

مقدمه
آموزش یک شبکه عصبی به معماری مناسب یا دادههای باکیفیت وابسته نیست. به این بستگی دارد که مدل چگونه از خطاهای خود یاد میگیرد. این وظیفه بر عهده الگوریتمهایی به نام بهینهسازها (Optimizers) است؛ ابزارهایی که مسیر حرکت مدل در فضای پارامترها را هدایت میکنند و تعیین میکنند وزنها و بایاسها با چه سرعت و الگویی بهروزرسانی شوند.
انتخاب نادرست بهینهساز میتواند منجر به همگرایی کند، نوسان شدید یا گیر افتادن در کمینههای محلی شود؛ در حالی که انتخاب درست، یادگیری را پایدارتر، سریعتر و قابلاعتمادتر میکند. به همین دلیل، بهینهسازها نقشی کلیدی در عملکرد نهایی مدلهای یادگیری ماشین و یادگیری عمیق دارند.
در این مقاله، بهینهسازهای پرکاربرد شبکههای عصبی از دیدگاه مفهومی و عملی بررسی میشوند: از گرادیان کاهشی ساده تا روشهای پیشرفته مانند Momentum، RMSProp و Adam. هدف این است که خواننده با درک منطق هر روش، بتواند بهینهساز مناسب را متناسب با مسئلۀ خود و ویژگیهای داده انتخاب کند.
بهینهساز (Optimizer) چیست؟
در یادگیری عمیق، بهینهساز عنصری حیاتی است که پارامترهای یک شبکه عصبی را در طول فرآیند آموزش تنظیم دقیق (Fine-tune) میکند. نقش اصلی آن به حداقل رساندن خطا یا تابع زیان (Loss Function) مدل است که در نهایت منجر به ارتقای عملکرد میشود. الگوریتمهای بهینهسازی مختلف که با نام بهینهساز شناخته میشوند، از استراتژیهای متفاوتی برای همگرایی کارآمد به سمت مقادیر بهینه پارامترها جهت بهبود پیشبینیها استفاده میکنند.
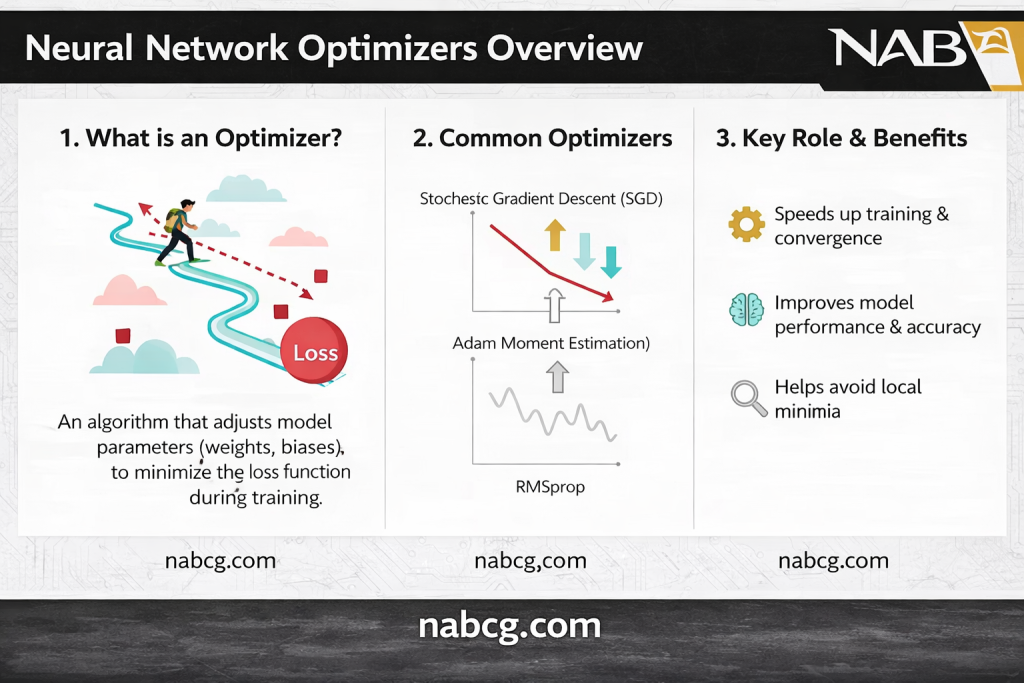
بهینهسازها در یادگیری عمیق چه هستند؟
بهینهسازها در یادگیری عمیق بسیار حیاتیاند: الگوریتمهایی که پارامترهای مدل را در طول آموزش بهصورت پویا تنظیم میکنند تا تابع زیانِ از پیش تعریفشده را به حداقل برسانند. این الگوریتمها با اصلاح مکرر وزنها و بایاسها بر اساس بازخورد دادهها، فرآیند یادگیری را تسهیل میکنند. مهمترین بهینهسازهای کاربردی عبارتند از:
- نزول گرادیان تصادفی (SGD)
- Adam
- RMSprop
هر یک از این موارد به قوانین بهروزرسانی، نرخ یادگیری و استراتژیهای مومنتوم (Momentum) متمایزی مجهز هستند که همگی در راستای هدف نهایی یعنی کشف و همگرایی بر پارامترهای بهینه مدل و در نتیجه ارتقای عملکرد کلی عمل میکنند.
