

1.مقدمه
پرسپترون (Perceptron) نخستین گام جدی بشر در مسیر مدلسازی هوشمندی مصنوعی بر پایهی عملکرد مغز انسان به شمار میآید. این مدل که در سال ۱۹۵۷ توسط فرانک روزنبلات معرفی شد، تلاش داشت رفتار سادهی یک نورون بیولوژیکی را در قالب یک فرمول ریاضی و محاسباتی بازسازی کند. پرسپترون در واقع سادهترین نوع شبکه عصبی مصنوعی است که تنها از یک نورون تشکیل شده و توانایی انجام تصمیمگیریهای دودویی را دارد.
در این مدل، دادههای ورودی با وزنهای مشخص ترکیب شده، سپس حاصل جمع وزندهیشده از یک تابع فعالسازی (Activation Function) عبور میکند تا خروجی نهایی تولید شود. این سازوکار، اگرچه ابتدایی به نظر میرسد، اما اساس و شالودهی بسیاری از الگوریتمهای پیشرفتهی یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning) را تشکیل میدهد.
در این نوشتار، ضمن بررسی ساختار و عملکرد پرسپترون، به نحوهی محاسبهی وزنها، نقش بایاس (Bias)، مفهوم تابع فعالسازی، فرآیند یادگیری تحت نظارت و پیادهسازی کد آن در پایتون پرداخته میشود. هدف اصلی این بخش، ایجاد درکی عمیق و کاربردی از پرسپترون بهعنوان هستهی اولیهی شبکههای عصبی مصنوعی است.
2.پرسپترون (The Perceptron)چیست؟
پرسپترون سادهترین شبکه عصبی ممکن است: یک مدل محاسباتی از یک نورون واحد، که شامل یک یا چند ورودی، یک پردازشگر، و یک خروجی واحد است.
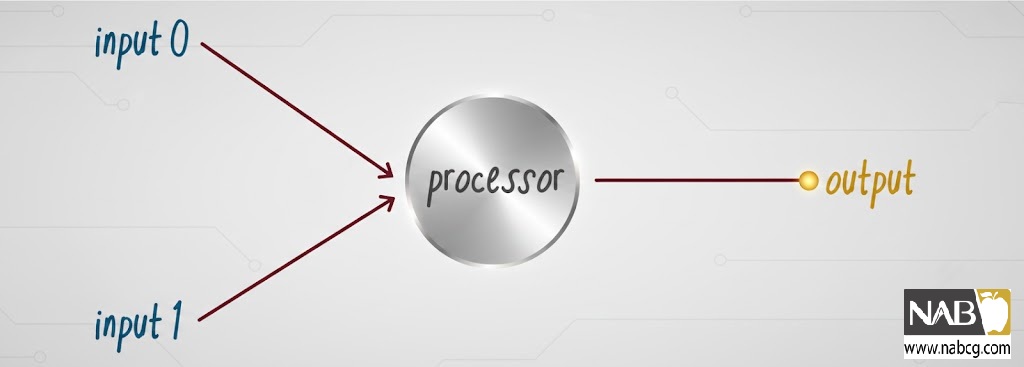
شکل1: یک پرسپترون ساده با دو ورودی و یک خروجی.
پرسپترون از مدل «انتشار رو به جلو» (feed-forward) پیروی میکند: دادهها در یک جهت از طریق شبکه عبور میکنند. ورودیها به داخل نورون ارسال میشوند، پردازش میشوند و منجر به یک خروجی میشوند. نمودار شبکه تکنورونی در شکل از چپ به راست خوانده میشود: ورودیها وارد میشوند و خروجی خارج میشود.
فرض کنید یک پرسپترون با دو ورودی، با مقادیر 12 و 4، داشته باشیم. در یادگیری ماشین، مرسوم است که هر ورودی را با یک x نشان دهیم، بنابراین ما این ورودیها را x0 و x1 مینامیم:
| ورودی (Input) | مقدار (Value) |
|---|---|
| x0 | 12 |
| x1 | 4 |
3.مراحل اجرای الگوریتم پرسپترون
برای رسیدن از این ورودیها به یک خروجی، پرسپترون دنبالهای از گامها را طی میکند.
