

1.چکیده
الگوریتم FANNY که مخفف Fuzzy Analysis Clustering است، یکی از روشهای مهم در خوشهبندی فازی (Fuzzy Clustering) بهشمار میآید. برخلاف روشهای سخت مانند K-Means یا K-Medoids که هر مشاهده را تنها به یک خوشه اختصاص میدهند، FANNY این امکان را فراهم میکند که هر داده بهصورت همزمان و با درجات عضویت متفاوت به چند خوشه تعلق داشته باشد. این ویژگی در بسیاری از مسائل واقعی اهمیت دارد؛ زیرا در دادههای پیچیده، مرز بین خوشهها معمولاً شفاف و قطعی نیست.
در این مقاله، الگوریتم FANNY را از منظر مفهومی، ریاضی و اجرایی بررسی میکنیم. ابتدا تعاریف پایه خوشهبندی فازی و تفاوت آن با خوشهبندی سخت توضیح داده میشود. سپس تابع هدف، قیود عضویت، منطق بهینهسازی و مراحل اجرای الگوریتم بهصورت دقیق بیان خواهد شد. برای تثبیت یادگیری، چند مثال عددی آموزشی نیز ارائه میشود. در ادامه، کاربردهای واقعی، مزایا، محدودیتها و مقایسه FANNY با روشهای مشابه مانند Fuzzy C-Means و K-Medoids مطرح میشود. هدف مقاله این است که خواننده درکی علمی، عملی و قابل اتکا از این الگوریتم برای استفاده در آموزش، پژوهش و تحلیل داده به دست آورد.
2.مقدمه
در بسیاری از مسائل دادهکاوی و یادگیری بدون ناظر (Unsupervised Learning)، هدف اصلی کشف ساختارهای پنهان در دادههاست. یکی از رایجترین ابزارها برای این منظور، خوشهبندی (Clustering) است. با این حال، در بسیاری از مجموعهدادههای واقعی، دادهها بهطور کامل و قطعی در یک گروه قرار نمیگیرند. برای مثال، یک مشتری ممکن است همزمان رفتاری نزدیک به چند دسته مختلف از مشتریان داشته باشد، یا یک سند متنی بتواند به چند موضوع مرتبط باشد.
در چنین شرایطی، روشهای خوشهبندی سخت پاسخ کاملی ارائه نمیکنند. الگوریتم FANNY برای حل همین مسئله طراحی شده است. این الگوریتم بهجای تخصیص قطعی هر داده به یک خوشه، برای هر مشاهده مجموعهای از درجات عضویت در خوشههای مختلف محاسبه میکند. بنابراین، FANNY برای مدلسازی ساختارهای مبهم، مرزهای نرم و دادههایی که تفکیکپذیری مطلق ندارند، روشی مناسب محسوب میشود.
هدف این مقاله، ارائه یک معرفی جامع و آموزشی از الگوریتم FANNY است. ابتدا مفاهیم پایه و مسئلهای که این روش حل میکند بررسی میشود. سپس مبانی نظری و ریاضی آن توضیح داده خواهد شد. در ادامه، مراحل اجرای الگوریتم، مثالهای عددی، کاربردهای واقعی، مزایا، محدودیتها و مقایسه با روشهای مشابه بیان میشود تا خواننده بتواند تصویر کاملی از جایگاه و کارکرد این روش به دست آورد.
.
3.تعاریف و مفاهیم پایه
خوشهبندی چیست؟
فرایندی است که در آن دادهها بر اساس شباهت یا فاصله، به گروههایی تقسیم میشوند؛ بهگونهای که اعضای یک خوشه به هم شبیهتر از اعضای خوشههای دیگر باشند.
خوشهبندی سخت در برابر خوشهبندی فازی
- در خوشهبندی سخت (Hard Clustering)، هر داده فقط به یک خوشه تعلق دارد. برای نمونه، در K-Means هر مشاهده دقیقاً در یکی از خوشهها قرار میگیرد.
- اما در خوشهبندی فازی (Fuzzy Clustering)، هر داده میتواند با شدتهای متفاوت به چند خوشه تعلق داشته باشد. این تعلق با عددی بین 0 و 1 نمایش داده میشود که به آن درجه عضویت (Membership Degree) میگویند.

درجه عضویت
اگر uiv درجه عضویت مشاهده i در خوشه v باشد، آنگاه:
- 0 ≤ uiv ≤ 1
- مجموع درجات عضویت هر مشاهده در همه خوشهها برابر 1 است.
یعنی:
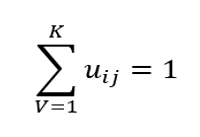
توضیح نمادها
- uiv: درجه عضویت داده i در خوشهv
- k: تعداد خوشهها
این قید نشان میدهد که عضویت هر داده بین خوشهها توزیع میشود، نه اینکه بدون قید و شرط به چند خوشه نسبت داده شود.
الگوریتم FANNY چیست؟
FANNY یک روش خوشهبندی فازی مبتنی بر ماتریس ناهمانندی (Dissimilarity Matrix) است. برخلاف Fuzzy C-Means که معمولاً بر پایه فاصله از مراکز خوشهای عمل میکند، FANNY مستقیماً با ناهمانندی بین زوج دادهها کار میکند. این ویژگی باعث میشود در مسائلی که دادهها بهصورت مستقیم در فضای برداری استاندارد نمایش نمییابند، یا تنها یک ماتریس فاصله/ناهمانندی در اختیار داریم، FANNY گزینهای مناسب باشد (Kaufman & Rousseeuw, 1990).
ماتریس ناهمانندی
ماتریس ناهمانندی ماتریسی است که در آن هر درایه (i,j) d میزان تفاوت یا فاصله بین مشاهده i و مشاهده j را نشان میدهد. هرچه این مقدار کمتر باشد، دو مشاهده به هم شبیهتر هستند.