انتخاب بهینهساز مناسب
الگوریتمهای بهینهساز برای ارتقای عملکرد مدلهای یادگیری عمیق از طریق بهبود دقت و سرعت آموزش ضروری هستند. آنها وزنهای شبکه عصبی و نرخ یادگیری را در هر دور آموزشی (Epoch) تنظیم میکنند تا تابع زیان به حداقل برسد. با توجه به اینکه مدلهای یادگیری عمیق اغلب میلیونها پارامتر دارند، انتخاب الگوریتم بهینهسازی صحیح برای آموزش مؤثر بسیار حیاتی است.
نکاتی برای انتخاب بهینهساز:
- بهینهسازها وزنها و نرخ یادگیری را در مدلهای یادگیری ماشین تنظیم میکنند.
- انتخاب بهینهساز به کاربرد و مسئله خاص شما بستگی دارد.
- انتخاب تصادفی بهینهسازها در مواجهه با مجموعهدادههای بزرگ میتواند باعث اتلاف وقت شود.
- زمانی که با صدها گیگابایت داده کار میکنید، اجرای تنها یک اپوک (Epoch) میتواند بسیار زمانبر باشد.
- این راهنما بهینهسازهای مختلف یادگیری عمیق از جمله نزول گرادیان و موارد دیگر را پوشش میدهد.
- بهینهسازهای مورد بحث عبارتند از: نزول گرادیان تصادفی (SGD)، نزول گرادیان مینی-بچ (Mini-Batch)، Adagrad، RMSProp، AdaDelta و. Adam
- در پایان این مقاله، خوانندگان میتوانند بهینهسازهای مختلف را مقایسه کرده و روند کار آنها را درک کنند.
حالا بیایید هر یک از این بهینهسازها را بررسی کنیم.
الگوریتمهای بهینهسازی: قلب تپنده یادگیری عمیق
در یادگیری عمیق، هدف نهایی ما رسیدن به کمترین میزان خطا است. بهینهساز (Optimizer) همان راننده هوشمندی است که با تنظیم دقیق وزنها و بایاسها، شبکه را به سمت این هدف هدایت میکند.
نزول گرادیان(Gradient Descent): از قله تا دره
تصور کنید توپی را در لبه یک کاسه رها کردهاید. توپ طبیعتاً در جهت تندترین شیب حرکت میکند تا در نهایت در ته کاسه آرام بگیرد. در دنیای ریاضیات، گرادیان همان نیرویی است که جهت تندترین شیب را به توپ نشان میدهد تا به کف کاسه (نقطه بهینه) برسد.
