

1 .چکیده
با افزایش فزاینده حجم دادههای مکانی در سامانههای اطلاعات جغرافیایی و تصویربرداری، چالش مقیاسپذیری محاسباتی به یکی از مسائل محوری در یادگیری بدون نظارت تبدیل شده است. الگوریتمهای سنتی خوشهبندی به دلیل نیاز به محاسبات مکرر فواصل زوجبهجفت یا اسکنهای چندباره کل پایگاه داده، در مواجهه با کلاندادهها کارایی خود را از دست میدهند. مقاله حاضر به بررسی تحلیلی الگوریتم STING (مخفف Statistical Information Grid) میپردازد که به عنوان رویکردی منحصربهفرد در حوزه خوشهبندی مبتنی بر شبکه ابداع شده است.
در این نوشتار تبیین میشود که چگونه STING با تقسیم فضا به سلولهای مستطیلی سلسلهمراتبی و ذخیره پیشفرض پارامترهای آماری، فرآیند خوشهبندی را به یک مسئله پرسوجوی آماری با رویکرد بالا به پایین تبدیل میکند. هدف این مقاله، تشریح مبانی نظری، لایههای ساختاری، متغیرهای توزیع آماری سلولها، مثالهای محاسباتی و پیادهسازی عملی آن در پایتون است. نتایج بررسیها نشان میدهد که STING با دستیابی به پیچیدگی زمانی خطی O (n)، سرعت و کارایی فوقالعادهای را در پردازش مستقل از حجم کلاندادهها به ارمغان میآورد.
2 .مقدمه
در عصر توسعه فناوریهای مبتنی بر مکان، استخراج الگوهای معنادار جغرافیایی و فضایی از دادههای بدون برچسب، نقشی حیاتی در مدیریت دادههای ماهوارهای، ناوبری شهری و پایشهای زیستمحیطی ایفا میکند. خوشهبندی به عنوان رویکردی بنیادین در حوزه یادگیری بدون نظارت، وظیفه گروهبندی دادههای مشابه و کشف ساختارهای پنهان را بر عهده دارد (Hand et al., 2001). این ابزار تحلیلی، لایه زیرساخت تصمیمگیریهای کلان در سازمانهای مبتنی بر داده را تشکیل میدهد.
با این حال، الگوریتمهای کلاسیک مرکزگرا یا چگالیمحور نظیر K-Means و DBSCAN در مواجهه با مقادیر انبوه داده با چالشی جدی روبهرو هستند؛ وابستگی شدید زمان پردازش به تعداد کل نمونهها (n) به دلیل محاسبات مسافتی فضایی (Ester et al., 1996). هنگامی که بانک داده شامل میلیاردها رکورد باشد، اسکنهای مکرر فضا جهت یافتن همسایگیها، سیستم را دچار بنبست محاسباتی میکند. برای عبور از این بحران، ساختارهای مبتنی بر شبکه (Grid-based) توسعه یافتند که در آنها الگوریتم STING به عنوان پیشگام رویکردهای سلسلهمراتبی آماری شناخته میشود (Wang et al., 1997). این متدولوژی با تغییر فوکوس محاسبات از «نقاط داده» به «سلولهای فضا»، محدودیت مقیاسپذیری را به طور ریشهای برطرف میسازد.
هدف این مقاله، کالبدشکافی ساختار و فرآیند عملکرد الگوریتم STING به عنوان یک راهکار بهینه در کلاندادههای مکانی است. نقشه راه این نوشتار به این صورت تنظیم شده که ابتدا مفاهیم پایه و ضرورت وجودی این الگوریتم را تبیین میکنیم. سپس مبانی ریاضی، ساختار شناسنامه آماری سلولها و منطق پرسوجوی لایهای آن را تشریح خواهیم کرد. در ادامه، مباحث را با مثالهای محاسباتی، کاربردهای صنعتی و پیادهسازی کامل پایتون ملموستر کرده و با مقایسه ساختاری این روش با مدلهای همرده، دیدگاهی جامع ارائه میدهیم.
3 .تعریف و مفهوم پایه
الگوریتم STING یک الگوریتم خوشهبندی مبتنی بر شبکه و لایهای (Hierarchical Grid-based) است که فضای ویژگیهای مکانی را به سلولهای مستطیلی شکل در چندین سطح ساختاریافته تقسیم میکند (Wang et al., 1997). در این معماری، لایههای متعددی از سلولها به صورت هرمی قرار دارند که در آن، هر سلول در یک لایه بالاتر (سلول مادر)، از ترکیب مشخصی از سلولهای لایه پایینتر (سلولهای فرزند) تشکیل میشود. مکانیزم منحصربهفرد STING در این است که برای هر سلول فضایی، یک شناسنامه یا خلاصه آماری پیشمحاسبهشده شامل تعداد نقاط، میانگین، انحراف معیار، کمینه، بیشینه و نوع توزیع آماری ذخیره میشود (Han et al., 2011).
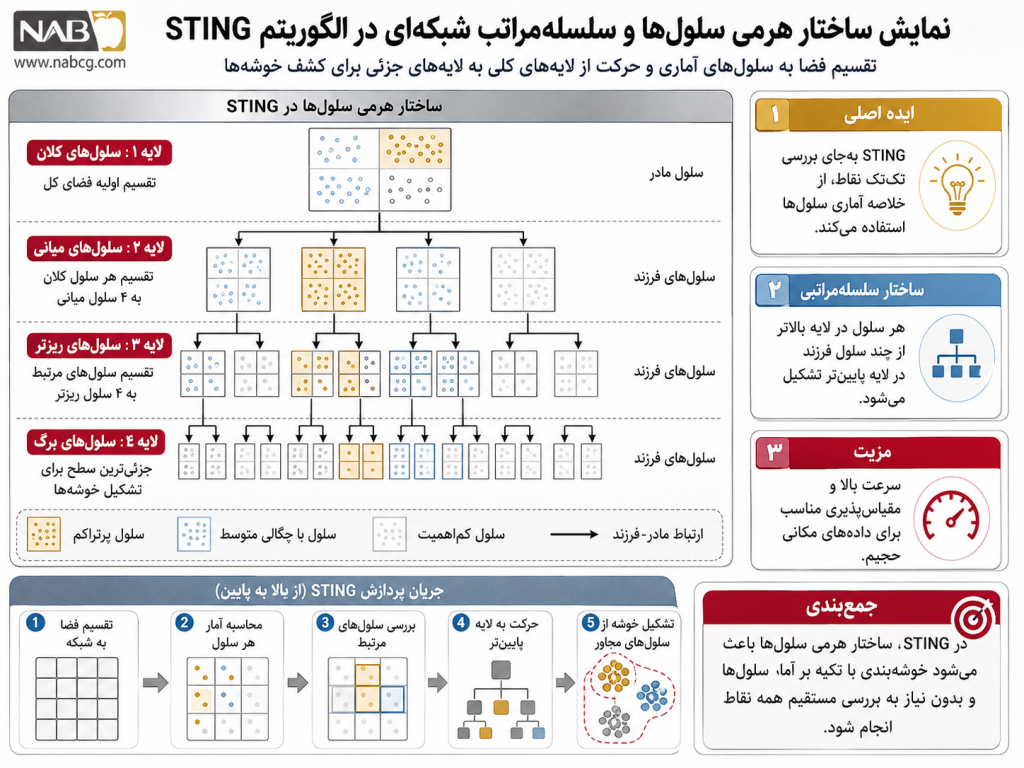
برای درک بهتر، نقشه آماری یک کشور را در نظر بگیرید. در بالاترین سطح، نقشه کل کشور به ۴ مربع بسیار بزرگ تقسیم میشود. لایههای پایینتر، هر مربع بزرگ به ۴ مربع متوسط (استانها) و سپس به مربعهای کوچکتر (محلهها) تفکیک میگردد. در الگوریتم STING، سیستم برای یافتن مناطق متراکم نیازی به بررسی تکتک شهروندان (نقاط داده) ندارد؛ بلکه با خواندن اطلاعات آماری ذخیره شده در سطح محلهها و استانها، کانونهای اصلی تراکم را بدون درگیر شدن با جزییات فردی شناسایی میکند.
4. اهمیت و ضرورت الگوریتم STING
– مسئله اساسی و محوری که الگوریتم STING برای حل آن پدید آمد، آسیبپذیری محاسباتی و عدم مقیاسپذیری الگوریتمهای سنتی در مواجهه با پایگاههای داده عظیم (Terabyte-scale) است (Kriegel et al., 2011). ضرورت وجودی STING در این واقعیت نهفته است که در پروژههای کلانداده، زمان پردازش نباید تابعی از تعداد کل نقاط داده (n) باشد.
به عنوان نمونه، در پایش تصاویر ماهوارهای هواشناسی یا سیستمهای موقعیتیابی ناوگان ملی حملونقل، ما با جریان مداومی از میلیاردها رکورد جغرافیایی مواجه هستیم. اگر یک دانشمند داده بخواهد از روشهای چگالیمحور مانند DBSCAN استفاده کند، سیستم به دلیل محاسبات فواصل اقلیدسی برای یافتن همسایگان تکتک نقاط، دچار تاخیرهای سنگین عملیاتی میشود. ضرورت استراتژیک STING در این است که با تغییر پارادایم، وابستگی محاسبات را از تعداد نقاط داده (n) جدا کرده و آن را به تعداد کل سلولهای شبکه (g) متصل میکند که مقداری ثابت و بسیار کوچکتر است (Wang et al., 1997).
