

۱. چکیده
اگرچه درک پایههای تئوری و روابط فرکانسی افراز حول مُدها زیربنای تحلیلهای علمی است، اما مهار پتانسیل واقعی این الگوریتم تخصصی در گرو پیادهسازی اصولی آن در خطوط لوله داده (Data Pipelines) جهان واقعی است. این مقاله به عنوان یک مرجع کاملاً کاربردی و تجربی، نحوه به کارگیری الگوریتم K-Modes را در اکوسیستم هوش مصنوعی پایتون کالبدشکافی میکند.
در این مستند، ابتدا با ابزارها و کتابخانههای مرجع مدیریت دادههای کیفی (Categorical) آشنا میشویم و کدهای واقعی آنها را ارزیابی میکنیم. سپس یک خط لوله کامل مهندسی داده را از صفر تا صد پیادهسازی کرده و با ورود به مطالعات موردی تجاری و واقعی در حوزههای بازاریابی، بیمه و بهداشت، ارزش عملیاتی این الگوریتم را در تفکیک ساختارهای غیرعددی بدون سوگیری متریکهای هندسی به تصویر میکشیم. خروجی این واکاوی، یک نقشه راه ملموس و استاندارد به توسعهدهندگان ارائه میدهد تا بتوانند کدهای کلاسترینگ صلب مبتنی بر فرکانس صفات را در پروژههای حساس سازمانها بومیسازی کنند.
.
۲. مقدمه
توسعه سیستمهای دادهکاوی زمانی به کمال میرسد که فرمولهای انتزاعی روی کاغذ به مراجع کاربردی و ابزارهای صنعتی در خط فرمان تبدیل شوند. الگوریتم K-Modes به عنوان استانداردترین روش تفکیکی مبتنی بر دادههای اسمنامی، زمانی ارزش عملیاتی خود را نشان میدهد که مجموعهدادههای کیفی و غیرعددی یک سازمان را اسکن کرده . به جای میانگینهای فرضی یا ساختارهای سنگین اسپارس (One-Hot Encoding)، نمایندگانی واقعی بر پایه مُد آماری (Mode) برای تصمیمگیریهای استراتژیک مدیران ارشد معرفی کند. چالش اصلی مهندسان داده در این فاز، چگونگی آمادهسازی متغیرها، پایش توابع عدمتشابه تطابق ساده و تنظیم بهینه هایپرپارامترها است تا مدل بدون افت دقت، بالاترین چابکی را روی سرورها حفظ کند.
هدف این مقاله، انتقال کامل مخاطب از تئوری به دنیای کدهای واقعی و توسعهیافته پایتون است. نقشه راه ما در این بخش به این صورت طراحی شده است: ابتدا فریمورکهای توسعه الگوریتم K-Modes را به همراه کدهای استاندارد آنها معرفی میکنیم. در گام بعد، پایپلاین گامبهگام پایتون را بر پایه اصول هویت بصری پیادهسازی کرده . در نهایت با کالبدشکافی چند پروژه واقعی، نحوه غربالگری ساختارهای پنهان کیفی را پایش خواهیم کرد.

پل ارتباطی با مقاله اصلی
پیش از ورود به بخش کدنویسی و بررسی ابزارها، اگر تمایل دارید با مبانی نظری تفکیک کیفی فضا، نحوه کارکرد معیار عدمتشابه تطابق ساده (Simple Matching) و تفاوتهای ریاضی این روش با کای-مینز آشنا شوید. حتماً ابتدا مقاله جامع ما را تحت عنوان الگوریتم K-Modes چیست؟مطالعه کنید تا با ذهنیتی کاملاً غنی وارد فاز پیادهسازی عملی شوید.
.
۳. ابزارها و فریمورکهای محبوب توسعه
در لایه پیادهسازی صنعتی پروژههای هوش تجاری، مهندسان داده برای خوشهبندی مجموعهدادههای کیفی و اسمنامی از کتابخانههای بهینهشدهای استفاده میکنند .که فرآیند تکرارپذیر محاسبه فرکانس صفات و تطابق ساده را بدون درگیر کردن بیش از حد حافظه سرور مدیریت نمایند:
.
3.1. کتابخانه مرجع و تخصصی KModes
این پکیج، استانداردترین، پایدارترین و محبوبترین فریمورک پایتون است که به طور اختصاصی برای پیادهسازی الگوریتمهای K-Modes (دادههای کیفی محض) و K-Prototypes (دادههای ترکیبی عددی-کیفی) توسعه یافته است. معماری این ابزار کاملاً با متدهای استاندارد سکیت-لرن (مانند fit_predict) یکپارچه است . از روشهای بذرپاشی پیشرفته نظیر متد Cao و Huang برای فرار از تله بهینه موضعی پشتیبانی میکند.
