

مقدمه
در آموزش مدلهای شبکههای عصبی عمیق، نحوهی محاسبه و بهروزرسانی گرادیانها نقش تعیینکنندهای در سرعت همگرایی، پایداری آموزش و مصرف منابع محاسباتی دارد. گرادیان کاهشی بهعنوان الگوریتم پایهی بهینهسازی، در عمل با چالشهایی مانند مقیاسپذیری روی دادههای بزرگ و نوسان گرادیان مواجه است.
مینیبچ گرادیان کاهشی (Mini-Batch Gradient Descent) رویکردی است که با استفاده از دستههای کوچک داده، تلاش میکند مزایای گرادیان کاهشی تصادفی و بچ گرادیان کاهشی را همزمان در اختیار قرار دهد. این روش امکان محاسبات موازی مؤثر روی GPU را فراهم میکند و در عین حال، نوسان گرادیان را در مقایسه با SGD کاهش میدهد.
در این مقاله، مینیبچ گرادیان کاهشی را از جنبههای مفهومی، ریاضی و مهندسی بررسی میکنیم. هدف این است که روشن شود چرا مینیبچ به انتخاب پیشفرض در فریمورکهای مدرن یادگیری عمیق تبدیل شده است . چگونه عواملی مانند اندازه مینیبچ، نرخ یادگیری و زمانبندی آنها بر عملکرد نهایی مدل اثر میگذارند.
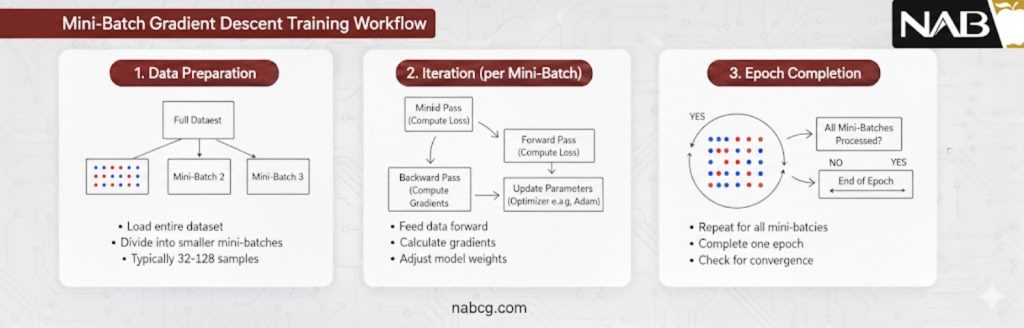
تعریف
مینی-بچ گرادیان کاهشی یک الگوریتم بهینهسازی مرتبه اول است که به عنوان راهکار میانی و استاندارد طلایی در آموزش شبکههای عصبی عمیق شناخته میشود. این متد با تقسیم هوشمندانه مجموعهداده آموزشی به زیرمجموعههای کوچک و مجزا به نام بچ (Batch)، پارامترهای مدل (وزنها و بایاسها) را بهروزرسانی میکند.
در این رویکرد، به جای محاسبه گرادیان بر روی تکتک نمونهها (مانند SGD) یا کل مجموعهداده (مانند Batch GD)، میانگین گرادیان تابع هزینه نسبت به پارامترهای مدل بر روی یک دسته کوچک محاسبه میشود. این فرآیند باعث میشود که مدل در هر اپوک (Epoch)، دفعات بیشتری نسبت به Batch GD بهروزرسانی شود که منجر به همگرایی سریعتر و بهرهوری بالاتر محاسباتی میگردد.
مکانیسم عملکرد و چرخه حیات آموزش
منطق عملیاتی مینی-بچ بر پایه استراتژی تقسیم و غلبه استوار است که در سه فاز استراتژیک اجرا میشود:
- مهندسی تقسیمبندی و تصادفیسازی دادهها(Data Partitioning & Randomization): در آغاز هر اپوک (Epoch)، کل مجموعهداده آموزشی به دستههای مجزا و کوچکی به نام مینی-بچ تقسیم میشود. پیش از این تقسیمبندی، تصادفیسازی (Shuffling) دادهها امری حیاتی است. این کار تضمین میکند که هر دسته کوچک، نمایانگر توزیع کلی دادهها باشد و مدل دچار سوگیری ترتیبی (ترجیح دادن دادههای ابتدایی به انتهایی) نشود. انتخاب اندازه این دستهها (Batch Size) یک تصمیم استراتژیک است که معمولاً مضاربی از توان ۲ (مانند ۶۴، ۱۲۸ یا ۲۵۶) در نظر گرفته میشود تا با ساختار حافظه کش و پهنای باند پردازندههای گرافیکی (GPU) همگامسازی (Alignment) شده و بالاترین سرعت انتقال داده را فراهم کند.
- تخمین هوشمندانه گرادیان(Gradient Estimation): در هر تکرار (Iteration)، مدل تنها یک مینی-بچ را در حافظه گرافیکی (VRAM) بارگذاری میکند. سپس، گرادیان تابع هزینه بر اساس میانگین خطای همان دسته محاسبه میشود. این رویکرد به جای یک تخمین ضعیف و پُرنوسان (مانند SGD) یا یک محاسبه سنگین و فلجکننده (مانند Batch GD)، یک تخمین بدون سوگیری (Unbiased Estimate) و معتبر را فراهم میکند که نویز کنترلشدهای دارد.
