

1.مقدمه
در آستانهی دههی سوم قرن بیست و یکم، هوش مصنوعی (Artificial Intelligence – AI) از یک رؤیای علمی-تخیلی به یک ابزار زیربنایی برای تحول در علوم، صنعت و جامعه تبدیل شده است. این فناوری صرفاً مجموعهای از الگوریتمهای پیچیده نیست، بلکه یک پارادایم نوین برای پردازش اطلاعات، استدلال و تصمیمگیری است که در حال بازتعریف تعامل انسان با دادهها و محیط پیرامون خود است. اهمیت این حوزه نه تنها در قابلیتهای محاسباتی آن، بلکه در پتانسیل آن برای حل چالشهای عظیمی نهفته است که پیش از این از توان محاسباتی و ادراکی انسان خارج بود (Goodfellow et al., 2020).
اما چرا هوش مصنوعی تا این حد مهم است؟ اهمیت AI در قابلیت آن برای یادگیری از تجربه نهفته است، نه صرفاً دنبال کردن دستورالعملهای صریح. این قابلیت، که ستون فقرات آن را یادگیری ماشین (Machine Learning – ML) تشکیل میدهد، به ما اجازه میدهد تا از حجم عظیم دادهها (Big Data) برای کشف الگوهای پنهان و اتخاذ تصمیمات بهینه در زمان واقعی (Real-Time) استفاده کنیم. از توسعه داروهای جدید و شخصیسازی درمانها در پزشکی تا بهینهسازی زنجیرههای تأمین و نوآوری در مدلهای زبانی بزرگ (LLMs)، AI در حال حاضر نیروی محرک اصلی در مرزهای نوآوری علمی و صنعتی محسوب میشود.
این مقاله با هدف ارائه یک چارچوب علمی و عمیق، به تشریح مفاهیم بنیادین AI، زیرشاخههای حیاتی آن (ML، DL) و سازوکارهای عملکرد میپردازد تا دانشجویان و متخصصان بتوانند درک کاملی از جایگاه کنونی این فناوری و مسیرهای پژوهشی آینده آن کسب کنند.
2.تعریف علمی و تمایز مفهومی
هوش مصنوعی، از منظر آکادمیک و مهندسی، مطالعه و طراحی عاملهای منطقی (Rational Agents) است. عامل منطقی سیستمی است که با دریافت ورودی از محیط (از طریق حسگرها)، با استفاده از دانش و منطق داخلی، عملی را انتخاب و اجرا میکند که انتظار میرود شانس دستیابی به اهداف از پیش تعیینشده را به حداکثر برساند (Russell & Norvig, 2021). این تعریف بر عملکرد صحیح و منطقی (Acting Rationally) تأکید دارد، نه لزوماً بر تقلید فرآیندهای فکری انسان.
تمایز مفهومی: AI، ML، DL و Data Mining
درک ارتباطات این حوزهها برای جلوگیری از سردرگمی تخصصی ضروری است AI: چتر مفهومی، ML ابزار اصلی آن و DL روش پیشرفتهی ML است.
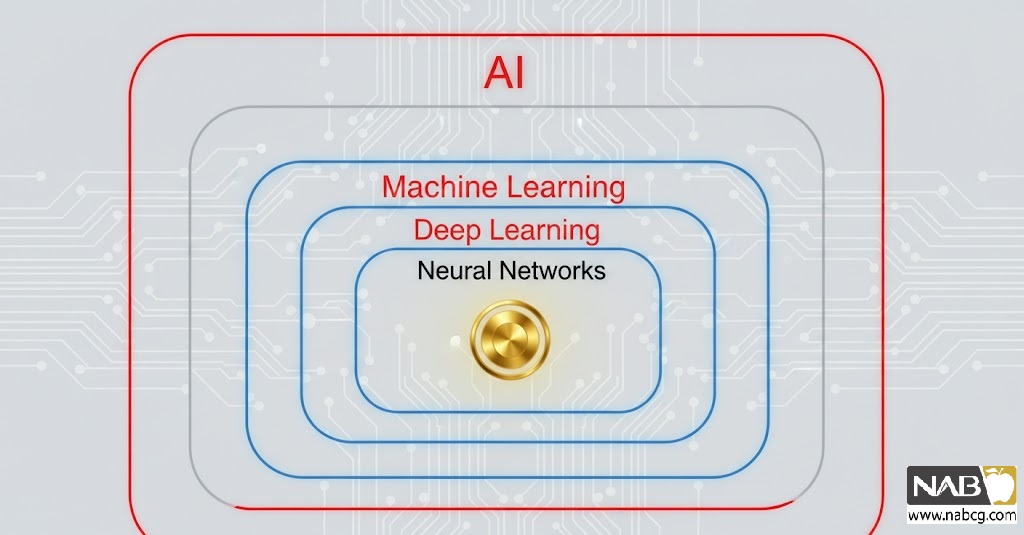
| تفاوت کلیدی با دیگری | تعریف علمی | مفهوم |
|---|---|---|
| چتر مفهومی است که ML و DL را شامل میشود. | ساخت ماشینهایی که هوشمندانه عمل کنند (عامل منطقی). | هوش مصنوعی (AI) |
| ابزار غالب AI مدرن؛ خودکارسازی وظیفه یادگیری. | زیرشاخهای از AI که امکان یادگیری از دادهها، بدون برنامهنویسی صریح را فراهم میکند (Mitchell, 1997). | یادگیری ماشین (ML) |
