

1.مرور کوتاه بر مفاهیم بخش اول
در بخش قبل با ساختار پرسپترون، وزندهی ورودیها و نحوه تولید خروجی آشنا شدیم.در این مقاله، به مرحله یادگیری تحت نظارت (Supervised Learning) میرسیم.میخواهیم ببینیم پرسپترون چگونه با مشاهده دادههای دارای پاسخ صحیح، وزنهای خود را تنظیم میکند تا بتواند الگوها را بهتر تشخیص دهد.
همچنین در پایان، محدودیت پرسپترون در مسائل غیرخطی مانند XOR را بررسی کرده و به مفهوم پرسپترون چندلایه (MLP) میرسیم که اساس یادگیری عمیق امروزی است.
این مقاله ادامه پرسپترون (بخش اول): مفاهیم پایه و ساختار است.اگر بخش اول را نخواندهاید، پیشنهاد میشود از آنجا شروع کنید.
import random, numpy as np, matplotlib.pyplot as plt
random.seed(42); np.random.seed(42)
برای تکرارپذیری نتایج، seed ثابت شد. از numpy و matplotlib برای محاسبات و نمودارسازی استفاده میکنیم.
برای شروع آموزش، ابتدا باید بدانیم هر نقطه داده نسبت به خط هدف در چه موقعیتی قرار دارد. پرسپترون باید بیاموزد که نقاط بالا و پایین خط را از هم تفکیک کند.
# خط هدف (همان خطی که در بخش اول تعریف شد؛ در صورت نیاز دوباره تعریفش کن)
def f(x):
return 0.5*x - 1
# یک نقطه تصادفی و برچسب آن (بالای خط = +1، پایین خط = -1)
def random_point():
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
return x, y
def label_point(x, y):
return 1 if y > f(x) else -1
# تست سریع
x, y = random_point()
desired = label_point(x, y)
print(f"point=({x:.2f},{y:.2f}) desired={desired}")
اکنون برای هر نقطه، برچسبی ( 1+یا 1−) داریم که پرسپترون باید یاد بگیرد آن را پیشبینی کند.
برای اینکه این برچسبها را به پرسپترون بدهیم، ابتدا باید ورودیها را در قالب آرایهای با افزودن مقدار بایاس تنظیم کنیم.
# ورودیِ پرسپترون: [x, y, bias]
inputs = [x, y, 1]
desired_output = desired # همان برچسب بالا/پایین خط
print("inputs:", inputs, " desired:", desired_output)
در اینجا مقدار بایاس (Bias) عدد ۱ در نظر گرفته شده است تا پرسپترون بتواند مرز تصمیم را از مبدأ جدا کند
حال به بخش اصلی میرسیم: فرآیند یادگیری. در این مرحله، پرسپترون با مقایسه خروجی حدسزدهشده و خروجی مطلوب، خطا را محاسبه کرده و وزنها را تنظیم میکند.