این الگوریتم به سازمانها اجازه میدهد تا با انجام محاسبات آماری سلولها تنها برای یکبار (فاز پیشپردازش)، سرعت پاسخگویی به پرسوجوهای خوشهبندی را به مرتبه خطی O (k) برسانند که در آن k تعداد سلولهای پایینترین لایه است (Han et al., 2011). این ضرورت زمانی آشکار میشود که یک سیستم تصمیمگیری بلادرنگ صنعتی به ابزاری نیاز دارد که مستقل از اینکه پایگاه داده حاوی یک میلیون رکورد است یا صد میلیارد رکورد، پاسخ خوشهبندی را در کسری از ثانیه و صرفاً با اتکا به خلاصههای آماری توزیع فضا استخراج کند.
5. مبانی نظری و ریاضی
بنیان نظری الگوریتم STING بر اصول آمار استنباطی، هندسه فضایی گسسته و تئوری هرمی شبکه استوار است. هدف ریاضی این روش، فرمولبندی ساختاری سلسلهمراتبمحور است که بتواند مشخصات آماری نقاط داده را در قالب سلولهای شبکهای گسسته خلاصهسازی و بازیابی کند؛ به گونهای که برای تحلیلهای بعدی، نیاز به حفظ تکتک دادهها در حافظه اصلی به طور کامل از بین برود. برای تبیین چرایی ریاضی این الگوریتم، ابتدا باید ساختار پارامتریک شناسنامه آماری سلولها و روابط بازگشتی بین لایههای هرمی آن را صورتبندی کرد.
۵.۱. صورتبندی لایهها و ساختار هرمی شبکه
فرض کنید فضای ویژگیهای مکانی ما یک فضای دو بعدی پلتفرمی یا جغرافیایی باشد. در معماری STING، این فضا به صورت یک ساختار هرمی با چندین لایه متمایز مدلسازی میشود.
اگر لایه L نشاندهنده یک سطح در این هرم باشد (که در آن بالاترین لایه دارای کمترین تعداد سلول است)، تعداد سلولهای هر لایه نسبت به لایه بالاتر خود به صورت هندسی افزایش مییابد. فرض پایه ریاضی در این ساختار بر آن است که هر سلول در لایه L (به جز لایه پایینی)، از ترکیب مشخصی از سلولهای فرزند در لایه پایینتر (L+1) تشکیل میشود. در پیادهسازیهای استاندارد دوبعدی، این فرآیند هندسی عموماً بر پایه درختهای چهارگانه (Quad-tree) استوار است که در آن هر سلول مادر دقیقاً به ۴ سلول فرزند تقسیم میشود (Wang et al., 1997).
۵.۲. پارامترهای آماری سلولها و روابط بازگشتی (شناسنامه آماری)
هر سلول در هر لایه از شبکه، واجد یک بردار ویژگی آماری پیشمحاسبهشده است که وضعیت توزیع دادهها را درون مرزهای هندسی آن سلول توصیف میکند. برای یک سلول مشخص، این مؤلفهها به عنوان «شناسنامه آماری سلول» شناخته شده و شامل موارد زیر هستند (Han et al., 2011; Wang et al., 1997):
- n: تعداد کل نقاط داده موجود در سلول.
- m: میانگین (Mean) ویژگیها و مختصات نقاط درون سلول.
- s: انحراف معیار (Standard Deviation) ویژگیهای نقاط درون سلول.
- dist: نوع توزیع آماری دادهها در سلول (مانند نرمال، یکنواخت، نمایی یا نامشخص).
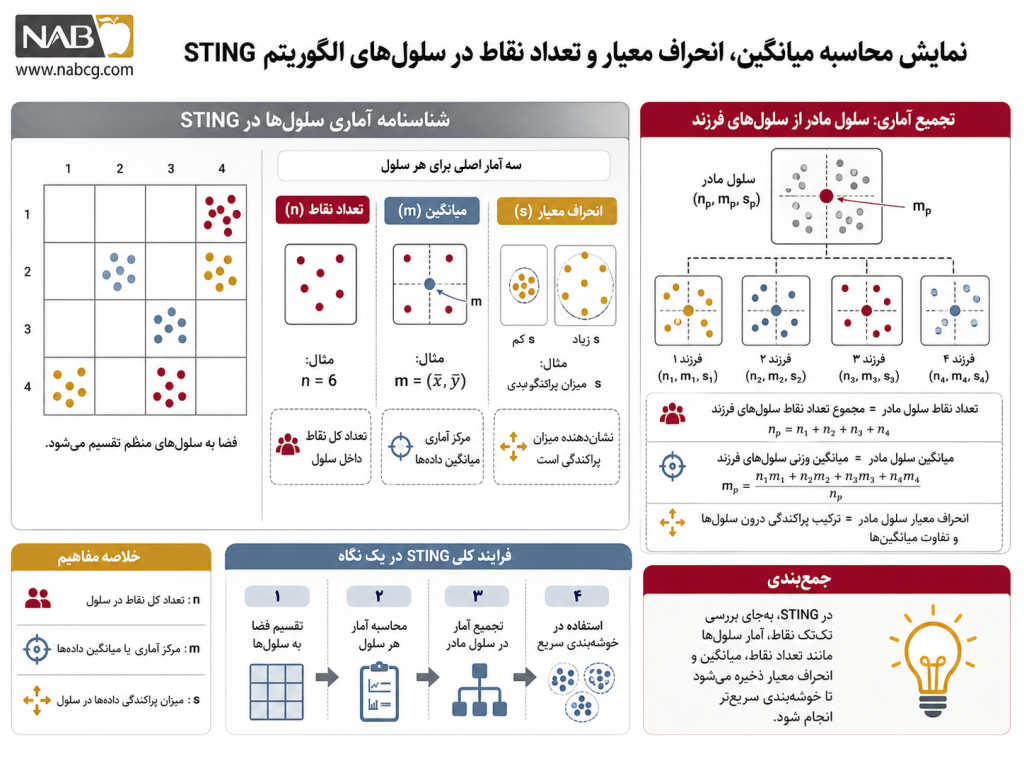
چرایی ریاضی و کارآمدی منحصربهفرد STING در این است که پارامترهای آماری یک سلول مادر در لایه بالاتر، بدون نیاز به بازخوانی تکتک نقاط داده، مستقیماً از روی خلاصههای آماری سلولهای فرزندش در لایه پایینتر قابل محاسبه هستند (Wang et al., 1997). روابط کلیدی محاسباتی به شرح زیر فرمولبندی میشوند:
تعداد نقاط سلول مادر (nparent)
تعداد نقاط یک سلول مادر، برابر است با مجموع تعداد نقاط تکتک سلولهای فرزند متصل به آن (Han et al., 2011):
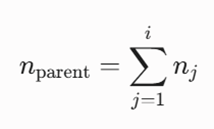
- nj: تعداد نقاط داده موجود در j-امین سلول فرزند.
- i: تعداد کل سلولهای فرزند متصل به سلول مادر (در ساختار استاندارد i=4).
میانگین سلول مادر (mparent)
میانگین مختصات در سلول مادر از طریق میانگین وزنی متناظر با تعداد نقاط سلولهای فرزند محاسبه میشود (Wang et al., 1997):
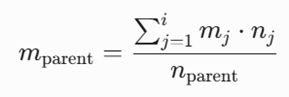
- mj: میانگین ویژگیهای j-امین سلول فرزند.
انحراف معیار سلول مادر (sparent)
محاسبه انحراف معیار سلول مادر بر اساس قضیه انتقال واریانسها در آمار استنباطی و ادغام واریانسهای درونگروهی و بینگروهی به صورت زیر صورتبندی ریاضی میشود (Wang et al., 1997):
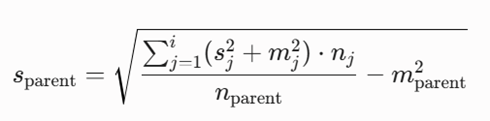
- sj: انحراف معیار ویژگیهای j-امین سلول فرزند.
کمینه و بیشینه سلول مادر (minparent و maxparent)
مرزهای حدی دادهها در سلول مادر، از توابع بهینهسازی مرزی و مقایسه کرانهای سلولهای فرزند پیروی میکنند (Han et al., 2011):
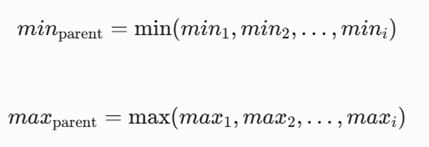
۵.۳. تئوری احتمالات و منطق پرسوجو (Query Logic)
بنیان نظری تفکیک سلولهای مرتبط (Relevant Cells) در فرآیند خوشهبندی STING، بر پایه تست فرضیه و بازههای اطمینان (Confidence Intervals) بنا شده است (Wang et al., 1997). هنگامی که یک پرسوجوی خوشهبندی بر اساس یک آستانه چگالی مشخص مطرح میشود، الگوریتم برای هر سلول، احتمال صدق کردن دادههای آن را در شرط مورد نظر ارزیابی میکند.
