

1.چکیده
الگوریتم Fuzzy C-Means (FCM) یکی از مهمترین روشهای خوشهبندی فازی در یادگیری بدون ناظر است که برخلاف روشهای سخت مانند K-Means، هر نقطه داده را فقط به یک خوشه محدود نمیکند، بلکه برای آن درجاتی از عضویت در چند خوشه بهصورت همزمان در نظر میگیرد. این ویژگی باعث میشود FCM در مسائلی که مرز خوشهها شفاف نیست یا دادهها بهطور طبیعی همپوشانی دارند، انتخابی مناسبتر باشد.
در این مقاله، ابتدا مفاهیم پایه خوشهبندی فازی و تفاوت آن با خوشهبندی سخت را توضیح میدهیم، سپس تابع هدف و روابط ریاضی اصلی الگوریتم را بهصورت دقیق بررسی میکنم. در ادامه، مراحل اجرای الگوریتم، معیار توقف و منطق بهروزرسانی مراکز خوشه و درجات عضویت ارائه میشود. برای تثبیت یادگیری، چند مثال عددی گامبهگام نیز آورده شده است. در پایان، کاربردهای واقعی، مزایا، محدودیتها، مقایسه با روشهای مشابه و مسیرهای توسعه آینده FCM بررسی میشود تا خواننده بتواند هم درک نظری مناسبی از الگوریتم به دست آورد و هم برای استفاده عملی از آن آمادگی پیدا کند.
2.مقدمه
در بسیاری از مسائل واقعی، دادهها مرزبندی کاملاً روشن و قطعی ندارند. برای مثال، در تحلیل مشتریان، تشخیص بیماری، پردازش تصویر یا تحلیل اسناد، ممکن است یک نمونه بهطور همزمان به چند الگو شباهت داشته باشد. در چنین شرایطی، روشهای خوشهبندی سخت که هر نمونه را فقط به یک خوشه اختصاص میدهند، همیشه بهترین مدلسازی را ارائه نمیکنند.
الگوریتم Fuzzy C-Means که معمولاً بهاختصار FCM نامیده میشود، برای حل همین مسئله طراحی شده است. ایده اصلی این الگوریتم آن است که هر داده به هر خوشه، با یک درجه عضویت تعلق دارد؛ درجهای که معمولاً مقداری بین صفر و یک است. به این ترتیب، FCM میتواند ساختارهای مبهم، پیوسته و همپوشان را بهتر از بسیاری از روشهای کلاسیک مدل کند.
هدف من در این مقاله، ارائه یک آموزش جامع، دقیق و قابلاتکا از الگوریتم FCM است. ابتدا تعاریف و مفاهیم پایه را مرور میکنم، سپس به ضرورت استفاده از این روش، مبانی نظری و ریاضی، مراحل اجرای الگوریتم، مثالهای عددی، کاربردها، مزایا، محدودیتها و مقایسه با روشهای مشابه میپردازم.
.
3.تعاریف و مفاهیم پایه
خوشهبندی (Clustering) چیست؟
خوشهبندی یکی از وظایف اصلی یادگیری بدون ناظر (Unsupervised Learning) است. در خوشهبندی، هدف آن است که مجموعهای از دادهها به گروههایی تقسیم شوند که اعضای هر گروه از نظر یک معیار شباهت، به هم نزدیکتر و از اعضای سایر گروهها دورتر باشند (Jain, 2010).
خوشهبندی سخت در برابر خوشهبندی فازی
در خوشهبندی سخت (Hard Clustering)، هر داده فقط به یک خوشه تعلق دارد. برای مثال، در K-Means اگر یک نقطه به خوشه دوم اختصاص داده شود، دیگر عضوی از خوشههای دیگر نیست.
اما در خوشهبندی فازی (Fuzzy Clustering)، هر داده میتواند همزمان به چند خوشه تعلق داشته باشد، با این تفاوت که میزان تعلق آن به هر خوشه متفاوت است. این میزان تعلق با درجه عضویت (Membership Degree) نشان داده میشود.

برای نمونه، اگر یک داده دارای درجات عضویت زیر باشد:
(0.7, 0.2, 0.1)
یعنی این داده با احتمال یا شدت بیشتری به خوشه اول شبیه است، اما شباهت کمتری نیز با خوشه دوم و سوم دارد. باید توجه کرد که در FCM، این اعداد احتمال به معنای آماری دقیق نیستند، بلکه شدت تعلق فازی را بیان میکنند.
مجموعه فازی (Fuzzy Set)
مفهوم مجموعه فازی توسط Zadeh (1965) معرفی شد. در مجموعههای کلاسیک، عضویت یک عنصر فقط دو حالت دارد: عضو هست یا نیست. اما در مجموعه فازی، عضویت میتواند پیوسته و بین صفر و یک باشد. FCM این ایده را به مسئله خوشهبندی تعمیم میدهد.
مرکز خوشه در FCM
در الگوریتم FCM، هر خوشه دارای یک مرکز (Cluster Center) یا Prototype است. این مرکز مشابه centroid در K-Means است، اما محاسبه آن بر اساس درجات عضویت فازی انجام میشود، نه تخصیص قطعی دادهها.
