

مقدمه
در هر مدل یادگیری ماشین و یادگیری عمیق، یک پرسش اساسی وجود دارد:
مدل از کجا میفهمد که چقدر اشتباه کرده و چگونه باید بهتر شود؟
پاسخ این پرسش در مفهومی کلیدی به نام تابع زیان (Loss Function) نهفته است.
تابع زیان معیاری عددی است که فاصله بین پیشبینیهای مدل و مقادیر واقعی را اندازهگیری میکند و بهعنوان قطبنمای فرآیند یادگیری عمل میکند. بدون تابع زیان، مدل هیچ درکی از کیفیت تصمیمهای خود ندارد و فرآیند آموزش عملاً بیمعنا خواهد بود. انتخاب نادرست این تابع میتواند حتی پیچیدهترین معماریهای یادگیری عمیق را به نتایج ضعیف برساند، در حالی که انتخاب آگاهانه آن مسیر یادگیری را هموار، پایدار و مؤثر میکند.
در این مقاله، مفهوم تابع زیان بهصورت جامع و کاربردی بررسی میشود؛ از نقش آن در مسائل رگرسیون و طبقهبندی گرفته تا توابع پیشرفته مورد استفاده در بینایی ماشین، پردازش زبان طبیعی و مدلهای مولد. هدف این است که خواننده پس از مطالعه این مطلب، بتواند تابع زیان مناسب را نه بر اساس حدس، بلکه با درک عمیق از مسئله، داده و رفتار مدل انتخاب کند.
تعریف کلی
تابع زیان تابعی است که تعیین میکند خروجی فعلی الگوریتم چقدر از خروجی مطلوب یا واقعیت فاصله دارد. این ابزار در واقع تکنیکی برای ارزیابی این موضوع است که الگوریتم ما با چه کیفیتی دادههای ورودی را مدلسازی کرده است.
- هدف اصلی: محاسبه میزان خطا در هر گام از آموزش مدل است.
- روند بهینهسازی: هرچه مقدار این تابع کمتر باشد، مدل عملکرد بهتری دارد و پیشبینیهای آن به واقعیت نزدیکتر است.
.
تابع زیان در یادگیری عمیق (Deep Learning)
در یادگیری عمیق، به دلیل پیچیدگی لایهها، تابع زیان نقشی حیاتی و استراتژیک ایفا میکند.
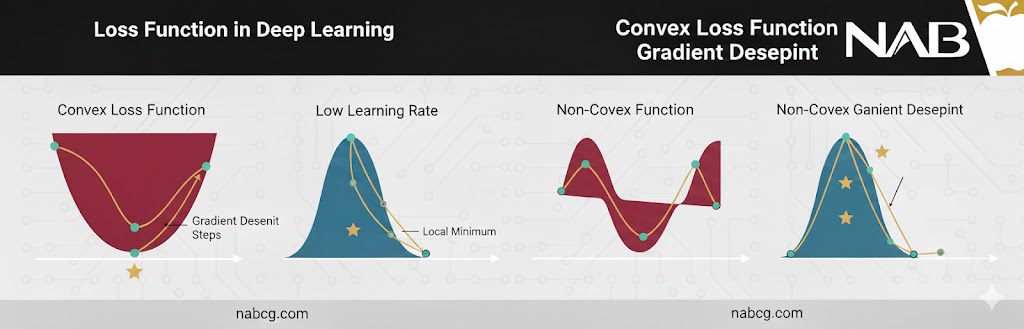
- فضای غیرمحدب: تابع زیان در شبکههای عصبی شبیه به یک کوهستان با هزاران قله و دره است. در اینجا مدل باید مراقب باشد که در کمینههای محلی گیر نیفتد و به سمت عمیقترین نقطه حرکت کند.
- محرک انتشار رو به عقب: تابع زیان در انتهای شبکه قرار دارد. خطای محاسبه شده توسط آن، از طریق فرآیند انتشار رو به عقب به سمت لایههای ابتدایی حرکت میکند تا سهم هر وزن در ایجاد خطا مشخص و اصلاح شود.
- ترکیب با لایه آخر: در یادگیری عمیق، تابع زیان وابستگی شدیدی به تابع فعالساز لایه آخر دارد؛ برای مثال، تابع زیان آنتروپی متقاطع معمولاً با تابع Softmax ترکیب میشود تا تفاوت توزیع احتمالی پیشبینی شده و واقعیت را بسنجد
کالبدشکافی تابع زیان در رگرسیون خطی
در یک مدل رگرسیون خطی ساده، پیشبینی با استفاده از پارامترهای شیب (m) و عرض از مبدأ (b) محاسبه میشود.
- تابع زیان در این حالت به صورت
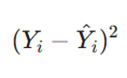
تعریف میشود.