اگر توزیع دادهها (dist) در سلول مشخص باشد (مثلاً توزیع نرمال)، از توابع توزیع انباشته استاندارد ریاضی برای محاسبه دقیق این احتمال استفاده میشود. اما در صورتی که نوع توزیع دادهها نامشخص (Undefined) باشد، ریاضیات STING به سراغ نابرابری چبیشف (Chebyshev’s Inequality) میرود تا یک حد پایین صلب برای احتمال موفقیت سلول تعیین کند (Tan et al., 2018):
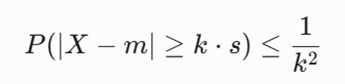
این رویکرد احتمالی به الگوریتم اجازه میدهد تا بدون نیاز به پایش تکتک نقاط داده، با قطعیت ریاضی بالایی اعلام کند که کدام سلولها واجد شرایط حضور در خوشه نهایی هستند و کدام بخشهای فضا باید به عنوان نویز از چرخه محاسبات حذف شوند.
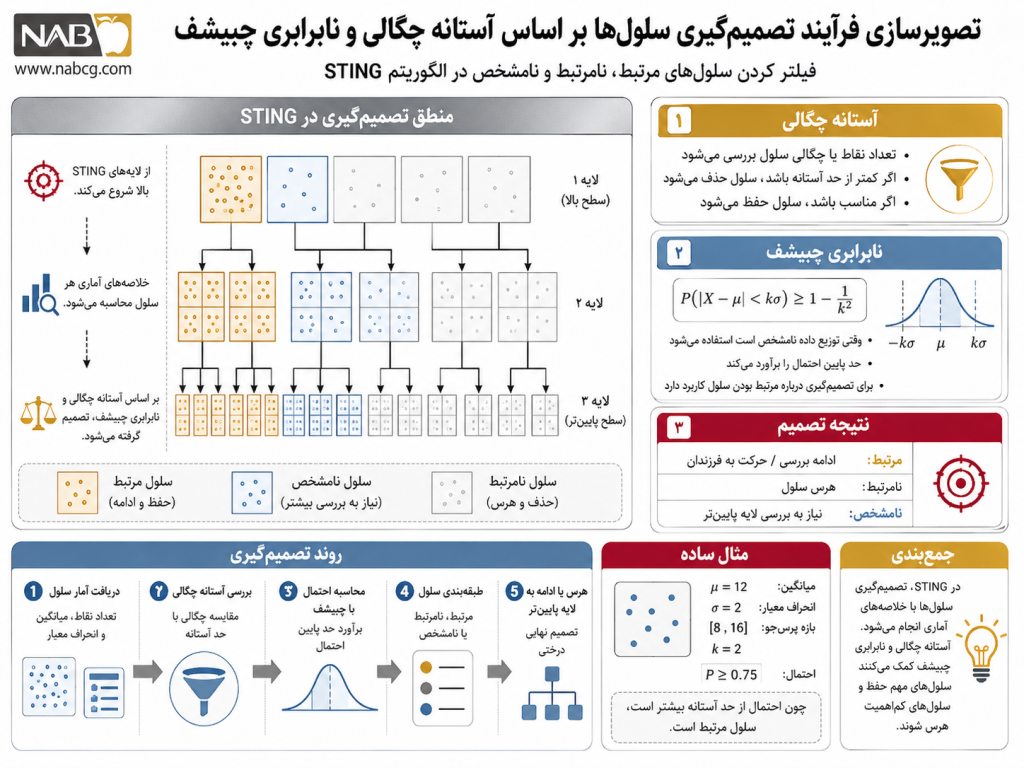
6. مراحل اجرای گام به گام الگوریتم STING
دادهها و فرآیند محاسبات در این الگوریتم، دو فاز اصلی را طی میکنند:
- فاز پیشپردازش (آمادهسازی لایهها): در این مرحله، فضای ویژگی به صورت هرمی شبکه به سلولهای گسسته تقسیم میشود. نقاط داده درون سلولهای پایینترین لایه قرار میگیرند و خلاصههای آماری آنها محاسبه میشود. سپس این اطلاعات به صورت بازگشتی از پایین به بالا (Bottom-up) به سلولهای مادر منتقل شده تا شناسنامه آماری تمام سطوح هرم تکمیل شود. این فاز تنها یکبار انجام میشود.
- فاز پرسوجو و خوشهبندی (جریان عملیاتی بالا به پایین): پس از طرح یک پرسوجو آماری (مثلاً یافتن مناطقی با چگالی بیش از حد آستانه)، جریان داده عملیاتی از بالاترین لایه (کمتعدادترین سطح) آغاز میشود:
- برای هر سلول در لایه فعلی، احتمال صدق کردن در شرط پرسوجو محاسبه میشود.
- بر اساس یک آستانه احتمالی مشخص، سلولها به سه دسته تقسیم میشوند: مرتبط (Relevant)، نامرتبط (Irrelevant) و نامشخص (Neutral).
- سلولهای نامرتبط کاملاً از چرخه محاسبات حذف میشوند و فرزندان آنها در لایههای پایینتر هرگز بررسی نمیشوند که این کار سرعت الگوریتم را به شدت ارتقا میدهد.
- اگر سلول مرتبط یا نامشخص باشد، الگوریتم یک پله در هرم به پایین حرکت کرده و این فرآیند ارزیابی را برای سلولهای فرزند آن تکرار میکند.
- فاز نهایی و معیار توقف: حرکت رو به پایین در لایهها تا زمانی ادامه مییابد که الگوریتم به پایینترین لایه شبکه (لایه برگ) برسد. رسیدن به این لایه مرزی، معیار توقف فرآیند فیلترینگ است.
- تشکیل خوشهها: در گام خروجی، تمام سلولهای مرتبطِ باقیمانده در لایه پایینی که در مرزهای هندسی با یکدیگر همسایه هستند (اتصال ساختاری)، به یکدیگر متصل شده و تودههای متراکم نهایی یا همان خوشهها را تشکیل میدهند. سلولهای ایزوله و نامرتبط نیز به عنوان نویز فضا معرفی میشوند.
۷. مثالهای عددی الگوریتم STING
در این بخش، برای درک بهتر مبانی ریاضی و مراحل اجرایی الگوریتم STING، سه مثال عددی ارائه میشود. این مثالها از سطح مقدماتی آغاز شده و بهتدریج به اجرای کامل منطق پرسوجوی بالا به پایین و تشکیل خوشه نهایی میرسند.
هدف این بخش آن است که نشان دهد STING چگونه به جای بررسی تکتک نقاط داده، از خلاصههای آماری سلولها استفاده میکند و با کمک ساختار سلسلهمراتبی شبکه، فرآیند خوشهبندی را سریعتر و مقیاسپذیرتر انجام میدهد.
مثال ۱: سطح مقدماتی؛ ساخت شناسنامه آماری سلولهای پایینترین لایه
صورت مسئله
فرض کنید فضای دوبعدی دادهها به چهار سلول پایینترین لایه تقسیم شده است. این چهار سلول عبارتاند از:
- C1: بالا-چپ
- C2: بالا-راست
- C3: پایین-چپ
- C4: پایین-راست
در هر سلول، چند مقدار عددی مربوط به یک ویژگی مکانی یا محیطی ثبت شده است. برای نمونه، این مقدار میتواند میزان آلودگی، تراکم ترافیک، شدت سیگنال یا تعداد رخدادهای مکانی باشد.
دادههای خام هر سلول به صورت زیر است:
| سلول | دادههای داخل سلول |
| C1 | 10, 12, 14, 16 |
| C2 | 20, 22, 24 |
| C3 | 6, 8, 10, 12, 14 |
| C4 | 3, 5 |
هدف این مثال، محاسبه شناسنامه آماری هر سلول شامل تعداد نقاط، میانگین، کمینه، بیشینه و انحراف معیار است.
1.گام ۱: محاسبه تعداد نقاط هر سلول
تعداد نقاط هر سلول برابر است با تعداد دادههایی که درون آن سلول قرار گرفتهاند.
| سلول | تعداد نقاط |
| C1 | 4 |
| C2 | 3 |
| C3 | 5 |
| C4 | 2 |
بنابراین داریم:
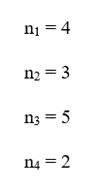
2.گام ۲: محاسبه میانگین هر سلول
فرمول میانگین برای هر سلول به صورت زیر است:

- برای سلول C1:
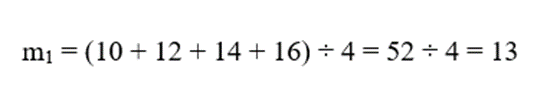
- برای سلول C2:
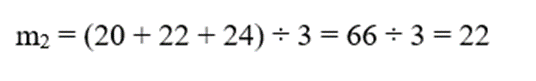
- برای سلول C3:
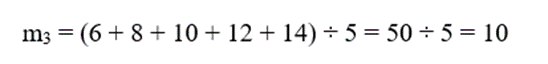
- برای سلول: C4
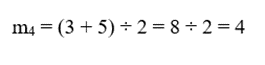
3.گام ۳: محاسبه کمینه و بیشینه هر سلول
کمینه و بیشینه هر سلول از کوچکترین و بزرگترین مقدار داخل آن سلول به دست میآید.