تفاوت FANNY با Fuzzy C-Means
- FANNY با ناهمانندی بین دادهها کار میکند.
- Fuzzy C-Means معمولاً با بردار ویژگی و مرکز خوشه کار میکند.
- FANNY در دادههای رابطهای یا فاصلهمحور کاربرد طبیعیتری دارد.

.
4.مسئلهای که این روش حل میکند؛ اهمیت و ضرورت
الگوریتم FANNY برای شرایطی طراحی شده است که در آن، دادهها بهصورت طبیعی دارای مرزهای مبهم بین گروهها هستند. در بسیاری از مسائل واقعی، نمیتوان با اطمینان گفت هر مشاهده فقط به یک خوشه تعلق دارد. برای مثال، یک مقاله علمی ممکن است همزمان به «یادگیری ماشین» و «پردازش زبان طبیعی» مرتبط باشد، یا یک بیمار بتواند نشانههایی از چند الگوی بالینی را بهطور همزمان نشان دهد.
در چنین موقعیتهایی، خوشهبندی سخت باعث از دست رفتن بخشی از واقعیت داده میشود؛ زیرا تنها یک برچسب نهایی به هر مشاهده اختصاص میدهد. FANNY این محدودیت را رفع میکند و امکان مدلسازی عضویت جزئی را فراهم میسازد.
اهمیت این روش بهویژه زمانی بیشتر میشود که دادهها نه در قالب مختصات استاندارد، بلکه بهصورت ماتریس ناهمانندی در دسترس باشند. در چنین حالتی، بسیاری از الگوریتمهای متداول مرکز-محور بهسادگی قابل استفاده نیستند، اما FANNY میتواند مستقیماً بر مبنای روابط جفتی بین نمونهها عمل کند. بنابراین، ضرورت وجودی FANNY در دو نکته خلاصه میشود:
- مدلسازی ساختارهای مبهم و چندتعلقی در دادهها
- امکان خوشهبندی در مسائل مبتنی بر فاصله یا ناهمانندی
.
5.مبانی نظری و ریاضی
الگوریتم FANNY تلاش میکند درجات عضویت را طوری تعیین کند که نمونههایی که به یک خوشه تعلق بیشتری دارند، نسبت به اعضای همان خوشه ناهمانندی کمتری نشان دهند.
یکی از صورتبندیهای رایج تابع هدف در FANNY به شکل زیر بیان میشود:
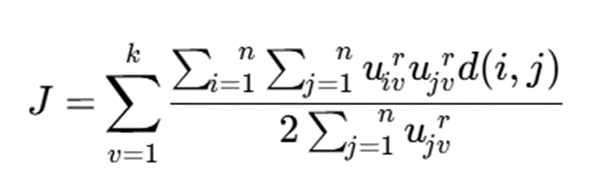
توضیح نمادها
- J: تابع هدف کل الگوریتم
- n: تعداد کل مشاهدات
- k: تعداد خوشهها
- uiv: درجه عضویت مشاهده i در خوشه v
- r: پارامتر فازیبودن یا fuzzifier که معمولاً بزرگتر از 1 است
- d(i,j): ناهمانندی بین مشاهدههای i و j
تفسیر تابع هدف
این تابع هدف بهدنبال کمینهسازی ناهمانندی درونخوشهای بهشکل فازی است. اگر دو مشاهده i و j هر دو عضویت بالایی در خوشه v داشته باشند، آنگاه عبارت
uriv ,urjv بزرگتر خواهد بود. در نتیجه، اگر فاصله d(i,j) نیز بزرگ باشد، هزینه افزایش مییابد. بنابراین الگوریتم ترجیح میدهد نمونههای با عضویت بالای مشترک در یک خوشه، به هم شبیهتر باشند.
قیود عضویت
برای هر مشاهده، باید مجموع درجات عضویت در همه خوشهها برابر 1 باشد:
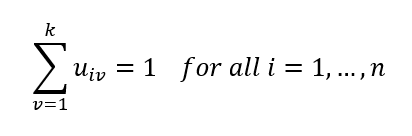
و همچنین:
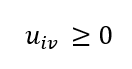
توضیح
این قیود تضمین میکنند که:
- هر مشاهده بین خوشهها توزیع میشود.
- عضویت منفی یا نامعتبر وجود ندارد.
نقش پارامتر r
پارامتر r میزان فازیبودن خوشهبندی را کنترل میکند:
- اگر r به 1 نزدیک باشد، مدل به سمت تخصیص سختتر میرود.
- اگر r بزرگتر شود، عضویتها نرمتر و پراکندهتر میشوند.
در عمل، انتخاب r بر تفسیرپذیری و تفکیک خوشهها اثر مهمی دارد.
فرضهای پایه
- یک معیار معتبر برای سنجش ناهمانندی بین زوج نمونهها وجود دارد.
- تعداد خوشهها k از پیش مشخص است یا با روشهای ارزیابی تعیین میشود.
- دادهها ساختار خوشهای قابلتشخیص دارند، هرچند این ساختار ممکن است کاملاً شفاف نباشد.
.
6.مراحل گام به گام اجرای الگوریتم
گام 1: آمادهسازی داده یا ماتریس ناهمانندی
ابتدا مجموعه داده یا مستقیماً ماتریس ناهمانندی d(i,j) آماده میشود. اگر دادهها بهصورت ویژگیمحور باشند، میتوان با یک معیار مناسب مانند فاصله اقلیدسی یا منهتن، ماتریس ناهمانندی را ساخت.
گام 2: تعیین تعداد خوشهها
تعداد خوشهها k مشخص میشود. این مقدار ممکن است بر اساس دانش مسئله، تحلیل اکتشافی یا شاخصهای اعتبارسنجی خوشهبندی انتخاب شود.
گام 3: تعیین پارامتر فازی r
پارامتر r >1 انتخاب میشود. این پارامتر سطح نرمی عضویتها را کنترل میکند.