پارامتر فازیساز m
یکی از مهمترین اجزای FCM، پارامتری به نام فازیساز یا fuzzifier است که معمولاً با m نمایش داده میشود. این پارامتر میزان فازیبودن عضویتها را کنترل میکند. هرچه m به 1 نزدیکتر باشد، رفتار الگوریتم به خوشهبندی سخت نزدیکتر میشود. با افزایش m، درجات عضویت نرمتر و پخشتر میشوند (Bezdek, 1981).
ماتریس عضویت
خروجی اصلی FCM فقط مراکز خوشه نیست، بلکه یک ماتریس عضویت نیز تولید میکند که در آن، سطرها معمولاً متناظر با خوشهها و ستونها متناظر با دادهها هستند. هر درایه نشان میدهد یک داده با چه شدتی به یک خوشه تعلق دارد.

تمایز FCM با K-Means
FCM و K-Means هر دو الگوریتمهای مرکز-مبنا هستند، اما تفاوت اصلی آنها در نوع انتساب دادههاست:
- K-Means: انتساب قطعی و سخت
- FCM: انتساب نرم و فازی
به همین دلیل، FCM در دادههایی که خوشهها همپوشانی دارند، معمولاً توصیف واقعبینانهتری ارائه میدهد.
.
4.مسئلهای که این روش حل میکند؛ اهمیت و ضرورت
الگوریتم FCM مسئلهای را حل میکند که در آن تقسیم قطعی دادهها به خوشههای کاملاً مجزا، با ماهیت واقعی داده سازگار نیست. در بسیاری از مجموعهدادهها، نمونهها در ناحیه مرزی میان چند خوشه قرار میگیرند و انتساب اجباری آنها به فقط یک گروه، باعث از دست رفتن بخشی از اطلاعات ساختاری داده میشود.
برای مثال، در دادههای پزشکی، یک بیمار ممکن است همزمان نشانههایی از چند الگوی بالینی را داشته باشد. در تحلیل مشتری، یک فرد میتواند هم به دسته «خریدار وفادار» و هم تا حدی به دسته «حساس به قیمت» نزدیک باشد. پس در پردازش تصویر نیز پیکسلهای مرزی ممکن است متعلق به چند ناحیه باشند. در چنین مسائلی، مدل سخت نمیتواند ابهام طبیعی داده را بازنمایی کند.
ضرورت FCM دقیقاً از همینجا ناشی میشود: این الگوریتم امکان میدهد ابهام، همپوشانی و تدریجیبودن مرز خوشهها مستقیماً در مدل وارد شود. بنابراین FCM فقط یک جایگزین برای K-Means نیست، بلکه پاسخی است به وضعیتی که در آن، تعریف کلاسیک «هر داده فقط در یک خوشه» از ابتدا فرض مناسبی نیست. به بیان دیگر، FCM برای مسئلهای طراحی شده است که در آن، ساختار واقعی دادهها بیشتر فازی است تا قطعی (Bezdek et al., 1984).
.
5. مبانی نظری و ریاضی
الگوریتم FCM بر پایه کمینهسازی یک تابع هدف فازی عمل میکند. فرض کنید:
- تعداد دادهها برابر n باشد.
- تعداد خوشهها برابر cباشد.
- دادهها بهصورت X={x1,x2,…,xn} تعریف شوند.
- مرکز خوشه j-ام با vj نمایش داده شود.
- درجه عضویت داده xi در خوشه j با uij نشان داده شود.
- پارامتر فازیساز با m نمایش داده شود، بهطوری که m>1.

تابع هدف FCM
تابع هدف استاندارد الگوریتم FCM بهصورت زیر است:
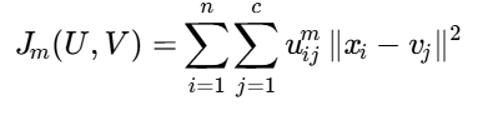
توضیح نمادها
- Jm (U, V): تابع هدف فازی که باید کمینه شود
- U: ماتریس عضویت
- V: مجموعه مراکز خوشه
- uij: درجه عضویت نمونه i در خوشه j
- m: پارامتر فازیساز
- ^2∥ xi− vj∥ : مربع فاصله اقلیدسی بین نمونه xi و مرکز خوشه vj
تفسیر تابع هدف
این تابع تلاش میکند دادهها را طوری خوشهبندی کند که:
- نمونهها به مراکز نزدیکتر، عضویت بیشتری بگیرند؛
- مجموع فاصلههای وزندهیشده با درجات عضویت، حداقل شود.
اگر uij برای یک خوشه بزرگ باشد، سهم فاصله آن داده از مرکز همان خوشه در تابع هدف بیشتر میشود. بنابراین الگوریتم میکوشد هم عضویتها را منطقی تنظیم کند و هم مراکز را در مکان مناسبی قرار دهد.
قیود ماتریس عضویت
درجات عضویت باید شرایط زیر را ارضا کنند:
0 ≤ uij ≤ 1
iبرای هر
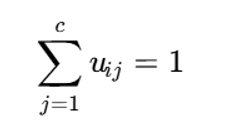
این قید دوم یعنی مجموع درجات عضویت هر داده در تمام خوشهها باید برابر 1 باشد.