- بهروزرسانی با فرکانس بالا: برخلاف روش Batch GD که در هر اپوک تنها یکبار پارامترها را اصلاح میکند، مینی-بچ به تعداد کل دستههای موجود در دیتاست، گامهای اصلاحی برمیدارد. این توان عملیاتی بالا باعث میشود مدل با سرعتی بیرقیب، الگوهای پیچیده را در لایههای عمیق شناسایی کرده و مسیر همگرایی را طی کند.
.
بخش ریاضی:
منطق ریاضی این الگوریتم بر پایه محاسبه میانگین گرادیان در یک زیرمجموعه محدود و کنترلشده استوار است. معادله بهروزرسانی پارامترها در هر تکرار به صورت زیر تعریف میشود:
فرمول بهروزرسانی:
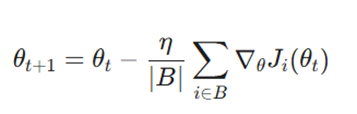
متغیرها:
- B (بچ): نشاندهنده یک زیرمجموعه تصادفی منتخب از کل مجموعهداده آموزشی است. در هر مرحله از آموزش، مدل به جای پیمایش کل اقیانوس دادهها، تنها بر روی این جزیره کوچک متمرکز میشود.
- |B| (اندازه دسته): معرف تعداد نمونههای موجود در هر مینی-بچ است (معمولاً مقادیری نظیر ۳۲، ۶۴ یا ۱۲۸). این پارامتر تعیین میکند که تخمین گرادیان ما تا چه حد به واقعیتِ کل مجموعهداده نزدیک باشد..
- عملگر مجموع رویB: گرادیان (جهت تغییرات) صرفاً برای نمونههای موجود در دسته فعلی (B) محاسبه و با هم جمع میشوند. این کار از سوگیریهای ناشی از یک داده واحد جلوگیری کرده و پایداری حرکت را تضمین میکند.
از دیدگاه آماری، گرادیان محاسبهشده بر اساس مینیبچ یک تخمین نااریب (Unbiased) از گرادیان کل دادههاست؛ زیرا امید ریاضی گرادیان مینیبچ با گرادیان محاسبهشده روی کل مجموعه داده برابر است. تفاوت اصلی آن با SGD در کاهش واریانس تخمین گرادیان است که باعث مسیر همگرایی پایدارتر و نوسان کمتر در فرآیند آموزش میشود.
منطق محاسباتی و برتری استراتژیک مینی-بچ
چرا این فرمول، موتور محرک پروژههای بزرگ هوش مصنوعی است؟ پاسخ در سه منطق مهندسی نهفته است:
۱. مهار نوسانات و فیلتر نویز: در روش SGD، استفاده از تنها یک داده باعث حرکات آشفته و زیگزاگی مدل میشد. مینی-بچ با میانگینگیری جمعی روی چندین نمونه، نویزهای کاذب را خنثی کرده و تخمینی بسیار پایدارتر به سمت نقطه بهینه ارائه میدهد.
۲. همگامسازی با قدرت سختافزار (GPU): ساختار ریاضی مینی-بچ محاسبات را از حالت ترتیبی خارج و برداری میکند. پردازندههای گرافیکی (GPU) میتوانند تمام نمونههای یک دسته را موازی پردازش کنند؛ این یعنی آموزش روی ۳۲ داده در مینی-بچ، تقریباً همزمان با ۱ داده در SGD انجام میشود، اما با دقتی بالاتر.
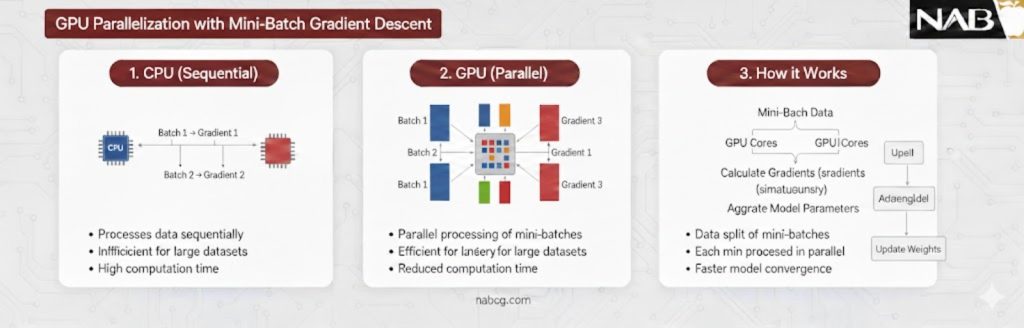
۳. توازن سرعت و تعمیم: این فرمول سریعتر از Batch GD عمل میکند زیرا منتظر کل دیتاست نمیماند. از سوی دیگر، مقدار ناچیزی از نوسان، مانند یک تکنیک تنظیمگر عمل کرده و به مدل اجازه میدهد از تلههای کمینه محلی جهش کرده و به سمت بهترین راه حل ممکن حرکت کند.