گام ۱: وزندهی ورودیها
هر ورودی که به داخل نورون ارسال میشود، باید ابتدا وزندهی شود، به این معنی که در یک مقدار (معمولاً عددی بین1 – تا 1+) ضرب میشود. ما وزنها را w0 و w1 مینامیم:
| ورودی (Input) | مقدار (Value) |
|---|---|
| x0 | 12 |
| x1 | 4 |
هر ورودی باید در وزن (Weight) متناظر خود ضرب شود:
| ورودی (Input) | وزن (Weight) | ورودی × وزن |
|---|---|---|
| 12 | 0.5 | 6 |
| 4 | 1- | 4- |
گام ۲: جمع ورودیها
ورودیهای وزندهیشده سپس با هم جمع میشوند: 6 + (4-) = 2
گام ۳: تولید خروجی
خروجی یک پرسپترون با عبور دادن مجموع (Sum) از طریق یک تابع فعالسازی تولید میشود که خروجی را به یکی از دو مقدار ممکن کاهش میدهد. این خروجی دودویی را مانند یک LED در نظر بگیرید که یا «خاموش» است یا «روشن»، یا مانند یک نورون در مغز واقعی که یا شلیک میکند یا شلیک نمیکند. تابع فعالسازی تعیین میکند که آیا پرسپترون باید «شلیک» کند یا خیر.
توابع فعالسازی میتوانند کمی گیجکننده باشند. با این حال، دوست جدید شما پرسپترون ساده یک گزینه آسانتر را فراهم میکند که همچنان مفهوم را نشان میدهد. تابع فعالسازی را علامت (Sign) مجموع در نظر میگیریم. اگر مجموع یک عدد مثبت باشد، خروجی 1+ است؛ اگر منفی باشد، خروجی1 – است:
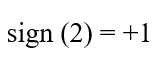
# تست تابع فعالسازی در نزدیکی صفر
for v in [-1e-9, 0, 1e-9]:
print(v, "→", 1 if v > 0 else -1)
در اینجا مشاهده میکنیم که اگر مجموع دقیقاً صفر باشد، میتوان خروجی را بهصورت دلخواه 1− یا 1+ در نظر گرفت. در این مثال، مقدار 1− انتخاب شده است.
جمعبندی نهایی
با در کنار هم قرار دادن سه بخش پیشین، مراحل الگوریتم پرسپترون آمده است:
- برای هر ورودی، آن ورودی را در وزن متناظر آن ضرب کنید.
- تمام ورودیهای وزندهیشده را با هم جمع کنید.
- خروجی پرسپترون را با عبور دادن آن مجموع از طریق یک تابع فعالسازی محاسبه کنید.
میتوانیم نوشتن این الگوریتم را در کد با استفاده از دو آرایه (Array) مقادیر شروع کنیم، یکی برای ورودیها و یکی برای وزنها:
# تعریف ورودیها و وزنها
inputs = [12, 4]
weights = [0.5, -1]
«برای هر ورودی» در گام ۱، یک حلقه را در بر میگیرد که هر ورودی را در وزن (Weight) متناظر خود ضرب میکند. برای به دست آوردن مجموع، نتایج را میتوان در همان حلقه با هم جمع کرد:
# محاسبه مجموع ورودیها پس از وزندهی
weighted_sum = sum(i * w for i, w in zip(inputs, weights))
print("Weighted Sum:", weighted_sum)
با استفاده از مجموع (Sum)، میتوانم سپس خروجی را محاسبه کنیم:
def activation(sum_value):
return 1 if sum_value > 0 else -1
output = activation(weighted_sum)
print("Output:", output)
ممکن است برای شما این سؤال پیش آمده باشد که با مقدار 0 در تابع فعالسازی چگونه رفتار میکنیم. آیا 0 مثبت است یا منفی؟
فارغ از پیامدهای عمیق فلسفی این سؤال، در اینجا به طور دلخواه تصمیم میگیریم که برای 0 مقدار 1- را برگردانیم، اما میتوانستیم به راحتی علامت > را به ≥ تغییر دهیم تا نتیجه معکوس شود. بسته به کاربرد، این تصمیم میتواند قابل توجه باشد، اما در اینجا برای اهداف نمایشی، میتوانیم یکی را انتخاب کنیم.
4.تشخیص الگوی ساده با استفاده از پرسپترون
حال که فرآیند محاسباتی یک پرسپترون را توضیح دادیم، بیایید مثالی از آن را در عمل ببینیم.
به عنوان مثال، تصور کنید یک مجموعه داده از گیاهان دارید و میخواهید آنها را به عنوان خشکیرُستها (گیاهانی که برای بقا در محیطی با آب کم و نور زیاد تکامل یافتهاند، مانند بیابان) یا آبرُستها (گیاهانی که با زندگی غوطهور در آب، با نور کم، سازگار شدهاند) شناسایی کنید. این همان روشی است که در این بخش استفاده خواهیم کرد.