رابطه بهروزرسانی مراکز خوشه
با کمینهسازی تابع هدف نسبت به مراکز خوشه، رابطه زیر به دست میآید:
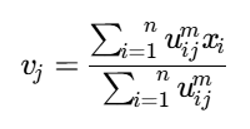
توضیح متغیرها
- vj: مرکز خوشه j-ام
- uij^m: وزن فازی داده xi در محاسبه مرکز خوشه j
- صورت کسر: مجموع وزندار دادهها
- مخرج کسر: مجموع وزنها
این فرمول نشان میدهد که مرکز هر خوشه، میانگین وزندار نقاط است؛ با این تفاوت که وزن هر نقطه از درجه عضویت فازی آن ناشی میشود.
رابطه بهروزرسانی درجات عضویت
با کمینهسازی تابع هدف نسبت به uij، رابطه زیر برای عضویتها حاصل میشود:
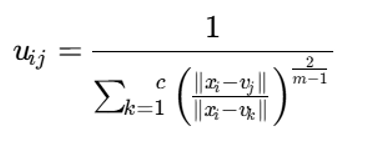
توضیح متغیرها
- uij: درجه عضویت داده xi در خوشه j
- vj: مرکز خوشه j
- vk: مرکز خوشه k
- m: پارامتر فازیساز
- توان 2 / (m-1) : عامل کنترل نرمی عضویتها
فرضهای پایه
الگوریتم FCM در شکل استاندارد خود معمولاً این فرضها را دارد:
- تعداد خوشهها cاز قبل مشخص است.
- از فاصله اقلیدسی استفاده میشود، مگر آنکه نسخه تعمیمیافتهای از الگوریتم به کار رود.
- دادهها در فضایی تعریف شدهاند که مفهوم مرکز خوشه و فاصله در آن معنادار باشد.
- ساختار خوشهها تا حدی با مراکز نمونهوار قابل توصیف باشد.
مثال عددی کوتاه برای درک فرمول مرکز خوشه
فرض کنید برای یک خوشه، سه نقطه و درجات عضویت فازی آنها بهصورت زیر باشد و m=2m=2m=2:
- x1=2 , u11=0.8
- x2=4 , u21=0.
- x3=6 , u31=0.3
ابتدا توان دوم عضویتها را حساب میکنیم:
- 0.8^2 = 0.64
- 0.6^2 = 0.36
- 0.3^2 = 0.09
اکنون مرکز خوشه:
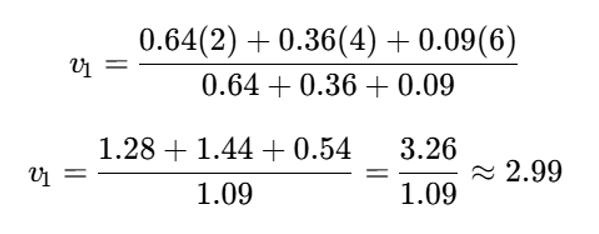
بنابراین مرکز خوشه تقریباً برابر 3 است. مشاهده میشود که نقطهای که عضویت بیشتری دارد، نقش بیشتری در تعیین مرکز خوشه ایفا میکند.
.
6. مراحل گام به گام اجرای الگوریتم
در این بخش، فرایند اجرایی FCM را از ورودی تا خروجی بهصورت مرحلهبهمرحله توضیح میدهم.
ورودیهای الگوریتم
- مجموعه داده
- تعداد خوشهها c
- پارامتر فازیساز m>1
- آستانه توقف ε
- حداکثر تعداد تکرارها
خروجیهای الگوریتم
- مراکز خوشهها: V={v1,v2,…,vc}
- ماتریس عضویت: U=[uij]
مراحل اجرا
گام 1: مقداردهی اولیه
یک ماتریس عضویت اولیه (0) ^ U تولید میشود، بهطوری که:
- همه درایهها بین 0 و 1 باشند.
- مجموع عضویتهای هر داده در همه خوشهها برابر 1 باشد.
این مقداردهی معمولاً بهصورت تصادفی انجام میشود.
گام 2: محاسبه مراکز خوشه
با استفاده از ماتریس عضویت فعلی، مرکز هر خوشه طبق رابطه زیر محاسبه میشود:
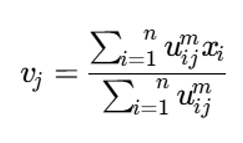
گام 3: بهروزرسانی درجات عضویت
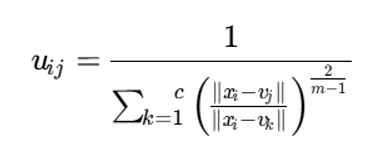
پس از محاسبه مراکز، عضویت هر داده نسبت به هر خوشه بهصورت زیر بهروزرسانی میشود:
اگر فاصله یک داده تا یک مرکز صفر شود، برای جلوگیری از تقسیم بر صفر، آن داده معمولاً عضویت 1 برای همان خوشه و 0 برای سایر خوشهها دریافت میکند.
گام 4: بررسی معیار توقف
اگر تغییر ماتریس عضویت یا تغییر مراکز خوشه از یک آستانه مشخص کمتر شود، الگوریتم متوقف میشود. بهصورت معمول:
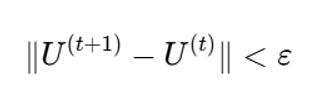
که در آن:
- (t)U^: ماتریس عضویت در تکرار t
- ε: آستانه خطا یا معیار توقف
در غیر این صورت، الگوریتم به گام 2 بازمیگردد.