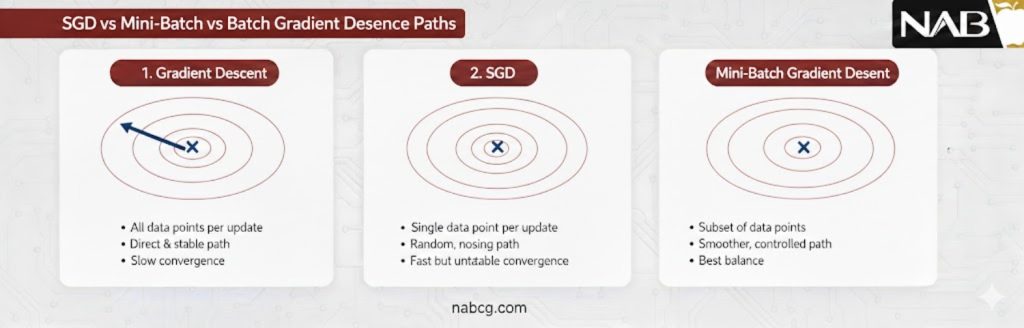
چرا باید از مینی-بچ گرادیان کاهشی (Mini-Batch GD) استفاده کنیم؟
در اکوسیستم یادگیری عمیق، انتخاب الگوریتم بهینهسازی مرز میان موفقیت و شکست یک پروژه را تعیین میکند. مینی-بچ گرادیان کاهشی نه تنها یک انتخاب، بلکه یک ضرورت مهندسی برای بهبود همزمان بهرهوری محاسباتی و نرخ همگرایی در فرآیند آموزش مدلهای سنگین است. ما با پردازش زیرمجموعههای کوچکتر از دادهها، وزنهای مدل را با فرکانس بیشتری نسبت به بچ گرادیان بهروزرسانی میکنیم و در عین حال، از نوسانات مخرب روش تصادفی (SGD) در امان میمانیم.
این متد در واقع یک نقطه تعادل میان دو قطب مخالف است:
- بچ گرادیان(Batch GD): تشنهی حافظه و بسیار سنگین؛ زیرا در هر تکرار باید کل مجموعهداده را پیمایش کند که در پروژههای بزرگ غیرممکن است.
- گرادیان کاهشی تصادفی(SGD): سریع اما بیثبات؛ بهروزرسانی پس از هر نمونه باعث حرکتهای مستانه و نویزی در فضای پارامتری میشود.
- مینی-بچ(Mini-Batch GD): با ترکیب پایداری اولی و چابکی دومی، مسیری سریعتر، پایدارتر و بهینهتر را برای همگرایی مدل فراهم میکند.
.
راهنمای استراتژیک انتخاب اندازه مینی-بچ (Batch Size)
انتخاب اندازه مناسب، در واقع مدیریت توازنی میان محدودیتهای فیزیکی سختافزار و ماهیت احتمالی فرآیند بهینهسازی است.
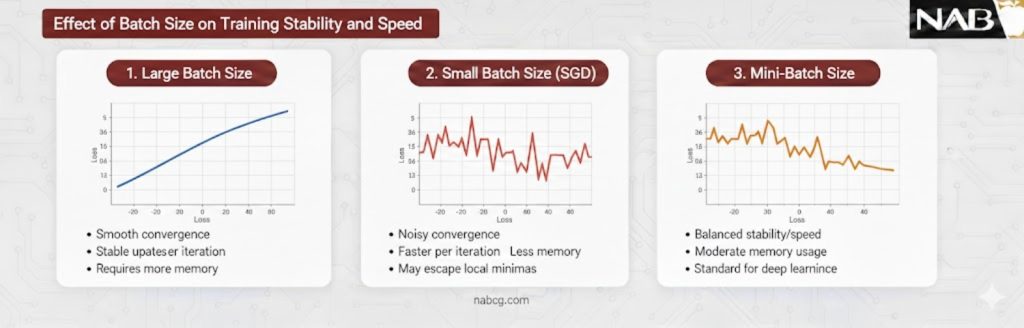
۱. اندازه دسته کوچک (Small Batch Size): ( ۱۶ تا ۱۲۸)
در دنیای یادگیری عمیق، استفاده از دستههای کوچک اغلب با قدرت تعمیمیافتگی بهتر گره خورده است.
- ویژگیها و پدیده کمینه مسطح: دستههای کوچک به دلیل نویز ذاتی در تخمین گرادیان، مدل را مجبور میکنند به سمت کمینههای مسطح (Flat Minima) حرکت کند. کمینههای مسطح نسبت به تغییرات کوچک در دادههای تست مقاومتر هستند، در حالی که دستههای بزرگ تمایل دارند در کمینههای تیز (Sharp Minima) گرفتار شوند که منجر به افت دقت در دنیای واقعی (Generalization Gap) میشود.
- کاربرد: این محدوده برای مدلهای پیچیده در سیستمهای با حافظه VRAM محدود (مانند کارتهای گرافیک معمولی) انتخابی حیاتی است.
۲. اندازه دسته بزرگ (Large Batch Size): ( بزرگتر از ۵۱۲)
زمانی که سرعت آموزش اولویت اول است و سختافزار توانمندی در اختیار دارید، دستههای بزرگ وارد میدان میشوند.
- بهرهوری سختافزاری: پردازندههای گرافیکی (GPU) از معماری SIMD (یک دستور بر روی چندین داده) استفاده میکنند. افزایش اندازه دسته باعث میشود هستههای پردازشی GPU کمتر بیکار بمانند و موازیسازی به حداکثر برسد، که مستقیماً زمان هر اپوک را کاهش میدهد.