یک راه برای نزدیک شدن به طبقهبندی گیاهان این است که دادههای آنها را در یک نمودار ۲-بُعدی ترسیم کنیم و به مسئله به عنوان یک مسئله مکانی نگاه کنیم. در محور x، میزان نور روزانه دریافتی توسط گیاه، و در محور y، میزان آب را رسم کنید. هنگامی که تمام دادهها ترسیم شدند، کشیدن یک خط در سراسر نمودار، با قرار گرفتن تمام خشکیرستها در یک طرف و تمام آبرستها در طرف دیگر، آسان است، همانطور که در شکل آمده است.
این همان روشی است که هر گیاه میتواند طبقهبندی شود: آیا زیر خط است؟ پس خشکیرست است. آیا بالای خط است؟ پس آبرست است.
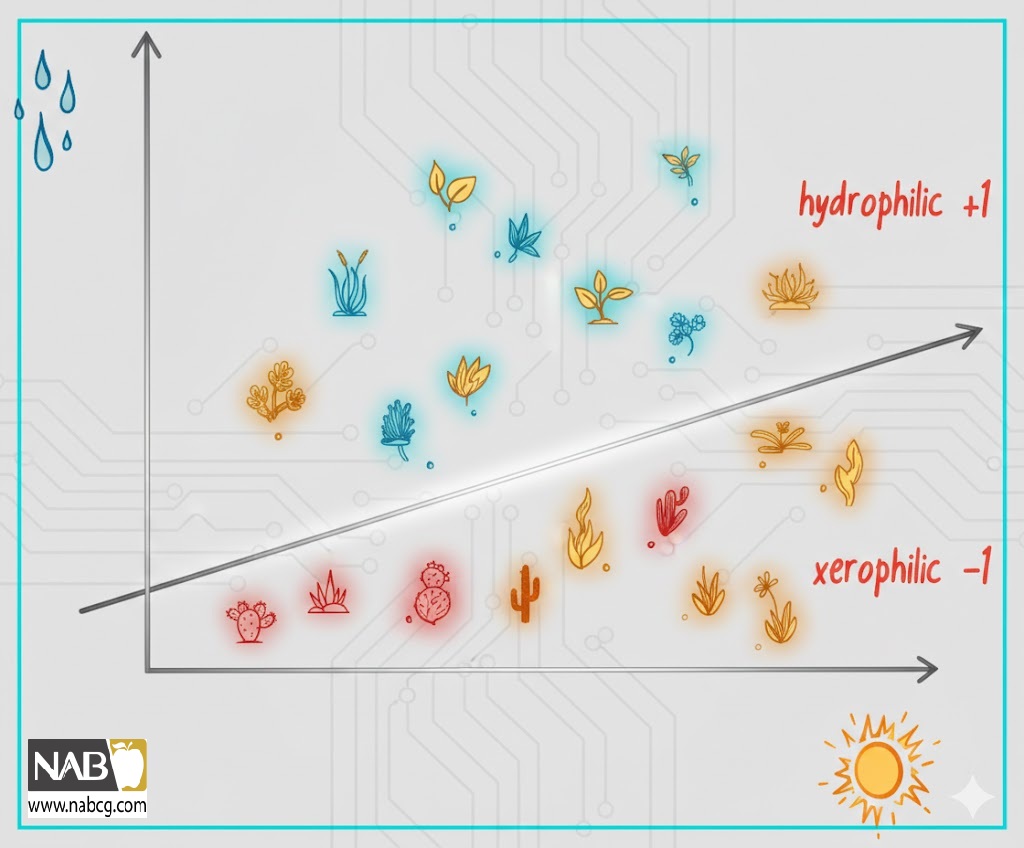
در حقیقت، برای اینکه بگوییم یک نقطه بالای یک خط قرار دارد یا پایین آن، به یک شبکه عصبی—حتی یک پرسپترون ساده—هم نیاز ندارم. میتوانیم پاسخ را با چشمهای خودمان ببینیم، یا از کامپیوتر بخواهیم که آن را با جبر ساده محاسبه کند.
اما درست همانند حل یک مسئله با پاسخ شناختهشده—«بودن یا نبودن»—که یک آزمون اولیه مناسب برای الگوریتم ژنتیک (GA) بود، آموزش یک پرسپترون برای دستهبندی نقاط به عنوان قرارگیری در یک طرف یا طرف دیگر یک خط، روشی ارزشمند برای نمایش الگوریتم پرسپترون و تأیید عملکرد صحیح آن خواهد بود.