.
شبهکد FCM
X، تعداد خوشهها c، پارامتر m، آستانه ε، حداکثر تکرار T
1. ماتریس عضویت U را بهصورت تصادفی مقداردهی اولیه کن
2. برای t = 1 تا T:
3. مراکز خوشهها V را با استفاده از U محاسبه کن
4. درجات عضویت جدید U را با استفاده از V بهروزرسانی کن
5. اگر ||U_new - U_old|| < ε:
6. توقف
7. در غیر این صورت:
8. U = U_new
9. خروجی: مراکز خوشهها V و ماتریس عضویت U
نکته آموزشی مهم
اگر در پایان بخواهیم یک برچسب قطعی نیز برای هر داده داشته باشیم، میتوانیم داده را به خوشهای نسبت دهیم که بیشترین درجه عضویت را دارد. با این حال، این فقط یک نگاشت ثانویه است و ماهیت اصلی FCM همچنان فازی باقی میماند.
.
7. مثالهای عددی
در این بخش، چهار مثال آموزشی از ساده به کمی پیشرفتهتر ارائه میکنم تا منطق الگوریتم FCM بهخوبی تثبیت شود.
.
مثال 1: محاسبه مرکز یک خوشه فازی در داده یکبعدی
صورت مسئله
سه داده یکبعدی داریم و میخواهیم مرکز یک خوشه را با استفاده از درجات عضویت دادهشده محاسبه کنیم. فرض کنید m=2.
داده ورودی
- x1=1 , u11=0. 9
- x2=3 , u21=0.5
- x3=5 , u31=0.2
حل گامبهگام
ابتدا توان دوم عضویتها را محاسبه میکنیم:
- 0.9^2 = 0.81
- 0.5^2 = 0.25
- 0.2^2 = 0.04
اکنون از فرمول مرکز خوشه استفاده میکنیم:
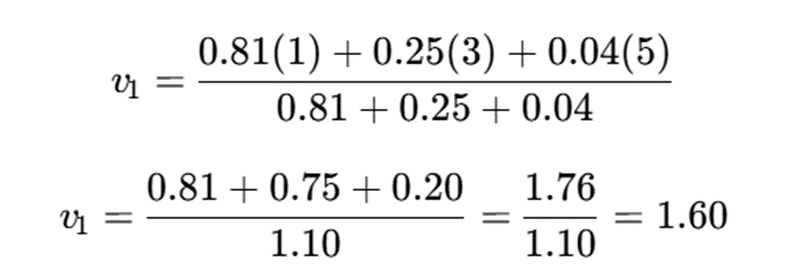
پاسخ نهایی
v1=1.60
تفسیر نتیجه
چون داده x1=1 عضویت بسیار بیشتری دارد، مرکز خوشه به آن نزدیکتر شده است. این مثال نشان میدهد که در FCM، همه دادهها نقش یکسانی در تعیین مرکز خوشه ندارند.
.
مثال 2: محاسبه درجه عضویت یک نقطه در دو خوشه
صورت مسئله
فرض کنید یک داده x=4 و دو مرکز خوشه داریم: v1 = 2 و v2 = 2 میخواهیم درجات عضویت این داده را در دو خوشه به دست آوریم. فرض کنید m=2
داده ورودی
- x=4
- v1=2
- v2=8
حل گامبهگام
ابتدا فاصلهها را حساب میکنیم:
∥x−v1∥=∣4−2∣=2
∥x−v2∥=∣4−8∣=4
برای m = 2، توان رابطه عضویت برابر است با:
2 / (m−1) = 2 / 1=2
اکنون برای خوشه اول:
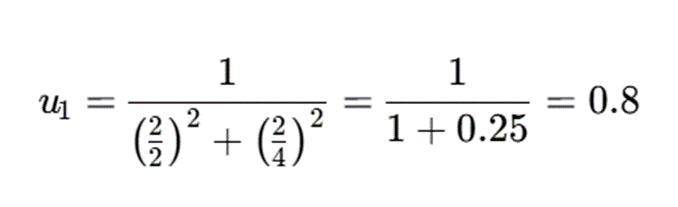
برای خوشه دوم:
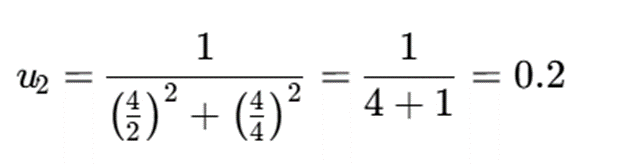
پاسخ نهایی
- عضویت در خوشه اول: 0.8
- عضویت در خوشه دوم: 0.2
تفسیر نتیجه
این نتیجه طبیعی است، زیرا داده x=4 به مرکز اول نزدیکتر از مرکز دوم است. در عین حال، چون FCM فازی است، داده بهطور کامل از خوشه دوم حذف نمیشود.
.
مثال 3: یک تکرار ساده FCM در داده یکبعدی
صورت مسئله
دو خوشه و سه داده یکبعدی داریم. ماتریس عضویت اولیه داده شده است. هدف این است که یک بار مراکز خوشه را محاسبه کنیم.