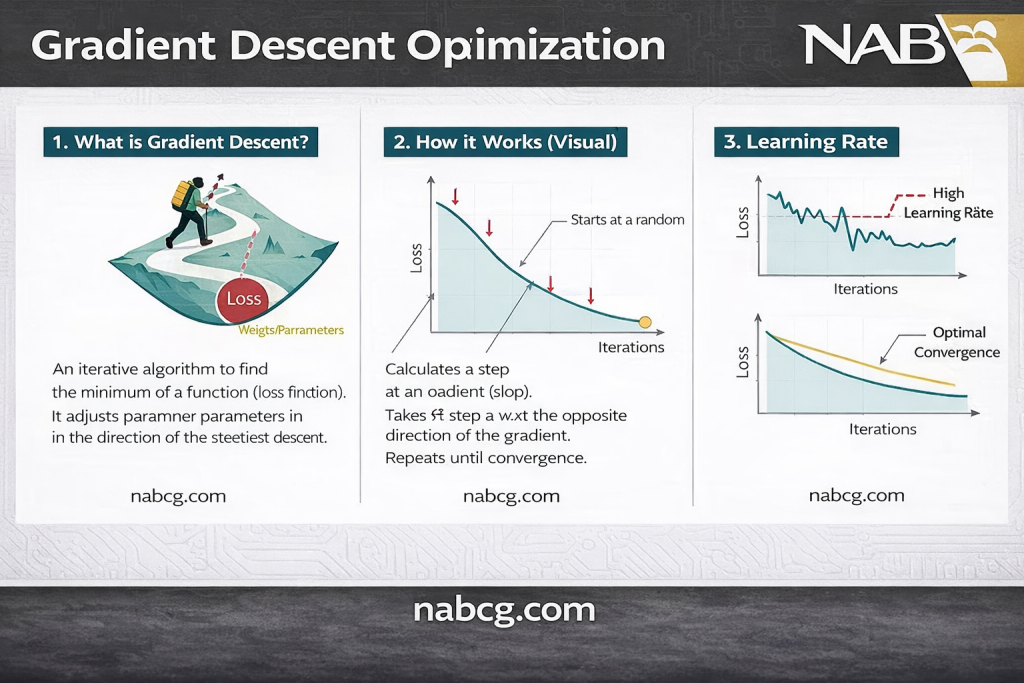
گامهای حیاتی در این سفر:
- مقداردهی اولیه: شروع کار با پارامترهای تصادفی.
- محاسبه گرادیان: محاسبه مشتق تابع خطا نسبت به پارامترها.
- بهروزرسانی: حرکت در جهت مخالف گرادیان (به سمت پایین) با مقیاسی به نام نرخ یادگیری.
فرمول:
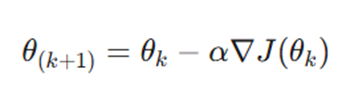
- θ (k+1): بردار پارامترهای بهروزرسانی شده در تکرار بعدی.
- θk: بردار پارامترهای فعلی در تکرار فعلی.
- α: نرخ یادگیری (Learning Rate)؛ یک عدد مثبت که اندازه هر قدم را تعیین میکند.
.
شرایط پیشرفته برای گامهای هوشمندتر
گاهی اوقات یک حرکت ساده کافی نیست و ما نیاز به تضمینهایی برای اندازه قدم خود داریم:
- شرط آرمیجو-گلدشتاین(Armijo Goldstein): این نسخه اطمینان حاصل میکند که اندازه گام (α) به قدری بزرگ باشد که تابع هدف را به شکلی مؤثر کاهش دهد.
شرط آزادسازی کامل آرمیجو(Full Relaxation): این مدل پا را فراتر گذاشته و از مشتقات دوم یا ماتریس هسین (Hessian Matrix) برای تعیین اندازه گام بسیار بهینهتر استفاده میکند.
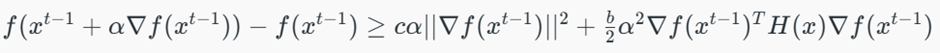
انواع نزول گرادیان بر اساس حجم داده
.
الف) نزول گرادیان تصادفی (Stochastic Gradient Descent – SGD)
وقتی با میلیونها داده سر و کار داریم، محاسبه گرادیان برای تکتک دادهها قبل از هر بهروزرسانی (روش Batch)، به شدت کند و غیرممکن است. در روش SGD، پارامترهای مدل بلافاصله پس از مشاهده هر یک نمونه آموزشی بهروزرسانی میشوند.
- مزایا:
- بهرهوری حافظه: تنها یک نمونه در هر لحظه در حافظه بارگذاری میشود که برای سیستمهای با منابع محدود عالی است.
- فرار از تلهها: به دلیل نوسانات زیاد، این الگوریتم میتواند از مینیممهای محلی بد (نواحی که مدل در آنها متوقف میشود اما بهینه نیستند) بپرد و به سمت نقاط بهتر حرکت کند.
- معایب:
- مسیر پرنوسان: به دلیل اینکه هر داده ممکن است جهت متفاوتی را پیشنهاد دهد، مسیر حرکت به سمت هدف بسیار زیگزاگی و نویزی است.
- همگرایی کند: برای رسیدن به نقطه پایانی دقیق، به تکرارها و زمان محاسباتی کل بیشتری نسبت به روشهای دیگر نیاز دارد.
.
ب) نزول گرادیان مینی-بچ (Mini-Batch Gradient Descent)
این روش نقطه طلایی بهینهسازی و محبوبترین روش در پروژههای واقعی است. مینی-بچ ترکیبی هوشمندانه از دقت روش کلنگر (Batch) و سرعت روش تکعضوی (SGD) است؛ به این صورت که دادهها به دستههای کوچکی (معمولاً بین ۳۲ تا ۵۱۲ نمونه) تقسیم میشوند.
