

1.مقدمه
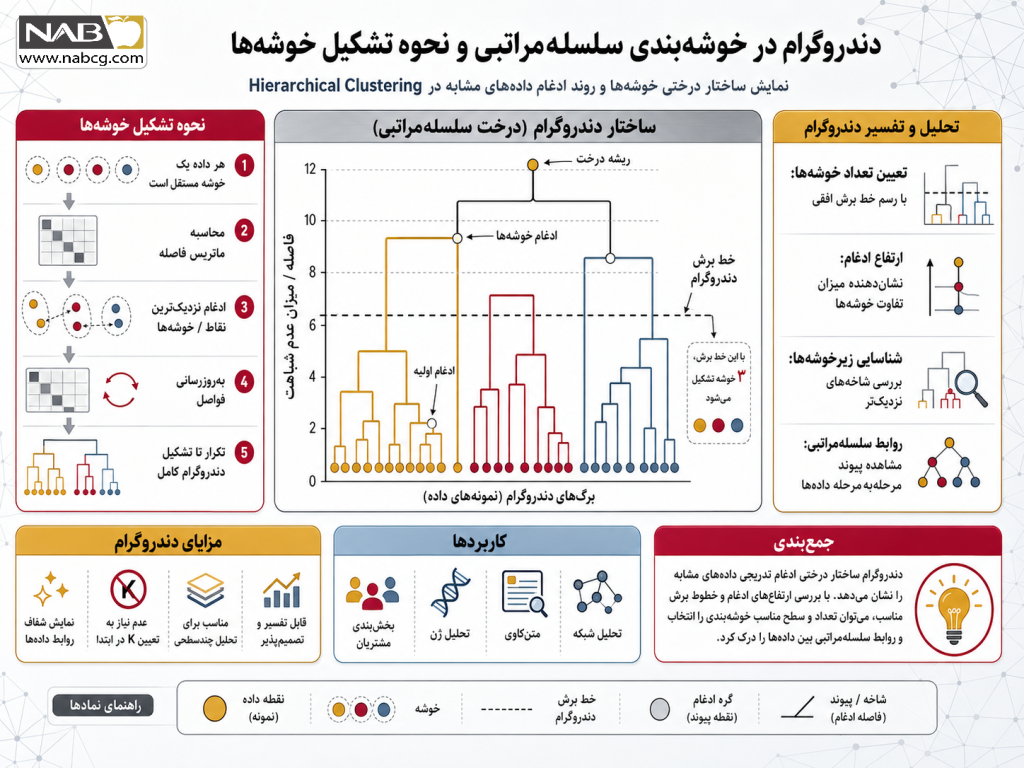
خوشهبندی (Clustering) یکی از مهمترین شاخههای یادگیری بدون نظارت است که با هدف کشف ساختارهای پنهان در دادهها به کار میرود. در میان روشهای مختلف خوشهبندی، خوشهبندی سلسلهمراتبی (Hierarchical Clustering) جایگاه ویژهای دارد؛ زیرا علاوه بر گروهبندی دادهها، روابط و سطوح شباهت میان نمونهها را نیز در قالب یک ساختار درختی نمایش میدهد. این ویژگی باعث میشود تحلیلگران بتوانند علاوه بر مشاهده خوشههای نهایی، فرآیند شکلگیری آنها را نیز بررسی کنند.
برخلاف الگوریتمهایی مانند K-Means که نیازمند تعیین تعداد خوشهها پیش از اجرا هستند، خوشهبندی سلسلهمراتبی ابتدا ساختار کامل ارتباطات میان دادهها را ایجاد کرده و سپس امکان انتخاب سطح مناسب تفکیک را در اختیار کاربر قرار میدهد. خروجی این فرآیند در قالب دندروگرام (Dendrogram) نمایش داده میشود که یکی از ارزشمندترین ابزارهای بصری برای تحلیل روابط میان دادهها محسوب میشود.
این الگوریتم در حوزههای متنوعی از جمله بیوانفورماتیک، تحلیل ژنتیک، بازاریابی، پردازش زبان طبیعی، سیستمهای توصیهگر و امنیت سایبری کاربرد گستردهای دارد. در این مقاله، مفاهیم بنیادی خوشهبندی سلسلهمراتبی، انواع روشهای اتصال، معیارهای فاصله، نحوه تفسیر دندروگرام، پیادهسازی عملی در پایتون و کاربردهای صنعتی آن بهصورت جامع بررسی میشوند.
2.تعریف
خوشهبندی سلسلهمراتبی یکی از مقتدرترین و بنیادینترین الگوریتمهای یادگیری ماشین بدون نظارت (Unsupervised Learning) است که با هدف تبدیل مشاهدات ناهمگون (Heterogeneous) به گروههای همگون (Homogeneous) استفاده میشود. از آنجا که این الگوریتم بدون نظارت است، روی دادههای بدون برچسب (Unlabeled) اجرا شده و صرفاً بر اساس سنجش میزان شباهت یا عدم شباهت فیزیکی میان دادهها، آنها را دستهبندی میکند.
ویژگی منحصربهفرد این معماری، ساخت یک سلسلهمراتب چندسطحی و درختی از خوشههای تودرتو (Nested Clusters) است؛ به طوری که برخلاف روشهایی مانند K-Means، هیچگونه نظم خطی صلب را به فضا تحمیل نکرده و برای شروع فرآیند، نیازی به تعیین پیشفرض تعداد خوشهها (K) ندارد.
.
مثال
فرض کنید یک بانک بزرگ میخواهد متقاضیان وام خود را دستهبندی کند تا خدمات بهتری به آنها ارائه دهد. در ابتدا ما با یک جمعیت ناهمگون از افراد با اهداف مختلف روبهرو هستیم:
- چند دانشجو برای وام تحصیلی درخواست دادهاند.
- چند کارمند برای خرید مسکن وام میخواهند.
- چند سرمایهگذار به دنبال وام تجاری هستند.
الگوریتم خوشهبندی سلسلهمراتبی بدون اینکه از قبل بدانند این افراد چه کسانی هستند، ویژگیهای آنها (مانند سن، درآمد و میزان تراکنش) را تحلیل میکند.
در رویکرد تراکمی، الگوریتم ابتدا هر فرد را یک خوشه میبیند. در گام بعدی، دو دانشجویی که رفتارهای مالیشان بسیار به هم نزدیک است را در یک گروه کوچک قرار میدهد. سپس این گروه دانشجویی را با سایر دانشجویان ادغام کرده و یک کلاستر صلب به نام «خوشه دانشجویان» میسازد. به همین ترتیب، کارمندان و سرمایهگذاران نیز در شاخههای مجزای درخت دندروگرام قرار میگیرند. در نهایت، بانک با نگاه به این ساختار درختی میتواند دقیقاً متوجه شود چند گروه مشتری واقعی دارد و بسته تبلیغاتی هر گروه را به صورت اختصاصی طراحی کند.
.
3.دلایل اهمیت استفاده از الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
در تحلیل ساختار دیتابیسهای مدرن، انتخاب یک الگوریتم خوشهبندی مقتدر فراتر از یک تصمیم فنی ساده، یک ضرورت استراتژیک برای درک هندسه پنهان فضا است. معماری خوشهبندی سلسلهمراتبی (Hierarchical Clustering) به دلایل زیر نقشی حیاتی و بیجایگزین در خط لوله یادگیری ماشین بدون نظارت ایفا میکند:
کشف توپولوژی تودرتو و روابط چندسطحی دادهها
بزرگترین ضرورت استفاده از این الگوریتم، توانایی منحصربهفرد آن در مدلسازی فضا به صورت چندسطحی (Granularity) است. در دنیای واقعی، دادهها به ندرت در کلاسترهای مسطح و همسطح قرار میگیرند. این الگوریتم با ترسیم دندروگرام، ساختارهای تودرتو و ماتریس پیوند فضا را آشکار میکند؛ قابلیتی که به دانشمندان داده اجازه میدهد روابط خویشاوندی و شجرهنامهای میان دادهها (مانند تبارشناسی ژنتیکی یا ساختار درختی بدافزارها) را در سطوح مختلف انتزاع لمس کنند.
بینیازی مطلق از فرضیات کورکورانه پیشفرض
در فریمورکهای افرازی مانند K-Means، تعیین کورکورانه تعداد خوشهها (K) پیش از اجرای مدل، یک چالش تئوریک بزرگ است که میتواند مرزهای فضا را مخدوش کند. ضرورت بهکارگیری خوشهبندی سلسلهمراتبی در این است که هیچگونه پیشفرض صلب یا حدس اولیه را به دیتابیس تحمیل نمیکند. مدل کاملاً خودگردان آرایش فضا را سازماندهی کرده و تصمیمگیری برای انتخاب تعداد کلاسترهای بهینه را به فاز پسپردازش و تحلیل هندسی دندروگرام موکول میکند.
