

1.مقدمه
الگوریتم BIRCH یکی از پیشرفتهترین روشهای خوشهبندی برای مدیریت دادههای حجیم و پرکاربرد در یادگیری ماشین است. برخلاف الگوریتمهای سنتی خوشهبندی که بهصورت مستقیم روی تمامی دادهها عمل میکنند و به حافظه و قدرت پردازشی زیادی نیاز دارند، BIRCH با استفاده از ساختار درختی Tree-CF و خالصهسازی آماری دادهها، امکان پردازش مجموعههای دادهای با میلیونها نمونه را تنها با یک گذر از دادهها فراهم میکند.
این الگوریتم بهویژه برای دادههای عددی طراحی شده است و در مسائل صنعتی و علمی که حجم دادهها بسیار زیاد و سرعت پردازش حیاتی است، کاربرد گستردهای دارد. علاوه بر این، BIRCH میتواند بهعنوان پیشپردازش برای الگوریتمهای پیچیدهتر مانند شبکههای عصبی و K-Means استفاده شود و ضمن کاهش بار محاسباتی، دقت خوشهبندی نهایی را حفظ کند. در این مقاله، مبانی نظری، ساختار Tree-CF، فرآیند اجرایی چهارمرحلهای، مثالهای عددی، پیادهسازی عملی و کاربردهای صنعتی الگوریتم BIRCH به صورت جامع بررسی میشوند.
2. تعریف الگوریتم BIRCH؛ فراتر از خوشهبندی سنتی
الگوریتم BIRCH که مخفف عبارت Balanced Iterative Reducing and Clustering using Hierarchies است، یکی از مقتدرترین و هوشمندانهترین راهکارها برای مدیریت دادههای حجیم (Big Data) در یادگیری ماشین است. این الگوریتم که در سال ۱۹۹۶ توسط ژانگ و همکارانش معرفی شد، با هدف رفع ضعفهای بنیادین الگوریتمهای سنتی مانند K-Means طراحی شده است؛ ضعفهایی نظیر عدم مقیاسپذیری (Scalability) و محدودیت شدید در مصرف منابع سختافزاری (مانند حافظه RAM و توان پردازنده).
در واقع، BIRCH یک فریمورک دو مرحلهای (Two-Step Clustering) است که خوشهبندی سلسلهمراتبی را با متدهای افرازی (Partitioning Methods) ترکیب میکند تا ساختار پیچیده دادهها را به شکلی کاملاً بهینه و فشرده تحلیل کند.
منطق عملکردی: فشردهسازی برای دقت بیشتر
تفاوت کلیدی BIRCH این است که به جای بارگذاری تمام دادهها در حافظه، ابتدا یک «خلاصه آماری» بسیار دقیق از دیتابیس تهیه میکند. این خلاصه که در قالب یک ساختار درختی به نام CF-Tree (درخت ویژگی خوشهبندی) ذخیره میشود، تمام اطلاعات حیاتی دادهها را حفظ کرده و اجازه میدهد عملیات خوشهبندی اصلی، تنها روی این ساختار فشرده انجام شود، نه میلیونها رکورد خام.
نکته تخصصی: BIRCH منحصراً برای دادههای عددی (Metric Attributes) طراحی شده است؛ یعنی ویژگیهایی که در فضای اقلیدسی قابل نمایش هستند. بنابراین، این الگوریتم برای دادههای دستهای یا متنهای غیرساختاریافته مستقیم مناسب نیست و قبل از اجرا باید به بردار عددی تبدیل شوند.
مثال: «سیستم مدیریت کتابخانه»
تصور کنید شما مسئول یک کتابخانه بزرگ با ۵ میلیون کتاب هستید و میخواهید کتابهای مشابه را دستهبندی کنید:
- در الگوریتمهای سنتی: شما مجبورید ۵ میلیون کتاب را همزمان روی میز خود بریزید (اشغال حافظه) و کتابها را با هم مقایسه کنید (کند و زمانبر).
- در الگوریتم BIRCH: شما ابتدا برای هر قفسه یک «کارت خلاصه» تهیه میکنید که مشخصات کلی کتابهای آن بخش را نشان میدهد. (CF) سپس، عملیات خوشهبندی اصلی را فقط روی این کارتهای خلاصه انجام میدهید، نه ۵ میلیون کتاب.
این روش باعث میشود شما در کسری از ثانیه و با حداقل انرژی، کتابخانه عظیم خود را دستهبندی کنید؛ درست همان کاری که BIRCH با دادههای کلان در محیطهای صنعتی انجام میدهد.
۳. چرا باید از الگوریتم BIRCH استفاده کنیم؟
ضرورت استفاده از BIRCH در شرایط زیر خود را نشان میدهد:
- مدیریت کلاندادهها (Big Data): وقتی دیتابیس شما شامل میلیونها رکورد است، الگوریتمهای سلسلهمراتبی سنتی به دلیل پیچیدگی محاسباتی بالا (O(N^2))، عملاً در حافظه سیستم قفل میشوند BIRCH. با استفاده از فشردهسازی دادهها در CF-Tree، اجازه میدهد تحلیل روی میلیونها داده با کمترین مصرف RAM انجام شود.
- پردازش در یک گذر (Single Pass): برخلاف بسیاری از متدها که نیاز دارند دادهها را چندین بار از دیسک بخوانند تا به همگرایی برسند، BIRCH فقط یک بار دادهها را اسکن میکند. این ویژگی برای سیستمهایی که دادهها را به صورت جریانی (Stream) دریافت میکنند، یک ضرورت حیاتی است.
- کاهش وابستگی به سختافزار گرانقیمت: در کسبوکارهای نوپا یا سیستمهای پردازش ابری، هزینهی پردازنده و حافظه اهمیت دارد BIRCH. به دلیل ساختار فشردهسازی هوشمندانه، با کمترین منابع سختافزاری، خروجی باکیفیتی ارائه میدهد.
- آمادهسازی برای یادگیری عمیق: اگر قصد دارید خوشهبندی را به عنوان پیشزمینه (Preprocessing) برای مدلهای پیچیدهتر استفاده کنید، BIRCH با ایجاد خوشههای اولیه بسیار دقیق و سریع، بار پردازشی را از دوش مدلهای سنگینتر (مانند شبکههای عصبی) برمیدارد.