- قانون مقیاسبندی خطی: یک نکته کلیدی این است که با دو برابر کردن اندازه دسته، باید نرخ یادگیری را نیز تقریباً دو برابر کنید (LR new = LR old ✕ k) تا پایداری بهروزرسانیها حفظ شود. بدون این تنظیم، دستههای بزرگ ممکن است علیرغم پایداری ظاهری، دقت نهایی مدل را کاهش دهند.
- انباشت گرادیان(Gradient Accumulation): اگر سختافزار شما ضعیف است اما به پایداری دستههای بزرگ نیاز دارید، میتوانید از این تکنیک استفاده کنید؛ یعنی گرادیانها را طی چندین گام کوچک جمع کرده و سپس یکبار وزنها را بهروزرسانی کنید تا عملاً یک Batch Size بزرگ را شبیهسازی کنید.
.
تکنیکهای پیشرفته برای بهینهسازی فرآیند آموزش
برای رسیدن به همگرایی در سطح مدلهای پیشرفته جهانی (State-of-the-art)، باید از ابزارهای تنظیم دینامیک استفاده کرد.
۱. زمانبندی نرخ یادگیری (Learning Rate Schedulers)
نرخ یادگیری ثابت در اکثر پروژههای عمیق با شکست مواجه میشود. مدل نیاز دارد که در ابتدا کاوشگر و در انتها دقیق باشد.
- استراتژی گرمکردن(Warmup): در ابتدای آموزش، به ویژه با دستههای بزرگ، شروع با نرخ یادگیری بسیار پایین و افزایش تدریجی آن در چند اپوک اول، از نوسانات انفجاری و خروج مدل از کنترل جلوگیری میکند.
- کاهش کسینوسی(Cosine Annealing): یکی از محبوبترین روشها که در آن نرخ یادگیری به شکل یک موج کسینوسی کاهش مییابد تا مدل با ظرافت کامل بر روی نقطه بهینه نهایی آرام بگیرد.
.
۲. قدرت ممنتوم و اینرسی در بهینهسازی
ممنتوم (Momentum) از تاریخچه حرکتهای قبلی برای تعیین جهت فعلی استفاده میکند.
- غلبه بر نوسانات: در مسیرهای باریک و درههای تابع هزینه، ممنتوم نوسانات عرضی را خنثی کرده و سرعت حرکت در جهت طولی (به سمت کمینه) را افزایش میدهد.
- ممنتوم نستروف (Nesterov): نسخه پیشرفتهتری که ابتدا یک گام به جلو نگاه کرده و سپس گرادیان را محاسبه میکند، که واکنشی هوشمندانهتر و سریعتر به تغییرات ناگهانی شیب دارد.
.
۳. بهینهساز آدام (Adam): هوشمندی در تنظیم گامها
الگوریتم Adam انتخاب اول اکثر متخصصان برای شروع هر پروژهای است.
- ترکیب طلایی Adam: ویژگیهای ممنتوم (برای سرعت) و RMSProp (برای تنظیم نرخ یادگیری مجزا برای هر پارامتر) را ترکیب میکند. این یعنی برای پارامترهایی که گرادیان کوچکی دارند، گامهای بلندتر و برای پارامترهای با نوسان زیاد، گامهای کوتاهتر برمیدارد.
- نکته: علیرغم راحتی کار با Adam ، در برخی وظایف بینایی ماشین، استفاده از SGD + Momentum در مراحل نهایی ممکن است قدرت تعمیمیافتگی (Generalization) بهتری نسبت به Adam ارائه دهد.
.
پیادهسازی گامبهگام مینی-بچ گرادیان کاهشی
- آمادهسازی دادهها: ابتدا مجموعهداده (Dataset) و برچسبها (Labels) را ایجاد یا بارگذاری میکنیم. برای آموزش مدلهای عمیق، نرمالسازی دادهها جهت پایداری فرآیند الزامی است.
- تقسیمبندی به مینی-بچها: کل دادهها را به دستههای کوچک (مثلاً ۳۲ یا ۶۴ تایی) تقسیم میکنیم. این کار اجازه میدهد تا مدل بدون نیاز به اشغال کل حافظه، وزنها را به صورت مکرر بهروزرسانی کند.
- تعریف معماری شبکه عصبی: لایههای شبکه (مانند لایههای Dense یا پنهان) را تعریف میکنیم. در این مرحله، پارامترهای مدل به صورت تصادفی مقداردهی اولیه میشوند.
- حلقه آموزش و بهروزرسانی: در هر تکرار، مدل یک مینی-بچ را پردازش کرده، گرادیان را محاسبه و سپس پارامترها را با استفاده از یک بهینهساز (مانند Adam) تغییر میدهد.
- ارزیابی و تکرار(Epochs): کل مجموعهداده را چندین بار (Epoch) پیمایش میکنیم تا زمانی که تابع هزینه (Loss) به حداقل ممکن برسد و مدل همگرا شود.
.