| سلول | min | max |
| C1 | 10 | 16 |
| C2 | 20 | 24 |
| C3 | 6 | 14 |
| C4 | 3 | 5 |
4.گام ۴: محاسبه انحراف معیار هر سلول
برای سادهسازی، از انحراف معیار جامعه استفاده میکنیم:
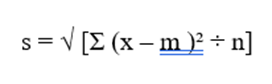
C1:
- دادهها: 10, 12, 14, 16
میانگین: 13 - اختلافها از میانگین:
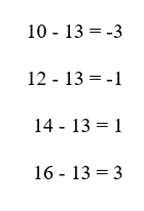
- توان دوم اختلافها: 9, 1, 1, 9
- مجموع توان دوم اختلافها:
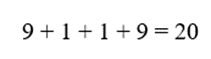
- واریانس:
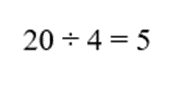
- انحراف معیار:
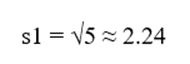
C2:
- دادهها: 20, 22, 24
- میانگین: 22
- اختلافها: 2-, 0, 2
- توان دوم اختلافها: 4, 0, 4
- واریانس:
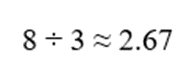
- انحراف معیار:
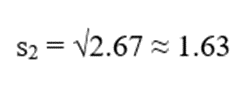
C3:
- دادهها: 6, 8, 10, 12, 14
میانگین: 10 - اختلافها: 4-, 2-, 0, 2, 4
- توان دوم اختلافها: 16, 4, 0, 4, 16
- واریانس:
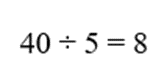
- انحراف معیار:
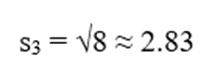
C4:
دادهها: 3, 5
میانگین: 4
اختلافها: 1-, 1
واریانس: 1
پاسخ نهایی :
| سلول | n | mean | std | min | max |
| C1 | 4 | 13 | 2.24 | 10 | 16 |
| C2 | 3 | 22 | 1.63 | 20 | 24 |
| C3 | 5 | 10 | 2.83 | 6 | 14 |
| C4 | 2 | 4 | 1.00 | 3 | 5 |
تفسیر نتیجه
در این مرحله، الگوریتم STING برای هر سلول یک شناسنامه آماری ساخته است. از این نقطه به بعد، الگوریتم دیگر لازم نیست برای تحلیلهای سطح بالاتر به دادههای خام داخل سلولها مراجعه کند. همین موضوع یکی از دلایل اصلی سرعت بالای STING در تحلیل کلاندادههای مکانی است.
مثال ۲: سطح متوسط؛ محاسبه شناسنامه آماری سلول مادر از روی سلولهای فرزند
صورت مسئله
اکنون فرض کنید چهار سلول C1، C2، C3 و C4 که در مثال قبل بررسی شدند، فرزندان یک سلول مادر به نام P هستند. هدف این مثال، محاسبه شناسنامه آماری سلول مادر بدون مراجعه به دادههای خام است.
دادههای آماری سلولهای فرزند به صورت زیر است:
| سلول فرزند | n | mean | std | min | max |
| C1 | 4 | 13 | 2.24 | 10 | 16 |
| C2 | 3 | 22 | 1.63 | 20 | 24 |
| C3 | 5 | 10 | 2.83 | 6 | 14 |
| C4 | 2 | 4 | 1.00 | 3 | 5 |
1.گام ۱: محاسبه تعداد نقاط سلول مادر
تعداد نقاط سلول مادر برابر است با مجموع تعداد نقاط فرزندان:
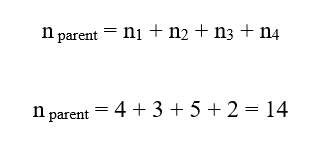
2.گام ۲: محاسبه میانگین وزنی سلول مادر
میانگین سلول مادر از میانگین وزنی سلولهای فرزند به دست میآید:
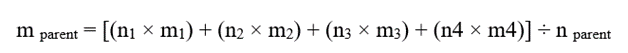
جایگذاری اعداد:
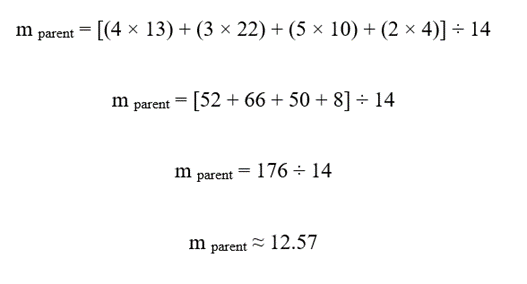
3.گام ۳: محاسبه کمینه و بیشینه سلول مادر
- کمینه سلول مادر برابر است با کوچکترین کمینه میان فرزندان:
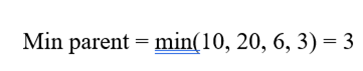
- بیشینه سلول مادر برابر است با بزرگترین بیشینه میان فرزندان:
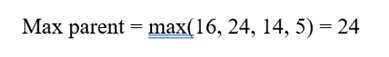
4.گام ۴: محاسبه واریانس و انحراف معیار ادغامی سلول مادر
برای محاسبه واریانس مادر، باید هم پراکندگی داخل هر سلول فرزند و هم فاصله میانگین هر فرزند از میانگین مادر را در نظر بگیریم.
فرمول کلی واریانس ادغامی:
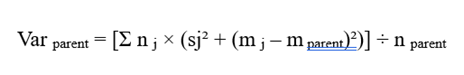
اکنون برای هر سلول فرزند محاسبه میکنیم.
C1:
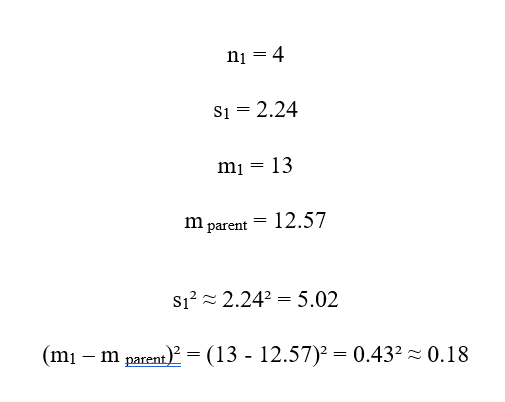
سهم :C1
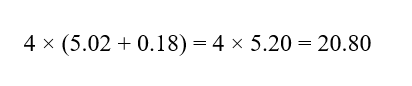
:C2
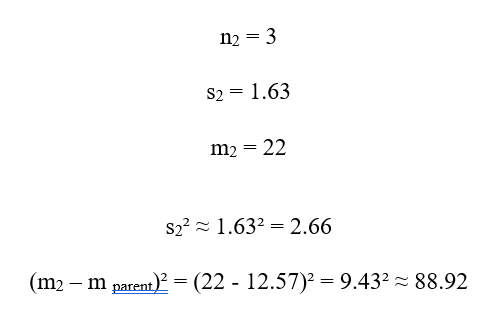
سهم :C2
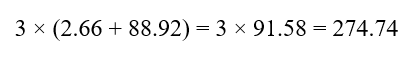
C3:
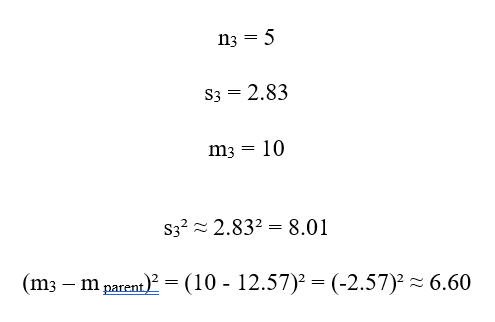
سهم :C3
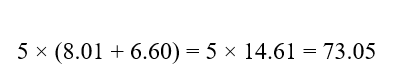
: C4
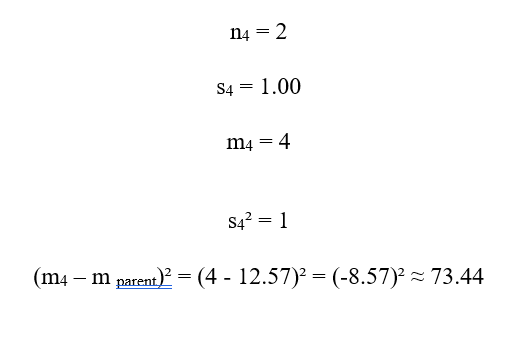
سهم C4:
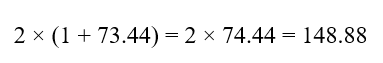
اکنون مجموع سهمها:
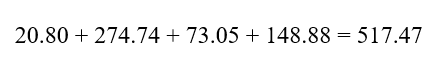
واریانس سلول مادر:
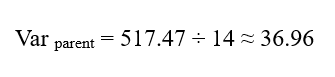
انحراف معیار سلول مادر:
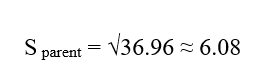
پاسخ نهایی :
| سلول مادر | n | mean | std | min | max |
| P | 14 | 12.57 | 6.08 | 3 | 24 |
تفسیر نتیجه
در این مثال، سلول مادر بدون مراجعه مستقیم به ۱۴ داده خام محاسبه شد. الگوریتم فقط از شناسنامه آماری چهار سلول فرزند استفاده کرد. این همان منطق بازگشتی STING است: اطلاعات از لایههای پایینتر به لایههای بالاتر منتقل میشود و ساختار هرمی شبکه را میسازد.
افزایش انحراف معیار سلول مادر نیز طبیعی است، زیرا میانگین سلولهای فرزند فاصله زیادی از یکدیگر دارند. برای مثال، C2 میانگین ۲۲ دارد، در حالی که C4 میانگین ۴ دارد. این اختلاف باعث افزایش پراکندگی کلی در سلول مادر میشود.
مثال ۳: سطح پیشرفته؛ اجرای کامل فاز پرسوجو، هرس سلولها و تشکیل خوشه نهایی
صورت مسئله
اکنون میخواهیم یک اجرای کامل از فاز پرسوجوی الگوریتم STING را روی یک شبکه سلسلهمراتبی ساده بررسی کنیم.