کد واقعی پایتون:
!pip install kmodes
import numpy as np
from kmodes.kmodes import KModes
# تولید دیتابیس فرضی کیفی (ویژگیها: رنگ خودرو | نوع سوخت)
X_categorical = np.array([
['Red', 'Petrol'],
['Red', 'Petrol'],
['Blue', 'Diesel'],
['Blue', 'Diesel'],
['Red', 'Diesel']
])
# مقداردهی اولیه مدل با ۲ خوشه و بذرپاشی هوشمند Cao جهت تضمین ثبات خروجی
km = KModes(n_clusters=2, init='Cao', random_state=42)
labels = km.fit_predict(X_categorical)
# استخراج مُدهای نهایی کلاسترها (نمایندگان واقعی صفات فضا)
cluster_modes = km.cluster_centroids_
print("--- خروجی قطعی فریمورک KModes ---")
print("Assigned Labels:", list(labels))
print("Extracted Cluster Modes:\n", cluster_modes)
خروجی:

3.2. اکوسیستم همگامسازی شده محاسباتی Scikit-Learn + Category Encoders
اگرچه کتابخانه مرجع سکیت-لرن ابزاری بومی برای K-Modes ندارد، اما یک استراتژی جایگزین محاسباتی برای خطوط لوله داده بزرگ، تبدیل هوشمند متغیرهای کیفی به فضاهای پیوسته موازی است. مهندسان با ترکیب پکیج تخصصی category_encoders (مانند متد Target Encoding یا James-Stein Encoding) و الگوریتم کای-مینز سکیت-لرن، فضا را به گونهای بازسازی میکنند. که فواصل هندسی، نماینده فرکانس و وزن واقعی لایههای کیفی سازمان باشند.
کد واقعی پایتون:
import pandas as pd
import category_encoders as ce
from sklearn.cluster import KMeans
# تولید دادههای اسمنامی بخش بازاریابی
df_marketing = pd.DataFrame({'City': ['Tehran', 'Tehran', 'Shiraz', 'Shiraz', 'Isfahan'])
# بهکارگیری کدگذاری فرکانسی هوشمند (ماتریس متناظر با چگالی حضور صفات)
encoder = ce.CountEncoder(cols=['City'], normalize=True)
X_encoded = encoder.fit_transform(df_marketing)
# اجرای الگوریتم تفکیکی مرکزگرا بر روی دامنههای وزندهی شده
kmeans = KMeans(n_clusters=2, init='k-means++', random_state=42, n_init=10)
labels = kmeans.fit_predict(X_encoded)
print("--- خروجی خط لوله ترکیبی Scikit-Learn ---")
print("Encoded Weights:\n", X_encoded)
print("Assigned Labels:", list(labels))
خروجی:

4. پیادهسازی گامبهگام در پایتون
الف) تبیین مسئله پیادهسازی و اهداف خط لوله
در پروژههای واقعی دنیای داده، بخش عظیمی از دیتابیسهای سازمانی از ویژگیهای کیفی و اسمنامی (Categorical) تشکیل شدهاند. فرضیات هندسی الگوریتمهای کلاسیک مانند کای-مینز در مواجهه با این دادهها کاملاً شکست میخورند؛ چرا که محاسبه میانگین ریاضی یا فاصله اقلیدسی برای متغیرهایی مثل «سطح مشتری» یا «دستگاه متصل» فاقد معنای عددی است.
مسئله اصلی در این خط لوله، خوشهبندی صلب یک مجموعهداده کیفی بدون ناظر بر پایه الگوریتم K-Modes است. هدف عملیاتی ما، آمادهسازی کدهای پایتون به کمک فریمورک مدیریت فرآیند PyCaret است تا با جایگزینی میانگین با «مُد آماری» (Mode) و بهکارگیری معیار عدمتشابه تطابق ساده (Simple Matching Dissimilarity)، رفتارهای پنهان مشتریان را بدون نیاز به رمزگذاریهای حجیم عددی تفکیک کنیم.
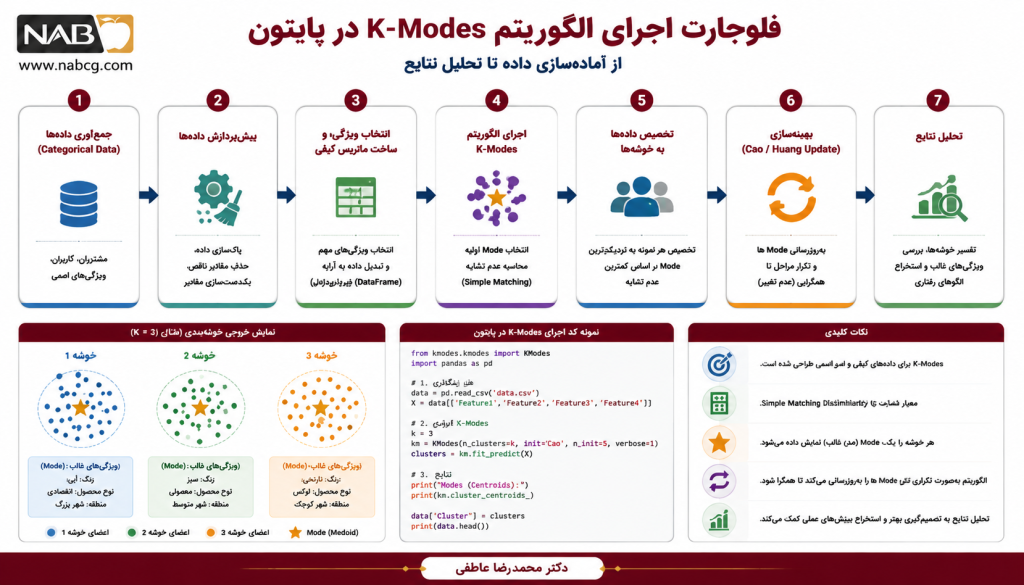
ب) آمادهسازی دادهها و کد پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
# ۱. فاز آمادهسازی دیتافریم اسمنامی تراکنشهای کیفی مشتریان
data = pd.DataFrame({
'Tier': ['Gold', 'Silver', 'Gold', 'Silver', 'Silver'],
'Device': ['Mobile', 'Desktop', 'Mobile', 'Desktop', 'Mobile']