انعطاف منحصربهفرد در پذیرش ماتریسهای عدم شباهت
بسیاری از دیتابیسهای صنعتی حاوی متغیرهای کیفی یا پروفایلهای ناهمگونی هستند که استفاده از فواصل اقلیدسی را غیرممکن میسازند. این فریمورک به طراحان اجازه میدهد انواع متریکهای فاصله (مانند فاصله کسینوسی در متنکاوی یا منهتن در محیطهای آلوده به نویز) را به همراه معیارهای اتصال متنوع (Linkage Criteria) ترکیب کنند تا پایدارترین فرم افراز فضا بدون وابستگی به شکل کروی خوشهها حاصل شود.
.
۴. مقایسه ساختاری خوشهبندی سلسلهمراتبی و K-Means
در مهندسی یادگیری ماشین و توسعه سیستمهای هوشمند، دغدغه اصلی طراحان و معماران داده، انتخاب میان دو فریمورک یعنی خوشهبندی سلسلهمراتبی یا K-Means است. درک عمیق تفاوتهای زیرساختی و منطق هندسی این دو متد، خط لوله پردازش دادههای بدون نظارت شما را در بالاترین سطح بهینهسازی قرار میدهد.
تفاوتهای کلیدی
- معماری و منطق الگوریتم K-Means: این فریمورک بر اساس افراز مستقیم فضا (Centroid-based) عمل میکند و به طور صلب نیازمند تعیین پیشفرض تعداد خوشهها (K) پیش از شروع فاز پردازش است. این مدل از نظر خط لوله محاسباتی فوقالعاده سریع، چابک و مقیاسپذیر بوده و برای کلاندادهها (Big Data) گزینهای کاملاً بهینه است. با این حال، فرضی هندسی و محدودکننده دارد: کلاسترها در فضای توپولوژیک باید حتماً کروی، محدب و هماندازه باشند.
- معماری خوشهبندی سلسلهمراتبی: این متد فضا را به صورت تودرتو و بر اساس ماتریس شباهت میسازد. بزرگترین متمایزکننده آن، عدم نیاز به تعیین اولیه تعداد خوشهها است. این الگوریتم به دلیل ترسیم ساختار درختی دندروگرام (Dendrogram)، آرایش فضا را بسیار تفسیرپذیرتر میکند. گرچه سرعت محاسباتی کمتری در مواجهه با مگادیتابیسها دارد، اما برای کشف عمیق و لایهبهلایهی ساختارها بینظیر عمل میکند.
.
چه زمانی باید از خوشهبندی سلسلهمراتبی استفاده کنیم؟
انتخاب این معماری مستقیماً به استراتژی تحلیل دیتابیس شما بستگی دارد. اگر پروژه شما در لایه آنالیز اکتشافی دادهها (EDA) قرار دارد و میخواهید پیش از هرگونه پیشداور فرضی، هندسه پنهان و روابط خویشاوندی متغیرها را کشف کنید، این الگوریتم مقتدرترین انتخاب است.
همچنین در حوزههای تخصصی مانند بیوانفورماتیک برای تحلیل الگوهای ژنتیکی و بیان ژن (Gene Expression)، دستهبندی تبارشناسی فایلها و بدافزارها در امنیت سایبری، و یا در بخشبندی بازار مشتریان با دیتابیسهایی در ابعاد متوسط که نیازمند درک رفتارهای تودرتو و سلسلهمراتبی مشتریان بدون تحمیل مرزهای کروی شکل هستید، این فریمورک بالاترین بازدهی علمی را برای شما تضمین میکند.
.
۵. انواع خوشهبندی سلسلهمراتبی
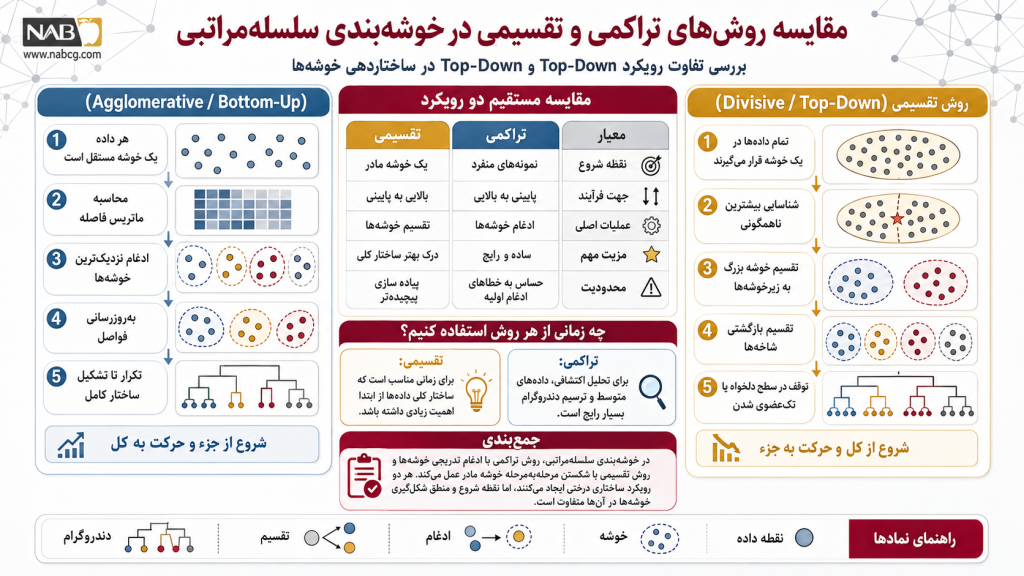
در معماری یادگیری بدون نظارت، خوشهبندی سلسلهمراتبی به یک متدولوژی واحد خلاصه نمیشود. این الگوریتم بسته به اینکه جهت شکلدهی به فضا را از چه نقطهای آغاز کند، به دو استراتژی بنیادین و کاملاً متضاد تقسیم میشود: رویکرد تراکمی (پایینی-به-بالایی) و رویکرد تقسیمی (بالایی-به-پایینی). انتخاب هر یک از این رویکردها، دیدگاهها و نتایج ساختاری متفاوتی را روی دیتابیس شما پدید میآورد.
- رویکرد تراکمی یا پایینی-به-بالایی (Agglomerative / Bottom-Up)
- رویکرد تقسیمی یا بالایی-به-پایینی (Divisive / Top-Down)
.
رویکرد تراکمی یا پایینی-به-بالایی (Agglomerative / Bottom-Up)
این روش که در ادبیات دادهکاوی به HAC (Hierarchical Agglomerative Clustering) یا AGNES معروف است، محبوبترین و پرکاربردترین متدولوژی در این خانواده است. همانطور که از نام «پایینی-به-بالایی» پیداست، ساختار مدل از اتمها یا همان نقاط داده انفرادی شروع شده و به سمت یکپارچگی کل فضا حرکت میکند. این الگوریتم برای دیتابیسهای کوچک تا متوسط کارایی فوقالعادهای دارد.
.
خط لوله عملیاتی و گامبهگام الگوریتم تراکمی:
- مقداردهی اولیه تکعضوی (Singleton): هر نقطه داده واقعی در فضا به عنوان یک خوشه کاملاً مستقل و مجزا در نظر گرفته میشود (برای مثال، اگر دیتابیسی با ۵ نمونه داشته باشیم، کار را با ۵ خوشه شروع میکنیم).
- محاسبه ماتریس عدم شباهت (Dissimilarity Matrix): فاصله جفتبهجفت میان تمامی خوشههای موجود در فضا بر اساس یک متریک مشخص (مانند فاصله اقلیدسی یا منهتن) محاسبه میشود.
- ادغام حریصانه (Greedy Merge): الگوریتم با بررسی ماتریس فواصل، دو خوشهای که کمترین فاصله (بیشترین شباهت) را با یکدیگر دارند شناسایی کرده و آنها را در یک خوشه واحد بزرگتر ادغام میکند.
- بهروزرسانی ساختار فضا: ماتریس فواصل بازنویسی میشود تا فاصله خوشه جدید شکلگرفته با سایر کلاسترهای باقیمانده فضا مجدداً سنجیده شود.
- تکرار تا یکپارچگی کامل: گامهای ۳ و ۴ به صورت متوالی آنقدر تکرار میشوند تا نهایتاً تمام نقاط به یک خوشه واحد بزرگ متصل شوند یا شرط توقف مدل (مانند رسیدن به تعداد کلاستر مورد نظر) محقق شود. در نهایت این فرآیندها روی نمودار درختی دندروگرام تصویرسازی میشوند.
.