- این یعنی تابع زیان مستقیماً تابعی از شیب و عرض از مبدأ است.
.
چرا تابع زیان (Loss Function) در یادگیری عمیق حیاتی است؟
در دنیای بهینهسازی ریاضی و تئوری تصمیمگیری، تابع زیان (که گاهی تابع هزینه یا تابع خطا نیز نامیده میشود) تابعی است که تفاوت بین پیشبینی مدل و واقعیت را به یک عدد حقیقی تبدیل میکند. این عدد در واقع نشاندهنده «هزینه» یا جریمهای است که مدل بابت اشتباهاتش پرداخت میکند.
نقش کلیدی توابع زیان در مدلهای هوش مصنوعی
- ارزیابی کیفیت مدل: تابع زیان روشی است برای سنجش اینکه الگوریتم شما چقدر خوب دادهها را مدلسازی کرده است.
- هدایت فرآیند آموزش: این توابع با کمیسازی خطاها، فرآیند آموزش را هدایت کرده و باعث بهروزرسانی دقیق پارامترها میشوند.
- پایه و اساس بهینهسازی: توابع زیان مبنای آموزش مدل هستند و به الگوریتمها جهت میدهند تا پارامترها را به سمتی تغییر دهند که دقت پیشبینی بهبود یابد.
.
توابع زیان در یادگیری عمیق: قلب تپنده بهینهسازی شبکه
در یادگیری عمیق، تابع زیان (Loss Function) تنها یک معیار ساده برای سنجش خطا نیست؛ بلکه قطبنمایی است که جهت حرکت شبکههای عصبی را در اقیانوسی از میلیونها پارامتر تعیین میکند. انتخاب هوشمندانه این تابع، مرز بین یک مدل با دقت بالا و یک مدل ناپایدار است.
۱. توابع زیان پیشرفته و کاربرد استراتژیک آنها
در یادگیری عمیق، توابع زیان بر اساس معماری لایه آخر و ماهیت دادهها انتخاب میشوند:
الف) استراتژیهای رگرسیون (تخمین مقادیر پیوسته)
- میانگین مربعات خطا(MSE): استاندارد طلایی در یادگیری عمیق برای مسائلی که توزیع خطا در آنها نرمال است. در شبکههای عصبی، MSE به دلیل ویژگی مشتقپذیری عالی، همگرایی سریعی را فراهم میکند، اما باید مراقب بود که دادههای پرت (Outliers) وزنهای شبکه را به اشتباه جابجا نکنند.
- میانگین قدر مطلق خطا(MAE): زمانی که دیتاست شما نویزی است، MAE به عنوان یک تابع مقاوم (Robust) وارد عمل میشود تا از انفجار گرادیانها در اثر دادههای دورافتاده جلوگیری کند.
- Huber Loss (تعادل هوشمند): محبوبترین انتخاب برای مدلهای رگرسیون عمیق صنعتی. این تابع در مرکز (خطاهای کوچک) مانند MSE دقیق عمل کرده و در حاشیهها (خطاهای بزرگ) مانند MAE در برابر نویز مقاومت میکند.
.
ب) جادوی احتمالات در دستهبندی (Classification)
- Cross-Entropy (آنتروپی متقاطع): ستون فقرات طبقهبندی در یادگیری عمیق. این تابع نه تنها روی برچسب درست تمرکز دارد، بلکه «توزیع احتمالی» خروجی را به توزیع واقعی نزدیک میکند.
- Binary Cross-Entropy: همراه همیشگی لایه خروجی با تابع فعالساز Sigmoid برای مسائل دوحالته.
- Categorical Cross-Entropy: مکمل تابع فعالساز Softmax در مسائل چندکلاسه (مثل تشخیص چهره یا اشیاء).
- Focal Loss: نسخه تکاملیافته آنتروپی متقاطع برای شبکههای عمیقی که با دادههای «نامتوازن» سر و کار دارند؛ این تابع مدل را مجبور میکند روی نمونههای سخت و کمیاب تمرکز بیشتری داشته باشد.
.