# نسخه خلاصه پرسپترون (Python)
class Perceptron:
def __init__(self, n_inputs, lr=0.01):
self.weights = [random.uniform(-1, 1) for _ in range(n_inputs)]
self.lr = lr
def feed_forward(self, inputs):
s = sum(i*w for i, w in zip(inputs, self.weights))
return 1 if s > 0 else -1
def train(self, inputs, desired):
guess = self.feed_forward(inputs)
error = desired - guess
for i in range(len(self.weights)):
self.weights[i] += self.lr * error * inputs[i]
# یک گام آموزش
p = Perceptron(3, lr=0.0001) # مطابق متن مقاله، lr کوچک
p.train(inputs, desired_output)
print("weights after 1 step:", [round(w, 4) for w in p.weights])
با تکرار آموزش روی دادههای مختلف، پرسپترون بهتدریج خط جداکنندهای پیدا میکند که دادهها را بهدرستی تفکیک میکند
مثال ۱.۱: پرسپترون (The Perceptron)
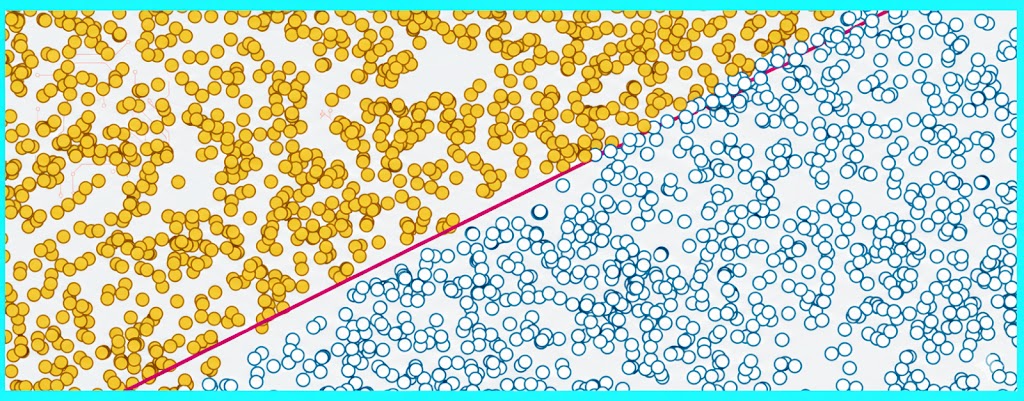
برای مشاهده روند یادگیری، نقاط آموزشی و خط مرز تصمیم را رسم میکنیم. رنگ هر نقطه نشان میدهد که پرسپترون آن را در حال حاضر چگونه طبقهبندی کرده است.
# ساخت چند نقطه آموزشی
def make_training_data(n=200):
data = []
for _ in range(n):
xx, yy = random_point()
lab = label_point(xx, yy)
data.append({"input": [xx, yy, 1], "label": lab})
return data
data = make_training_data(300)
# چند epoch آموزشِ آرام
for _ in range(5): # مطابق «بهتدریج بهتر میشود»
for d in data:
p.train(d["input"], d["label"])
# رسم نقاط + خط هدف + مرز تصمیم فعلیِ پرسپترون
plt.figure(figsize=(6,6))
# نقاط: خاکستری برای +1 و سفید برای -1 (مطابق متن)
for d in data:
guess = p.feed_forward(d["input"])
# رنگ: +1 → خاکستری (0.6)، -1 → سفید
c = str(0.6) if guess == 1 else "1.0"
plt.scatter(d["input"][0], d["input"][1], c=c, s=14, edgecolor="k", linewidths=0.2)
# خط هدف y = f(x)
xline = np.linspace(-1, 1, 200)
yline = f(xline)
plt.plot(xline, yline, 'r-', label='Target line')
# مرز تصمیم پرسپترون: w0*x + w1*y + w2*1 = 0 → y = -(w0*x + w2)/w1
w0, w1, w2 = p.weights
if abs(w1) > 1e-9:
y_dec = -(w0*xline + w2) / w1
plt.plot(xline, y_dec, 'k--', label='Perceptron boundary')
plt.xlim(-1, 1); plt.ylim(-1, 1)
plt.legend()
plt.title("دادههای آموزشی، خط هدف و مرز تصمیم فعلی پرسپترون")
plt.show()
مشاهده میکنید که با گذشت چند مرحله آموزشی، خط مرز تصمیم پرسپترون به خط هدف نزدیکتر میشود. این فرایند مصداقی ساده از یادگیری تحت نظارت است.
در مثال ۱.۱، دادههای آموزشی در کنار خط راهحل هدف، بصریسازی میشوند. هر نقطه، یک قطعه از دادههای آموزشی را نمایش میدهد، و رنگ آن توسط طبقهبندی فعلی پرسپترون تعیین میشود—خاکستری برای +1 یا سفید برای. -1 ما از یک ثابت یادگیری کوچک (0.0001) استفاده میکنیم تا سرعت پالایش طبقهبندیها توسط سیستم را در طول زمان کُند کنیم.
وزنها و هندسه مرز تصمیم
یک جنبه جذاب این مثال، در رابطه بین وزنهای پرسپترون و مشخصههای خط جداکننده نقاط نهفته است—به طور خاص، شیب (m) و عرض از مبدأ (b) خط (در معادله y = mx + b). وزنها در این زمینه صرفاً مقادیر دلخواه یا «جادویی» نیستند؛ آنها یک رابطه مستقیم با هندسه مجموعه داده دارند.