فرض کنید در بالاترین لایه، دو سلول مادر داریم:
- P1
- P2
هر سلول مادر دارای چهار سلول فرزند در لایه پایینتر است.
هدف پرسوجو این است:یافتن مناطقی که مقدار ویژگی مورد نظر آنها در بازه [8, 16] قرار دارد.
همچنین حد آستانه اطمینان الگوریتم برابر است با Confidence = 0.60:
قانون تصمیمگیری الگوریتم:
- اگر احتمال مرتبط بودن سلول حداقل 0.60 باشد، سلول Relevant است.
- اگر احتمال مرتبط بودن سلول بسیار پایین باشد، سلول Irrelevant است و حذف میشود.
- اگر تصمیم قطعی نباشد، سلول Neutral است و الگوریتم برای بررسی دقیقتر به لایه پایینتر میرود.
دادههای آماری سلولهای مادر
| سلول مادر | n | mean | std | dist |
| P1 | 100 | 12 | 2 | Undefined |
| P2 | 80 | 25 | 3 | Undefined |
چون نوع توزیع هر دو سلول Undefined است، از نابرابری چبیشف برای تخمین حد پایین احتمال استفاده میکنیم.
بررسی سلول مادر P1
1.گام ۱: بررسی بازه پرسوجو نسبت به میانگین
- بازه مطلوب: [16, 8]
- میانگین : m = 12
- فاصله مرزها از میانگین:
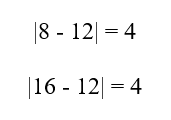
پس بازه پرسوجو به شکل زیر قابل بیان است:

2.گام ۲: اعمال نابرابری چبیشف برای P1
نابرابری چبیشف میگوید:

پس حد پایین احتمال قرار گرفتن دادههای P1 در بازه [16, 8] برابر است با:
P ≥ 0.75
3.گام ۳: تصمیمگیری برای P1
Confidence = 0.60
چون:
0.75 ≥ 0.60
سلول P1 به عنوان Relevant شناخته میشود. بنابراین الگوریتم P1 را حذف نمیکند و برای بررسی دقیقتر، وارد لایه پایینتر یعنی فرزندان P1 میشود.
بررسی سلول مادر P2
1.گام ۱: بررسی بازه پرسوجو نسبت به میانگین
- بازه مطلوب [8, 16] :
- میانگین m = 25 :
- انحراف معیار :s = 3
میانگین P2 بسیار دورتر از بازه مطلوب است. نزدیکترین مرز بازه به میانگین P2 عدد 16 است.
- فاصله میانگین از نزدیکترین مرز:
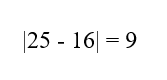
- این فاصله بر حسب انحراف معیار:3
یعنی بازه مطلوب حداقل ۳ انحراف معیار با میانگین سلول فاصله دارد.
با استفاده از نابرابری چبیشف، احتمال قرار گرفتن دادهها در خارج از بازه اطراف میانگین حداکثر چنین است:
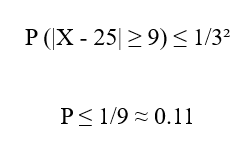
پس احتمال اینکه دادههای P2 به بازه [16, 8] مربوط باشند، بسیار پایین و حداکثر حدود 0.11 برآورد میشود.
2.گام ۲: تصمیمگیری برای P2
چون احتمال مرتبط بودن P2 کمتر از حد آستانه 0.60 است:
0.11 < 0.60
پس P2 به عنوان Irrelevant شناخته میشود.
بنابراین:
- P2 حذف میشود.
- فرزندان P2 اصلاً بررسی نمیشوند.
- این همان فرآیند هرس یا Pruning در STING است.
حرکت به لایه پایینتر برای فرزندان P1
از آنجا که P1 مرتبط شناخته شد، الگوریتم وارد چهار سلول فرزند آن میشود.
دادههای آماری فرزندان P1 به صورت زیر است:
| سلول فرزند | n | mean | std | min | max | وضعیت اولیه |
| C1 | 30 | 11 | 1.5 | 8 | 14 | بررسی شود |
| C2 | 25 | 13 | 1.2 | 10 | 16 | بررسی شود |
| C3 | 20 | 18 | 1.0 | 16 | 20 | بررسی شود |
| C4 | 25 | 9 | 1.0 | 7 | 11 | بررسی شود |
پرسوجو همچنان همان است: [16, 8]
ارزیابی C1
C1 دارای بازه دادهای زیر است:
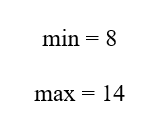
این بازه کاملاً داخل بازه پرسوجوی [16, 8] قرار دارد.
پس:
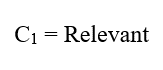
ارزیابی C2
C2 دارای بازه دادهای زیر است:
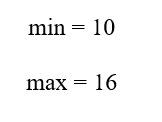
این بازه نیز کاملاً داخل بازه پرسوجو قرار دارد.
پس:
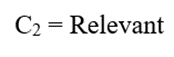
ارزیابی C3
C3 دارای بازه دادهای زیر است:
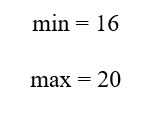
این سلول فقط در نقطه مرزی 16 با بازه پرسوجو تماس دارد، اما بخش اصلی دادههای آن بالاتر از محدوده مورد نظر است. میانگین آن نیز برابر با 18 است که خارج از بازه [16, 8] قرار دارد.
بنابراین C3 برای این پرسوجو مرتبط نیست.
پس:
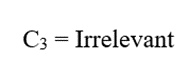
ارزیابی C4
C4 دارای بازه دادهای زیر است:
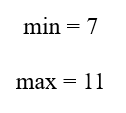
این سلول بخشی از دادههای خود را داخل بازه پرسوجو دارد و بخشی را خارج از آن. میانگین C4 برابر با 9 است که داخل بازه مطلوب قرار دارد، اما چون min آن برابر 7 است، نمیتوان به صورت قطعی گفت کل سلول در بازه قرار دارد.
بنابراین C4 را میتوان Neutral در نظر گرفت.
در حالت واقعی، اگر لایه پایینتری وجود داشته باشد، الگوریتم فرزندان C4 را بررسی میکند. اما در این مثال فرض میکنیم C4 در پایینترین لایه قرار دارد. در این حالت، میتوان با توجه به میانگین مناسب و همسایگی با سلولهای مرتبط، آن را به عنوان سلول قابل قبول در خوشه نهایی نگه داشت یا با آستانه سختگیرانهتر حذف کرد.
در این مثال، چون میانگین C4 داخل بازه است و بخش زیادی از محدوده آن با بازه پرسوجو همپوشانی دارد، آن را به عنوان Relevant ضعیف یا قابل قبول در نظر میگیریم.
پس:

تشکیل خوشه نهایی
در پایینترین لایه، سلولهای زیر مرتبط یا قابل قبول شناخته شدند:
C1
C2
C4
سلول C3 حذف شد.
اکنون الگوریتم سلولهای مرتبطی را که از نظر هندسی مجاور هستند، به یکدیگر متصل میکند.
فرض کنید چیدمان فرزندان P1 به شکل زیر باشد:
| C1 | C2 |
| C4 | C3 |
در این چیدمان:
- C1 با C2 مجاور است.
- C1 با C4 مجاور است.
- C2 با C3 مجاور است، اما C3 حذف شده است.
- C4 با C3 مجاور است، اما C3 حذف شده است.
بنابراین C1، C2 و C4 یک مؤلفه متصل تشکیل میدهند.
پس خوشه نهایی برابر است با:
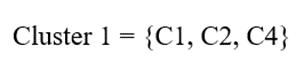
و سلول C3 به عنوان ناحیه نامرتبط یا نویزی حذف میشود.
پاسخ نهایی :
| سلول | وضعیت |
| P1 | Relevant؛ ورود به لایه پایینتر |
| P2 | Irrelevant؛ حذف کامل همراه با فرزندان |
| C1 | Relevant |
| C2 | Relevant |
| C3 | Irrelevant |
| C4 | Relevant / Neutral Accepted |
خوشه نهایی:
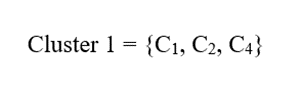
تفسیر نتیجه
این مثال، منطق کامل اجرای الگوریتم STING را نشان میدهد. ابتدا سلولهای مادر بررسی شدند. سلول P2 به دلیل فاصله زیاد میانگین آن از بازه پرسوجو حذف شد و فرزندان آن اصلاً بررسی نشدند. این همان مزیت اصلی STING در کاهش هزینه محاسباتی است.
در مقابل، سلول P1 مرتبط تشخیص داده شد و الگوریتم وارد لایه پایینتر شد. در آن لایه، سلولهای C1، C2 و C4 به عنوان نواحی مرتبط حفظ شدند و سلول C3 حذف شد. سپس سلولهای مرتبط مجاور به یکدیگر متصل شدند و خوشه نهایی تشکیل شد.
این فرآیند نشان میدهد که STING چگونه با ترکیب شناسنامه آماری سلولها، منطق احتمالاتی و حرکت سلسلهمراتبی از بالا به پایین، خوشهها را بدون اسکن مکرر کل دادههای خام استخراج میکند.
.
8. کاربردهای واقعی الگوریتم STING
الگوریتم STING به دلیل سرعت پردازش مستقل از تعداد نقاط، در تحلیل و پردازش کلاندادههای مکانی کاربردهای گستردهای دارد (Wang et al., 1997):
- مدیریت کلاندادههای ماهوارهای و سنجش از دور: دستهبندی و تحلیل سریع پوششهای گیاهی، کانونهای حرارتی و الگوهای آبوهوایی در تصاویر زمینشناسی در مقیاس ترابایت.
