

مقدمه
در آموزش مدلهای یادگیری عمیق، فقط داشتن داده و معماری مناسب کافی نیست. یکی از مهمترین عوامل مؤثر بر سرعت، پایداری و دقت یادگیری، نرخ یادگیری (Learning Rate) است.
نرخ یادگیری مشخص میکند که مدل در هر گام آموزشی، چه مقدار از خطای خود درس بگیرد و وزنها را تا چه اندازه تغییر دهد. انتخاب نادرست این مقدار میتواند باعث واگرایی مدل، نوسان شدید در فرآیند یادگیری یا توقف زودهنگام آموزش شود؛ در حالی که انتخاب آگاهانه آن، مسیر همگرایی را هموار و یادگیری را مؤثر میکند.
در این مقاله، نرخ یادگیری را از دیدگاه مفهومی و عملی بررسی میکنیم: از نقش آن در الگوریتم گرادیان کاهشی و تأثیرش بر رفتار تابع زیان، گرفته تا روشهای تنظیم پویا و پیادهسازی عملی — همه با هدفِ توضیحی شفاف و کاربردی از این مفهوم کلیدی.
تعریف
نرخ یادگیری (Learning Rate) یک هایپرپارامتر کلیدی در الگوریتمهای بهینهسازی است که اندازه گام بهروزرسانی پارامترهای مدل را در هر تکرار آموزشی تعیین میکند. این پارامتر مشخص میکند که وزنها و بایاسهای مدل، در پاسخ به گرادیان محاسبهشده از تابع زیان، با چه شدتی اصلاح شوند.
به بیان ساده، نرخ یادگیری تعیین میکند مدل چقدر سریع به سمت کمینه تابع زیان حرکت کند. اگر این مقدار بیش از حد بزرگ باشد، مدل ممکن است از نقطه بهینه عبور کرده و ناپایدار شود؛ و اگر بیش از حد کوچک انتخاب شود، فرآیند یادگیری بسیار کند یا متوقف خواهد شد. بنابراین، نرخ یادگیری نقشی حیاتی در تعادل میان سرعت یادگیری و پایداری آموزش ایفا میکند.
درک عمیقتر نرخ یادگیری و فرمول ریاضی آن
نرخ یادگیری (که اغلب با نمادهای α یا η نشان داده میشود) کلیدیترین هایپرپارامتر در شبکههای عصبی است و سرعت یادگیری مدل را کنترل میکند. این پارامتر میزان تغییر وزنها را در هر گام بهروزرسانی — در پاسخ به خطای مشاهدهشده — تعیین میکند. به عبارت دیگر، اندازهٔ گامهای بهینهسازی را مشخص میکند تا مدل به کمینهٔ تابع زیان همگرا شود.
از دیدگاه ریاضی، در روشهایی مانند گرادیان کاهشی تصادفی (SGD)، نرخ یادگیری در گرادیان تابع زیان ضرب میشود تا وزنها بهروزرسانی شوند:
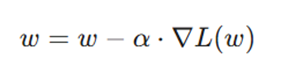
در این فرمول:
- w: نشاندهنده وزنهای مدل است.
- α: همان نرخ یادگیری است.
- L(w)∇: گرادیان تابع زیان نسبت به وزنهاست.
.
چرا نرخ یادگیری (Learning Rate) در هوش مصنوعی حیاتی است؟
نرخ یادگیری یکی از مهمترین ستونهای آموزش یک مدل هوش مصنوعی است؛ زیرا مانند یک راهنما، به مدل میآموزد که چگونه از دادههای آموزشی خود به شکلی مؤثر درس بگیرد. انتخاب این عدد، تفاوت بین یک مدل هوشمند و یک مدل سردرگم را رقم میزند.
تحلیل اثرات نرخ یادگیری بر عملکرد مدل
انتخاب نرخ یادگیری یک تعادل حساس بین سرعت و دقت است . این عدد مستقیماً بر سرعت همگرایی و کیفیت نهایی مدل تأثیر میگذارد.