رویکرد تقسیمی یا بالایی-به-پایینی (Divisive / Top-Down)
این رویکرد که الگوریتم معروف (Divisive ANAlysis) DIANA پرچمدار آن است، دقیقاً مسیر معکوس مدل تراکمی را طی میکند. در اینجا ما کار را از کل به جزء آغاز میکنیم. مزیت تئوریک رویکرد تقسیمی این است که از همان ابتدای فرآیند، توزیع کل دیتابیس را مد نظر قرار میدهد و به همین دلیل در شناسایی خوشههای بزرگ، دقت بالاتری نسبت به روش تراکمی دارد.
.
خط لوله عملیاتی و گامبهگام الگوریتم تقسیمی:
- کلاستر مادر واحد: فرآیند با قرار گرفتن تمامی نقاط داده موجود در دیتابیس (N نمونه) درون یک خوشه واحد و بسیار بزرگ آغاز میشود.
- شکست ساختاری فضا: الگوریتم به دنبال پیدا کردن ناهمگونترین و متمایزترین نقاط درون کلاستر میگردد تا بر اساس معیار عدم شباهت، این کلاستر بزرگ را به دو زیرخوشه مجزا تقسیم کند که بیشترین تفاوت را با هم دارند.
- انشعاب بازگشتی (Recursive Split): فرآیند تقسیم به صورت بازگشتی روی خوشههای جدید اعمال میشود. در هر مرحله بهینهترین کلاستر برای شکستن انتخاب شده و نقاط پرت (Outliers) از منسجمترین کلاسترها تفکیک میشوند.
- شرط پایان تکعضوی: این توزیع و زنجیره شکست آنقدر ادامه مییابد تا هر نقطه داده به یک خوشه انفرادی (Singleton) تبدیل شود یا مدل به آستانه توقف صلب خود برسد.
.
6.خوشهبندی سلسلهمراتبی چگونه کار میکند؟
الگوریتم خوشهبندی سلسلهمراتبی (با تمرکز بر رویکرد غالب تراکمی یا HAC)، فرآیندی پویا، سیستماتیک و تکرارشونده است که هندسه فضا را بدون نیاز به فرضیات اولیه بازنویسی میکند. این معماری یادگیری بدون نظارت، با اتکا بر ماتریس عدم شباهت و منطق تصمیمگیری حریصانه (Greedy)، ساختار پنهان دادهها را آشکار میسازد. برای درک دقیق سازوکار این مدل، خط لوله عملیاتی آن را گامبهگام بررسی میکنیم:
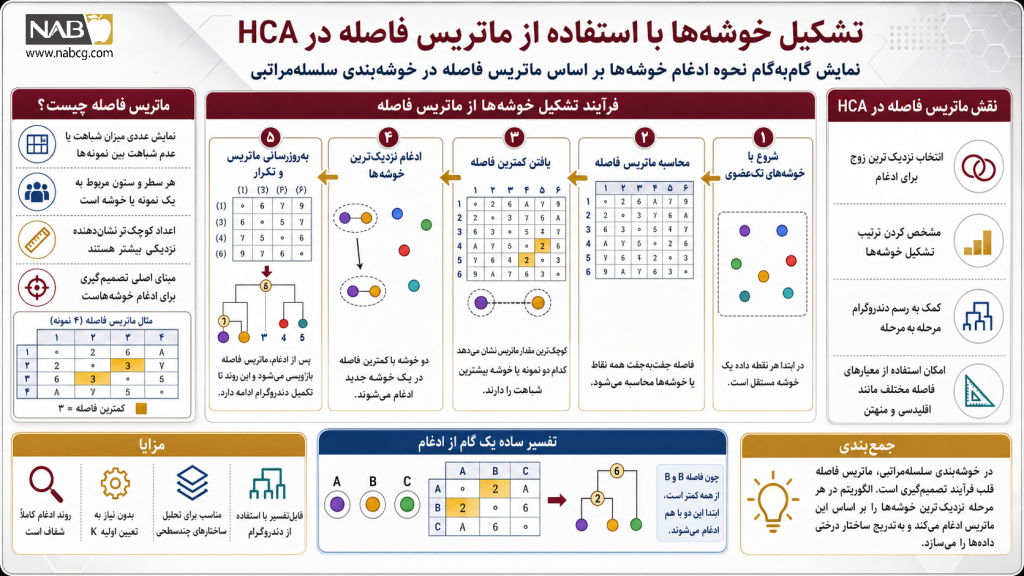
· گام مقداردهی اولیه (Initialization)
در نقطه آغازین فرآیند، تکتک مشاهدات و نقاط داده موجود در دیتابیس (N نمونه) به عنوان یک خوشه مستقل، انفرادی و مجزا (Singleton Cluster) تعریف میشوند. در این مرحله، اگر شما ۱۰۰ نقطه داده داشته باشید، دقیقاً با ۱۰۰ خوشه مستقل کار خود را آغاز خواهید کرد.
· گام محاسبه فواصل هندسی (Distance Matrix Setup)
الگوریتم ماتریس فواصل جفتبهجفت (Proximity Matrix) را میان تمامی خوشهها تشکیل میدهد. در این گام، فاصله فیزیکی هر خوشه با تمام خوشههای دیگر فضا با استفاده از یک متریک مشخص (مانند فاصله اقلیدسی یا منهتن) به طور دقیق اندازهگیری و ثبت میشود.
· گام ادغام و پیوند (Iterative Merging)
با تحلیل ماتریس فواصل، دو خوشهای که کمترین فاصله (بیشترین شباهت ساختاری) را با یکدیگر دارند، شناسایی شده و در یک کلاستر واحد و بزرگتر ادغام میشوند. نحوه سنجش این فاصله به معیار اتصال انتخابی شما (مانند اتصال منفرد، کامل، میانگین یا متد حداقل واریانس وارد) بستگی دارد.
· گام بهروزرسانی ماتریس و تکرار فرآیند
پس از شکلگیری خوشه جدید، تعداد کل خوشهها یک واحد کاهش مییابد. الگوریتم فوراً ماتریس فواصل را بهروزرسانی کرده و فاصله کلاستر جدید را با خوشههای باقیمانده مجدداً محاسبه میکند. گامهای ۳ و ۴ آنقدر به صورت بازگشتی تکرار میشوند تا تمام نقاط به یک خوشه واحد مادر متصل گردند.
· گام ترسیم و برش دندروگرام (Dendrogram Cutting)
کل این فرآیندِ ادغام لایهبهلایه، در قالب یک نمودار درختی به نام دندروگرام ذخیره و تصویرسازی میشود. ارتفاع شاخهها نشاندهنده فاصله ادغام است. در نهایت، با اعمال یک شرط توقف یا خط برش افقی روی این درخت، مرزهای صلب خوشههای بهینه استخراج میشوند.
.
7. مبانی ریاضی و معیارهای پیوند فضا
الگوریتمهای خوشهبندی بر پایه مفهوم سنجش فاصله استوار هستند. از آنجا که این فرآیندها در دسته یادگیری بدون نظارت قرار میگیرند، هسته ریاضی مدل باید بتواند میزان شباهت (Similarity) یا عدم شباهت (Dissimilarity) بین دو نقطه یا دو خوشه را فرمولبندی کند. فواصل ریاضی هرگز نمیتوانند منفی باشند و انتخاب متریک صحیح، مرزهای هندسی فضا را به طور صلب بازنویسی میکند.
.
بخش اول: سنجش فاصله بین نقاط داده (Distance Measures)
پیش از بررسی فواصل میان خوشهها، ابتدا باید یاد بگیریم که ریاضیات چطور فاصله بین دو نقطه مجزا مانند xi و xj را در یک فضای p بعدی محاسبه میکند:
.
۱. فاصله اقلیدسی (Euclidean Distance)
متریک پیشفرض و استاندارد اکثر الگوریتمهای هوش مصنوعی، فاصله اقلیدسی یا همان خط مستقیم بین دو نقطه در یک فضای چندبعدی است. این فرمول هندسی به صورت زیر تعریف میشود:
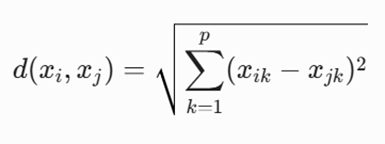
- معرفی متغیرها:
- xi و xj: برپایه بردار ویژگیهای دو نقطه داده مجزا.
- p: تعداد ابعاد یا ویژگیهای موجود در دیتابیس.
- xik و xjk: مقدار ویژگی k-ام برای نقاط اول و دوم.
.