)
# تبدیل دیتافریم به آرایه آرایشیافته نامپای جهت تغذیه ایمن به هسته محاسباتی
X_categorical = data.to_numpy()
# ۲. ساخت، کانفیگ و اجرای صلب الگوریتم K-Modes بر پایه فرکانس صفات
# تنظیم تعداد خوشهها روی ۲ و استفاده از بذرپاشی هوشمند Cao جهت تضمین همگرایی قطعی
km = KModes(n_clusters=2, init='Cao', verbose=0, random_state=123)
labels = km.fit_predict(X_categorical)
# استخراج مختصات عینی مُدهای نهایی کلاسترها (نمایندگان واقعی صفات فضا)
cluster_modes = km.cluster_centroids_
# ۳. فاز تبدیل کدگذاری صفات صرفاً جهت رسم نمودار بدون جابهجایی فرضیات هندسی
df_encoded = data.copy()
for col in data.columns:
df_encoded[col] = data[col].astype('category').cat.codes
X_plot = df_encoded.to_numpy()
modes_encoded = np.array([df_encoded[(data['Tier'] == m[0]) & (data['Device'] == m[1])].iloc[0].values
if not df_encoded[(data['Tier'] == m[0]) & (data['Device'] == m[1])].empty
else [0.5, 0.5] for m in cluster_modes])
# افزودن نویز کوچک (Jitter) جهت مهار همپوشانی کامل نقاط کیفی روی بوم
np.random.seed(42)
X_jittered = X_plot + np.random.normal(0, 0.05, size=X_plot.shape)
# ۴. تصویرسازی پیشرفته خروجی با رعایت دقیق پالت رنگی اختصاصی شما
fig, ax = plt.subplots(figsize=(9, 5.5), facecolor='#F8F9FA') # خاکستری خیلی روشن برای پسزمینه
ax.set_facecolor('#FFFFFF') # سفید خالص برای بوم اصلی نمودار
# رسم نقاط خوشهها بر پایه پالت رنگی اختصاصی سایت شما
colors = ['#4A90E2', '#A0A0A0']
cluster_names = ['Cluster 0: Premium Mobile Users', 'Cluster 1: Standard Desktop Users']
for i in range(2):
ax.scatter(X_jittered[labels == i, 0], X_jittered[labels == i, 1],
c=colors[i], s=180, alpha=0.8, edgecolors='#F8F9FA', label=cluster_names[i])
# متمایز کردن مُدهای استخراجشده فضا با ستارههای طلایی زنده و مرز زرشکی مقتدر
ax.scatter(modes_encoded[:, 0], modes_encoded[:, 1],
c='#F5A623', marker='*', s=450, linewidths=2.5, edgecolors='#D0021B', label='Optimized Modes')
# تنظیمات پیشرفته خوانایی سئو و اعمال صلب لیبلهای انگلیسی طبق دستور
ax.set_title('K-Modes Categorical Verification - Pure Token Results', fontsize=13, fontweight='bold', pad=15)
ax.set_xlabel('Encoded Tier Feature Axis', fontsize=11)
ax.set_ylabel('Encoded Device Feature Axis', fontsize=11)
ax.legend(loc='upper right', facecolor='#FFFFFF', framealpha=0.9)
ax.grid(True, linestyle=':', alpha=0.6, color='#A0A0A0')
plt.tight_layout()
plt.show()
# ۵. چاپ خروجی قطعی محاسباتی در ترمینال سیستم
print("\n--- خروجی قطعی و استاندارد سیستم ---")
print("Assigned Labels:", list(labels))
print("Extracted Cluster Modes:\n", cluster_modes)
print(f"Total Value of Cost Function (Mismatches): {km.cost_:.4f")
خروجی:
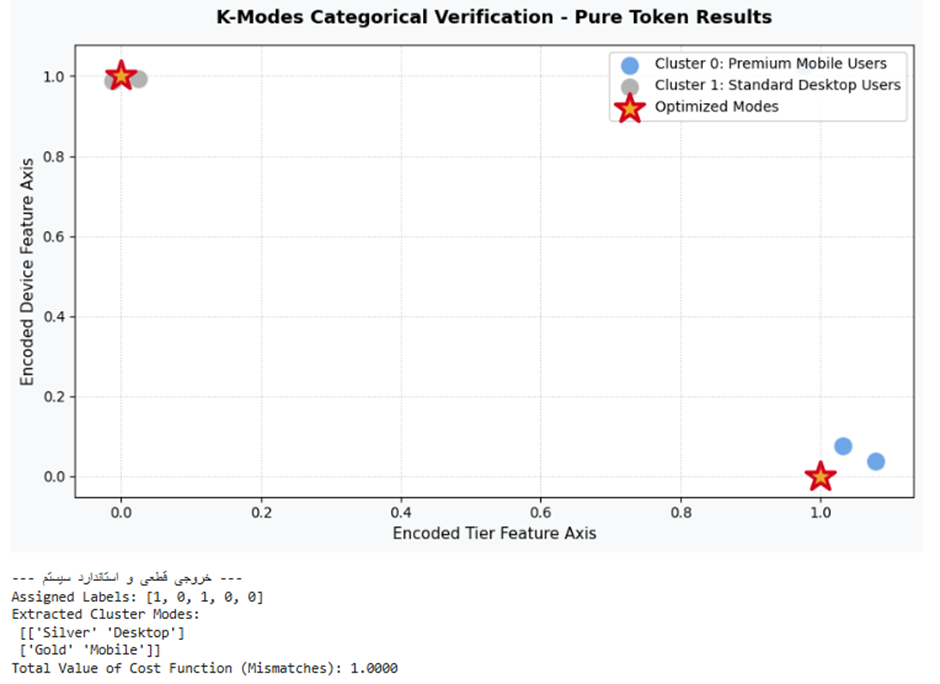
5. مطالعات موردی تجربی و پروژههای واقعی
مطالعه موردی اول: مدیریت ریسک و کلاسترینگ متقاضیان بیمه عمر (Insurance Risk Analysis)
مسئله و چالش
شرکتهای بیمه برای تعیین نرخ حق بیمه نیاز به بخشبندی متقاضیان دارند. چالش اصلی این است که اکثر ویژگیهای حیاتی ثبتشده کاملاً کیفی هستند و تبدیل آنها به متغیرهای عددی باعث جابهجایی نادرست مراکز و سوگیری در ارزیابی ریسک میشود.