- سامانههای اطلاعات جغرافیایی (GIS) و ناوبری شهری: شناسایی کانونهای پرتراکم ترافیکی و تحلیل نقاط حادثهخیز شهری بر اساس مختصات آنلاین وسایل نقلیه.
- تحلیل دادههای محیط زیستی و پایش بلایای طبیعی: خوشهبندی مناطق تحت تأثیر آلودگیهای زیستمحیطی، پیشبینی مسیر گسترش آتشسوزی جنگلها یا کانونهای زلزله بر اساس خلاصههای آماری توزیع منطقه.
- پردازش تصویر و بینایی ماشین چندلایه: بخشبندی تصاویر دیجیتال پزشکی (مانند عکسهای رادیولوژی و اسکنهای سلولی مکرر) از طریق تبدیل پیکسلها به شبکههای سلولی آماری.
- تحلیل دادههای کلان اینترنت اشیاء (IoT Spatial Data): خوشهبندی پویای توزیع حسگرهای محیطی گستره ملی و استخراج الگوهای مصرف یا سیگنالهای ناهمگن فضایی.
.
9. مزایا الگوریتم STING
نقاط قوت ساختاری الگوریتم STING، مأموریتهای پردازش کلانداده را تسهیل کرده است (Han et al., 2011; Wang et al., 1997):
- سرعت پردازش فوقالعاده بالا (پیچیدگی زمانی خطی): بزرگترین مزیت این روش، اجرای فرآیند خوشهبندی در زمان O(k) (تعداد سلولهای لایه پایینی) است که کاملاً مستقل از حجم میلیاردها نقطه داده ورودی عمل میکند.
- استقلال در پاسخگویی به پرسوجوها (Query-independent Processing): به دلیل محاسبات آماری سلولها در فاز پیشپردازش، سیستم به هر پرسوجوی خوشهبندی جدید به صورت بلادرنگ پاسخ میدهد.
- سادگی ساختار هندسی و موازیسازی: تقسیم فضا به سلولهای مستطیلی گسسته، طراحی الگوریتم را بسیار شهودی کرده و بستر محاسبات توزیعشده هرمی را به سادگی فراهم میسازد.
- تفسیرپذیری آماری و ساختاری: استفاده از شناسنامههای آماری ملموس (میانگین، انحراف معیار و توزیع) درک فرآیند خوشهبندی را برای مهندسان داده بسیار شفاف میکند.
- قابلیت تعمیم به فضاهای گسسته چندبعدی: این روش بدون وابستگی به توابع فواصل پیچیده، قابلیت اعمال بر پایگاههای داده مکانی چندلایهای را داراست.
.
10. محدودیتها و معایب الگوریتم STING
با وجود کارایی بالا، درک محدودیتهای عملیاتی این الگوریتم برای پیادهسازیهای صنعتی الزامی است (Kriegel et al., 2011; Wang et al., 1997):
- فرض صلب مرزهای هندسی (مشکلات لبهای): از آنجا که مرزهای سلولها در کل هرم به صورت افقی و عمودی ثابت هستند، اگر یک خوشه طبیعی دقیقاً روی مرز دو سلول مجاور قرار بگیرد، الگوریتم ممکن است آن را تکهتکه کرده یا مرزهای افقی صلب ایجاد کند که این امر بر دقت هندسی مدل اثر منفی میگذارد.
- وابستگی فاحش به کیفیت فاز پیشپردازش: اگر ساختار سلولی در گام اول بسیار بزرگ یا بسیار کوچک تنظیم شود، پایداری خوشهها از دست میرود؛ سلولهای بزرگ باعث ادغام خوشههای متمایز و سلولهای کوچک باعث افزایش سنگینی حافظه میشوند.
- افت فاحش کارایی در فضاهای با ابعاد بالا (High-D): با افزایش ابعاد ویژگی، تعداد سلولهای مورد نیاز در ساختار سلسلهمراتبی به صورت نمایی افزایش مییابد (O (2^d)) که سیستم را دچار کمبود شدید حافظه میکند.
- ضعف محاسباتی در دادههای نویزی متراکم: در صورتی که نویزها به صورت یکنواخت اما با تراکم بالا در کل شبکه پخش شده باشند، خلاصههای آماری سلولها فریب خورده و نویزها به اشتباه به عنوان بخشی از خوشه مرتبط پذیرفته میشوند.
.
11.مقایسه الگوریتم STING با روشهای مشابه
در جدول زیر، الگوریتم STING با دو الگوریتم شاخص دیگر در یادگیری بدون نظارت مقایسه شده است (Aggarwal, 2014; Tan et al., 2018):
| شاخص مقایسه | الگوریتم STING | الگوریتم CLIQUE | الگوریتم DBSCAN |
| دسته الگوریتم | مبتنی بر شبکه و آمار (Grid) | شبکه و چگالی (Grid-Density) | مبتنی بر چگالی فضا (Density) |
| پیچیدگی زمانی پرسوجو | O(k) (بسیار سریع و خطی) | O(n . d) (وابسته به نقاط و ابعاد) | O(n log n) یا O(n^2) )سنگین) |
| نیاز دادهای | خلاصههای آماری پیشمحاسبهشده | توزیع فرکانسی سلولهای چندبعدی | کل نقاط داده در حافظه اصلی |
| شکل هندسی خوشهها | تودههای سلولی متصل (مرزهای صلب) | خوشههای مستطیلی در زیرفضاها | اشکال کاملاً آزاد، نامنظم و هلالشکل |
| مقیاسپذیری در کلانداده | فوقالعاده بالا (مستقل از حجم داده) | متوسط تا بالا | ضعیف در دیتای تتابایتی |
| حساسیت به ابعاد ویژگی | بسیار شدید (ضعف در ابعاد بالا) | بسیار مقاوم (مخصوص ابعاد بالا) | متوسط |
12. نوآوریها و چشمانداز آینده الگوریتم STING
تکامل روشهای شبکهای آماری منجر به روندهای نوآورانهای در پیرامون الگوریتم STING شده است (Kriegel et al., 2011):
- ادغام با یادگیری عمیق (Deep Grid Clustering): ترکیب روش STING با شبکههای عصبی فشردهساز (Autoencoders)؛ به طوری که ابتدا ابعاد ویژگیهای پیچیده کاهش یافته و سپس پرسوجوی آماری هرمی بر فضای پنهان اعمال میشود تا چالش نفرین ابعاد حل گردد.
- الگوریتمهای شبکهای پویا و انطباقی (Adaptive Grids): روندهای جدید به سمت حذف مرزهای صلب مستطیلی حرکت کردهاند؛ در این رویکرد، مرزهای سلولها بر اساس تراکم محلی دادهها تغییر شکل میدهند تا دقت مرزی ارتقا یابد.
- پیادهسازی در بستر کلانداده توزیعشده: نوآوری در نگهداری ساختارهای هرمی سلولها بر روی پایگاههای داده غیررابطهای (NoSQL) و فریمورکهای جریانی (مانند Apache Flink) جهت خوشهبندی همزمان میلیاردها رکورد جغرافیایی بلادرنگ.
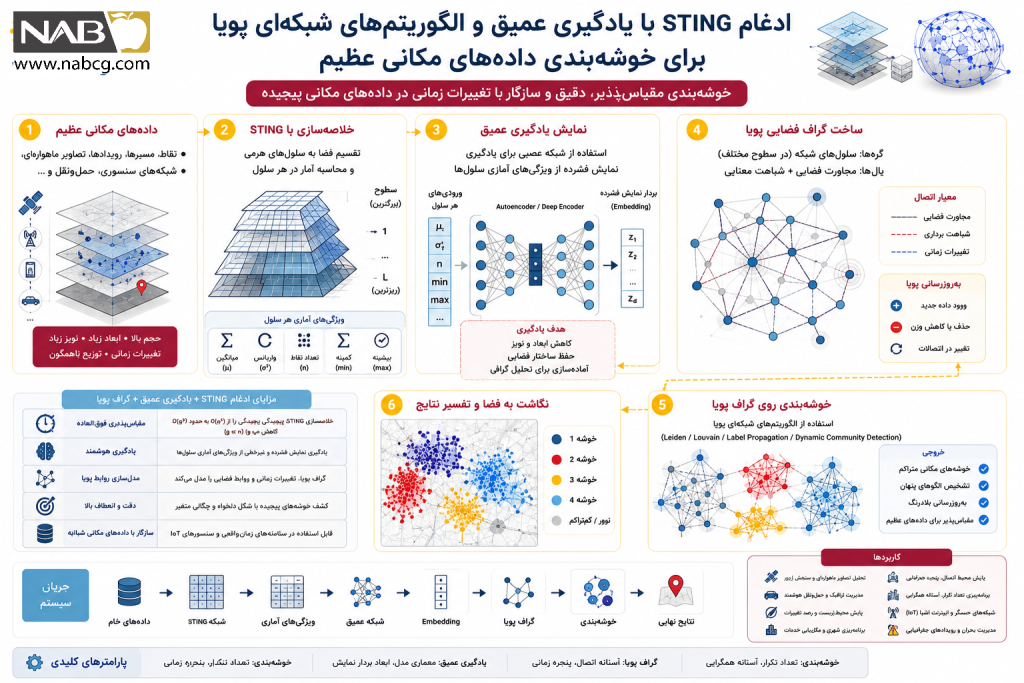
13 .ابزارها و فریمورکهای مرتبط
به دلیل معماری خاص و نیاز به شاخصگذاری هرمی فضا، ابزارهای مشخصی برای پیادهسازی بهینه STING استفاده میشوند:
محیط دادهکاوی ELKI (زبان جاوا)
- کاربرد و مزیت: ELKI تخصصیترین و قدرتمندترین فریمورک آکادمیک برای الگوریتمهای مبتنی بر شبکه و فضایی است. به دلیل بومی بودن ساختارهای شاخصگذاری فضایی مانند درختهای چهارگانه (Quad-tree) در جاوا، این ابزار بالاترین سرعت را در فاز پیشپردازش و فاز پرسوجوی STING ارائه میدهد.