| تفاوت در یادگیری خودکار ویژگیها ؛ نیاز به دادههای بسیار بزرگ و GPU دارد. | زیرشاخهای از ML با استفاده از شبکههای عصبی چندلایه (Deep Neural Networks). | یادگیری عمیق (DL) |
| یک وظیفه کاربردی است که از الگوریتمهای ML برای هدف کشف دانش استفاده میکند. | فرآیند کشف الگوها و دانش مفید از پایگاههای داده بزرگ (بخشی از KDD). | دادهکاوی (Data Mining) |
3.ساز وکار و نحوه عملکرد
سازوکار عملکرد AI مدرن عمدتاً بر پایه یادگیری ماشین (ML) و بویژه یادگیری عمیق (DL) استوار است. این مکانیزم برخلاف برنامهنویسی سنتی، که شامل دستورالعملهای خط به خط برای هر موقعیت است، بر بهینهسازی یک تابع تمرکز دارد.
مدلسازی به عنوان بهینهسازی
یک مدل ML، مانند یک تابع فرضی (h: X → Y) عمل میکند که نگاشتی بین دادههای ورودی (X) و خروجی مورد نظر (Y) را ایجاد میکند. فرآیند یادگیری به شرح زیر است:
- تابع زیان (Loss Function): ابتدا یک تابع زیان (L) تعریف میشود که میزان اختلاف بین خروجی پیشبینیشده مدل (h(x)) و خروجی واقعی (y) را اندازهگیری میکند.
- بهینهسازی: الگوریتم (مثلاً گرادیان نزولی) به صورت تکراری وزنها و بایاسهای مدل را تنظیم میکند تا مقدار تابع زیان بر روی کل دادههای آموزشی کمینه شود. این فرآیند با محاسبه گرادیان (مشتق) تابع زیان نسبت به پارامترهای مدل انجام میشود.
- انتشار به عقب (Backpropagation): در شبکههای عصبی (ANN/DL)، این فرآیند تنظیم وزنها از طریق الگوریتم انتشار به عقب انجام میشود که سیگنال خطا را از لایه خروجی به لایههای ورودی باز میگرداند تا پارامترهای مدل بهروزرسانی شوند (Rumelhart et al., 1986).
.
مثال کاربردی: تشخیص تصویر
در یک CNN برای تشخیص تصاویر:
- ورودی: یک تصویر خام (ماتریس پیکسلها) وارد لایهی اول میشود.
- لایههای کانولوشن: این لایهها بهطور خودکار، ویژگیهای سلسلهمراتبی را استخراج میکنند. لایههای اولیه لبهها و بافتها را میآموزند، در حالی که لایههای عمیقتر، اشیاء پیچیده (مانند چشم، گوش یا چرخ) را یاد میگیرند.
- خروجی: لایه نهایی با استفاده از تابع فعالسازی Softmax، احتمال تعلق تصویر به هر یک از دستههای ممکن (مثلاً، سگ، گربه، ماشین) را گزارش میدهد. این فرآیند بر پایه میلیونها بار تکرار و بهینهسازی برای کمینه کردن خطای طبقهبندی استوار است (LeCun et al., 2015).
.
4.انواع مدلها و زیرشاخههای کلیدی
هوش مصنوعی مدرن بر سه پارادایم اصلی یادگیری استوار است که هر کدام برای نوع خاصی از وظایف طراحی شدهاند.
یادگیری نظارتشده (Supervised Learning)
این پارادایم بر اساس مجموعه دادههای برچسبدار (Labeled Data) عمل میکند و هدف آن یادگیری نگاشت مستقیم از ورودی (X) به خروجی (Y) است.
- وظیفه طبقهبندی: پیشبینی یک خروجی گسسته .مثال: رگرسیون لجستیک ، که برای تعیین ریسک اعتبار مشتری در بانکداری استفاده میشود (Hastie et al., 2009).