در این مورد، ما فقط از دادههای ۲-بُعدی استفاده میکنیم، اما برای بسیاری از کاربردهای یادگیری ماشین، دادهها در فضاهای بُعدی بسیار بالاتری وجود دارند. وزنهای یک شبکه عصبی به پیمایش این فضاها کمک میکنند و «ابرصفحهها» یا مرزهای تصمیم را تعریف میکنند که دادهها را قطعهبندی و طبقهبندی میکنند.
2.قرار دادن «شبکه» (Network) در شبکۀ عصبی
یک پرسپترون (Perceptron) میتواند ورودیهای متعددی داشته باشد، اما همچنان فقط یک نورون تنها است. متأسفانه، این امر، دامنه مسائلی را که میتواند حل کند، محدود میکند. قدرت واقعی شبکههای عصبی از بخش «شبکه» (Network) آن ناشی میشود. با پیوند دادن چندین نورون به یکدیگر، شما قادر به حل مسائل با پیچیدگی بسیار بالاتری خواهید بود.
اگر یک کتاب درسی هوش مصنوعی را بخوانید، میگوید که یک پرسپترون فقط میتواند مسائل «تفکیکپذیر خطی» (linearly separable) را حل کند.
اگر یک مجموعه داده تفکیکپذیر خطی باشد، میتوانید آن را نمودار کنید و به سادگی با ترسیم یک خط مستقیم، آن را به دو گروه طبقهبندی کنید .طبقهبندی گیاهان به خشکیرُستها یا آبرُستها یک مسئله تفکیکپذیر خطی است.

شکل1: نقاط دادهای که به صورت خطی قابل تفکیک هستند (چپ) و نقاط دادهای که به صورت غیرخطی قابل تفکیک هستند، زیرا برای جداسازی نقاط به یک منحنی نیاز است (راست).
3.محدودیت پرسپترون در تفکیکپذیری غیرخطی
اکنون تصور کنید که گیاهان را بر اساس اسیدیته خاک (-x محور) و دما (-y محور)طبقهبندی میکنید. برخی گیاهان ممکن است در خاک اسیدی رشد کنند اما تنها در یک محدوده دمایی باریک، در حالی که گیاهان دیگر خاک کمتر اسیدی را ترجیح میدهند اما محدوده دمایی گستردهتری را تحمل میکنند.
یک رابطه پیچیدهتر بین این دو متغیر وجود دارد، بنابراین نمیتوان یک خط مستقیم برای جداسازی دو دسته گیاه—اسیددوست (acidophilic) و قلیادوست (alkaliphilic)—ترسیم کرد .یک پرسپترون تنها نمیتواند این نوع مسئله غیرخطی قابل تفکیک را مدیریت کند.
4.مسئله XOR و منطق بولی
# داده XOR (ورودی دودویی، خروجی دودویی)
X_xor = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=float)
Y_xor = np.array([[0],[1],[1],[0]], dtype=float)
print("XOR samples:\n", X_xor, "\nlabels:\n", Y_xor)
چهار حالت ممکن داریم؛ خروجی فقط وقتی ۱ است که دقیقاً یکی از ورودیها ۱ باشد.
یکی از سادهترین مثالهای یک مسئله غیرخطی قابل تفکیک، XOR (یا انحصاری) است. این یک عملگر منطقی است که شبیه به عملگرهای آشناتر AND (و) و OR (یا) است. برای اینکه A و B (AND) درست باشد، هر دو A و B باید درست باشند. با OR (یا)، یا A یا B (یا هر دو) میتوانند درست باشند. این هر دو، مسائل خطی قابل تفکیک هستند.