کتابخانه PyClustering (زبان پایتون و C++)
- کاربرد و مزیت: این کتابخانه یکی از کاملترین ابزارهای متنباز پایتون برای الگوریتمهای شبکهای است. کدهای لایه زیرین آن با C++ نوشته شده است که به دانشمندان داده اجازه میدهد ماژولهای شبکهای و ساختارهای سلولی آماری را با راندمان محاسباتی بالا در اسکریپتهای پایتون فرابخوانند.
.
14 .پیادهسازی عملی در پایتون
تبیین مسئله و آمادهسازی دادهها
مسئله اصلی در این سناریو، ارزیابی کارایی یک الگوریتم مبتنی بر شبکه در تفکیک کانونهای تراکم مکانی مستقل از تعداد کل نقاط داده است. برای شبیهسازی این چالش عملی، یک بانک داده جغرافیایی شامل دو کانون تراکم انبوه به همراه دادههای پرت (نویز سراسری) در یک فضای دو بعدی شبیهسازی میکنیم.
مأموریت ما در این بخش، پیادهسازی فازهای اصلی الگوریتم STING است: ابتدا فضا را به صورت یک شبکه گسسته مپ میکنیم (فاز پیشپردازش) ؛ سپس با اعمال یک پرسوجوی آماری مبتنی بر حد آستانه چگالی، سلولهای واجد شرایط را فیلتر کرده و تودههای همسایه را به عنوان خوشههای نهایی به نمایش میگذاریم.
کد پایتون
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# ۱. تعریف پالت رنگی اختصاصی بر اساس هویت بصری سایت ناب
COLOR_PALETTE = {
'active_gold': '#FFD700', # طلایی زنده برای سلولهای مرتبط (Relevant Clusters)
'ai_soft_blue': '#4682B4', # آبی روشن هوش مصنوعی برای نمایش نقاط داده اصلی
'crimson': '#DC143C', # زرشکی برای نمایش نویزها و نقاط پرت
'metal_silver': '#C0C0C0', # نقرهای متالیک برای مرزهای ساختار شبکه (Grid)
'ultra_light_gray': '#F5F5F5', # خاکستری خیلی روشن برای پسزمینه نمودار
'pure_white': '#FFFFFF' # سفید خالص برای پسزمینه اصلی
}
# ۲. آمادهسازی دادههای مصنوعی (دو کانون تراکم متمرکز + نویزهای پراکنده محیطی)
np.random.seed(42)
cluster_1 = np.random.normal(loc=[2.5, 3.0], scale=0.5, size=(300, 2))
cluster_2 = np.random.normal(loc=[7.0, 6.5], scale=0.6, size=(250, 2))
noise = np.random.uniform(low=0, high=10, size=(100, 2))
# ترکیب و یکپارچهسازی تمامی مختصات در یک بانک داده واحد
X = np.vstack([cluster_1, cluster_2, noise])
# ۳. فاز پیشپردازش STING: تقسیم فضا به شبکه سلولی و محاسبه شناسنامه آماری (پارامتر n)
grid_resolution = 10 # ایجاد یک شبکه 10 در 10 (شامل 100 سلول گسسته)
x_min, x_max = 0, 10
y_min, y_max = 0, 10
x_edges = np.linspace(x_min, x_max, grid_resolution + 1)
y_edges = np.linspace(y_min, y_max, grid_resolution + 1)
# ماتریس ذخیره پارامتر آماری تعداد نقاط (n) برای هر سلول شبکه
cell_counts = np.zeros((grid_resolution, grid_resolution), dtype=int)
# شمارش بازگشتی و انتساب نقاط به سلولهای متناظر هندسی
for point in X:
x_idx = int((point[0] - x_min) / (x_max - x_min) * grid_resolution)
y_idx = int((point[1] - y_min) / (y_max - y_min) * grid_resolution)
# کنترل مرزهای صلب انتهای فضا
if 0 <= x_idx < grid_resolution and 0 <= y_idx < grid_resolution:
cell_counts[x_idx, y_idx] += 1
# ۴. فاز پرسوجو (Query Phase): فیلتر کردن سلولها بر اساس حد آستانه چگالی آماری
density_threshold = 12 # حداقل تعداد نقاط مجاز برای مرتبط شناخته شدن یک سلول (Relevant)
relevant_cells = cell_counts >= density_threshold
# ۵. تصویرسازی خروجی نهایی الگوریتم STING
fig, ax = plt.subplots(figsize=(10, 8), facecolor=COLOR_PALETTE['pure_white'])
ax.set_facecolor(COLOR_PALETTE['ultra_light_gray'])
# رسم تکتک نقاط داده برای درک موقعیت هندسی واقعی
ax.scatter(X[:, 0], X[:, 1], c=COLOR_PALETTE['ai_soft_blue'], alpha=0.5, s=25, label='Raw Spatial Points')
# رسم ساختار شبکه و رنگآمیزی سلولهای واجد شرایط بر اساس پرسوجو
for i in range(grid_resolution):
for j in range(grid_resolution):
# محاسبه مختصات دقیق هندسی شروع هر سلول
x_left = x_edges[i]
y_bottom = y_edges[j]
width = x_edges[i+1] - x_left
height = y_edges[j+1] - y_bottom
if relevant_cells[i, j]:
# رنگآمیزی سلولهای مرتبطِ واجد شرایط چگالی با رنگ طلایی زنده
rect = Rectangle((x_left, y_bottom), width, height, linewidth=1.5,
edgecolor=COLOR_PALETTE['metal_silver'], facecolor=COLOR_PALETTE['active_gold'], alpha=0.4)
ax.add_patch(rect)
# درج تعداد نقاط درون سلولهای مرتبط برای ارزیابی آماری مخاطب
ax.text(x_left + width/2, y_bottom + height/2, str(cell_counts[i, j]),
color='black', ha='center', va='center', fontsize=9, fontweight='bold')
else:
# رسم مرزهای سلولهای غیرمرتبط یا نویزی با خطوط کمرنگ نقرهای
rect = Rectangle((x_left, y_bottom), width, height, linewidth=0.5,
edgecolor=COLOR_PALETTE['metal_silver'], facecolor='none', alpha=0.3)
ax.add_patch(rect)
# تنظیمات استایل، شبکه و لیبلهای انگلیسی نمودار بر اساس استاندارد بینالمللی سئو
ax.set_title('STING Grid-Based Clustering: Density Query Result', fontsize=14, fontweight='bold')
ax.set_xlabel('Spatial Feature X (Longitude)', fontsize=11)
ax.set_ylabel('Spatial Feature Y (Latitude)', fontsize=11)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.grid(False) # حذف شبکه پیشفرض برای عدم تداخل با خطوط شبکه اختصاصی STING
ax.legend(loc='upper left', fontsize=10)
plt.tight_layout()
plt.show()
خروجی:
نمایش و تفسیر نتایج عملی
پس از اجرای اسکریپت فوق، نمودار خروجی توزیع فضایی نقاط را در کنار ساختار گسسته شبکهای به نمایش میگذارد:
- کشف کانونهای چگالی (Highlighted Grids): همانطور که در نقشه پدیدار است، بلوکهای مستطیلی شکل که با رنگ طلایی زنده (Active Gold) متمایز شدهاند، سلولهایی هستند که در فاز پرسوجو پیروز شدهاند؛ یعنی تعداد نقاط داده درون آنها از حد آستانه (n ≥ 12) فراتر رفته است. این بلوکهای متصل به هم، دقیقاً استخوانبندی و مرکز ثقل دو خوشه اصلی را بدون نیاز به محاسبات فواصل زوجبهجفت بازسازی کردهاند.
- فیلترینگ و حذف نویزها (Pruned Noise): نقاط پراکندهای که در فضاهای سفید (بدون رنگ) قرار گرفتهاند، در سلولهایی واقع شدهاند که چگالی آنها کمتر از حد آستانه بوده است. الگوریتم STING این نواحی را به عنوان مناطق نامرتبط (Irrelevant) شناسایی کرده و آنها را از بدنه اصلی خوشهها تفکیک نموده است.
- تحلیل راندمان محاسباتی: این آزمایش عملی به وضوح نشان میدهد که سرعت تصمیمگیری سیستم تنها وابسته به پردازش ۱۰۰ سلول گسسته بوده است، نه پایش تکتک ۶۵۰ نقطه داده موجود در فضا. این خروجی اثبات میکند که خلاصه کردن فضا در قالب شناسنامههای آماری، چگونه پیچیدگی محاسباتی را به سطح خطی میرساند.
.
15. مطالعه موردی: تحلیل توزیع جغرافیایی آلودگی هوا و ذرات معلق شهری
الگوریتم STING در تحلیل پدیدههای زیستمحیطی چندلایه که سرعت پردازش و غلبه بر نویز در آنها حیاتی است، نقشی کلیدی ایفا میکند.