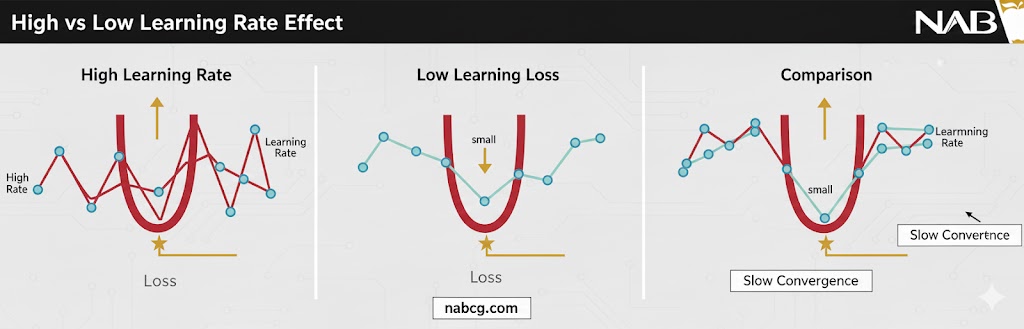
۱. نرخ یادگیری پایین (Low Learning Rate)
- همگرایی کُند: مدل برای رسیدن به پاسخ زمان زیادی نیاز دارد.
- افزایش هزینههای محاسباتی: به اپوکهای (Epoch) بیشتری برای آموزش نیاز است.
- دقت بالا: اگرچه کُند است، اما میتواند با دقت بیشتری به نقطه بهینه نزدیک شود؛ هرچند خطر گیر افتادن در کمینههای محلی را دارد.
.
۲. نرخ یادگیری بالا (High Learning Rate)
- سرعت کاذب: آموزش در ابتدا سریع به نظر میرسد.
- خطر بیشپرش: (Overshooting) مدل ممکن است از روی وزنهای بهینه بپرد و هرگز به هدف نرسد.
- ناپایداری: میتواند باعث نوسانات شدید یا حتی واگرایی (شکست) تابع زیان شود.
.
۳. نرخ یادگیری بهینه (Optimal Learning Rate)
- تعادل ایدهآل: سرعت آموزش و دقت مدل را در بهترین حالت نگه میدارد.
- پایداری: بدون صرف زمان یا منابع اضافه، مدل را به همگرایی پایدار میرساند.
.
راهنمای عیبیابی بصری: شنیدن صدای مدل از روی نمودار Loss
یک متخصص یادگیری عمیق باید بتواند مانند یک پزشک، با نگاه کردن به نوار قلبِ مدل (نمودار Loss)، مشکل نرخ یادگیری را تشخیص دهد:
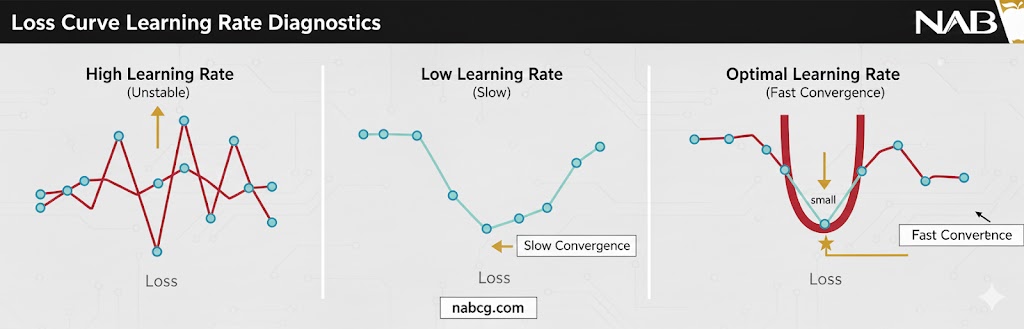
نمودار واگرا یا انفجاری(Divergence):
اگر مشاهده کردید که خطای مدل ناگهان به سمت اعداد بسیار بزرگ یا مقدار “NaN” میرود، این هشداری جدی است که نرخ یادگیری شما بسیار بالاست. در این حالت، مدل به جای حرکت آرام به سمت دره خطا، با هر گام بزرگتر، از روی دره میپرد و به سمت فضا پرتاب میشود. (Overshooting)
نمودار تخت یا ایستا(Stagnation):
اگر خطِ خطا مثل یک خط صاف افقی شده و برای اپوکهای متوالی هیچ تغییری نمیکند، نرخ یادگیری شما بیش از حد محافظهکارانه و پایین است. مدل شما عملاً در حال درجا زدن است و گامهایش آنقدر ریز است که هزاران اپوک هم برای رسیدن به نتیجه کافی نخواهد بود که این امر هزینههای محاسباتی را بیهوده افزایش میدهد.