گام 4: مقداردهی اولیه درجات عضویت
برای هر مشاهده و هر خوشه، درجه عضویت اولیه uivطوری تعیین میشود که:
- همه مقادیر نامنفی باشند.
- مجموع عضویتهای هر مشاهده برابر 1 باشد.
گام 5: ارزیابی تابع هدف
با استفاده از درجات عضویت فعلی و ماتریس ناهمانندی، مقدار تابع هدف J محاسبه میشود.
گام 6: بهروزرسانی عضویتها
الگوریتم بهصورت تکراری درجات عضویت را تغییر میدهد تا مقدار تابع هدف کاهش یابد. در این مرحله، عضویت هر مشاهده در هر خوشه با توجه به ناهمانندی آن نسبت به سایر اعضای خوشهها بازتنظیم میشود.
گام 7: بررسی معیار توقف
تکرارها تا زمانی ادامه پیدا میکند که یکی از شرایط زیر برقرار شود:
- تغییرات درجات عضویت از یک آستانه مشخص کمتر شود.
- کاهش تابع هدف ناچیز شود.
- تعداد تکرارها به حداکثر تعیینشده برسد.
گام 8: تولید خروجی نهایی
در پایان:
- ماتریس عضویت فازی تولید میشود.
- در صورت نیاز، هر مشاهده به خوشهای با بیشترین درجه عضویت نسبت داده میشود.
- همچنین میتوان میزان ابهام هر مشاهده را از روی توزیع عضویتهایش تحلیل کرد.
شبهکد
Input: Dissimilarity matrix D, number of clusters k, fuzzifier r
Initialize membership matrix U randomly
Repeat:
Compute objective function J
Update membership values U
Normalize memberships so that each row sums to 1
Until convergence criterion is met
Output: Membership matrix U and fuzzy clustering structure
7.مثالهای عددی
مثال 1: دادهای با تعلق تقریباً قطعی
صورت مسئله
سه مشاهده داریم که باید در دو خوشه فازی دستهبندی شوند. ماتریس ناهمانندی به شکل زیر است:
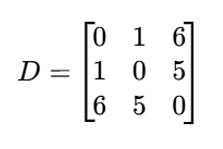
فرض کنید انتظار داریم مشاهدههای 1 و 2 به هم نزدیک باشند و مشاهده 3 از آنها دور باشد.
داده ورودی
- تعداد خوشهها: k=2
- پارامتر فازی: r=2
حل گامبهگام
با توجه به ماتریس، نمونههای 1 و 2 فاصله کمی دارند و هر دو از نمونه 3 دور هستند. بنابراین یک تخصیص فازی معقول میتواند چنین باشد:
- مشاهده 1: (0.9 , 0.1)
- مشاهده 2: (0.85 , 0.15)
- مشاهده 3: (0.1 , 0.9)
پاسخ نهایی
- خوشه 1: عمدتاً شامل مشاهدههای 1 و 2
- خوشه 2: عمدتاً شامل مشاهده 3
تفسیر نتیجه
اگرچه تخصیص غالب مشخص است، اما مدل هنوز امکان عضویت جزئی را حفظ میکند. این موضوع در دادههای واقعی مفید است، زیرا معمولاً قطعیت کامل وجود ندارد.
.
مثال 2: مشاهده مرزی بین دو خوشه
صورت مسئله
چهار مشاهده داریم. ماتریس ناهمانندی نشان میدهد که مشاهده چهارم تا حدی به هر دو گروه نزدیک است.
داده ورودی
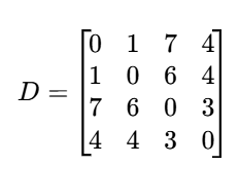
حل گامبهگام
- مشاهدههای 1 و 2 بسیار شبیهاند.
- مشاهده 3 از آنها دور است.
- مشاهده 4 نسبت به 3 نزدیکتر است، اما از 1 و 2 نیز خیلی دور نیست.
پس یک الگوی عضویت محتمل میتواند چنین باشد:
- مشاهده 1: (0.9 , 0.1)
- مشاهده 2: (0.88 , 0.12)
- مشاهده 3: (0.15 , 0.85)
- مشاهده 4: (0.4 , 0.6)
پاسخ نهایی
مشاهده 4 به خوشه دوم نزدیکتر است، اما عضویت معناداری در خوشه اول نیز دارد.
تفسیر نتیجه
این مثال نشان میدهد FANNY برای شناسایی نقاط مرزی بسیار مناسب است؛ نقاطی که در خوشهبندی سخت مجبور به تخصیص قطعی میشوند.
.
مثال 3: داده با ابهام بالا
صورت مسئله
میخواهیم وضعیتی را بررسی کنیم که در آن یک مشاهده تقریباً بهطور برابر به دو خوشه تعلق دارد.
داده ورودی
فرض کنید پس از اجرای الگوریتم، عضویتها چنین به دست آمدهاند:
- مشاهده 1: (0.95 , 0.05)
- مشاهده 2: (0.5 , 0.5)
- مشاهده 3: (0.08 , 0.92)
حل گامبهگام
- مشاهده 1 تقریباً کاملاً در خوشه اول قرار دارد.
- مشاهده 3 تقریباً کاملاً در خوشه دوم قرار دارد.
- مشاهده 2 دقیقاً در مرز بین دو خوشه است.
پاسخ نهایی
مشاهده 2 یک عضو مبهم یا Ambiguous Point است.
تفسیر نتیجه
در بسیاری از کاربردها، همین مشاهدههای مبهم ارزش تحلیلی بالایی دارند. برای مثال، در بخشبندی مشتریان، این افراد ممکن است در آستانه تغییر رفتار باشند.
.
مثال 4: بررسی اثر پارامتر فازی
صورت مسئله
برای یک مشاهده خاص، میخواهیم اثر تغییر r را بر نرمی عضویتها درک کنیم.