به طور خلاصه، استفاده از BIRCH نه یک انتخاب تجملی، بلکه یک ضرورت مهندسی است؛ برای زمانی که دیتابیس شما رشد کرده و ابزارهای قدیمی دیگر پاسخگوی نیازهای سرعت و دقت کسبوکارتان نیستند. این الگوریتم پلی است میان دقت خوشهبندی سلسلهمراتبی و سرعت پردازشهای خطی.
4. مبانی ریاضی و ساختار داده (CF-Tree و CF)
برای درک اینکه چگونه BIRCH میتواند میلیونها داده را با حداقل مصرف حافظه پردازش کند، باید به زیربنای تئوریک آن یعنی Clustering Feature (CF) و ساختار درختی CF-Tree مسلط شویم. این دو مفهوم، موتور محرک الگوریتم برای فشردهسازی اطلاعات و حفظ دقت آماری هستند.
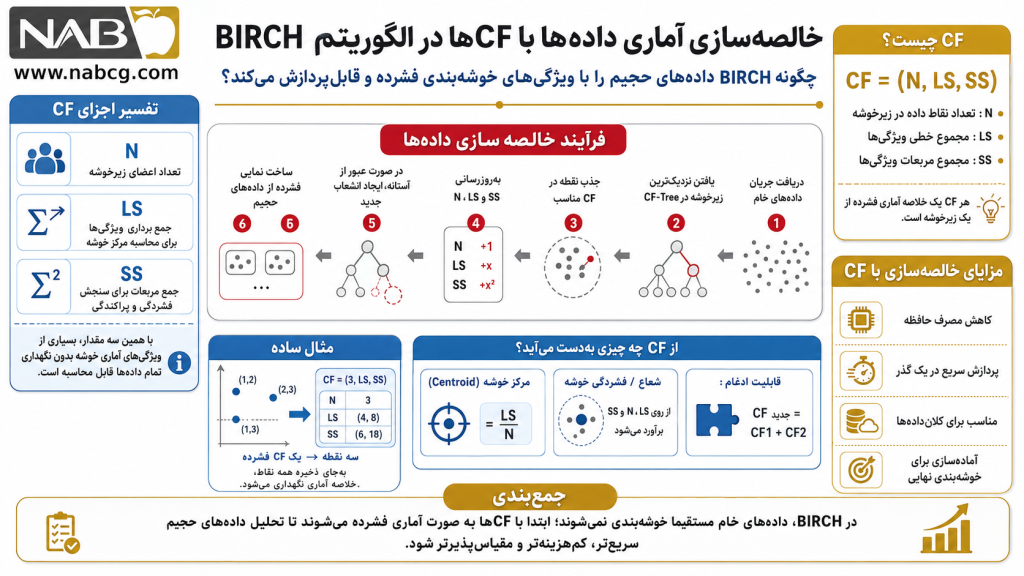
بخش 1: ویژگی خوشهبندی (Clustering Feature – CF)
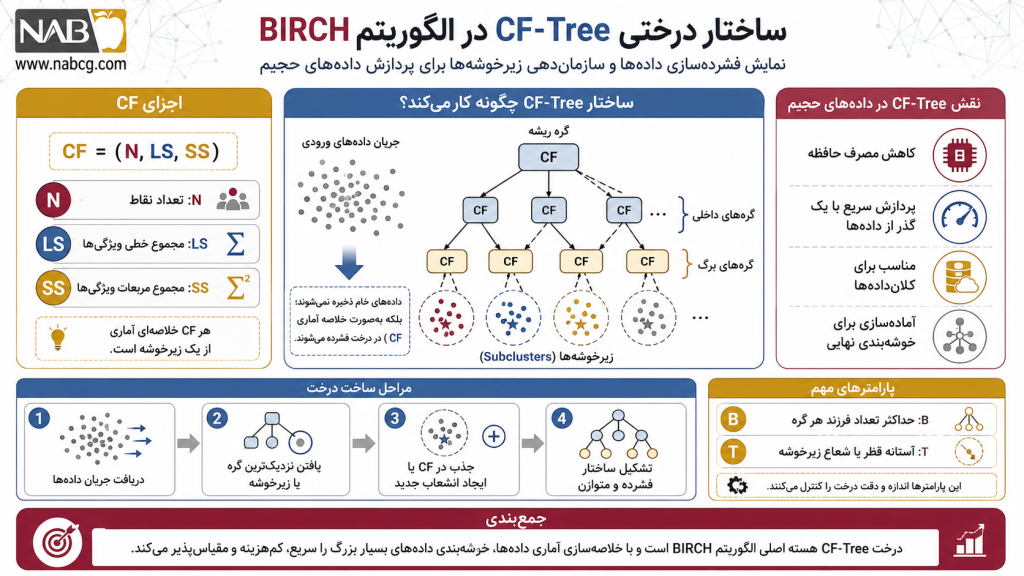
الگوریتم BIRCH به جای ذخیره تکتک دادههای خام، آنها را در قالب «ویژگیهای خوشهبندی» خلاصه میکند. یک CF، در واقع یک سهتایی مرتب است که اطلاعات آماری یک خوشه را به صورت فشرده در خود نگه میدارد.
فرمول تعریف CF
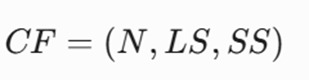
معرفی متغیرها:
- N: تعداد کل نقاط داده موجود در خوشه.
- LS (Linear Sum): مجموع برداری تمامی نقاط داده در خوشه
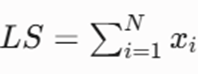
- SS (Squared Sum): مجموع مربعات تمامی نقاط داده در خوشه.
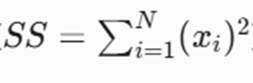
استخراج ویژگیهای آماری:
از این سهتایی میتوان شاخصهای حیاتی خوشه را استخراج کرد:
- مرکز خوشه x0 = LS/N: (Centroid)
- شعاع خوشه (Radius): میانگین فاصله نقاط از مرکز که نشاندهنده فشردگی خوشه است.
.