داده ورودی
دادهها:
x1=1 , x2=4 , x3=7
ماتریس عضویت اولیه:

و m=2
حل گامبهگام
خوشه اول
عضویتهای تواندار:
- 0.8^2=0.64
- 0.6^2=0.36
- 0.2^2=0.04
مرکز خوشه اول:
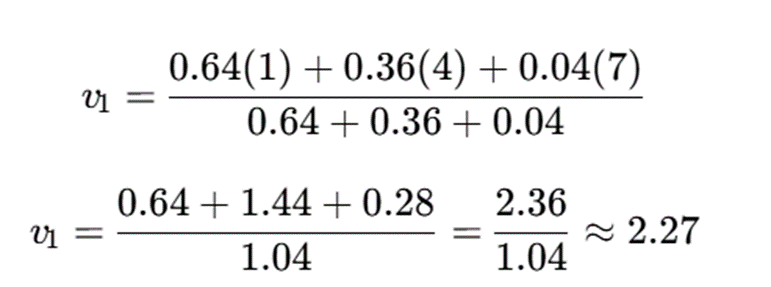
خوشه دوم
عضویتهای تواندار:
- 0.2^2=0.04
- 0.4^2=0.16
- 0.8^2=0.64
مرکز خوشه دوم:
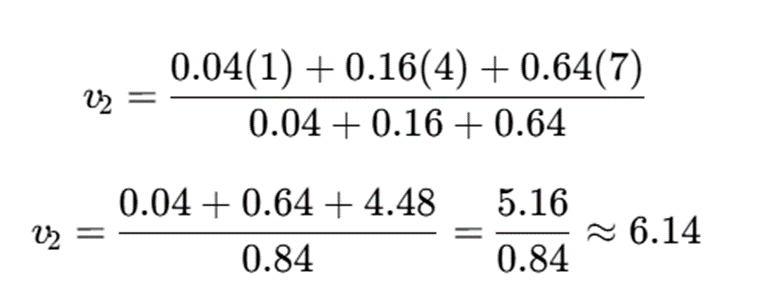
پاسخ نهایی
- v1≈2.27
- v2≈6.14
تفسیر نتیجه
مرکز خوشه اول به سمت دادههای کوچکتر و مرکز خوشه دوم به سمت دادههای بزرگتر قرار گرفته است. این با الگوی عضویت اولیه سازگار است.
.
مثال 4: تفسیر خروجی فازی در یک داده مرزی
صورت مسئله
فرض کنید در یک مسئله خوشهبندی، برای یک نمونه خاص، درجات عضویت زیر به دست آمده است:
(0.45, 0.40, 0.15)
داده ورودی
- تعداد خوشهها: 3
- درجه عضویت یک نمونه: 0.45، 0.40، 0.150
حل گامبهگام
از نظر محاسباتی، این خروجی نشان میدهد:
- نمونه بیشترین تعلق را به خوشه اول دارد.
- فاصله آن با خوشه دوم نیز کم است.
- تعلق آن به خوشه سوم نسبتاً ضعیف است.
پاسخ نهایی
اگر بخواهیم برچسب سخت استخراج کنیم، این نمونه به خوشه اول اختصاص داده میشود، چون 0.45 بیشترین مقدار است.
تفسیر نتیجه
نکته مهم این است که این نمونه مرزی است و برخلاف K-Means، FCM این ابهام را حفظ میکند. این دقیقاً یکی از دلایل ارزشمند بودن خوشهبندی فازی در مسائل واقعی است.
.
8. کاربردهای واقعی
- بخشبندی تصویر (Image Segmentation): برای جداسازی نواحی تصویر، بهویژه در پیکسلهای مرزی که به چند ناحیه شباهت دارند.
- تصویربرداری پزشکی: در تحلیل MRI، CT و دادههای پزشکی که مرز بافتها همیشه شفاف نیست (Pham et al., 2000).
- تحلیل مشتریان: برای مدلسازی مشتریانی که رفتارشان بین چند الگوی خرید قرار میگیرد.
- سیستمهای توصیهگر: برای گروهبندی نرم کاربران یا آیتمها بر اساس شباهت رفتاری.
- متنکاوی و خوشهبندی اسناد: وقتی یک سند به بیش از یک موضوع نزدیک باشد.
- تشخیص الگو (Pattern Recognition): در دادههایی که کلاسها همپوشانی دارند.
- زیستاطلاعات (Bioinformatics): برای تحلیل دادههای ژنی و بیان ژن با مرزهای غیرقطعی.
- تحلیل دادههای مکانی و محیطی: وقتی نواحی جغرافیایی به چند الگوی اقلیمی یا کاربری نزدیک باشند.
- دادههای مکانی و سنجش از دور در مسائل دارای مرزهای تدریجی
- تحلیل سیگنال در مسائل مهندسی برق و مخابرات
.