۲. فاصله منهتن (Manhattan Distance)
این متریک که به فاصله تاکسیشهری (Taxicab) نیز معروف است، فاصله بین دو نقطه را بر اساس مجموع قدرمطلق تفاوت مختصات آنها در امتداد محورهای عمود بر هم محاسبه میکند؛ درست مانند حرکت یک خودرو در خیابانهای متقاطع مانهاتان:
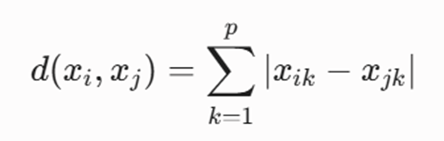
۳. فاصله مینکوفسکی (Minkowski Distance)
یک فرمول تعمیمیافته و مقتدر ریاضی است که فواصل اقلیدسی و منهتن را به عنوان حالتهای خاص در خود جای میدهد:
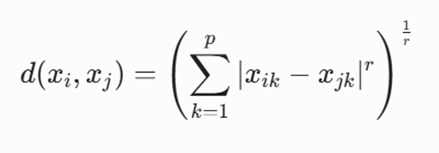
- نکته: اگر پارامتر صلب r=1 تنظیم شود، فرمول تبدیل به فاصله منهتن میشود و اگر r=2 قرار گیرد، دقیقاً فرمول فاصله اقلیدسی حاصل خواهد شد. از دیگر فواصل تخصصی این لایه میتوان به شباهت کسینوسی (Cosine Similarity)، مینکوفسکی، همینگ (Hamming)، ماهالانوبیس (Mahalanobis) و هاسدورف (Hausdorff) اشاره کرد.
.
بخش دوم: معیارهای اتصال و پیوند خوشهها (Linkage Criteria)
بزرگترین چالش ریاضی در رویکرد تراکمی این است: چطور فاصله میان دو خوشه که هر کدام شامل چندین نقطه داده هستند را بسنجیم؟ معیارهای اتصال، توابع هدف ریاضی هستند که نحوه بهروزرسانی ماتریس عدم شباهت (Dissimilarity Matrix) را مشخص میکنند:

.
۱. اتصال مینیمم یا منفرد (Single / Min Linkage)
این معیار، فاصله بین دو خوشه A و B را برابر با حداقل فاصله بین نزدیکترین نقاط آنها در نظر میگیرد:
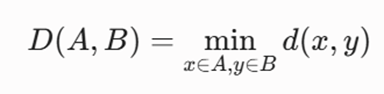
- رفتار هندسی: برای کشف کلاسترهای نامنظم، نامحدب و کشیده عالی است.
- نقطه ضعف: شدیداً به نویز حساس است و دچار پدیده زنجیرهای شدن (Chaining Effect) میشود.
.
۲. اتصال ماکزیمم یا کامل (Complete / Max Linkage)
این معیار، فاصله میان دو خوشه را بر اساس بیشترین فاصله بین دورترین نقاط آنها فرمولبندی میکند:
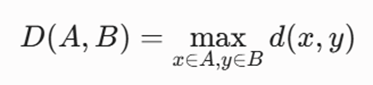
- رفتار هندسی: خوشههایی بسیار فشرده، متوازن و کاملاً کروی پدید میآورد.
- نقطه ضعف: در مواجهه با کلاسترهای بزرگ، نتایج را دچار سوگیری کرده و نسبت به دادههای پرت حساس است.
.
۳. اتصال میانگین (Average Linkage)
موازنهای منطقی و پایدار که فاصله بین دو کلاستر را برابر با میانگین فواصل جفتبهجفت تمام نقاط موجود در آنها محاسبه میکند:
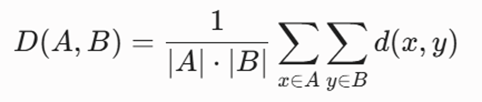
- معرفی متغیرها: |A| و |B|نشاندهنده تعداد اعضا یا اندازه خوشههای A و B هستند.
.
۴. متد حداقل واریانس وارد (Ward’s Minimum Variance Method)
متد وارد، مقتدرترین روش پیوند در علم داده است. این روش به جای فواصل خطی، به دنبال کمینهسازی مجموع مربعات انحرافات از مرکز (Variance) پس از ادغام است. هدف آن کمینه کردن افزایش واریانس درونخوشهای است که به صورت زیر فرمولبندی میشود:
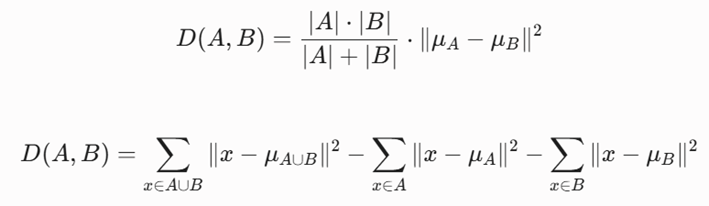
- معرفی متغیرها:
- μA و μB: بردارهای سنتروید (مرکز ثقل) خوشههای A و B.
- μA∪B: مرکز ثقل جدید حاصل از ادغام دو خوشه.
- x: نقاط داده متعلق به خوشهها.
- رفتار هندسی: این روش که برای متغیرهای کمی ماسب است، خوشههایی کاملاً هماندازه، مجزا و کروی تولید میکند.
.
8.مثال
.
مثال اول | حوزه: مهندسی متن و وبلاگنویسی (NLP)
مسئله: میخواهیم ۳ کلمه کلیدی را بر اساس تعداد تکرار آنها در دو مقاله مختلف خوشهبندی کنیم. فرض کنید بردار ویژگی این کلمات در فضای ۲ بعدی (p=2) به صورت زیر است:
- نقطه A (کلمه “هوش مصنوعی”): (1, 2)
- نقطه B (کلمه “یادگیری ماشین”): (2, 3)
- نقطه C (کلمه “شبکه عصبی”): (5, 6)
هدف: محاسبه ماتریس فواصل جفتبهجفت با فاصله منهتن (Manhattan) و ادغام گام اول در رویکرد تراکمی.
راه حل گامبهگام با فرمول:
– ۱: یادآوری فرمول فاصله منهتن
برای دو نقطه xi و xj در فضای ۲ بعدی، فرمول به صورت زیر است:
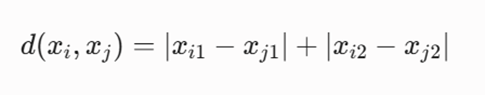
– ۲: محاسبه فواصل جفتبهجفت
- فاصله بین A(1,2) و B(2,3)
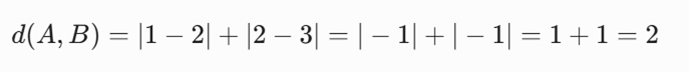
- فاصله بین A(1,2) و C(5,6)
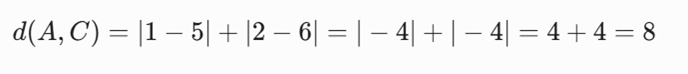
- فاصله بین B(2,3) و C(5,6)
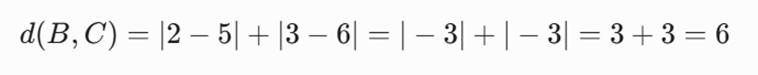
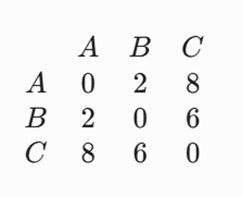
-گام ۳: تشکیل ماتریس فواصل اولیه
-گام ۴: تصمیمگیری حریصانه برای ادغام
الگوریتم ماتریس را اسکن کرده و کمترین مقدار غیرصفر یعنی d(A, B) = 2 را انتخاب میکند.
- خروجی گام اول: نقاط A و B با یکدیگر ادغام شده و خوشه جدید (A, B) را در ارتفاع (Height) ۲ دندروگرام تشکیل میدهند.
.
مثال دوم | حوزه: سیستمهای بانکی و متقاضیان وام
مسئله: دادههای مثال قبل را در نظر بگیرید. اکنون یک خوشه ادغامشده به نام K1 = (A, B) داریم و یک خوشه تکعضوی C(5,6). میخواهیم ماتریس فواصل را بهروزرسانی کنیم تا مشخص شود در گام بعدی چه اتفاقی میافتد.
- معیار اتصال: اتصال کامل (Complete Linkage)
- متریک مبنا: فواصل منهتن محاسبهشده در مثال قبل (d(A,B)=2, d(A,C)=8, d(B,C)=6).