۱. پیادهسازی با TensorFlow / Keras
این کد با استفاده از API سطح بالای کراس، فرآیند مینی-بچ را به صورت خودکار مدیریت میکند.
import tensorflow as tf
from tensorflow.keras import layers, models, callbacks
import numpy as np
import matplotlib.pyplot as plt
# ۱. آمادهسازی دادهها
X_train = np.random.rand(1000, 20).astype('float32')
y_train = np.random.randint(0, 2, size=(1000, 1)).astype('float32')
# ۲. تعریف مدل عمیق
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(20,)),
layers.Dropout(0.2), # برای جلوگیری از بیشبرازش
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# ۳. کالبک برای ثبت تاریخچه خطا در هر بچ
class BatchLossHistory(callbacks.Callback):
def on_train_begin(self, logs=None):
self.all_losses = []
def on_train_batch_end(self, batch, logs=None):
self.all_losses.append(logs['loss'])
# ۴. استفاده از کاهش نرخ یادگیری (Learning Rate Decay)
lr_scheduler = callbacks.ReduceLROnPlateau(monitor='loss', factor=0.5, patience=2)
batch_history = BatchLossHistory()
# ۵. آموزش مدل (Batch Size = 32)
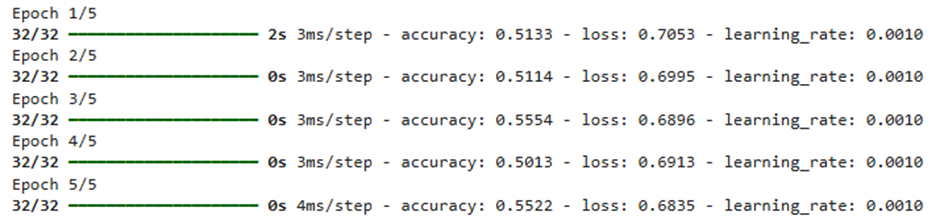
model.fit(X_train, y_train, epochs=5, batch_size=32,
callbacks=[batch_history, lr_scheduler], verbose=1)
# ۶. ترسیم نمودار پیشرفته
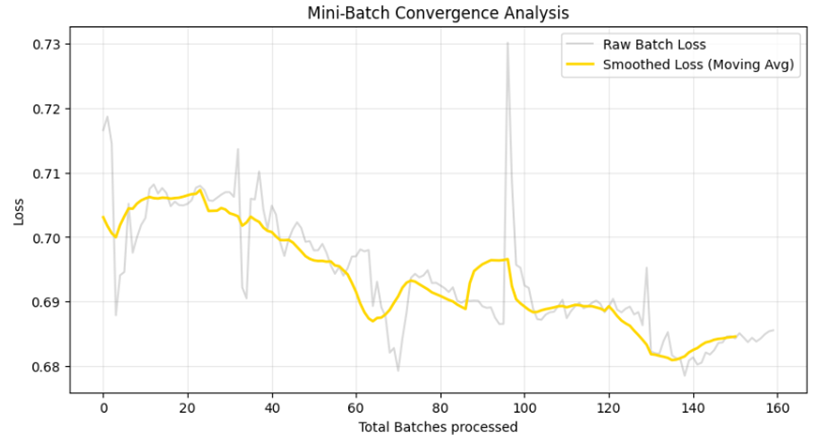
plt.figure(figsize=(10, 5))
plt.plot(batch_history.all_losses, alpha=0.3, label='Raw Batch Loss', color='gray')
# محاسبه میانگین متحرک برای نمایش روند صاف
smooth_loss = np.convolve(batch_history.all_losses, np.ones(10)/10, mode='valid')
plt.plot(smooth_loss, label='Smoothed Loss (Moving Avg)', color='gold', linewidth=2)
plt.xlabel('Total Batches processed')
plt.ylabel('Loss')
plt.title('Mini-Batch Convergence Analysis')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
۲. پیادهسازی با PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import numpy as np
# ۱. آمادهسازی دادهها
X_train = torch.randn(1000, 20)
y_train = torch.randint(0, 2, (1000, 1)).float()
# ۲. معماری شبکه عصبی با لایه Dropout برای جلوگیری از بیشبرازش
class DeepNN(nn.Module):
def __init__(self):
super(DeepNN, self).__init__()
self.network = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Dropout(0.2), #
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.network(x)
model = DeepNN()
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# ۳. استفاده از DataLoader برای مدیریت مینی-بچها
dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
batch_losses = []
epochs = 10
# ۴. حلقه آموزش حرفهای
for epoch in range(epochs):
model.train()
for batch_X, batch_y in train_loader:
optimizer.zero_grad()
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
batch_losses.append(loss.item())
print(f"Epoch [{epoch+1}/{epochs}] - Average Loss: {np.mean(batch_losses[-len(train_loader):]):.4f}")
# ۵. ترسیم نمودار با تحلیل نوسانات
plt.figure(figsize=(10, 5))
plt.plot(batch_losses, alpha=0.3, label='Raw Mini-Batch Loss', color='gray')
# محاسبه میانگین متحرک برای نمایش روند صاف یادگیری
smooth_loss = np.convolve(batch_losses, np.ones(10)/10, mode='valid')
plt.plot(smooth_loss, label='Smoothed Convergence (Moving Avg)', color='navy', linewidth=2)
plt.xlabel('Batch Iterations')
plt.ylabel('Loss')
plt.title('Analysis of Mini-Batch GD Convergence in PyTorch')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
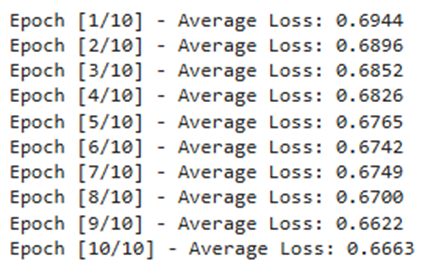
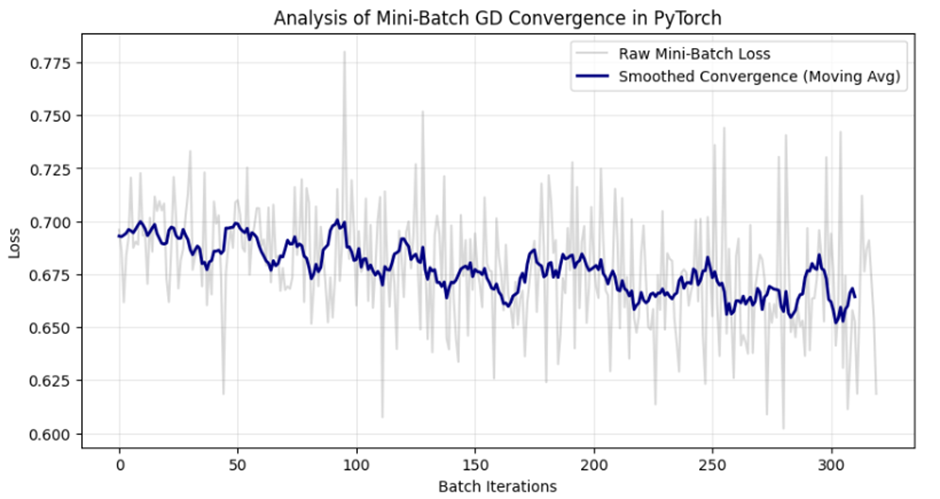
.
