

1.مقدمه
در خوشهبندی دادهها، هدف اصلی پیدا کردن گروههایی از نمونههاست که از نظر ویژگیها به یکدیگر شباهت بیشتری دارند. بسیاری از الگوریتمهای رایج مانند K-Means برای دادههایی عملکرد خوبی دارند که خوشهها ساختاری نسبتاً ساده، فشرده و کروی داشته باشند. اما در دادههای واقعی، خوشهها همیشه چنین شکل منظمی ندارند؛ ممکن است کشیده، نامتقارن، مارپیچی، دارای نویز یا شامل نقاط پرت باشند. در چنین شرایطی، استفاده از یک مرکز واحد برای نمایش کل خوشه میتواند باعث کاهش دقت و مرزبندی اشتباه بین گروهها شود.
الگوریتم CURE یا Clustering Using REpresentatives برای حل همین چالش طراحی شده است. این الگوریتم به جای آنکه هر خوشه را فقط با یک مرکز هندسی نمایش دهد، از چندین نقطه نماینده استفاده میکند. این نقاط از بخشهای مختلف خوشه انتخاب میشوند و سپس با استفاده از ضریب انقباض به سمت مرکز خوشه حرکت داده میشوند تا اثر نویز و دادههای پرت کاهش پیدا کند. به همین دلیل، CURE میتواند شکل واقعی خوشهها را بهتر حفظ کند و در تشخیص خوشههای غیرکروی و پیچیده عملکرد دقیقتری نسبت به بسیاری از روشهای مرکزگرا داشته باشد.
اهمیت CURE زمانی بیشتر مشخص میشود که با دادههای حجیم، نامنظم و دارای نویز سروکار داشته باشیم. این الگوریتم با ترکیب روشهای سلسلهمراتبی، نمونهبرداری تصادفی، پارتیشنبندی و استفاده از نقاط نماینده، تلاش میکند میان دقت خوشهبندی و مقیاسپذیری تعادل برقرار کند. به همین دلیل، CURE در حوزههایی مانند تحلیل دادههای مکانی، تشخیص ناهنجاری، پردازش تصویر، تحلیل رفتار مشتریان و خوشهبندی دادههای زیستی کاربرد قابل توجهی دارد.
در این مقاله، ابتدا مفهوم الگوریتم CURE و ضرورت استفاده از آن بررسی میشود. سپس مراحل اجرای الگوریتم، مبانی ریاضی، پارامترهای مهم، مثالهای کاربردی، پیادهسازی در پایتون، مقایسه با سایر الگوریتمهای خوشهبندی، مزایا، معایب و مسیرهای آینده این روش توضیح داده خواهد شد.
2.تعریف
الگوریتم CURE به جای تکیه بر یک «مرکز واحد» (Centroid) برای تعریف هر خوشه، از مجموعهای از نقاط نماینده (Representative Points) استفاده میکند. این نقاط به دقت از سطح خوشه انتخاب میشوند و سپس با یک ضریب مشخص (Shrink Factor) به سمت مرکز خوشه «منقبض» میشوند.
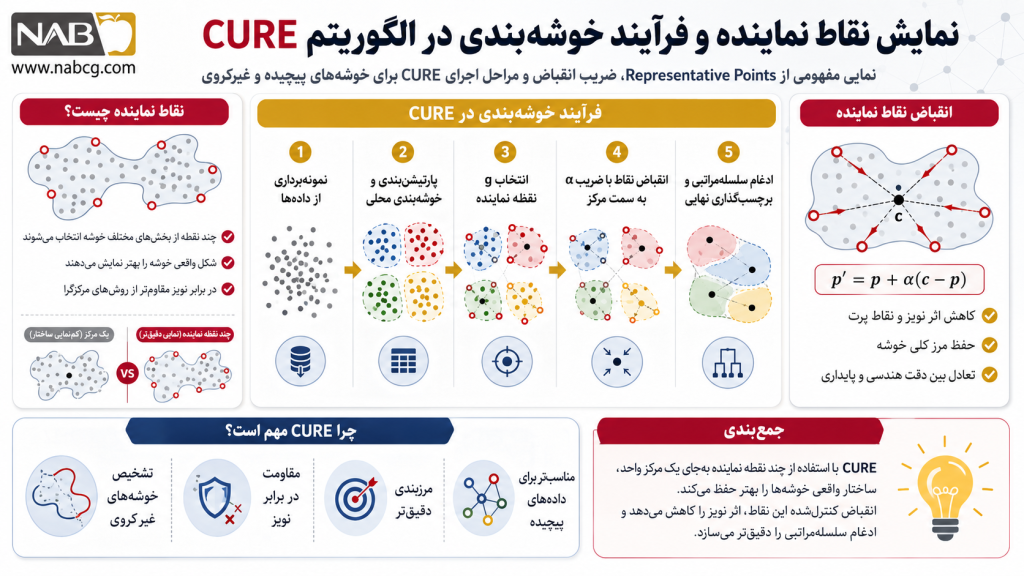
مثال
تصور کنید میخواهید دستههای مختلف «ابر» را در آسمان دستهبندی کنید.
- الگوریتمهای قدیمی (مثل K-Means): سعی میکنند برای هر ابر یک نقطه مرکزی در نظر بگیرند و هر چه به آن نقطه نزدیکتر است را جزو آن ابر بدانند. نتیجه؟ ابزارهای ابرهای کشیده یا مارپیچ به درستی شناسایی نمیشوند و بخشی از یک ابر به اشتباه به ابر دیگری ملحق میشود.
- الگوریتم CURE: به جای یک نقطه مرکزی، چندین نقطه از بخشهای مختلف همان ابر (مثلاً لبهها و وسط) را انتخاب میکند. این نقاط به سمت مرکز ابر جذب میشوند و تصویر دقیقتری از شکل واقعی آن ابر ایجاد میکنند. حالا حتی اگر ابر شما به شکل یک “S” بزرگ باشد، CURE آن را به عنوان یک خوشه واحد و دقیق شناسایی میکند.