9. مزایا
- توانایی مدلسازی همپوشانی بین خوشهها
- ارائه درجه عضویت بهجای تصمیم قطعی
- مناسب برای دادههایی با مرزهای مبهم و تدریجی
- تفسیرپذیری مناسب در بسیاری از مسائل تحلیلی
- تعمیمپذیری بهتر نسبت به روشهای سخت در برخی دادههای واقعی
- امکان استخراج هم خروجی فازی و هم برچسب سخت نهایی از روی عضویتها
- کاربردپذیری بالا در پردازش تصویر، پزشکی و تشخیص الگو
- سادگی مفهومی و ساختار ریاضی نسبتاً روشن (Bezdek, 1981)
.
10.محدودیتها و معایب
- نیاز به تعیین تعداد خوشهها c از پیش
- حساسیت به مقداردهی اولیه
- امکان گیر افتادن در بهینه محلی
- حساسیت به دادههای پرت و نویز، بهویژه در نسخه استاندارد
- وابستگی عملکرد به انتخاب مناسب پارامتر m
- هزینه محاسباتی بیشتر نسبت به K-Means در بسیاری از مسائل
- فرض ضمنی درباره مناسببودن مراکز خوشه و فاصله اقلیدسی
- عملکرد ضعیفتر در دادههایی با خوشههای بسیار نامتقارن یا ساختارهای غیرکروی
.
11. مقایسه با روشهای مشابه
مقایسه FCM با K-Means و Gaussian Mixture Model
| ویژگی | FCM | K-Means | Gaussian Mixture Model (GMM) |
| نوع عضویت | فازی | سخت | احتمالی |
| خروجی اصلی | درجه عضویت + مراکز | برچسب خوشه + مراکز | احتمال تعلق + پارامترهای توزیع |
| نیاز به تعداد خوشه | دارد | دارد | دارد |
| حساسیت به مقداردهی اولیه | نسبتاً بالا | بالا | بالا |
| مناسب برای داده همپوشان | بله | کمتر | بله |
| تفسیر مرکز خوشه | میانگین فازی | centroid | میانگین توزیعی |
| پیچیدگی محاسباتی | متوسط | پایینتر | معمولاً بالاتر |
| پایه نظری | مجموعه فازی | کمینهسازی واریانس درونخوشهای | مدلسازی آماری |
تحلیل مقایسه
- در مقایسه با K-Means:
FCM زمانی مناسبتر است که دادهها مرز شفاف نداشته باشند. اما اگر هدف فقط یک خوشهبندی سریع و ساده روی دادههای نسبتاً مجزا باشد، K-Means معمولاً ارزانتر و سریعتر است. K-Means اطلاعات غنیتری ارائه میدهد، اما محاسبات بیشتری نیاز دارد.
- در مقایسه با GMM:
FCM عضویت فازی ارائه میدهد، در حالی که GMM بر پایه احتمال و فرض توزیع گاوسی عمل میکند. اگر دادهها با مدل آماری گاوسی سازگار باشند، GMM تفسیر آماری قویتری دارد؛ اما FCM اغلب از نظر مفهومی و پیادهسازی سادهتر است.
- در مقایسه با Hierarchical Clustering:
روشهای سلسلهمراتبی ساختار درختی ارائه میدهند، اما معمولاً خروجی فازی استاندارد مانند FCM ندارند و در دادههای بزرگ نیز میتوانند پرهزینه باشند.
.
12. نوآوریها و چشمانداز آینده
اگرچه FCM یک الگوریتم کلاسیک در خوشهبندی فازی است، اما همچنان موضوع پژوهشهای جدید باقی مانده است. بخش مهمی از توسعههای اخیر بر رفع محدودیتهای نسخه استاندارد، افزایش مقاومت در برابر نویز، بهبود مقیاسپذیری و ترکیب با روشهای یادگیری مدرن متمرکز بوده است.
.
12.1 نسخههای مقاوم در برابر نویز و دادههای پرت
یکی از نقدهای اصلی به FCM استاندارد، حساسیت آن به دادههای پرت است. به همین دلیل، نسخههایی مانند Possibilistic C-Means (PCM) و مدلهای ترکیبی فازی-امکانی توسعه یافتهاند تا اثر نقاط غیرعادی را کاهش دهند (Krishnapuram & Keller, 1993).
.
12.2 ادغام با اطلاعات مکانی در پردازش تصویر
در تصویربرداری پزشکی و بخشبندی تصویر، پژوهشگران نسخههایی از FCM را توسعه دادهاند که علاوه بر شدت پیکسل، از اطلاعات همسایگی و ساختار مکانی نیز استفاده میکنند. این کار باعث میشود الگوریتم در برابر نویز تصویری پایدارتر شود (Pham et al., 2000).
.
12.3 نسخههای هستهای و غیرخطی
برای دادههایی که در فضای اصلی بهخوبی قابل جداسازی نیستند، نسخههای Kernel FCM معرفی شدهاند. در این رویکرد، دادهها به فضای ویژگی غنیتری نگاشت میشوند تا مرزهای خوشه بهتر آشکار شوند.
.
12.4 بهینهسازی و مقداردهی اولیه بهتر
یکی از مسیرهای توسعه، استفاده از الگوریتمهای فراابتکاری مانند Genetic Algorithm، Particle Swarm Optimization و Differential Evolution برای مقداردهی اولیه بهتر یا بهینهسازی مراکز خوشه است. هدف این است که احتمال گرفتارشدن در بهینه محلی کاهش یابد.