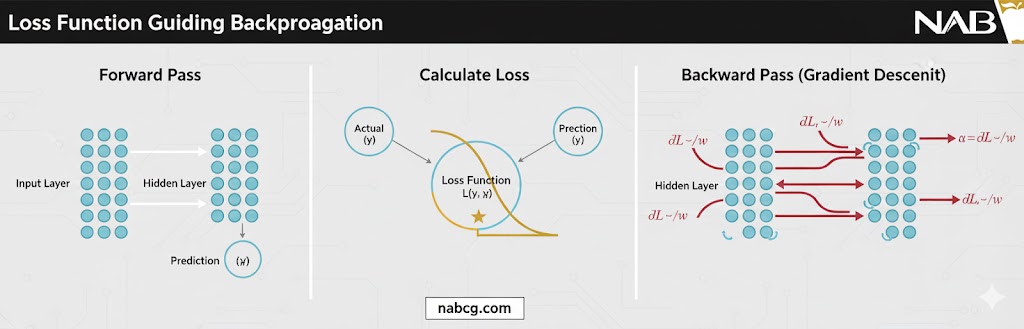
۲. همکاری استراتژیک تابع زیان و انتشار رو به عقب (Backpropagation)
در یادگیری عمیق، تابع زیان نقطه شروع فرآیند یادگیری است. این همکاری در سه مرحله حیاتی رخ میدهد:
- محاسبه جریمه نهایی: پس از اتمام یک دور رفت (Forward Pass)، تابع زیان مشخص میکند که شبکه چقدر از واقعیت فاصله دارد
- تولید سیگنال خطا: مقدار عددی زیان، از طریق زنجیرهای از مشتقات (Chain Rule) تبدیل به گرادیان میشود
- بهینهسازی با گرادیان کاهشی: الگوریتمهایی مانند Adam یا SGD با استفاده از این گرادیانها، وزنهای شبکه را در جهت عکس خطا حرکت میدهند تا به کمینه مطلق (Global Minimum) در فضای غیرمحدب شبکه عصبی برسند.
توابع زیان در رگرسیون (Regression Loss Functions)
توابع زیان در مسائل رگرسیون زمانی به کار میروند که مدل ما وظیفه دارد یک مقدار عددی پیوسته را پیشبینی کند؛ مانند پیشبینی قیمت مسکن، سن افراد یا میزان دمای هوا.
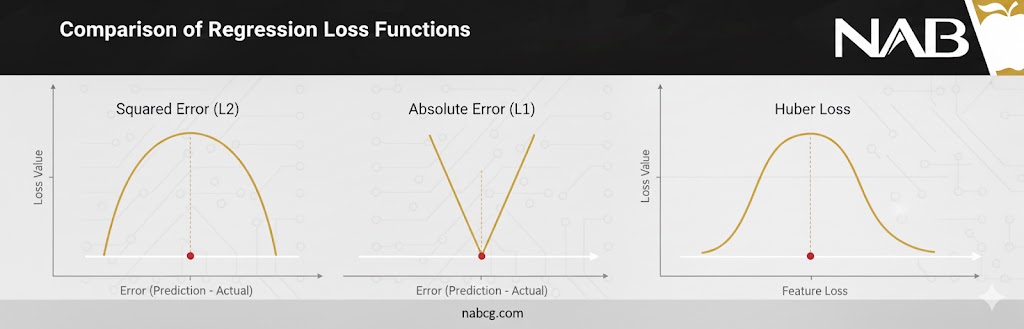
۱. میانگین مربعات خطا (Mean Squared Error – MSE)
این تابع که با نامهای Squared Loss یا L2 Loss نیز شناخته میشود، محبوبترین انتخاب برای مسائل رگرسیون است.
- MSE تفاوت بین واقعیت و پیشبینی را به توان ۲ میرساند. این کار باعث میشود جریمهی خطاهای بزرگ به صورت نمایی افزایش یابد تا مدل بیشترین تلاش را برای کاهش خطاهای فاحش انجام دهد.
- فرمول :
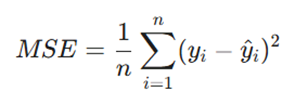
- توضیح متغیرها:
- n: تعداد کل نمونههای داده.
- yi: مقدار واقعی (Ground Truth).
- ^yi: مقدار پیشبینی شده توسط مدل.
- مزایا:
- محدب بودن: یک منحنی نرم ایجاد میکند که تنها یک نقطه کمینه دارد و برای بهینهسازی عالی است.
- مشتقپذیری کامل: در تمام نقاط مشتقپذیر است که کار با الگوریتم Gradient Descent را ساده میکند.
- معایب:
- حساسیت شدید به Outliers: به دلیل توان ۲، دادههای پرت میتوانند به شدت روی مدل تأثیر منفی بگذارند.
- واحد غیرمستقیم: واحد خروجی آن مجذور واحد اصلی است که تفسیر شهودی را سخت میکند.
کد پایتون:
import numpy as np
def mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(mean_squared_error(act,pred))
.
۲. میانگین قدرمطلق خطا (Mean Absolute Error – MAE)
این تابع که به آن L1 Loss نیز میگویند، جایگزینی مقاوم برای MSE است.
- MAE به جای توان ۲، از قدرمطلق تفاوتها استفاده میکند. این یعنی وزن تمام خطاها (چه کوچک و چه بزرگ) به صورت خطی لحاظ میشود.
- فرمول :
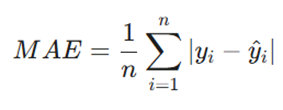
- مزایا:
- مقاومت در برابر دادههای پرت: برخلاف MSE، دادههای غلط و عجیب تأثیر ویرانگری روی مدل ندارند.