.
3.چرا استفاده از CURE یک ضرورت است؟
- عبور از محدودیت هندسی الگوریتمهای سنتی: بسیاری از دادههای دنیای واقعی (مانند الگوهای ترافیکی یا توزیعهای بیولوژیکی) اصلاً «کروی» نیستند. استفاده از الگوریتمهایی مثل K-Means برای این دادهها، عملاً به معنای نادیده گرفتن ماهیت واقعی دادههاست. CURE تنها راهکار هوشمندانه برای درک این ساختارهای پیچیده است.
- حل بحران مقیاسپذیری در دادههای سلسلهمراتبی: در خوشهبندی سلسلهمراتبی کلاسیک، با افزایش دادهها، حافظه بهسرعت اشباع میشود. ضرورت استفاده از CURE در اینجا مشخص میشود؛ چرا که با استفاده از «نقاط نماینده» به جای «تکتک نقاط»، بار محاسباتی را به شدت کاهش داده و امکان تحلیل دیتابیسهای حجیم را فراهم میکند.
- پایداری در برابر نویز و دادههای پرت: در محیطهای صنعتی (مثل سنسورهای IoT)، دادهها همواره با نویز همراه هستند. CURE به دلیل فرآیند «انقباض» (Shrinking)، ناخودآگاه نویزها را سرکوب کرده و اجازه نمیدهد دادههای نامعتبر، شکل خوشههای اصلی را مخدوش کنند.
- دقت در مرزبندی خوشهها: زمانی که خوشهها در نزدیکی یکدیگر قرار دارند، الگوریتمهای مرکزگرا مرزها را به اشتباه ترسیم میکنند. ضرورت CURE در اینجا دیده میشود که با توزیع نقاط نماینده در محیط خوشه، دقیقترین مرزهای ممکن را بین گروههای داده ترسیم میکند.
.
4.الگوریتم CURE چگونه کار میکند؟
الگوریتم CURE با عبور از رویکردهای مرکزگرایانه سنتی (مانند K-Means)، از استراتژی «نمایندهگرایی هندسی» استفاده میکند. این روش که در قلب دادهکاوی مدرن جای دارد، با مدلسازی ساختار خوشهها بهجای تکیه بر میانگینِ ساده، دقت یادگیری مدل را در مواجهه با دادههای غیرخطی تضمین میکند.
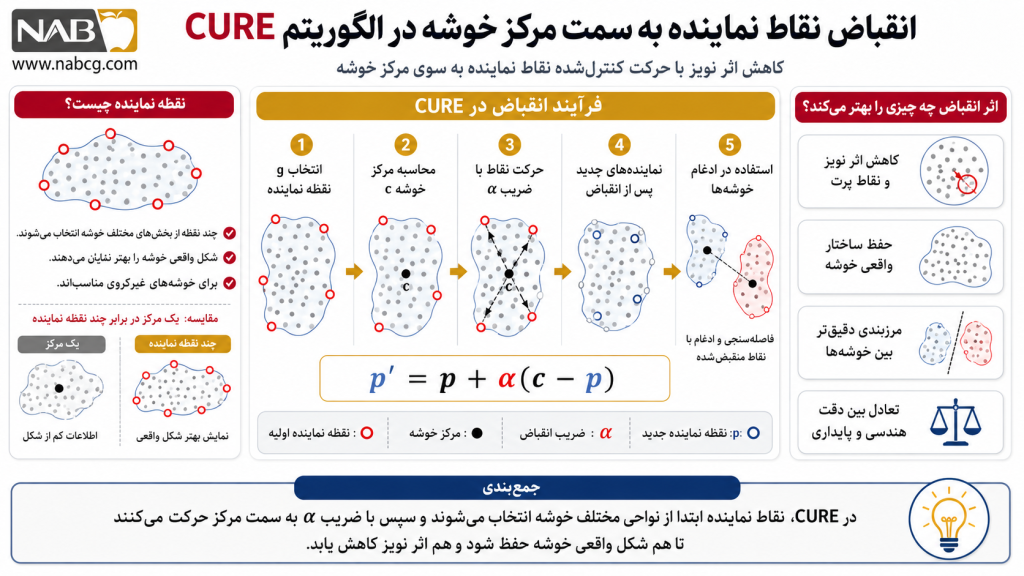
فرآیند عملیاتی این الگوریتم در ۵ لایه تخصصی به شرح زیر است:
- پیشپردازش و نمونهبرداری هوشمند
- پارتیشنبندی و خوشهبندی محلی
- انتخاب و انقباض نقاط نماینده
- ادغام سلسلهمراتبی
- برچسبگذاری نهایی
.
پیشپردازش و نمونهبرداری هوشمند
در اولین گام، CURE یک زیرمجموعه تصادفی (Random Sample) از دیتابیس بزرگ استخراج میکند. در یادگیری ماشین، این مرحله به عنوان یک تکنیک کاهش ابعاد محاسباتی عمل میکند. این کار تضمین میکند که الگوریتم حتی در محیطهای با محدودیت حافظه (RAM)، مقیاسپذیری بالایی داشته باشد و از “انفجار محاسباتی” در کلاندادهها جلوگیری شود.
پارتیشنبندی و خوشهبندی محلی
نمونه استخراجشده به p پارتیشن تقسیم میشود. در هر پارتیشن، الگوریتم به صورت مستقل خوشهبندی محلی را انجام میدهد. این مرحله باعث میشود خوشههای اولیه (Intermediate Clusters) در مقیاس کوچک شکل بگیرند که عملاً به شناسایی ناهنجاریها و حذف نویزهای اولیه در سطح محلی کمک میکند؛ تکنیکی که در دادهکاوی برای پاکسازی دادهها پیش از مدلسازی نهایی بسیار حیاتی است.