- مکانیزم اجرا:
- انتخاب یک دسته (Batch) کوچک از دادهها.
- محاسبه میانگین گرادیان برای آن دسته.
- بهروزرسانی وزنهای مدل بر اساس آن میانگین.
- مزایا:
- تعادل سرعت و دقت: نوسانات کمتری نسبت به SGD دارد و سریعتر از روش Batch به نتیجه میرسد.
- استفاده از توان پردازشی: این روش به خوبی از قابلیت پردازش موازی در کارتهای گرافیک (GPU) استفاده میکند.
- پایداری بیشتر: مسیر حرکت به سمت هدف هموارتر است و شانس رسیدن به دقت نهایی بالاتر را افزایش میدهد.
- معایب:
- نیاز به تنظیم ابرپارامتر: شما باید اندازه مناسب برای هر دسته (Batch Size) را پیدا کنید که خود یک چالش فنی است.
.
ج) SGD با مومنتوم (Momentum)؛ قدرت گلوله برفی
مومنتوم با صاف کردن نوسانات نویزی SGD، به همگرایی سرعت میبخشد. این الگوریتم مانند یک گلوله برفی است که از تپه پایین میآید و با حفظ سرعت قبلی، شتاب میگیرد.
فرمول:
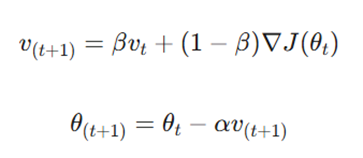
- vt: تکانه یا سرعت انباشته شده در زمان. t
- β: ضریب مومتوم (تعیینکننده میزان حفظ سرعت قبلی).
.
مثال عددی: کالبدشکافی یک گام هوشمند در نزول گرادیان
تصور کنید ما در حال آموزش یک نورون برای تشخیص یک الگوی ساده هستیم و در حال حاضر میخواهیم وزن آن (θ) را اصلاح کنیم تا خطای مدل کاهش یابد. این مثال به شما نشان میدهد که چگونه ریاضیات در کسری از ثانیه، مسیر بهینه را پیدا میکند.
وضعیت فعلی سیستم (نقطه شروع):

تحلیل استراتژیک گرادیان: عدد مثبت 2.0 نشاندهنده یک شیب صعودی است؛ یعنی با افزایش وزن، خطا نیز بیشتر میشود. الگوریتم با درک این موضوع، فرمان حرکت در خلاف جهت (به سمت اعداد کوچکتر) را صادر میکند.
عملیات بهروزرسانی در دو مرحله عملیاتی:
مرحله اول: محاسبه مقدار جابهجایی (Step Size)
در این مرحله مشخص میکنیم که با توجه به تندی شیب و نرخ یادگیری، دقیقاً چه مقدار باید جابهجا شویم:
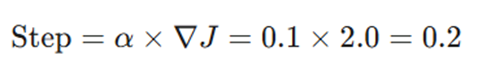
مرحله دوم: تعیین موقعیت جدید (Update)
حالا از موقعیت فعلی، به اندازه گام محاسبه شده عقبنشینی میکنیم تا به نقطه مطلوبتری در قعر دره برسیم:
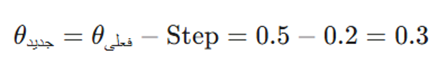
تفسیر و نتیجهگیری عملیاتی:
در این گام، مدل با موفقیت متوجه شد که با کاهش وزن از 0.5 به 0.3، هزینه یا همان میزان خطای سیستم کاهش مییابد. این فرآیند به صورت زنجیروار و تکرارشونده ادامه مییابد:
- در تکرار بعدی، مدل دوباره گرادیان را در نقطه جدید (0.3) محاسبه میکند.
- اگر گرادیان همچنان مثبت باشد (مثلاً 0.5)، باز هم وزن را کمی کاهش میدهد.
- این چرخه تا زمانی ادامه مییابد که گرادیان به صفر نزدیک شود؛ این یعنی ما به کف دره (نقطه بهینه) رسیدهایم و مدل دقیقترین حالت خود را پیدا کرده است.
.