- تفسیر آسان: خروجی آن دقیقاً در همان واحد اندازهگیری اصلی (مثلاً دلار یا متر) است.
- معایب:
- عدم مشتقپذیری در صفر: در نقطهای که خطا صفر است، مشتق تعریف نشده است که میتواند باعث نوسان در آموزش شود.
- پیچیدگی محاسباتی: بهینهسازی آن گاهی از MSE زمانبرتر است.
کد پایتون:
import numpy as np
def mean_absolute_error(act, pred):
diff = pred - act
abs_diff = np.absolute(diff)
mean_diff = abs_diff.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act,pred)
.
۳. تابع زیان هابر (Huber Loss)
هابر یک تابع هوشمند است که مزایای MSE و MAE را ترکیب کرده تا بر معایب هر دو غلبه کند.
- این تابع برای خطاهای کوچک شبیه MSE عمل میکند (دقت بالا) و برای خطاهای بزرگ شبیه MAE )مقاومت در برابر دادههای پرت ).
- فرمول:
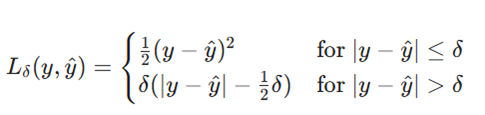
- توضیح متغیرها:
- δ (دلتا): پارامتری است که تعیین میکند از چه نقطهای به بعد تابع از حالت مربعی به حالت خطی تغییر رفتار دهد.
- مزایا:
- بهترینِ هر دو دنیا: هم دقت MSE را دارد و هم پایداری MAE را.
- مشتقپذیری در تمام نقاط: مشکل عدم مشتقپذیری MAE در صفر را ندارد.
- معایب:
- نیاز به تنظیم هایپرپارامتر: انتخاب مقدار مناسب برای δ نیاز به آزمایش و خطا دارد.
.
مطالعه موردی رگرسیون: پیشبینی قیمت مسکن در بازار پرنوسان
در این سناریو، هدف پیشبینی قیمت ملک بر اساس متراژ و منطقه است.
- استفاده ازMSE: وقتی دادهها تمیز هستند، MSE به مدل کمک میکند تا با دقت میلیمتری قیمتها را تخمین بزند.
- استفاده ازMAE: اگر در دیتاست چند ویلای فوقلاکچری با قیمتهای نجومی (داده پرت) وجود داشته باشد که با بقیه دادهها همخوانی ندارند، MAE از انحراف کل مدل به سمت این قیمتهای خاص جلوگیری میکند.
- راهکار حرفهای (Huber): در پروژههای صنعتی، از Huber Loss استفاده میشود تا اگر خطا از یک آستانه (δ) فراتر رفت، جریمه از حالت مربعی به خطی تغییر کند و پایداری شبکه حفظ شود.
.
توابع زیان در طبقهبندی
این توابع برای سنجش عملکرد مدلهایی که خروجی آنها برچسب کلاسهاست (مثلاً تشخیص گربه، سگ یا اسب) استفاده میشوند.
۱. آنتروپی متقاطع باینری (Binary Cross-Entropy / Log Loss)
استاندارد طلایی برای مسائلی که فقط دو انتخاب دارند (بله/خیر).
- این تابع میزان تفاوت بین دو توزیع احتمال را میسنجد. اگر مدل با قاطعیت اشتباه کند، به شدت جریمه میشود.
- فرمول:
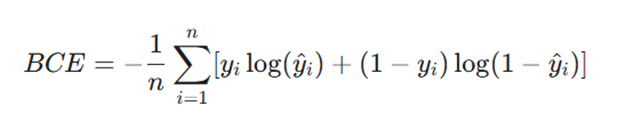
- توضیح متغیرها:
- yi: لیبل واقعی (۰ یا ۱).
- ^yi : احتمال پیشبینی شده توسط مدل (عددی بین ۰ و ۱).
- مزایا:
- پایداری در آموزش: برای شبکههای عصبی بسیار بهینه است.
- تفسیر احتمالی: خروجی مدل را به عنوان احتمال واقعی به ما میدهد.
- معایب:
- وابستگی به خروجی احتمال: مدل حتماً باید خروجی بین ۰ و ۱ (مثل خروجی Sigmoid) تولید کند.
.
۲. آنتروپی متقاطع چندکلاسه (Categorical Cross-Entropy)
زمانی استفاده میشود که بیش از دو کلاس داریم (مثلاً تشخیص اعداد دستنویس از ۰ تا ۹).
- این تابع بررسی میکند که توزیع احتمالی خروجی مدل (از لایه Softmax) چقدر به واقعیت (One-Hot Encoding) نزدیک است.