.
12.5 ترکیب با کاهش بُعد و embedding
در دادههای پربعد، FCM میتواند با روشهایی مانند PCA، Autoencoder یا embeddingهای یادگرفتهشده ترکیب شود تا ابتدا نمایش داده مناسبتر شود و سپس خوشهبندی فازی روی آن اجرا گردد. این رویکرد در متنکاوی، بینایی ماشین و زیستاطلاعات اهمیت زیادی پیدا کرده است.
.
12.6 افزایش مقیاس پذیری برای داده های حجیم
نسخه کلاسیک FCM به دلیل نیاز به نگهداری ماتریس عضویت در حافظه، برای دادههای بزرگ با محدودیت روبروست. نوآوریهای اخیر (مانند Literal Fuzzy C-Means) بر استفاده از استراتژیهای «تقسیم و غلبه» (Divide and Conquer) و محاسبات توزیعشده در چارچوبهای Apache Spark و MapReduce تمرکز کردهاند. این روشها با خوشهبندی زیرمجموعههایی از داده و سپس ادغام نتایج، مرتبه زمانی را به شدت کاهش میدهند (Havyarimana et al., 2021).
.
12.7 پیوند با تفسیرپذیری و تصمیمسازی
از آنجا که FCM فقط یک برچسب نهایی تولید نمیکند، بلکه درجات عضویت را نیز در اختیار میگذارد، میتواند در سامانههای تصمیمیار، تحلیل ریسک و مدلسازی عدم قطعیت نقش مهمی داشته باشد. این ویژگی در آینده، بهویژه در حوزههای حساس مانند پزشکی و مالی، اهمیت بیشتری خواهد یافت.
.
۱2.8 ادغام با یادگیری عمیق و خوشهبندی عمیق فازی (Deep Fuzzy Clustering)
یکی از برجستهترین روندها از سال ۲۰۱۵، ترکیب FCM با شبکههای عصبی عمیق، بهویژه Autoencoders است. در این رویکرد، شبکه عصبی وظیفه استخراج ویژگیهای غیرخطی (Feature Extraction) را بر عهده دارد و لایه فازی در فضای نهفته (Latent Space) عمل خوشهبندی را انجام میدهد. این ترکیب باعث میشود FCM در مواجهه با دادههای بسیار پیچیده مانند تصاویر با رزولوشن بالا یا متنهای حجیم، کارایی بسیار بالاتری داشته باشد (Alizadeh et al., 2021).
.
۱2.9 خوشهبندی فازی مبتنی بر هسته (Kernel-based FCM) و توابع انتقال
محققان با معرفی توابع هسته (Kernel Functions) جدید، FCM را قادر ساختهاند تا دادههایی که در فضای اصلی جداسازیپذیر نیستند را در فضاهای با ابعاد بالاتر خوشهبندی کند. نوآوریهای اخیر بر استفاده از هستههای تطبیقی (Adaptive Kernels) تمرکز دارند که پارامترهای هسته را همزمان با فرآیند خوشهبندی بهینه میکنند تا دقت بازنمایی مرزهای فازی افزایش یابد.
.
۱2.10 خوشهبندی فازی بازهای و نوع ۲ (Type-2 Fuzzy Clustering)
برای مدیریت عدم قطعیتهای شدیدتر که خودِ «درجه عضویت» را هم شامل میشود، استفاده از مجموعههای فازی نوع ۲ در الگوریتم FCM گسترش یافته است. این روشها بهجای یک عدد تکمقدار برای عضویت، یک بازه (Interval) در نظر میگیرند که باعث مقاومت بسیار بالای الگوریتم در برابر نویزهای محیطی و دادههای پرت (Outliers) میشود (Ghalib & Taher, 2020).
.
۱2.11 نسخههای نیمهنظارتی (Semi-Supervised FCM)
در بسیاری از سناریوها، مقدار کمی داده برچسبدار در دسترس است. نوآوریهای اخیر در FCM نیمهنظارتی، از این دادههای اندک بهعنوان «راهنما» برای هدایت فرآیند خوشهبندی استفاده میکنند. این کار باعث میشود الگوریتم در تشخیص خوشههایی که همپوشانی شدیدی دارند، بسیار دقیقتر عمل کند.
.
۱2.12 بهینهسازی فراابتکاری (Metaheuristic Optimization)
از آنجا که FCM مستعد گیر افتادن در بهینههای محلی است، ترکیب آن با الگوریتمهای تکاملی جدید (مانند Whale Optimization یا Grey Wolf Optimizer) پس از ۲۰۱۵ شتاب گرفته است. این الگوریتمهای ترکیبی، ابتدا فضای جستوجو را برای یافتن مراکز اولیه مناسب کاوش میکنند و سپس FCM برای رسیدن به دقت نهایی (Fine-tuning) وارد عمل میشود.
.
۱2.13 خوشهبندی فازی با حفظ ساختار مکانی (Spatial FCM)
در حوزه پردازش تصاویر پزشکی (MRI و CT)، نسخههای جدید FCM از اطلاعات همسایگی برای حذف نویز استفاده میکنند. نوآوریهای اخیر بر «تطبیقپذیری محلی» تمرکز دارند؛ یعنی میزان تأثیر همسایهها بر اساس بافت تصویر (Texture) بهطور خودکار تنظیم میشود تا جزئیات لبهها (Edges) در حین خوشهبندی از بین نرود.
