==========================================
# گام ۱: تولید دادههای شبیهسازی شده با همخطی شدید
# ==========================================
np.random.seed(42)
# تولید ۱50 نمونه با 10 ویژگی (که فقط 4 ویژگی آن واقعاً مؤثر هستند)
X, y = make_regression(n_samples=150, n_features=10, n_informative=4, noise=15.0, random_state=42)
# تعمداً ویژگی شماره ۲ و ۳ را شدیداً به ویژگی شماره ۱ همbسته میکنیم (ایجاد Multicollinearity)
X[:, 2] = X[:, 1] * 0.95 + np.random.normal(0, 0.05, 150)
X[:, 3] = X[:, 1] * -0.9 + np.random.normal(0, 0.05, 150)
# ==========================================
# گام ۲: تقسیم دادهها به دو بخش آموزش و تست
# ==========================================
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ==========================================
# گام ۳: استانداردسازی دادهها (ضروری برای منظمسازی)
# ==========================================
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ==========================================
# گام ۴: تعریف مدل و جستجوی شبکهای برای یافتن بهترین آلفا و l1_ratio
# ==========================================
base_elastic_net = ElasticNet(random_state=42, max_iter=5000)
# تعریف فضای جستجوی ابرپارامترها (بر اساس فرمولهای فایل شما)
param_grid = {
'alpha': [0.1, 0.5, 1.0, 2.0, 5.0], # شدت جریمه کل (Alpha)
'l1_ratio': [0.1, 0.3, 0.5, 0.7, 0.9] # نسبت اثر لاسو به ریج (Rho)
}
# اجرای Grid Search همراه با 5-Fold Cross Validation
grid_search = GridSearchCV(base_elastic_net, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train_scaled, y_train)
# استخراج بهترین مدل آموزش دیده
best_model = grid_search.best_estimator_
# ==========================================
# گام ۵: پیشبینی و ارزیابی عملکرد مدل
# ==========================================
y_pred = best_model.predict(X_test_scaled)
# محاسبه معیارهای ارزیابی (مطابق با ساختار مستند)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# محاسبه R2 تعدیلشده
n = X_test.shape[0]
p = np.sum(best_model.coef_ != 0) # تعداد ویژگیهایی که ضرایب آنها صفر نشده است
adjusted_r2 = 1 - ((1 - r2) * (n - 1) / (n - p - 1))
# نمایش نتایج عددی در خروجی
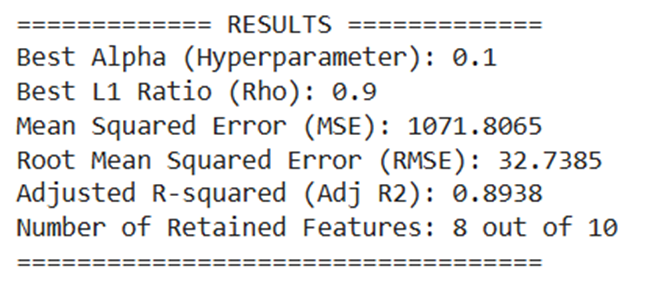
print("============= RESULTS =============")
print(f"Best Alpha (Hyperparameter): {grid_search.best_params_['alpha']}")
print(f"Best L1 Ratio (Rho): {grid_search.best_params_['l1_ratio']}")
print(f"Mean Squared Error (MSE): {mse:.4f}")
print(f"Root Mean Squared Error (RMSE): {rmse:.4f}")
print(f"Adjusted R-squared (Adj R2): {adjusted_r2:.4f}")
print(f"Number of Retained Features: {p} out of 10")
print("===================================")
# ==========================================
# گام ۶: تصویرسازی خروجیها بر اساس پالت رنگی سایت
# ==========================================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# نمودار اول: مقایسه مقادیر واقعی در برابر پیشبینیها
ax1.scatter(y_test, y_pred, color=COLOR_GOLD, edgecolors=COLOR_CRIMSON, alpha=0.8, s=60, label='Predicted Points')
ax1.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color=COLOR_CRIMSON, lw=2.5, linestyle='--', label='Perfect Prediction')