- فرمول :
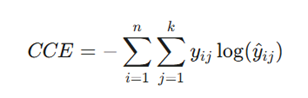
- مزایا:
- رقابت بین کلاسها: مدل را مجبور میکند برای کلاس صحیح بیشترین احتمال را در نظر بگیرد.
- معایب:
- نیاز به One-Hot: دادههای هدف باید به فرمت برداری تبدیل شوند که مصرف حافظه را بالا میبرد.
.
۳. آنتروپی متقاطع چندکلاسه پراکنده (Sparse Categorical Cross-Entropy)
نسخه بهینهسازی شده CCE برای صرفهجویی در حافظه.
- عملکردی دقیقاً مشابه CCE دارد، اما به جای دریافت بردار One-Hot، مستقیم اعداد صحیح (Integer) را به عنوان لیبل دریافت میکند.
- فرمول:
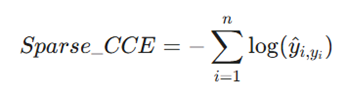
- مزایا:
- بهرهوری بالا: در مسائلی با هزاران کلاس (مثل ترجمه ماشینی) حجم حافظه را به شدت کاهش میدهد.
.
۴. واگرایی کولبک-لایبلر (KL Divergence)
بیشتر در مدلهای احتمالی و یادگیری بدون نظارت کاربرد دارد.نشان میدهد که یک توزیع احتمال چقدر از توزیع هدف فاصله گرفته است.
- مزایا: بسیار حساس به تفاوتهای ظریف در احتمالات.
- معایب: متقارن نیست؛ یعنی فاصله توزیع A تا B با B تا A برابر نیست.
.
۵. زیان هینج (Hinge Loss)
ابزار اصلی در الگوریتمهای کلاسیک مثل. SVM
- به دنبال ایجاد حاشیه (Margin) بین کلاسهاست. تا زمانی که داده در جای درست و با فاصله کافی باشد، جریمهای در نظر نمیگیرد.
- فرمول:
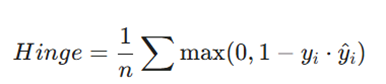
- مزایا: خروجیهای پایدار و مقاوم.
- معایب: فقط برای طبقهبندی مناسب است و احتمالات را به ما نمیدهد.
.
توابع زیان رتبهبندی
این توابع به جای تمرکز بر مقدار دقیق یک عدد، بر روی رابطه نسبی و ترتیب آیتمها تمرکز دارند. کاربرد اصلی آنها در سیستمهای پیشنهادگر و جستجوی پیشرفته است.
۱. زیان تقابلی (Contrastive Loss)
- مفهوم: این تابع برای آموزش شبکههایی (مانند شبکههای سیامی) به کار میرود که باید شباهت یا عدم شباهت دو ورودی را تشخیص دهند.
- فرمول:
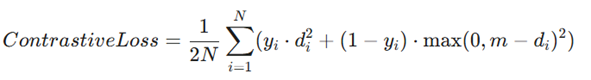
- متغیرها:
- di: فاصله بین دو ویژگی استخراج شده.
- yi: برچسب جفتها (۱ برای جفتهای مشابه و ۰ برای جفتهای متفاوت).
- m: حد آستانه یا Margin که فاصله حداقلی بین جفتهای متفاوت را تعیین میکند.
- مزایا: ایجاد فضایی که در آن اشیاء مشابه در کنار هم و اشیاء متفاوت دور از هم قرار میگیرند.
- معایب: حساسیت زیاد به انتخاب پارامتر m (حاشیه).
.
۲. زیان سهگانه (Triplet Loss)
- مفهوم: این تابع به طور همزمان سه نمونه را مقایسه میکند: مرجع (Anchor)، نمونه مثبت (Positive) و نمونه منفی .(Negative) هدف این است که فاصله مرجع با مثبت کمتر از فاصلهاش با منفی باشد.

- فرمول:
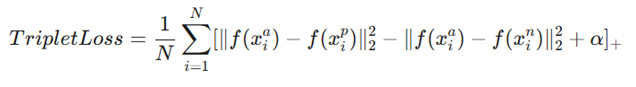
- متغیرها:
- f(x_i^a), f(x_i^p), f(x_i^n): به ترتیب ویژگیهای مرجع، مثبت و منفی.
- α: حاشیه امن بین فواصل.
- کاربرد: در مدلهای تشخیص چهره پیشرفته مانند FaceNet گوگل.
.
مطالعه موردی رتبهبندی: سیستم تایید هویت در گوشیهای هوشمند
فرض کنید میخواهید سیستمی بسازید که با نگاه کردن به چهره کاربر، قفل گوشی را باز کند.