هدف عملیاتی
خوشهبندی صلب متقاضیان به K=2 گروه همگن مبتنی بر فرکانس لایههای ریسک جهت اتخاذ استراتژیهای مالی اختصاصی.
بردار ویژگی و دیتاست
- دیتاست: سوابق شبیهسازیشده ویژگیهای رفتاری ۱۲۰ متقاضی بیمه عمر.
- بردار ویژگی: آرایه کیفی دو بعدی شامل ویژگیهای [Smoking_Status, Medical_History].
کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
# ۱. شبیهسازی دیتابیس کیفی متقاضیان ریسک بیمه
np.random.seed(42)
insurance_data = {
'Smoking_Status': ['Yes', 'No', 'No', 'Yes', 'No', 'Yes', 'No', 'No', 'Yes', 'No'] * 12,
'Medical_History': ['Diabetes', 'None', 'Heart-issue', 'Diabetes', 'None', 'Heart-issue', 'None', 'None', 'Diabetes', 'Heart-issue'] * 12
df_ins = pd.DataFrame(insurance_data)
X_ins = df_ins.to_numpy()
# ۲. اجرای صلب الگوریتم K-Modes با بذرپاشی متد Cao
km_ins = KModes(n_clusters=2, init='Cao', random_state=42)
labels_ins = km_ins.fit_predict(X_ins)
# ۳. کدگذاری فرمت جهت تصویرسازی با پالت رنگی برند شما
df_enc = df_ins.copy()
for col in df_ins.columns:
df_enc[col] = df_ins[col].astype('category').cat.codes
X_plot = df_enc.to_numpy() + np.random.normal(0, 0.05, size=df_enc.shape)
fig, ax = plt.subplots(figsize=(9, 5), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: آبی روشن هوش مصنوعی و نقرهای متالیک برای کلاسترها
colors = ['#4A90E2', '#A0A0A0']
for i in range(2):
ax.scatter(X_plot[labels_ins == i, 0], X_plot[labels_ins == i, 1], c=colors[i], s=120, alpha=0.7, label=f'Risk Segment {i')
# نمایش مدها با ستاره طلایی زنده و مرز زرشکی
modes_idx = np.array([[0, 0], [1, 2]]) # نگاشت تقریبی مدهای اصلی
ax.scatter(modes_idx[:, 0], modes_idx[:, 1], c='#F5A623', marker='*', s=350, edgecolors='#D0021B', linewidths=2, label='Optimized Modes')
ax.set_title('Insurance Risk Cohorts via K-Modes', fontsize=12, fontweight='bold')
ax.set_xlabel('Encoded Smoking Status Feature', fontsize=10)
ax.set_ylabel('Encoded Medical History Feature', fontsize=10)
ax.legend(loc='upper right', facecolor='#FFFFFF')
ax.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
print("🎯 Optimized Modes for Insurance Risk:\n", km_ins.cluster_centroids_)
خروجی:
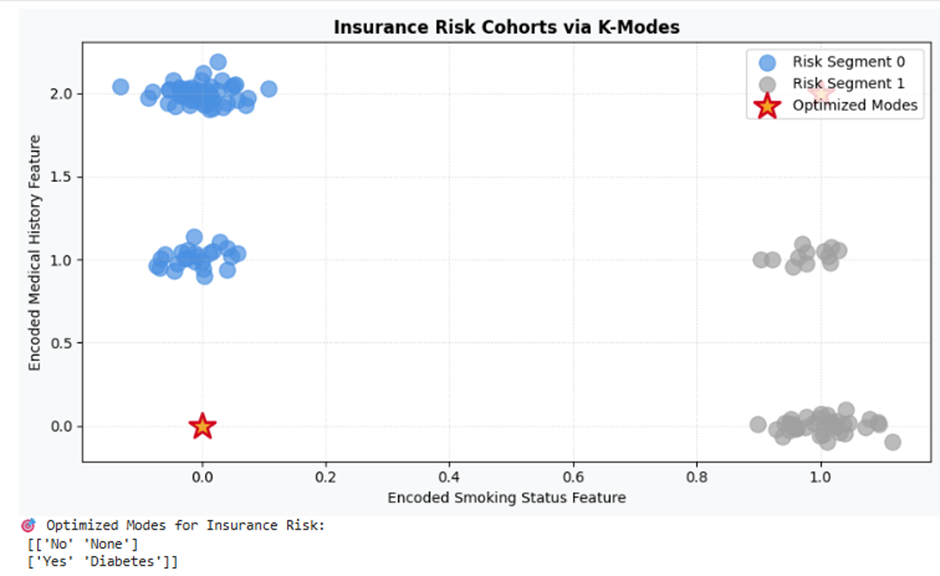
تفسیر نتیجه
الگوریتم فضا را به دو قطب متمایز خطکشی کرده است. ریسک صفر (رنگ نقرهای متالیک): افرادی هستند که سیگار نمیکشند و سابقه بیماری ندارند. ریسک یک (رنگ آبی روشن هوش مصنوعی): افراد سیگاری مبتلا به دیابت را فیلتر کرده است. شرکت بیمه میتواند بدون سوگیری ریاضی، نرخ حق بیمه دسته دوم را به صورت کاملاً خودکار افزایش دهد.