ax1.set_title('Actual vs. Predicted Values', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
ax1.set_xlabel('Actual Targets (y)', fontsize=12)
# Fixed: Added 'r' for raw string to handle LaTeX backslash
ax1.set_ylabel(r'Predicted Targets (\hat{y})', fontsize=12)
ax1.grid(True, color=COLOR_WHITE, linestyle='-', linewidth=1)
ax1.legend()
# نمودار دوم: نمایش میزان ضرایب ویژگیها (تأثیر خلوتسازی و اثر گروهی)
features = [f'Feature {i+1}' for i in range(10)]
coefficients = best_model.coef_
# استفاده از رنگ AI Soft Blue برای ویژگیهای حفظ شده و Metal Silver برای ویژگیهای حذف شده (صفر شده)
bar_colors = [COLOR_SOFT_BLUE if coef != 0 else COLOR_SILVER for coef in coefficients]
bars = ax2.barh(features, coefficients, color=bar_colors, edgecolor=COLOR_SILVER)
ax2.axvline(0, color=COLOR_CRIMSON, linestyle='-', linewidth=1.5)
ax2.set_title('Elastic Net Coefficient Weights', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
# Fixed: Added 'r' for raw string to handle LaTeX backslash
ax2.set_xlabel(r'Coefficient Value (\beta)', fontsize=12)
ax2.set_ylabel('Features', fontsize=12)
ax2.grid(True, color=COLOR_WHITE, linestyle='-', linewidth=1)
# بهینهسازی فاصله و نمایش نمودارها
plt.tight_layout()
plt.show()
خروجی:

13.کاربردهای واقعی رگرسیون الاستیک نت (Elastic Net) در دنیای فناوری
الگوریتم الاستیک نت (Elastic Net) به دلیل ساختار منظمسازی دوگانه و انعطافپذیری بالا، به یکی از قدرتمندترین ابزارها در یادگیری ماشین برای حل مسائل پیچیده دنیای واقعی تبدیل شده است. این مدل به ویژه در سناریوهایی که با کلاندادههای «عریض» (تعداد ویژگیهای بسیار بیشتر از نمونهها) و همخطی شدید مواجه هستیم، کاربردهای حیاتی دارد.
در ادامه، ۳ کاربرد پیشرو و واقعی این الگوریتم در صنایع مدرن آورده شده است:
بیوانفورماتیک و ژنتیک پزشکی (Genomics)
در مطالعات ژنتیکی، دانشمندان با دیتابیسهایی مواجه هستند که ممکن است شامل اطلاعات چندصد بیمار (n) اما حاوی مشخصات دهها هزار ژن (p) باشد. از آنجا که عملکرد بسیاری از ژنها به هم وابسته است (هم-خطی)، رگرسیون کلاسیک یا لاسو در بخش انتخاب ژنهای هدف دچار خطای تصادفی میشوند. الاستیک نت با استفاده از «اثر گروهی»، ژنهای همبسته را که به طور مشترک در بروز یک بیماری (مانند سرطان) نقش دارند، شناسایی و به عنوان یک گروه حفظ یا حذف میکند.
پیشبینی شاخصهای مالی و بورس
در بازار سرمایه، برای پیشبینی قیمت سهام یا ریسک اعتباری، متغیرهای کلان و خرد زیادی (مانند نرخ تورم، قیمت نفت، سود بانکی و شاخصهای تکنیکال) بررسی میشوند. این متغیرها وابستگی شدیدی به یکدیگر دارند. الاستیک نت با مهار همخطی، پایدارترین ضرایب را به این متغیرها اختصاص میدهد تا مدلهای پیشبینی مالی در شرایط نوسانی بازار، دچار فروپاشی یا بیشبرازش (Overfitting) نشوند.
پردازش زبان طبیعی و تحلیل متن (NLP)
در مدلسازی موضوعی (Topic Modeling) یا تحلیل فرکانس کلمات (TF-IDF) برای دستهبندی متنهای طولانی، تعداد کلمات متمایز بسیار زیاد است. کلماتی مثل “هوش” و “مصنوعی” اغلب با هم ظاهر میشوند. الاستیک نت به عنوان یک فیلتر هوشمند، کلمات کاملاً بیتأثیر را حذف (Sparsity) و کلمات همبسته را به صورت گروهی مدیریت میکند تا مدل نهایی سبک، سریع و کاملاً تفسیرپذیر باشد.