نمودار نوسانی شدید(Oscillation):
اگر خطا مدام به شکل زیگزاگی کم و زیاد میشود، یعنی نرخ یادگیری در ابتدا خوب بوده اما اکنون که به نزدیکی نقطه بهینه رسیده، بسیار بزرگ است. مدل دورِ نقطه بهینه میچرخد اما نمیتواند درون آن آرام بگیرد؛ راه حل این مشکل استفاده از زمانبندی کاهش نرخ یادگیری (LR Decay) در انتهای آموزش است
درک شهودی نرخ یادگیری
تصور کنید یک موجود فضایی برای یادگیری درباره زندگی روی زمین به سیاره ما آمده است. او با دیدن سگ، گربه و اسب به این نتیجه میرسد که «همه حیوانات ۴ پا دارند». ناگهان او با یک مرغ روبرو میشود! واکنش او کاملاً به نرخ یادگیریاش بستگی دارد:
- نرخ یادگیری بهینه: موجود فضایی متوجه میشود که مرغ هم یک حیوان است و نتیجه میگیرد که «تعداد پاها» لزوماً معیار اصلی حیوان بودن نیست.
- نرخ یادگیری پایین: او نمیتواند از دیدن یک مرغ درس کافی بگیرد. او تصور میکند مرغ حیوان نیست چون ۴ پا ندارد و تا زمانی که مرغهای زیادی نبیند، تفکرش را تغییر نمیدهد.
- نرخ یادگیری بالا: او دچار اصلاح بیش از حد میشود. حالا نتیجه میگیرد چون مرغ حیوان است و ۲ پا دارد، پس همه حیوانات باید ۲ پا داشته باشند! در واقع او در لحظه «بیش از حد» یاد گرفته است.
.
پارامترها و موتور محرک یادگیری در شبکههای عصبی
در یادگیری عمیق، مدلها با تنظیم مداوم متغیرهایی که رفتارشان را دیکته میکنند، به تکامل میرسند. این متغیرها به دو دسته اصلی پارامترها و هایپرپارامترها تقسیم میشوند.
۱. پارامترهای یادگیری شده (Model-learned Parameters)
پارامترها همان «دانش» مدل هستند که از طریق تجربه (دادهها) به دست میآیند.
- وزنها(Weights): اینها مهمترین پارامترهای داخلی هستند که اهمیت هر ویژگی ورودی را تعیین میکنند. مدل در هر گام، وزنها را برای بهبود عملکرد تغییر میدهد.
- بایاس(Bias): به مدل اجازه میدهد تا انعطافپذیری داشته باشد و منحنی یادگیری را جابهجا کند تا با دادهها منطبق شود.
- نقش نرخ یادگیری: سرعت و میزان تغییر این پارامترها در هر مرحله توسط نرخ یادگیری کنترل میشود.
- استراتژی در فینتیونینگ: از آنجا که مدل قبلاً آموزش دیده، برای حفظ دانش قبلی و جلوگیری از تخریب وزنها، از نرخ یادگیری بسیار پایینتری استفاده میکنیم.
.
۲. هایپرپارامترها: معماران فرآیند آموزش
هایپرپارامترها قبل از شروع آموزش توسط انسان تنظیم میشوند و «نقشه راه» یادگیری را مشخص میکنند.
- نرخ یادگیری(Learning Rate): تعیینکننده مقدار گامی است که مدل به سمت کمینه خطا برمیدارد. معمولاً مقداری بین 0.0 تا 1.0 دارد.
- اپوک(Epoch): یک دور کامل عبور تمام دادههای آموزشی از شبکه6. افزایش اپوکها لزوماً بهتر نیست و ممکن است باعث بیشبرازش (Overfitting) شود.
- اندازه دسته(Batch Size): تقسیم دادهها به گروههای کوچکتر برای بهروزرسانی وزنها. دستههای کوچکتر باعث ایجاد نویز مفید برای فرار از کمینههای محلی میشوند.