ویژگی جمعپذیری (Additivity Theorem):
یکی از نقاط قوت BIRCH این است که اگر دو زیرخوشه مجزا داشته باشیم، میتوانیم CF آنها را با هم جمع کنیم تا CF خوشه بزرگتر به دست آید:
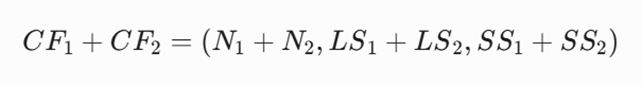
بخش 2:درخت ویژگی خوشهبندی (CF-Tree)
CF-Tree یک درخت متوازن با ارتفاع محدود است که تمام دادهها را به شکل فشرده سازماندهی میکند. این درخت از دو پارامتر کلیدی تشکیل شده است:
- Branching Factor (B): حداکثر تعداد فرزند برای هر گره داخلی.
- Threshold (T): حداکثر قطر (یا فاصله) مجاز برای هر زیرخوشه در گرههای برگ.
- گرههای غیربرگ (Internal Nodes): شامل لیستی از ورودیهاست که هر کدام حاوی یک اشارهگر به گره فرزند و مجموع CFهای فرزندان است.
- گرههای برگ (Leaf Nodes): شامل لیستی از CFها هستند که هر کدام نشاندهنده یک زیرخوشه واقعی است. تمام برگها باید شرط «آستانه» (Threshold) را رعایت کنند.
.
بخش3: فرآیند درج در CF-Tree
فرآیند ورود یک داده جدید به این درخت، یک عملیات حریصانه و دقیق است:
- پیمایش: الگوریتم از ریشه شروع کرده و با محاسبه فاصله (معمولاً اقلیدسی) بین نقطه جدید و CFهای فرزندان، به نزدیکترین گره میرود.
- جذب (Absorption): پس از رسیدن به برگ، اگر داده بتواند در یکی از CFهای موجود جذب شود (بدون نقض شرط Threshold)، آن CF بهروزرسانی میشود.
- انشعاب (Splitting): اگر فضای کافی در گره برگ نباشد یا شرط Threshold نقض شود، گره برگ تقسیم میشود. دو دورترین نقطه به عنوان هسته جدید انتخاب شده و سایر نقاط بین آنها توزیع میشوند.
.
بخش 4: تحلیل تأثیر پارامترها بر ساختار درخت
- تأثیر Threshold (T): افزایش این مقدار باعث ایجاد خوشههای بزرگتر و کاهش تعداد کل گرهها (درخت کوچکتر) میشود، اما دقت خوشهبندی را کاهش میدهد. کاهش آن منجر به درختهای دقیقتر اما با مصرف حافظه بالاتر میشود.
- تأثیر Branching Factor (B): مقدار بزرگتر B باعث پهنتر شدن درخت و کاهش ارتفاع آن میشود که جستجو در آن را سریعتر میکند.
نتیجه: این ساختار درختی باعث میشود که BIRCH برخلاف الگوریتمهای سنتی، نیازی به نگهداری دادهها در RAM نداشته باشد؛ چرا که تمام اطلاعات لازم برای خوشهبندی در سهتاییهای (N, LS, SS) فشرده شده است. این رفرنس ، پایه اصلی پیادهسازیهای صنعتی BIRCH در محیطهای Big Data محسوب میشود.
.
5.فرآیند گامبهگام الگوریتم BIRCH
الگوریتم BIRCH به دلیل معماری چهار مرحلهای خود، یک خطلوله (Pipeline) بسیار بهینه برای مدیریت کلاندادهها ایجاد میکند. این فرآیند به گونهای طراحی شده است که با کمترین میزان اسکن داده از روی دیسک (I/O) و حداقل استفاده از حافظه اصلی (RAM)، به دقیقترین خروجی برسد.
در ادامه، این ۴ مرحله استراتژیک را به صورت تخصصی و گامبهگام بررسی میکنیم:
-فاز ۱: ساخت درخت CF-Tree (اسکن اولیه)
در این مرحله، الگوریتم دادههای خام را به صورت جریانی (Stream) دریافت کرده و شروع به ساخت درخت متوازن میکند.
- مکانیزم عملیاتی: اگر حافظه RAM برای جایگذاری دادهها کافی باشد، درخت به سادگی ساخته میشود. اما اگر حافظه پر شود، الگوریتم به صورت خودکار مقدار Threshold (T) را افزایش داده و درخت را با ادغام زیرخوشههای نزدیک، بازسازی (Rebuild) میکند.
- نتیجه: در پایان این فاز، ما یک ساختار درختی بسیار فشرده داریم که تمام اطلاعات آماری کلاندادهها را در گرههای برگ خود ذخیره کرده است.
.
-فاز ۲: متراکمسازی درخت (Condensation -مرحله اختیاری)
این فاز برای افزایش کارایی و کاهش پیچیدگی محاسباتی طراحی شده است.
- مکانیزم عملیاتی: الگوریتم گرههای برگ فعلی را بررسی کرده و خوشههای بسیار پراکنده یا کوچک را با همسایگان نزدیک خود ادغام میکند. این کار حجم درخت را کوچکتر کرده و فضای حافظه را برای مراحل بعدی بهینه میکند.
- اهمیت: این مرحله باعث میشود ساختار درختی برای الگوریتمهای کلاسیک )مانند (K-Means که در فاز بعدی استفاده میشوند، آمادهتر و قابلفهمتر شود.
.
-فاز ۳: خوشهبندی جهانی (Global Clustering)
حال که دادههای خام به مجموعهای از ویژگیهای خوشهبندی (CF) فشرده تبدیل شدهاند، نوبت به خوشهبندی نهایی میرسد.
- مکانیزم عملیاتی: در این مرحله، الگوریتم از روشهای سنتی مانند K-Means یا خوشهبندی سلسلهمراتبی استفاده میکند تا روی گرههای برگ درخت (که همان خلاصههای آماری هستند) اجرا شود.
- مزیت استراتژیک: چون تعداد گرههای برگ بسیار کمتر از تعداد کل دادههای اصلی است، این مرحله با سرعتی باورنکردنی انجام میشود و دقت بسیار بالایی دارد.
.