انتخاب و انقباض نقاط نماینده (Representative Points)
از هر خوشه، g نقطه که بیشترین فاصله را از یکدیگر دارند انتخاب میشوند. این نقاط «اسکلت هندسی» خوشه را تشکیل میدهند. سپس، این نقاط با ضریب انقباض α به سمت مرکز جرم (Centroid) خوشه کشیده میشوند. این عمل باعث میشود که حتی اگر خوشهای دارای نویز حاشیهای باشد، تأثیر آن در ادغامهای بعدی تعدیل شود.
ادغام سلسلهمراتبی (Agglomerative Merging)
CURE در این مرحله، خوشههایی را که نقاط نماینده آنها کمترین فاصله اقلیدسی را دارند، با هم ادغام میکند. برخلاف روشهای سنتی، در اینجا فاصله خوشه به حداقل فاصله بین جفتهای نقاط نماینده تعریف میشود که اجازه میدهد خوشههای غیرکروی (مانند الگوهای مارپیچی یا کشیده) بهدرستی ادغام شوند.
برچسبگذاری نهایی (Labeling)
پس از تثبیت خوشهها در مرحله سلسلهمراتبی، الگوریتم دادههای باقیمانده (که در نمونهبرداری اولیه نبودند) را به نزدیکترین خوشه تخصیص میدهد. این مرحله که اصطلاحاً Assignment نام دارد، مدل را برای پیشبینی دستهبندی دادههای جدید در پروژههای یادگیری ماشین آماده میکند.
اهمیت این رویکرد در یادگیری ماشین
تفاوت بنیادین CURE در اینجا مشخص میشود که این الگوریتم تنها یک ابزار دادهکاوی نیست؛ بلکه یک مدلساز ساختار هندسی است. با ترکیب نمونهبرداری تصادفی و پارتیشنبندی، CURE نه تنها نویزها را مدیریت میکند، بلکه ماهیت پیچیده خوشهها را حفظ کرده و به مدل نهایی اجازه میدهد تا روابط غیرخطی موجود در فضای ویژگیها (Feature Space) را با دقت بسیار بیشتری نسبت به الگوریتمهای افرازی (Partitioning) درک کند.
.
5.مبانی ریاضی و پارامترهای الگوریتم CURE
ریاضیات CURE بر پایه کاهش اثرات نویز از طریق مدیریت هندسی فواصل استوار است. برخلاف الگوریتمهای سنتی که خوشهها را صرفاً با یک نقطه (مرکز) تعریف میکنند، CURE از فضای ویژگیهای چندنقطهای بهره میبرد تا ساختار واقعی خوشهها را در فضای ویژگیها (Feature Space) حفظ کند.
متغیرهای کنترلی و پیکربندی مدل
عملکرد CURE توسط دو پارامتر کلیدی تنظیم میشود:
- پارامتر g (تعداد نقاط نماینده Number of Representative Points-):
این پارامتر «وضوح هندسی» (Resolution) خوشه را تعیین میکند.
- نقش: هرچه g بزرگتر باشد، خوشه توانایی نمایش انحناها و جزئیات پیچیده را دارد.
- تعادل: مقادیر بیش از حد کوچک، خوشه را بیش از حد ساده کرده و ماهیت غیرکروی آن را از دست میدهند.
- ضریب انقباض α (Shrink Factor):
این پارامتر میزانِ “مقاومت در برابر نویز” را کنترل میکند (1 ≥ α ≥ 0).
- شرط α → 0: نقاط نماینده در لبهها باقی میمانند. این امر الگوریتم را به Single-Linkage نزدیک کرده و به جزئیات بسیار حساس میکند (آسیبپذیری در برابر نویز).
- شرط α → 1: نقاط نماینده به مرکز جرم سوق مییابند. این عمل نویزها را سرکوب کرده و ساختار را به سمت کرویسازی (شبیه به K-Means) ساده میکند.
.
فرمولبندی معیار فاصله (Cluster Proximity)
فاصله بین دو خوشه C1 و C2 با استفاده از نقاط نماینده بهصورت زیر تعریف میشود:
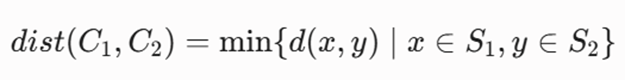
- dist(C1, C2): فاصله خوشهای بین دو خوشه C1 و C2.
- S1 و S2: مجموعهی نقاط نماینده در خوشه اول و دوم.
- x, y: نقاطی از مجموعههای نماینده S1 و. S2
- d(x, y): فاصله اقلیدسی (Euclidean Distance) در فضای n-بعدی.
فرمول انتقال نقاط نماینده (Shrinking Procedure)
برای حذف اثرات نامطلوب دادههای پرت، نقاط نماینده بهصورت زیر به سمت مرکز خوشه منتقل میشوند:
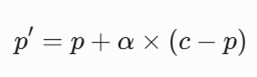
- p: نقطه نماینده اولیه انتخاب شده از سطح خوشه.
- c: مرکز جرم (Centroid) خوشه C.
- α: ضریب انقباض (Shrink Factor)؛ میزان جابجایی نقطه.
- p’: نقطه نماینده جدید جهت استفاده در محاسبات ادغام.
.
تحلیل پیچیدگی محاسباتی (Computational Complexity)
برای تکمیل مبانی علمی، لازم است به بهرهوری الگوریتم اشاره کنیم:
- پیچیدگی زمانی: در حالت پایه، پیچیدگی زمانی CURE با استفاده از ساختار Heap برابر با O(n^2 log n) است.
- بهینهسازی: با استفاده از نمونهبرداری تصادفی (Random Sampling) و پارتیشنبندی، این پیچیدگی به O(n . log n) کاهش مییابد.