جدولهای حقیقت در شکل زیر فضای راهحل آنها را نشان میدهد. هر مقدار درست یا غلط در جدول، خروجی را برای ترکیب خاصی از ورودیهای درست یا غلط نشان میدهد. آیا میبینید که چگونه میتوانید یک خط مستقیم برای جداسازی خروجیهای درست از خروجیهای غلط ترسیم کنید؟
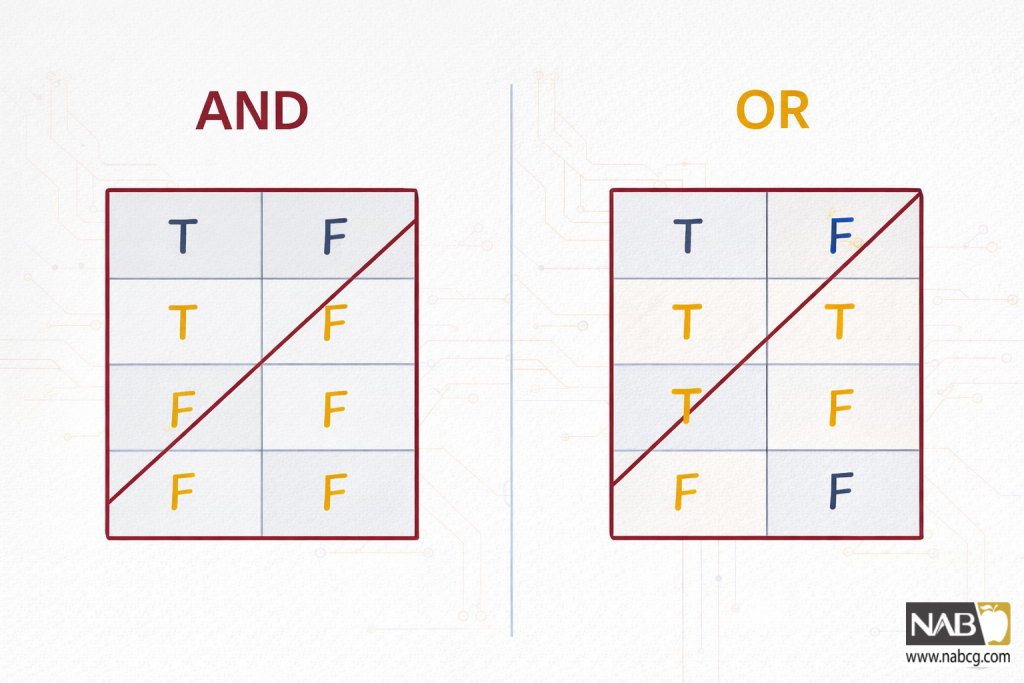
جدولهای حقیقت برای عملگرهای منطقی AND (و) و OR (یا). خروجیهای درست و غلط را میتوان با یک خط جدا کرد.
5.عملگر XOR (یا انحصاری)
عملگر XOR (Exclusive OR) معادل با (OR) AND (NOT AND) است. به عبارت دیگر،A XOR B تنها زمانی درست ارزیابی میشود که یکی از ورودیها درست باشد. اگر هر دو ورودی غلط یا هر دو درست باشند، خروجی غلط است.
برای مثال، فرض کنید برای شام پیتزا میخورید. شما آناناس را روی پیتزا دوست دارید و قارچ را هم روی پیتزا دوست دارید، اما آنها را با هم بگذارید—وای! و پیتزای ساده هم که خوب نیست!
جدول حقیقت XOR در شکل به صورت خطی قابل تفکیک نیست. تلاش کنید یک خط مستقیم برای جداسازی خروجیهای درست از خروجیهای غلط ترسیم کنید—نمیتوانید!