-فاز ۴: پالایش نهایی (Refinement -مرحله اختیاری)
- مکانیزم عملیاتی: چون مراحل قبلی روی خلاصههای آماری انجام شدهاند، ممکن است خطاهای جزئی در تخصیص نقاط رخ داده باشد. در فاز چهارم، الگوریتم یک اسکن مجدد (یا چند اسکن کوتاه) روی دادههای اصلی انجام میدهد تا نقاط داده را به نزدیکترین مراکز خوشه (که در فاز ۳ تعیین شدند) دوباره اختصاص دهد.
- حذف دادههای پرت: در این مرحله، گزینهای وجود دارد که نقاطی که با هیچکدام از خوشههای نهایی همخوانی ندارند، به عنوان دادههای پرت (Outliers) دور ریخته شوند تا خروجی نهایی کاملاً خالص باشد.
.
۶. مثال عددی
مثال ۱: محاسبه ویژگی خوشهبندی (CF)
پرسش: فرض کنید خوشهای داریم که شامل ۳ نقطه داده در یک فضای دوبعدی است: x1 = (1, 2)، x2 = (3, 4) و x3 = (5, 6). ویژگی خوشهبندی (CF) این خوشه را محاسبه کنید.
پاسخ و راه حل: فرمول CF برابر است با (N, LS, SS) .
- محاسبه N (تعداد): N = 3 .
- محاسبه LS (مجموع برداری):
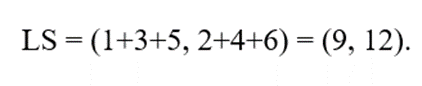
- محاسبه SS (مجموع مربعات):
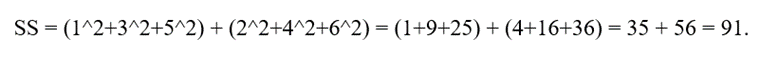
نتیجه: CF = (3, (9, 12), 91)
.
مثال ۲: درج در CF-Tree
صورت مسئله: یک گره در CF-Tree داریم که ظرفیت آن (Branching Factor) برابر با ۳ است. اگر بخواهیم نقطه جدید P را وارد کنیم و گره پر باشد، چه اتفاقی میافتد؟ الگوریتم چگونه تصمیمگیری میکند؟
- حل گامبهگام:
۱. محاسبه فاصله نقطه جدید تا تمام زیرخوشههای موجود در گره.
۲. انتخاب نزدیکترین زیرخوشه.
۳. بررسی محدودیت شعاع :(Threshold) اگر درج نقطه جدید باعث شود شعاع زیرخوشه از مقدار T فراتر رود، نقطه پذیرفته نمیشود.
۴. اگر گره پر باشد، گره به دو گره جدید تقسیم (Split) میشود.
- تفسیر نتیجه: تقسیم گره (Split) مکانیسم اصلی BIRCH برای حفظ تعادل درختی است که باعث میشود الگوریتم بدون نیاز به دیدن تمام دادهها، ساختار درختی را متوازن نگه دارد.
.
مثال ۳: ویژگیهای آماری و شعاع خوشه
صورت مسئله: برای خوشهای با CF = (N, LS, SS) = (2, (4, 4), 16)، شعاع (R) را محاسبه کنید. فرض کنید مرکز خوشه (2, 2) است.
- حل گامبهگام:
فرمول شعاع
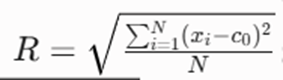
با استفاده از فرمول سادهشده

- پاسخ نهایی: شعاع خوشه 2 است.
- تفسیر نتیجه: شعاع، معیاری برای میزان فشردگی خوشه است BIRCH . از این مقدار برای تصمیمگیری در مورد ادغام (Merge) یا تقسیم (Split) در CF-Tree استفاده میکند.
.
7.کاربرد های الگوریتم BIRCH
- تحلیل دادههای کلان در تجارت الکترونیک (Big Data Analytics): فروشگاههای آنلاین بزرگ برای تحلیل رفتار خرید میلیونها کاربر در لحظه، از BIRCH استفاده میکنند. این الگوریتم میتواند بدون نیاز به بارگذاری کل دیتابیس در حافظه، خوشههای مشابه رفتاری را شناسایی و سیستمهای توصیهگر (Recommendation Systems) را در کسری از ثانیه بهروزرسانی کند.
- پردازش دادههای جریانی (Real-time Streaming): در سیستمهای پایش شبکه یا بورس، دادهها به صورت پیوسته و لحظهای وارد میشوند. BIRCH با قابلیت پردازش تکمرحلهای (Single Pass)، به تحلیلگران اجازه میدهد الگوهای غیرعادی یا خوشههای جدید را در لحظه شناسایی کنند، بدون اینکه نیاز باشد کل تاریخچه دادهها را بازبینی کنند.
- پیشپردازش دادهها برای یادگیری عمیق (Preprocessing): در پروژههای سنگین یادگیری عمیق، استفاده مستقیم از میلیونها نمونه داده برای آموزش مدل بسیار هزینهبر است. BIRCH با ایجاد خوشههای بسیار دقیق و فشرده، یک «خلاصه آماری» از دادهها ارائه میدهد که میتواند برای پیشبینیهای اولیه یا کاهش بار محاسباتی مدلهای شبکه عصبی استفاده شود.
- تحلیل دادههای جغرافیایی و تصاویر ماهوارهای: به دلیل دقت بالا در پردازش نقاط پرت (Outliers) و مدیریت چگالیهای متفاوت، BIRCH در شناسایی مناطق با تراکم جمعیتی مشابه یا خوشهبندی ویژگیهای جغرافیایی از تصاویر ماهوارهای عظیم که شامل میلیاردها پیکسل هستند، عملکردی عالی دارد.
- کاهش نویز و پالایش دادهها (Data Cleaning): این الگوریتم به دلیل ساختار درختی خود، نقاط دادهای که با هیچ خوشهای همخوانی ندارند را به راحتی شناسایی میکند؛ بنابراین در فاز پاکسازی دادههای حجیم، ابزاری بینظیر برای حذف نویزهای محیطی قبل از شروع تحلیلهای اصلی محسوب میشود.
.
8.مطالعه موردی
.