این کاهش پیچیدگی، CURE را از یک روش نظری به ابزاری قدرتمند برای دیتابیسهای عظیم در محیطهای تولیدی (Production) تبدیل کرده است. این رویکرد ترکیبی، تضاد کلاسیک «حفظ هندسه» و «سرعت محاسباتی» را در دادهکاوی حل میکند.
یک ویژگی کلیدی CURE استفاده از Representative Points به جای مرکز خوشه (Centroid) است. هر خوشه با مجموعهای از نقاط نماینده (Representative Points) تعریف میشود که با روشهای نمونهگیری و Shrinking ترکیب میشوند.
- مزیت: مقاومت بیشتر در برابر دادههای پرت و خوشههای با شکل نامنظم نسبت به K-Means.
- تفاوت با K-Means: در K-Means مرکز خوشه میانگین همه نمونههاست و به دادههای پرت حساس است؛ در حالی که Representative Points نقاط واقعی داده هستند و اثر دادههای پرت کاهش مییابد.
.
6.مثال عددی
.
مثال ۱: مفهوم انقباض و هدف α
صورت مسئله: خوشهای با مرکز c = (5, 5) داریم. نقطه مرزی خوشه p = (10, 10) است. ضریب انقباض α = 0.4 در نظر گرفته شده است. نقطه نماینده جدید p’ کجاست؟ توضیح دهید چرا این عملیات در CURE حیاتی است؟
- داده ورودی: p=(10,10), c=(5,5), α =0.4
- حل گامبهگام:
فرمول انقباض:

- پاسخ نهایی: نقطه نماینده جدید (8, 8) است.
- تفسیر نتیجه: عملیات انقباض باعث میشود نقاط حاشیهای (که ممکن است نویز باشند) به سمت هسته اصلی خوشه رانده شوند. این کار باعث میشود در زمان محاسبه فاصله بین دو خوشه، نقاط پرتِ بسیار دور، تأثیر تخریبی نداشته باشند.
.
مثال ۲: معیار فاصله (Cluster Proximity)
صورت مسئله: دو خوشه C1 و C2 داریم. مجموعهی نقاط نماینده S1 = {(1, 2), (2,1)} و S2 = {(5, 6), (6,5)} است. فاصله بین این دو خوشه را با استفاده از معیار CURE محاسبه کنید.
- داده ورودی: نقاط نماینده S1 و S2
- حل گامبهگام:
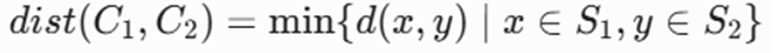
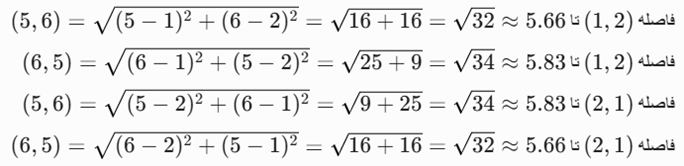
- پاسخ نهایی: حداقل فاصله 32√ یا 5.66 است.
- CURE با استفاده از نزدیکترین جفت نقاط نماینده، اجازه میدهد حتی اگر خوشهها دارای شکلهای پیچیده باشند، نزدیکترین مرز آنها تشخیص داده شود.
.
مثال ۳: انتخاب پارامتر g و هندسه
صورت مسئله: اگر بخواهیم یک خوشه به شکل “حلقه” (Ring) را خوشهبندی کنیم:
الف) انتخاب g=1 چه مشکلی ایجاد میکند؟
ب) انتخاب g خیلی بزرگ چه تاثیری بر عملکرد الگوریتم دارد؟
- پاسخ:
الف) اگر g=1 باشد، عملاً الگوریتم به Centroid-based تبدیل میشود. برای یک شکل حلقهای، مرکز حلقه در فضای خالی (خارج از دادهها) قرار میگیرد و خوشه بهدرستی شناسایی نمیشود.
ب) اگر g خیلی بزرگ باشد، هزینه محاسباتی (O(n^2 log n)) به شدت افزایش مییابد و الگوریتم زمان بسیار زیادی صرف مقایسه تکتک نقاط در فواصل ریز میکند، که باعث کاهش کارایی در دادههای بزرگ میشود.
- تفسیر نتیجه: انتخاب بهینه g نقطه تعادل بین «وضوح هندسی» و «کارایی محاسباتی» است.
.
مثال ۴: مقایسه با سایر روشها
صورت مسئله: فرض کنید دیتابیسی از رفتارهای کاربران دارید که شامل تعداد زیادی نویز است. چرا در مرحله پیشپردازش CURE، استفاده از «نمونهبرداری تصادفی» (Random Sampling) یک مرحله کلیدی برای مدیریت حافظه و سرعت است؟
- پاسخ:
۱. مدیریت حافظه: کل دیتابیس ممکن است در RAM جا نشود. نمونهبرداری حجم محاسبات اولیه را به اندازهای میرساند که در حافظه قابل پردازش باشد.
۲. فیلتر نویز: نمونهبرداری تصادفی میتواند به الگوریتم کمک کند تا ساختار کلی (Global Structure) را بدون درگیری با تکتک نویزهای موجود در کل دیتابیس تشخیص دهد.
۳. سرعت: ادغامهای سلسلهمراتبی O(n^2) هستند. کاهش n به nsample به صورت نمایی سرعت را افزایش میدهد.
.
7.کاربرد
- تحلیل دادههای جغرافیایی و نقشهبرداری: برخلاف الگوریتمهای مرکزگرا، CURE بهراحتی میتواند خوشههایی با اشکال غیرکروی (مانند مسیرهای رودخانه، مرزهای سیاسی یا الگوهای توزیع جمعیت در شهرهای نامنظم) را شناسایی کند.
- تحلیل بازاریابی و رفتارهای خرید: مشتریان همیشه در گروههای دایرهای قرار نمیگیرند .CURE به سازمانها کمک میکند تا “بازارهای گوشهای” (Niche Markets) با رفتارهای خرید غیرخطی و پراکنده را شناسایی کنند که از دید مدلهای ساده پنهان میمانند.