داده ورودی
فرض کنید برای یک داده، در حالت اول:
- با. r=1.3: عضویت (0.8 , 0.2)
و در حالت دوم:
- r=2.5: عضویت (0.65 , 0.35)
حل گامبهگام
وقتی r افزایش مییابد، الگوریتم تمایل دارد تخصیصها را نرمتر کند. در نتیجه فاصله بین عضویت غالب و غیرغالب کمتر میشود.
پاسخ نهایی
افزایش r باعث افزایش ابهام و کاهش قطعیت در عضویتها میشود.
تفسیر نتیجه
انتخاب r تنها یک جزئیات فنی نیست، بلکه مستقیماً بر نحوه تفسیر خروجی خوشهبندی اثر میگذارد.
.
8.کاربردهای واقعی
- بخشبندی مشتریان در بازاریابی: زمانی که یک مشتری ویژگیهای چند گروه رفتاری را همزمان دارد.
- زیستاطلاعات (Bioinformatics): برای تحلیل الگوهای ژنی یا نمونههای زیستی با مرزهای نامشخص.
- تحلیل اسناد و متن: وقتی یک متن میتواند به چند موضوع وابسته باشد.
- پزشکی و تحلیل بالینی: برای مدلسازی بیمارانی که نشانههای ترکیبی از چند الگوی بیماری دارند.
- علوم اجتماعی: در دستهبندی افراد یا گروهها بر اساس ویژگیهای رفتاری یا نگرشی مبهم.
- پردازش تصویر: برای تفکیک نواحیای که مرز آنها در تصویر واضح نیست.
- سیستمهای توصیهگر: برای شناسایی تعلق نسبی کاربران به چند الگوی ترجیحی.
- تحلیل دادههای رابطهای: در مسائلی که دادهها بیشتر بهصورت فاصله یا شباهت بین نمونهها قابل بیان هستند.
.
9.مزایا
- مدلسازی واقعبینانهتر دادههای مبهم
- امکان عضویت همزمان یک مشاهده در چند خوشه
- مناسب برای دادههای مبتنی بر ماتریس ناهمانندی
- مفید برای شناسایی نقاط مرزی و نمونههای مبهم
- انعطافپذیری بیشتر نسبت به خوشهبندی سخت
- قابلیت استفاده در حوزههایی که ساختار برداری صریح وجود ندارد
- ارائه اطلاعات غنیتر از صرفاً یک برچسب خوشهای
.
10.محدودیتها و معایب
- نیاز به تعیین تعداد خوشهها از پیش
- حساسیت به انتخاب پارامتر فازی r
- پیچیدگی محاسباتی بالاتر نسبت به برخی روشهای سخت، بهویژه در دادههای بزرگ
- تفسیر دشوارتر خروجی برای کاربران غیرمتخصص، چون بهجای یک برچسب نهایی، ماتریس عضویت ارائه میشود
- امکان حساسیت به کیفیت ماتریس ناهمانندی؛ اگر معیار فاصله مناسب نباشد، نتایج ضعیف میشوند
- مقیاسپذیری محدودتر نسبت به بعضی روشهای سادهتر مانند K-Means
- احتمال همپوشانی زیاد خوشهها در صورت انتخاب نامناسب پارامترها
.
11.مقایسه با روشهای مشابه
مقایسه مفهومی
FANNY از نظر فلسفه به خوشهبندی فازی نزدیک است، اما از نظر ورودی و نحوه مدلسازی با روشهایی مانند K-Means و Fuzzy C-Means تفاوت دارد.
| روش | نوع خوشهبندی | مبنای محاسبه | خروجی | مناسب برای داده فاصلهمحور | تفسیرپذیری |
| K-Means | سخت | فاصله تا مرکز خوشه | برچسب قطعی | محدود | بالا |
| K-Medoids | سخت | فاصله تا مدوئید | برچسب قطعی | خوب | بالا |
| FANNY | فازی | ناهمانندی بین زوج دادهها | درجات عضویت | بسیار خوب | متوسط تا بالا |

مقایسه با روشهای جدیدتر
| الگوریتم | شکل خوشهها | معیار فاصله / ناهمانندی | حساسیت به نویز و دادهپرت | ویژگی کلیدی و نوآوری | کاربرد اصلی |
| FCM (Fuzzy C-Means) | کروی (Spherical) | فاصله اقلیدسی (Euclidean) | بسیار حساس | سادهترین و پرکاربردترین روش فازی | عمومی، پردازش تصویر اولیه |
| FCMdc (FCM with Constraints) | وابسته به قیود | اقلیدسی وزندار / مقید | متوسط | استفاده از دانش پیشین یا قیود توزیعشده | یادگیری نیمهنظارتی، سیستمهای توزیعشده |
| PCM (Possibilistic C-Means) | کروی | فاصله توانمندی (Possibilistic) | بسیار مقاوم (Robust) | حل مشکل عضویت نسبی؛ هر خوشه مستقل است | حذف نویز، شناسایی دادههای خاص |
| GK (Gustafson-Kessel) | بیضوی (Ellipsoidal) | فاصله ماهالانوبیس تطبیقی | حساس | استخراج ماتریس کوواریانس برای هر خوشه | دادههای با همبستگی خطی، سری زمانی |
| Kernel FCM (KFCM) | اشکال پیچیده و غیرخطی | نگاشت به فضای هیلبرت (RKHS) | متوسط (بسته به Kernel) | استفاده از تابع هسته برای تفکیکناپذیری خطی | بیوانفورماتیک، تشخیص الگوهای پیچیده |
| FANNY (Fuzzy Analysis) | منعطف (رابطهای) | ماتریس ناهمانندی (Dissimilarity) | متوسط | عدم نیاز به بردار ویژگی؛ کار با روابط جفتی | تحلیل شبکهای، دادههای کیفی و رابطهای |
تفاوت K-Means و FANNY
- K-Means فقط در فضای ویژگیمحور استاندارد و با تخصیص سخت عمل میکند.