- وظیفه رگرسیون: پیشبینی یک خروجی پیوسته. مثال: پیشبینی قیمت خانه بر اساس متراژ و موقعیت مکانی با استفاده از رگرسیون خطی.
.
یادگیری بدون نظارت (Unsupervised Learning)
این پارادایم بر کشف ساختارها، الگوها و نمایشهای پنهان در دادههای بدون برچسب تمرکز دارد.
- خوشهبندی(Clustering): گروهبندی دادههای مشابه. مثال: استفاده از الگوریتم K-Means توسط شرکتهای خدمات استریم (مانند Netflix) برای تقسیمبندی کاربران و ارائه توصیههای محتوایی متناسب (Tan et al., 2018).
- کاهش ابعاد (Dimensionality Reduction): سادهسازی دادهها با کاهش تعداد ویژگیها در عین حفظ حداکثر اطلاعات مفید. مثال: استفاده از PCA (Principal Component Analysis) در مرحله پیشپردازش برای تسریع آموزش مدلهای. DL
.
یادگیری تقویتی (Reinforcement Learning – RL)
مدلی برای تصمیمگیری توالی است که در آن یک عامل یاد میگیرد تا با تعامل با یک محیط ، سیاستی را به دست آورد که پاداش تجمعی آن را به حداکثر برساند (Sutton & Barto, 2018).
- کاربرد: در سالهای اخیر، RL نقش محوری در توسعه سیستمهای خودکار داشته است. مثال: استفاده از الگوریتمهای پیشرفته RL مانند Deep Q-Networks توسط DeepMind برای آموزش عاملها به منظور انجام بازیهای ویدئویی پیچیده و حتی کنترل سیستمهای خنککننده مراکز داده Google (DeepMind Blog, 2020).
.
5.کاربردهای واقعی هوش مصنوعی
.
پردازش زبان طبیعی (Natural Language Processing – NLP) و مدلهای زبانی بزرگ: (LLMs)
- کاربرد: تولید و درک زبان انسان.
- مثال: مدلهای مبتنی بر معماری ترانسفورمر (مانند GPT و BERT) که توسط Google AI و Meta AI توسعه یافتهاند، در تولید محتوای متنی خلاقانه، خلاصهسازی اسناد حقوقی و ترجمه ماشینی پیشرو هستند. LLMs از طریق تکنیکهایی مانند یادگیری خود-نظارتشده بر روی دادههای عظیم اینترنت آموزش میبینند (Brown et al., 2020).
.
پزشکی و تشخیص تصویر:
- کاربرد: تحلیل دادههای پزشکی و تشخیص زودهنگام بیماریها.
- مثال: استفاده از شبکههای عصبی کانولوشنی (CNN) برای تحلیل تصاویر رادیولوژی(مانند اشعه ایکس و MRI) و تشخیص دقیقتر و سریعتر تومورهای سرطانی یا رتینوپاتی دیابتی. مدلهای DL در این زمینه در برخی موارد به دقت بالاتری نسبت به چشمپزشکان انسانی رسیدهاند (Rajpurkar et al., 2017).
.
وسایل نقلیه خودران:
- کاربرد: تصمیمگیری در محیطهای پیچیده و پویا.
- مثال: سیستمهای رانندگی خودران (مانند Waymo یا Cruise) از ترکیبی از حسگرها (LIDAR، دوربین، رادار) و الگوریتمهای DL و RL برای ادراک محیط (Perception)، برنامهریزی مسیر و کنترل عملگرها استفاده میکنند. این سیستمها باید در کسری از ثانیه تصمیمات ایمن و منطقی بگیرند (NVIDIA Developer, 2021).

سیستمهای توصیهگر:
- کاربرد: شخصیسازی تجربه کاربری و پیشبینی علایق مصرفکننده.
- مثال: پلتفرمهایی مانند Netflix و Amazon از فیلترینگ مشارکتی (Collaborative Filtering) و مدلهای فاکتورگیری ماتریسی مبتنی بر ML و DL برای پیشنهاد فیلمها، موسیقی و محصولات متناسب با سلیقه فردی استفاده میکنند، که ستون اصلی درآمدزایی آنها است (Koren et al., 2009).
.
6.مزایا
- افزایش مقیاسپذیری و کارآیی : AI میتواند حجم عظیمی از دادهها را پردازش کند و وظایف تکراری را با سرعتی بسیار فراتر از توان انسان و با خطای کمتر انجام دهد (مثلاً در پردازش اسناد حقوقی یا کنترل کیفیت در تولید).
- کشف دانش پنهان: الگوریتمهای ML و Data Mining میتوانند الگوهای پیچیده و غیربدیهی را در دادهها کشف کنند که ذهن انسان به راحتی از درک آنها عاجز است (Han et al., 2011).