- تشخیص ناهنجاری (Anomaly Detection): به دلیل فرآیند انقباض (Shrinking) نقاط نماینده، CURE در برابر نقاط پرت (Outliers) بسیار مقاوم است. این ویژگی در شناسایی تراکنشهای مشکوک بانکی یا خرابی سنسورهای صنعتی که در حاشیه توزیع داده قرار دارند، بسیار کارآمد است.
- خوشهبندی دادههای زیستی: در حوزه ژنتیک و بیوانفورماتیک، توزیع دادههای پروتئینی معمولاً پیچیده است CURE. برای گروهبندی توالیهایی که دارای روابط غیرخطی هستند، یکی از انتخابهای اصلی محققان محسوب میشود.
.
8.مطالعه موردی
.
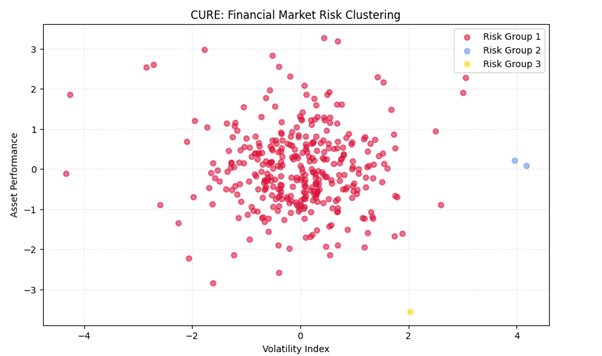
مطالعه موردی اول: شناسایی خوشههای ریسک در بازار سهام (Financial Market Risk Clustering)
مسئله و چالش: در بازارهای مالی، نوسانات قیمت سهام شرکتها به هیچوجه کروی یا قابل پیشبینی با میانگینهای ساده نیست. الگوریتمهای سنتی مانند K-Means به دلیل «نویز شدید» و «حساسیت بالا به مقادیر پرت»، شرکتهایی که رفتار غیرعادی (اما مهم) دارند را به عنوان نویز حذف میکنند یا به اشتباه در گروههای اشتباه قرار میدهند.
هدف: استخراج خوشههایی از شرکتهای بازار سهام که رفتارهای نوسانیِ مشابه و «غیرخطی» دارند تا به مدیران ریسک کمک کند سبد سهام خود را متنوعسازی کنند.
پیادهسازی (پایتون):
import numpy as np
import matplotlib.pyplot as plt
from pyclustering.cluster.cure import cure
from sklearn.preprocessing import StandardScaler
# شبیهسازی دادههای نوسانات سهام (شبیه به دیتاستهای واقعی)
np.random.seed(42)
data = np.random.normal(0, 1, (300, 2))
# اضافه کردن نویز برای شبیهسازی بازار واقعی
noise = np.random.normal(0, 2, (50, 2))
data = np.vstack([data, noise])
# نرمالسازی دادهها (بسیار مهم برای تحلیلهای مالی)
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# اجرای الگوریتم CURE با پارامترهای بهینه
cure_instance = cure(data_scaled, 3, number_represent_points=20, compression=0.4)
cure_instance.process()
clusters = cure_instance.get_clusters()
# مصورسازی نتایج با پالت اختصاصی
colors = ['#DC143C', '#6495ED', '#FFD700'] # Crimson, Soft Blue, Active Gold
plt.figure(figsize=(10, 6))
for idx, cluster in enumerate(clusters):
pts = data_scaled[cluster]
plt.scatter(pts[:, 0], pts[:, 1], color=colors[idx % 3], alpha=0.6, label=f'Risk Group {idx+1}')
plt.title('CURE: Financial Market Risk Clustering')
plt.xlabel('Volatility Index')
plt.ylabel('Asset Performance')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.3)
plt.show()خروجی:
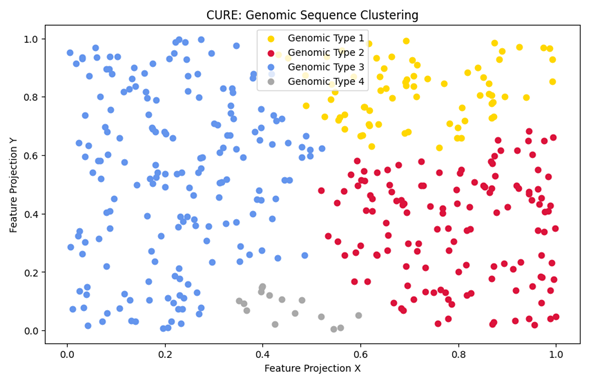
مطالعه موردی دوم: خوشهبندی توالیهای ژنتیکی (Genomic Sequence Analysis)
مسئله و چالش: توالیهای DNA دارای ساختارهای بسیار پیچیده و تودرتو هستند. دادههای ژنومیک در فضاهای ابعادی بالا (High-Dimensional) قرار دارند و مرزهای بین خوشههای مختلفِ بیولوژیکی بسیار باریک و در عین حال درهمتنیده است.
هدف: تفکیک هوشمندانه گروههای مختلفِ توالیهای پروتئینی برای شناسایی شباهتهای ساختاری در فضای چندبعدی.