- FANNY برای شرایطی مناسبتر است که مرز بین خوشهها نرم باشد یا دادهها بهصورت ماتریس ناهمانندی بیان شوند.
مقایسه FANNY و Fuzzy C-Means
- هر دو فازی هستند، اما Fuzzy C-Means معمولاً به مرکز خوشه وابسته است.
- FANNY رابطه بین زوج دادهها را مبنا قرار میدهد.
- در دادههایی که ساختار برداری واضح ندارند، FANNY انتخاب طبیعیتری است.
تفاوت K-Medoids وFANNY
- K-Medoids نیز با فاصله/ناهمانندی سازگار است، اما خوشهبندی سخت انجام میدهد.
- FANNY وقتی برتری دارد که تحلیل عضویت جزئی و نقاط مرزی مهم باشد.
جمع بندی
- FCM: معیار استاندارد است اما در برابر نویز ضعیف عمل میکند زیرا مجموع عضویتها باید یک شود (Outlierها عضویت بالایی میگیرند).
- PCM: برخلاف FCM، مجموع عضویتها را به یک محدود نمیکند؛ بنابراین برای دادههای پرت عضویت بسیار کمی در نظر میگیرد.
- GK: به دلیل استفاده از ماتریس کوواریانس محلی، میتواند خوشههایی با حجم و جهتگیری متفاوت را شناسایی کند، اما هزینه محاسباتی بالاتری دارد.
- KFCM: با انتقال داده به ابعاد بالاتر، خوشههایی که در فضای اصلی در هم تنیده هستند را جدا میکند.
- FANNY: تنها روشی است که در آن لزومی ندارد دادهها بهصورت مختصات (Coordinates) باشند؛ داشتن یک ماتریس از شباهت یا تفاوت میان نمونهها کفایت میکند.
.
12. نوآوریها و چشمانداز آینده
الگوریتم FANNY یا Fuzzy Analysis Clustering از نظر تاریخی یک روش کلاسیک در خوشهبندی فازی است، اما ایده مرکزی آن، یعنی «اختصاص درجه عضویت بهجای برچسب قطعی»، همچنان با بسیاری از جریانهای پژوهشی جدید در یادگیری ماشین، علم داده و هوش مصنوعی همراستا است. از سال 2015 به بعد، بخش مهمی از پژوهشها در خوشهبندی به سمت دادههای بزرگ، دادههای گرافی، نمایشهای عمیق، خوشهبندی مقاوم، یادگیری نیمهنظارتی و تحلیل عدمقطعیت حرکت کردهاند. در این فضا، FANNY میتواند نه صرفاً بهعنوان یک الگوریتم مستقل، بلکه بهعنوان یک چارچوب فکری برای مدلسازی عضویت نرم و ابهام در دادهها بازخوانی شود.
.
12.1. ترکیب FANNY با یادگیری نمایش و یادگیری عمیق
یکی از مهمترین تحولات پس از 2015، رشد روشهای خوشهبندی عمیق (Deep Clustering) است. در این رویکردها، بهجای اجرای مستقیم خوشهبندی روی داده خام، ابتدا یک شبکه عصبی نمایش فشردهتر و معنادارتری از داده تولید میکند و سپس خوشهبندی روی این نمایش انجام میشود. برای نمونه، روش Deep Embedded Clustering نشان داد که یادگیری نمایش و خوشهبندی میتوانند بهصورت مشترک بهینه شوند (Xie, Girshick, & Farhadi, 2016).
در این مسیر، FANNY میتواند بهصورت زیر توسعه یابد:
- استفاده از شبکههای عصبی برای تبدیل دادههای خام، مانند تصویر، متن یا دادههای حسگری، به بردارهای نهفته.
- محاسبه ماتریس ناهمانندی بر اساس فاصله میان نمایشهای نهفته.
- اجرای FANNY روی این ماتریس ناهمانندی برای تولید عضویتهای فازی.
- تحلیل نمونههایی که در فضای نهفته نیز عضویت مبهم دارند.
ارزش این ترکیب در آن است که FANNY ذاتاً با ماتریس ناهمانندی کار میکند؛ بنابراین اگر نمایشهای عمیق بتوانند فاصلههای معنادارتری بین نمونهها ایجاد کنند، خروجی FANNY نیز تفسیرپذیرتر و دقیقتر خواهد شد. این رویکرد بهویژه برای دادههای پیچیدهای مانند تصاویر پزشکی، اسناد متنی و دادههای چندرسانهای اهمیت دارد.
.
12.2. FANNY در کنار مدلهای زبانی و بردارهای معنایی
پس از ظهور مدلهای زبانی بزرگ و روشهای تولید بردارهای تعبیهشده (Embeddings)، خوشهبندی متون وارد مرحله تازهای شده است. امروزه متنها، جملهها، اسناد و حتی کاربران را میتوان بهصورت بردارهای معنایی نمایش داد. در چنین شرایطی، میتوان از FANNY برای خوشهبندی فازی اسناد استفاده کرد؛ زیرا یک متن معمولاً فقط به یک موضوع تعلق ندارد.
برای مثال، یک مقاله درباره «یادگیری عمیق در پزشکی» میتواند همزمان به خوشههای زیر تعلق داشته باشد:
- یادگیری عمیق
- تحلیل تصویر پزشکی
- سلامت دیجیتال
- هوش مصنوعی کاربردی
روشهای سخت مانند K-Means معمولاً چنین سندی را فقط در یک خوشه قرار میدهند، اما FANNY میتواند توزیعی از عضویتها تولید کند. این موضوع با روندهای جدید در تحلیل معنایی متون، بازیابی اطلاعات، سامانههای توصیهگر و پردازش زبان طبیعی سازگار است. بنابراین، یکی از چشماندازهای مهم FANNY استفاده از آن روی فاصلههای محاسبهشده از embeddingهای مدرن مانند BERT، Sentence-BERT یا مدلهای مشابه است.