- تصمیمگیری مبتنی بر داده: AI با ارائه پیشبینیهای دقیق و تحلیلهای عمیق، امکان تصمیمگیری آگاهانه و کاهش عدم قطعیت را برای سازمانها فراهم میکند.
.
7.محدودیتها
- چالش داده و بایاس: مدلهای AI به شدت وابسته به دادههای آموزشی خود هستند. اگر دادهها دارای سوگیریهای تاریخی یا اجتماعی باشند، مدل این سوگیریها را تقویت کرده و نتایج ناعادلانهای تولید میکند. این یک چالش جدی در حوزهی اخلاق AI (AI Ethics) است که نیاز به مداخله فعال انسانی و تکنیکهای رفع سوگیری دارد (Mehrabi et al., 2021).
- مشکل جعبه سیاه و عدم شفافیت: بهویژه در شبکههای عمیق، درک اینکه مدل دقیقاً بر چه مبنایی به یک تصمیم رسیده است، بسیار دشوار است. این امر قابلیت اعتماد (Trustworthiness) را در کاربردهای حساس (مانند پزشکی) کاهش میدهد و نیازمند توسعه روشهای هوش مصنوعی قابل تفسیر (Explainable AI – XAI) است (Adadi & Berrada, 2018).
- شکنندگی و حملات خصمانه: مدلهای DL میتوانند در برابر ورودیهای خصمانه و نویزهای بسیار کوچک که برای انسان نامرئی هستند، آسیبپذیر باشند. این حملات میتوانند باعث شوند مدل به طور کامل شکست بخورد، که یک چالش امنیتی جدی در بینایی ماشین و امنیت سایبری است.
.
8.آینده و مسیر توسعه هوش مصنوعی
.
هوش مصنوعی مولد و مدلهای بنیادی (Generative AI & Foundation Models)
ظهور مدلهای مقیاس بزرگ مانند GPT-4 و Gemini، نشاندهنده عصر جدیدی از هوش مصنوعی مولد (Generative AI) است که قادر به تولید محتوای جدید (تصویر، متن، کد، موسیقی) با کیفیت بالا است. این مدلها که بر پایه معماری ترانسفورمر و SSL آموزش دیدهاند، به دلیل اندازه عظیم و توانایی تعمیم، به عنوان مدلهای بنیادی (Foundation Models) شناخته میشوند و به زیرساخت توسعه AI تبدیل شدهاند (Bommasani et al., 2021; Stanford AI Lab).
.
عاملهای هوشمند و خودمختاری (AI Agents and Autonomy)
تمرکز پژوهش در حال گذار از مدلهای صرفاً پیشبینیکننده به عاملهای هوشمند است. این عاملها قادرند:
- برنامهریزی: توالی اقدامات پیچیده را طراحی کنند.
- حافظه: تجربیات گذشته را برای بهبود عملکرد ذخیره کنند.
- استفاده از ابزار : از ابزارهای خارجی(مانند مرورگرهای وب، ماشینحساب یا APIها) برای غلبه بر محدودیتهای خود استفاده کنند.
این پیشرفتها، مسیر را برای هوش مصنوعی فراگیر (Embodied AI) در رباتیک و سیستمهای خودگردان باز میکند (Lilian Weng Blog, 2023).
.
یادگیری کارآمد و اخلاقی
- یادگیری با دادههای کم: توسعه متدهایی که مدلها را قادر سازد تا با حداقل دادههای برچسبدار (یا بدون آن)، وظایف جدید را به طور موثر تعمیم دهند (Wang et al., 2020).
.
نتیجهگیری
هوش مصنوعی، با زیرشاخههای قدرتمندی چون یادگیری ماشین و یادگیری عمیق، دیگر یک ترند فناوری نیست، بلکه یک توانمندساز بنیادین (Fundamental Enabler) است که آیندهی علوم داده، مهندسی و نوآوری را شکل میدهد. گذار از مدلهای جعبه سیاه به سیستمهای شفاف (XAI)، و حرکت به سمت عاملهای هوشمندی که میتوانند به طور مستقل عمل کنند، افقهای هیجانانگیزی را برای پژوهشگران فراهم آورده است.
تسلط بر مبانی آکادمیک (مانند تجزیه بایاس-واریانس، معماریهای ترانسفورمر و فرآیند KDD) نه تنها برای تحلیل دادهها، بلکه برای توسعه راهکارهای هوشمند، اخلاقی و مقیاسپذیر در دنیای فردا ضروری است. جامعهی آکادمیک، با تکیه بر منابع معتبر و تحقیقات بهروز، متعهد به پرورش نسلی از متخصصان است که نه تنها قادر به استفاده از این ابزارها باشند، بلکه بتوانند مرزهای نوآوری در این حوزه را به پیش ببرند.