5.پرسپترون به عنوان مدل طبقهبندی
برای حل این مسئله، دو ورودی به پرسپترون1 میدهیم: x0 مختصات x یک نقطه است که میزان نور روزانه دریافتی گیاه را نشان میدهد، و x1 مختصات y آن نقطه است که میزان آب گیاه را نشان میدهد.
پرسپترون سپس طبقهبندی گیاه را بر اساس علامت مجموع وزندهیشده این ورودیها حدس میزند:
- اگر مجموع مثبت باشد، پرسپترون خروجی 1+ را میدهد، که نشاندهنده یک آبرُست (hydrophyte) (بالای خط) است.
- اگر مجموع منفی باشد، پرسپترون خروجی 1- را میدهد، که نشاندهنده یک خشکیرُست (xerophyte) (پایین خط) است.
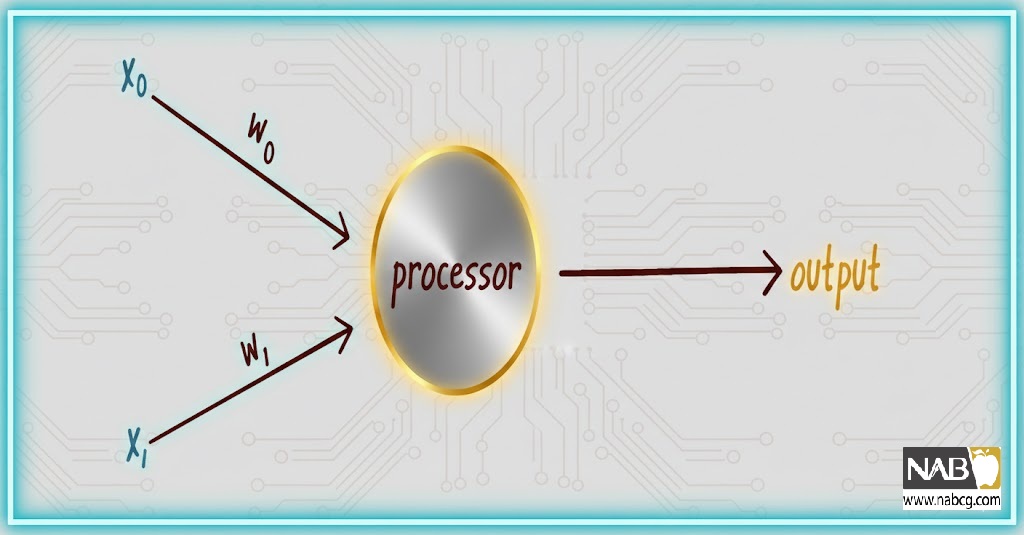
شکل 3: یک پرسپترون با دو ورودی (x0 و x1)، یک وزن برای هر ورودی (w0 و w1)، و یک نورون پردازشگر که خروجی را تولید میکند.
با این حال، این طرح یک مشکل بسیار مهم دارد. چه میشود اگر نقطه داده ما (0, 0) باشد و ما این نقطه را به عنوان ورودیهای x0=0 و x1=0 به پرسپترون بفرستیم؟ مهم نیست وزنها چه باشند، ضرب در 0، برابر با 0 است. بنابراین، ورودیهای وزندهیشده همچنان 0 خواهند بود و مجموع آنها نیز 0 خواهد بود. نقطه (0, 0) قطعاً میتواند بالای خطوط مختلفی در دنیای ۲-بُعدی یا پایین آنها قرار گیرد. پرسپترون چگونه قرار است آن را به طور دقیق تفسیر کند؟
راهحل: ورودی بایاس
برای جلوگیری از این معضل، پرسپترون به یک ورودی سوم نیاز دارد که معمولاً به عنوان ورودی «بایاس» (bias) شناخته میشود. این ورودی اضافی همیشه مقدار 1 را دارد و آن نیز وزندهی میشود. شکل زیر پرسپترون را با افزودن بایاس نشان میدهد.

شکل 4: افزودن ورودی بایاس (Bias Input)، به همراه وزن آن، به پرسپترون.
این کار چه تأثیری بر نقطه (0, 0) میگذارد؟
| ورودی (Input) | وزن (Weight) | نتیجه (Result) |
|---|---|---|
| 0 | w0 | 0 |
| 0 | w1 | 0 |
| 1 | wbias | wbias |
خروجی در این صورت، مجموع نتایج وزندهیشده است: 0 + 0 + wbias. بنابراین، بایاس بهتنهایی به این سؤال پاسخ میدهد که (0, 0) در کجای رابطه با خط قرار دارد.