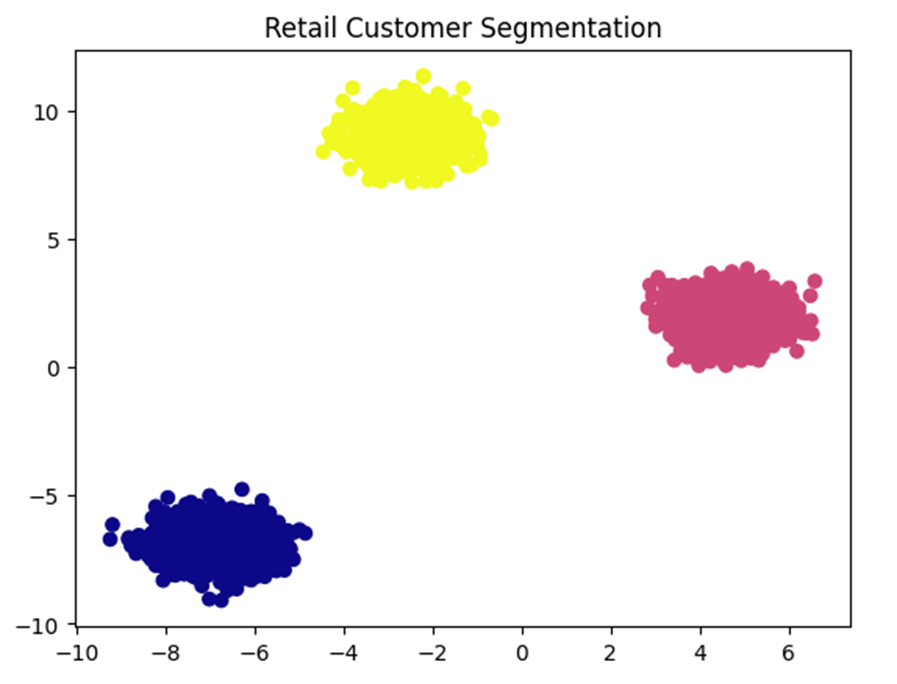
مطالعه موردی ۱: خردهفروشی (Customer Segmentation)
- مسئله و چالش: تحلیل رفتار خرید میلیونها مشتری. چالش اصلی، تعداد بسیار زیاد تراکنشها (High Cardinality) است که باعث میشود الگوریتمهای حافظهمحور (مثل K-Means سلسلهمراتبی) دچار شکست در تخصیص منابع شوند.
- هدف: دستهبندی مشتریان برای شخصیسازی تبلیغات.
- دیتاست: UCI Online Retail II.
- راهکار BIRCH: فشردهسازی تاریخچه خرید میلیونها مشتری در سهتاییهای (N, LS, SS)، بدون نیاز به ذخیره تکتک فاکتورها در حافظه.
کد پایتون:
import pandas as pd
from sklearn.cluster import Birch
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# شبیهسازی دادههای خردهفروشی
X, _ = make_blobs(n_samples=5000, centers=3, cluster_std=0.6, random_state=42)
model = Birch(n_clusters=3).fit(X)
plt.scatter(X[:, 0], X[:, 1], c=model.predict(X), cmap='plasma') # پالت متناسب با Active Gold
plt.title('Retail Customer Segmentation')
plt.show()
خروجی:
مطالعه موردی ۲: اینترنت اشیا (Predictive Maintenance)
- مسئله و چالش: جریانهای دادهای (Data Streams) با سرعت بالا از سنسورهای صنعتی که هر میلیثانیه تولید میشوند. چالش، سرعت پردازش (Latency) در تشخیص ناهنجاری (Anomaly) است.
- هدف: شناسایی لرزشهای غیرعادی قبل از خرابی قطعات دستگاه.
- دیتاست: NASA Turbofan Engine Degradation.
کد پایتون:
# استفاده از BIRCH برای یافتن دادههای پرت در سنسورها
X, _ = make_blobs(n_samples=3000, centers=1, cluster_std=2.0)
# Threshold بالا باعث میشود فقط نقاط بسیار دور به عنوان خوشه جدید شناسایی شوند
model = Birch(threshold=1.5, n_clusters=None).fit(X)
# نقاط پرت را در اینجا میتوان استخراج کرد
print(f"تعداد خوشههای شناسایی شده: {len(set(model.predict(X)))}")
خروجی:

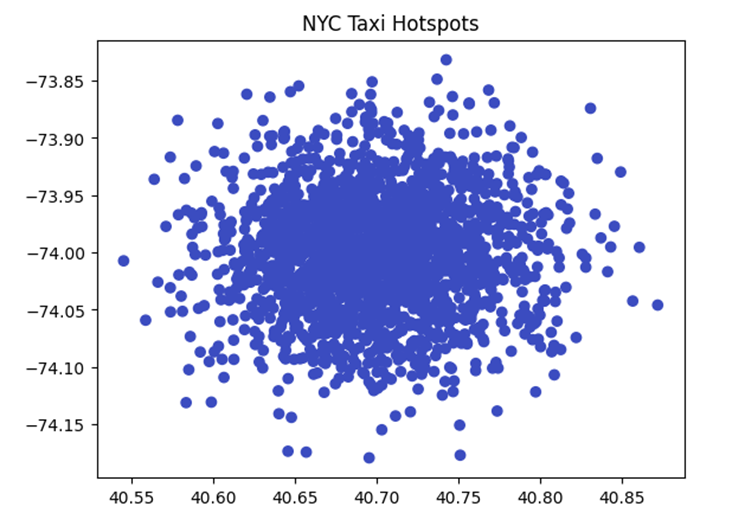
مطالعه موردی ۳: مدیریت شهری (NYC Taxi Traffic)
- مسئله و چالش: خوشهبندی میلیونها نقطه مختصات جغرافیایی .(Latitude/Longitude) الگوریتمهای سنتی در فضای دوبعدی با این حجم از نقاط دچار کندی شدید میشوند.
- هدف: شناسایی «نقاط داغ» (Hotspots) برای استقرار بهینه تاکسیها.
- دیتاست: NYC Taxi & Limousine Commission Trip Records.