بهینهسازهای تطبیقی (Adaptive Optimizers)

۱. آداگراد(AdaGrad): متخصص دادههای پراکنده
آداگراد نرخ یادگیری را بر اساس اطلاعات تاریخی گرادیانها برای هر پارامتر بهطور جداگانه تنظیم میکند. در واقع، پارامترهایی که تغییرات زیادی دارند، نرخ یادگیری کوچکتری دریافت میکنند و پارامترهایی که به ندرت تغییر میکنند (ویژگیهای پراکنده یا Sparse)، با نرخ یادگیری بزرگتری بهروز میشوند.
- فرمول:
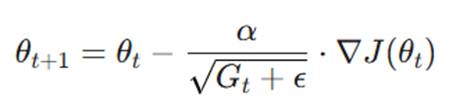
- Gt: مجموع مجذور گرادیانهای قبلی.
- ε: عدد بسیار کوچک برای جلوگیری از تقسیم بر صفر.
- مزایا: نیاز به تنظیم دستی نرخ یادگیری را از بین میبرد و برای دادههای دارای ویژگیهای کمیاب عالی است.
- معایب: نرخ یادگیری به صورت تهاجمی و یکنواخت کاهش مییابد؛ تا جایی که ممکن است یادگیری مدل کاملاً متوقف شود.
.
۲. آراماسپراپ(RMSProp): متعادلکننده هوشمند
این الگوریتم برای رفع نقص آداگراد طراحی شده است. به جای جمع کردن تمام گرادیانهای قبلی، RMSProp از یک میانگین متحرک نمایی استفاده میکند تا از کاهش شدید و زودهنگام نرخ یادگیری جلوگیری کند.
- فرمول:
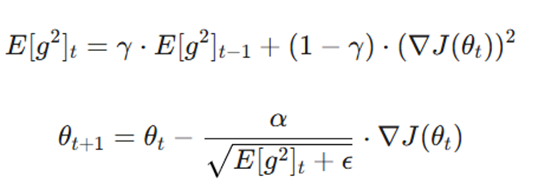
- γ: نرخ زوال (Decay Rate) یا فاکتور فراموشی.
- مثال: اگر پارامتری مثل «رنگ» در مدل طبقهبندی ماهیها باعث نوسان زیاد خطا شود، RMSProp سرعت بهروزرسانی آن را جریمه میکند تا مدل بتواند روی ویژگیهای پایدارتر تمرکز کند.
.
۳. آدام (Adam): پادشاه بهینهسازها
آدام (Adaptive Moment Estimation) ترکیبی از قدرت مومنتوم و RMSProp است. این الگوریتم هم میانگین گرادیانها (ممان اول) و هم واریانس آنها (ممان دوم) را محاسبه میکند تا نرخ یادگیری را برای هر وزن به صورت کاملاً پویا تنظیم کند.
- فرمولهای کلیدی:
- بهروزرسانی ممان اول (میانگین) mt = β1 mt-1 + (1- β1) ∇J(θt):
- بهروزرسانی ممان دوم (واریانس) vt = β2 vt-1 + (1- β2) (∇J(θt))^2:
- اصلاح سوگیری (Bias Correction) برای گامهای اولیه.
- مزایا: همگرایی بسیار سریع، نیاز به حافظه کم و تنظیمات حداقلی؛ آدام امروزه به عنوان بهینهساز پیشفرض در اکثر مقالات هوش مصنوعی توصیه میشود.
.
مثال عددی: محاسبات بهینهساز آدام (Adam)
تصور کنید میخواهیم یک وزن خاص را در مرحله اول آموزش بهروز کنیم.
دادههای اولیه:
- وزن فعلی 1.0 : (θt)
- نرخ یادگیری 0.01: (α)
- گرادیان فعلی 0.5: (gt)
- β1= 0.9 و β2= 0.999 (مقادیر استاندارد)
- مقادیر قبلی ممانها (mt-1 و vt-1) :0
۱: محاسبه ممانها
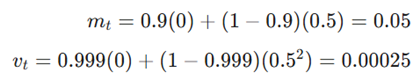
۲: اصلاح سوگیری (برای گام اول t=1)
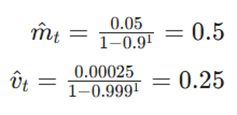
۳: بهروزرسانی نهایی وزن
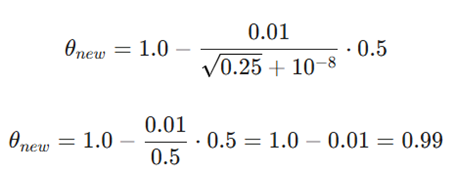
تحلیل: مدل با استفاده از اطلاعات میانگین و نوسان گرادیان، متوجه شد که باید گام بسیار دقیقی بردارد تا از نقطه بهینه عبور نکند.