.
۱2.14 چشمانداز آینده
آینده FCM به سمت خوشهبندی خودکار (Automated Clustering) حرکت میکند، جایی که الگوریتم خود قادر به تعیین تعداد بهینه خوشهها (ccc) و پارامتر فازیساز (mmm) بر اساس شاخصهای اعتبارسنجی داخلی باشد. همچنین، استفاده از FCM در یادگیری فدرال (Federated Learning) برای حفظ حریم خصوصی دادهها، یکی از افقهای نوین این الگوریتم است.
.
13. جمعبندی
الگوریتم Fuzzy C-Means (FCM) یکی از مهمترین روشهای خوشهبندی فازی است که برای دادههای دارای مرزهای مبهم، همپوشان و غیرقطعی طراحی شده است. تفاوت اصلی آن با روشهایی مانند K-Means در این است که هر داده را فقط به یک خوشه محدود نمیکند، بلکه درجاتی از تعلق به چند خوشه را بهطور همزمان در نظر میگیرد. همین ویژگی باعث میشود FCM در بسیاری از مسائل واقعی، توصیف دقیقتر و طبیعیتری از ساختار دادهها ارائه دهد.
در این مقاله، دیدیم که FCM بر پایه کمینهسازی یک تابع هدف فازی عمل میکند و با بهروزرسانی تکراری مراکز خوشه و درجات عضویت به پاسخ میرسد. همچنین مشخص شد که این الگوریتم در کنار مزایایی مانند انعطافپذیری و مدلسازی ابهام، محدودیتهایی مانند حساسیت به نویز، نیاز به تعیین تعداد خوشه و امکان همگرایی به بهینه محلی نیز دارد.
اگر مسئلهای در اختیار دارید که در آن مرز خوشهها روشن و قطعی نیست، FCM یکی از گزینههای جدی و ارزشمند برای تحلیل داده خواهد بود. برای مطالعه عمیقتر، پیشنهاد میکنم نسخههای مقاوم در برابر نویز، Kernel FCM و کاربردهای آن در بخشبندی تصویر و دادههای پربعد را نیز بررسی کنید.
.
14. منابع
Bezdek, J. C. (1981). Pattern recognition with fuzzy objective function algorithms. Springer.
Bezdek, J. C., Ehrlich, R., & Full, W. (1984). FCM: The fuzzy c-means clustering algorithm. Computers & Geosciences, 10(2–3), 191–203.
Dunn, J. C. (1973). A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. Journal of Cybernetics, 3(3), 32–57.
Han, J., Kamber, M., & Pei, J. (2011). Data mining: Concepts and techniques (3rd ed.). Morgan Kaufmann.
Jain, A. K. (2010). Data clustering: 50 years beyond k-means. Pattern Recognition Letters, 31(8), 651–666.
Krishnapuram, R., & Keller, J. M. (1993). A possibilistic approach to clustering. IEEE Transactions on Fuzzy Systems, 1(2), 98–110.
Pal, N. R., Bezdek, J. C., & Hathaway, R. J. (1996). Sequential competitive learning and the fuzzy c-means clustering algorithms. Neural Networks, 9(5), 787–796.
Pham, D. L., Xu, C., & Prince, J. L. (2000). Current methods in medical image segmentation. Annual Review of Biomedical Engineering, 2, 315–337.
Ross, T. J. (2010). Fuzzy logic with engineering applications (3rd ed.). Wiley.
Xu, R., & Wunsch, D. C. (2009). Clustering. Wiley-IEEE Press.
Zadeh, L. A. (1965). Fuzzy sets. Information and Control, 8(3), 338–353.
Alizadeh, S. M., et al. (2021). Deep Fuzzy Clustering: A Survey. IEEE Transactions on Fuzzy Systems.
.
Bezdek, J. C. (1981). Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum Press. (منبع کلاسیک الزامی)
Ghalib, S. S., & Taher, B. H. (2020). A Review of Type-2 Fuzzy C-Means Clustering Algorithms. Journal of Computer Science.
Havens, T. C., Bezdek, J. C., Leckie, C., Hall, L. O., & Pal, N. R. (2012). Fuzzy c-Means Algorithms for Very Large Data. IEEE Transactions on Fuzzy Systems.
Havyarimana, V., et al. (2021). A Survey on Fuzzy C-Means Clustering for Big Data. Journal of Big Data.
Lei, T., et al. (2018). A novel fuzzy clustering algorithm with adaptive local weight for medical image segmentation. IEEE Transactions on Medical Imaging.
Ross, T. J. (2017). Fuzzy Logic with Engineering Applications (4th ed.). Wiley.
Schubert, E., & Rousseeuw, P. J. (2019). Faster k-Medoids Clustering: Improving the PAM, CLARA, and CLARANS Algorithms. Information Systems. (برای مقایسه ساختاری)
Wu, J. (2020). Advances in K-means Clustering: A Data Mining Thinking. Springer. (بخش مقایسه با روشهای نرم)
Zhang, H., et al. (2022). Deep Fuzzy Clustering Network for Unsupervised Image Representation. Information Sciences.