در یک نگاه: اپوک «زمان» آموزش، اندازه دسته «تکرار» بهروزرسانی و نرخ یادگیری «شدت» یادگیری را تعیین میکنند.
مکانیزم بهینهسازی: قلب تپنده هوش مصنوعی
الگوریتم بهینهسازی مجموعهای از دستورات ریاضی است که به مدل میگوید چگونه خطا را کاهش دهد.
الف) تابع زیان (Loss Function)
این تابع فاصله بین پیشبینی مدل و واقعیت را محاسبه میکند. هدف هر شبکه عصبی، رساندن این مقدار به کمترین حد ممکن است.
ب) گرادیان کاهشی (Gradient Descent)
رایجترین روش برای پیمودن مسیر به سمت کمترین خطا است.
- هدف: رسیدن به کمینه محلی یا در بهترین حالت، کمینه مطلق. (Global Minimum)
- انتشار رو به عقب(Backpropagation): فرآیندی که در آن سیگنال خطا از خروجی به سمت لایههای عقب حرکت میکند تا سهم هر وزن در ایجاد خطا مشخص و اصلاح شود.
.
چگونه نرخ یادگیری بهینه را تعیین کنیم؟
بهینهسازی نرخ یادگیری در شبکههای عصبی بر دو اصل اساسی استوار است: کاهش (Decay) و مومنتوم. (Momentum) بسیاری از کتابخانههای یادگیری عمیق مثل Keras این محاسبات را به صورت خودکار مدیریت میکنند.
- کاهش(Decay): با پیشرفت آموزش، نرخ یادگیری را کُند میکند. این کار اجازه میدهد مدل ابتدا سریع یاد بگیرد و سپس با گامهای ریزتر حرکت کند تا از روی نقطه همگرایی نپرد.
- مومنتوم(Momentum): مانند اینرسی در فیزیک عمل میکند. اگر گرادیانها در یک جهت باشند، سرعت را زیاد میکند تا از کمینههای محلی (Local Minima) عبور کند. مومنتومِ کم ممکن است باعث توقف در چالههای کوچک شود و مومنتومِ زیاد ممکن است از روی دره اصلیِ خطا عبور کند.
.
روشهای جستجوی سنتی و سیستماتیک
جستجوی شبکهای (Grid Search)
در این روش، دانشمندان داده جدولی از نرخهای یادگیری احتمالی میسازند و هر کدام را تست و اعتبارسنجی میکنند.
- مزیت: بررسی جامع تمام گزینهها.
- عیب: به شدت زمانبر و از نظر محاسباتی سنگین است.
.
بهینهسازی هایپرپارامترها (Tuning)
این روش کل پیکربندی مدل را در نظر میگیرد تا بفهمد هر هایپرپارامتر چه تأثیری روی بقیه دارد. این فرآیند خودکار است اما برای تعداد زیاد پارامترها، هزینهبر میشود.
.
تکنیکهای تنظیم و تطبیق نرخ یادگیری
برای خروج از بنبستِ انتخاب یک عدد ثابت، از تکنیکهای هوشمند زیر استفاده میشود:
۱. نرخ یادگیری ثابت (Fixed)
سادهترین روش است که در آن نرخ در تمام مراحل آموزش ثابت میماند. اگرچه پیادهسازی آن آسان است، اما چون نمیتواند با مراحل مختلف آموزش (نیاز به گامهای درشت در ابتدا و ریز در انتها) تطبیق یابد، معمولاً نتایج ضعیفتری میدهد.
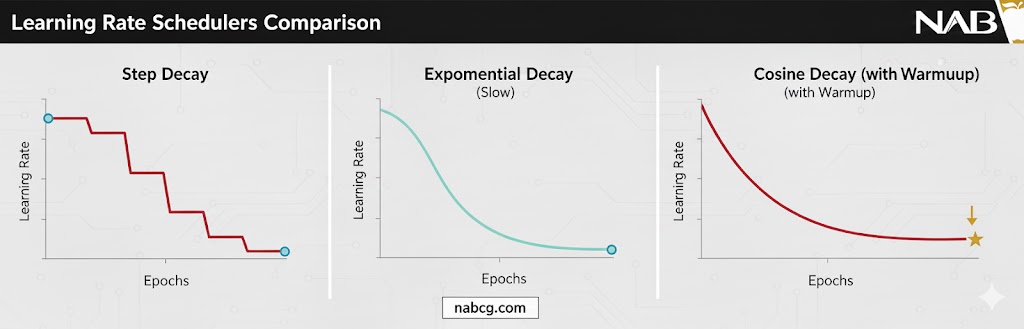
۲. زمانبندی نرخ یادگیری (Schedules)
این روشها نرخ یادگیری را طبق قوانین از پیش تعیین شده کاهش میدهند:
- کاهش پلهای(Step Decay): کاهش نرخ با یک ضریب ثابت در فواصل زمانی مشخص (مثلاً هر ۱۰ اپوک).