مقایسه بهینهسازها
| بهینهساز | سرعت همگرایی (سرعت رسیدن به دره) | پایداری و نوسان (در طی مسیر) | مصرف حافظه (RAM/GPU) | بهترین کاربرد (Best Use Case) |
| SGD | کُند | پرنوسان و زیگزاگی | بسیار کم | پروژههایی با محدودیت شدید حافظه و نیاز به تعمیمپذیری بالا. |
| SGD مینی-بچ | متوسط | نوسان متعادل | کم | اکثر پروژههای استاندارد یادگیری عمیق برای تعادل سرعت و دقت. |
| Momentum | سریع | حرکت مستقیم و هدفمند | متوسط | شتابدهی به SGD و عبور از موانع کوچک در مسیر خطا. |
| AdaGrad | سریع در ابتدا | کاهش تدریجی نوسان | متوسط | دادههای خلوت (Sparse) مثل پردازش زبان طبیعی (NLP). |
| RMSProp | بسیار سریع | پایدار و کنترلشده | بالا | شبکههای عصبی پیچیده و دادههای غیر-ایستا. |
| Adam | بسیار سریع (قهرمان) | بسیار پایدار (هوشمند) | بسیار بالا | بهینهساز پیشفرض برای اکثر مدلهای مدرن (مثل پردازش تصویر). |
پیادهسازی عملی بهینهسازها
ما تا اینجا تئوریهای کافی را یاد گرفتهایم و اکنون نوبت به تحلیل عملی رسیده است. زمان آن است که آموختههای خود را به چالش بکشیم و با انتخاب بهینهسازهای مختلف روی یک شبکه عصبی ساده، نتایج را با هم مقایسه کنیم.
ما یک مدل ساده را با استفاده از لایههای پایه آموزش میدهیم؛ در حالی که اندازه دستهها (Batch Size) و تعداد دورهای آموزشی (Epochs) را ثابت نگه میداریم، اما در هر مرحله بهینهساز را تغییر میدهیم. برای رعایت انصاف در مقایسه، از مقادیر پیشفرض (Default Values) برای هر بهینهساز استفاده خواهیم کرد.
وارد کردن کتابخانههای مورد نیاز
در این مرحله، ابزارهای لازم برای پردازش داده و ساخت مدل را فراخوانی میکنیم.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
بارگذاری و پیشپردازش مجموعهداده
x_train= x_train.reshape(x_train.shape[0],28,28,1)
x_test= x_test.reshape(x_test.shape[0],28,28,1)
input_shape=(28,28,1)
y_train=keras.utils.to_categorical(y_train)#,num_classes=)
y_test=keras.utils.to_categorical(y_test)#, num_classes)
x_train= x_train.astype('float32')
x_test= x_test.astype('float32')
x_train /= 255
x_test /=255
گامهای ساخت مدل
batch_size=64
num_classes=10
epochs=10
def build_model(optimizer):
model=Sequential()
model.add(Conv2D(32,kernel_size=(3,3),activation='relu',input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy, optimizer= optimizer, metrics=['accuracy'])
return model
آموزش مدل
optimizers = ['Adadelta', 'Adagrad', 'Adam', 'RMSprop', 'SGD']
# Correct the shape of y_train and y_test
y_train = y_train[:, :, 1]
y_test = y_test[:, :, 1]
for i in optimizers:
model = build_model(i)
hist=model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test,y_test))
پیشبینی و تحلیل عملکرد بهینهسازها
ما مدل خود را با اندازه دسته (Batch Size) ۶۴ و در ۱۰ دوره آموزشی (Epoch) اجرا کردیم. پس از امتحان کردن بهینهسازهای مختلف، نتایجی که به دست آوردیم بسیار جالب توجه هستند.