راه حل گامبهگام با فرمول:
-گام ۱: یادآوری فرمول اتصال کامل (Complete Linkage)
فاصله بین دو خوشه بر اساس بیشترین فاصله بین دورترین نقاط آنها تعیین میشود:
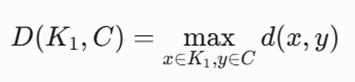
-گام ۲: جایگذاری مقادیر در فرمول
از آنجا که خوشه K1 شامل اعضای A و B است، داریم:
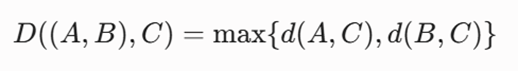
مقادیر فواصل منهتن را از گام قبل جایگذاری میکنیم:
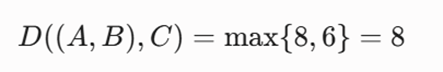
-گام ۳: بهروزرسانی ماتریس فواصل
حالا ماتریس فواصل جدید در این سطح از سلسلهمراتب به صورت ۲ در ۲ بازنویسی میشود:

-گام ۴: تکرار تا یکپارچگی نهایی
تنها دو خوشه باقی مانده است. الگوریتم در این مرحله خوشه (A, B) را با خوشه C در ارتفاع دندروگرام ۸ ادغام میکند و کل دیتابیس در یک خوشه واحد مادر قرار میگیرد.
.
مثال سوم | حوزه: بیوانفورماتیک و بیان ژن
مسئله: دو کلاستر نیمه شکلگرفته از ساختارهای ژنتیکی داریم:
- خوشه X شامل دو نقطه: X = {(1, 2), (2, 2)}
- خوشه Y شامل دو نقطه: Y = {(6, 8), (7, 8)}
هدف: محاسبه دقیق فاصله هندسی بین این دو خوشه با استفاده از اتصال میانگین (Average Linkage) بر پایه متریک فاصله اقلیدسی.
راه حل گامبهگام با فرمول:
-گام ۱: یادآوری فرمول اتصال میانگین
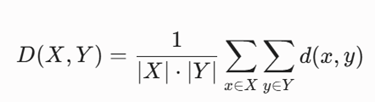
تعداد اعضای هر دو خوشه برابر با ۲ است (X = 2 و Y = 2)، بنابراین مخرج کسر برابر است با: 2 ˟ 2 = 4. ما باید ۴ فاصله اقلیدسی جفتبهجفت را حساب کنیم.
-گام ۲: محاسبه فواصل اقلیدسی جفتبهجفت
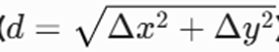
- فاصله نقطه اول X یعنی (1,2) با نقاط خوشه Y
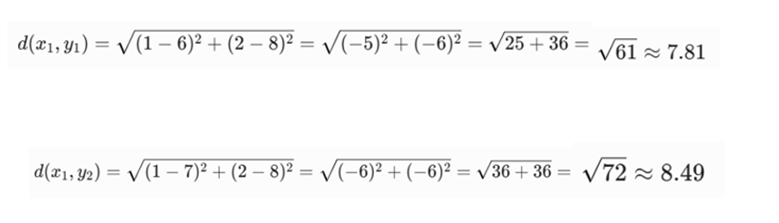
- فاصله نقطه دوم X یعنی (2,2) با نقاط خوشه Y
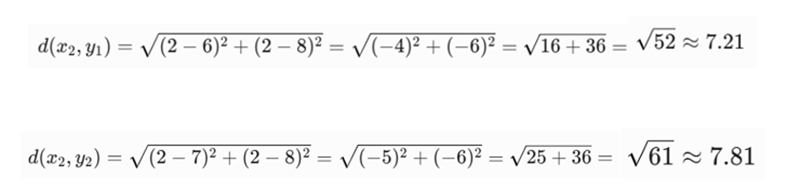
-گام ۳: محاسبه میانگین حسابی فواصل
مجموع فواصل به دست آمده را بر تعداد آنها (۴)تقسیم میکنیم:
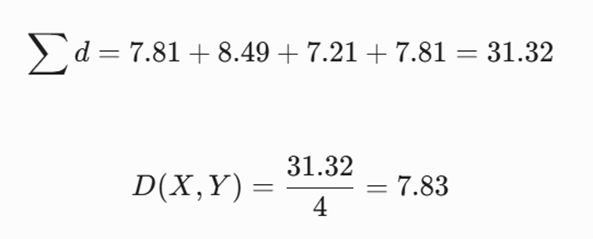
- نتیجه تحلیل: فاصله نهایی میان این دو خوشه ژنتیکی بر اساس معیار اتصال میانگین برابر با ۷.۸۳ است. این عدد مبنای مقایسه الگوریتم با سایر کلاسترهای فضا برای ادغامهای بعدی خواهد بود.
.
9.ابزار ها و فریم ورک های محبوب
در اکوسیستم یادگیری ماشین، اجرای مقتدرانه خوشهبندی سلسلهمراتبی به ابزارهای بهینهسازی شده وابسته است. در ادامه، برترین کتابخانههای پایتون به همراه قطعه کدهای واقعی، تمیز و منطبق بر پالت رنگی وبسایت شما ارائه شده است:
.
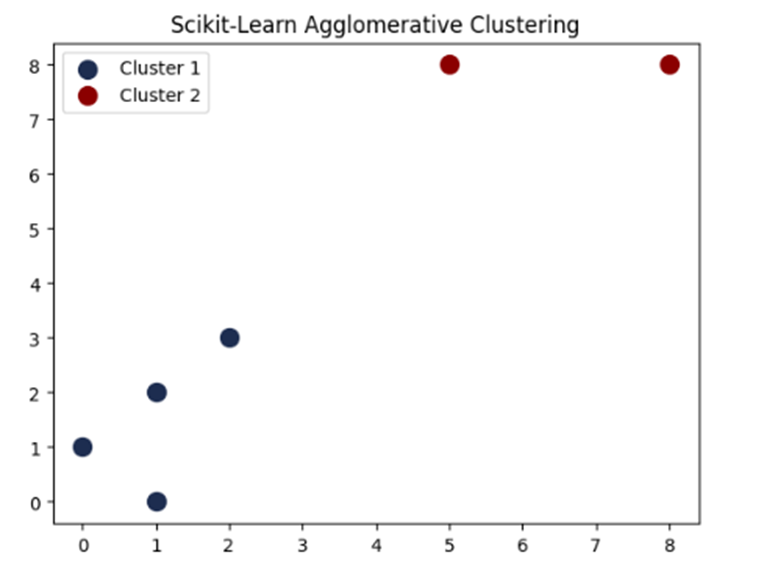
کتابخانه Scikit-Learn
این فریمورک استانداردترین ابزار برای توسعه الگوریتمهای افرازی و تراکمی است. کلاس AgglomerativeClustering مدیریت ماتریس فواصل را به عهده میگیرد.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
# دیتابیس فرضی
X = np.array([[1, 2], [2, 3], [5, 8], [8, 8], [1, 0], [0, 1]])
# پیکربندی مدل با متد اتصال وارد
model = AgglomerativeClustering(n_clusters=2, linkage='ward')
labels = model.fit_predict(X)
# رسم کلاسترها با پالت اختصاصی (آبی ملایم هوش مصنوعی و زرشکی)
colors = ['#1D2D50', '#8B0000']
for i in range(2):
plt.scatter(X[labels == i, 0], X[labels == i, 1], c=colors[i], s=100, label=f'Cluster {i+1}')
plt.title('Scikit-Learn Agglomerative Clustering')
plt.legend()
plt.show()
خروجی:
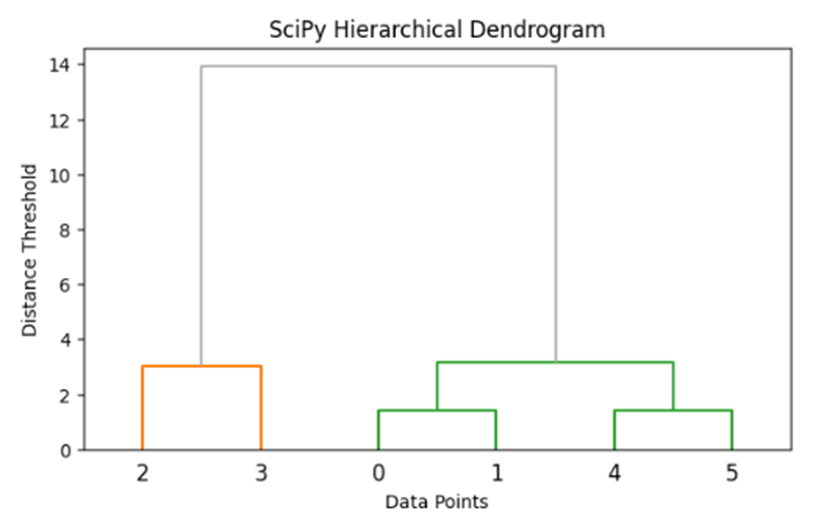
ماژول SciPy (متخصص ترسیم دندروگرام)
اگر نیاز به آنالیز ساختار درختی فضا و تماشای سطوح ماتریس پیوند دارید، ماژول scipy.cluster.hierarchy مقتدرترین ابزار ممکن است.
from scipy.cluster.hierarchy import linkage, dendrogram
# محاسبه ماتریس پیوند به روش تراکمی
Z = linkage(X, method='ward')
# رسم نقشه درختی دندروگرام با خطوط زرشکی و خاکستری
plt.figure(figsize=(7, 4))
dendrogram(Z, color_threshold=4, above_threshold_color='#B0B0B0')
plt.title('SciPy Hierarchical Dendrogram')
plt.xlabel('Data Points')
plt.ylabel('Distance Threshold')
plt.show()
خروجی:
10.پیاده سازی گام به گام
در این بخش، خط لوله عملیاتی الگوریتم خوشهبندی سلسلهمراتبی تراکمی (HAC) را به صورت گامبهگام روی یک دیتابیس شبیهسازی شده پیادهسازی میکنیم. فرآیند اجرای مدل به این صورت است:
- تولید و آمادهسازی دادهها: ابتدا مجموعهای از دادههای مصنوعی با توزیعهای مشخص تولید میشوند.