- کاهش نمایی(Exponential): کاهش مداوم و نمایی نرخ در طول زمان که حرکت نرمتری ایجاد میکند.
- کاهش چندجملهای(Polynomial): ارائه گذارهای بسیار نرمتر نسبت به روش پلهای.
۳. روشهای تطبیقی (Adaptive Methods)
این الگوریتمها نرخ یادگیری را به صورت پویا و برای هر پارامتر به طور جداگانه تنظیم میکنند:
- AdaGrad: بر اساس مجموع مجذور گرادیانها عمل میکند؛ برای دادههای پراکنده عالی است اما ممکن است خیلی زود نرخ یادگیری را صفر کند.
- RMSprop: با استفاده از میانگین متحرک، مشکل کاهش شدیدِ AdaGrad را حل کرده و پایداری را افزایش میدهد.
- Adam: محبوبترین روش که ترکیبی از RMSprop و مومنتوم است؛ هم سریع است و هم پایدار.
۴. نرخ یادگیری چرخهای (Cyclic)
در این روش، نرخ بین یک مقدار حداقل و حداکثر نوسان میکند. این نوسان به مدل کمک میکند تا از تلههای سطحی در سطح خطا (Loss Surface) فرار کرده و نقاط بهینه بهتری را کشف کند.
تنظیم هوشمند نرخ یادگیری در شبکههای عصبی با استفاده از PyTorch
همانطور که پیشتر بررسی کردیم، نرخ یادگیری (LR) حیاتیترین هایپرپارامتر در الگوریتم گرادیان کاهشی است. مقدار این عدد تعیین میکند که شبکه عصبی با چه سرعتی به سمت کمینه خطا (Minima) حرکت کند. معمولاً ما یک نرخ یادگیری اولیه را انتخاب کرده و بر اساس نتایج، آن را برای رسیدن به مقدار بهینه تغییر میدهیم.
- اگر نرخ یادگیری بیش از حد پایین باشد: فرآیند همگرایی بسیار کُند شده و زمان آموزش به شدت طولانی میشود.
- اگر نرخ یادگیری بیش از حد بالا باشد: همگرایی سریع به نظر میرسد، اما خطر بزرگی وجود دارد که تابع زیان دچار بیشپرش (Overshoot) شود و از روی نقطه بهینه عبور کند.
بنابراین، ما همیشه در حال تنظیم دستی این پارامتر هستیم؛ اما آیا راهی برای بهبود و خودکارسازی این فرآیند وجود دارد؟
چرا باید نرخ یادگیری را در طول زمان تغییر دهیم؟
به جای استفاده از یک نرخ یادگیری ثابت در کل طول آموزش، استراتژی هوشمندانهتر این است که با یک LR بالاتر شروع کنیم (برای حرکت سریع در مراحل اولیه) و سپس مقدار آن را به صورت دورهای پس از تکرارهای مشخص، کاهش دهیم.
این روش دو مزیت اصلی دارد:
- سرعت در ابتدا: در شروع کار که مدل فاصله زیادی با هدف دارد، با گامهای بلند سریعتر پیش میرویم.
- دقت در انتها: با نزدیک شدن به نقطه بهینه، گامها را ریزتر میکنیم تا شانس اورشوت کردن (Overshooting) کاهش یابد و مدل با پایداری کامل در کمینه خطا مستقر شود.
epochs = 10
scheduler = <Any scheduler>
for epoch in range(epochs):
# Training Steps
# Validation Steps
scheduler.step()
زمانبندیهای پرکاربرد در torch.optim.lr_scheduler
کتابخانه پایتورچ (PyTorch) چندین متد مختلف را برای تنظیم نرخ یادگیری بر اساس تعداد اپوکها (Epochs) ارائه میدهد. بیایید نگاهی به یکی از پرکاربردترین آنها بیندازیم:
StepLR
این زمانبندی، نرخ یادگیری را در هر بازهی مشخص که با step_size تعیین میشود، در مقدار gamma ضرب میکند.