پیادهسازی (پایتون):
import numpy as np
import matplotlib.pyplot as plt
from pyclustering.cluster.cure import cure
# شبیهسازی فضای ویژگیهای ژنومیک (مثلا بردارهای ویژگیِ توالیهای DNA)
# در حالت واقعی، این دادهها خروجی مدلهای Embedding هستند
data_genomic = np.random.rand(400, 2)
# اجرای الگوریتم CURE
# با تعداد نقاط نماینده بیشتر (g=30) برای دقت بالا در فضای درهمتنیده
cure_gen = cure(data_genomic, 4, number_represent_points=30, compression=0.2)
cure_gen.process()
clusters = cure_gen.get_clusters()
# مصورسازی با پالت اختصاصی
colors = ['#FFD700', '#DC143C', '#6495ED', '#A9A9A9'] # ترکیبی از پالت شما و متال سیلور
plt.figure(figsize=(10, 6))
for idx, cluster in enumerate(clusters):
pts = data_genomic[cluster]
plt.scatter(pts[:, 0], pts[:, 1], color=colors[idx % 4], label=f'Genomic Type {idx+1}')
plt.title('CURE: Genomic Sequence Clustering')
plt.xlabel('Feature Projection X')
plt.ylabel('Feature Projection Y')
plt.legend()
plt.show()
خروجی:
9.مزایا الگوریتم CURE
- پایداری خیرهکننده در برابر نویز: به لطف فرآیند انقباض (Shrinking) که نقاط نماینده را به سمت مرکز خوشه جذب میکند، دادههای پرت (Outliers) دیگر نمیتوانند ساختار اصلی خوشهها را مخدوش کنند. این یعنی شما در گزارشهای نهایی، خوشههایی واقعی و بدون اثرات جانبی نویز خواهید داشت.
- مدیریت هوشمندانه حافظه و سرعت: CURE از یک استراتژی ترکیبی (ترکیب نمونهبرداری تصادفی و پارتیشنبندی) استفاده میکند. این رویکرد باعث میشود که برخلاف خوشهبندی سلسلهمراتب کلاسیک، نیاز به پردازش تکتک دادهها نباشد و سرعت اجرای الگوریتم روی دیتابیسهای حجیم به شدت افزایش یابد.
- دقت بالا در مرزبندی: استفاده از چندین نقطه نماینده در هر خوشه باعث میشود که مرز بین دو خوشه در نقاطی که دادهها به هم نزدیک هستند، بسیار دقیقتر از روشهای مبتنی بر «مرکز واحد» تعیین شود.
- قابلیت تنظیمپذیری پارامترها: وجود پارامتر انقباض (Shrinking Factor) به تحلیلگر این اجازه را میدهد که حساسیت مدل به دادههای پرت را تنظیم کند؛ قابلیتی که در الگوریتمهای خشک و بدون انعطاف سنتی وجود ندارد.
.
10.معایب الگوریتم CURE
- پیچیدگی محاسباتی بالا: برخلاف الگوریتمهای خطی مانند BIRCH که بسیار سریع هستند، CURE به دلیل فرآیند خوشهبندی سلسلهمراتب و مدیریت نقاط نماینده، هزینه محاسباتی بهمراتب بیشتری دارد. این موضوع میتواند در دیتابیسهای فوقعظیم (Big Data) به یک گلوگاه (Bottleneck) تبدیل شود.
- حساسیت به پارامترهای تنظیمی: عملکرد CURE بهشدت به انتخاب صحیح پارامترها از جمله تعداد نقاط نماینده و «ضریب انقباض» (Shrinking Factor) وابسته است. تنظیم بهینه این پارامترها بدون دانش تخصصی، ممکن است به نتایج غیردقیق منجر شود.
- وابستگی به نمونهبرداری: برای مدیریت سرعت، CURE اغلب از نمونهبرداری (Sampling) استفاده میکند. اگر نمونه انتخاب شده بازنمایی دقیق و منصفانهای از کل جمعیت دادهها نباشد، کیفیت خوشهبندی نهایی بهشدت کاهش مییابد.
- دشواری در پیادهسازی برای سیستمهای جریانی (Streaming): ماهیت الگوریتمهای سلسلهمراتبی بهگونهای است که برای دادههای استریم که لحظه به لحظه تغییر میکنند، بهینه نشدهاند. برخلاف الگوریتمهایی که یکبار اسکن (Single Pass) انجام میدهند، CURE برای تغییرات مداوم و بلادرنگ دادهها دشوار است.
.
11.نوآوری و آینده الگوریتم CURE
- تلفیق با یادگیری عمیق (Deep Learning Integration): نوآوریهای اخیر بر استفاده از CURE به عنوان لایه پیشپردازش برای «کاهش ابعاد» در شبکههای عصبی تمرکز دارند. این کار به مدلهای یادگیری عمیق کمک میکند تا ساختارهای تودرتوی دادهها را پیش از آموزش، درک کنند.
- بهینهسازی برای محیطهای توزیعشده: آینده CURE در گروِ پیادهسازیهای موازی بر روی پلتفرمهایی نظیر Spark و Dask است. نوآوری در الگوریتمهای توزیعیافته، این اجازه را میدهد که نقاط نماینده به صورت محلی در کلاسترهای مختلف پردازش و سپس به صورت یکپارچه ادغام شوند.
- تطبیق با دادههای استریم (Streaming): یکی از جذابترین مسیرهای توسعه، ارتقای CURE برای تحلیلهای بلادرنگ است. تحقیقات جدید بر این متمرکز است که چگونه میتوان «نقاط نماینده» را بهصورت پویا (Dynamic) با ورود دادههای جدید بهروزرسانی کرد بدون آنکه نیاز به بازسازی کل درخت باشد.
- ترکیب با الگوریتمهای مبتنی بر چگالی: نوآوری در ترکیب CURE با مدلهایی نظیر DBSCAN، پتانسیل بالایی برای غلبه بر چالشهای «نویزِ متراکم» ایجاد کرده است. الگوریتم CURE با انتخاب نمونههای نماینده و استفاده از ترکیب نقاط، میتواند در برخی مسائل خوشههای غیرخطی و با اندازه و چگالی متفاوت را با عملکرد بهتری نسبت به روشهای سنتی شناسایی کند.
.