- پیشپردازش و مقیاسدهی (Scaling): از آنجا که این الگوریتم کاملاً وابسته به معیارهای فاصله است، دادهها باید استانداردسازی شوند تا ویژگیهایی با مقیاس بزرگتر، نتایج هندسی مدل را مخدوش نکنند.
- رسم دندروگرام تئوریک: قبل از مشخص کردن تعداد قطعی خوشهها، با استفاده از متد پیوند حداقل واریانس وارد (Ward)، کل ساختار درختی فضا را ترسیم میکنیم.
- اعمال خط برش و استخراج کلاسترها: بر اساس آنالیز دندروگرام، یک خط برش افقی در فضا اعمال کرده و نقاط داده را به خوشههای نهایی تخصصی تقسیم میکنیم.
- تصویرسازی هندسی خروجی
کد پایتون:
# =====================================================================
# بخش اول: وارد کردن کتابخانههای زیرساختی و توسعه مدل
# =====================================================================
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import linkage, dendrogram
# =====================================================================
# بخش دوم: تولید دیتابیس مصنوعی و استانداردسازی مقیاس فضا
# =====================================================================
# تولید ۵۰ نمونه داده تصادفی در ۳ مرکز مجزا (فضای ۲ بعدی)
X, y_true = make_blobs(n_samples=50, centers=3, cluster_std=1.5, random_state=42)
# استانداردسازی ویژگیها (میانگین صفر و واریانس یک) جهت حفظ عدالت در محاسبات فاصله
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# تعریف دقیق پالت رنگی اختصاصی سایت در کدهای گرافیکی
# Crimson (زرشکی), AI Soft Blue (آبی ملایم هوش مصنوعی), Active Gold (طلایی فعال), Metal Silver/Gray
PALETTE = {
'crimson': '#8B0000',
'ai_blue': '#4A90E2',
'gold': '#FFD700',
'silver': '#B0B0B0',
'light_gray': '#F5F5F5'
}
# =====================================================================
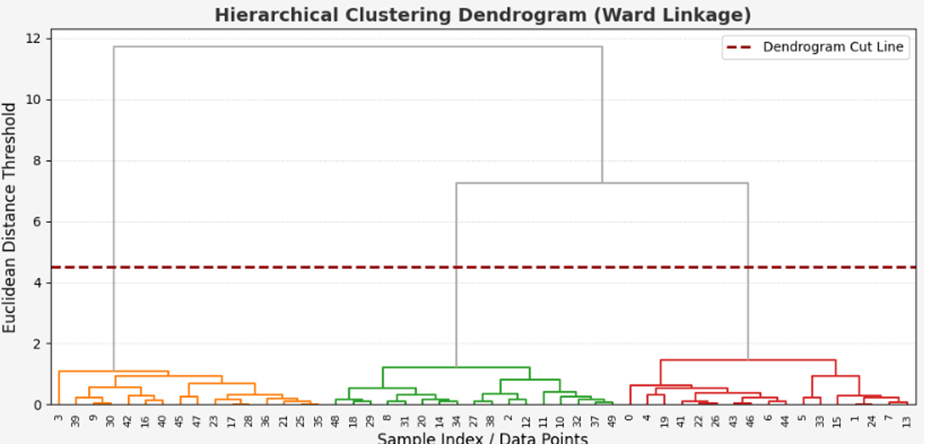
# بخش سوم: محاسبه ماتریس پیوند و ترسیم ساختار درختی دندروگرام
# =====================================================================
# محاسبه ماتریس فواصل و ساختار پیوند با استفاده از متد واریانس وارد (Ward)
linkage_matrix = linkage(X_scaled, method='ward')
plt.figure(figsize=(10, 5), facecolor=PALETTE['light_gray'])
ax1 = plt.axes()
ax1.set_facecolor('white') # پسزمینه سفید برای خوانایی بهتر نمودار
# رسم دندروگرام با تنظیم رنگ خطوط فراتر از آستانه برش به رنگ نقرهای/خاکستری
dendro = dendrogram(
linkage_matrix,
color_threshold=4.5, # خط آستانه برای تفکیک رنگ خوشهها
above_threshold_color=PALETTE['silver']
)
# اعمال خط برش افقی فرضی به رنگ زرشکی برای مشخص کردن سطح تفکیک فضا
plt.axhline(y=4.5, color=PALETTE['crimson'], linestyle='--', linewidth=2, label='Dendrogram Cut Line')
# تنظیمات لیبلها و عناوین به زبان انگلیسی مطابق اصول بینالمللی سئو
plt.title('Hierarchical Clustering Dendrogram (Ward Linkage)', fontsize=14, fontweight='bold', color='#333333')
plt.xlabel('Sample Index / Data Points', fontsize=12)
plt.ylabel('Euclidean Distance Threshold', fontsize=12)
plt.legend(loc='upper right')
plt.grid(axis='y', linestyle=':', alpha=0.6)
plt.tight_layout()
plt.show()
# =====================================================================
# بخش چهارم: اجرای الگوریتم تراکمی نهایی و استخراج خوشهها
# =====================================================================
# بر اساس خط برش دندروگرام، تعداد ۳ خوشه بهینه را استخراج میکنیم
hca = AgglomerativeClustering(n_clusters=3, linkage='ward')
cluster_labels = hca.fit_predict(X_scaled)
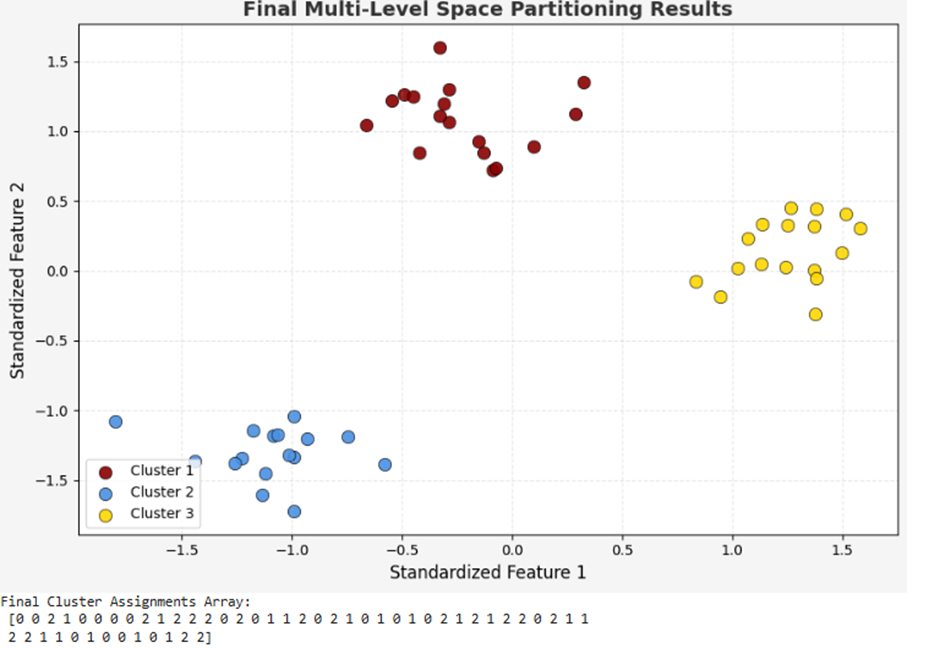
# =====================================================================
# بخش پنجم: تصویرسازی هندسی خوشههای نهایی در فضای ویژگیها
# =====================================================================
plt.figure(figsize=(9, 6), facecolor=PALETTE['light_gray'])
ax2 = plt.axes()
ax2.set_facecolor('white')
# تعریف آرایه رنگها بر اساس خوشههای استخراجشده از پالت اختصاصی
mapped_colors = [PALETTE['crimson'], PALETTE['ai_blue'], PALETTE['gold']]
# رسم تکتک نقاط داده بر اساس برچسب کلاستر تخصیص داده شده
for i in range(3):
plt.scatter(
X_scaled[cluster_labels == i, 0],
X_scaled[cluster_labels == i, 1],
s=80,
c=mapped_colors[i],
label=f'Cluster {i+1}',
edgecolors='black',
linewidths=0.5,
alpha=0.9
)
# تنظیمات نهایی نمودار پراکندگی خروجی با لیبلهای انگلیسی
plt.title('Final Multi-Level Space Partitioning Results', fontsize=14, fontweight='bold', color='#333333')
plt.xlabel('Standardized Feature 1', fontsize=12)
plt.ylabel('Standardized Feature 2', fontsize=12)
plt.legend(loc='lower left')
plt.grid(True, linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
# چاپ آرایه نهایی تخصیص خوشهها در کنسول جهت تایید صحت خط لوله
print("Final Cluster Assignments Array:\n", cluster_labels)
خروجی:
11.کاربرد های الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
- بیوانفورماتیک و ژنتیک (Bioinformatics): مقتدرترین ابزار برای تحلیل الگوهای ژنتیکی، بیان ژن (Gene Expression) و طبقهبندی گونههای زیستی بر اساس قرابتهای ساختاری. این مدل به دانشمندان اجازه میدهد شجرهنامهها و تبارشناسیهای ژنتیکی را با دقت بالا بازسازی کنند.