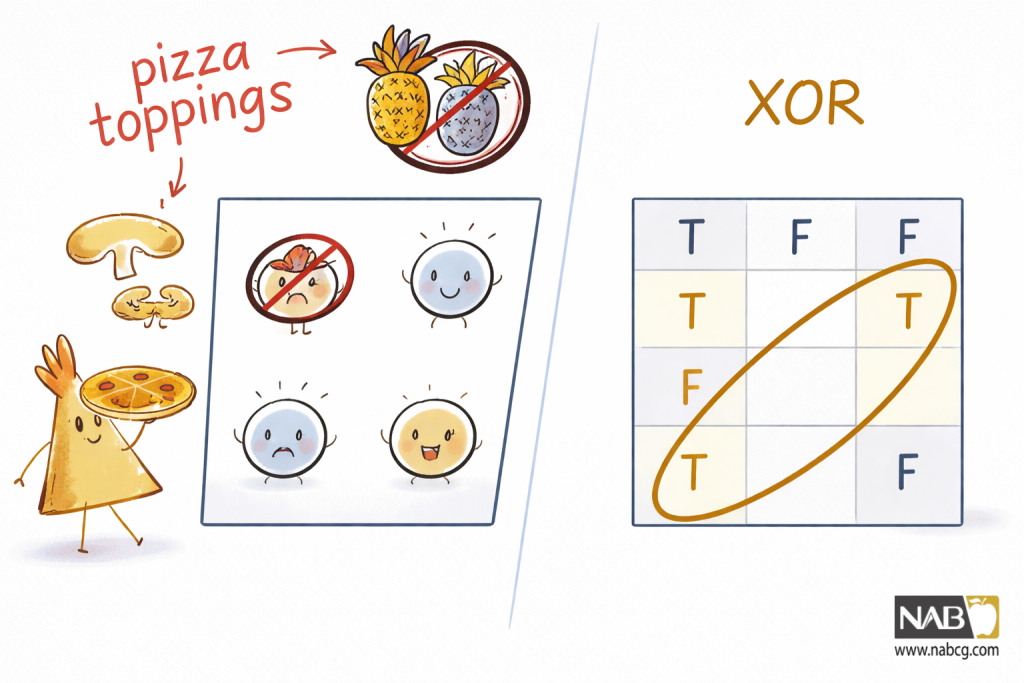
جدولهای حقیقت برای اینکه آیا میخواهید پیتزا بخورید (چپ) و XOR (راست). توجه کنید که چگونه خروجیهای درست و غلط را نمیتوان با یک خط واحد جدا کرد.
6.حل معضل XOR با شبکههای چندلایه
این واقعیت که یک پرسپترون حتی نمیتواند چیزی به سادگی XOR را حل کند، ممکن است بسیار محدودکننده به نظر برسد. اما چه میشود اگر ما شبکهای را از دو پرسپترون بسازیم؟
اگر یک پرسپترون بتواند مسئله OR قابل تفکیک خطی را حل کند و یک پرسپترون بتواند مسئله NOT AND قابل تفکیک خطی را حل کند، آنگاه ترکیب دو پرسپترون میتواند مسئله XOR غیرخطی قابل تفکیک را حل کند.
# یک MLP خیلی ساده با یک لایه پنهان، سیگموئید و بکپراپ
class MLP:
def __init__(self, n_in, n_hidden, n_out, lr=0.5):
self.W1 = np.random.uniform(-1, 1, (n_hidden, n_in))
self.W2 = np.random.uniform(-1, 1, (n_out, n_hidden))
self.lr = lr
@staticmethod
def sigmoid(x):
return 1 / (1 + np.exp(-x))
@staticmethod
def sigmoid_deriv(a):
# مشتق نسبت به خروجی سیگموئید (a = sigmoid(x))
return a * (1 - a)
def forward(self, x):
# x شکل (n_in,)
self.h = self.sigmoid(self.W1 @ x) # (n_hidden,)
self.y = self.sigmoid(self.W2 @ self.h) # (n_out,)
return self.y
def train_step(self, x, y_true):
# پیشرو
y_pred = self.forward(x)
# خطا + گرادیان خروجی
error = y_true - y_pred # (n_out,)
d_out = error * self.sigmoid_deriv(y_pred)
# گرادیان لایه پنهان
d_hidden = (self.W2.T @ d_out) * self.sigmoid_deriv(self.h)
# بهروزرسانی وزنها
self.W2 += self.lr * np.outer(d_out, self.h)
self.W1 += self.lr * np.outer(d_hidden, x)
return float(np.mean(error**2)) # MSE
از سیگموئید برای فعالسازی و از انتشار معکوس برای بهروزرسانی وزنها استفاده میکنیم.