اگر وزن بایاس مثبت باشد، (0, 0) بالای خط است؛ اگر منفی باشد، پایین آن است. ورودی اضافی و وزن آن، «بایاس»، درک پرسپترون را از موقعیت خط نسبت به (0, 0) جهتدار میکند.
6.پیاده سازی کد پرسپترون در پایتون
اکنون آمادهایم تا کد یک کلاس پرسپترون (Perceptron) را جمعآوری کنیم. پرسپترون نیاز به ردیابی تنها وزنهای ورودی دارد که ما میتوانیم با استفاده از یک آرایه ذخیره کنیم:
import random
class Perceptron:
def __init__(self, n_inputs):
# آرایهای از وزنها (weights) ایجاد میکنیم
# هر وزن با عددی تصادفی بین 1- و1 + مقداردهی میشود
self.weights = [random.uniform(-1, 1) for _ in range(n_inputs)]
سازنده (Constructor) میتواند آرگومانی را که نشاندهنده تعداد ورودیها است (که در این حالت سه مورد است: x0، x1 و یک بایاس)، دریافت کند و آرایه «وزنها» را متناسب با آن اندازهبندی کرده، و آن را با مقادیر تصادفی برای شروع پُر کند:
import random
class Perceptron:
def __init__(self, n):
self.weights = [random.uniform(-1, 1) for _ in range(n)]
self.learning_rate = 0.01
وظیفه یک پرسپترون دریافت ورودیها و تولید یک خروجی است. این نیازمندیها میتوانند در یک متد ()feedForwardبستهبندی شوند. در این مثال، ورودیهای پرسپترون یک آرایه هستند (که باید همطول با آرایه وزنها باشند) و خروجی یک عدد، +1 یا -1 است، که توسط تابع فعالسازی بر اساس علامت مجموع بازگردانده میشود:
def feed_forward(self, inputs):
total = sum(i * w for i, w in zip(inputs, self.weights))
return self.activate(total)
def activate(self, total):
return 1 if total > 0 else -1
احتمالاً، اکنون میتوانیم یک شیء «پرسپترون» (Perceptron object) ایجاد کنیم و از آن بخواهیم که برای هر نقطه دادهشدهای حدس بزند، همانطور که در شکل زیر آمده است.
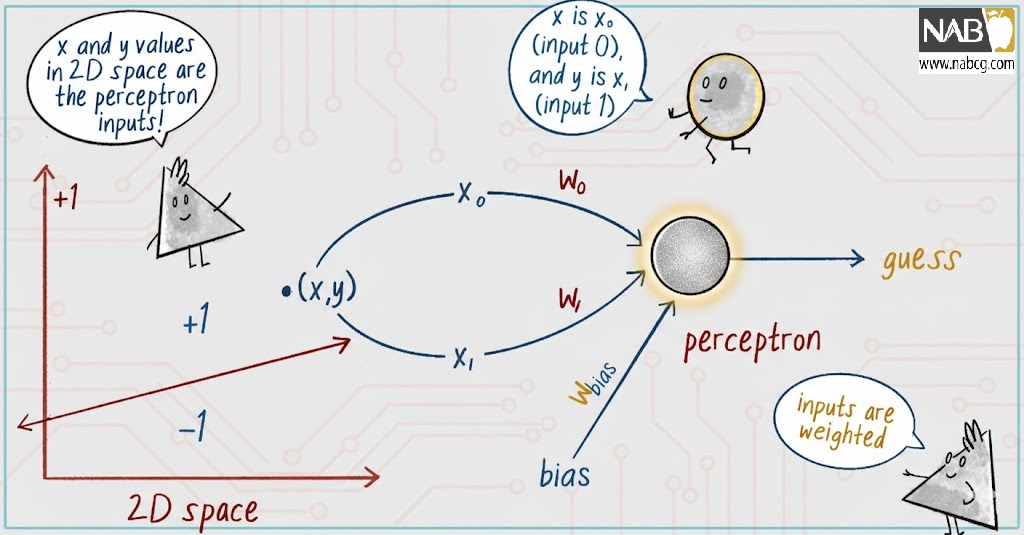
شکل5: یک مختصات (x, y) از فضای ۲-بُعدی، ورودی پرسپترون است.
در اینجا کدی برای تولید یک حدس آمده است:
p = Perceptron(3)
inputs = [5, -3, 1] # دو ورودی + بایاس
print("Guess:", p.feed_forward(inputs))
آیا پرسپترون پاسخ صحیح را داد؟ شاید آری، شاید نه. در این مرحله، پرسپترون شانسی بهتر از 50/50 برای رسیدن به پاسخ صحیح ندارد، زیرا هر وزن با یک مقدار تصادفی شروع میشود. یک شبکه عصبی یک ابزار جادویی نیست که بتواند به طور خودکار به تنهایی حدس صحیح را بزند. باید به آن یاد بدهیم که چگونه این کار را انجام دهد!