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
# 1. Load and Preprocess Data
(x_train, y_train_raw), (x_test, y_test_raw) = mnist.load_data()
# Reshape and normalize images
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
# One-hot encode labels
y_train = to_categorical(y_train_raw, 10)
y_test = to_categorical(y_test_raw, 10)
input_shape = (28, 28, 1)
num_classes = 10
batch_size = 64
epochs = 10 # Let's use 10 epochs as in the article for a clearer comparison
def build_model(optimizer_name):
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25),
Flatten(),
Dense(256, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(loss='categorical_crossentropy', optimizer=optimizer_name, metrics=['accuracy'])
return model
optimizers_to_test = ['Adadelta', 'Adagrad', 'Adam', 'RMSprop', 'SGD']
histories = {} # Dictionary to store history for each optimizer
for opt_name in optimizers_to_test:
print(f"\n--- Training with {opt_name} ---")
model = build_model(opt_name)
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1, # Set verbose to 1 to see progress during training
validation_data=(x_test, y_test))
histories[opt_name] = history.history
# --- Plotting the Results ---
plt.figure(figsize=(15, 6))
# Plot Validation Accuracy
plt.subplot(1, 2, 1)
for opt_name, history_data in histories.items():
plt.plot(history_data['val_accuracy'], label=opt_name)
plt.title('Validation Accuracy vs. Epochs')
plt.xlabel('Epoch')
plt.ylabel('Validation Accuracy')
plt.legend()
plt.grid(True)
# Plot Validation Loss
plt.subplot(1, 2, 2)
for opt_name, history_data in histories.items():