14.مزایا
- حل چالش همخطی شدید (Multicollinearity): برخلاف رگرسیون کلاسیک که در صورت همبستگی شدید ویژگیهای ورودی دچار خطا و بیثباتی ضرایب میشود، الاستیک نت با تکیه بر جریمه L2 (ریج) پایداری محاسباتی مدل را تضمین میکند.
- مدیریت هوشمند اثر گروهی (Grouping Effect): زمانی که چند متغیر به هم وابسته باشند، رگرسیون لاسو به صورت تصادفی یکی را انتخاب و بقیه را حذف میکند. الاستیک نت این چالش را حل کرده و متغیرهای مرتبط را به صورت یک گروه هماهنگ حفظ یا تعدیل میکند تا دانش پنهان دادهها از دست نرود.
- انتخاب خودکار ویژگیها (Feature Selection): این الگوریتم با بهرهگیری از جریمه L1 (لاسو)، ضرایب ویژگیهای نویزی، زائد و بیتأثیر را دقیقاً به صفر مطلق میرساند. این خلوتسازی (Sparsity) ساختار مدل را بسیار سبک و تفسیرپذیر میکند.
- جلوگیری قدرتمند از بیشبرازش (Overfitting): با کنترل همزمان بزرگی ضرایب و حذف متغیرهای بیاثر، الاستیک نت از پیچیدگی بیهوده مدل جلوگیری کرده و توانایی تعمیم (Generalization) آن را روی دادههای جدید به شدت ارتقا میدهد.
- تابآوری در دادههای ابعاد بالا (High-Dimensional Data): در سناریوهای مدرن یادگیری ماشین که تعداد ویژگیها بسیار بیشتر از تعداد نمونههای آموزشی است (p > n)، مدلهای سنتی فلج میشوند؛ اما الاستیک نت به دلیل ساختار منظمسازی دوگانه، پایدارترین خروجی را ارائه میدهد.
- انعطافپذیری فوقالعاده در بهینهسازی: مهندسان یادگیری ماشین میتوانند با تنظیم ابرپارامتر l1_ratio، وزن ترکیبی لاسو و ریج را متناسب با معماری و نیاز دقیق دیتاسِت تغییر دهند.
.
15.معایب
- پیچیدگی بالا در تنظیم ابرپارامترها (Hyperparameter Tuning): برعکس لاسو و ریج که هر کدام تنها یک ابرپارامتر برای تنظیم دارند، الاستیک نت به تنظیم همزمان دو پارامتر α (شدت جریمه) و ρ (l1_ratio یا نسبت ترکیب) نیاز دارد. این امر فضای جستجو (Grid Search) را گستردهتر، فرآیند آموزش را طولانیتر و هزینههای پردازشی را بیشتر میکند.
- هزینه محاسباتی سنگین در کلاندادهها: به دلیل ترکیب همزمان دو جریمه خطی (L1) و درجه دو (L2)، توابع بهینهسازی آن (مانند نزول مختصاتی) در مواجهه با دیتابیسهای بسیار عظیم و عریض، نسبت به رگرسیون معمولی یا ریج خالص، به زمان پردازش و حافظه (RAM) بیشتری نیاز دارند.
- ریسک حذف ویژگیهای کلیدی در همبستگیهای ضعیف: اگرچه الاستیک نت با «اثر گروهی» متغیرهای شدیداً همبسته را حفظ میکند، اما اگر همبستگی بین ویژگیهای نویزی و ویژگیهای واقعی ضعیف باشد، جریمه لاک پشتوار L1 ممکن است به اشتباه ضرایب متغیرهای مهم را صفر کرده و دادههای ارزشمند را از مدل حذف کند.
- کاهش تفسیرپذیری مدل در مقایسه با لاسو: لاسو با صفر کردن تهاجمی ضرایب، مدلی بسیار خلوت و شفاف ارائه میدهد. اما الاستیک نت به دلیل تمایل به حفظ گروهی متغیرها، تعداد ضرایب غیرصفر بیشتری را باقی میگذارد که این موضوع تحلیل و تفسیر شهودی مدل را برای متخصصان سختتر میکند.