7.شبکههای پرسپترون چندلایه (Multilayer Perceptron)
هنگامی که چندین پرسپترون را با هم ترکیب میکنید، یک «پرسپترون چندلایه» (multilayered perceptron) به دست میآورید؛ شبکهای از نورونهای متعدد.
mlp = MLP(n_in=2, n_hidden=3, n_out=1, lr=0.5)
loss_history = []
for epoch in range(6000):
epoch_loss = 0.0
for i in range(len(X_xor)):
epoch_loss += mlp.train_step(X_xor[i], Y_xor[i])
loss_history.append(epoch_loss / len(X_xor))
# نمایش روند کاهش خطا
plt.figure(figsize=(5,3.2))
plt.plot(loss_history)
plt.xlabel("Epoch"); plt.ylabel("MSE")
plt.title("روند کاهش خطا در آموزش XOR با MLP")
plt.tight_layout(); plt.show()
# ارزیابی نهایی
for i in range(len(X_xor)):
out = mlp.forward(X_xor[i])
print(f"Input {X_xor[i]} -> Pred {out.round(3)}")
میبینیم که خطا بهتدریج کم میشود و خروجیهای شبکه به مقادیر ۰ یا ۱ نزدیک میشوند. بنابراین MLP میتواند الگوی غیرخطی XOR را بیاموزد؛ چیزی که پرسپترون ساده قادر به آن نبود
- نورونهای ورودی: برخی نورونهای ورودی هستند و ورودیهای اولیه را دریافت میکنند.
- لایه پنهان: برخی بخشی از چیزی هستند که لایه پنهان نامیده میشود (زیرا مستقیماً به ورودیها یا خروجیهای شبکه متصل نیستند).
- نورونهای خروجی: و سپس نورونهای خروجی وجود دارند که نتایج از آنها خوانده میشود.
تا به حال، یک پرسپترون منفرد را با یک دایره بصریسازی میکردیم که نشاندهنده یک نورون است که ورودیهای خود را پردازش میکند. اکنون، با حرکت به سمت شبکههای بزرگتر، معمولتر است که تمام عناصر (ورودیها، نورونها، خروجیها) به صورت دایره نمایش داده شوند، با پیکانهایی که جریان داده را نشان میدهند. در شکل زیر، میتوانید ورودیها و بایاس را مشاهده کنید که به داخل لایه پنهان جریان مییابند و سپس به خروجی میرسند.
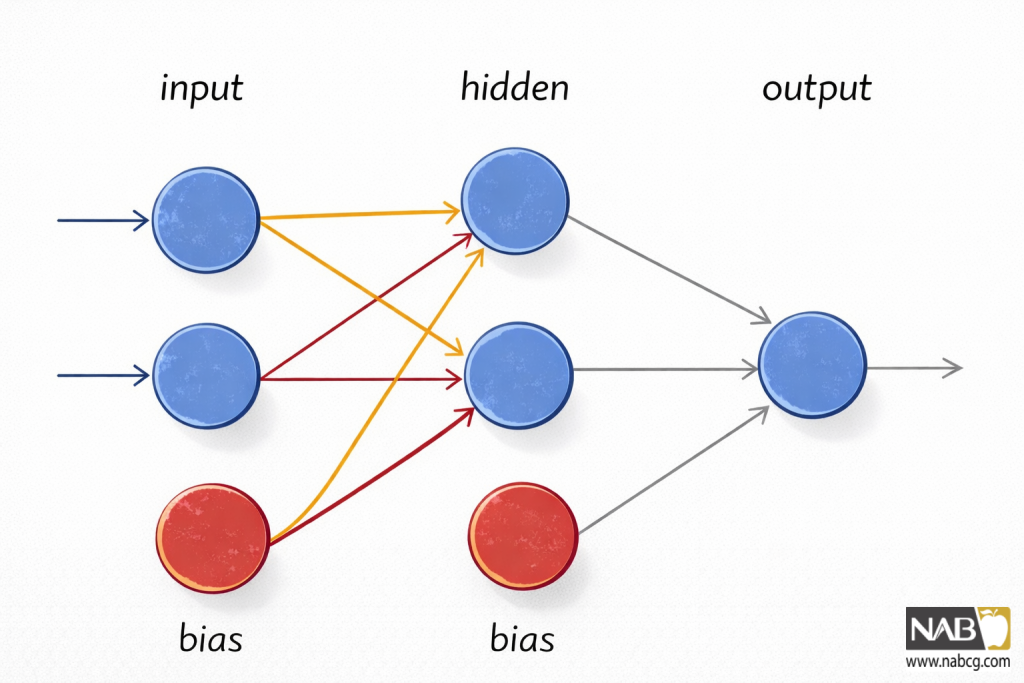
یک پرسپترون چندلایه (Multilayered Perceptron) ورودیها و خروجیهای مشابه پرسپترون ساده دارد، اما اکنون شامل یک لایه پنهان از نورونها است.