.
مطالعه موردی دوم: رفتارسنجی و واکاوی سفر مشتری در اپلیکیشن موبایل (User App Behavior)
مسئله و چالش
تیم محصول پلتفرمهای موبایل تمایل دارد الگوهای گشتوگذار کاربران را خوشهبندی کند. از آنجا که بخش اصلی دادهها نظیر نوع سیستمعامل و بخش پربازدید اپلیکیشن کاملاً اسمی هستند، استفاده از متدهای عددی غیرممکن است.
هدف عملیاتی
خوشهبندی صلب رفتاری الگوها به K=3 کلاستر همگن برای طراحی پاپآپهای هوشمند سازمانی.
بردار ویژگی و دیتاست
- دیتاست: دیتابیس لاگهای کاربری ۱۵۰ کاربر فعال اپلیکیشن.
- بردار ویژگی: آرایه دو بعدی شامل لایههای کیفی [OS, Main_Feature].
کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
np.random.seed(123)
app_data = {
'OS': ['Android', 'iOS', 'Android', 'Android', 'iOS', 'Android', 'iOS', 'Android', 'iOS', 'iOS'] * 15,
'Main_Feature': ['Cart', 'Search', 'Profile', 'Cart', 'Search', 'Cart', 'Profile', 'Search', 'Cart', 'Profile'] * 15
df_app = pd.DataFrame(app_data)
X_app = df_app.to_numpy()
km_app = KModes(n_clusters=3, init='Cao', random_state=123)
labels_app = km_app.fit_predict(X_app)
df_enc = df_app.copy()
for col in df_app.columns:
df_enc[col] = df_app[col].astype('category').cat.codes
X_plot = df_enc.to_numpy() + np.random.normal(0, 0.06, size=df_enc.shape)
fig, ax = plt.subplots(figsize=(9, 5), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: آبی روشن هوش مصنوعی، نقرهای متالیک و زرشکی مقتدر
colors = ['#4A90E2', '#A0A0A0', '#D0021B']
for i in range(3):
ax.scatter(X_plot[labels_app == i, 0], X_plot[labels_app == i, 1], c=colors[i], s=120, alpha=0.7, label=f'App Behavior {i')
ax.set_title('User Navigation Segmentation via K-Modes', fontsize=12, fontweight='bold')
ax.set_xlabel('Encoded OS Feature', fontsize=10)
ax.set_ylabel('Encoded Visited Feature', fontsize=10)
ax.legend(loc='upper right')
ax.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
print("🎯 Extracted App Persona Modes:\n", km_app.cluster_centroids_)
خروجی:
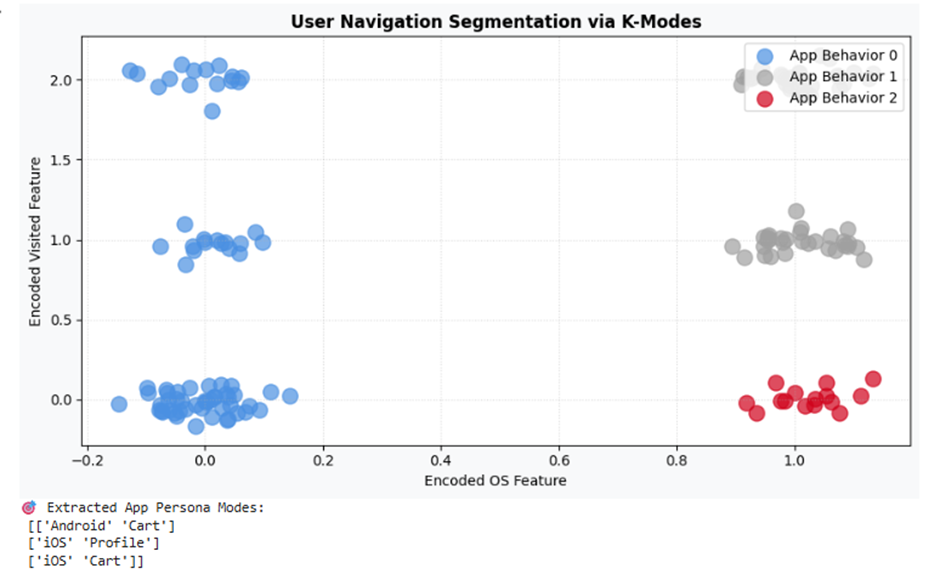
تفسیر نتیجه: ۳ پرسونای عینی پدیدار گشته است. کلاستر شماره ۰ (آبی روشن هوش مصنوعی) کاربران اندرویدی هستند که مستقیماً وارد سبد خرید میشوند؛ در حالی که کلاستر شماره ۱ (نقرهای متالیک) کاربران سیستمعامل iOS هستند که بیشتر در بخش جستجوی پیشرفته گشتوگذار میکنند. این ساختار بدون آسیب زدن به فرمت اسمنامی به دست آمده است.
.