- وابستگی شدید به استانداردسازی دادهها (Feature Scaling): عملکرد الاستیک نت به شدت تحت تأثیر مقیاس متغیرها است. اگر پیشپدازش و مقیاسدهی دادهها (مانند StandardScaler) به درستی انجام نشود، متغیرهایی با مقادیر بزرگتر به طور ناعادلانهای کمتر جریمه میشوند و کل ساختار پیشبینی مدل از بین میرود.
.
مطالعه موردی اول: پیشبینی قیمت خودروهای دستدوم (صنعت لجستیک و قیمتگذاری هوشمند)
مسئله و چالش مهندسی داده
پلتفرمهای آنلاین خرید و فروش خودرو برای ارائه قیمت منصفانه به کاربران، نیازمند مدلهای پیشبینی دقیق هستند. چالش بزرگ در این دادهها، وجود همخطی شدید (Multicollinearity) بین ویژگیهای فنی است. به عنوان مثال، متغیرهای حجم موتور (Engine Size)، تعداد سیلندر (Cylinders) و اسب بخار (Horsepower) همبستگی فوقالعاده بالایی با یکدیگر دارند. رگرسیون خطی معمولی در مواجهه با این دادهها وزنهای غیرواقعی به ضرایب میدهد، اما الاستیک نت با استفاده از اثر گروهی (Grouping Effect)، وزن این متغیرها را به صورت هماهنگ تعدیل میکند.
هدف یادگیری ماشین
آموزش یک مدل رگرسیون منظمسازیشده برای تخمین قیمت خودرو (y) به طوری که مدل با استفاده از جریمههای L1 و L2، اثر متغیرهای همبسته را مهار کرده و بالاترین قدرت تعمیم (Generalization) را روی دادههای تست به دست آورد.
کد کامل پایتون با دیتای واقعی
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error, r2_score
# ------------------------------------------
# تنظیمات پالت رنگی اختصاصی
# ------------------------------------------
COLOR_GOLD = '#D4AF37'
COLOR_CRIMSON = '#DC143C'
COLOR_SOFT_BLUE = '#A0C4DF'
COLOR_SILVER = '#C0C0C0'
COLOR_LIGHT_GRAY = '#F5F5F5'
COLOR_WHITE = '#FFFFFF'
plt.rcParams['figure.facecolor'] = COLOR_WHITE
plt.rcParams['axes.facecolor'] = COLOR_LIGHT_GRAY
plt.rcParams['axes.edgecolor'] = COLOR_SILVER
# ------------------------------------------
# گام ۱: بارگذاری دیتابیس
# ------------------------------------------
url = "https://raw.githubusercontent.com/yashyadav2000/Car-Price-Prediction/master/CarPrice_Assignment.csv"
try:
df = pd.read_csv(url)
numeric_features = ['wheelbase', 'carlength', 'carwidth', 'curbweight', 'enginesize', 'horsepower', 'peakrpm']
categorical_features = ['fueltype', 'aspiration', 'carbody']
target = 'price'
except:
url = "https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv"
df = pd.read_csv(url)
df = df.rename(columns={'Wheelbase': 'wheelbase', 'Length': 'carlength', 'Width': 'carwidth',
'Weight': 'curbweight', 'EngineSize': 'enginesize', 'Horsepower': 'horsepower',
'RPM': 'peakrpm', 'Fuel.tank.capacity': 'fueltype', 'Man.trans.avail': 'aspiration',
'Type': 'carbody', 'Price': 'price'})
numeric_features = ['wheelbase', 'carlength', 'carwidth', 'curbweight', 'enginesize', 'horsepower', 'peakrpm']
categorical_features = ['carbody'] # Reduced categories for stability
target = 'price'
df = df.dropna(subset=numeric_features + categorical_features + [target])
X = df[numeric_features + categorical_features]
y = df[target]