- استفاده از:Triplet Loss این مدل سه تصویر را همزمان بررسی میکند: تصویر صاحب گوشی (Anchor)، تصویر دیگری از صاحب گوشی (Positive) و تصویر یک فرد غریبه. (Negative)
- نتیجه: تابع زیان به شبکه عصبی یاد میدهد که فاصله برداری (Embedding) بین تصاویر صاحب گوشی را به صفر نزدیک کند و فاصله با فرد غریبه را از یک حد مشخص (α) بیشتر کند. این دقیقاً همان تکنولوژی پشت پرده FaceID است.
.
توابع زیان تصویر و بازسازی
این توابع برای مدلهایی طراحی شدهاند که وظیفهی تولید یا بازسازی تصاویر را بر عهده دارند تا خروجی نهایی از نظر بصری و ساختاری بیشترین شباهت را به هدف (Ground Truth) داشته باشد.
۱. زیان Dice و Jaccard (IoU)
- برخلاف توابع ساده که پیکسلها را به صورت مستقل بررسی میکنند، این دو تابع میزان «همپوشانی» یا اشتراک بین ناحیه پیشبینی شده و ناحیه واقعی را میسنجند.
- فرمول ریاضیDice:
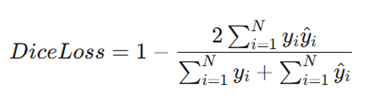
- فرمول ریاضی Jaccard (IoU):
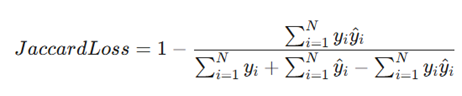
- توضیح متغیرها:
- yi: برچسب واقعی (Ground Truth) برای هر پیکسل.
- ^yi: احتمال پیشبینی شده توسط مدل برای هر پیکسل.
- N: تعداد کل پیکسلهای تصویر.
- کاربرد: استاندارد طلایی در بخشبندی تصاویر پزشکی مانند تشخیص تومورها.
- مزایا: عملکرد بسیار عالی در دادههای نامتوازن، یعنی زمانی که هدف (مثلاً یک لکه کوچک سرطان) بخش بسیار ناچیزی از کل تصویر را اشغال کرده است.
مطالعه موردی طبقهبندی: سیستم تشخیص تومور در تصاویر پزشکی
در بخشبندی تصاویر پزشکی (Medical Segmentation)، معمولاً تومور تنها ۱٪ از کل تصویر را اشغال میکند و بقیه تصویر بافت سالم است.
- چالش: اگر از تابع Cross-Entropy معمولی استفاده کنیم، مدل یاد میگیرد که همه چیز را «بافت سالم» تشخیص دهد تا خطایش کم شود (داده نامتوازن).
- راهکار(Dice Loss): این تابع به جای پیکسلها، روی همپوشانی (Overlap) تمرکز میکند. در این مطالعه موردی، Dice Loss مدل را مجبور میکند تا دقیقاً روی محدوده تومور متمرکز شود، حتی اگر بسیار کوچک باشد.
.
۲. زیان ادراکی (Perceptual Loss)
- مفهوم: به جای مقایسه مستقیم مقادیر پیکسلها (که اغلب منجر به تاری تصویر میشود)، تفاوت بین ویژگیهای سطح بالا مانند بافت، لبهها و مفاهیم بصری را مقایسه میکند. این کار از طریق لایههای یک شبکه عصبی از پیش آموزش دیده (مانند VGG) انجام میشود.
- فرمول :
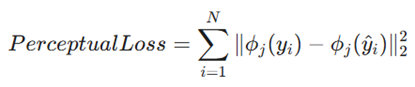
- توضیح متغیرها:
- : ϕj: نشاندهنده لایه j-اُم از یک شبکه عصبی از پیش آموزش دیده است که ویژگیها را استخراج میکند.
- yi و ^yi: به ترتیب تصویر واقعی و تصویر بازسازی شده توسط مدل هستند.
- کاربرد: افزایش وضوح و کیفیت تصاویر (Super Resolution) و انتقال سبکهای هنری (Style Transfer).
.
توابع زیان تخاصمی
این توابع قلب تپنده شبکههای تولیدگر تخاصمی (GANs) هستند که بر پایه رقابت بین دو شبکه بنا شدهاند.
- مفهوم (بازی موش و گربه):
- تولیدکننده(Generator): سعی میکند تصاویری بسازد که آنقدر واقعی باشند که سیستم تشخیصدهنده را فریب دهند.
- تشخیصدهنده(Discriminator): تلاش میکند تفاوت بین تصاویر واقعی و تصاویر ساخته شده توسط تولیدکننده را پیدا کند.