.
12.3. توسعه FANNY برای دادههای گرافی و شبکهای
بسیاری از دادههای جدید ساختار گرافی دارند: شبکههای اجتماعی، شبکههای زیستی، شبکههای حملونقل، گراف دانش و شبکههای استنادی. در این نوع دادهها، مسئله اصلی همیشه داشتن بردار ویژگی استاندارد نیست؛ بلکه اغلب رابطه میان نمونهها اهمیت بیشتری دارد. از آنجا که FANNY با ناهمانندی زوجی کار میکند، از نظر مفهومی برای دادههای گرافی ظرفیت بالایی دارد.
در پژوهشهای جدید، روشهایی مانند Graph Embedding و Graph Neural Networks تلاش میکنند گرههای گراف را به بردارهایی تبدیل کنند که ساختار شبکه را حفظ کنند (Hamilton, Ying, & Leskovec, 2017). پس از استخراج این نمایشها، میتوان فاصله میان گرهها را محاسبه و FANNY را برای خوشهبندی فازی گرهها به کار گرفت.
این رویکرد برای مسائلی مانند موارد زیر مفید است:
- شناسایی کاربران با رفتارهای چندگانه در شبکههای اجتماعی
- کشف جوامع همپوشان در شبکهها
- تحلیل ژنها یا پروتئینهایی که در چند مسیر زیستی نقش دارند
- خوشهبندی مقالات علمی با حوزههای پژوهشی مشترک
در این زمینه، FANNY میتواند مکمل روشهای کشف اجتماع همپوشان (Overlapping Community Detection) باشد؛ زیرا خروجی آن ذاتاً امکان عضویت همزمان در چند گروه را فراهم میکند.
.
12.4. مقیاسپذیری و نسخههای مناسب دادههای بزرگ
یکی از محدودیتهای اصلی FANNY، هزینه محاسباتی آن است. چون این الگوریتم با ماتریس ناهمانندی سروکار دارد، در دادههای بزرگ با مسئله حافظه و زمان محاسباتی روبهرو میشود. اگر تعداد نمونهها n باشد، ماتریس ناهمانندی معمولاً مرتبهای در حدود O(n^2) دارد. این موضوع برای دادههای بزرگ یک مانع جدی است.
پژوهشهای پس از 2015 در حوزه خوشهبندی، بهشدت به سمت الگوریتمهای مقیاسپذیر، نمونهبرداری هوشمند، پردازش توزیعشده و روشهای تقریبی حرکت کردهاند. در همین راستا، آینده FANNY میتواند بر توسعه نسخههای زیر متمرکز شود:
- FANNY مبتنی بر نمونهبرداری: اجرای الگوریتم روی زیرمجموعهای نماینده از دادهها و سپس تعمیم عضویتها به سایر نمونهها.
- FANNY توزیعشده: تقسیم محاسبات ناهمانندی و بهینهسازی عضویتها روی چند گره پردازشی.
- FANNY تقریبی: استفاده از روشهای تقریب نزدیکترین همسایهها یا ماتریسهای کمرتبه برای کاهش هزینه محاسبه فاصلهها.
- FANNY جریاندادهای: بهروزرسانی تدریجی عضویتها هنگام ورود دادههای جدید، بدون اجرای کامل الگوریتم از ابتدا.
این مسیر با روند عمومی یادگیری ماشین مدرن، یعنی حرکت از الگوریتمهای دقیق اما پرهزینه به سمت الگوریتمهای تقریبی، سریع و قابلاستفاده در مقیاس واقعی، همخوان است.
.
12.5. خوشهبندی فازی مقاوم در برابر نویز و دادههای پرت
یکی از مسائل مهم در دادههای واقعی، وجود نویز، دادههای پرت و مشاهدات غیرعادی است. از سال 2015 به بعد، پژوهشهای زیادی بر طراحی روشهای خوشهبندی مقاوم تمرکز کردهاند؛ زیرا بسیاری از الگوریتمهای کلاسیک در حضور دادههای پرت دچار انحراف میشوند.
در FANNY نیز کیفیت ماتریس ناهمانندی نقش اساسی دارد. اگر فاصلهها تحت تأثیر نویز یا مقادیر پرت قرار بگیرند، درجات عضویت نهایی نیز ممکن است ناپایدار شوند. بنابراین یکی از مسیرهای توسعه آینده، طراحی نسخههای مقاومتر FANNY است؛ برای مثال:
- استفاده از معیارهای فاصله مقاوم به جای فاصله اقلیدسی ساده.
- کاهش اثر دادههای پرت در تابع هدف.
- افزودن خوشه نویز یا درجه عضویت در «ناحیه نامطمئن».
- ترکیب FANNY با روشهای تشخیص ناهنجاری.
این توسعه بهویژه در پزشکی، امنیت سایبری، تحلیل مالی و دادههای حسگری اهمیت دارد؛ زیرا در این حوزهها دادههای پرت نهتنها فراواناند، بلکه گاهی از نظر تحلیلی بسیار معنادار هستند.
.
12.5. انتخاب خودکار تعداد خوشهها و اعتبارسنجی فازی
یکی از چالشهای عملی FANNY، نیاز به تعیین تعداد خوشهها k پیش از اجرای الگوریتم است. این چالش محدود به FANNY نیست و در بسیاری از الگوریتمهای خوشهبندی وجود دارد. با این حال، در خوشهبندی فازی، انتخاب k پیچیدهتر میشود؛ زیرا علاوه بر ساختار خوشهها، میزان ابهام و همپوشانی نیز باید ارزیابی شود.
پژوهشهای جدید در خوشهبندی بر استفاده از شاخصهای اعتبارسنجی، روشهای پایداری، معیارهای اطلاعاتی و راهکارهای مبتنی بر بازنمونهگیری تأکید دارند. برای FANNY، مسیرهای آینده میتواند شامل موارد زیر باشد:
- توسعه شاخصهای اعتبارسنجی ویژه برای خروجی فازی.