plt.plot(history_data['val_loss'], label=opt_name)
plt.title('Validation Loss vs. Epochs')
plt.xlabel('Epoch')
plt.ylabel('Validation Loss')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# Print final accuracies
print("\n--- Final Validation Accuracies ---")
for opt_name, history_data in histories.items():
print(f"{opt_name:10}: {history_data['val_accuracy'][-1]:.4f}")
خروجی:
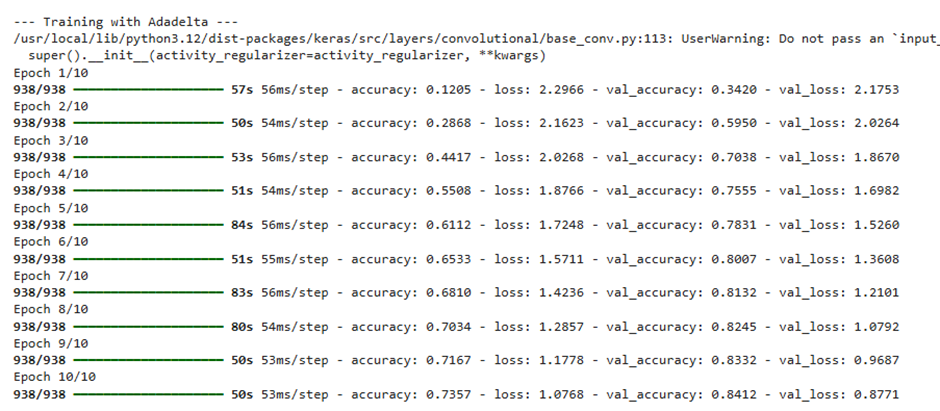
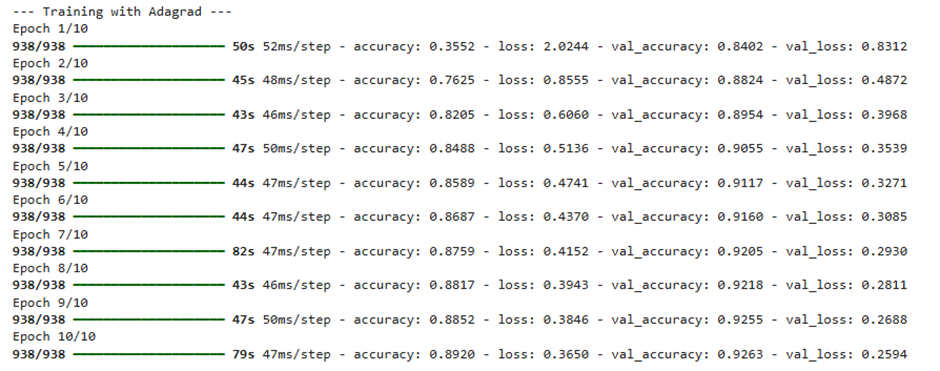
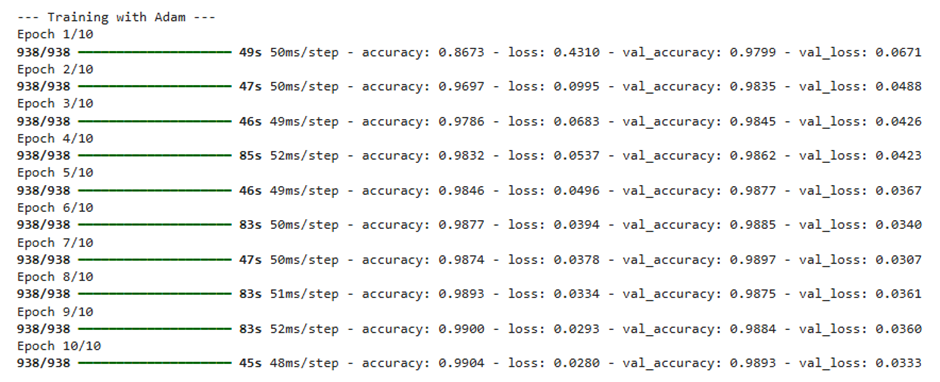

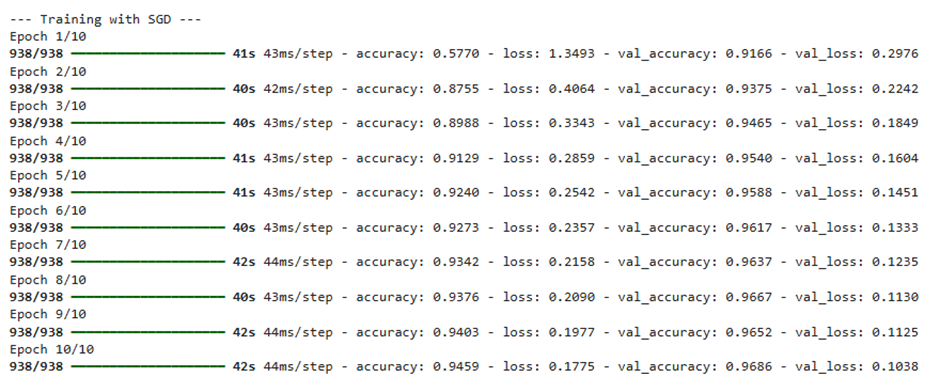
شما میتوانید روند تغییرات دقت هر بهینهساز را در هر اپوک، در نمودار زیر مشاهده و تحلیل کنید.
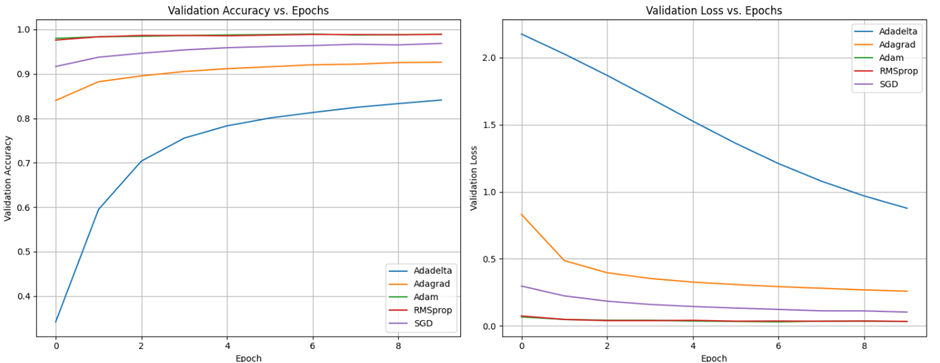
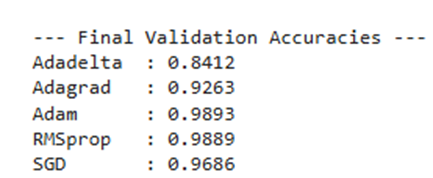
جمع بندی
بهینهسازها قلب فرآیند آموزش شبکههای عصبی هستند و کیفیت یادگیری مدل بهطور مستقیم به نحوه عملکرد آنها وابسته است. این الگوریتمها با استفاده از گرادیان تابع زیان، مسیر حرکت پارامترها را تعیین میکنند و نقش مهمی در سرعت همگرایی، پایداری آموزش و تعمیمپذیری مدل دارند.
در این مقاله دیدیم که هیچ بهینهسازی بهطور مطلق بهترین انتخاب نیست. روشهایی مانند SGD با وجود سادگی، در بسیاری از مسائل تعمیم بهتری ارائه میدهند، در حالی که بهینهسازهای تطبیقی مانند Adam و RMSProp در مسائل پیچیده و دادههای حجیم، همگرایی سریعتری ایجاد میکنند. شناخت مزایا و محدودیتهای هر روش، کلید استفاده مؤثر از آنهاست.
در نهایت، انتخاب بهینهساز باید بر اساس نوع داده، معماری مدل، منابع محاسباتی و هدف پروژه انجام شود. تسلط بر این مفهوم به شما کمک میکند فرآیند آموزش را از یک آزمونوخطای پرهزینه به یک تصمیمگیری آگاهانه و مهندسیشده تبدیل کنید و مدلهایی پایدارتر و کارآمدتر بسازید.