7. فرآیند آموزش تحت نظارت (Supervised Learning)
برای آموزش یک شبکه عصبی به گونهای که پاسخ درست را بدهد، ما از روش یادگیری تحت نظارت که قبلاً در این مقاله توضیح دادیم، استفاده خواهیم کرد. به یاد بیاورید، این تکنیک شامل دادن ورودیها با پاسخهای شناختهشده به شبکه است. این امر شبکه را قادر میسازد تا بررسی کند که آیا حدس درستی زده است یا خیر. اگر نه، شبکه میتواند از اشتباه خود بیاموزد و وزنهای خود را تنظیم کند.
این فرآیند به شرح زیر است:
- به پرسپترون ورودیهایی را بدهید که پاسخ آنها شناخته شده است.
- از پرسپترون بخواهید که پاسخ را حدس بزند.
- خطا را محاسبه کنید. (آیا پاسخ صحیح را به دست آورد یا غلط؟)
- تمام وزنها را مطابق با خطا تنظیم کنید.
- به گام ۱ بازگردید و تکرار کنید!
تعریف خطای پرسپترون
این فرآیند را میتوان در یک متد در کلاس Perceptron بستهبندی کرد، اما قبل از اینکه بتوانم آن را بنویسم، باید گامهای ۳ و ۴ را با جزئیات بیشتری بررسی کنم. چگونه خطای پرسپترون را تعریف کنم؟ و چگونه باید وزنها را مطابق با این خطا تنظیم کنم؟
خطای پرسپترون را میتوان به صورت تفاضل بین پاسخ مطلوب و حدس آن تعریف کرد:
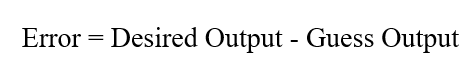
قیاس با نیروی هدایت (Steering Force)
آیا این فرمول آشنا به نظر میرسد؟ به فرمول نیروی هدایت برای یک وسیله نقلیه فکر کنید که محاسبه کردیم:
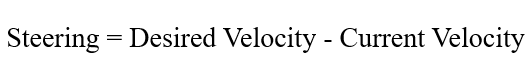
این نیز یک محاسبه خطا است! سرعت فعلی به عنوان یک حدس عمل میکند و خطا (نیروی هدایت) نشان میدهد که چگونه باید سرعت را در جهت صحیح تنظیم کرد. تنظیم سرعت یک وسیله نقلیه برای دنبال کردن یک هدف، مشابه تنظیم وزنهای شبکه عصبی به سمت پاسخ صحیح است.
8. محاسبه خطای پرسپترون (Possible Errors)
برای پرسپترون، خروجی تنها دو مقدار ممکن دارد: 1+ یا 1-. بنابراین، تنها سه خطا ممکن است:
- اگر پرسپترون پاسخ صحیح را حدس بزند، حدس با خروجی مطلوب برابر است و خطا 0 است.
- اگر پاسخ صحیح 1- باشد و پرسپترون 1+ حدس بزند، آنگاه خطا 2- است.
- اگر پاسخ صحیح 1+ باشد و پرسپترون1 – حدس بزند، آنگاه خطا 2+ است.
این فرآیند به طور خلاصه در جدول زیر آمده است:
| خروجی مطلوب (Desired) | حدس (Guess) | خطا (Error) |
|---|---|---|
| 1- | 1- | 0 |
| 1- | 1+ | 2- |
| 1+ | 1- | 2+ |
| 1+ | 1+ | 0 |
خطا عامل تعیینکننده چگونگی تنظیم وزنهای پرسپترون است. برای هر وزن مشخص، آنچه ما به دنبال محاسبه آن هستیم، تغییر در وزن (Δweight) است :
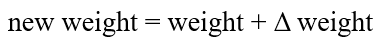
برای محاسبه Δ weight ، باید خطا را در ورودی ضرب کنیم:
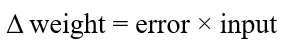
بنابراین، وزن جدید به صورت زیر محاسبه میشود:
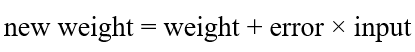
ثابت یادگیری (Learning Constant)
شبکه عصبی از یک راهبرد مشابه با متغیری به نام «ثابت یادگیری» (learning constant) استفاده خواهد کرد:
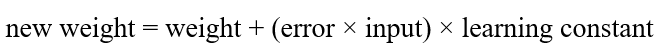
یک ثابت یادگیری بالا باعث میشود وزن به طور شدیدتری تغییر کند. این ممکن است به پرسپترون کمک کند تا سریعتر به یک راهحل برسد، اما خطر فراجهش وزنهای بهینه را نیز افزایش میدهد. یک ثابت یادگیری کوچک وزنها را به آرامی تنظیم میکند و به زمان آموزش بیشتری نیاز دارد، اما به شبکه اجازه میدهد تنظیمات کوچکی انجام دهد که میتواند دقت کلی را بهبود بخشد.