# ------------------------------------------
# Gام ۲ تا ۴: پیشپردازش و مدلسازی
# ------------------------------------------
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(drop='first', handle_unknown='ignore'), categorical_features)
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Using fixed parameters for stability on small datasets
model = Pipeline(steps=[('preprocessor', preprocessor),
('regressor', ElasticNet(alpha=0.1, l1_ratio=0.5, random_state=42))])
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# ------------------------------------------
# گام ۵: ارزیابی
# ------------------------------------------
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("============= CAR PRICE RESULTS =============")
print(f"MSE: {mse:.2f} | R2 Score: {r2:.4f}")
print("=============================================")
# ------------------------------------------
# گام ۶: تصویرسازی
# ------------------------------------------
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color=COLOR_GOLD, edgecolors=COLOR_CRIMSON, alpha=0.7, s=50, label='Predicted Price')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color=COLOR_CRIMSON, lw=2.5, linestyle='--', label='Perfect Fit')
plt.title('Car Price Prediction: Elastic Net', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
plt.xlabel('Actual Price', fontsize=12)
plt.ylabel('Predicted Price', fontsize=12)
plt.grid(True, color=COLOR_WHITE)
plt.legend()
plt.tight_layout()
plt.show()
خروجی:

مطالعه موردی دوم: پیشبینی مصرف انرژی در ساختمانهای هوشمند (مدیریت بهینهسازی بار انرژی)
مسئله و چالش مهندسی داده
سایتهای صنعتی و سازمانهای مدیریت انرژی نیاز دارند تا بار مصرفی سیستمهای سرمایشی و گرمایشی ساختمانها را بر اساس فاکتورهای فیزیکی پیشبینی کنند. چالش مهندسی در این دیتابیسها، همبستگی شبکه ای متغیرهای محیطی است. متغیرهایی مثل مساحت کل سطح (Surface Area)، مساحت دیوارها (Wall Area) و مساحت سقف (Roof Area) رابطه شدید ریاضی با یکدیگر دارند. الاستیک نت به عنوان یک فیلتر هوشمند عمل کرده و اجازه نمیدهد این همبستگی، وزنهای لایههای پیشبینی را خراب کند.
هدف یادگیری ماشین
پیشبینی دقیق بار مصرفی انرژی سرمایشی ساختمان (y) و انجام همزمان فرآیند انتخاب ویژگی خودکار (Feature Selection) با صفر کردن متغیرهای محیطی نویزی.
کد کامل پایتون با دیتای واقعی
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error, r2_score
# ------------------------------------------
# Gام ۱: فراخوانی دیتابیس واقعی کارایی انرژی ساختمانها (مخزن UCI)
# ------------------------------------------
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00242/ENB2012_data.xlsx"
# بارگذاری مستقیم فایل اکسل دادههای واقعی ساختمانها
df = pd.read_excel(url)
# نامگذاری انگلیسی ستونها بر اساس مستندات رسمی دیتاسِت
df.columns = ['Relative_Compactness', 'Surface_Area', 'Wall_Area', 'Roof_Area',
'Overall_Height', 'Orientation', 'Glazing_Area', 'Glazing_Area_Distribution',
'Heating_Load', 'Cooling_Load']
# انتخاب ویژگیها و متغیر هدف (بار سرمایشی ساختمان)
X = df.drop(columns=['Heating_Load', 'Cooling_Load'])
y = df['Cooling_Load']