- استفاده از پایداری عضویتها برای انتخاب k.
- ترکیب شاخصهایی مانند silhouette با معیارهای فازی.
- استفاده از روشهای بیزی یا اطلاعاتی برای انتخاب تعداد خوشهها.
در عمل، انتخاب تعداد خوشهها نباید فقط بر اساس کمینهسازی تابع هدف انجام شود؛ زیرا افزایش تعداد خوشهها معمولاً تابع هدف را کاهش میدهد، اما لزوماً به ساختار معنادارتر منجر نمیشود.
.
12.7. پیوند FANNY با عدمقطعیت، تفسیرپذیری و هوش مصنوعی قابل اعتماد
پس از 2015، موضوع هوش مصنوعی قابل اعتماد (Trustworthy AI) و تفسیرپذیری (Interpretability) اهمیت زیادی پیدا کرده است. در بسیاری از سامانههای تصمیمیار، تنها دانستن برچسب نهایی کافی نیست؛ بلکه باید بدانیم مدل با چه میزان اطمینان به آن تصمیم رسیده است. خوشهبندی فازی از این نظر مزیت مهمی دارد، زیرا خروجی آن خودبهخود نوعی نمایش از عدمقطعیت است.
در FANNY، اگر یک نمونه عضویتهایی مانند زیر داشته باشد:
(0.50,0.48,0.02)
این خروجی نشان میدهد نمونه میان دو خوشه اول قرار دارد و تخصیص قطعی آن میتواند گمراهکننده باشد. اما اگر عضویت به شکل زیر باشد:
(0.95,0.03,0.02)
مدل با وضوح بیشتری آن نمونه را به خوشه اول نسبت میدهد.
این ویژگی در حوزههایی مانند پزشکی، آموزش، اعتبارسنجی مالی و سیاستگذاری عمومی بسیار ارزشمند است. بنابراین یکی از چشماندازهای آینده FANNY، استفاده از آن بهعنوان ابزاری برای تحلیل ابهام ساختاری دادهها و کمک به تصمیمگیری انسانی است.
.
12.8. ترکیب FANNY با خوشهبندی نیمهنظارتی و دانش خبره
در بسیاری از مسائل واقعی، دادهها کاملاً بدون برچسب نیستند. گاهی متخصص دامنه میداند که چند نمونه باید در یک گروه قرار بگیرند یا برخی نمونهها نباید با یکدیگر همخوشه شوند. پژوهشهای جدید در خوشهبندی نیمهنظارتی تلاش میکنند چنین دانش پیشینی را وارد فرایند خوشهبندی کنند.
FANNY میتواند در آینده با قیدهای زیر توسعه یابد:
- Must-link constraint: دو نمونه باید تا حد زیادی در یک خوشه عضویت داشته باشند.
- Cannot-link constraint: دو نمونه نباید عضویت بالایی در یک خوشه مشترک داشته باشند.
- وزندهی به نمونهها بر اساس اعتماد متخصص.
- تنظیم ماتریس ناهمانندی با استفاده از دانش دامنه.
این مسیر برای کاربردهای تخصصی مانند پزشکی، زیستاطلاعات، حقوق، تحلیل آموزشی و علوم اجتماعی اهمیت زیادی دارد؛ زیرا در این حوزهها دانش انسانی نقش مهمی در تفسیر داده دارد.
.
12.9.FANNY در دادههای چندنمایی و چندمنبعی
بسیاری از دادههای امروزی فقط از یک منبع نمیآیند. برای مثال، درباره یک بیمار ممکن است همزمان دادههای آزمایشگاهی، تصویر پزشکی، متن گزارش پزشک و دادههای ژنتیکی داشته باشیم. به این نوع مسائل، دادههای چندنمایی یا چندوجهی گفته میشود.
در چنین شرایطی، میتوان برای هر نما یک ماتریس ناهمانندی ساخت و سپس FANNY را روی ترکیبی از این ماتریسها اجرا کرد. برای مثال:
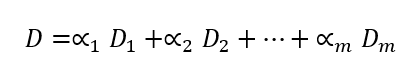
در این رابطه:

قید معمول برای وزنها بهصورت زیر است:
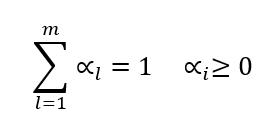
یعنی وزن هر نما نامنفی است و مجموع وزنها برابر یک میشود.
این چارچوب امکان میدهد FANNY در مسائل چندمنبعی مدرن به کار گرفته شود. برای نمونه، در تحلیل مشتریان میتوان همزمان رفتار خرید، دادههای وب، تعاملات پشتیبانی و ویژگیهای جمعیتشناختی را وارد خوشهبندی کرد.
.
12.10. حرکت به سمت FANNY آنلاین و پویا
نسخه کلاسیک FANNY برای مجموعهدادهای نسبتاً ثابت طراحی شده است. اما در بسیاری از مسائل امروزی، دادهها دائماً تغییر میکنند؛ مانند تراکنشهای مالی، رفتار کاربران در وب، دادههای حسگرها و شبکههای اجتماعی. بنابراین یکی از مسیرهای آینده، طراحی نسخههای آنلاین یا پویا از FANNY است.
در FANNY پویا، پرسشهای اصلی اینها هستند:
- وقتی نمونه جدید وارد میشود، چگونه عضویت آن را بدون اجرای کامل الگوریتم محاسبه کنیم؟
- اگر ساختار خوشهها در طول زمان تغییر کند، چگونه آن را تشخیص دهیم؟
- چگونه میتوان عضویتهای گذشته را با دادههای جدید بهروزرسانی کرد؟
- چه زمانی باید تعداد خوشهها تغییر کند؟
این مسیر برای سامانههای توصیهگر، پایش سلامت، تحلیل رفتار کاربر، تشخیص تقلب و دادههای صنعتی اهمیت فراوانی دارد.