- تنوع در فرمول:
- نسخه استاندارد(GAN Loss): بر اساس لگاریتم احتمال (Minimax Game) عمل میکند:
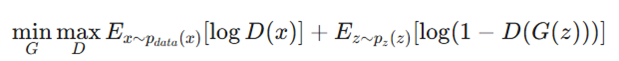
- نسخه Least Squares (LSGAN): برای پایداری بیشتر در آموزش و جلوگیری از مشکل فروپاشی مدل (Mode Collapse)، از حداقل مربعات خطا استفاده میکند تا کیفیت تصاویر تولیدی افزایش یابد.
.
توابع زیان تخصصی
این توابع برای حل چالشهای بسیار خاص در دادههای ترتیبی، شمارشی و برداری مهندسی شدهاند.
۱. زیان CTC (Connectionist Temporal Classification)
- تعریف: تابعی حیاتی برای مسائلی که در آنها طول توالی ورودی با طول توالی خروجی برابر نیست و تراز (Alignment) دقیقی بین آنها وجود ندارد.
- فرمول:
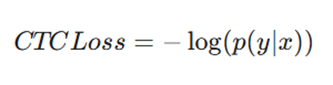
- توضیح متغیرها:
- p(y | x): احتمال توالی خروجی صحیح به شرط توالی ورودی داده شده.
- کاربرد: تبدیل گفتار به متن (Speech-to-Text) و سیستمهای تشخیص متن در تصویر (OCR).
مطالعه موردی تخصصی: تبدیل ویسهای طولانی به متن (Speech-to-Text)
در سیستمهای تایپ صوتی، سرعت حرف زدن افراد متفاوت است؛ ممکن است یک کلمه ۳ ثانیهای بیان شود اما در متن فقط ۲ حرف باشد.
- چالش :ما نمیدانیم کدام صدمثانیه از صوت دقیقاً مربوط به کدام حرف است (عدم تراز).
- راهکار: در این مطالعه موردی، CTC اجازه میدهد مدل تمام ترازهای ممکن را بررسی کرده و مجموع احتمال توالی درست را به حداکثر برساند. این تابع بدون نیاز به علامتگذاری دستیِ تکتک ثانیهها، یادگیری را ممکن میکند.
.
۲. زیان پوآسون (Poisson Loss)
- تعریف: برای مدلسازی دادههایی استفاده میشود که ماهیت «شمارشی» دارند و توزیع آنها از نوع پوآسون فرض میشود.
- فرمول:
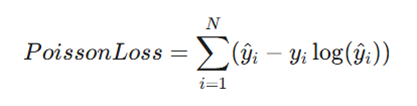
- توضیح متغیرها:
- ^yi: مقدار شمارش پیشبینی شده.
- yi: مقدار شمارش واقعی ثبت شده.
- کاربرد: پیشبینی تعداد رخدادها در یک بازه زمانی (مانند تعداد مراجعین به یک مرکز در ساعت).
.
۳. زیان مجاورت کسینوسی (Cosine Proximity Loss)
- تعریف: به جای بررسی تفاوت عددی، «شباهت جهت» بین دو بردار را در فضای چندبعدی میسنجد.
- فرمول:
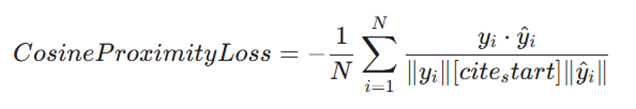
نقشه راه انتخاب هوشمندانه تابع زیان در یادگیری عمیق
برای اینکه مدل به بهترین نحو آموزش ببیند، باید این پنج گام استراتژیک را دنبال کنید:
۱. درک ماهیت اصلی مسئله
اولین و حیاتیترین قدم، شناخت دقیق هدفی است که مدل شما دنبال میکند.
- رگرسیون: برای پیشبینی اعداد پیوسته (مثل تخیمن قیمت یا سن)، از MSE یا MAE استفاده کنید.
- طبقهبندی: برای تشخیص دستهها (مثل تشخیص اشیاء)، Cross-Entropy استاندارد طلایی است.
- رتبهبندی: برای سیستمهای پیشنهادگر یا تشخیص چهره، از Contrastive یا Triplet Loss بهره ببرید.
- بخشبندی تصویر: در پروژههای Segmentation، توابع Dice یا Jaccard بهتری نتیجه را میدهند.
.
۲. تحلیل نوع خروجی مدل
تابع زیان باید با فرمت خروجی لایه نهایی شبکه عصبی شما همخوانی داشته باشد.
- اعداد پیوسته: توابع رگرسیونی را به کار بگیرید.
- برچسبهای کلاسی: از توابع طبقهبندی استفاده کنید.
- توالیهای زمانی زمانی که طول ورودی و خروجی ناهماهنگ است، تابع CTC Loss تنها راه حل منطقی است.
۳. مدیریت دادههای نامتوازن
اگر در مجموعه داده شما، برخی کلاسها بسیار کمیاب هستند ، مدل ممکن است کلاسهای اقلیت را نادیده بگیرد.