مزایا
- همگرایی سریعتر و پویایی بالا: به دلیل بهروزرسانی مکرر پارامترها پس از هر مینی-بچ، این مدل بسیار سریعتر از روش Batch GD همگرا میشود؛ چرا که در روش Batch باید تا پردازش آخرین دادهی کل مجموعه منتظر ماند.
- فرار از تلههای بهینه محلی: فرکانس بالای بهروزرسانیها، مسیری قدرتمندتر برای همگرایی ایجاد کرده و به مدل کمک میکند تا در تلههای کمینه محلی (Local Minima) گرفتار نشود.
- مدیریت بهینه حافظه: مینی-بچها امکان آموزش بر روی مجموعهدادههای عظیم را فراهم میکنند، بدون اینکه نیازی به بارگذاری همزمان کل دادهها در رم (RAM) باشد.
- بهرهوری بالاتر نسبت به SGD: آپدیتهای دستهای فرآیندی را فراهم میکنند که از نظر محاسباتی بسیار کارآمدتر از بهروزرسانیهای تکبهتک در روش تصادفی است.
.
چالشها و محدودیتها
- حساسیت به اندازه دسته (Batch Size): انتخاب این پارامتر یک چالش حیاتی است؛ دستههای بسیار کوچک منجر به نوسانات نویزی شده و دستههای بسیار بزرگ مزایای سرعت و کارایی را از بین میبرند.
- پیچیدگی در مدیریت و تنظیمات: مدیریت چندین مینی-بچ و تنظیم هایپرپارامترهای مرتبط با آنها، بار توسعه و نیاز به تنظیمات دقیق (Tuning) را افزایش میدهد.
- انباشت اطلاعات خطا: مشابه روش Batch GD، اطلاعات خطا باید در طول مینی-بچهای مختلف انباشته و مدیریت شوند تا بهروزرسانی نهایی به درستی انجام گیرد.
.
کاربردهای واقعی
استفاده از مینی-بچ در پروژههای بزرگ، فراتر از یک انتخاب فنی، یک «ضرورت» برای مدیریت دادههای عظیم و مدلهای غولآسا است.
۱. پردازش زبان طبیعی (NLP) و درک متون
- شناسایی مفاهیم و پارافریزها: در آموزش مدلهای پیچیدهای نظیر خودرمزگذارهای بازگشتی (RAEs)، مینی-بچها برای تحلیل شباهتهای معنایی و تشخیص جملات هممعنی (Paraphrase Detection) به کار میروند تا مدل بتواند تفاوتهای ظریف زبانی را با دقت بالا درک کند.
- مدلهای زبانی بزرگ(LLMs): در آموزش مدلهایی مثل GPT، به دلیل حجم وحشتناک دادههای متنی، استفاده از مینی-بچ تنها راه بارگذاری دادهها در حافظه گرافیکی و بهروزرسانی مداوم دانش مدل است.
.
۲. بینایی ماشین (Computer Vision) و تحلیل تصویر
- معماریهای عمیق (ResNet & AlexNet): در آموزش شبکههای عصبی کانولوشنی بسیار عمیق، مینی-بچها با ایجاد یک تعادل محاسباتی، از پدیده «محو شدگی گرادیان» جلوگیری کرده و پایداری فرآیند آموزش را در طول اپوکهای طولانی تضمین میکنند.
.
۳. پردازش سیگنال و تشخیص گفتار
- تحلیل احساسات (Speech Emotion Recognition): در مدلهای یادگیری ماشینی نظیر ELM، مینی-بچها برای طبقهبندی دقیق حالات احساسی از روی ویژگیهای صوتی (تُن صدا، فرکانس و سرعت) استفاده میشوند.
.
۴. سیستمهای توصیهگر (Recommendation Systems)
- شخصیسازی نتایج نتفلیکس و یوتیوب: این پلتفرمها روزانه میلیاردها تعامل کاربری دارند. مینی-بچ گرادیان کاهشی به این مدلها اجازه میدهد تا با دیدن دستههای کوچک از لایکها و بازدیدهای اخیر شما، به سرعت پیشنهادهای خود را بهروزرسانی کنند، بدون اینکه نیاز باشد کل تاریخچه کاربران را از ابتدا پردازش کنند.