با فرض اضافه شدن ویژگی learningConstant به کلاس پرسپترون، اکنون میتوانیم متد آموزش را مطابق با مراحلی که قبلاً تشریح کردیم، بنویسیم:
def train(self, inputs, desired):
guess = self.feed_forward(inputs)
error = desired - guess
for i in range(len(self.weights)):
self.weights[i] += error * inputs[i] * self.learning_rate
این کلاس کامل پرسپترون (Perceptron) است:
import random
class Perceptron:
def __init__(self, n):
self.weights = [random.uniform(-1, 1) for _ in range(n)]
self.learning_rate = 0.01
def feed_forward(self, inputs):
total = sum(i * w for i, w in zip(inputs, self.weights))
return self.activate(total)
def activate(self, total):
return 1 if total > 0 else -1
def train(self, inputs, desired):
guess = self.feed_forward(inputs)
error = desired - guess
for i in range(len(self.weights)):
self.weights[i] += error * inputs[i] * self.learning_rate
برای آموزش پرسپترون، ما به مجموعهای از ورودیها با پاسخهای شناختهشده نیاز داریم. با این حال، ما مجموعه داده را برای سناریوی خشکیرُستها و آبرُستها در اختیار نداریم. در حقیقت، هدف این است که چگونه یک پرسپترون میتواند یاد بگیرد که آیا نقاط در یک نمودار بالای یک خط یا پایین یک خط قرار دارند، و بنابراین، هر مجموعهای از نقاط کارآمد است.
9.دادههای مصنوعی (Synthetic Data) و کنترل سناریو
آنچه ما توصیف میکنیم، مثالی از «دادههای مصنوعی» (synthetic data) است؛ دادههایی که به صورت مصنوعی تولید شدهاند و اغلب در یادگیری ماشین برای ایجاد سناریوهای کنترلشده برای آموزش و آزمون استفاده میشوند.
در این حالت، دادههای مصنوعی ما شامل مجموعهای از نقاط ورودی تصادفی خواهند بود که هر کدام دارای یک پاسخ شناختهشده هستند و نشان میدهند که آیا نقطه بالای یک خط است یا پایین آن. این رویکرد به ما اجازه میدهد تا فرآیند آموزش را به وضوح نشان دهیم و نحوه یادگیری پرسپترون را به نمایش بگذاریم.
def make_training_data(n=100):
data = []
for _ in range(n):
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
label = 1 if y > f(x) else -1
data.append({"input": [x, y, 1], "label": label})
return data
10.تعریف خط جداکننده
یک خط میتواند به عنوان مجموعهای از نقاط توصیف شود، که در آن مختصات y هر نقطه تابعی از مختصات x آن است :y = f(x)
برای یک خط مستقیم (به طور خاص، یک تابع خطی)، رابطه را میتوان به صورت زیر نوشت :y = mx + b
در اینجا m شیب (slope) خط و b مقدار y است هنگامی که x برابر با 0 است (نقطه تلاقی با محور y یا y-intercept). در اینجا یک مثال با نمودار متناظر در شکل زیر آمده است :y = 0.5 x – 1
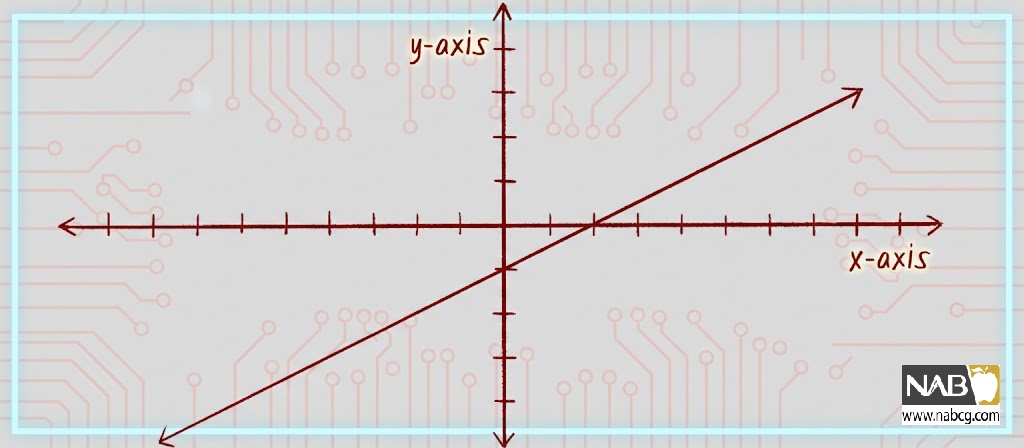
شکل6: نموداری از خط y = 0.5x – 1.