- مثال کاربردی: اگر نرخ یادگیری اولیه lr = 0.1 باشد، مقدار gamma = 0.1 و step_size = 10 در نظر گرفته شود، پس از ۱۰ اپوک، نرخ یادگیری به lr ✕ gamma تغییر یافته و برابر با 0.01 میشود.
- ادامه فرآیند: پس از گذشت ۱۰ اپوک دیگر (در مجموع ۲۰ اپوک)، نرخ یادگیری مجدداً کاهش یافته و به 0.001 میرسد.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1 and step_size = 10
lr = 0.1 for epoch < 10
lr = 0.01 for epoch >= 10 and epoch < 20
lr = 0.001 for epoch >= 20 and epoch < 30
... and so on
MultiStepLR
این یک نسخه سفارشیسازی شده از StepLR است که در آن نرخ یادگیری (LR) پس از رسیدن به اپوکهای خاصی تغییر میکند. در این متد، ما مجموعهای از نقاط هدف (Milestones) را ارائه میدهیم؛ این نقاط در واقع همان اپوکهایی هستند که میخواهیم در آنها نرخ یادگیری خود را بهروزرسانی کنیم.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = MultiStepLR(optimizer, milestones=[10,30], gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1 and milestones=[10,30]
lr = 0.1 for epoch < 10
lr = 0.01 for epoch >= 10 and epoch < 30
lr = 0.001 for epoch >= 30
ExponentialLR
این یک نسخه تهاجمیتر از StepLR است که در آن نرخ یادگیری (LR) پس از هر اپوک (Epoch) تغییر میکند. شما میتوانید این متد را به عنوان یک StepLR در نظر بگیرید که در آن مقدار step_size برابر با ۱ تنظیم شده است.
# Code format:-
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = ExponentialLR(optimizer, gamma=0.1)
# Procedure:-
lr = 0.1, gamma = 0.1
lr = 0.1 for epoch = 1
lr = 0.01 for epoch = 2
lr = 0.001 for epoch = 3
... and so on
ReduceLROnPlateau
این متد زمانی نرخ یادگیری را کاهش میدهد که بهبود در یک معیار مشخص (Metric) متوقف شده باشد. مدلها اغلب از کاهش نرخ یادگیری با ضریبی بین ۲ تا ۱۰، پس از اینکه فرآیند یادگیری به ثبات (Stagnation) رسید، سود میبرند.
این زمانبندی، مقدارِ یک معیار (مانند دقت یا زیان) را مطالعه کرده و اگر برای تعداد مشخصی از اپوکها (Patience) هیچ بهبودی در آن مشاهده نشود، نرخ یادگیری را کاهش میدهد
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
# In min mode, lr will be reduced when the metric has stopped decreasing.
# In max mode, lr will be reduced when the metric has stopped increasing.
آموزش شبکههای عصبی با استفاده از زمانبندیها (Schedulers)
برای این بخش آموزشی، ما از مجموعه دادههای MNIST استفاده خواهیم کرد؛ بنابراین کار را با بارگذاری دادهها آغاز کرده و سپس مدل را تعریف میکنیم. توصیه میشود که پیش از شروع، با نحوه ساخت و آموزش یک شبکه عصبی در PyTorch آشنایی داشته باشید. بیایید با بارگذاری دادههایمان شروع کنیم.