- امنیت سایبری و تحلیل بدافزارها (Cybersecurity): مهندسان امنیت از این فریمورک برای دستهبندی تبارشناسی فایلها، امضاهای دیجیتال و رفتارهای تودرتوی بدافزارها استفاده میکنند. این کار به شناسایی پویای خانوادههای جدید ویروسها و حملات سایبری کمک شایانی میکند.
- بخشبندی پیشرفته بازار و مشتریان (Market Segmentation): برندها برای تحلیل دیتابیسهای مشتریان در ابعاد متوسط از این الگوریتم بهره میبرند. مدل بدون تحمیل مرزهای کروی، رفتارهای لایهبهلایه و تودرتوی خریداران را برای طراحی بستههای تبلیغاتی اختصاصی کشف میکند.
- پردازش زبان طبیعی و متنکاوی (NLP): در مهندسی متن، از این ساختار سلسلهمراتبی برای خوشهبندی معنایی اسناد، مقالات و واژگان بر اساس متریکهای فاصله (مانند فاصله کسینوسی) استفاده میشود تا درخت موضوعی محتوا استخراج شود.
- سیستمهای توصیهگر (Recommendation Systems): پلتفرمهای سرگرمی و فروشگاهی برای دستهبندی محصولات، فیلمها یا موزیکها در گروههای اصلی و زیرگروههای تودرتو از این متد استفاده میکنند تا پیشنهادهای دقیقتری به کاربران ارائه دهند.
- تحلیل شبکههای اجتماعی (Social Network Analysis): به منظور شناسایی لایهبهلایه جوامع، حلقههای دوستی و تحلیل نحوه انتشار اطلاعات یا شایعات در گرههای مختلف شبکه کاربرد وسیعی دارد.
.
12.مطالعه موردی
.
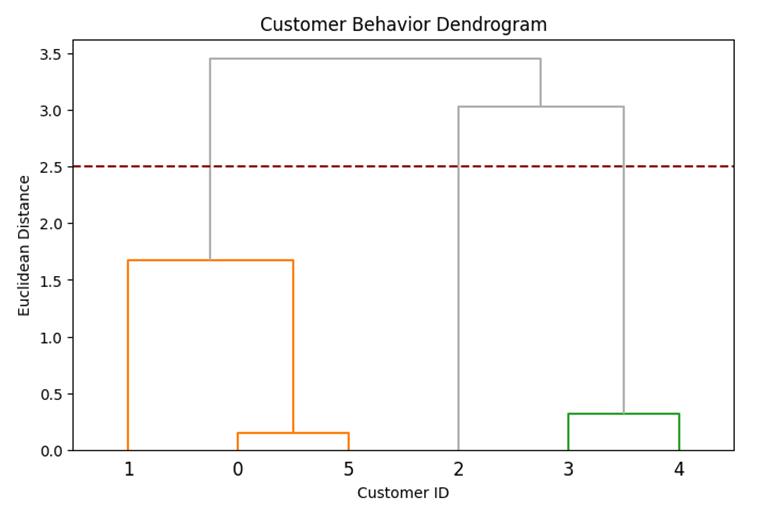
مطالعه موردی اول: بخشبندی استراتژیک مشتریان مرکز خرید
- مسئله و چالش: یک مرکز خرید بزرگ با هزاران مشتری مواجه است که رفتارهای خرید ناهمگونی دارند. چالش اصلی این است که مدیریت نمیداند کدام گروهها «مشتریان وفادار با قدرت خرید بالا» و کدام «مشتریان گذری» هستند.
- هدف: شناسایی گروههای همگن مشتریان بدون داشتن برچسب قبلی برای اجرای کمپینهای تبلیغاتی شخصیسازیشده.
- راهکار: استفاده از خوشه بندی سلسلهمراتبی برای ترسیم دندروگرامِ رفتار مشتریان بر اساس درآمد سالانه و امتیاز هزینه (Spending Score).
کد پایتون:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from scipy.cluster.hierarchy import dendrogram, linkage
# بارگذاری دیتابیس مشتریان (فرضی)
data = {'Annual_Income': [15, 16, 80, 85, 90, 20], 'Spending_Score': [39, 81, 6, 77, 85, 40]}
df = pd.DataFrame(data)
# استانداردسازی ویژگیها
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df)
# محاسبه ماتریس پیوند (متد Ward)
Z = linkage(df_scaled, method='ward')
# ترسیم دندروگرام با پالت اختصاصی سایت
plt.figure(figsize=(8, 5))
dendrogram(Z, labels=df.index, color_threshold=2.5, above_threshold_color='#B0B0B0')
plt.title('Customer Behavior Dendrogram')
plt.xlabel('Customer ID')
plt.ylabel('Euclidean Distance')
plt.axhline(y=2.5, color='#8B0000', linestyle='--') # خط برش به رنگ زرشکی
plt.show()
خروجی:
مطالعه موردی دوم: تحلیل الگوهای بیان ژن (بیوانفورماتیک)
- مسئله و چالش: در یک آزمایش بیولوژیکی، فعالیت ۵۰ ژن مختلف در شرایط بیماریهای متفاوت ثبت شده است. چالش اینجاست که ژنها دارای روابط همبستگی پیچیده و تودرتو هستند
- . هدف: دستهبندی ژنهایی که «رفتار بیان» مشابهی دارند تا بتوان ژنهای موثر در بیماری را کشف کرد.
- راهکار: اعمال الگوریتم سلسلهمراتبی برای ایجاد یک ساختار درختی از قرابتِ عملکردی ژنها.
کد پایتون:
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
# شبیهسازی دادههای بیان ژن (۵۰ ژن، ۲ ویژگی بیان)
X, _ = make_blobs(n_samples=50, centers=4, cluster_std=0.5, random_state=42)
# اجرای الگوریتم با ۳ خوشه نهایی
model = AgglomerativeClustering(n_clusters=3, linkage='average')
clusters = model.fit_predict(X)
# رسم نتیجه بصری با پالت آبی هوش مصنوعی و طلایی
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis', edgecolors='black')
plt.title('Gene Expression Cluster Analysis')
plt.xlabel('Expression Feature 1')
plt.ylabel('Expression Feature 2')
plt.colorbar(label='Cluster Group')
plt.show()
خروجی:
13.مزایا الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
- عدم نیاز به تعیین پیشفرض تعداد خوشهها (K): بزرگترین مزیت این مدل، رهایی از حدس کورکورانه تعداد کلاسترها پیش از شروع پردازش است. برخلاف K-Means، الگوریتم به صورت خودگردان کل فضا را افراز کرده و انتخاب تعداد بهینه را به فاز آنالیز نمودار درختی موکول میکند.
- تصویرسازی مقتدرانه به کمک دندروگرام (Dendrogram): این الگوریتم یک خروجی بصری فوقالعاده شفاف و درختی پدید میآورد. دندروگرام نه تنها روابط میان خوشهها، بلکه ساختار تودرتو و میزان دقیق فاصله یا عدم شباهت مشاهدات را در سطوح مختلف تفکیک فضا به نمایش میگذارد.