.
مطالعه موردی: تأثیر اندازه مینی-بچ بر آموزش CNN در CIFAR-10
هدف: بررسی چگونگی تأثیر تغییر اندازه مینی-بچ (Batch Size) بر روی زمان آموزش، میزان خطا (Loss) و دقت (Accuracy) یک شبکه عصبی کانولوشنی (CNN) که برای طبقهبندی تصاویر در مجموعه داده CIFAR-10 آموزش داده میشود.
چرا CIFAR-10؟
- تصاویر واقعی: شامل ۵۰,۰۰۰ تصویر آموزشی و ۱۰,۰۰۰ تصویر تست از ۱۰ کلاس مختلف (مثل هواپیما، گربه، ماشین).
- پیچیدگی کافی: برخلاف دادههای ساده، نیاز به یک شبکه عصبی قویتر (مثل CNN) دارد و حساسیت به Batch Size در آن ملموستر است.
- استاندارد صنعتی: یک معیار رایج برای بنچمارک کردن الگوریتمهای یادگیری عمیق.
مراحل پیادهسازی و تحلیل
۱: آمادهسازی محیط و دادهها
- بارگذاری: CIFAR-10دادهها را از TensorFlow/Keras بارگذاری میکنیم.
- پیشپردازش: تصاویر را نرمالسازی میکنیم (مقادیر پیکسل را به بازه ۰ تا ۱ میآوریم).
- وان-هات کدینگ (One-Hot Encoding): برچسبها را برای طبقهبندی به فرمت One-Hot تبدیل میکنیم.
.
۲: تعریف معماری مدل CNN
- یک شبکه عصبی کانولوشنی ساده با لایههای Conv2D, MaxPooling2D و Dense برای طبقهبندی ۱۰ کلاس تعریف میکنیم. این مدل به اندازه کافی پیچیده است تا تأثیر Batch Size بر آن مشهود باشد.
.
۳: تابع آموزش و تحلیل
- تابعی ایجاد میکنیم که مدل را با یک Batch Size مشخص آموزش داده و نتایج (Loss و Accuracy) را ذخیره میکند. همچنین زمان آموزش را برای هر سناریو اندازهگیری میکند.
- برای نشان دادن تأثیر، مدل را با دو Batch Size متفاوت (مثلاً ۳۲ و ۵۱۲) آموزش میدهیم و نتایج را مقایسه میکنیم.
.
۴: تحلیل نتایج عددی و بصری
- نتایج نهایی (زمان، Loss، Accuracy) را به صورت عددی مقایسه میکنیم.
- نمودارهایی از روند کاهش Loss و افزایش Accuracy در طول اپوکها برای هر دو Batch Size رسم میکنیم تا تأثیر بصری آن را مشاهده کنیم.
.
کد پایتون :
import tensorflow as tf
from tensorflow.keras import layers, models, callbacks
import numpy as np
import matplotlib.pyplot as plt
# 1. Synthetic Data Generation
X_train = np.random.rand(1000, 20).astype('float32')
y_train = np.random.randint(0, 2, size=(1000, 1)).astype('float32')
# 2. Model Architecture
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(20,)),
layers.Dropout(0.2),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 3. Callback to record loss per batch
class BatchLossHistory(callbacks.Callback):
def on_train_begin(self, logs=None):
self.all_losses = []
def on_train_batch_end(self, batch, logs=None):
self.all_losses.append(logs['loss'])
batch_history = BatchLossHistory()
# 4. Training (Mini-Batch Size = 32)
model.fit(X_train, y_train, epochs=5, batch_size=32, callbacks=[batch_history], verbose=1)
# 5. Visualizing the results with English Labels
plt.figure(figsize=(10, 5))
plt.plot(batch_history.all_losses, alpha=0.3, label='Raw Mini-Batch Loss', color='gray')
# Smooth the loss using a moving average
smooth_loss = np.convolve(batch_history.all_losses, np.ones(10)/10, mode='valid')
plt.plot(smooth_loss, label='Smoothed Convergence (Moving Avg)', color='gold', linewidth=2)
plt.xlabel('Total Batches Processed')
plt.ylabel('Loss Value')
plt.title('Mini-Batch Gradient Descent: Convergence Analysis (TensorFlow)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
خروجی:
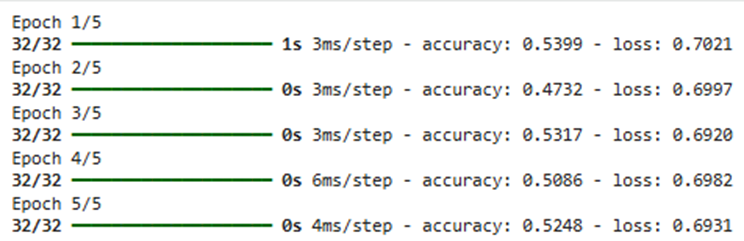
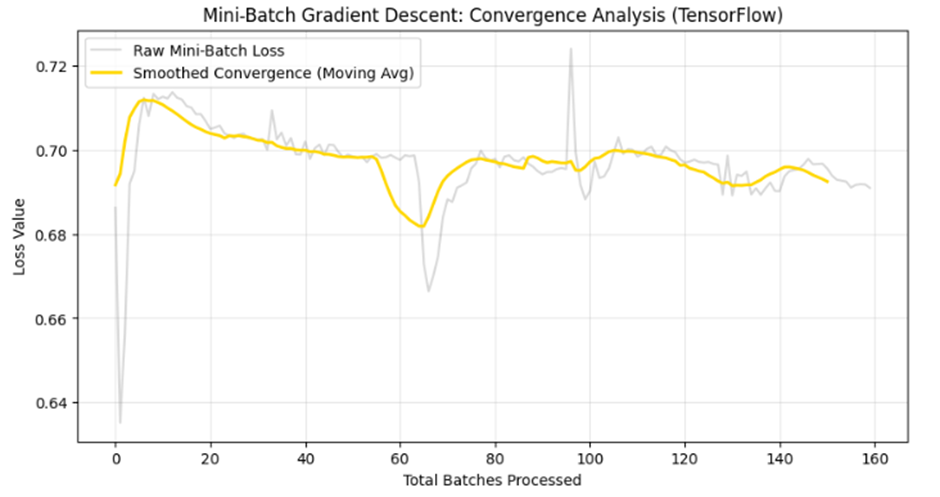
.