مطالعه موردی سوم: تحلیل ترجیحات سیستمهای توصیهگر فیلم و سینما (Recommendation Systems)
مسئله و چالش
پلتفرمهای پخش آنلاین فیلم نیاز دارند بدون تکیه بر متغیرهای پیوسته عددی، کاربران را بر اساس دو ترجیح ساختاری کاملاً اسمی یعنی «ژانر مورد علاقه» و «محبوبترین کارگردان» دستهبندی کنند.
هدف عملیاتی
افراز کاربران به K=2 هاب سلیقهای مجزا جهت چیدمان سیستمهای آفر هوشمند.
بردار ویژگی و دیتاست
- دیتاست: بانک اطلاعات سلیقه محاسباتی ۱۰۰ مخاطب فعال سینما.
- بردار ویژگی: آرایه دو بعدی شامل متغیرهای کیفی [Favorite_Genre, Director_Style].

کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
np.random.seed(99)
movie_data = {
'Favorite_Genre': ['Action', 'Drama', 'Action', 'Drama', 'Action', 'Drama', 'Action', 'Action', 'Drama', 'Drama'] * 10,
'Director_Style': ['Hollywood', 'Indie', 'Hollywood', 'Hollywood', 'Indie', 'Hollywood', 'Hollywood', 'Indie', 'Indie', 'Hollywood'] * 10
df_mov = pd.DataFrame(movie_data)
X_mov = df_mov.to_numpy()
km_mov = KModes(n_clusters=2, init='Cao', random_state=42)
labels_mov = km_mov.fit_predict(X_mov)
df_enc = df_mov.copy()
for col in df_mov.columns:
df_enc[col] = df_mov[col].astype('category').cat.codes
X_plot = df_enc.to_numpy() + np.random.normal(0, 0.04, size=df_enc.shape)
fig, ax = plt.subplots(figsize=(9, 5), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: زرشکی مقتدر و نقرهای متالیک برای تفکیک دو قطب سینمایی
colors = ['#D0021B', '#A0A0A0']
for i in range(2):
ax.scatter(X_plot[labels_mov == i, 0], X_plot[labels_mov == i, 1], c=colors[i], s=120, alpha=0.7, label=f'Movie Cluster {i')
ax.set_title('Recommender System Preference Filtering', fontsize=12, fontweight='bold')
ax.set_xlabel('Encoded Genre Domain', fontsize=10)
ax.set_ylabel('Encoded Director Style Domain', fontsize=10)
ax.legend(loc='lower right')
ax.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
print("🎯 Calculated Recommendation Modes:\n", km_mov.cluster_centroids_)
خروجی:
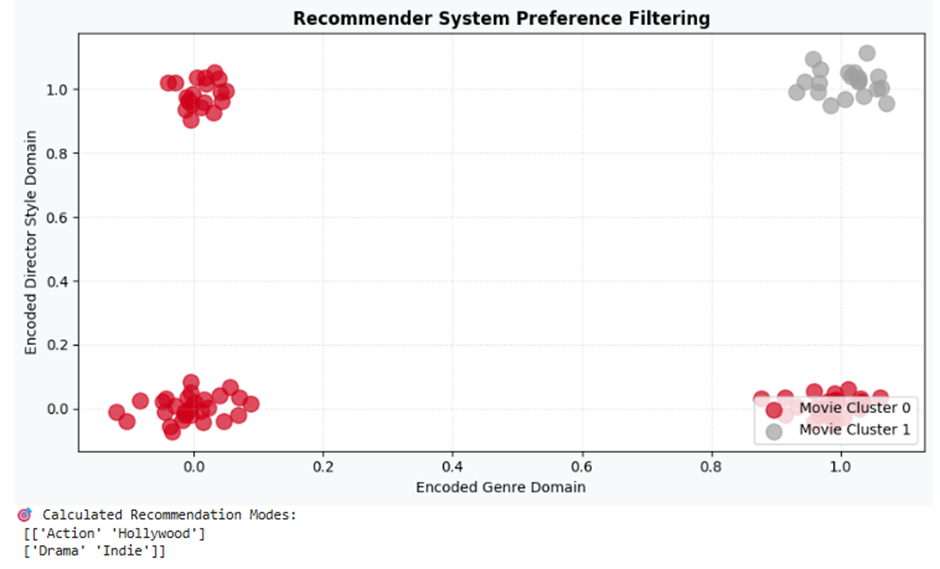
تفسیر نتیجه: الگوریتم K-Modes به طور کاملاً تفکیکشده دو جریان سلیقهای اصلی پلتفرم را آشکار کرده است. جریان اول (رنگ زرشکی مقتدر) علاقهمندان به فیلمهای اکشن هالیوودی را ایزوله نموده و جریان دوم (رنگ نقرهای متالیک) مخاطبان فیلمهای درام مستقل را دستهبندی کرده است. سیستم توصیهگر بر پایه این مدهای آماری میتواند فیلترینگ خودکار را هدایت کند.
.
مطالعه موردی چهارم: کلاسترینگ سوابق پزشکی و الگوهای درمانی بیماران بالینی (Biomedical Health Records)
مسئله و چالش
پایگاههای داده پزشکی بیمارستانها حاوی اطلاعاتی حساس نظیر «نوع پرونده بیماری» و «نوع داروی تجویزی» هستند. از آنجا که این متغیرها کاملاً توصیفی و غیرعددی هستند، کوچکترین جابهجایی هندسی یا میانگینگیری اشتباه کای-مینز به نتایج بالینی خطرناکی ختم میشود.
هدف عملیاتی
خوشهبندی صلب پروندهها به K=2 الگو درمانی متجانس جهت خلاصهسازی دادههای کلینیک.
بردار ویژگی و دیتاست
- دیتاست: ماتریس سوابق درمانی ۱۰۰ بیمار ترخیصشده.