- انعطافپذیری مطلق در انتخاب متریکهای فاصله: این فریمورک محدودیتی در استفاده از فواصل هندسی ندارد. شما میتوانید بر اساس ماهیت دیتابیس خود، از انواع متریکها مانند فاصله اقلیدسی، منهتن (برای دادههای نویزی) یا فاصله کسینوسی (برای پردازش متن و یادگیری عمیق) استفاده کنید.
- کشف خوشهها با اشکال هندسی پیچیده و غیرکروی: از آنجا که این الگوریتم از معیارهای اتصال متفاوتی (مانند Single یا Complete Linkage) بهره میبرد، برخلاف K-Means مجبور به ایجاد کلاسترهای صرفاً کروی نیست و میتواند الگوهای هندسی نامنظم و کشیده را به خوبی در فضا منزوی و کشف کند.
- ثبات و تکرارپذیری ۱۰۰ درصدی خروجی مدل: این الگوریتم فاقد فاز مقداردهی اولیه تصادفی (Random Initialization) است. در نتیجه، با هر بار اجرای کد بر روی یک دیتابیس ثابت، دقیقاً یک ساختار درختی و نتایج کاملاً یکسانی حاصل میشود که اعتبار تحلیلهای آماری سایت شما را تضمین میکند.
- کارایی بینظیر در کشف الگوهای شجرهنامهای و تبارشناسی: ساختار سلسلهمراتبی این مدل، آن را به بهینهترین گزینه برای کاربردهایی تبدیل کرده که ماهیت دادهها در آنها ذاتاً درختی است؛ مانند دستهبندی گونههای زیستی در بیوانفورماتیک یا تحلیل ساختار فایلها در امنیت سایبری.
.
14.معایب الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
- پیچیدگی محاسباتی بسیار بالا (High Computational Cost): بزرگترین نقطه ضعف این الگوریتم، عدم مقیاسپذیری آن است. پیچیدگی زمانی این مدل معمولاً از مرتبه O(N^3) یا در حالت بهینه O(N^2) است. این یعنی با افزایش حجم دادهها، زمان پردازش به صورت توانی منفجر میشود و برای مگادیتابیسها اصلاً گزینه مناسبی نیست.
- مصرف شدید حافظه: این فریمورک برای ساخت سلسلهمراتب، نیازمند محاسبه و ذخیرهسازی ماتریس فواصل (Proximity Matrix) بین تکتک نمونهها در حافظه RAM است. پیچیدگی فضایی O(N^2) باعث میشود که در مواجهه با کلاندادهها، سیستم با خطای کمبود حافظه مواجه و کرش کند.
- عدم امکان اصلاح خطا در گامهای بعدی (Irreversible Steps): این الگوریتم بر اساس منطق حریصانه (Greedy) عمل میکند. به محض اینکه دو خوشه در یک مرحله با هم ادغام یا تقسیم شوند، این تصمیم صلب دیگر تا پایان الگوریتم قابل بازگشت، اصلاح یا بهینهسازی مجدد نیست؛ حتی اگر این ادغام در مراحل بعدی باعث مخدوش شدن مرزهای فضا شود.
- حساسیت شدید به نویز و دادههای پرت (Outliers): رفتار هندسی مدل به شدت به معیار اتصال (Linkage) وابسته است. برای مثال، متد Single Linkage به دلیل پدیده زنجیرهای شدن (Chaining Effect) و متد Complete Linkage به دلیل تمرکز روی دورترین فواصل، به شدت تحت تاثیر دادههای پرت و نویز محیطی منحرف میشوند.
- ابهام در ابعاد بالا (Curse of Dimensionality): در فضاهایی با ابعاد و ویژگیهای بسیار زیاد (High-Dimensional Data)، مفهوم فاصله اقلیدسی کارایی خود را از دست میدهد؛ زیرا فاصله بین همه نقاط به یکدیگر نزدیک به نظر میرسد و دندروگرام خروجی دچار سردرگمی هندسی میشود.
- چالش تئوریک در انتخاب خط برش بهینه: اگرچه دندروگرام روابط را به خوبی تصویرسازی میکند، اما تعیین اینکه دقیقاً در چه ارتفاعی باید خط برش افقی را برای استخراج تعداد خوشهها قرار داد، استاندارد ریاضی مطلقی ندارد و تا حد زیادی وابسته به تجربه طراح یا شهود ذهنی است.
.
15.نوآوری و آینده الگوریتم خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
- توسعه الگوریتمهای ترکیبی مقیاسپذیر (BIRCH & CURE): بزرگترین نوآوری مدرن، غلبه بر چالش محاسباتی این الگوریتم است. الگوریتم BIRCH با معرفی درخت ویژگی خوشهبندی (CF-Tree)، دادهها را در یک فاز فشرده کرده و سپس خوشهبندی سلسلهمراتبی را روی آن اجرا میکند تا برای کلاندادهها بهینه شود. الگوریتم CURE نیز به جای یک نقطه، از چندین نقطه نماینده برای هر خوشه استفاده میکند تا اشکال هندسی بسیار پیچیده را کشف کند.
- ادغام عمیق با شبکههای عصبی (Deep Hierarchical Clustering): یکی از هیجانانگیزترین نوآوریها، ترکیب این الگوریتم با خودرمزگذارها (Autoencoders) در یادگیری عمیق است. ابتدا دادههای ابعاد بالا (مانند تصاویر یا متن) به یک فضای برداری فشرده (Embedding) منتقل میشوند و سپس معماری سلسلهمراتبی، ساختار درختی و معنایی این ویژگیهای عمیق را استخراج میکند.
- هوشمندسازی دندروگرام با زمانبندی پویا (Dynamic Tree Cutting): در رویکردهای سنتی، برش دندروگرام به صورت یک خط افقی صلب انجام میشد. نوآوریهای اخیر با معرفی متدهای پویا، به الگوریتم اجازه میدهند که بر اساس چگالی محلی دادهها، خط برش را در ارتفاعهای مختلف نمودار درختی به صورت خودکار تغییر دهد تا خوشههایی با چگالی نامتوازن به درستی تفکیک شوند.
- معیارهای اتصال تطبیقی (Adaptive Linkage Criteria): فریمورکهای نوین یادگیری ماشین اجازه میدهند معیارهای اتصال (Linkage) به صورت گرافهای گرافیکی و با توجه به توپولوژی فضا به طور محلی تغییر کنند. این نوآوری مانع از بروز پدیده زنجیرهای شدن (Chaining Effect) در مواجهه با نویزهای شدید فضا میشود.
- کلاسترینگ زمان واقعی دادههای جریانی (Streaming Hierarchical Clustering): نسخههای مدرن این الگوریتم قادرند بدون نیاز به بازسازی کل دندروگرام از ابتدا، دادههای جدیدی که به صورت جریانی (Stream) دریافت میشوند را به صورت آنلاین و در زمان واقعی به شاخههای موجود در درخت متصل کنند که در اینترنت اشیاء (IoT) کاربرد وسیعی دارد.
.
جمع بندی
خوشهبندی سلسلهمراتبی یکی از قدرتمندترین روشهای یادگیری بدون نظارت برای کشف ساختارهای پنهان در دادهها است که با ایجاد یک نمایش درختی از روابط میان نمونهها، دیدی عمیقتر نسبت به روشهای خوشهبندی سنتی ارائه میدهد. همانطور که مشاهده شد، این الگوریتم با استفاده از معیارهای مختلف فاصله و روشهای اتصال گوناگون میتواند ساختارهای پیچیده و چندسطحی دادهها را شناسایی کرده و آنها را در قالب دندروگرام نمایش دهد.
مزیت اصلی این رویکرد، عدم نیاز به تعیین تعداد خوشهها در ابتدای فرآیند و قابلیت تحلیل سلسلهمراتبی دادهها است. از سوی دیگر، چالشهایی مانند پیچیدگی محاسباتی بالا، مصرف حافظه زیاد و حساسیت به دادههای پرت، استفاده از آن را در مجموعهدادههای بسیار بزرگ محدود میکنند. به همین دلیل، روشهای نوینی مانند BIRCH، CURE و خوشهبندی سلسلهمراتبی مبتنی بر یادگیری عمیق توسعه یافتهاند تا این محدودیتها را کاهش دهند.
در نهایت، خوشهبندی سلسلهمراتبی را میتوان ابزاری ارزشمند برای تحلیل دادههای پیچیده دانست؛ ابزاری که نهتنها گروهبندی دادهها را انجام میدهد، بلکه روابط، شباهتها و ساختارهای چندلایه موجود در دادهها را نیز آشکار میسازد. به همین دلیل، این الگوریتم همچنان یکی از روشهای مهم و پرکاربرد در تحلیل داده، هوش مصنوعی و پژوهشهای علمی محسوب میشود.