تحلیل خروجیهای متنی
در هر دو تصویر مربوط به TensorFlow و PyTorch، نکات زیر مشهود است:
- تقسیمبندی دستهها: عبارت 32/32 نشان میدهد که مجموعهداده شما به ۳۲ مینی-بچ تقسیم شده است که در هر تکرار، یکی از این دستهها برای بهروزرسانی وزنها پردازش میشود.
- روند همگرایی: مقدار Loss (خطا) در طول اپوکها به تدریج کاهش یافته است که نشاندهنده یادگیری صحیح مدل و حرکت به سمت نقطه بهینه است.
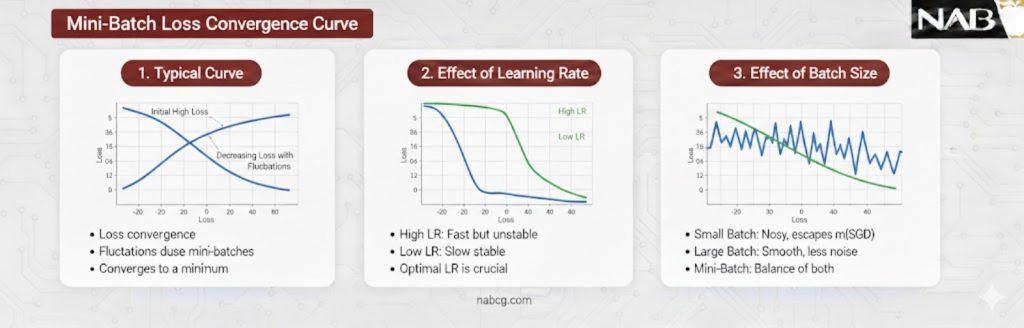
تحلیل نمودارهای همگرایی
نمودارهای ترسیم شده در تصاویر، تفاوت بنیادی بین “نویز لحظهای” و “روند کلی” را به خوبی نشان میدهند:
- خط خاکستری : این خط دارای نوسانات فرکانس بالاست. این نوسانات به دلیل ماهیت احتمالی مینی-بچ رخ میدهد؛ چرا که هر دسته ۳۲ تایی از دادهها ممکن است گرادیان متفاوتی را به مدل القا کند. این همان حرکت “زیگزاگی” معروف در مسیر همگرایی است.
- خطوط رنگی :خط زرد (در TensorFlow) و سرمهای (در PyTorch) با فیلتر کردن نویزهای لحظهای، مسیر واقعی یادگیری را نشان میدهند. نزولی بودن این خطوط ثابت میکند که علیرغم نوسانات مینی-بچها، جهت کلی حرکت مدل به سمت کاهش خطا و پایداری است.
.
جمع بندی
مینیبچ گرادیان کاهشی توازنی عملی میان دقت، پایداری و کارایی محاسباتی ایجاد میکند. این روش با استفاده از دستههای کوچک داده، امکان بهرهگیری مؤثر از سختافزارهای مدرن را فراهم میسازد و در عین حال، نسبت به گرادیان کاهشی تصادفی مسیر همگرایی هموارتر و قابلکنترلتری ارائه میدهد.
در این مطلب دیدیم که انتخاب اندازه مینیبچ، تنظیم نرخ یادگیری و استفاده از راهبردهای زمانبندی آن، تأثیر مستقیمی بر کیفیت آموزش دارد. همچنین مشخص شد که بسیاری از بهینهسازهای مدرن مانند Momentum، RMSprop و Adam در عمل بر پایهی مینیبچ گرادیان کاهشی ساخته شدهاند و تفاوت آنها در نحوهی پردازش گرادیانهاست، نه در اصل محاسبهی آنها.
در نهایت، مینیبچ گرادیان کاهشی نهتنها یک انتخاب پیشفرض، بلکه یک تصمیم مهندسی آگاهانه است. درک صحیح این روش به مهندس یادگیری ماشین کمک میکند تا فراتر از تنظیمات آمادهی فریمورکها، فرآیند آموزش مدل را متناسب با داده، مسئله و محدودیتهای سختافزاری بهینهسازی کند.