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor()
])
train = datasets.MNIST('',train = True, download = True, transform=transform)
valid = datasets.MNIST('',train = False, download = True, transform=transform)
trainloader = DataLoader(train, batch_size= 32, shuffle=True)
validloader = DataLoader(test, batch_size= 32, shuffle=True)
اکنون که بارگذاریکننده دادههای ما (Dataloader) آماده شده است، میتوانیم برای ساخت مدل خود اقدام کنیم. مدلهای پایتورچ (PyTorch) از ساختار و فرمت زیر پیروی میکنند:
from torch import nn
class model(nn.Module):
def __init__(self):
# Define Model Here
def forward(self, x):
# Define Forward Pass Here
با توجه به توضیحات قبلی، بیایید مدل خود را تعریف کنیم:
import torch
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28,256)
self.fc2 = nn.Linear(256,128)
self.out = nn.Linear(128,10)
self.lr = 0.01
self.loss = nn.CrossEntropyLoss()
def forward(self,x):
batch_size, _, _, _ = x.size()
x = x.view(batch_size,-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.out(x)
model = Net()
# Send the model to GPU if available
if torch.cuda.is_available():
model = model.cuda()
اکنون که مدل خود را در اختیار داریم، میتوانیم بهینهساز (Optimizer)، تابع زیان (Loss Function) و زمانبندی نرخ یادگیری (lr_scheduler) خود را مشخص کنیم. ما از بهینهساز SGD، تابع زیان CrossEntropyLoss و زمانبندی ReduceLROnPlateau برای مدیریت نرخ یادگیری استفاده خواهیم کرد.
from torch.optim import SGD
from torch.optim.lr_scheduler import ReduceLROnPlateau
optimizer = SGD(model.parameters(), lr = 0.1)
loss = nn.CrossEntropyLoss()
scheduler = ReduceLROnPlateau(optimizer, 'min', patience = 5)
بیایید حلقه آموزشی (Training Loop) را تعریف کنیم. ساختار حلقه آموزشی دقیقاً مشابه حالتهای قبلی است؛ با این تفاوت که این بار، متدِ step مربوط به زمانبندی (scheduler) خود را در انتهای حلقه فراخوانی میکنیم.
from tqdm.notebook import trange
epoch = 25
for e in trange(epoch):
train_loss, valid_loss = 0.0, 0.0
# Set model to training mode
model.train()
for data, label in trainloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
target = model(data)
train_step_loss = loss(target, label)
train_step_loss.backward()
optimizer.step()
train_loss += train_step_loss.item() * data.size(0)
# Set model to Evaluation mode
model.eval()
for data, label in validloader:
if torch.cuda.is_available():
data, label = data.cuda(), label.cuda()
target = model(data)
valid_step_loss = loss(target, label)
valid_loss += valid_step_loss.item() * data.size(0)
curr_lr = optimizer.param_groups[0]['lr']
print(f'Epoch {e}\t \
Training Loss: {train_loss/len(trainloader)}\t \
Validation Loss:{valid_loss/len(validloader)}\t \
LR:{curr_lr}')
scheduler.step(valid_loss/len(validloader))
خروجی:
.
همانطور که مشاهده میکنید، زمانی که مقدار خطای اعتبارسنجی (Validation Loss) دیگر کاهش نیافت، زمانبند (Scheduler) به تنظیم مجدد نرخ یادگیری (lr) ادامه داد.
جمع بندی
نرخ یادگیری یکی از حساسترین و تأثیرگذارترین پارامترها در آموزش مدلهای یادگیری عمیق است که مستقیماً بر رفتار الگوریتم بهینهسازی و کیفیت همگرایی مدل اثر میگذارد. این پارامتر تعیین میکند که مدل چگونه از خطاهای خود بیاموزد و با چه سرعتی به سمت پاسخ بهینه حرکت کند.
در این مقاله دیدیم که نرخ یادگیری ثابت همیشه بهترین انتخاب نیست و در بسیاری از مسائل واقعی، استفاده از روشهای تنظیم پویا مانند Learning Rate Schedulerها میتواند به همگرایی سریعتر و پایدارتر منجر شود. همچنین بررسی مثالهای عملی نشان داد که تحلیل نمودار Loss یکی از مؤثرترین راهها برای تشخیص مناسب یا نامناسب بودن نرخ یادگیری است.
در نهایت، نرخ یادگیری را میتوان فرمان هدایت فرآیند یادگیری دانست؛ پارامتری که در کنار تابع زیان، الگوریتم بهینهسازی و معماری مدل، مسیر آموزش را شکل میدهد. تسلط بر این مفهوم به شما کمک میکند مدلها را نه بهصورت آزمونوخطا، بلکه با نگاهی تحلیلی و مهندسی تنظیم و بهینهسازی کنید.