.
12.11. استفاده از FANNY برای شناسایی نقاط مرزی و موارد نیازمند بررسی انسانی
یکی از کاربردهای آیندهدار FANNY، نه صرفاً خوشهبندی دادهها، بلکه شناسایی نمونههایی است که مدل درباره آنها اطمینان کمی دارد. در بسیاری از پروژهها، این نمونهها ارزشمندترین موارد برای بررسی انسانیاند.
برای مثال، اگر در یک مسئله پزشکی بیماری عضویت تقریباً مساوی در دو الگوی بالینی داشته باشد، این بیمار میتواند نیازمند بررسی دقیقتر پزشک باشد. در آموزش، دانشآموزی که بین چند الگوی یادگیری قرار میگیرد، ممکن است به مداخله آموزشی خاص نیاز داشته باشد. در بازاریابی، مشتریانی با عضویت مرزی ممکن است در آستانه تغییر رفتار یا جابهجایی میان بخشهای بازار باشند.
از این نظر، FANNY میتواند در کنار رویکردهای Human-in-the-loop AI قرار گیرد؛ یعنی مدل موارد مبهم را شناسایی کند و تصمیم نهایی یا تحلیل دقیقتر به متخصص انسانی سپرده شود.
.
12.12. جایگاه FANNY در آینده خوشهبندی فازی
با وجود ظهور روشهای جدید، FANNY همچنان سه ویژگی مهم دارد که آن را برای پژوهشهای آینده قابل توجه میکند:
- با ماتریس ناهمانندی کار میکند، بنابراین به فضای برداری صریح محدود نیست.
- خروجی آن فازی است، بنابراین ابهام و همپوشانی را مدل میکند.
- از نظر تفسیری نسبت به بسیاری از مدلهای پیچیده جدید قابل فهمتر است.
به همین دلیل، چشمانداز آینده FANNY احتمالاً در رقابت مستقیم با روشهای عظیم یادگیری عمیق نیست، بلکه در ترکیب هوشمندانه با آنها است. FANNY میتواند پس از استخراج نمایشهای بهتر، روی فاصلههای معنادارتر اجرا شود و خروجیای تولید کند که هم از قدرت مدلهای جدید بهره ببرد و هم تفسیرپذیری خوشهبندی فازی را حفظ کند.
.
جمعبندی
الگوریتم FANNY یکی از روشهای مهم خوشهبندی فازی است که بهجای تخصیص قطعی، برای هر مشاهده درجات عضویت در چند خوشه را محاسبه میکند. این ویژگی آن را برای مسائلی مناسب میسازد که در آنها مرز بین گروهها مبهم است یا دادهها بهصورت ماتریس ناهمانندی در دسترس هستند.
در این مقاله دیدیم که FANNY چه مسئلهای را حل میکند، از چه مبانی ریاضی بهره میبرد، چگونه اجرا میشود و چه تفاوتی با روشهایی مانند K-Means، K-Medoids و Fuzzy C-Means دارد. همچنین روشن شد که ارزش اصلی این روش در مدلسازی ابهام، انعطافپذیری تحلیلی و ارائه تصویری غنیتر از ساختار دادهها نهفته است.
اگر هدف شما تحلیل دادههایی با مرزهای نرم، عضویتهای همپوشان و ساختار رابطهای است، FANNY میتواند گزینهای علمی و قابل اتکا باشد. برای مطالعه بیشتر، پیشنهاد میکنم این الگوریتم را در کنار سایر روشهای خوشهبندی فازی و شاخصهای اعتبارسنجی خوشهبندی بررسی کنید.
.
منابع
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: An introduction to cluster analysis. John Wiley & Sons.
Bezdek, J. C. (1981). Pattern recognition with fuzzy objective function algorithms. Springer.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning (2nd ed.). Springer.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An introduction to statistical learning (2nd ed.). Springer.
Tan, P.-N., Steinbach, M., & Kumar, V. (2019). Introduction to data mining (2nd ed.). Pearson.
Han, J., Kamber, M., & Pei, J. (2012). Data mining: Concepts and techniques (3rd ed.). Morgan Kaufmann.
Xu, R., & Wunsch, D. (2009). Clustering. Wiley-IEEE Press.
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
Bezdek, J. C., Keller, J., Krishnapuram, R., & Pal, N. R. (2005). Fuzzy models and algorithms for pattern recognition and image processing. Springer.
Campello, R. J. G. B., Moulavi, D., Zimek, A., & Sander, J. (2015). Hierarchical density estimates for data clustering, visualization, and outlier detection. ACM Transactions on Knowledge Discovery from Data, 10(1), 1–51.
Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems.
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651–666.
Kaufman, L., & Rousseeuw, P. J. (1990). Finding groups in data: An introduction to cluster analysis. John Wiley & Sons.
.
Min, E., Guo, X., Liu, Q., Zhang, G., Cui, J., & Long, J. (2018). A survey of clustering with deep learning: From the perspective of network architecture. IEEE Access, 6, 39501–39514.
Saxena, A., Prasad, M., Gupta, A., Bharill, N., Patel, O. P., Tiwari, A., Er, M. J., Ding, W., & Lin, C.-T. (2017). A review of clustering techniques and developments. Neurocomputing, 267, 664–681.
Xu, D., & Tian, Y. (2015). A comprehensive survey of clustering algorithms. Annals of Data Science, 2, 165–193.
Xie, J., Girshick, R., & Farhadi, A. (2016). Unsupervised deep embedding for clustering analysis. In Proceedings of the 33rd International Conference on Machine Learning, 478–487.
Yang, M.-S., & Nataliani, Y. (2018). A feature-reduction fuzzy clustering algorithm based on feature-weighted entropy. IEEE Transactions on Fuzzy Systems, 26(2), 817–835.