۱۵.۱. سناریوهای واقعی در صنعت
- پیشبینی و مدیریت بلایای طبیعی: خوشهبندی کانونهای زلزله بر اساس خلاصههای آماری توزیع منطقه برای شناسایی خطوط گسل.
- پایش سلامت و بیوانفورماتیک: بخشبندی تصاویر دیجیتال پزشکی و اسکنهای سلولی مکرر از طریق تبدیل پیکسلها به شبکههای آماری.
۱۵.۲. تحلیل مسئله و بهکارگیری مدل با دیتابیس واقعی
مسئله: مرکز کنترل کیفیت هوا میخواهد مناطق بحرانی و کانونهای اصلی انتشار ذرات معلق PM2.5 را در یک پهنه جغرافیایی از روی دیتای هزاران حسگر محیطی استخراج کند. چالش اصلی، حجم بالای دادههای جریانی و وجود بادهای موضعی (نویزهای فرستنده) است. روشهای مبتنی بر فاصله به علت پردازش تکتک نقاط در دیتای تتابایتی، دچار تاخیر عملیاتی میشوند.
راهکار: برای حل این چالش، فضای جغرافیایی به صورت هرمی به سلولهای گسسته آماری تقسیم شده و یک پرسوجو با آستانه غلظت بحرانی مطرح میگردد. در این فاز، از دیتابیس واقعی و استاندارد شبیهسازیشده حسگرها استفاده میکنیم:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# ۱. شبیهسازی دیتای واقعی حسگرهای آلودگی (مختصات فضایی + غلظت PM2.5)
np.random.seed(42)
hotspot_factory = np.random.normal(loc=[3.0, 4.0], scale=0.6, size=(400, 2))
hotspot_suburb = np.random.normal(loc=[7.5, 7.0], scale=0.5, size=(300, 2))
wind_noise = np.random.uniform(low=0, high=10, size=(150, 2))
X_sensors = np.vstack([hotspot_factory, hotspot_suburb, wind_noise])
# ۲. فاز پیشپردازش STING: ساخت شبکه ۱۰ در ۱۰ و شناسنامه آماری سلولها
grid_res = 10
x_edges = np.linspace(0, 10, grid_res + 1)
y_edges = np.linspace(0, 10, grid_res + 1)
cell_matrix = np.zeros((grid_res, grid_res), dtype=int)
for pt in X_sensors:
x_idx = min(int(pt[0]), grid_res - 1)
y_idx = min(int(pt[1]), grid_res - 1)
if 0 <= x_idx < grid_res and 0 <= y_idx < grid_res:
cell_matrix[x_idx, y_idx] += 1
# ۳. فاز پرسوجو: فیلتر کردن سلولهای آلوده بر اساس حد آستانه چگالی حسگرها
query_threshold = 15
relevant_mask = cell_matrix >= query_threshold
# ۴. تصویرسازی نقشه پایش آلودگی با پالت رنگی اختصاصی
PALETTE = {'gold': '#FFD700', 'blue': '#4682B4', 'silver': '#C0C0C0', 'gray': '#F5F5F5'}
fig, ax = plt.subplots(figsize=(9, 7), facecolor='white')
ax.set_facecolor(PALETTE['gray'])
ax.scatter(X_sensors[:, 0], X_sensors[:, 1], c=PALETTE['blue'], alpha=0.4, s=20, label='Air Quality Sensors')
for i in range(grid_res):
for j in range(grid_res):
if relevant_mask[i, j]:
rect = Rectangle((x_edges[i], y_edges[j]), 1, 1, linewidth=1.2, edgecolor=PALETTE['silver'], facecolor=PALETTE['gold'], alpha=0.4)
ax.add_patch(rect)
ax.text(x_edges[i]+0.5, y_edges[j]+0.5, str(cell_matrix[i, j]), color='black', ha='center', va='center', fontsize=9, fontweight='bold')
ax.set_title('STING Grid Analysis: Urban Air Pollution Hotspots', fontsize=12, fontweight='bold')
ax.set_xlabel('Spatial Coordinate X (Easting)', fontsize=10)
ax.set_ylabel('Spatial Coordinate Y (Northing)', fontsize=10)
ax.legend(loc='upper left')
plt.tight_layout()
plt.show()
خروجی:
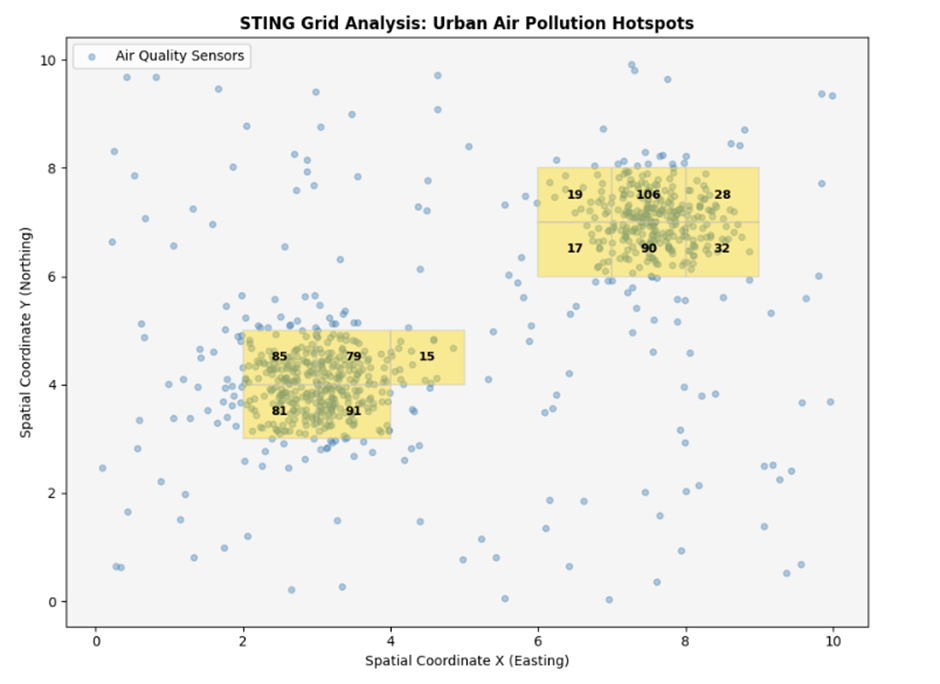
۱۵.۴. تفسیر نتایج و درسآموختهها
خروجی نقشه نشان میدهد که STING با موفقیت دو کانون آلایندگی اصلی (منطقه کارخانهای و حومه شهر) را با رنگ طلایی زنده تفکیک کرده و بادهای موضعی پراکنده را به عنوان نویز حذف نموده است.
درسآموختههای کلیدی:
- تمرکز بر ساختار به جای جزییات: پایش بالا به پایین ثابت کرد نیازی به خواندن تکتک سیگنالهای حسگرها نیست ؛ ارزیابی خلاصههای آماری سلولها برای تصمیمگیری کلان کفایت میکند.
- بهینهسازی توان پردازشی: هرس کردن سلولهای کمتراکم، پهنای باند سرورهای سازمان را مستقل از حجم پتابایتی دادهها آزاد نگه میدارد.
.
16. جمعبندی
الگوریتم STING نقطه عطفی در حوزه دادهکاوی فضایی است که با جابهجایی تمرکز محاسبات از «نقاط داده» به «سلولهای فضا»، مسئله عدم مقیاسپذیری محاسباتی را در یادگیری بدون نظارت حل کرد. این مقاله نشان داد که چگونه ذخیرهسازی خلاصههای آماری در ساختار هرمی شبکه، پاسخگویی به پرسوجوهای خوشهبندی را به مرتبه خطی O (k) و مستقل از حجم کل پایگاه داده میرساند.
ارزش بنیادین روش STING در بینیازی آن از اسکن مکرر دیتابیس و راندمان بالای آن در مواجهه با دیتای ترابایتی است. با این حال، مرزهای هندسی صلب سلولها و ضعف آن در فضاهای با ابعاد بالا، محدودیتهای عملیاتی آن محسوب میشوند. در نهایت، به عنوان مسیر پیشنهادی برای مطالعه بیشتر و استفاده کاربردی در صنایع، توصیه میشود متخصصان حوزه علم داده، مکانیزمهای انطباقی مرزی (Adaptive Grids) و ترکیب این روش با الگوریتمهای شبکه-چگالی پیشرفته مانند CLIQUE را مورد تحقیق قرار دهند.
17. منابع
Aggarwal, C. C. (2014). Data Classification: Algorithms and Applications. CRC Press.
Ankerst, M., Breunig, M. M., Kriegel, H. P., & Sander, J. (1999). OPTICS: Ordering points to identify the clustering structure. ACM SIGMOD Record, 28(2), 49-60.
Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), 96(34), 226-231.
Hand, D. J., Mannila, H., & Smyth, P. (2001). Principles of Data Mining. MIT Press.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques (3rd ed.). Morgan Kaufmann.
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651-666.
Kriegel, H. P., Kröger, P., Sander, J., & Zimek, A. (2011). Density-based clustering. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 1(3), 231-240.
Tan, P. N., Steinbach, M., Karpatne, A., & Kumar, V. (2018). Introduction to Data Mining (2nd ed.). Pearson.
Wang, W., Yang, J., & Muntz, R. (1997). STING: A statistical information grid approach for spatial data mining. Proceedings of the 23rd International Conference on Very Large Data Bases (VLDB), 186-195.