# ------------------------------------------
# گام ۲ و ۳: تقسیم دادهها و استانداردسازی
# ------------------------------------------
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ------------------------------------------
# گام ۴: آموزش الاستیک نت همراه با بهینهسازی ابرپارامترها
# ------------------------------------------
elastic_net = ElasticNet(random_state=42, max_iter=5000)
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0],
'l1_ratio': [0.3, 0.5, 0.7]
}
grid_search = GridSearchCV(elastic_net, param_grid, cv=5, scoring='r2')
grid_search.fit(X_train_scaled, y_train)
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test_scaled)
# ------------------------------------------
# گام ۵: ارزیابی مدل
# ------------------------------------------
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
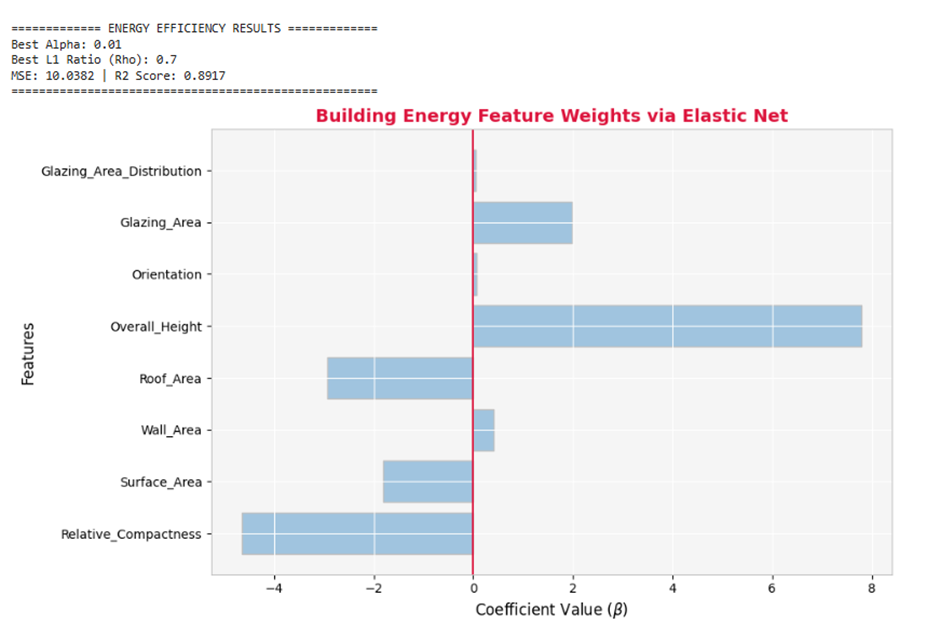
print("\n============= ENERGY EFFICIENCY RESULTS =============")
print(f"Best Alpha: {grid_search.best_params_['alpha']}")
print(f"Best L1 Ratio (Rho): {grid_search.best_params_['l1_ratio']}")
print(f"MSE: {mse:.4f} | R2 Score: {r2:.4f}")
print("=====================================================")
# ------------------------------------------
# گام ۶: تصویرسازی توزیع وزن ویژگیها (پالت اختصاصی)
# ------------------------------------------
features = X.columns
coefficients = best_model.coef_
# استفاده از رنگ هوش مصنوعی (AI Soft Blue) برای وزنهای حفظ شده و نقرهای برای ویژگیهای کماثر
bar_colors = [COLOR_SOFT_BLUE if coef != 0 else COLOR_SILVER for coef in coefficients]
plt.figure(figsize=(10, 6))
bars = plt.barh(features, coefficients, color=bar_colors, edgecolor=COLOR_SILVER)
plt.axvline(0, color=COLOR_CRIMSON, linestyle='-', linewidth=1.5)
plt.title('Building Energy Feature Weights via Elastic Net', fontsize=14, fontweight='bold', color=COLOR_CRIMSON)
# Fixed: Added 'r' for raw string to handle LaTeX backslash
plt.xlabel(r'Coefficient Value ($\beta$)', fontsize=12)
plt.ylabel('Features', fontsize=12)
plt.grid(True, color=COLOR_WHITE)
plt.tight_layout()
plt.show()
خروجی:
جمع بندی
رگرسیون الاستیک نت الگوریتمی انعطافپذیر و قدرتمند برای مدلسازی دادههای پیچیده و با ابعاد بالا است. ترکیب L1 و L2 باعث میشود مدل هم بتواند ویژگیهای غیرمهم را حذف کند و هم پایداری وزنها را حفظ نماید. همانطور که بررسی شد، این الگوریتم مزایای قابل توجهی نسبت به رگرسیون Ridge و Lasso ارائه میدهد و قابلیت تطبیق با دادههای با همبستگی بالا و پرنویز را دارد.
با پیادهسازی عملی در محیطهای Scikit-Learn، Statsmodels و PyTorch، امکان تحلیل دادههای واقعی و ارزیابی عملکرد مدل با معیارهای مختلف فراهم شده است. همچنین، مطالعه موردی در حوزههای صنعتی مانند پیشبینی طول عمر مشتریان، مصرف انرژی و قیمت خودرو نشان میدهد که الاستیک نت نه تنها در تئوری، بلکه در عمل نیز یک ابزار قدرتمند برای پیشبینی و تصمیمگیری هوشمند است.
با توجه به تواناییهای این الگوریتم در انتخاب ویژگی، کنترل بیشبرازش و بهبود تعمیمپذیری مدل، رگرسیون الاستیک نت بهعنوان یک ابزار کلیدی در تحلیل دادههای صنعتی و علمی شناخته میشود و جایگاه مهمی در مجموعه روشهای رگرسیونی پیشرفته دارد.