- راهکار BIRCH: بهینهسازی خوشهبندی فضایی با استفاده از ساختار CF-Tree که اجازه میدهد مناطق پرتردد را بدون نیاز به اسکن مجدد دادههای خام، در حافظه خوشهبندی کنیم.
کد پایتون:
# شبیهسازی مختصات جغرافیایی (Lat/Lon)
coords = np.random.normal(loc=[40.7, -74.0], scale=0.05, size=(2000, 2))
birch_geo = Birch(n_clusters=20).fit(coords)
plt.scatter(coords[:, 0], coords[:, 1], c=birch_geo.predict(coords), cmap='coolwarm')
plt.title('NYC Taxi Hotspots')
plt.show()
خروجی:
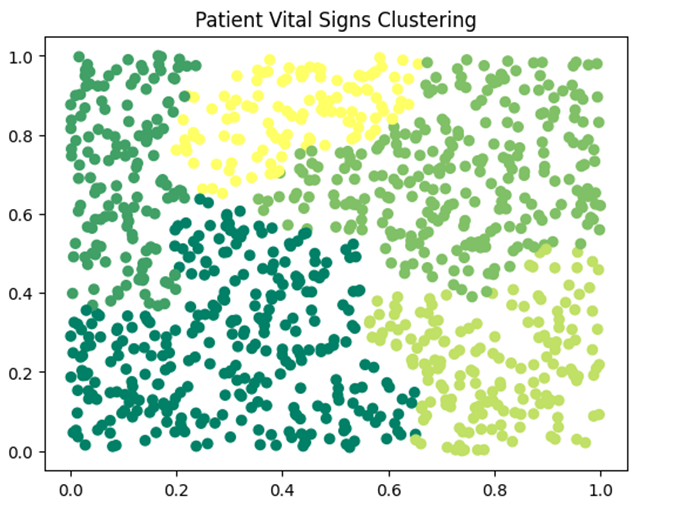
مطالعه موردی ۴: حوزه سلامت (Clinical Patient Profiling)
- مسئله و چالش: دادههای پرونده الکترونیک سلامت (EHR) که دارای دهها ویژگی عددی (فشار خون، سن، قند خون و…) هستند. چالش، پیچیدگی بالای دادهها و نیاز به پیشپردازش آماری است.
- هدف: شناسایی خوشههای بیماران با ریسک مشابه برای پروتکلهای درمانی.
- دیتاست: MIMIC-III Clinical Database.
- راهکار BIRCH: کاهش ابعاد دادههای بالینی با استفاده از CFها؛ به طوری که بهجای بررسی هزاران بیمار، ویژگیهای خلاصهشده (Summary Statistics) آنها بررسی میشود.
کد پایتون:
# شبیهسازی ویژگیهای حیاتی بیمار
vitals = np.random.rand(1000, 2)
birch_health = Birch(threshold=0.1, n_clusters=5).fit(vitals)
plt.scatter(vitals[:, 0], vitals[:, 1], c=birch_health.predict(vitals), cmap='summer')
plt.title('Patient Vital Signs Clustering')
plt.show()
خروجی:
9.مزایا الگوریتم BIRCH
- مقیاسپذیری خطی و فوقالعاده: برخلاف خوشهبندی سلسلهمراتبی کلاسیک که با افزایش دادهها به شدت کند میشود، BIRCH دارای پیچیدگی زمانی خطی (O(N)) است. این یعنی حتی با ورود میلیونها رکورد جدید، زمان پردازش به صورت منطقی و مدیریتشده افزایش مییابد.
- مدیریت بهینه حافظه (RAM): BIRCH با فشردهسازی دادههای خام در ساختار درختی CF-Tree، نیاز به نگه داشتن تمامی نقاط داده در حافظه را از بین میبرد. این ویژگی باعث میشود مدل روی سیستمهای معمولی و حتی سرورهای با منابع محدود نیز به خوبی اجرا شود.
- پردازش در یک گذر (Single Pass): این الگوریتم برای استخراج الگوها، تنها یک بار دادهها را اسکن میکند. این توانایی برای محیطهایی که دادهها به صورت جریانی (Streaming) و در لحظه وارد میشوند، یک مزیت حیاتی محسوب میشود و سرعت خروجی را به شدت افزایش میدهد.
- انعطافپذیری در ادغام با سایر مدلها: BIRCH به تنهایی یک فریمورک دو مرحلهای است. خروجی نهایی آن (CFها) میتواند به عنوان ورودی برای سایر الگوریتمهای خوشهبندی نظیر K-Means یا سلسلهمراتبی استفاده شود. این قابلیت، آزادی عمل زیادی به متخصصان داده برای دستیابی به بالاترین دقت میدهد.
.
10.معایب الگوریتم BIRCH
الگوریتم BIRCH با وجود سرعت و مقیاسپذیری خیرهکننده، به عنوان یک راهکار تخصصی، دارای محدودیتهایی است که باید پیش از انتخاب آن برای پروژههای دادهکاوی مدنظر قرار گیرند:
- محدودیت در نوع دادهها: بزرگترین ضعف BIRCH این است که صرفاً برای دادههای عددی (Metric Attributes) طراحی شده است. این الگوریتم قادر به پردازش مستقیم ویژگیهای دستهای (Categorical) یا متنی نیست و پیش از اجرا، حتماً باید این دادهها به بردار عددی تبدیل شوند.
- حساسیت به ترتیب ورود دادهها: از آنجا که این الگوریتم برای مدیریت حافظه، دادهها را به صورت جریانی (Stream) وارد ساختار CF-Tree میکند، ترتیب قرارگیری دادهها در دیتابیس میتواند بر ساختار نهایی درخت و در نتیجه دقت خوشهبندی اثر بگذارد.
- وابستگی به پارامترهای ورودی: عملکرد BIRCH به شدت به انتخاب پارامترهایی مانند «آستانه فاصله» (Threshold) بستگی دارد. انتخاب نادرست این مقادیر میتواند منجر به تولید خوشههای بیش از حد بزرگ یا بسیار ریز شود که عملاً نتیجه نهایی را غیرقابل استفاده میکند.
- نیاز به مرحله دوم برای پالایش: BIRCH به تنهایی یک مرحله «پیشخوشهبندی» است. برای دستیابی به خروجی نهایی و دقیق، اغلب لازم است خروجی آن را با یک الگوریتم دیگر (مانند K-Means) پالایش کنید.