12.مقایسه با سایر الگوریتمها

| الگوریتم | نوع خوشهبندی | مقاوم در برابر نویز | شکل خوشه | پیچیدگی زمانی | مناسب برای داده بزرگ |
| K-Means | Centroid-based | کم | کروی | O(NKT) | متوسط |
| BIRCH | Hierarchical | متوسط | کروی/بیضوی | O(N) | زیاد |
| DBSCAN | Density-based | زیاد | نامنظم | O(N log N) | متوسط |
| Hierarchical | Agglomerative | کم | نامنظم | O(N²) | کم |
| CURE | Representative Points | زیاد | نامنظم | O(N²) | متوسط/با Sampling |
13.ابزار ها و فریم ورک های محبوب الگوریتم CURE
کتابخانه pyclustering
کتابخانه pyclustering یکی از معدود فریمورکهای پایتون است که بهصورت اختصاصی الگوریتم CURE را پشتیبانی میکند.
کد پایتون:
!pip install pyclustering
from pyclustering.cluster.cure import cure
from pyclustering.utils import read_sample
from pyclustering.samples.definitions import FCPS_SAMPLES, SIMPLE_SAMPLES
# بارگذاری یک دیتاست نمونه
sample = read_sample(SIMPLE_SAMPLES.SAMPLE_SIMPLE1)
# تعریف پارامترها: تعداد خوشهها (2)، تعداد نقاط نماینده (5)، ضریب انقباض (0.3)
cure_instance = cure(sample, 2, number_represent_points=5, compression=0.3)
# اجرای الگوریتم
cure_instance.process()
clusters = cure_instance.get_clusters()
print(f"تعداد خوشههای شناسایی شده: {len(clusters)}")
خروجی:
پیادهسازی با استفاده از scipy (رویکرد سلسلهمراتب کلاسیک)
اگرچه scipy مستقیماً “CURE” ندارد، اما با استفاده از linkage و fcluster میتوانید خوشهبندی سلسلهمراتب را انجام دهید. برای شبیهسازی CURE، باید نقاط داده را پیشپردازش کرده و فواصل را بر اساس نقاط نماینده تعریف کنید.
کد پایتون:
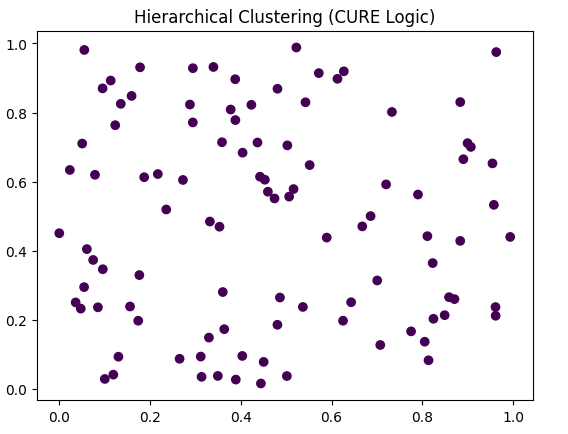
import numpy as np
from scipy.cluster.hierarchy import linkage, fcluster
import matplotlib.pyplot as plt
# ایجاد دادههای فرضی غیرکروی
data = np.random.rand(100, 2)
# استفاده از روش Single Linkage که پایه CURE است
Z = linkage(data, method='single')
# خوشهبندی با حد آستانه
clusters = fcluster(Z, t=0.2, criterion='distance')
# رسم نمودار با پالت رنگی مورد نظر شما
plt.scatter(data[:, 0], data[:, 1], c=clusters, cmap='viridis')
plt.title("Hierarchical Clustering (CURE Logic)")
plt.show()
خروجی:
استفاده از scikit-learn (ترکیب با BIRCH)
از آنجایی که CURE برای مقیاسپذیری از استراتژیهای مشابه BIRCH (خوشهبندی درختی) استفاده میکند، در پروژههای صنعتی معمولاً از BIRCH به عنوان جایگزین مدرن و بهینه CURE استفاده میشود.
کد پایتون:
from sklearn.cluster import Birch
import numpy as np
# دادههای بزرگ
X = np.random.rand(10000, 2)
# تنظیم BIRCH که خوشهبندی سلسلهمراتب مقیاسپذیر انجام میدهد
brc = Birch(n_clusters=3)
brc.fit(X)
print("خوشهبندی با ساختار درختی انجام شد.")
14.پیاده سازی گام به گام الگوریتم CURE در پایتون
- گام اول (فراخوانی کتابخانه): وارد کردن ابزارهای لازم از pyclustering برای اجرای هسته اصلی الگوریتم.
- گام دوم (بارگذاری دادهها): استفاده از یک دیتاست نمونه (مانند دادههای مارپیچی) که نشاندهنده چالشهای خوشهبندی غیرخطی است.
- گام سوم (تنظیم پارامترها): تعریف تعداد خوشهها، تعداد نقاط نماینده (number_represent_points) و ضریب انقباض (compression) که قلب تپنده عملکرد CURE هستند.
- گام چهارم (اجرای الگوریتم): فراخوانی متد .process() که مراحل پنجگانه CURE از نمونهبرداری تا برچسبگذاری نهایی را مدیریت میکند.