ما به صورت دلخواه این را به عنوان معادله خط انتخاب میکنیم و تابعی را بر اساس آن مینویسیم:
def f(x):
return 0.5 * x - 1
حالا، مسئله مربوط به پیشفرض بودن بوم (canvas) در در گوشه بالا سمت چپ (0, 0) است، در حالی که محور y به سمت پایین اشاره میکند. برای این بحث، فرض میکنیم موارد زیر را در کد برای جهتدهی مجدد بوم به گونهای که با یک فضای کارتزین سنتیتر مطابقت داشته باشد، تعبیه کردهایم.
import matplotlib.pyplot as plt
plt.figure(figsize=(5, 5))
plt.axhline(0, color='gray', linewidth=1)
plt.axvline(0, color='gray', linewidth=1)
plt.xlim(-1, 1)
plt.ylim(-1, 1) # بدون invert → y رو به بالا
plt.title("سیستم مختصات کارتزین (y رو به بالا)")
plt.show()
اکنون میتوانیم یک نقطه تصادفی را در فضای ۲-بُعدی انتخاب کنیم:
import random
def random_point():
"""تولید یک نقطه تصادفی در فضای دوبعدی (-1 تا 1)"""
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
return x, y
# تست
p = random_point()
print("Random Point:", p)
چگونه بدانیم که این نقطه بالای خط است یا پایین آن؟ تابع خط (f(x)) مقدار y روی خط را برای آن موقعیت x بازمیگرداند. ما این مقدار را yline مینامیم:
def f(x):
"""تابع خط جداکننده y = 0.5x - 1"""
return 0.5 * x - 1
def label_point(x, y):
"""بررسی اینکه نقطه بالای خط هست یا پایین آن"""
y_line = f(x)
if y > y_line:
return 1 # بالای خط
else:
return -1 # پایین خط
# تست:
x, y = random_point()
print(f"Point ({x:.2f}, {y:.2f}) → Label:", label_point(x, y))
اگر مقدار y که ما در حال بررسی آن هستیم، بالای خط باشد، آنگاه بزرگتر از yline خواهد بود، همانطور که در شکل آمده است.
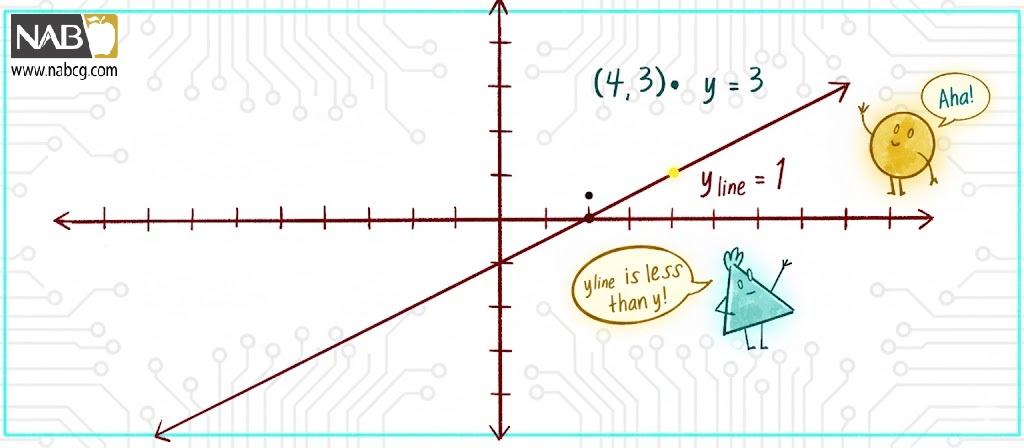
شکل7: اگر yline کمتر از y باشد، نقطه بالای خط قرار دارد.
در بخش بعدی، به آموزش پرسپترون و توسعهی آن به شبکههای چندلایه (MLP) میپردازیم. برای مطالعهی ادامهی مطلب، به مقالهی پرسپترون (بخش دوم): آموزش و شبکههای چندلایه مراجعه کنید