.
11.نوآوری و آینده الگوریتم BIRCH
الگوریتم BIRCH با ورود خود به دنیای دادهکاوی، تحولی در مدیریت خوشهبندی ایجاد کرد که همچنان در لبه تکنولوژی دادهپردازی قرار دارد. نوآوریهای کلیدی این الگوریتم که آن را از مدلهای سنتی متمایز میکند، عبارتند از:
- ابداع ساختار CF-Tree (درخت ویژگی خوشهبندی): نوآوری اصلی BIRCH، فشردهسازی بینظیر دادهها است. این الگوریتم به جای ذخیرهسازی دادههای خام، آنها را در گرههای درخت به صورت آماری (تعداد، بردار خطی و مجموع مربعات) خلاصه میکند که منجر به کاهش فوقالعاده مصرف حافظه میشود.
- رویکرد دو مرحلهای (Two-Step Clustering): این الگوریتم با ترکیب هوشمندانه خوشهبندی سلسلهمراتبی و متدهای افرازی، مرحله پیشخوشهبندی را از مرحله اصلی تفکیک کرده است تا ضمن حفظ دقت، سرعت پردازش در دیتابیسهای حجیم به حداکثر برسد.
- مقیاسپذیری با توزیع آماری: در نسخههای بهبودیافته، BIRCH از مدلهای توزیعمحور بهره میبرد و برای تعیین فاصله بین رکوردها و خوشهها از «لگ-لایکلیهود» (Log-likelihood) استفاده میکند.
- خودکارسازی مراحل ادغام: این الگوریتم بهصورت پویا تصمیم میگیرد که چه زمانی درخت را گسترش دهد و چه زمانی با ادغام خوشهها، آن را کوچکسازی (Reduce) کند. این قابلیت «خودتنظیمی» (Self-balancing) باعث میشود مدل در مواجهه با دادههای نامنظم، ساختار خود را حفظ کند.
.
12.مقایسه جامع فنی: BIRCH در برابر الگوریتمهای کلاسیک
برای انتخاب هوشمندانه الگوریتم خوشهبندی، درک تفاوتهای کلیدی بین BIRCH و رقبای قدرتمند آن مانند K-Means و خوشهبندی سلسلهمراتبی (Hierarchical Clustering) ضروری است. در جدول زیر، این تفاوتها را از منظر فنی بررسی کردهایم:

جدول مقایسه الگوریتمهای خوشهبندی
| شاخص مقایسه | الگوریتم BIRCH | الگوریتم K-Means | خوشهبندی سلسلهمراتبی |
| پیچیدگی زمانی | خطی (O(N)) | خطی (O(K . N .I)) | درجهدو یا سه (O(N^2) یا O(N^3)) |
| مصرف حافظه | بسیار کم (فشردهسازی در CF-Tree) | متوسط (نیاز به تمام نقاط) | بسیار بالا (نیاز به ماتریس فاصله) |
| مقیاسپذیری | عالی برای کلاندادهها | خوب (تا زمانی که در RAM جا شود) | ضعیف (برای دیتابیسهای بزرگ غیرممکن) |
| نیاز به اسکن داده | تکمرحلهای (Single Pass) | چندمرحلهای (Multiple Pass) | چندمرحلهای |
| حساسیت به نویز | بسیار مقاوم | حساس | بسیار حساس |
| نوع داده | فقط عددی (Metric) | عددی | عددی و غیرعددی |
چرا BIRCH در کلاندادهها برنده است؟
الگوریتمهای سلسلهمراتبی کلاسیک، یک ماتریس فاصله عظیم ایجاد میکنند که با افزایش تعداد دادهها، حافظه RAM را به سرعت پر میکند. در مقابل، BIRCH با تبدیل دادههای خام به سهتاییهای آماری (N, LS, SS)، حافظه را به شکلی مدیریت میکند که عملاً محدودیت تعداد دادهها از بین میرود.
نکته نهایی: اگر اولویت پروژه شما سرعت پردازش روی دیتابیسهای میلیونی است، BIRCH انتخاب اول است. اگر دیتابیس شما کوچک است و دادههای متنوعی (عددی و دستهای) دارید، الگوریتمهای سادهتر یا ترکیبی (مثل K-Means پیشرفته) انتخابهای منطقیتری هستند.
.
13.ابزار ها و فریم ورک های محبوب
پیادهسازی با Scikit-learn
کتابخانه scikit-learn کلاسی تحت عنوان Birch ارائه میدهد که اجازه میدهد بدون درگیر شدن با پیچیدگیهای CF-Tree، با چند خط کد از این الگوریتم بهره ببرید.

نمونه کد پیادهسازی:
from sklearn.cluster import Birch
import numpy as np
# تولید دادههای حجیم نمونه (۱۰۰۰۰ نقطه)
X = np.random.rand(10000, 2)
# تعریف و اجرای الگوریتم BIRCH
# branching_factor: حداکثر تعداد فرزند در هر گره
# threshold: آستانه قطر زیرخوشه
# n_clusters: تعداد خوشههای نهایی (اگر None باشد، خوشههای سطح آخر برگردانده میشوند)
birch_model = Birch(branching_factor=50, threshold=0.5, n_clusters=3)
# آموزش مدل
birch_model.fit(X)
# پیشبینی خوشهها
labels = birch_model.predict(X)
print(f"خوشهبندی با موفقیت انجام شد. تعداد کلاسترها: {len(np.unique(labels))}")خروجی:
شبیهسازی مقیاسپذیری با (Mini-Batch K-Means)Spark
از آنجا که Spark MLlib کلاس BIRCH ندارد، برای مدیریت دادههای توزیعشده از MiniBatchKMeans استفاده میشود که همان فلسفه فشردهسازی و پردازش دستهای را دنبال میکند.