- راهکار: استفاده از Focal Loss پیشنهاد میشود. این تابع با تمرکز بیشتر روی نمونههای دشوار و کمیاب، از “اشباع شدن” مدل توسط نمونههای ساده جلوگیری کرده و یادگیری را متعادل میکند.
.
۴. مقاومت در برابر دادههای پرت
دادههای نویزی یا پرت میتوانند گرادیانهای بسیار بزرگی ایجاد کنند که باعث ناپایداری کل شبکه عصبی شود.
- راهکار: اگر متوجه شدید مدل شما توسط دادههای پرت منحرف میشود، از Huber Loss استفاده کنید. این تابع ترکیبی از قدرت MSE و پایداری MAE را ارائه میدهد و مدل را در برابر نوسانات شدید محافظت میکند.
.
۵. تمرکز بر همگرایی و عملکرد نهایی
انتخاب شما باید سرعت همگرایی (رسیدن به کمینه خطا) را افزایش دهد.
- گاهی اوقات استفاده از Hinge Loss در مدلهای خاص میتواند عملکرد پایدارتری نسبت به آنتروپی متقاطع داشته باشد.
.
جدول تصمیمگیری سریع
این جدول به شما کمک میکند تا بر اساس معماری و هدف، سریعترین انتخاب را داشته باشید:
| نوع مسئله | تابع زیان (Loss Function) | مزیت اصلی | چالش کلیدی | بهترین کاربرد |
| رگرسیون | MSE (L2 Loss) | پایداری ریاضی بالا و ایجاد منحنی محدب برای همگرایی سریع. | حساسیت شدید به دادههای پرت که میتواند مدل را منحرف کند. | پیشبینی دقیق قیمت مسکن یا سن در دادههای بدون نویز. |
| رگرسیون | MAE (L1 Loss) | مقاومت فوقالعاده در برابر نویز و دادههای دورافتاده (Outliers). | عدم مشتقپذیری در نقطه صفر که باعث نوسان در آموزش میشود. | تخمین مقادیر عددی در محیطهای صنعتی با دادههای نویزی. |
| رگرسیون | Huber Loss | ترکیب هوشمندانه دقت MSE و پایداری MAE برای نتایج بهینه. | نیاز به تنظیم دقیق پارامتر دلتا از طریق آزمون و خطا. | مسائل رگرسیون حساس که نیاز به تعادل در جریمه خطا دارند. |
| طبقهبندی دوتایی | Binary Cross-Entropy | جریمه سنگین برای پیشبینیهای غلط قاطع و پایداری در آموزش. | وابستگی کامل به خروجیهای احتمالی (۰ تا ۱) تولید شده توسط Sigmoid. | تشخیص هرزنامه، بیماری یا تقلب بانکی (حالتهای بله/خیر). |
| طبقهبندی چندگانه | Categorical Cross-Entropy | ایجاد رقابت بین کلاسها و مدیریت همزمان چندین برچسب مختلف. | نیاز به تبدیل دادهها به فرمت کُدگذاری تک-فعال (One-Hot Encoding). | تشخیص اشیاء در تصویر، دستخط و طبقهبندیهای چندگانه. |
جمع بندی
تابع زیان یکی از حیاتیترین اجزای هر سیستم یادگیری ماشین است که مستقیماً جهت و کیفیت یادگیری مدل را تعیین میکند. این تابع به مدل نشان میدهد در هر مرحله تا چه اندازه از هدف فاصله دارد و چگونه باید پارامترهای خود را برای کاهش خطا تنظیم کند. به بیان ساده، تابع زیان زبان ارتباطی بین دادههای واقعی و فرآیند بهینهسازی مدل است.
در این مقاله دیدیم که هیچ تابع زیانی بهطور مطلق بهترین انتخاب نیست. هر Loss Function رفتار متفاوتی در برابر نویز، دادههای پرت، عدم توازن کلاسها و نوع خروجی دارد. بررسی توابع مختلفfrom MSE و Cross-Entropy گرفته تا Dice، Focal، Triplet و CTCنشان داد که انتخاب صحیح تابع زیان نیازمند درک دقیق مسئله و هدف نهایی مدل است، نه صرفاً پیروی از انتخابهای رایج.
در نهایت، تابع زیان نقطه اتصال پیشبینیهای مدل با الگوریتمهای بهینهسازی مانند گرادیان کاهشی و پسانتشار است. تسلط بر این مفهوم، شما را از کاربرِ صرف مدلهای آماده به یک طراح آگاه و مهندسیمحور سیستمهای یادگیری عمیق تبدیل میکند و پایهای محکم برای ساخت مدلهای دقیقتر، پایدارتر و قابلاعتمادتر فراهم میسازد.