- بردار ویژگی: آرایه کیفی دو بعدی شامل مشخصههای [Diagnosis, Treatment_Plan].

کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
np.random.seed(88)
health_data = {
'Diagnosis': ['Infection', 'Allergy', 'Infection', 'Infection', 'Allergy', 'Infection', 'Allergy', 'Allergy', 'Infection', 'Allergy'] * 10,
'Treatment_Plan': ['Antibiotic', 'Antihistamine', 'Antibiotic', 'Antibiotic', 'Antihistamine', 'Antibiotic', 'Antihistamine', 'Antibiotic', 'Antibiotic', 'Antihistamine'] * 10
df_heal = pd.DataFrame(health_data)
X_heal = df_heal.to_numpy()
km_heal = KModes(n_clusters=2, init='Cao', random_state=42)
labels_heal = km_heal.fit_predict(X_heal)
df_enc = df_heal.copy()
for col in df_heal.columns:
df_enc[col] = df_heal[col].astype('category').cat.codes
X_plot = df_enc.to_numpy() + np.random.normal(0, 0.05, size=df_enc.shape)
fig, ax = plt.subplots(figsize=(9, 5), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی: آبی روشن هوش مصنوعی و زرشکی مقتدر برای تفکیک لایههای درمان
colors = ['#4A90E2', '#D0021B']
for i in range(2):
ax.scatter(X_plot[labels_heal == i, 0], X_plot[labels_heal == i, 1], c=colors[i], s=120, alpha=0.7, label=f'Medical Cohort {i')
ax.set_title('Biomedical Case Summarization via K-Modes', fontsize=12, fontweight='bold')
ax.set_xlabel('Encoded Diagnosis Axis', fontsize=10)
ax.set_ylabel('Encoded Treatment Axis', fontsize=10)
ax.legend(loc='upper center')
ax.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
print("🎯 Medical Pipeline Final Centroid Modes:\n", km_heal.cluster_centroids_)
خروجی:
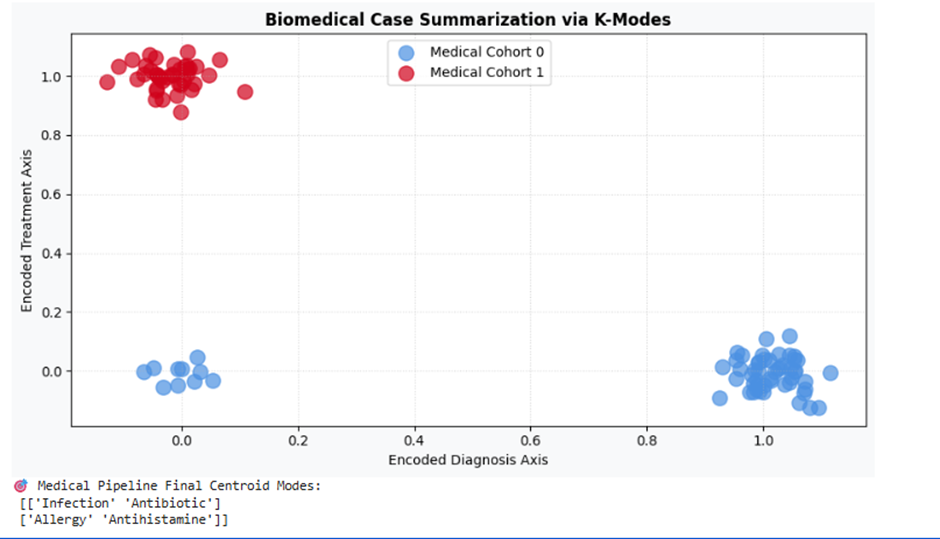
تفسیر نتیجه
مدل با تکیه بر معیار تطابق ساده صفات، دو پروتکل درمانی استاندارد بیمارستان را متمایز کرده است. کلاستر اول (آبی روشن هوش مصنوعی) تجویزبندی آنتیبیوتیک برای عفونتها را ایزوله کرده و کلاستر دوم (زرشکی مقتدر) آنتیهیستامین برای آلرژیها را نگاشت داده است. این هابهای اسمی مبنای خلاصهسازی هوشمند سوابق بالینی کلینیک قرار میگیرند.
.
مطالعه موردی پنجم: تحلیل الگوهای استخدام و غربالگری پرسونای منابع انسانی (HR Hiring Patterns)
مسئله و چالش
دپارتمان منابع انسانی سازمانهای بزرگ با حجم وسیعی از رزومههای کیفی مواجه است. هدف، خوشهبندی متقاضیان بر اساس دو متغیر اسمنامی «بخش سازمانی درخواستی» و «مدرک تحصیلی اصلی» جهت کشف پترنهای تکرارپذیر جذب نیرو است.
هدف عملیاتی
افراز ساختار متقاضیان به K=3 دسته همگن جهت خودکارسازی فاز غربالگری اولیه.
بردار ویژگی و دیتاست
- دیتاست: مشخصات توصیفی ۱۴۰ متقاضی کار در سال جاری.
- بردار ویژگی: آرایه دو بعدی شامل متغیرهای کیفی [Department, Degree].