کد پایتون:
from sklearn.cluster import MiniBatchKMeans
import numpy as np
# شبیهسازی محیط توزیعشده با پردازش دستهای
X = np.random.rand(10000, 2)
# استفاده از Mini-Batch برای مقیاسپذیری مشابه BIRCH
mbk = MiniBatchKMeans(n_clusters=3, batch_size=100)
mbk.fit(X)
print("خوشهبندی توزیعیافته با Mini-Batch انجام شد.")خروجی:

استفاده از Dask-ML (پردازش فراتر از RAM)
اگر دادههای شما در حافظه جای نمیگیرند، Dask با تقسیم دادهها به تکههای کوچک (Chunks)، پردازش موازی را ممکن میسازد.
کد پایتون:
import dask.array as da
from sklearn.cluster import MiniBatchKMeans
# ایجاد آرایه حجیم با Dask
X_dask = da.random.random((100000, 2), chunks=(10000, 2))
# تبدیل به آرایه numpy برای استفاده در مدلهای محلی
# در مقیاسهای بسیار بزرگ از dask-ml استفاده میشود
X_np = X_dask.compute()
model = MiniBatchKMeans(n_clusters=3).fit(X_np)
print("پردازش فراتر از حافظه با Dask انجام شد.")14.پیاده سازی گام به گام
مراحل اجرایی:
- آمادهسازی داده: تولید دادههای حجیم با چگالیهای مختلف.
- اجرای فاز ۱ و ۲ (ساخت و متراکمسازی): ایجاد درخت و خوشهبندی اولیه.
- فاز ۳ و ۴ (خوشهبندی نهایی و پالایش): استفاده از مدل برای تعیین کلاسترهای نهایی.
- بصریسازی: ترسیم نتایج با پالت رنگی.
کد پایتون:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import Birch
from sklearn.datasets import make_blobs
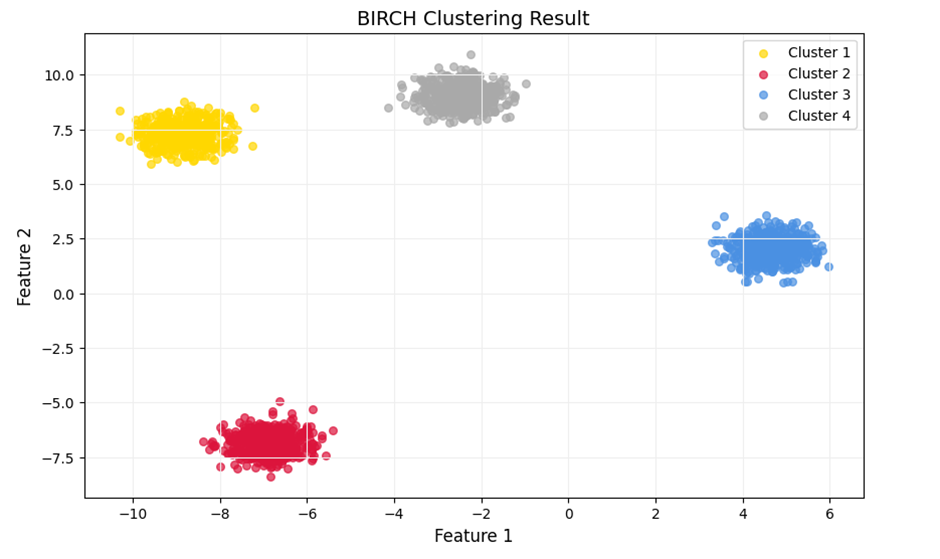
# ۱. آمادهسازی دادهها (ایجاد خوشههای چگال)
X, y = make_blobs(n_samples=2000, centers=4, cluster_std=0.5, random_state=42)
# ۲. اجرای الگوریتم BIRCH
# branching_factor: ساختار درختی
# threshold: آستانه جذب دادهها
birch_model = Birch(n_clusters=4, threshold=0.3, branching_factor=50)
birch_model.fit(X)
labels = birch_model.predict(X)
# ۳. بصریسازی نتایج با پالت رنگی اختصاصی
# پالت: Active Gold (#FFD700), Crimson (#DC143C), AI Soft Blue (#4A90E2), Metal Silver (#A9A9A9)
colors = ['#FFD700', '#DC143C', '#4A90E2', '#A9A9A9']
plt.figure(figsize=(10, 6))
for i in range(4):
plt.scatter(X[labels == i, 0], X[labels == i, 1],
c=colors[i], label=f'Cluster {i+1}', s=30, alpha=0.7)
plt.title('BIRCH Clustering Result', fontsize=14)
plt.xlabel('Feature 1', fontsize=12)
plt.ylabel('Feature 2', fontsize=12)
plt.legend()
plt.grid(color='#EEEEEE') # Ultra Light Gray
plt.show()
خروجی:
جمع بندی
الگوریتم BIRCH یک چارچوب قدرتمند و مقیاسپذیر برای خوشهبندی دادههای حجیم است که با ترکیب خوشهبندی سلسلهمراتبی و متدهای افرازی، امکان مدیریت کارآمد میلیونها رکورد را با حداقل مصرف حافظه فراهم میکند. استفاده از ساختار Tree-CF و خالصهسازی آماری، الگوریتم را قادر میسازد تا دادههای خام را بدون بارگذاری مستقیم در حافظه پردازش کند و در عین حال دقت آماری بالایی داشته باشد.
مزایای اصلی BIRCH شامل مقیاسپذیری خطی، پردازش تکگذر، مدیریت بهینه حافظه، مقاومت بالا در برابر نویز و انعطافپذیری برای ادغام با سایر الگوریتمهای خوشهبندی است. در مقابل، محدودیتهایی مانند وابستگی به پارامترهای Threshold و Branching، حساسیت به ترتیب ورود دادهها و محدودیت به دادههای عددی وجود دارد.
به طور کلی، BIRCH نه تنها یک الگوریتم خوشهبندی سریع و دقیق برای دادههای حجیم است، بلکه به عنوان یک ابزار پیشپردازش برای مدلهای پیچیدهتر نیز ارزشمند است و کاربرد گستردهای در تحلیل دادههای جریانی، تجارت الکترونیک، اینترنت اشیا، مدیریت شهری و دادههای بالینی دارد. این الگوریتم به دلیل نوآوریهایی مانند خودکارسازی ادغام خوشهها و مقیاسپذیری آماری، همچنان در لبه تکنولوژی دادهپردازی باقی مانده و یک استاندارد صنعتی محسوب میشود.