آموزش یک پرسپترون ساده نسبتاً سرراست است: شما دادهها را به شبکه میدهید و ارزیابی میکنید که چگونه وزنهای ورودی را مطابق با خطا تغییر دهید. با این حال، با یک پرسپترون چندلایه، فرآیند آموزش پیچیدهتر میشود.
8.چالش آموزش شبکههای چندلایه
خروجی کلی شبکه همچنان به روش مشابه قبل تولید میشود: ورودیها در وزنها ضرب شده، جمع میشوند و به صورت رو به جلو از طریق لایههای مختلف شبکه تغذیه میشوند. و شما همچنان از حدس شبکه برای محاسبه خطا استفاده میکنید.
اما اکنون اتصالات زیادی بین لایههای شبکه وجود دارد که هر کدام وزن مخصوص به خود را دارند. چگونه میدانید که هر نورون یا اتصال چقدر در خطای کلی شبکه سهم داشته است و چگونه باید تنظیم شود؟
راهحل برای بهینهسازی وزنهای یک شبکه چندلایه، «انتشار معکوس» (backpropagation) است.این فرآیند، خطا را میگیرد و آن را به صورت بازگشت به عقب (backward)از طریق شبکه هدایت میکند تا بتواند وزنهای تمام اتصالات را متناسب با سهمی که در خطای کل داشتهاند، تنظیم کند.
جزئیات انتشار معکوس فراتر از دامنه این مقاله است. این الگوریتم از توابع فعالسازی مختلف (یک مثال کلاسیک، تابع سیگموئید) و همچنین مقداری حساب دیفرانسیل استفاده میکند.
# نکته اختیاری: آستانهگذاری برای خروجی دودویی
def hard_threshold(a, t=0.5):
return (a >= t).astype(int)
print("Hard predictions:")
for i in range(len(X_xor)):
print(X_xor[i], "->", hard_threshold(mlp.forward(X_xor[i])))
برای تبدیل خروجی سیگموئید به برچسب دودویی، آستانه 0.5 کافی است.
جمع بندی
در این مقاله دیدیم که پرسپترون چگونه با دریافت دادههای دارای پاسخ صحیح، میتواند از طریق تنظیم تدریجی وزنها، الگوهای خطی را یاد بگیرد و مرز تصمیم بهینهای بسازد. این سازوکارِ سادهی یادگیری تحت نظارت، اساس تمام شبکههای عصبی مدرن است.
اما پرسپترونِ منفرد محدود به جداسازی دادههای «خطی» است و نمیتواند الگوهای پیچیدهتر، مانند مسئلهی منطقی XOR، را تفکیک کند. برای غلبه بر این محدودیت، با ترکیب چند نورون در قالب «پرسپترون چندلایه » (Multilayer Perceptron) به مدلی رسیدیم که توانایی مدلسازی روابط غیرخطی را دارد.
با معرفی تابع فعالسازی سیگموئید و استفاده از الگوریتم «انتشار معکوس »(Backpropagation) توانستیم روند آموزش شبکه را بهینه کنیم تا خطا بهصورت پیوسته کاهش یابد. نتیجه این روند، شکلگیری پایههای یادگیری عمیق (Deep Learning) است که امروزه در شبکههای عصبی پیچیدهتر مانند CNN و RNN نیز به کار میرود.