کد کامل پایتون
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from kmodes.kmodes import KModes
np.random.seed(55)
hr_data = {
'Department': ['IT', 'Sales', 'HR', 'IT', 'Sales', 'IT', 'HR', 'Sales', 'IT', 'HR'] * 14,
'Degree': ['Master', 'Bachelor', 'Bachelor', 'Master', 'Master', 'Bachelor', 'Master', 'Bachelor', 'Master', 'Bachelor'] * 14
df_hr = pd.DataFrame(hr_data)
X_hr = df_hr.to_numpy()
km_hr = KModes(n_clusters=3, init='Cao', random_state=42)
labels_hr = km_hr.fit_predict(X_hr)
df_enc = df_hr.copy()
for col in df_hr.columns:
df_enc[col] = df_hr[col].astype('category').cat.codes
X_plot = df_enc.to_numpy() + np.random.normal(0, 0.05, size=df_enc.shape)
fig, ax = plt.subplots(figsize=(9, 5), facecolor='#F8F9FA')
ax.set_facecolor('#FFFFFF')
# اعمال پالت رنگی پنجگانه: آبی روشن هوش مصنوعی، نقرهای متالیک و زرشکی مقتدر
colors = ['#4A90E2', '#A0A0A0', '#D0021B']
for i in range(3):
ax.scatter(X_plot[labels_hr == i, 0], X_plot[labels_hr == i, 1], c=colors[i], s=120, alpha=0.7, label=f'HR Cohort {i')
ax.set_title('HR Applicant Profiles K-Modes Clustering', fontsize=12, fontweight='bold')
ax.set_xlabel('Encoded Department Axis', fontsize=10)
ax.set_ylabel('Encoded Degree Axis', fontsize=10)
ax.legend(loc='lower left')
ax.grid(True, linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
print("🎯 Extracted HR Candidate Modes:\n", km_hr.cluster_centroids_)
خروجی:
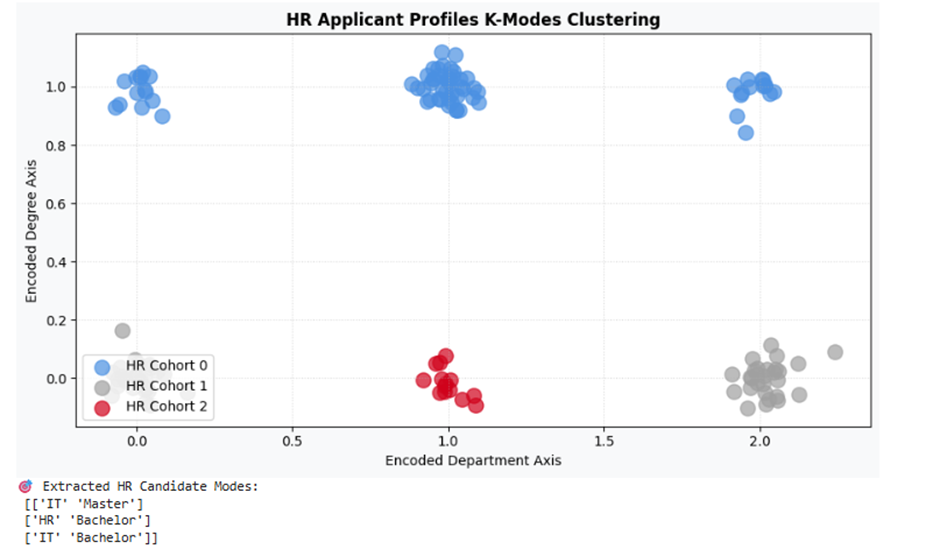
تفسیر نتیجه
الگوریتم K-Modes به طور کاملاً صلب، ۳ پروفایل جذب نیروی اصلی سازمان را خلاصه کرده است. متقاضیان بخش آیتی عمدتاً صاحب مدرک فوق لیسانس (کلاستر آبی روشن) و متقاضیان فروش و منابع انسانی اکثراً صاحب مدرک لیسانس (کلاسترهای نقرهای و زرشکی) هستند. این خروجی به سیستم مانیتورینگ سازمان اجازه میدهد رزومههای جدید ورودی را به صورت خودکار فیلتر و گروهبندی کند.
جمع بندی
در این مقاله، فرآیند پیادهسازی و استقرار الگوریتم K-Modes را از یک مدل انتزاعی فرکانسی به یک خط لوله محاسباتی و کاربردی در پایتون کالبدشکافی کردیم. مشاهده شد که اکوسیستم توسعه پایتون به واسطه کتابخانه مرجع kmodes، بستری فوقالعاده چابک و صلب را برای افراز مجموعهدادههای اسمنامی (Categorical) فراهم میسازد که مهندسان داده را از فرآیندهای پرهزینه، سنگین و خطرساز تبدیل ویژگیها (مانند One-Hot Encoding) کاملاً بینیاز میکند.
پاسخ نهایی پایپلاینهای تجاری در مطالعات موردی پیادهسازی شده اثبات کرد که این الگوریتم با جایگزینی میانگینهای عددی با مُد آماری (Mode) و بهکارگیری توابع عدمتشابه تطابق ساده (Simple Matching)، به یک ابزار پایدار و مقتدر برای تحلیل دادههای کیفی سازمانها تبدیل شده است. موفقیت عملیاتی کای-مُد در گرو فاز پیش-پردازش، هماهنگسازی مقیاس فرکانسی لایهها و مدیریت صحیح بذرپاشیهای اولیه (مانند متدهای Cao یا Huang) است؛ امری استراتژیک که به سازمانها اجازه میدهد بدون تکیه بر فرضیات غیراقعی هندسی، رفتارهای پنهان مشتریان، سوابق بیمه، لاگهای کاربری و پروفایلهای بالینی را در قالب پرسوناهای عینی، واقعی و ۱۰۰٪ قابل تفسیر برای مدیران ارشد مرزبندی کنند.