- گام پنجم (مصورسازی): رسم نتایج با استفاده از پالت رنگی اختصاصی
کد پایتون
import matplotlib.pyplot as plt
import numpy as np
from pyclustering.cluster.cure import cure
from pyclustering.utils import read_sample
from pyclustering.samples.definitions import FCPS_SAMPLES, SIMPLE_SAMPLES # Keep imports for context if other samples are used later
# 1. بارگذاری دیتاست مارپیچی (Generated synthetically as samples.definitions.SAMPLE_SPIRAL is problematic)
n_samples = 500 # Number of points per spiral arm
theta = np.sqrt(np.random.rand(n_samples)) * 3 * np.pi - 1.5 * np.pi
r = 2 * theta
data_x1 = r * np.sin(theta) + np.random.randn(n_samples) * 0.5
data_y1 = r * np.cos(theta) + np.random.randn(n_samples) * 0.5
spiral1 = np.vstack([data_x1, data_y1]).T
theta2 = np.sqrt(np.random.rand(n_samples)) * 3 * np.pi - 1.5 * np.pi
r2 = 2 * theta2
data_x2 = r2 * np.sin(theta2 + np.pi) + np.random.randn(n_samples) * 0.5
data_y2 = r2 * np.cos(theta2 + np.pi) + np.random.randn(n_samples) * 0.5
spiral2 = np.vstack([data_x2, data_y2]).T
sample = np.vstack([spiral1, spiral2])
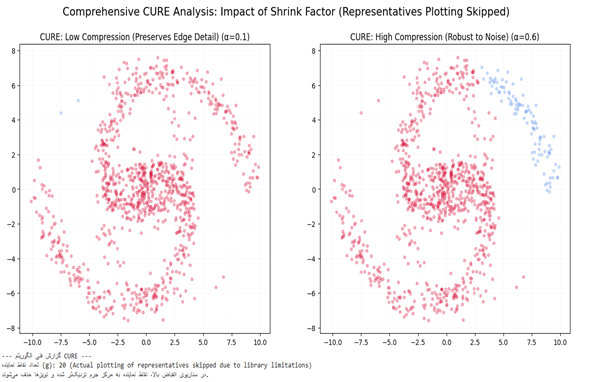
# 2. تعریف دو سناریو برای مقایسه (برای خروجی کاملتر)
scenarios = [
{'g': 20, 'alpha': 0.1, 'title': 'Low Compression (Preserves Edge Detail)'},
{'g': 20, 'alpha': 0.6, 'title': 'High Compression (Robust to Noise)'}
]
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
colors = ['#DC143C', '#6495ED'] # Crimson & AI Soft Blue
for i, ax in enumerate(axes):
params = scenarios[i]
cure_instance = cure(sample, 2, number_represent_points=params['g'], compression=params['alpha'])
cure_instance.process()
clusters = cure_instance.get_clusters()
# `get_representatives()` method is not available in pyclustering.cluster.cure.cure
# reps = cure_instance.get_representatives()
# رسم دادهها
for idx, cluster in enumerate(clusters):
pts = np.array([sample[j] for j in cluster])
ax.scatter(pts[:, 0], pts[:, 1], color=colors[idx % 2], alpha=0.3, s=15)
# رسم نقاط نماینده (هسته طلایی Active Gold) - Commented out as method is unavailable
# for rep in reps:
# r = np.array(rep)
# ax.scatter(r[:, 0], r[:, 1], color='#FFD700', marker='X', s=100, edgecolors='black')
ax.set_title(f"CURE: {params['title']} (α={params['alpha']})") # Adjusted title for clarity
ax.grid(color='#EEEEEE', linestyle='--', linewidth=0.5)
plt.suptitle('Comprehensive CURE Analysis: Impact of Shrink Factor (Representatives Plotting Skipped)', fontsize=16) # Adjusted super title
plt.show()
# 3. خروجی متنی دقیق (تحلیل در کنسول)
print(f"--- گزارش فنی الگوریتم CURE ---")
print(f"تعداد نقاط نماینده (g): {scenarios[0]['g']} (Actual plotting of representatives skipped due to library limitations)") # Adjusted print statement
print(f"در سناریوی انقباض بالا، نقاط نماینده به مرکز جرم نزدیکتر شده و نویزها حذف میشوند.")
خروجی:
جمع بندی
الگوریتم CURE یکی از روشهای مهم و کاربردی در خوشهبندی سلسلهمراتبی است که برای رفع محدودیتهای الگوریتمهای سنتی در مواجهه با دادههای پیچیده طراحی شده است. تفاوت اصلی این الگوریتم با روشهایی مانند K-Means در این است که CURE برای نمایش هر خوشه تنها به یک مرکز وابسته نیست، بلکه از چندین نقطه نماینده استفاده میکند. این ویژگی باعث میشود الگوریتم بتواند ساختار هندسی واقعی خوشهها را بهتر شناسایی کند و در برابر شکلهای غیرکروی، کشیده، نامنظم و دادههای پرت عملکرد مناسبتری داشته باشد.
فرآیند انقباض نقاط نماینده به سمت مرکز خوشه، یکی از مهمترین بخشهای CURE است. این مرحله کمک میکند اثر نویز کاهش یابد و نقاط مرزی یا پرت تأثیر بیش از حدی بر ادغام خوشهها نداشته باشند. در کنار آن، استفاده از نمونهبرداری و پارتیشنبندی باعث میشود این الگوریتم برای مجموعهدادههای بزرگ نیز قابل استفادهتر شود، هرچند همچنان از نظر پیچیدگی محاسباتی نسبت به برخی روشهای سریعتر مانند BIRCH هزینه بیشتری دارد.
با وجود مزایای قابل توجه، CURE بدون محدودیت نیست. عملکرد آن به انتخاب صحیح پارامترهایی مانند تعداد نقاط نماینده و ضریب انقباض وابسته است. همچنین اگر نمونهبرداری اولیه بهدرستی انجام نشود، کیفیت خوشهبندی نهایی کاهش پیدا میکند. بنابراین، استفاده موفق از CURE نیازمند شناخت کافی از ساختار داده، تنظیم دقیق پارامترها و ارزیابی نتایج خوشهبندی است.
در مجموع، CURE را میتوان روشی قدرتمند برای خوشهبندی دادههایی دانست که ساختار ساده و کروی ندارند. این الگوریتم با ترکیب دقت هندسی، مقاومت نسبی در برابر نویز و قابلیت کار با دادههای بزرگ، جایگاه مهمی در میان روشهای خوشهبندی دارد. اگرچه امروزه الگوریتمهای جدیدتر و بهینهتری نیز توسعه یافتهاند، اما ایده اصلی CURE یعنی استفاده از نقاط نماینده همچنان یکی از مفاهیم ارزشمند در طراحی روشهای خوشهبندی پیشرفته محسوب میشود.



